Comment on: “Decision-theoretic foundations for statistical causality”
-
Ilya Shpitser


Professor Dawid has been a tireless advocate for the decision-theoretic approach to causal inference, hereafter called “the DT approach,” for over two decades [1,2,3]. The DT approach is formulated using graphs, interventions, and decision nodes (or regime indicators), but importantly not using potential outcomes as other popular approaches [4,5, 6,7]. In fact, the DT approach eschews any mention of counterfactual quantities. In addition, the DT approach views causal inference as about (perhaps exclusively) assisting decision making.
Finally, the DT approach is a partially causal approach: only interventions on subsets of variables in the problem are considered. What properties are essential for a variable to have in order to allow interventions would presumably vary from one researcher to another, but one common standard is that a randomized controlled trial (RCT) with the variable as exposure may be conceptualized, even if in principle. The DT approach thus stands in contrast to the framework for causal inference advocated by Pearl, where interventional semantics are sometimes given via replacement of structural equations, with much work in this framework (including that of the author of this comment) explicitly or implicitly assuming all interventions are allowed. The approach based on Single-World Intervention Graphs (SWIGs) [8] defines causal models on potential outcomes using graphs and allows either all variables to be intervenable (Chapter 3) or interventions only on a restricted set to be defined (Chapter 8 and Appendix C). Restricted intervention models in Chapter 8 and Appendix C are a reformulation of models discussed in ref. [5] as explicitly graphical models. Much applied and methodological causal inference work, primarily in the statistics and public health literature, is consistent with the restricted intervention models as in ref. [5] (in the sense that no counterfactuals other than those encoding responses to interventions on specific treatment variables are ever referred to or defined). The DT framework similarly only considers responses to interventions only on specific variables, while dispensing with counterfactual quantities entirely.
The merits and drawbacks of formulating causal inference using counterfactual quantities are a subject of an extensive and lively debate in the literature. Rather than contributing to that debate, this comment will discuss a number of questions that arise exclusively in the DT framework due to its unique combination of philosophical commitments and mathematical features, compared to other causal inference frameworks. To summarize:
Causal inference in the DT framework is exclusively about assisting decision making.
In general, only interventions on a subset of all observed variables need to be considered, in the DT framework.
Observational and interventional distributions that arise in the DT framework are conditional in the sense of exhibiting dependence on regime indicators, which are not random variables, and finally
These distributions exhibit determinism and context-specific independence.
1 Causal inference versus assisted decision-making
Equating causal inference in the DT framework with assisted decision making seems to be mismatched with the rationale for much applied causal inference work. Indeed, causal inference methods allow the use of observational data to mimic an RCT. Many randomized and observational studies are performed primarily to establish a scientifically interesting relationship between variables, rather than to assist with a particular decision. In practice, such studies provide support for actual decisions either not at all, or only indirectly, and perhaps only in the context of a large collection of similar studies which together form sufficiently strong evidence to merit change in government policy, or modification of clinical practice.
That this is the role causal inference plays in practice is explicitly acknowledged by many empirical disciplines, which establish hierarchies of evidence, with meta analyses of randomized trials forming the most convincing type of evidence for a causal claim. It is thus not clear what role an explicitly decision-focused type of causal inference would play in the ecosystem in which empirical science is done today.
2 Why is the DT approach based on directed acyclic graphs (DAGs)?
Like other frameworks for causal inference, specifically Pearl’s approach [7], and the approach based on SWIGs [6], the DT framework is based on DAGs. In the case of Pearl’s approach, the use of DAGs follows naturally from non-parametric structural equation semantics, where the output variable of each structural equation may be viewed as a child of all input variables in the graph.
Similarly, an SWIG causal model in which all variables can be intervened on assumes (1) a total ordering among variables, and (2) a set of one-step-ahead counterfactuals, from which all other counterfactuals making up the causal model are defined. These assumptions immediately lead to a DAG representation of a causal model in ref. [5] called the finest causally interpretable structured tree graph (FCISTG) as detailed as the data (that assumes all variables can be intervened on) [9]. Note that general structured tree graph models are defined given a subset of variables in the problem on which interventions may be conceptualized. Given such a subset, an FCISTG model is only considered finest and as detailed as the data if restrictions defining it involve interventions on all variables that permit interventions, and not otherwise [5].
