A recursive encoding for cuneiform signs
-
Daniel M. Stelzer
Daniel Stelzer is a doctoral student at the University of Illinois at Urbana-Champaign, specializing in computational analysis of ancient languages. They received their MA and BA in Linguistics and a BS in Computer Science with a minor in Classics from the same institution. Their current focus is digitization of Hittite cuneiform.


Abstract
One of the most significant problems in cuneiform studies is the process of identifying unknown signs, which often involves a tedious page-by-page search through a sign list. This paper proposes a new “recursive encoding” for signs, which represents the arrangement of strokes in a way that computers can process. A series of new algorithms then offers scholars a new way to look up signs by any distinctive component, as well as providing new ways to render signs and tablets electronically.
ACM CCS
Applied computing → Document management and text processing → Document preparation → Format and notation.
1 Introduction
Cuneiform is famous – or infamous – for several reasons. It is the oldest deciphered script in the world, the script used to document the oldest known epic poems and the oldest readable accounting records. And it is infamously difficult both to learn and to read. Huehnergard [1], p. xxiv] calls it “very cumbersome” and “unquestionably the most difficult aspect of learning Akkadian”, relegating it to the later parts of his textbook. Cooper [2], p. 55] claims that “[n]either efficiency nor convenience played an important role in the development of Akkadian cuneiform”, and according to Worthington [3], p. 289], its orthographic features “suggest that ancient sight-readers of cuneiform were expected to decipher a line a bit at a time – not to sweep their eyes across it as we do with our script”.
But this difficulty isn’t just a property of the system itself. As Watkins and Snyder [4], p. 2] put it, “the pedagogical tools are, in many cases, non-optimal”. Looking up unfamiliar words in a dictionary, physical or electronic, is standard practice when learning a new language. But cuneiform in particular involves at minimum hundreds of phonetic signs, and hundreds of logograms on top of those. Even after memorizing the basics, modern students will inevitably encounter signs they’ve never seen before – and on the level of individual signs, there’s no alphabetical order or computerized search to help find them. While a learner of English has a standardized ordering to help their search (if they’re looking for reverent, it will be after revenge and before revile), a student of Akkadian or Sumerian has no such aid.[1]
The traditional solution for this problem is a sign list, such as Borger’s [5] Mesopotamisches Zeichenlexikon or Labat’s [6] Manuel d’épigraphie akkadienne. These typically order the signs based on their strokes, counted from left to right, in the clean, unambiguous Neo-Assyrian form. But most cuneiform is not Neo-Assyrian, and damaged tablets are the rule rather than the exception. Tablets tend to be found in a minimum of ten distinct pieces [7], p. 8], and signs with damage to the left side are common. In these cases, Robson [8] recommends checking other sign indices, and offers a few alternatives if those also fail:
You can make an educated guess at the value the sign ought to have, based on the signs immediately around it, and then look up that value in the relevant index of Borger or Labat. Then you can compare your sign with the entry in Labat’s table or Borger’s paleographic list. The PSL lists of homophones and compounds can often be useful aids in this type of search.
Or you can simply page through Labat’s table, looking for the closest match to your sign in the relevant script. I have done this countless times. It doesn’t seem very clever or efficient, but sometimes it is the only way to find what you are looking for.
The aim of this project is to find a better way. While learning cuneiform has always been a difficult and time-consuming task, we now have technologies the ancient Babylonians never dreamed of. Can we find a better way of looking up an unknown, potentially-damaged sign than scanning through Labat one page at a time?
Section 2 reviews previous work in this area, both with cuneiform and other logographic writing systems. Section 3 draws on this to propose a new encoding system for cuneiform, based on earlier work with Xixia. Section 4 then describes several algorithms using this new system, and the uses to which they can be put.
2 Previous work
2.1 Sign lists
Unfamiliar logograms[2] in cuneiform are not a new problem – one ancient letter describes a perplexed Kassite administrator receiving shipments of straw (the very common logogram  in) when he’d ordered clay pots (the similar and much rarer
in) when he’d ordered clay pots (the similar and much rarer  kan.ni) [9], pp. viii, 142]. Ancient lexical lists giving names and meanings for cuneiform logograms are archaeologically common [2], as is evidence of students using them. Babylonian scribes referenced, copied out, and eventually memorized many of these sign lists to prepare for their job – as we can learn from their own complaints![3]
kan.ni) [9], pp. viii, 142]. Ancient lexical lists giving names and meanings for cuneiform logograms are archaeologically common [2], as is evidence of students using them. Babylonian scribes referenced, copied out, and eventually memorized many of these sign lists to prepare for their job – as we can learn from their own complaints![3]
If you have learned the scribal art, you have recited all of it, the different lines [of the dictionary], chosen from the scribal art; the [names of] animals living in the steppe to the [names of] artisans, you have written; after that, you hate writing!
However, it’s unclear whether scribes would actually memorize every logogram, and texts describe scribes both reciting them and referencing physical tablets (from the same text as above: “all the vocabulary of the scribes in the eduba is in your hands”). Sjöberg [10], p. 164] points out that, while scribes would brag about their memorization skills, the surviving lexical lists are often extremely long, and would be infeasible to memorize by rote. The aforementioned list of “names of artisans”, l
Ú = ša, consists of about a thousand lines [11], while the “animals living in the steppe” comes from ur
5
-ra =  , with around 3,000 [12]. Worthington [3], p. 289] goes further and suggests that reading fluently through a text simply did not happen in ancient Mesopotamia, with scribes frequently needing to pause to figure out an unclear or ambiguous sign.
, with around 3,000 [12]. Worthington [3], p. 289] goes further and suggests that reading fluently through a text simply did not happen in ancient Mesopotamia, with scribes frequently needing to pause to figure out an unclear or ambiguous sign.
In modern times, several authors have revived the ancient tradition of cuneiform sign lists, such as Deimel and Gössman [13] for Sumerian, Rüster and Neu [14] for Hittite, or Borger [5] and Labat [6] for Akkadian. These are generally extensive lists of signs with names and information on each one. While there’s no universal order for cuneiform signs that could aid in searching, an informal standard has arisen: sorting starts at the left side of the sign, with  preceding
preceding  preceding
preceding  preceding
preceding  preceding
preceding  [5], p. 1, 27, p. 26, 23, p. 183]. Borger set precedent basing his sorting on the Neo-Assyrian style, where the ordering of strokes tends to be fairly clear. But in his own words [15], p. 2]:
[5], p. 1, 27, p. 26, 23, p. 183]. Borger set precedent basing his sorting on the Neo-Assyrian style, where the ordering of strokes tends to be fairly clear. But in his own words [15], p. 2]:
Regrettably, it is practically impossible to arrange other versions of cuneiform writing (including the Ur III signs) by the shape of their signs in a consistent and unequivocal way.
Indeed, while Labat’s [6] general Akkadian index and Rüster and Neu’s [14] Hittite sign list try to follow the same pattern,[4] it’s an imprecise measure at best. The ancients don’t seem to have had any better system – the ordering of signs in standard lexical lists comes off as arbitrary at best, and may have generally come down to the whim of the compiler[5] [2], p. 48]. Similar-looking and similar-sounding signs were generally grouped together, but without a broader sorting order as found in modern dictionaries[6] [18].
More recently, electronic references such as Šašková [19] and ePSD [20] have arisen to make it easier to find information on particular signs. These are significantly more convenient than physical sign lists when looking up signs by name or reading, since they can take advantage of electronic searching. But they’re no help when looking at an autograph or an actual tablet: the student needs to already know at least one reading to use these tools.
2.2 Cuneiform encodings
While sign lists and dictionaries remain the most popular cuneiform references, the present author is far from the first to notice the problem. According to Gottstein [16], these sign lists “are very helpful for translation work, but are in most cases extremely impractical to handle”[7] – in particular, “because of how comparatively time-consuming it is to find particular signs, especially in academic introductory classes”.[8] In his words:
A precise system for classifying and, more importantly, looking up particular cuneiform signs within the framework of a analytical sign dictionary has long been among the desiderata of Ancient Near Eastern research, but so far has been neither realized nor tackled in any consistent way.[9]
A chemist by profession, Gottstein was inspired by molecular formulae. There’s no obvious way to impose an alphabetical order on three-dimensional chemical structures, either, but reference works on chemistry have found a solution: molecules are indexed by the number of each type of atom they contain. A conventional order for the atoms ensures that these formulae can be sorted in a coherent way: the entry on nitrobenzene would be listed under C6H5NO2, after quinone (C6H4O2) but before benzene (C6H6).[10]
A molecular formula isn’t necessarily unique – C6H5NO2 can also describe nicotinic acid, or a handful of other chemicals. But there are generally few enough chemicals with a particular formula that a student can scan through them easily to find the one they need. This is the sort of system Gottstein hoped to extend to cuneiform.
![Figure 1:
A demonstration of the “Gottstein system”, adapted from Gottstein [16], p. 129] and Homburg [21], p. ii131].](/document/doi/10.1515/itit-2024-0067/asset/graphic/j_itit-2024-0067_fig_001.jpg)
Cuneiform across all times, places, and languages is generally analyzed as having five basic types of wedges: vertical, horizontal, downward diagonal, upward diagonal, and the “Winkelhaken” or “hook” [22], p. 9, 2, p. 1]. These became the “elements” of Gottstein’s encoding, with the first four labelled ‘a’, ‘b’, ‘c’, and ‘d’ respectively (Figure 1).[11] After some early experiments, he grouped Winkelhaken into the ‘c’ category as well – these identifiers weren’t meant to be entirely unique, and the distinction between downward diagonals and Winkelhaken is not always obvious on an actual tablet. Still, some users of this system have extended it with a ‘w’ category to capture that difference.[12]
Every sign can then be categorized in three ways: by the total number of strokes it contains (“category”), which types of strokes it contains (“designation”), and the number of each type of stroke (“Gottstein code”). The sign eme ‘tongue’ in Figure 2 contains nine strokes total, of the ‘a’, ‘b’, and ‘c’ species, giving it category 9, designation ABC, and Gottstein code a3b5c1.
![Figure 2:
Gottstein’s analysis of the sign eme ‘tongue’, adapted from Gottstein [16], p. 129] and Homburg [21], p. ii131].](/document/doi/10.1515/itit-2024-0067/asset/graphic/j_itit-2024-0067_fig_002.jpg)
Gottstein proposed a sign list that would be organized first by category, then by Gottstein code, displaying each sign and variant that could possibly have that code: Figure 3 shows the section for category 3, code a3.
![Figure 3:
An excerpt from Gottstein’s [16], p. 133] sign list, showing the signs with the Gottstein code a3.](/document/doi/10.1515/itit-2024-0067/asset/graphic/j_itit-2024-0067_fig_003.jpg)
An excerpt from Gottstein’s [16], p. 133] sign list, showing the signs with the Gottstein code a3.
In the same paper, Gottstein describes the broad outlines of an experiment, reporting that “every sign listed according to the ‘Gottstein System’ could be found within seconds. Even non-specialists could find the signs they were looking for within a few moments.”[13] While several signs could have the same Gottstein code, this posed little difficulty: “Experience shows that the additional effort only takes a second.”[14] This would seem to be a perfect solution to the problem, and indeed, it forms the basis of various electronic sign recognition systems like CuneiPainter.[15]
However, cuneiform signs differ from chemicals in a few crucial respects. For the most part, adding or removing an atom from a molecule creates a different chemical completely: H2O (water) behaves very differently from H2O2 (hydrogen peroxide). But ancient scribes were less consistent. The sign u 2 ‘plant’ is typically drawn with three vertical strokes, as shown in Figure 4, but Rüster and Neu [14], p. 185] report variations with as few as two and as many as seven.

