Decision-theoretic foundations for statistical causality: Response to Shpitser
-
Philip Dawid


Abstract
I thank Ilya Shpitser for his comments on my article, and discuss the use of models with restricted interventions.
1 Introduction
It has been a pleasure to read Ilya Shpitser’s thoughtful discussion [1] of my article [2]. I am delighted to see how readily he has taken the DT approach to statistical causality, and he has demonstrated admirable facility in manipulating it. As he notes, I have been advocating and exploring this approach for over 20 years, though with disappointingly little causal effect. I hope that excellent contributions such as his to this area will help to spread the good word more widely.
He says: “It is thus not clear what role an explicitly decision-focused type of causal inference would play in the ecosystem in which empirical science is done today.” This is a fair point, but one that can just as easily be directed at the other current formal frameworks, such as potential outcomes and graphical models. In my partial defence, I could point to the importance, in this ecosystem, of the ability to transport [3] causal findings from one context (e.g. that of an experimental or observational study) to another (e.g. “real-world” behaviour in a population of interest). This typically involves making an invariance assumption [4] that certain marginal or conditional distributions are the same in all relevant contexts. DT focuses on just this kind of assumption, where a conditional distribution, e.g. of
2 Graphs or algebra?
Shpitser asks: “Why is the DT approach based on directed acyclic graphs?” To which I answer: “It isn’t.” It is based, as indicated above, on the identification of transportable distributional components, which are then described in terms of ECI, and manipulated using the algebra of conditional independence. Given an initial set of assumptions, expressed as ECI properties, we can uncover their implications by repeated application of the ECI axioms (properties P1–P5 in my article). Sometimes our assumptions can be represented and manipulated (using
That said, DAG representations of causal problems are ubiquitous, and, when available, are much easier to understand and apply than the stark algebra. I have used and investigated DAGs in my article for these reasons – but they are never necessary.
3 Identification theory
Most of Shpitser’s discussion concerns an incidental aspect of DT: formal intervention variables are introduced only when they represent genuine real-world interventions. To me this seems only natural, though I am perhaps not quite as committed to it as he appears to be: I would not be averse to making purely instrumental use of an artificial intervention variable, if that could be shown to facilitate analysis. Nevertheless, I always favour a minimalist approach, so was happy to learn from him that, when applying (the DT version of) do-calculus, it is never necessary to incorporate intervention variables other than those required to give meaning to the query at hand. Shpitser’s illustrations of this, for the front-door and napkin problems, are very pleasing.
Some time ago, Vanessa Didelez and I developed an argument for the front-door criterion (see [7], Section 5.4.2), as modelled by Figure 1. Like Figure 1(a) of [1], this involves intervention only on
In addition, we have the deterministic relation
All further analysis is by purely algebraic application of properties (1)–(4).
For simplicity, we suppose all variables are discrete. We write
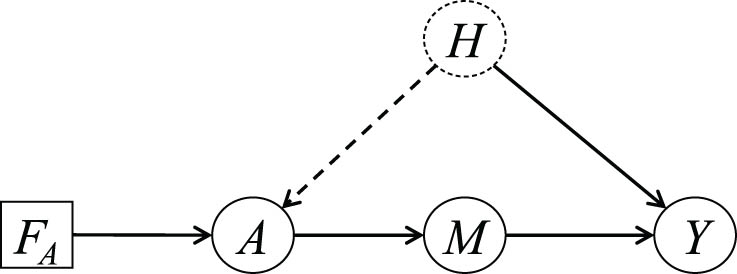
Augmented DAG for the front-door criterion.
Lemma 1
Consider the following function
Then
Proof
We trivially have
Also,
where (8) holds because, by (3),
If we could intervene on
Theorem 1
This is the front-door formula, yielding an expression for
Proof
From (5) and (2),
since
Finally, by Lemma 1 the second sum can be replaced by
The above argument differs from that of Shpitser’s DT argument: it uses
-
Conflict of interest: Prof. Philip Dawid is a member of the Editorial Board in the Journal of Causal Inference but was not involved in the review process of this article.