Unlike these formalisms, however, the only part of the DT approach that seems to entail a DAG structure is the relationship between the regime indicator
While DAGs allow an analytically convenient Markov property via the d-separation criterion, analytical convenience does not seem to me to be a good standard for choosing a representation of a causal model. However, if it is true that the DT framework may be formulated for other types of graphical models (or even without graphs), this may be a strength rather than a weakness of the formalism. Indeed, more general types of graphs have been used to represent various complications that DAGs are ill suited for capturing [10,11, 12,13]. Incorporating these graphs into existing causal frameworks is often challenging. For example, defining a causal chain graph model[2] entailed a generalization of structural equation replacement semantics for DAGs to models allowing samplers that reach equilibrium [10]. In contrast, such extensions may be much easier in the DT framework, as it seems to be largely graph structure agnostic. Indeed, Professor Dawid discussed extensions of the DT framework to chain graphs in one particular special case in ref. [14].
3 General identification theory
The DT framework has, like the CISTG approach in ref. [5], the (in my opinion desirable) property of being only partially causal. To illustrate why this property can create difficulties for the fundamental problem of causal effect identification, I will consider identification of an interventional distribution in the DT framework version of the front-door model [7,15], as shown in Figure 1(a). Unlike the derivation in ref. [16], the derivation below makes no mention of the hidden variable
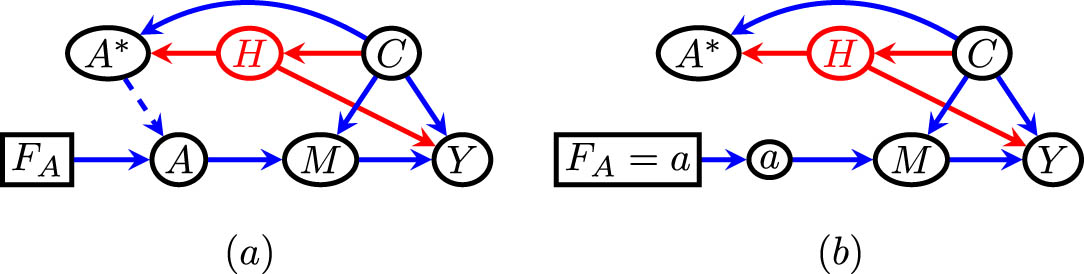
(a) The front-door model graph represented in the decision-theoretic framework. The dashed edge represents a context-specific relation between the intention to treat version of the treatment (
A number of interesting observations follow from this derivation.
While the intention to treat variable
A context-specific independence is used on line 6. Specifically, it is only the case that the intention to treat variable
Note also that a seemingly reasonable replacement of the term
Another curious manifestation of this phenomenon is that under the given model
The functional on the last line contains only observed quantities, and therefore serves as the identifying functional for
Professor Dawid points out that intention to treat variables behave as covariates. In the identifying functional
Despite the previous point, and in keeping with the DT framework being partly causal, the above derivation did not assume the mediator
where intervention on
In the front-door model example, the usual identifying functional can be obtained without requiring that interventions on the mediator variable
As an illustration, consider the model, called the new napkin problem by Pearl [18], which is shown in Figure 2(a). In the model where all interventions are allowed, identification of

(a) A graphical counterfactual representation of the new napkin model. Interventions on all variables are allowed. (b) The SWIG representing the counterfactual distribution
We next note that the marginal distribution
the steps where we concluded that
In fact, the same derivation may be performed without relying on the existence of a well-defined intervention on
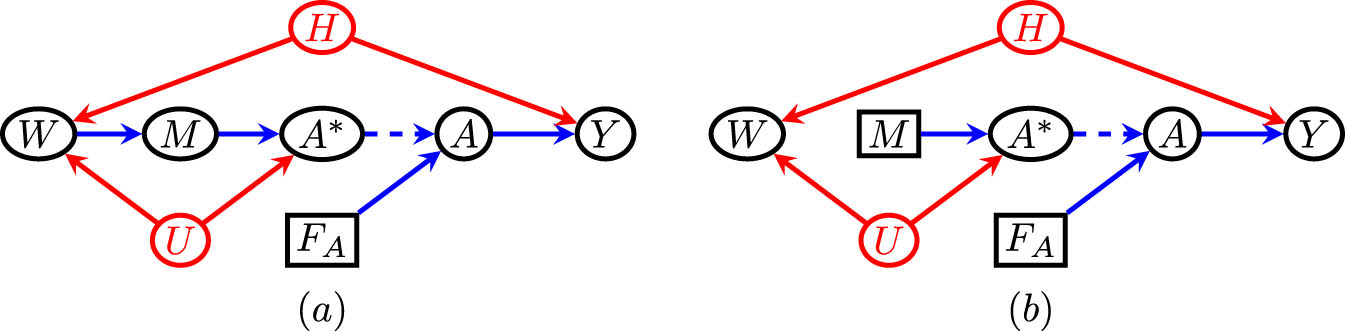
(a) The DT framework version of the napkin model. Only interventions on
Since
The reason for the equality
Derivations of the above sort, which reason about distributions where only some variables may be intervened on, correspond more closely to how subject matter experts think about variables and their causal relationships in practice. However, obtaining such derivations in general problems seems to not be entirely obvious if interventions are restricted.