Three variants of the sign u 2 ‘plant’. The leftmost is standard, but all three are attested in Hittite.
Gottstein’s solution is to list as many variants as possible, with entries for U2 under a2b2, a3b2, and so on. More crucially, though, it’s very common for a sign to be unclear or damaged. This is something Gottstein’s system fundamentally cannot handle – if damage obliterated the only diagonal wedge in a sign, for example, its category, designation, and code would all be wrong.
A different approach was taken by Homburg [21]. In the study of Egyptian hieroglyphs, the Manuel de Codage [23] is a well-established standard for representing the layout of a text; it’s intended to specify where each sign should be placed relative to the signs around it, making it easy to encode complicated arrangements of glyphs. For example, the MdC code in Figure 5 indicates that the game board (‘mn’) is on top of the water (‘n’) and to the right of the reed leaf (‘i’).[16]
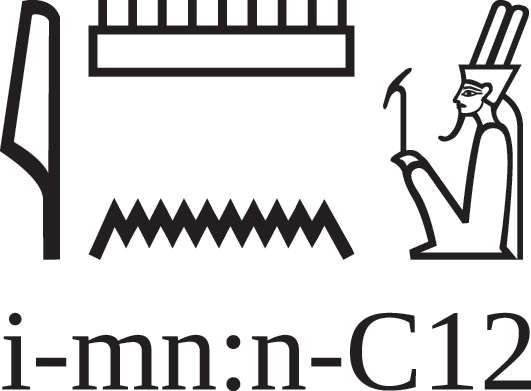
The name of the god Amon, encoded in the MdC system.
Homburg’s [21] system, “PaleoCodage”, aims to encode cuneiform signs in the same way: by specifying the position of each stroke relative to its surroundings. The Manuel defines only three operators,[17] which is sufficient for most hieroglyphic texts. But as the name suggests, PaleoCodage is intended for paleography – for analyzing the fine details of handwriting and ductus that go beyond telling one sign from another. For this purpose, knowing that one stroke is to the right of another isn’t enough. The exact distance there could be crucially important!
As a result, Homburg [21], pp. ii133–ii135] extends Gottstein’s four stroke types with the Winkelhaken, two types of reversed diagonal wedges, and two types of “seal wedges” used in archaic number signs, all of which can be modified in three different ways. These can be combined via a staggering array of operators, allowing a paleographer to encode the size, angle, and position of each stroke with perfect accuracy. Three different “to the right of” operators encode subtle differences of spacing, or can be combined for further detail – and if this still proves insufficient, a “factor operator” can be used to adjust them by as little as one percent.
When discussing specific variants of signs, as Homburg [21], p. ii138] puts it, “a very fine-granular modeling is often needed to depict the changes distinguishing the new sign variant from the other standard sign form”. PaleoCodage is thus tuned to specify enough detail to distinguish one scribe’s particular handwriting from another. But this abundance of detail poses a difficulty for our purposes. Homburg [21], p. ii140] proposes a way to look up similar characters by comparing their PaleoCodage encodings – but by these string similarity metrics, a small horizontal stroke (sb) is no more similar to a large horizontal (B) than it is to a small vertical (sa).
In order for PaleoCodage to express this level of precision, its operators don’t quite encode relationships (as in the MdC system) between the strokes. Instead, each operator represents a change in state for the parsing automaton [21], p. ii140]. This means that the operators between particular wedges don’t necessarily have anything to do with those wedges themselves – two vertical strokes next to each other might be encoded as a-a or a_a, but the difference has nothing to do with those wedges themselves. Instead, it indicates whether any horizontal strokes crossing those wedges should cross both, or only one! In short, the same features that make PaleoCodage useful for paleography also make it generally unsuitable for a search system.
2.3 Machine learning
In recent years, the problem of cuneiform transcription has attracted more attention from computer scientists, and machine learning algorithms have been applied to a variety of different aspects. Machine learning has been extremely effective at recognizing Han logograms, for example, even with only “off-the-shelf” algorithms [24]. It would seem reasonable to apply these methods to cuneiform in the same way.
Unfortunately, the most effective algorithms for recognizing Han characters (as described by Liu et al. [25] and Liu and Zhou [26], among others) tend to rely on specific details of how those characters are written, such as stroke trajectory. In theory, the concepts behind these algorithms could be adapted to cuneiform wedges. At present, however, the cutting-edge algorithms used in Han lookup tools (such as Pleco) cannot be easily applied to cuneiform. To make them work, some fundamental aspects would need to be redesigned from the ground up.
Unicode attempts to provide a codepoint for each cuneiform sign,[18] and most attempts at cuneiform machine learning, such as Doostmohammadi and Nassajian [27] and Gordin et al. [28], take Unicode-encoded text as their starting point. While remarkable progress has been made in tasks like identifying the language of a text and choosing appropriate readings for each sign, these projects require the signs to have already been transcribed and identified – which can often be the most difficult and time-consuming part. Research in this direction won’t help with the actual lookup and identification of logograms.
Other projects, like Dencker et al. [29], attempt to go all the way from tablet photographs to a full transliteration. These projects have also achieved remarkable successes from relatively little training material. But they often suffer from trying to do too much at once – the system has to learn the entire model at the same time, all the way from recognizing shadows in a photograph to picking out the right reading for a sign. This means that what the system learns about recognizing wedges in Neo-Assyrian cuneiform, for example, can’t be easily generalized to another dialect like Old Akkadian, even though the fundamental principles are the same. This becomes a serious issue when there’s very limited data for a particular dialect.
One remarkable outlier is Kriege et al. [30], which builds on earlier work by Fisseler et al. [31]. Fisseler et al. aimed to solve a smaller problem: converting scans of tablets into readable autographs. They were remarkably successful at this, and Kriege et al. used the output of that model as the input to theirs, looking at relationships between wedges rather than raw images. By applying graph-based neural networks from Fey et al. [32] to this input, they were able to identify signs with remarkable accuracy.
However, their initial experiment used a very limited selection of signs written by modern scholars, with manual annotation for which wedges belonged to which signs. While their results are still extremely promising, and hint that specialized stroke-detection algorithms along the lines of Liu et al. [25] and Liu and Zhou [26] could be developed for cuneiform, it remains to be seen how well they will generalize to actual ancient tablets with hundreds of distinct signs and no clear marking of sign boundaries.[19]
Based on this, it seems that there is currently no effective machine-learning solution to the problem of sign recognition. But note also that one of the most pressing difficulties in applying machine learning to cuneiform seems to be the lack of a good intermediate representation: a concise, useful way of indicating the wedges that make up a sign, which image-recognition models could convert scans and photographs into, and other models could separately convert to readings.[20] This would effectively break the problem in half, like how modern machine learning models generally handle OCR (recognition of the graphemes making up written text) separately from the interpretation of that text. The new encoding system proposed in this paper may prove useful for this purpose as well.
2.4 Other logographies
For many languages, ancient and modern, learning the script is only a minor obstacle. Students of Greek generally have no issue learning its alphabet, for instance, and have no need for transliterations. Why is cuneiform any different?
The difference lies in the sheer number of signs. The Greek alphabet uses only 24 letters, while Rüster and Neu [14] have documented 375 signs for Hittite, plus additional variations. 21 of those variations have distinct forms and meanings, raising the total to 396. For Akkadian, Labat’s [6] index numbers go up to 567, while Borger’s [5] reach 905.
Of the 396 signs used in Hittite, 241 of those are never used phonetically for Hittite words – they’re exclusively used for logograms, punctuation, or foreign words.[21] In some genres and eras,[22] it’s not uncommon for 85 % of the signs in a text to be logograms [2], p. 53], and some scribes seem to have invented new unique logograms for their own particular uses [7], p. 330]. So while students will quickly master the common phonetic signs, even experienced cuneiform scholars are sure to come across logograms they have never memorized, or perhaps even seen before. This is where a lookup system is essential.
Cuneiform, though, is not the only writing system to require hundreds of logograms. Other scholars have run into this same problem when analyzing Han logograms and Egyptian hieroglyphs, among others, and have needed effective lookup methods long before the advent of machine learning.
For Egyptian hieroglyphs, the standard way to look up a sign originates with Gardiner [35].[23] He created a catalogue of hieroglyphs based on the objects they represent, so that, for example, all signs depicting birds can be found under “G”, and all signs depicting ships and parts of ships can be found under “P”. This means that a student should only have to look through a few dozen signs to find the one they need, rather than several hundred (Figure 6).
A handful of Egyptian hieroglyphs classified with Gardiner’s system. Diagram adapted from work by Gérard Ducher, CC-BY-SA, https://commons.wikimedia.org/wiki/File:Hi%C3%A9roglyphes_-_A_-_Hommes.pdf.
But Gardiner’s system depends on students being able to tell easily what a sign depicts, which is sometimes non-trivial (it’s not at all obvious to a modern-day student that a speckled circle represents a threshing floor while a lined circle represents an animal placenta[24]) and sometimes impossible (such as in hieratic writing, a much more stylized variation of hieroglyphic Egyptian). Certain signs could also reasonably fall into multiple categories, increasing the difficulty for the student. Would a sign of a vulture god and a cobra god together be found under G for “birds”, I for “reptiles and amphibians”, or C for “deities”?[25] Cuneiform signs are much less representational than hieroglyphic ones, so this system is infeasible for our purposes.
For the several thousand Han logograms, quite a lot of different lookup systems have been proposed over the years. The most famous and popular are radical-based systems [37]. Most Han logograms contain recognizable smaller parts, known as “radicals”. An index of characters by their most distinctive radical, or in newer electronic dictionaries by all radicals they contain, can then narrow down the search space tremendously (Figure 7) [37]. Some go a step further, annotating the radicals for their exact positions within the sign, though the reliance on absolute positioning becomes a problem when signs may be obscured or damaged.
![Figure 7:
A selection of Han characters and the radicals they contain, taken from Breen [37], p. 5]. The character can be looked up by one or more of these radicals. (From the top: ‘rising sun’, ‘address’, ‘origin’, and ‘poetic meter’.)](/document/doi/10.1515/itit-2024-0067/asset/graphic/j_itit-2024-0067_fig_007.jpg)
A selection of Han characters and the radicals they contain, taken from Breen [37], p. 5]. The character can be looked up by one or more of these radicals. (From the top: ‘rising sun’, ‘address’, ‘origin’, and ‘poetic meter’.)
To some extent, this sort of system has already been used for cuneiform. The naming rules for signs, as discussed in Tinney [38] and Robson [39], can indicate when a sign is composed of recognizable pieces: the logogram nag ‘drink’ (Figure 8) is named KA × A (“ka ‘mouth’ enclosing a ‘water’”), while the logogram ug ‘tiger(?)’ is officially named PIRIĜ&UT (“piri ĝ ‘lion’ on top of ut”).[26] However, most cuneiform signs don’t contain meaningful sub-units larger than single wedges, and signs that were once made of clearly distinct radicals may cease to be so over time: the logogram ME š ‘[plural]’ was once a transparent compound ME + EŠ (“me up against eš”), but became a single indivisible unit MEŠ in later eras.
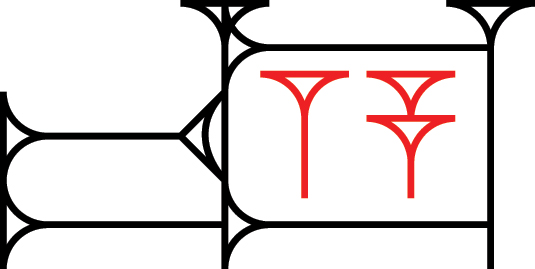
KA (black) enclosing A (red).
A related system indexes characters by how many strokes they contain; the KANJIDIC database that underlies popular tools like Jisho, for example, includes this type of indexing [40]. However, as shown in Figure 4, the number of wedges in a cuneiform sign is much less consistent than the number of strokes in a Han logogram. Scribes would very frequently leave a wedge off, or include an additional one by mistake. This makes stroke-number systems generally unsuitable for cuneiform.
Another popular system for Han logograms is the “four corners method” [41], [42], which involves dividing all visual elements into ten broad categories, then listing which category each corner of the sign (and sometimes additionally the center) falls under. This gives each glyph a four- or five-digit number that can be used as an index, as seen in Figure 9. A system broadly similar to this (using the leftmost edge) is already standard in cuneiform sign lists, as discussed above. It can be somewhat helpful; however, it still often leaves hundreds of glyphs to search through, damage to signs is common, and cuneiform scribes were often less careful than Han writers in keeping their stroke types distinct. When the leftmost stroke is used as the main index, uncertainty about that particular wedge – whether caused by scribal carelessness, damage to the tablet, or simply bad lighting in a photograph – can and does render the system unusable.
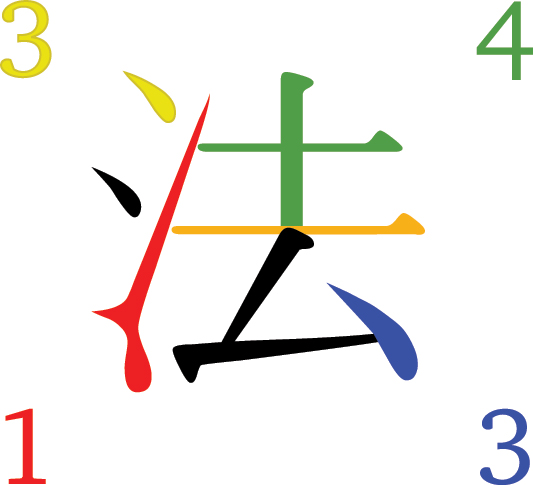
An example of four-corners classification: this sign would be indexed as 3413 in a four-digit system, or 3413-1 in a five-digit system. Diagram by Oona Räisänen, https://commons.wikimedia.org/wiki/File:Four-corner_method.svg.
For Xixia/Tangut, an extinct logography possibly related to Han characters, a different sort of index was proposed by Nishida in 1966.[27] Nishida’s system divides all Xixia characters into 319 radicals, then indexes characters based on their structure – three radicals next to each other are structure A3, for example, while two radicals on top of two other radicals are structure M1 (Figure 10). Unfortunately, as discussed above, the dependence on radicals makes this system generally unsuitable for cuneiform.
![Figure 10:
The structures used in Nishida’s index, from Nishida [43], p. 246], reproduced in Downes [42], p. 13].](/document/doi/10.1515/itit-2024-0067/asset/graphic/j_itit-2024-0067_fig_010.jpg)
A related proposal was incorporated into Unicode in 1999, dubbed the “Ideographic Description System” and meant to apply to Han, Xixia, and other similar writing systems; the intent was to allow fonts to synthesize obscure characters that may not have dedicated codepoints. The IDS is similar to Nishida’s index, enumerating a certain number of possible structures that radicals can fit into. But it goes one step further, allowing these structures to be nested recursively, as shown in Figure 11 [44], pp. 689–692].
![Figure 11:
An example of the IDS, from the Unicode consortium [44], p. 691].](/document/doi/10.1515/itit-2024-0067/asset/graphic/j_itit-2024-0067_fig_011.jpg)
An example of the IDS, from the Unicode consortium [44], p. 691].
While this proposal has potential, the Unicode consortium warns against using it for anything beyond describing unencoded variants, and thus little time and effort has been devoted to it. At the time of writing, no software has been found that actually uses or even supports it. A similar system was proposed for cuneiform by Snyder [45], but was not accepted by the Unicode consortium.[28] Wong, Yiu, and Ng [46] lay out another idea in the same vein, dubbed “HanGlyph”, which uses 41 basic strokes and 12 operations to potentially describe any Han character (even one not composed of recognizable radicals). But this proposal is also mostly theoretical, as no actual implementation seems to be available, or any evaluation of its usability.
Another recursive description system for both Xixia and Han was proposed by Downes [42] and elaborated on in Downes [47]. Like the Unicode IDS, Downes’ system tries to describe the relationships between radicals in a recursive way. This system uses only three relationships, compared to the IDS’s twelve: “stacked horizontally”, “stacked vertically”, and “enclosed by” (Figure 12). These prove sufficient to describe virtually all Han and Xixia characters; the Xixia characters in fact can be described with only two relationships, since they never enclose one radical with another.[29]
![Figure 12:
An example of Downes’s recursive index for Xixia, reproduced from Downes [42], p. 15].](/document/doi/10.1515/itit-2024-0067/asset/graphic/j_itit-2024-0067_fig_012.jpg)
An example of Downes’s recursive index for Xixia, reproduced from Downes [42], p. 15].
This system seems the most promising for our purposes.[30] Rather than Downes’s 176 radicals for Xixia and 420 for Han, we can reduce characters all the way down to their most basic strokes.[31] As mentioned in Section 2.2, cuneiform across all times, places, and languages is generally analyzed as having five types of wedges – far fewer than Wong, Yiu, and Ng’s 41. Empirically, only three types of compositions have proven sufficient to encode 99 % of the signs and variants in Rüster and Neu [14]. Horizontal and vertical stacking are implemented as in Downes [42]; the third form of composition is intersection or superposition, since this system goes down to the level of individual cuneiform wedges, while Downes generally calls any intersecting strokes a new radical.
3 Recursive encoding
This new proposal, inspired by Downes [42], is to represent a cuneiform sign as a tree. The leaves of this tree are the five basic types of wedges, and the branches are the three basic ways of combining them (“compositions”): stacked horizontally, stacked vertically, or intersecting (Figure 13). The result is termed the kadaru encoding, from Akkadian kadārum ‘divide up with boundaries’. Informal experiments suggest that Downes’s [42] bracket notation ({[vv][vv]}) is easier for students to read than Snyder’s [45] infix notation with precedence (v+v&v+v),[32] so this forms the foundation of the syntax: wedges are indicated by lowercase letters,[33] and compositions by various types of brackets.
These operations prove sufficient to describe almost all cuneiform signs used in Hittite. Hittite cuneiform is the particular focus of the initial work here for a few reasons: it has a relatively small sign inventory compared to most periods of Akkadian and Sumerian, and these signs were (in the words of Gordin [7], p. 29]) “written with a keen sense of accuracy and symmetry”, with very reliable spacing and paragraph breaks.[34] At the same time, the Hittite signs defy the straightforward classification of Neo-Assyrian, heightening the need for new indexing tools. And, last but certainly not least, ongoing Hittite classes at the University of Illinois offered a pool of students for testing. However, it’s true that the vast majority of cuneiform in existence is not Hittite; Section 3.4 discusses applications to Old Babylonian, Neo-Assyrian, and other styles.
Examples of recursive encoding in the kadaru system.
3.1 Aesthetics
The basic kadaru system as presented in Table 1 only encodes the five basic types of wedges and their relationships to each other – not any other details of their position or size. This is a notable departure from previous systems like the indexing in Rüster and Neu [14], which considers a long horizontal wedge and a short horizontal wedge to be as thoroughly different as a horizontal and a diagonal.[35] The four patterns shown in Figure 14 are all separate headings in their sign index.
The core of the kadaru encoding.
| Name | Example | Syntax |
|---|---|---|
| Horizontal |