References
[1] Shpitser I. Comment on: “Decision-theoretic foundations for statistical causality”. J Causal Inference 2022;10:190–6. 10.1515/jci-2021-0056Search in Google Scholar
[2] Dawid AP. Decision-theoretic foundations for statistical causality. J Causal Inference. 2021;9:39–77. 10.1515/jci-2020-0008. Search in Google Scholar
[3] Pearl J, Bareinboim E. Transportability of causal and statistical relations: a formal approach. In: Burgard W, Roth D, editors, Proceedings of the 25th AAAI Conference on Artificial Intelligence. Menlo Park, CA: AAAI Press; 2011. p. 247–54. http://www.aaai.org/ocs/index.php/AAAI/AAAI11/paper/view/3769/386410.1109/ICDMW.2011.169Search in Google Scholar
[4] Bühlmann P. Invariance, causality and robustness (with Discussion). Statistical Sci. 2020;35:404–36. 10.1214/19-STS721Search in Google Scholar
[5] Dawid AP. Counterfactuals, hypotheticals and potential responses: a philosophical examination of statistical causality. In: Russo F, Williamson J, editors. Causality and Probability in the Sciences. Volume 5 of Texts in Philosophy. London: College Publications. 2007. p. 503–32. Search in Google Scholar
[6] Dawid AP. Beware of the DAG!. In: Guyon I, Janzing D, Schölkopf B, editors. Proceedings of the NIPS 2008 Workshop on Causality. Volume 6 of Journal of Machine Learning Research Workshop and Conference Proceedings. Brookline, MA: Microtome Publishing; 2010. p. 59–86. http://tinyurl.com/33va7tm. Search in Google Scholar
[7] Didelez V. Causal concepts and graphical models. In: Maathuis M, Drton M, Lauritzen S, Wainwright M. editors. Handbook of Graphical Models. Chapter 15. 1st edition. Boca Raton, FL; CRC Press; 2018. p. 353–80. 10.1201/9780429463976-15Search in Google Scholar
© 2022 Philip Dawid, published by De Gruyter
This work is licensed under the Creative Commons Attribution 4.0 International License.
Articles in the same Issue
- Editorial
- Causation and decision: On Dawid’s “Decision theoretic foundation of statistical causality”
- Research Articles
- Simple yet sharp sensitivity analysis for unmeasured confounding
- Decomposition of the total effect for two mediators: A natural mediated interaction effect framework
- Causal inference with imperfect instrumental variables
- A unifying causal framework for analyzing dataset shift-stable learning algorithms
- The variance of causal effect estimators for binary v-structures
- Treatment effect optimisation in dynamic environments
- Optimal weighting for estimating generalized average treatment effects
- A note on efficient minimum cost adjustment sets in causal graphical models
- Estimating marginal treatment effects under unobserved group heterogeneity
- Properties of restricted randomization with implications for experimental design
- Clarifying causal mediation analysis: Effect identification via three assumptions and five potential outcomes
- A generalized double robust Bayesian model averaging approach to causal effect estimation with application to the study of osteoporotic fractures
- Sensitivity analysis for causal effects with generalized linear models
- Individualized treatment rules under stochastic treatment cost constraints
- A Lasso approach to covariate selection and average treatment effect estimation for clustered RCTs using design-based methods
- Bias attenuation results for dichotomization of a continuous confounder
- Review Article
- Causal inference in AI education: A primer
- Commentary
- Comment on: “Decision-theoretic foundations for statistical causality”
- Decision-theoretic foundations for statistical causality: Response to Shpitser
- Decision-theoretic foundations for statistical causality: Response to Pearl
- Special Issue on Integration of observational studies with randomized trials
- Identifying HIV sequences that escape antibody neutralization using random forests and collaborative targeted learning
- Estimating complier average causal effects for clustered RCTs when the treatment affects the service population
- Causal effect on a target population: A sensitivity analysis to handle missing covariates
- Doubly robust estimators for generalizing treatment effects on survival outcomes from randomized controlled trials to a target population
Articles in the same Issue
- Editorial
- Causation and decision: On Dawid’s “Decision theoretic foundation of statistical causality”
- Research Articles
- Simple yet sharp sensitivity analysis for unmeasured confounding
- Decomposition of the total effect for two mediators: A natural mediated interaction effect framework
- Causal inference with imperfect instrumental variables
- A unifying causal framework for analyzing dataset shift-stable learning algorithms
- The variance of causal effect estimators for binary v-structures
- Treatment effect optimisation in dynamic environments
- Optimal weighting for estimating generalized average treatment effects
- A note on efficient minimum cost adjustment sets in causal graphical models
- Estimating marginal treatment effects under unobserved group heterogeneity
- Properties of restricted randomization with implications for experimental design
- Clarifying causal mediation analysis: Effect identification via three assumptions and five potential outcomes
- A generalized double robust Bayesian model averaging approach to causal effect estimation with application to the study of osteoporotic fractures
- Sensitivity analysis for causal effects with generalized linear models
- Individualized treatment rules under stochastic treatment cost constraints
- A Lasso approach to covariate selection and average treatment effect estimation for clustered RCTs using design-based methods
- Bias attenuation results for dichotomization of a continuous confounder
- Review Article
- Causal inference in AI education: A primer
- Commentary
- Comment on: “Decision-theoretic foundations for statistical causality”
- Decision-theoretic foundations for statistical causality: Response to Shpitser
- Decision-theoretic foundations for statistical causality: Response to Pearl
- Special Issue on Integration of observational studies with randomized trials
- Identifying HIV sequences that escape antibody neutralization using random forests and collaborative targeted learning
- Estimating complier average causal effects for clustered RCTs when the treatment affects the service population
- Causal effect on a target population: A sensitivity analysis to handle missing covariates
- Doubly robust estimators for generalizing treatment effects on survival outcomes from randomized controlled trials to a target population