4 Conclusion
I want to thank Professor Dawid for writing such a stimulating paper. Professor Dawid views the DT framework as a harmonious influence in the “babel” of different voices advocating for different causal inference frameworks. My take is slightly different: I think the DT framework is a lovely corner in a garden where a thousand flowers bloom.
Acknowledgements
The author is grateful to Thomas S. Richardson and James M. Robins for helpful discussions. The author was supported in part by grants ONR N00014-21-1-2820, NSF CAREER 1942239, NSF 2040804, and NIH R01 AI127271-01A1.
-
Conflict of interest: Prof. Ilya Shpitser is a member of the Editorial Board in the Journal of Causal Inference but was not involved in the review process of this article.
References
[1] Dawid AP. Influence diagrams for causal modelling and inference. Int Statist Rev. 2002;70:161–89. 10.1111/j.1751-5823.2002.tb00354.xSearch in Google Scholar
[2] Dawid AP. Counterfactuals, hypotheticals and potential responses: a philosophical examination of statistical causality. In: Russo F, Williamson J, editors. Causality and probability in the sciences, texts in philosophy. Vol. 5. London: College Publications; 2007. p. 503–32. Search in Google Scholar
[3] Dawid AP. Statistical causality from a decision-theoretic perspective. Annual Rev Statist Appl. 2015;2:273–303. 10.1146/annurev-statistics-010814-020105Search in Google Scholar
[4] Rubin DB. Causal inference and missing data (with discussion). Biometrika. 1976;63:581–92. 10.1093/biomet/63.3.581Search in Google Scholar
[5] Robins JM. A new approach to causal inference in mortality studies with sustained exposure periods – application to control of the healthy worker survivor effect. Math Model. 1986;7:1393–512. 10.1016/0270-0255(86)90088-6Search in Google Scholar
[6] Richardson TS, Robins JM. Single world intervention graphs (SWIGs): A unification of the counterfactual and graphical approaches to causality. 2013. Preprint: http://wwwcssswashingtonedu/Papers/wp128pdf. Search in Google Scholar
[7] Pearl J. Reasoning, and inference. 2nd ed. Cambridge, UK: Cambridge University Press; 2009. Search in Google Scholar
[8] Richardson TS, Evans RJ, Robins JM, Shpitser I. Nested Markov properties for acyclic directed mixed graphs. 2017. Working paper. Search in Google Scholar
[9] Shpitser I, Richardson TS, Robins JM. Multivariate counterfactual systems and causal graphical models. 2020. https://arxiv.org/abs/2008.06017. Search in Google Scholar
[10] Lauritzen SL, Richardson TS. Chain graph models and their causal interpretations (with discussion). J R Statist Soc B. 2002;64:321–61. 10.1111/1467-9868.00340Search in Google Scholar
[11] Sherman E, Shpitser I. Identification and estimation of causal effects from dependent data. In: Advances in neural information processing systems. Vol. 31. NY, United States: Curran Associates Inc.; 2018. Search in Google Scholar
[12] Sherman E, Shpitser I. General identification of dynamic treatment regimes under interference. In: Proceedings of the 21st International Conference on Artificial Intelligence and Statistics (AISTATS 2020). 2020. Search in Google Scholar
[13] Tchetgen Tchetgen EJ, Fulcher I, Shpitser I. Auto-G-computation of causal effects on a network. J Am Statist Assoc. 2020;116(534):833–44.10.1080/01621459.2020.1811098Search in Google Scholar PubMed PubMed Central
[14] Dawid AP. Beware of the DAG! In: Proceedings of Workshop on Causality: Objectives and Assessment at NIPS. vol. 6. 2010. p. 59–86. Search in Google Scholar
[15] Fulcher IR, Shpitser I, Marealle S, Tchetgen Tchetgen EJ. Robust inference on population indirect causal effects: the generalized front-door criterion. J R Statist Soc. B. 2019;82(1):199–214. 10.1111/rssb.12345Search in Google Scholar PubMed PubMed Central
[16] Didelez V. Causal concepts and graphical models. In: Handbook of Graphical Models. Boca Raton, FL: CRC Press; 2017. 10.1201/9780429463976-15Search in Google Scholar
[17] Malinsky D, Shpitser I, Richardson TS. A potential outcomes calculus for identifying conditional path-specific effects. In: Proceedings of the 22nd International Conference on Artificial Intelligence and Statistics. 2019. Search in Google Scholar
[18] Pearl J, MacKenzie D. The book of why: the new science of cause and effect. New York: Basic Books; 2018. Search in Google Scholar
[19] Verma TS, Pearl J. Equivalence and synthesis of causal models. Department of Computer Science. Los Angeles: University of California; 1990. p. R–150. Search in Google Scholar
[20] Forre P, Mooij JM. Causal calculus in the presence of cycles, latent confounders and selection bias. In: Proceedings of The 35th Uncertainty in Artificial Intelligence Conference. 2020. Search in Google Scholar
© 2022 Ilya Shpitser, published by De Gruyter
This work is licensed under the Creative Commons Attribution 4.0 International License.