|
h |
| Vertical |
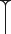
|
v |
| Downward diagonal |
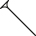
|
d |
| Upward diagonal |

|
u |
| Hook |
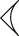
|
c |
| Horizontal stack |

|
[] |
| Vertical stack |

|
{} |
| Intersect |

|
() |

Four consecutive headings from the Zeichenlexikon’s sign index.
However, the main effect of this is to index many signs several times over. The sign pa  , for example, is listed separately under the first, third, and fourth of those headings – simply because scribes seldom seemed to notice or care which stroke was longer!
, for example, is listed separately under the first, third, and fourth of those headings – simply because scribes seldom seemed to notice or care which stroke was longer!
The kadaru encoding is thus designed to ignore the exact size and placement of wedges, focusing only on their relationships to each other. While the parallel wedges in  may vary in length, they are always horizontal, and one is always placed above the other. This is intended to aid scholars in looking up signs, since they can ignore these details and focus only on the general pattern. During testing, multiple students expressed frustration with this particular aspect of traditional sign lists, saying they were unsure which of the headings from Figure 14 they should be looking at.
may vary in length, they are always horizontal, and one is always placed above the other. This is intended to aid scholars in looking up signs, since they can ignore these details and focus only on the general pattern. During testing, multiple students expressed frustration with this particular aspect of traditional sign lists, saying they were unsure which of the headings from Figure 14 they should be looking at.
It should be noted, however, that the lengths of wedges can sometimes carry semantic meaning. The phonograms ku and ma, for example, are distinguished solely by the lengths of the horizontal strokes, as seen in Figure 15. In the basic system, both would be encoded as [{hhh}v]. However, cases like this are rare, and even in these instances the stroke lengths can vary significantly. While this is a demonstrable limitation of the system, the practical impact is minimal: a student searching for one of these signs will find both, and decide based on context which is more appropriate.
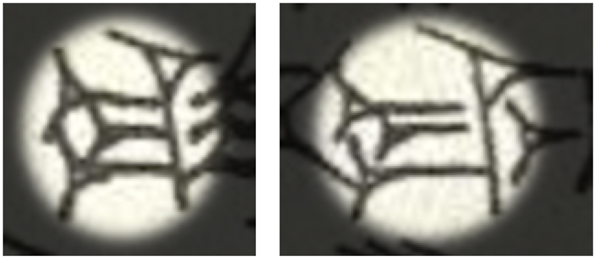
Signs ku (left) and ma (right), from KBo 23.52.
These five basic wedge types and three basic compositions are sufficient for a search system, but finer control of the details is important for other applications. A typesetting system, for example, must be able to distinguish between ku and ma, and also make its middle stroke shorter than the outer ones (as in Figure 15). And even for searching, scholars will – quite rightly – expect the search results to resemble what they see in the clay, rather than a platonic version that ignores spacing and stroke length.
For these reasons, the system includes a set of wedge modifiers and component modifiers, shown in Table 2. These can be used to lay out a sign in finer detail,[36] adjusting the size and positioning of strokes within the recursive structure; the effects can be seen in Figure 16. These are removed during normalization (Section 4.2), ensuring that they’re ignored while searching.
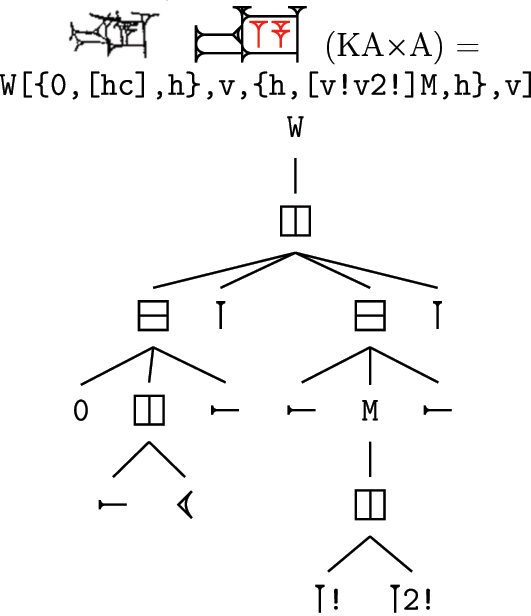
A more complex recursive encoding: the sign KA × A (nag ‘drink’), rendered in color for Figure 8. Component modifiers like M act as their own non-branching nodes in the tree, while wedge modifiers like 2 are parsed as part of a leaf. The commas are ignored by the parser but can be used to clarify the boundaries between sub-units.
Examples of use can be seen in Figures 16 and 17. While these encodings are hardly less complicated than the signs themselves, most people will never need to work with them – when searching, users only need to encode a small fragment of the sign, using only the basic syntax from Table 1. The advanced features are important for rendering, but are not needed for a search.
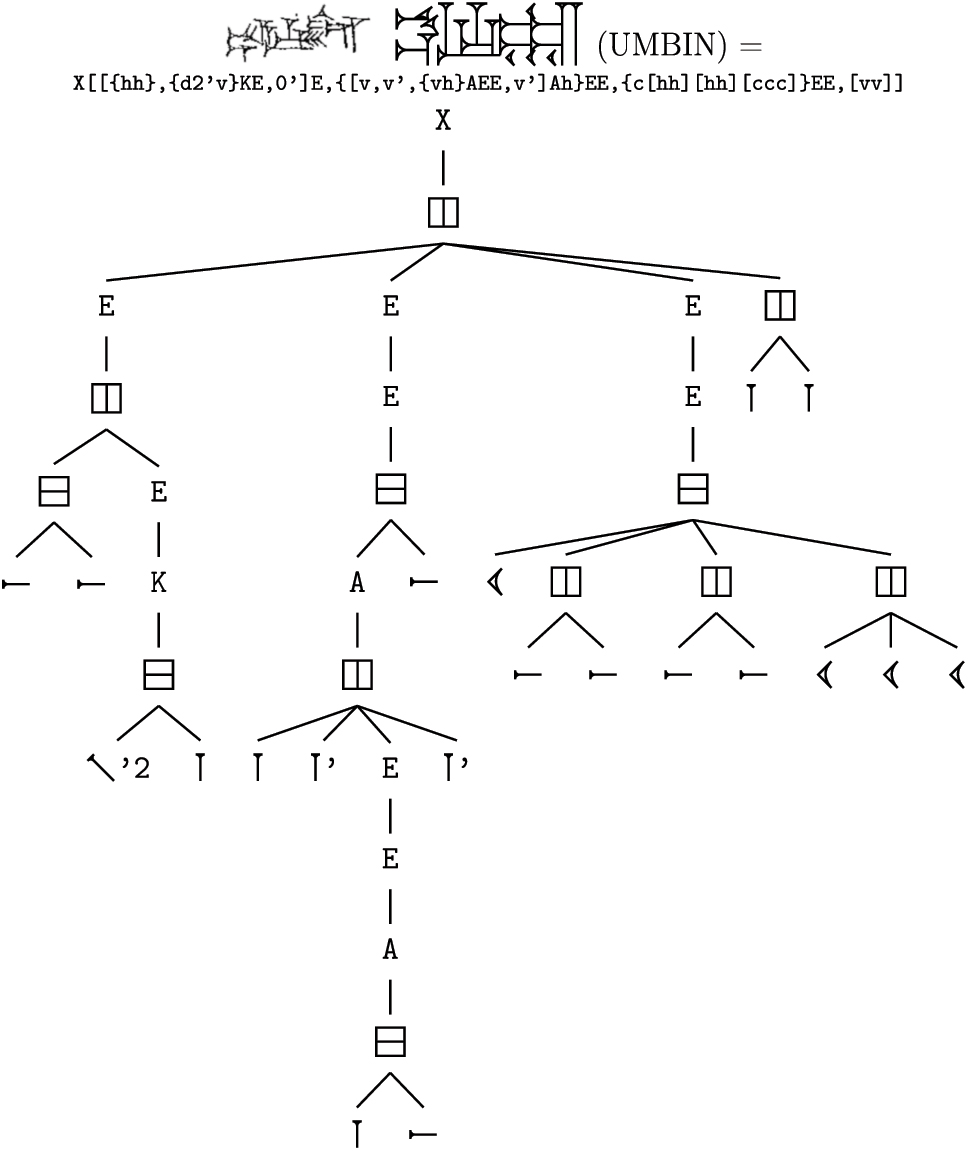
Old Script form of umbin ‘fingernail’, the most complex sign in the Zeichenlexikon by number of wedges. It can be built recursively out of a series of vertical components stacked horizontally, with various modifiers applied for more attractive rendering.
3.2 Semantics
Some of the modifiers in Table 2 require a bit more attention. Many of them are purely aesthetic, and can be simply removed without changing the fundamental nature of the sign. Others require a bit of adjustment when they’re removed: v2 (a double-headed vertical stroke) is more similar to {vv} than v, two verticals rather than one, but the difference between v2 and {vv} is purely an aesthetic one.
Advanced syntax.
| Name | Explanation | Syntax |
|---|---|---|
| Void | A “stroke” that takes up space, either horizontally, vertically, or both, but is not displayed | 0 |
| Wildcard | A “stroke” indicating that something stands in a particular position without committing to what it might be (for example, if a sign is damaged) | * |
| Shortening | Make a stroke shorter, either from the head end or the tail end | ’, ” |
| Doubling | Put a second head on the same stroke | 2 |
| Damage | Hatch over a part of the sign to indicate damage to the tablet | # |
| Expansion | Instruct the renderer to give this component more space | E |
| Margin | Instruct the renderer to leave some empty space around this component | M |
| Restriction | Prevent a component from expanding in any direction | R |
| Allowance | Allow a component to expand in any direction | A |
| Kerning | Allow adjacent components to kern in from every side | K |
| Tenû (or Tilt) | Rotate an entire component 45° | T |
| Canvas size | Change the width of the canvas | (Various) |
The tenû modifier, though, is a fundamental change to the sign: 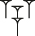 ninda ‘bread’ is a different sign from
ninda ‘bread’ is a different sign from 
 . Why should this be implemented as a modifier? Wouldn’t it be better to have a “diagonal stacking” composition to capture cases like
. Why should this be implemented as a modifier? Wouldn’t it be better to have a “diagonal stacking” composition to capture cases like  , encoded perhaps as ⟨<ddd>d⟩ – akin to PaleoCodage’s . and , operators?
, encoded perhaps as ⟨<ddd>d⟩ – akin to PaleoCodage’s . and , operators?
Notably, though, this “diagonal stacking” has a very restricted distribution. While diagonal strokes are frequently stacked horizontally and vertically (e.g. ni  ), horizontal and vertical strokes are never stacked diagonally. And with only one possible exception,[37] horizontal and vertical stacks never appear inside or overlap with diagonal ones in Hittite.
), horizontal and vertical strokes are never stacked diagonally. And with only one possible exception,[37] horizontal and vertical stacks never appear inside or overlap with diagonal ones in Hittite.
Instead, components (or even entire signs) are written “tenû”: rotated by 45°.[38] It is likely that this was handled by physically rotating either the hand or the tablet, as opposed to horizontal and vertical wedges, made using different edges of the stylus with the same basic hand position. In other words, these “diagonal stacks” are fundamentally a modification of horizontal and vertical stacks, rather than a separate entity of their own.
For these reasons, diagonal stacking is not considered its own separate composition in the system. Rather, it is treated as either a horizontal or vertical stack, containing only horizontal and vertical strokes, with the tenû modifier applied. During normalization, horizontal wedges within a tenû composition are replaced with upward diagonals, while vertical wedges become downward diagonals[39] – meaning that a search for  won’t find
won’t find 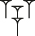 .
.
3.3 Exceptions
The first true test of this system is its completeness. With the modifiers from Table 2, it can make a satisfactory rendering of all but two signs in the Hethitisches Zeichenlexikon. These two exceptions are the logograms ga
š
an ‘Lady’ (a title used in prayers to female deities) and 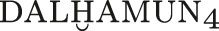 ‘Dalhamun’ (an epithet of the Akkadian storm deity Adad).
‘Dalhamun’ (an epithet of the Akkadian storm deity Adad).
The latter can be quite reasonably ignored. It consists of the sign NAGA written four times in different directions, converging on a center point to make a cross shape. A similar construction (shown in Figure 18) involves four copies of the logogram š ir ‘testicle’ arranged in the same pattern, likely an epithet of the moon-god; this one is a hapax and doesn’t even merit an official name or Unicode codepoint.
![Figure 18:
A Kreuzform sign, “ŠIR × 4”, from Torri [48].](/document/doi/10.1515/itit-2024-0067/asset/graphic/j_itit-2024-0067_fig_018.jpg)
A Kreuzform sign, “ŠIR × 4”, from Torri [48].
These “Kreuzform” signs don’t fit into a standard line of text, and in fact never seem to be used inline on actual tablets in the Hittite era: they appear only in lists of logograms or sketched in colophons [48]. They are not given their own index numbers in Rüster and Neu [14] and are not supported in any common Hittite fonts, so I have no qualms about leaving them unencoded.[40]
The sign GAŠAN poses a larger issue. As presented in the Zeichenlexikon, it involves horizontal strokes meeting a diagonal, as shown at the top of Figure 19. This is something the kadaru system currently can’t handle – the best way to do it would be to put downward diagonals inside a tenû modifier, which is not allowed.

Variants of the sign ga š an ‘Lady’. At the top, how it’s presented in the Zeichenlexikon; in the middle, how it appears in autographs (KBo 8.110, KBo 24.43, KBo 47.133, KUB 27.1, and KBo 39.159); on the bottom, different ways of representing it in the kadaru encoding.
Curiously, though, the sign as found in tablet autographs tends to look quite different. Several examples can be seen in the middle of Figure 19, and none of them quite match the Zeichenlexikon’s form. This makes sense, if diagonal strokes were indeed made by rotating the tablet: having horizontal strokes truly meet a diagonal would require significantly more effort than meeting a vertical.
Historically speaking, this sign started as a gunû (“decorated”) form of the sign u ‘ten’, a single Winkelhaken. This can be represented in the kadaru system by superposing tenû strokes (bottom left). Various other representations are possible too, as shown across the bottom; while none of them are perfect representations of how it’s shown in the autographs, they can approximate it significantly better than they can the Zeichenlexikon form. The question of which source best represents the actual tablets, and what the Platonic ideal of the Hittite GAŠAN should truly look like, is left for future work.
3.4 Other languages
While the kadaru system is well-suited for encoding Hittite, this is only a small fraction of the cuneiform in existence. Even if Hittite is the focus of the initial experiments, it’s well worth asking if this system can be generalized to other languages and eras.
While most Akkadian sign lists give between 500 and 1,000 signs, Huehnergard’s [1] textbook provides a short reference list for its exercises, with only 196 signs. Better yet, these 196 signs are provided in three different styles – Old Babylonian lapidary (for carving into stone), Old Babylonian cursive (for impressing into clay), and Neo-Assyrian, as shown in Figure 20. While far from complete, this can be taken as a more-or-less representative sample of the script.
![Figure 20:
A sign from Huehnergard’s [1] sign list, in three different styles, encoded in the kadaru system.](/document/doi/10.1515/itit-2024-0067/asset/graphic/j_itit-2024-0067_fig_020.jpg)
A sign from Huehnergard’s [1] sign list, in three different styles, encoded in the kadaru system.
The vast majority of the Old Babylonian cursive signs can be encoded in the kadaru system without problems. Several required one adjustment to the system: unlike Hittite, Old Babylonian signs sometimes make use of upward vertical wedges, as in the sign 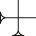 nu. But these are far less common than the five basic types from Table 1 – rare enough that they don’t receive their own headings when categorizing signs, or their own designations in Gottstein’s system or PaleoCodage. Instead, we represent them with a new modifier, ?, which inverts the direction of a wedge.[41]
nu. But these are far less common than the five basic types from Table 1 – rare enough that they don’t receive their own headings when categorizing signs, or their own designations in Gottstein’s system or PaleoCodage. Instead, we represent them with a new modifier, ?, which inverts the direction of a wedge.[41]  can then be represented as (hv?). Additional modifiers like this are the easiest way to extend the system, without modifying the basic strokes and compositions; the triple-headed wedges in Old Assyrian
can then be represented as (hv?). Additional modifiers like this are the easiest way to extend the system, without modifying the basic strokes and compositions; the triple-headed wedges in Old Assyrian 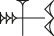 bal ‘libate’ could be handled with a new 3 modifier, and the remaining wedge types found in PaleoCodage but not the kadaru system (“seal wedges” used in archaic accounting, written with a round stylus instead of a rectangular one) might be implemented the same way.[42]
bal ‘libate’ could be handled with a new 3 modifier, and the remaining wedge types found in PaleoCodage but not the kadaru system (“seal wedges” used in archaic accounting, written with a round stylus instead of a rectangular one) might be implemented the same way.[42]
With this modifier added, only two Old Babylonian cursive signs posed an issue: one (sign 152, uk) because the illustration in Huehnergard is too smudged to make out the individual wedges, the other (sign 136, na 2 ‘bed’) because of the same issue as Hittite ga š an, above. A full text in this style is shown in Figure 21. In Neo-Assyrian, many more signs had the “ga š an problem”, suggesting that it really does need a solution. However, the lapidary signs ran into issues left and right, with a worrying proportion of them unable to be rendered properly (Figure 20), or in some cases even encoded at all.
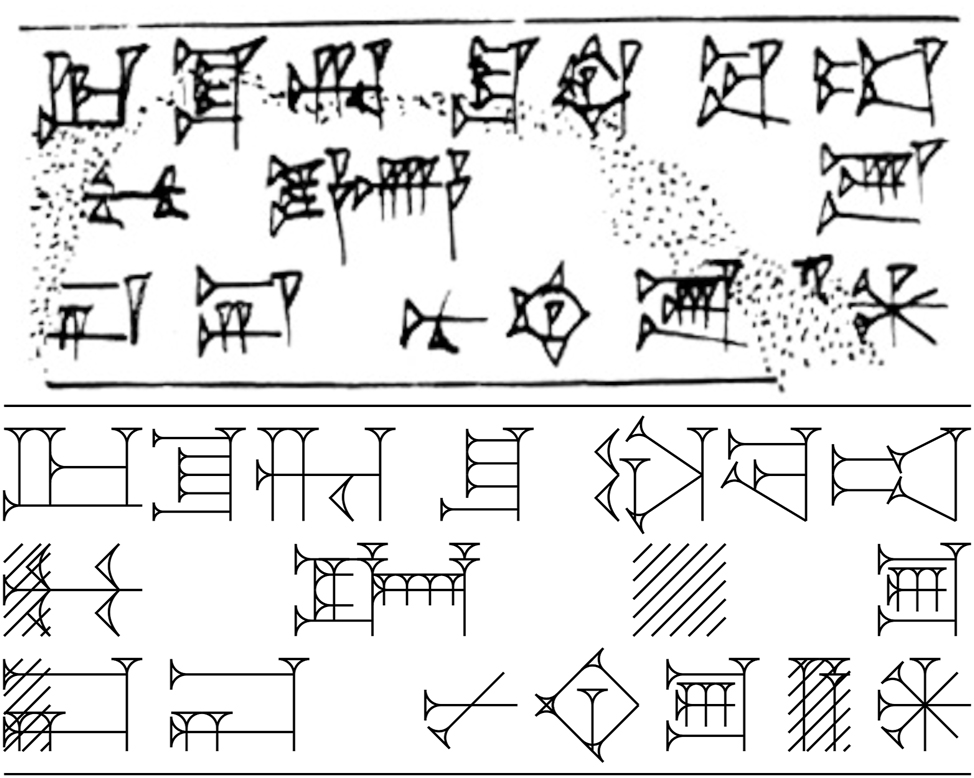
A Sumerian proverb in Old Babylonian cuneiform (CDLI P346305): “The dog knows ‘take it’. It does not know ‘drop it’.” Autograph taken from https://cdli.mpiwg-berlin.mpg.de/artifacts/346305. Most sign forms are taken from the Old Babylonian database in Section 3.4; missing and non-matching ones were encoded specifically for this tablet.