Articles in the same Issue
- Editorial
- Causation and decision: On Dawid’s “Decision theoretic foundation of statistical causality”
- Research Articles
- Simple yet sharp sensitivity analysis for unmeasured confounding
- Decomposition of the total effect for two mediators: A natural mediated interaction effect framework
- Causal inference with imperfect instrumental variables
- A unifying causal framework for analyzing dataset shift-stable learning algorithms
- The variance of causal effect estimators for binary v-structures
- Treatment effect optimisation in dynamic environments
- Optimal weighting for estimating generalized average treatment effects
- A note on efficient minimum cost adjustment sets in causal graphical models
- Estimating marginal treatment effects under unobserved group heterogeneity
- Properties of restricted randomization with implications for experimental design
- Clarifying causal mediation analysis: Effect identification via three assumptions and five potential outcomes
- A generalized double robust Bayesian model averaging approach to causal effect estimation with application to the study of osteoporotic fractures
- Sensitivity analysis for causal effects with generalized linear models
- Individualized treatment rules under stochastic treatment cost constraints
- A Lasso approach to covariate selection and average treatment effect estimation for clustered RCTs using design-based methods
- Bias attenuation results for dichotomization of a continuous confounder
- Review Article
- Causal inference in AI education: A primer
- Commentary
- Comment on: “Decision-theoretic foundations for statistical causality”
- Decision-theoretic foundations for statistical causality: Response to Shpitser
- Decision-theoretic foundations for statistical causality: Response to Pearl
- Special Issue on Integration of observational studies with randomized trials
- Identifying HIV sequences that escape antibody neutralization using random forests and collaborative targeted learning
- Estimating complier average causal effects for clustered RCTs when the treatment affects the service population
- Causal effect on a target population: A sensitivity analysis to handle missing covariates
- Doubly robust estimators for generalizing treatment effects on survival outcomes from randomized controlled trials to a target population
Articles in the same Issue
- Editorial
- Causation and decision: On Dawid’s “Decision theoretic foundation of statistical causality”
- Research Articles
- Simple yet sharp sensitivity analysis for unmeasured confounding
- Decomposition of the total effect for two mediators: A natural mediated interaction effect framework
- Causal inference with imperfect instrumental variables
- A unifying causal framework for analyzing dataset shift-stable learning algorithms
- The variance of causal effect estimators for binary v-structures
- Treatment effect optimisation in dynamic environments
- Optimal weighting for estimating generalized average treatment effects
- A note on efficient minimum cost adjustment sets in causal graphical models
- Estimating marginal treatment effects under unobserved group heterogeneity
- Properties of restricted randomization with implications for experimental design
- Clarifying causal mediation analysis: Effect identification via three assumptions and five potential outcomes
- A generalized double robust Bayesian model averaging approach to causal effect estimation with application to the study of osteoporotic fractures
- Sensitivity analysis for causal effects with generalized linear models
- Individualized treatment rules under stochastic treatment cost constraints
- A Lasso approach to covariate selection and average treatment effect estimation for clustered RCTs using design-based methods
- Bias attenuation results for dichotomization of a continuous confounder
- Review Article
- Causal inference in AI education: A primer
- Commentary
- Comment on: “Decision-theoretic foundations for statistical causality”
- Decision-theoretic foundations for statistical causality: Response to Shpitser
- Decision-theoretic foundations for statistical causality: Response to Pearl
- Special Issue on Integration of observational studies with randomized trials
- Identifying HIV sequences that escape antibody neutralization using random forests and collaborative targeted learning
- Estimating complier average causal effects for clustered RCTs when the treatment affects the service population
- Causal effect on a target population: A sensitivity analysis to handle missing covariates
- Doubly robust estimators for generalizing treatment effects on survival outcomes from randomized controlled trials to a target population