As a further experiment, short texts were encoded and rendered in Ugaritic (Figure 22) and Old Persian – two types of cuneiform historically unrelated to the tradition of Sumerian, Akkadian, and Hittite, but designed to be written in the same way with a reed stylus on clay.[43] These similarly posed no issue. This suggests that the kadaru encoding is well-suited for the medium of a reed stylus on clay in general, rather than any particular features of Hittite cuneiform. The medium itself puts certain limits on the precision of the strokes, preventing the intricate arrangements of lines and hatches found in the Old Babylonian lapidary style.
![Figure 22:
A Ugaritic abecedary tablet (RS 12.063/KTU 5.6). Tablet photo originally from Yon [49], 124, Figure 2a], reproduced at https://mnamon.sns.it/index.php?page=Esempi&id=30&lang=en. The 3 (triple-headed) and ? (inverted) modifiers are required here.](/document/doi/10.1515/itit-2024-0067/asset/graphic/j_itit-2024-0067_fig_022.jpg)
A Ugaritic abecedary tablet (RS 12.063/KTU 5.6). Tablet photo originally from Yon [49], 124, Figure 2a], reproduced at https://mnamon.sns.it/index.php?page=Esempi&id=30&lang=en. The 3 (triple-headed) and ? (inverted) modifiers are required here.
3.5 Comparison
The benefits over the Gottstein system are clear. The kadaru encoding includes the same information about the wedge types, plus additional information about how they relate; a database of kadaru-encoded signs can be trivially converted to Gottstein codes, or allow searching by Gottstein code as an alternative.
The benefits over PaleoCodage are less obvious. Both of them fundamentally try to represent the same thing: the relative positions of strokes within a sign. What is there to gain by representing this with a tree, rather than state changes in a finite automaton?
The key is that, in the kadaru encoding, the relationships between the wedges themselves are fundamental. In PaleoCodage, the operator between two strokes doesn’t just express the relationship between them – it conveys how they relate to the sign as a whole, and the other strokes in it. As mentioned in Section 2.2, the difference between a-a and a_a (a vertical wedge next to a vertical wedge) doesn’t necessarily represent anything about those two strokes. Instead, the primary difference is how they interact with other types of strokes overlapping them.
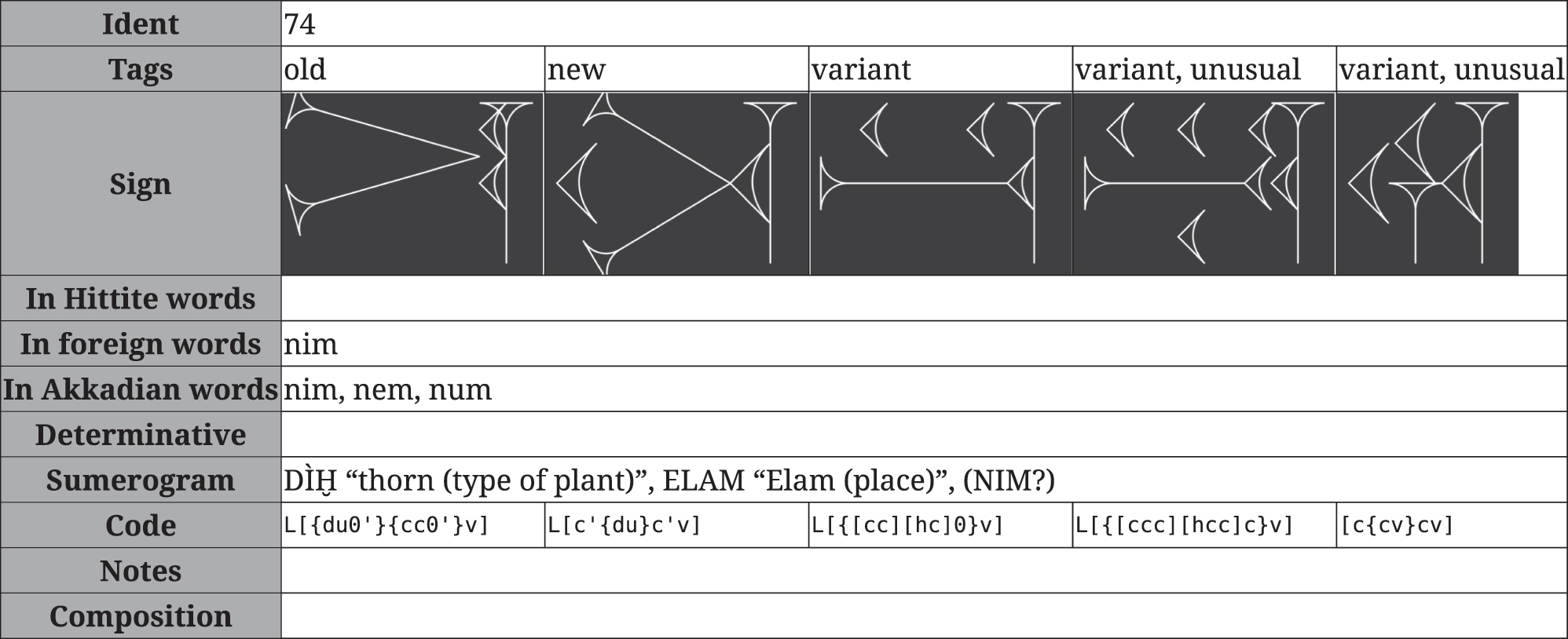
In the kadaru system, on the other hand, the relationship between any two strokes can be determined by finding their last common ancestor in the tree. In the sign  ge
š
tin ‘wine’, the hook is to the left of the diagonal – and this is reflected in the encoding (Figure 23). The last common ancestor of those two (shown by the blue lines) is a horizontal stack, and the hook precedes the diagonal.
ge
š
tin ‘wine’, the hook is to the left of the diagonal – and this is reflected in the encoding (Figure 23). The last common ancestor of those two (shown by the blue lines) is a horizontal stack, and the hook precedes the diagonal.
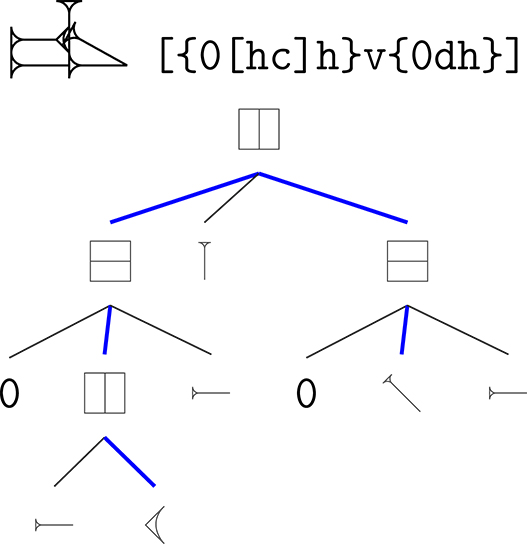
The relationships between certain strokes in the sign ge š tin ‘wine’, highlighted in blue.
The encompassing algorithm described in Section 4.3 then ensures that a search for [cd] will find this sign, no matter how far apart the hook and diagonal are in the encoded sign. As a result, a student using the kadaru encoding can search for any part of a sign – no matter whether other parts of the sign are missing, damaged, badly transcribed, or just difficult to encode. This is something that neither the Gottstein nor PaleoCodage systems currently supports. The kadaru system is designed around the relationships between strokes first and foremost, and as a result is far more resilient to damage (Figure 30) or just simple obscurity than its predecessors.
A comparison of how a few different signs would be encoded in these three systems can be found in Table 3, and a fuller demonstration in Table 4.
Three signsa with identical Gottstein codes, but distinct PaleoCodage and kadaru encoding.
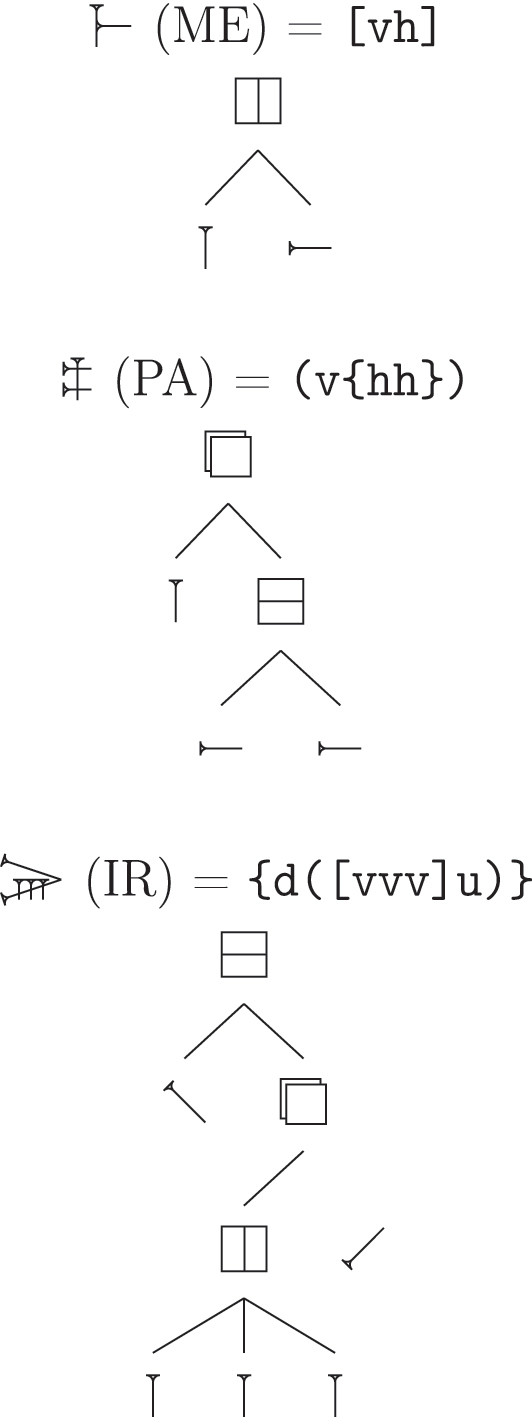
| Sign | Gottstein | PaleoCodage | Kadaru |
|---|---|---|---|
 MAŠ MAŠ |
a1b1 | :b-a | (vh) |
 BAR BAR |
a1b1 | ;b-a | {vh} |
 ME ME |
a1b1 | a-:b | [vh] |
-
aThis demonstration is taken from Homburg [21], p. ii131]; in Hittite, the signs MAŠ and BAR have merged.
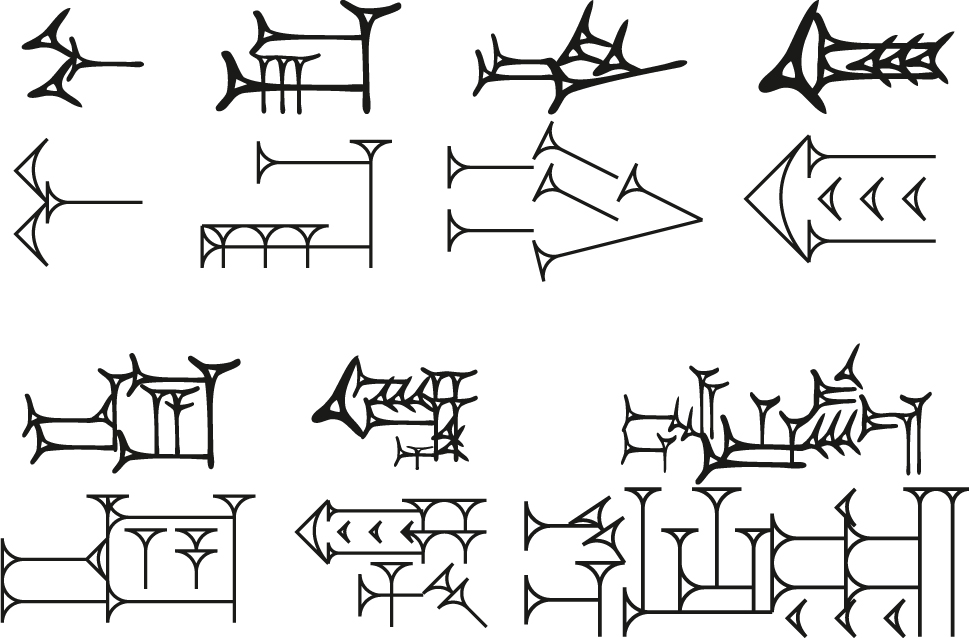
Various phonetic signs encoded in each system, for comparison.a
| Sign | Name | Gottstein | Kadaru | PaleoCodage | PaleoCodage render |
|---|---|---|---|---|---|
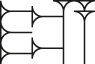
|
ya | a3b5 | L[{hhh}{hh}vv2] | b:b:b_/b:b_a-a:a |
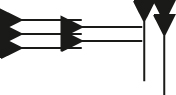
|
|
bi | b2c2 | {[hc’][hc’]} | b:b_w:w |
|
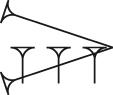
|
ir | a3c2 | L{d(u[vvv])} | <;C>>D-:;sa-:;sa-:;sa |
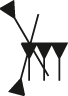
|

|
lu | a3b3 | [v{h(hv)Mh}v] | :a-b;b-:::sb::-::sa-a |

|
-
aGottstein code, PaleoCodage encoding, and PaleoCodage rendering (the rightmost column) are taken from the demonstration at https://situx.github.io/PaleoCodage/. Kadaru encoding and rendering (the leftmost column) are adapted to match this version of the sign if it differs from the Hittite one.
4 Algorithms
4.1 Rendering
Now that we have a way of encoding signs into trees, we can write algorithms to manipulate them in various ways. For example, we can render a tree back into an image of a sign. Unlike in PaleoCodage, the encoding is not expected to specify the exact size, position, and angle of each wedge – instead, the rendering algorithm applies various aesthetic principles to arrange the strokes in a clear and pleasing way. This means that, for example, diagonal strokes in the kadaru system only encode whether they’re oriented upward or downward; the exact angle is chosen by the rendering algorithm based on aesthetic constraints.
The main goal of this algorithm is to assign a rectangle of space to each node in the tree. This space is represented as an axis-aligned bounding box, specifying the height, width, and coordinates of the top left corner, but not rotation. Then, each leaf node can be drawn[44] into the appropriate space.
Since the input to the algorithm is a tree, this is best handled recursively. The root of the tree determines the overall size of the sign: one unit in height, with the width determined by a special character at the beginning of the encoding. Then each node is assigned space by its parent, and assigns an appropriate amount of space to each of its children:
Intersections assign the full space to each of their children, causing them to overlap.
Margin adjustments remove an appropriate amount of length (one-fifth the width, one-fifth the height, or one-tenth of a unit, whichever is smallest) from each side of the rectangle, then allot the resulting space to their child.
Tenû adjustments assign the space from (0, 0) to
All other component modifiers assign their entire space to their child without alteration.
The complicated case is the horizontal and vertical stacks. These require some additional definitions first:
Horizontal wedges can expand horizontally, but not vertically.
Vertical wedges can expand vertically, but not horizontally.
Diagonal wedges and voids can expand in both directions.
Winkelhaken are always twice as tall as they are wide, and can expand in whichever direction is the limiting factor in that ratio.
Compositions can expand if any of their children can.
Allow adjustments can always expand, and restrict adjustments can never expand, regardless of their children.
Vertical wedges allow kerning up to half their width from the left and right, and not at all from the top and bottom.
Horizontal wedges allow kerning up to half their height from the top and bottom, and not at all from the left and right.
Kern adjustments allow kerning up to half their width/height from every direction.
Horizontal stacks allow kerning on the left and right based on their leftmost and rightmost children, and on the top and bottom based on the minimum allowed by any of their children.
Vertical stacks allow kerning on the top and bottom based on their topmost and bottommost children, and on the left and right based on the minimum allowed by any of their children.
Tenû adjustments take the endpoints of all descendant non-void strokes, convert them to the outer coordinate system, and allow kerning to the leftmost, rightmost, topmost, and bottommost of those endpoints.
Other nodes use the minimum allowed by any of their children on all sides.
The size factor of an expand adjustment is one plus the size factor of its child.
The size factor of an allow adjustment is the size factor of its child, allowing it to be wrapped around an expand adjustment.
The size factor of a cursor (in the interface) is zero.
The size factor of any other node is one.
Now, to render a horizontal stack:
As a first pass, divide the width between all the element’s children, in proportion to their size factors.
Then, repeat the following:
Determine whether any of the element’s children can expand horizontally. If not, the process is complete.
For each pair of adjacent elements, determine if one allows kerning in the appropriate direction, and the other does not.[45] If so, move them together by the maximum allowed amount.
Add up how much space has been reclaimed via kerning. If there is none, the process is complete.
Distribute the reclaimed space between the children that can expand, in proportion to their size factors.
Vertical stacks are the same, substituting “vertical” for “horizontal” and “height” for “width”.
This algorithm is simple – requiring much less detail than the paleologically-focused PaleoCodage – but the end results are remarkably effective. With only two exceptions (see Section 3.3), it has been able to create aesthetically pleasing renditions of every sign and common variant listed in Rüster and Neu [14], across all eras of Hittite. Figure 24 compares the results against the detail-oriented PaleoCodage renderer, and Figure 25 compares this algorithm’s rendering of several logograms against a traditional hand-drawn cuneiform font.

The phonetic sign ya, rendered in PaleoCodage (left) and the kadaru system (right). PaleoCodage’s renderer is optimized for precision in detail, as necessary for paleography, while the kadaru renderer is optimized for overall aesthetics and readability at the expense of precision.
Logograms of varying complexity rendered in a traditional hand-drawn font (lines 1 and 3) and in our new rendering engine (lines 2 and 4). Top row: munus ‘woman’, iku ‘field’, lugal ‘king’, ki š ‘world’. Bottom row: nag ‘drink’, buru 14 ‘harvest’, umbin ‘fingernail’. “Ullikummi”, created by Sylvie Vanséveren.
While the original goal was only to encode signs for searching purposes, this renderer compares favorably against traditional fonts. It could be used to quickly render unusual glyphs and glyph variants for discussion, much like Wong, Yiu, and Ng’s [46] proposed HanGlyph synthesizer,[46] and could potentially render entire documents in a clean, easily-readable style. All the inline glyphs used in this article are rendered in this way. While PaleoCodage can be far more precise in the details – even with aesthetic modifiers, the kadaru system is not designed to capture the paleographic details of a particular scribe’s handwriting – the output of the kadaru renderer is meant to be more readable for general usage, equivalent to a typeset edition of a manuscript rather than a facsimile.
Hittite cuneiform tablets in particular have a reputation for being very clean and readable in their layout, even in daily correspondence: words are clearly distinguished, lines of text are more or less justified, paragraphs and sections are marked. Some cuneiform scholars[47] will even “lovingly” call it “typewriter cuneiform” (Schreibmaschinen-Keilschrift). Could the renderer replicate these features, laying out full tablets on these principles? This would provide, effectively, cuneiform typesetting of a sort seldom attempted before. A prototype can be seen in Figure 26.

A prototype rendering of three lines from a tablet – in this case, the Hittite Gilgamesh. Autograph taken from https://www.assyrianlanguages.org/hittite/index_en.php?page=textes. Unlike PaleoCodage, the kadaru renderer is optimized for overall readability, sacrificing paleographic detail for this purpose: the scribe of the original tablet left off a vertical stroke in the GIM sign, third on the first line, for example, but the kadaru render uses the standard form.
4.2 Normalization
One issue with this encoding is that it can be ambiguous. While every recursive code describes exactly one sign, the same sign can sometimes be described by multiple codes.  za, for example, could be described either as [{vv}{vv}] or as {[vv][vv]}: a horizontal stack of two vertical stacks, or a vertical stack of two horizontal stacks. This poses a problem for searching. How can a user know which of these two they should search for?
za, for example, could be described either as [{vv}{vv}] or as {[vv][vv]}: a horizontal stack of two vertical stacks, or a vertical stack of two horizontal stacks. This poses a problem for searching. How can a user know which of these two they should search for?
The solution is a recursive algorithm for normalization: converting encodings to a form that is unambiguous to compare. The main purpose of this “normalized” or “functional” form is to be used as the input to other algorithms. As a proof of concept, two different “modes” of normalization are implemented; in the standard mode, all five stroke types remain distinct, but in “Gottstein mode”, downward diagonals and Winkelhaken are not distinguished, as recommended by Gottstein [16]. This demonstrates that similar adjustments could be made for particular languages or eras as necessary.
In the following algorithms, the word contains means “is the parent of”, while indirectly contains means “is the ancestor of”. That is, a node contains its children, and indirectly contains its children, its children’s children, and so on.
The normalization algorithm is as follows:
The normalized form of a double-headed stroke is a stack of two single strokes (h2 → [hh]) – a vertical stack for vertical and downward diagonal wedges, a horizontal stack for horizontal and upward diagonals.[48]
If operating in “Gottstein mode”, the normalized form of a downward diagonal is a Winkelhaken, or a vertical stack of two Winkelhaken if double-headed. This normalizes away the difference between these two types of strokes for styles of cuneiform where they are not reliably distinguished.
The normalized form of a void is nothing at all. In other words, voids are discarded.
The normalized form of any other stroke is that stroke without any modifiers.
The normalized form of the tenû adjustment is the normalized form of its child, with all horizontal descendants replaced by upward diagonals, and all vertical descendants replaced by downward diagonals.[49]
The normalized form of any other component modifier (like E) is the normalized form of its child.
The normalized form of a composition is based on the normalized forms of all its children. If it’s an intersection (where the order of the children doesn’t matter), the children are sorted in lexicographic order.[50] Then, a few special cases are checked:
If a composition has only a single child, the normalized form of the composition is the normalized form of the child ([v] → v).
If a composition has no children, the normalized form of that composition is nothing at all.
If a composition contains another composition of the same type, the nesting is removed ([v[vv]v] → [vvvv]).
If a vertical stack contains only horizontal stacks, and all those horizontal stacks have the same number of elements, and the parent of this node is not a vertical stack, the normalized form is rearranged into a horizontal stack of vertical stacks. This means that the normalized form of
 is always [{vv}{vv}], never {[vv][vv]}.
is always [{vv}{vv}], never {[vv][vv]}.Conversely, if a horizontal stack contains only vertical stacks, and all those vertical stacks have the same number of elements, and the parent of this node is a vertical stack, the normalized form is rearranged into a vertical stack of horizontal stacks. This reduces the total number of stacks, since a vertical stack inside a vertical stack is removed by the third special case.
If a vertical stack contains one or more horizontal stacks, and any of those stacks contains a horizontal wedge and a Winkelhaken at the right or left end, remove those Winkelhaken from the ends and rearrange them into vertical stacks of their own. Then combine those vertical stacks together as a horizontal stack: {[hc]h} becomes [{}{hh}{c}] (removing one Winkelhaken from the right and none from the left). The empty and singleton stacks are then simplified by the other cases above. This handles the ambiguity of signs like uš; the difference between
 and
and 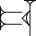 is clear in the trees, but not at all clear on the actual clay, and this ensures that the normalized form always has the Winkelhaken outside the vertical stack.
is clear in the trees, but not at all clear on the actual clay, and this ensures that the normalized form always has the Winkelhaken outside the vertical stack.An intersection composition is mixed iff it indirectly contains both horizontal and vertical strokes. If a vertical stack contains only horizontal elements and a mixed intersection, or a horizontal stack contains only vertical elements and a mixed intersection, the normalized form puts the stack inside the intersection. This is the strangest normalization rule, and its purpose is to ensure that patterns like {hh(hv)}, {h({hh}v)}, and ({hhh}v) have the same normalized form, since they are nearly impossible to distinguish on actual clay: it’s not always clear how many of the horizontals the vertical was meant to cross.
If none of these special cases apply, the normalized form of the composition is the same composition of the normalized forms of its children.
The end result is that aesthetic variations, like the lengths of strokes or the size of the gaps between them, will not affect searching or comparisons.
4.3 Encompassing
The most crucial algorithm is termed encompassing. For the search system to be effective, a tree must “encompass” any subset of its strokes, as long as the relationships between those strokes are preserved; the strokes should not have to be contiguous, and the relationships to any other strokes not in the subset should not matter. In other words, a sign should “encompass” any part a user might search for, even if other parts of the sign are damaged or difficult to read.
The algorithm given here is significantly more complex than previous approaches to recursive searching. Downes [42], for instance, uses standard substring matching in Excel, and similar algorithms exist to match subtrees.[51] Homburg [21] likewise uses standard metrics of string similarity. However, subtree matching is not sufficient for our purposes. Consider the sign in Figure 27. It’s impossible for both the red component and the blue component to be subtrees. But both are perfectly reasonable ways for a user to search for the sign! Something better is needed.
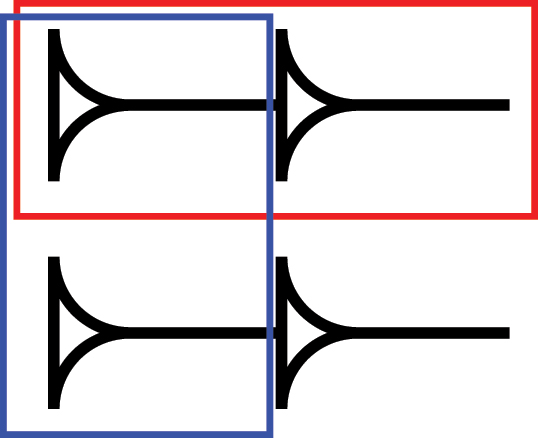
An illustration of why subtree matching is not sufficient for sign identification.
The encompassing algorithm is the most crucial part of this system. This relation allows users to search for whichever part of a sign is clearest and most readable. They aren’t limited to the leftmost part of the sign, or even a complete subtree; any visible strokes can be used to narrow the search (Figure 33).
The algorithm for this is, like the others, recursive.
A stroke encompasses a stroke of the same type.
Any stroke encompasses a wildcard.
A composition A encompasses a node B if any child of A encompasses B.
An intersection A encompasses an intersection B if every child of B is encompassed by some child of A.[52]
A stack A encompasses a stack B if:
A and B have the same type (vertical or horizontal), and
Every child of B is encompassed by some child of A, and
For any children of B x and y, if x precedes y, then the child of A that encompasses y does not precede the child of A that encompasses x. This ensures that [vh] does not encompass [hv], but [hcv] does. In other words, it loosely enforces an ordering.
A slight modification of this algorithm can also return a list of the wedges matched in the first bullet point. In the interface, this is used to highlight the matching part of each search result, displaying those wedges in a different color (as in Figures 29, 32 and 33).
4.4 Interface
Finally, some sort of interface is needed for scholars to actually make use of these algorithms. The prototype consists of a canvas and a search engine, available at https://dstelzer.pythonanywhere.com/canvas.html (Figures 28–33).
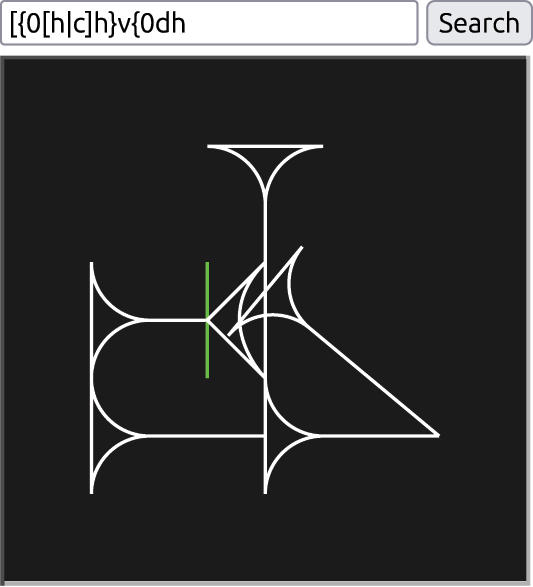
The “canvas” part of the interface, helping users enter kadaru codes by showing the result in real time. The code entered here doesn’t need to be complete (note the two brackets opened but never closed), and the position of the cursor is marked with a green bar (between the horizontal and Winkelhaken), indicating where a newly-typed stroke will be inserted. A drop-down at the top changes the rendering style, letting users customize it to their preference.
The “search” part of the interface, showing all the signs encompassing the code the user created with the canvas. The matching strokes are highlighted in green. Other options allow the user to narrow down signs by name and change the sorting method or normalization mode.

Examples of signs with varying degrees of damage, taken from KBo autographs: kiri 6 ‘garden’, tur ‘small’, nag ‘drink’, sa 5 ‘red’, and a š 3 ‘six’.
The database provides information about both the sign as a whole, such as its various readings, and about its individual forms. In this case, the first form shown is used in Old Script, the second in New Script, and the last is flagged as particularly unusual.

The process of searching for a complete sign: an š e ‘donkey’ (left). The user looks for the part of the sign that seems easiest to encode; in this case, that’s the four strokes on the left. Using the interface from Figure 28, they encode this as {ddhh} (middle). The search interface from Figure 29 then shows them a list of all six signs which encompass this component, and the user can identify the correct sign (right) from among them.
![Figure 33:
The process of searching for a broken sign: dug ‘vessel’ (left). Since the left side of this sign is broken, the user encodes the bottom part: the horizontal stroke intersecting an A sign, (h[vv2]) (middle). The program then produces a list of all seven signs encompassing this element, allowing the user to identify the best one (right).](/document/doi/10.1515/itit-2024-0067/asset/graphic/j_itit-2024-0067_fig_033.jpg)
The process of searching for a broken sign: dug ‘vessel’ (left). Since the left side of this sign is broken, the user encodes the bottom part: the horizontal stroke intersecting an A sign, (h[vv2]) (middle). The program then produces a list of all seven signs encompassing this element, allowing the user to identify the best one (right).
The canvas is designed to help users input kadaru codes. It has a text box to enter a code, and displays the graphical result next to it, updating in real time. The position of the cursor in the text box is reflected with a green bar in the output, showing where a newly-typed stroke would appear, and any strokes highlighted in the text box are colored green. This is intended to help users develop an intuition for the kadaru system (Figure 28).
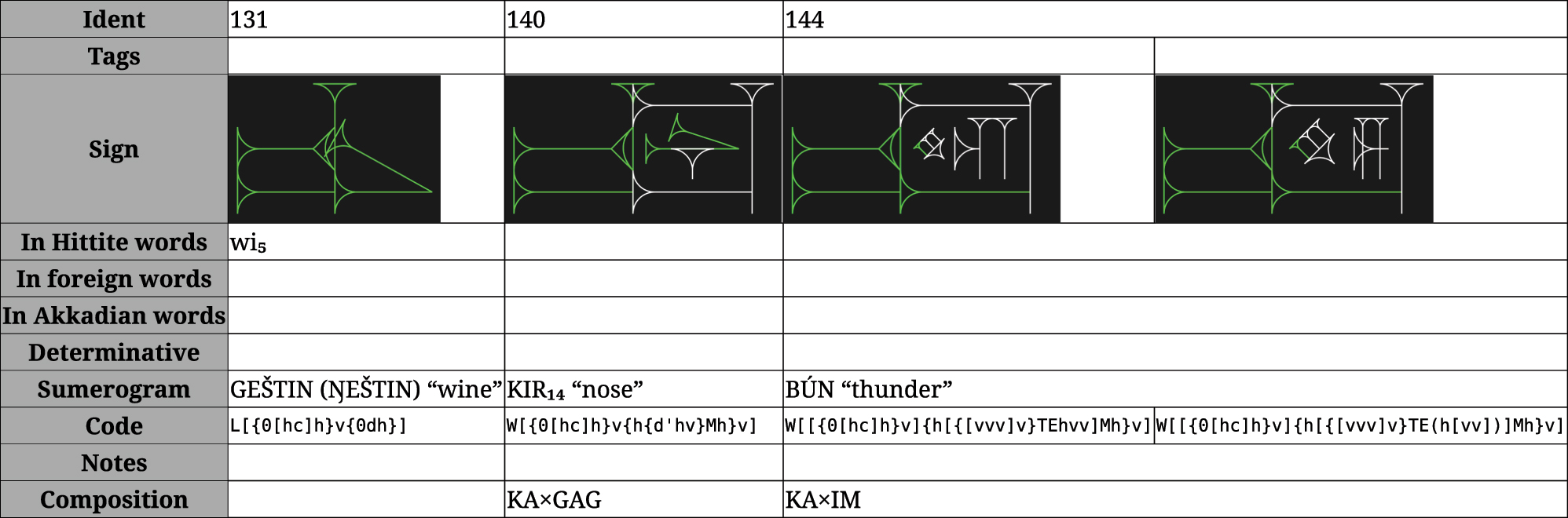
The search engine then takes a pattern entered through the canvas and displays a list of signs that encompass that pattern, using the algorithm from Section 4.3 (Figure 29). The database behind this currently contains all signs and major variants from Rüster and Neu [14], and the results can be sorted by Rüster and Neu’s index number, sign usage (phonogram, heterogram, logogram, semagram), or number of wedges.[53] Since the Hittite script changed significantly over its five centuries of use, individual forms can be “tagged” with notes about their usage (Figure 31); this way, a scholar searching for a damaged sign in a Neo-Hittite tablet can tell if their search results are New Script or Old Script, and common forms or unusual variants.
5 Conclusions
This paper proposes a new method of encoding the shape of a cuneiform sign, as a tree made up of strokes and compositions. As a result, computers can now work with the shape of a sign in a way that wasn’t possible before. At its most basic level, this can be used for rendering, turning this recursive encoding into a picture of the sign.
But rendering is only the tip of the iceberg. Using these tools, scholars can now search for a sign based on any wedges that are visible, regardless of damage or obscurity. Experiments are currently underway to determine if this makes a quantitative difference to the users’ experience, and pilot results are promising.
The kadaru encoding can also serve as an intermediate form for machine learning approaches to cuneiform, allowing problems to be factored into smaller steps than were possible before. I believe these recursive approaches have potential far beyond what’s been tested so far, and may be a significant step forward in computational analysis of cuneiform writing.
5.1 Resources
The code discussed in this article can be found at https://bitbucket.org/dstelzer/hantatallas, and can be used at https://dstelzer.pythonanywhere.com/canvas.html. A full reference is given in Table 5.
A complete syntax reference. Canvas size is indicated by the first character; other modifiers and adjustments come after the nodes they modify; commas and whitespace can be used as optional delimiters.
| Strokes | h | Horizontal |

|
| v | Vertical |
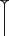
|
|
| d | Downward diagonal |

|
|
| u | Upward diagonal |

|
|
| c | Winkelhaken/Hook |
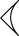
|
|
| 0 | Void | An invisible “stroke” that takes up space | |
| * | Wildcard | Matches any stroke in the encompassing algorithm | |
| | | Cursor | Renders as a line or cross, to show where a new stroke will be inserted in the interface; ignored | |
| in searching | |||
| Compositions | [] | Horizontal stack | Arrange children from left to right |
| {} | Vertical stack | Arrange children from top to bottom | |
| () | Intersection | Overlay children onto the same space | |
| Stroke modifiers | ’ | Shorten head | For most strokes, shorten by bringing the head inward; for a Winkelhaken, reduce size slightly; for |
| a void, prevent expanding horizontally | |||
| ” | Shorten tail | For most strokes, shorten by bringing the tail inward; for a Winkelhaken, reduce size greatly; for | |
| a void, prevent expanding vertically | |||
| 2 | Double head | Put an additional head on the stroke | |
| 3 | Triple head | Put two additional heads on the stroke | |
| # | Damage | Draw hatching (diagonal lines) over this stroke, to indicate damage to the tablet in rendering | |
| ! | Highlight | Render this stroke in a different color | |
| ? | Invert | Swap the head and tail of this stroke | |
| Node adjustments | T | Tenû | Rotate a node 45° counter-clockwise |
| E | Expand | Ask the arrangement algorithm to give this node twice as much space | |
| M | Margin | Leave a small amount of empty space on all sides of this node | |
| R | Restrict | Prevent this node from expanding in any direction | |
| A | Allow | Allow this node to expand infinitely in all directions | |
| K | Kern | Allow adjacent nodes to kern into this node from every side | |
| Canvas size | N | Narrow | 1:3 (width:height ratio) |
| P | Portrait | 2:3 | |
| S | Square | 1:1 (default) | |
| L | Landscape | 3:2 | |
| W | Wide | 2:1 | |
| X | Extra-wide | 3:1 |
About the author

Daniel Stelzer is a doctoral student at the University of Illinois at Urbana-Champaign, specializing in computational analysis of ancient languages. They received their MA and BA in Linguistics and a BS in Computer Science with a minor in Classics from the same institution. Their current focus is digitization of Hittite cuneiform.
Acknowledgments
I would like to thank my thesis advisor, Ryan Shosted, who introduced me to cuneiform studies in the first place and funded my experiments with this system; the user Yellow Sky on StackExchange, who spurred all of this by directing my attention to Downes’ work back in 2020; Daniel Jost, who corrected my translations of Gottstein’s German; the editors and two anonymous reviewers who first gave feedback on this paper for the Cuneiform Digital Library Journal; and the editors and two further anonymous reviewers who then helped refine it here.
-
Research ethics: Not applicable.
-
Informed consent: Not applicable.
-
Author contributions: The author has accepted responsibility for the entire content of this manuscript and approved its submission.
-
Use of Large Language Models, AI and Machine Learning Tools: None declared.
-
Conflict of interest: The author states no conflict of interest.
-
Research funding: None declared.
-
Data availability: The raw data can be obtained on request from the corresponding author.
References
[1] J. Huehnergard, A Grammar of Akkadian. Third. Harvard Semitic Studies, Winona Lake, Indiana, Eisenbrauns, 2011. Available at: https://www.academia.edu/234695/2011_A_Grammar_of_Akkadian_3rd_edition_.10.1163/9789004369160Search in Google Scholar
[2] J. S. Cooper, “Sumerian and Akkadian,” in The World’s Writing Systems, P. T. Daniels and W. Bright, Eds., Oxford University Press, 1996.Search in Google Scholar
[3] M. Worthington, Principles of Akkadian Textual Criticism, Berlin, De Gruyter, 2012.10.1515/9781614510567Search in Google Scholar
[4] L. Watkins and D. Snyder, “The Digital Hammurabi Project,” 2003. Available at: https://www.researchgate.net/publication/247838547_The_digital_hammurabi_project.Search in Google Scholar
[5] R. Borger, Mesopotamisches Zeichenlexikon. German. 2., revidierte und aktualisierte Aufl. Alter Orient und Altes Testament; 305, Münster, Ugarit-Verlag, 2010.Search in Google Scholar
[6] R. Labat, Manuel d’épigraphie akkadienne. Signes, syllabaire, idéogrammes, 6th ed. Paris, Librairie orientalisle P. Geuthner, 1995.Search in Google Scholar
[7] S. Gordin, Hittite Scribal Circles: Scholarly Tradition and Writing Habits, 1st ed. Harrassowitz Verlag, 2015. Available at: http://www.jstor.org/stable/j.ctvc76zpc.10.2307/j.ctvc76zpcSearch in Google Scholar
[8] E. Robson, “Using sign lists: Labat, Borger, and PSL,” in Cuneiform Revealed: An Introduction to Cuneiform Script and the Akkadian Language, 2010. Available at: http://knp.prs.heacademy.ac.uk/cuneiformrevealed/learningsigns/usingsignlists/.Search in Google Scholar
[9] H. Radau, Letters to Cassite Kings from the Temple Archives of Nippur, University of Pennsylvania Department of Archaeology, 1908. Available at: https://archive.org/details/letters-to-cassite-kings-from-the-temple-archives-of-nippur.10.9783/9781512820805Search in Google Scholar
[10] Å. W. Sjöberg, “The Old Babylonian eduba,” in Sumerological Studies in Honor of Thorkild Jacobsen on His Seventieth Birthday, S. J. Lieberman, Ed., Assyriological Studies 20. University of Chicago Press, 1974, pp. 159–179.Search in Google Scholar
[11] J. Taylor, “OB Nippur Lu=ša,” in Digital Corpus of Cuneiform Lexical Texts, Berkeley, University of California, 2005.Search in Google Scholar
[12] DCCLT, “Introduction. What is a lexical list?” in Digital Corpus of Cuneiform Lexical Texts, University of California, Berkeley, 2003.Search in Google Scholar
[13] A. Deimel and P. F. Gössman, Šumerisches Lexikon, Scripta Pontificii Instituti Biblici. sumptibus Pontificii instituti biblici, 1934. Available at: https://books.google.com/books?id=2hcdAAAAIAAJ.Search in Google Scholar
[14] C. Rüster and E. Neu, Hethitisches Zeichenlexikon. Inventar und Interpretation der Keilschriftzeichen aus den Boğazköy-Texten, Studien zu den Boğazköy-Texten: Beiheft. O. Harrassowitz, 1989. Available at: https://books.google.com/books?id=L15pAJsx%5C_y0C.Search in Google Scholar
[15] R. Borger, List of Neo-Assyrian Cuneiform Signs: A Practical and Critical Guide to the Unicode Blocks ‘Cuneiform’ and ‘Cuneiform Numbers’ of Unicode Standard Version 5.0, 2007. Available at: http://www.sumerisches-glossar.de/download/SignListNeoAssyrian.pdf.Search in Google Scholar
[16] N. Gottstein, “Ein stringentes Identifikations- und Suchsystem für Keilschriftzeichen,” in Mitteilungen der Deutschen Orient-Gesellschaft zu Berlin, vol. 145, 2013, pp. 127–136.Search in Google Scholar
[17] N. Christiaan Veldhuis, Elementary Education at Nippur: The Lists of Trees and Wooden Objects, Ph.D. thesis, University of Groningen, 1997.Search in Google Scholar
[18] C. J. Crisostomo, “Introduction to cuneiform sign lists,” in Digital Corpus of Cuneiform Lexical Texts. The DCCLT Project, 2019.Search in Google Scholar
[19] K. Šašková, Cuneiform Sign List, 2021. Available at: http://home.zcu.cz/∼ksaskova/Sign_List.html.Search in Google Scholar
[20] ePSD, The Electronic Pennsylvania Sumerian Dictionary, University of Pennsylvania Museum of Anthropology and Archaeology, 2006. Available at: http://psd.museum.upenn.edu/nepsd-frame.html.Search in Google Scholar
[21] T. Homburg, “PaleoCodage: enhancing machine-readable cuneiform descriptions using a machine-readable paleographic encoding,” in Digital Scholarship in the Humanities 36.Supplement_2, 2021, pp. ii127–ii154.10.1093/llc/fqab038Search in Google Scholar
[22] Theo van den Hout, The Elements of Hittite, Cambridge, Cambridge University Press, 2011.10.1017/CBO9781139013369Search in Google Scholar
[23] J. Burman, et al.., “Inventaire des signes hiéroglyphiqures en vue de leur saisie informatique. Manuel de codage des textes hiéroglyphiques en vue de leur saisie informatique,” in Mémoires de L’académie des inscriptions et belles lettres, 1988.Search in Google Scholar
[24] A. Kamate, “Creating a Japanese Handwriting Recognizer: using tensorflow to create a machine learning model for handwriting recognition,” in Towards Data Science, 2020.Search in Google Scholar
[25] X. Liu, B. Hu, Q. Chen, X. Wu, and J. You, “Stroke sequence-dependent deep convolutional neural network for online handwritten Chinese character recognition,” IEEE Trans. Neural Netw. Learn. Syst., vol. 31, no. 11, pp. 4637–4648, 2020. https://doi.org/10.1109/TNNLS.2019.2956965.Search in Google Scholar PubMed
[26] C.-L. Liu and X.-D. Zhou, “Online Japanese character recognition using trajectory-based normalization and direction feature extraction,” in Tenth International Workshop on Frontiers in Handwriting Recognition, G. Lorette, Ed., France, Université de Rennes 1. La Baule, Suvisoft, 2006.Search in Google Scholar
[27] E. Doostmohammadi and M. Nassajian, “Investigating machine learning methods for language and dialect identification of cuneiform texts,” in Proceedings of the Sixth Workshop on NLP for Similar Languages, Varieties and Dialects, Ann Arbor, Michigan, Association for Computational Linguistics, 2019, pp. 188–193.10.18653/v1/W19-1420Search in Google Scholar
[28] S. Gordin, et al.., “Reading Akkadian cuneiform using natural language processing,” PLoS One, vol. 15, no. 10, pp. 1–16, 2020. https://doi.org/10.1371/journal.pone.0240511.Search in Google Scholar PubMed PubMed Central
[29] T. Dencker, P. Klinkisch, S. M. Maul, and B. Ommer, “Deep learning of cuneiform sign detection with weak supervision using transliteration alignment,” PLoS One, vol. 15, no. 12, pp. 1–21, 2020. https://doi.org/10.1371/journal.pone.0243039.Search in Google Scholar PubMed PubMed Central
[30] N. M. Kriege, et al.., “Recognizing cuneiform signs using graph based methods,” in COST@SDM, 2018.Search in Google Scholar
[31] D. Fisseler, et al.., “Towards an interactive and automated script feature analysis of 3D scanned cuneiform tablets,” in Scientific Computing and Cultural Heritage, vol. 2013, 2013.Search in Google Scholar
[32] M. Fey, et al.., “SplineCNN: fast geometric deep learning with continuous B-spline kernels,” in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, pp. 869–877.10.1109/CVPR.2018.00097Search in Google Scholar
[33] E. Stötzner, et al.., “R-CNN based polygonal wedge detection learned from annotated 3D renderings and mapped photographs of open data cuneiform tablets,” in Eurographics Workshop on Graphics and Cultural Heritage, The Eurographics Association, A. Bucciero, et al.., Ed., 2023.10.1109/ICCVW60793.2023.00183Search in Google Scholar
[34] D. Snyder, “The initiative for cuneiform encoding,” 2000. Available at: https://pages.jh.edu/ice/.Search in Google Scholar
[35] A. H. Gardiner, Egyptian Grammar: Being an Introduction to the Study of Hieroglyphs, Oxford, Griffith Institute, Ashmolean Museum, Oxford University Press, 1957. Available at: http://web.ff.cuni.cz/ustavy/egyptologie/pdf/Gardiner_signlist.pdf.Search in Google Scholar
[36] A. H. Gardiner, Catalogue of the Egyptian Hieroglyphic Printing Type: From Matrices Owned and Controlled by Dr. Alan H. Gardiner: in Two Sizes 18 Point, 12 Point with Intermediate Forms, Oxford University Press, 1928. Available at: https://libmma.contentdm.oclc.org/digital/collection/p15324coll10/id/127182.Search in Google Scholar
[37] J. Breen, “Multiple indexing in an electronic kanji dictionary,” in Proceedings of the Workshop on Enhancing and Using Electronic Dictionaries. ElectricDict ’04, Geneva, Switzerland, Association for Computational Linguistics, 2004, pp. 1–7.10.3115/1610042.1610044Search in Google Scholar
[38] S. Tinney, ATF Inline Tutorial, Oracc: The Open Richly Annotated Cuneiform Corpus, 2019. Available at: http://oracc.museum.upenn.edu/doc/help/editinginatf/primer/inlinetutorial/index.html.Search in Google Scholar
[39] E. Robson, “Wedges and signs,” in Cuneiform Revealed: An Introduction to Cuneiform Script and the Akkadian Language, 2010.Search in Google Scholar
[40] Electronic Dictionary Research and Development Group, “KANJIDIC project,” 1991–2021. Available at: http://www.edrdg.org/wiki/index.php/KANJIDIC_Project.Search in Google Scholar
[41] J. Breen, An Overview of the Four Corner Coding System, Monash University, 2000. Available at: http://nihongo.monash.edu//FOURCORNER.html.Search in Google Scholar
[42] A. Downes, “The Xixia writing system,” Bachelor of Arts Honours Thesis, Macquarie University, 2008.Search in Google Scholar
[43] T. Nishida, Seikago no kenkyū: A Study of the Hsi-hsia Language; Reconstruction of the Hsi-hsia Language and Decipherment of the Hsi-hsia Script, vol. 2, Japan, Zauho Kaukokai, 1966.Search in Google Scholar
[44] The Unicode Consortium, “East Asia,” in The Unicode Standard, Version 9.0, 2016.Search in Google Scholar
[45] D. Snyder, “Examples of cuneiform ideographic descriptor usage,” 2004. Available at: https://pages.jh.edu/ice/basesigns/CuneiformDescriptorUsage.pdf.Search in Google Scholar
[46] W. Wong, C. L. K. Yiu, and K. C. F. Ng, “Typesetting rare Chinese characters in LaTeX,” in TUGBoat, vol. 24, TeX Users Group, 2003, pp. 582–587.Search in Google Scholar
[47] A. Downes, How Does Tangut Work? Ph.D. thesis, Macquarie University, 2016.Search in Google Scholar
[48] G. Torri, “Hittite scribes at play: the case of the cuneiform sign AN,” in Investigationes Anatolicae: Gedenkschrift für Erich Neu, 2010, pp. 317–327.Search in Google Scholar
[49] M. Yon, The City of Ugarit at Tell Ras Shamra, University Park, Eisenbrauns, 2006.10.1515/9781575065144Search in Google Scholar
© 2025 the author(s), published by De Gruyter, Berlin/Boston
This work is licensed under the Creative Commons Attribution 4.0 International License.
Articles in the same Issue
- Frontmatter
- Editorial
- Kleine Fächer Digital
- Research Articles
- Discrete Morse theory segmentation on high-resolution 3D lithic artifacts
- Signed, sealed, delivered – digital approaches to Byzantine sigillography
- Matschoss 2.0 - Virtual machine collections as the missing link between museums and historic monuments
- A recursive encoding for cuneiform signs
- A case study of the use of logical data analysis in the Workmen’s Village in Tell el-Amarna, Egypt
- Digital and computational archaeology in Germany
Articles in the same Issue
- Frontmatter
- Editorial
- Kleine Fächer Digital
- Research Articles
- Discrete Morse theory segmentation on high-resolution 3D lithic artifacts
- Signed, sealed, delivered – digital approaches to Byzantine sigillography
- Matschoss 2.0 - Virtual machine collections as the missing link between museums and historic monuments
- A recursive encoding for cuneiform signs
- A case study of the use of logical data analysis in the Workmen’s Village in Tell el-Amarna, Egypt
- Digital and computational archaeology in Germany