Multinomial Logistic Model for Coinfection Diagnosis Between Arbovirus and Malaria in Kedougou
-
Mor Absa Loum
 ,
Marie-Anne Poursat
,
Marie-Anne Poursat

Abstract
In tropical regions, populations continue to suffer morbidity and mortality from malaria and arboviral diseases. In Kedougou (Senegal), these illnesses are all endemic due to the climate and its geographical position. The co-circulation of malaria parasites and arboviruses can explain the observation of coinfected cases. Indeed there is strong resemblance in symptoms between these diseases making problematic targeted medical care of coinfected cases. This is due to the fact that the origin of illness is not obviously known. Some cases could be immunized against one or the other of the pathogens, immunity typically acquired with factors like age and exposure as usual for endemic area. Thus, coinfection needs to be better diagnosed. Using data collected from patients in Kedougou region, from 2009 to 2013, we adjusted a multinomial logistic model and selected relevant variables in explaining coinfection status. We observed specific sets of variables explaining each of the diseases exclusively and the coinfection. We tested the independence between arboviral and malaria infections and derived coinfection probabilities from the model fitting. In case of a coinfection probability greater than a threshold value to be calibrated on the data, long duration of illness and age are mostly indicative of arboviral disease while high body temperature and presence of nausea or vomiting symptoms during the rainy season are mostly indicative of malaria disease.
1 Introduction
Concurrent infections are often observed among vector borne diseases such as malaria and arthropod-borne viral diseases (arbovirus) in tropical regions [1, 2]. It is the case for malaria and dengue in American, African and Asian tropical regions where their endemic areas overlap largely [3, 4, 5, 6, 7, 8, 9]. Malaria can be easily ascribed to other febrile illnesses because its clinical symptoms are often indistinguishable from those initially seen in dengue or chikungunya for instance [10]. Since the introduction of the Rapid Diagnostic Test (RDT) in 2007 in Senegal, malaria has been better diagnosed and an important decrease has been noticed in the prevalence of malaria. Thus we may think that malaria has been overestimated for some time at the expense of other febrile diseases such as arbovirus or bacteria [11, 12]. Presumptive treatment of fever with antimalarial is widely practiced to reduce malaria attributable mortality. This practice means that ill patients may be inappropriately treated, particularly where rapid diagnosis test kits are not readily available, or if the opportunity to test for arboviral infections is missed. Thus, misdiagnosis of arbovirus coinfections as malaria infections may be a cause for underestimating emerging arbovirus infections. In 2009, surveillance of acute febrile illness (AFI) was implemented in Kedougou for early detection of arbovirus outbreaks and malaria and in order to accurately measure disease morbidity and mortality in this geographical region. Due to co-circulation of malaria parasites and arbovirus, that were mainly dengue (DEN), chikungunya (CHIK), Zika (ZIK), yellow fever (YF) and Rift Valley fever viruses (RVFV) in this region (neglecting the prevalence of other arboviral infections), concurrent infections were observed and posed a challenge for medical diagnosis [13]. Here we compare clinical profiles of coinfected patients to clinical profiles of mono-infected patients through the statistical analysis of a data set collected from febrile patients in the Kedougou region, Senegal from 2009 to 2013. Our study aims to characterize the risk factors of coinfection and to provide statistical indicators that improve differential diagnosis of febrile cases for arbovirus.
The data of our study were provided by the Institut Pasteur de Dakar (IPD) at Kedougou (southern-east Senegal). In this region, malaria and arbovirus are endemic due to the climate and the population movements. Data were collected through seven healthcare centers in the region: Ninefesha rural hospital, Kedougou and Saraya Health Centers, Bandafassi and Khossanto health posts, the Kedougou military health post, and the Catholic Mission mobile team. Inclusion criteria were (i) being at least one year old at the date of the visit, (ii) having fever (i. e. body temperature ≥ 38°C) and (iii) manifesting at least one clinical sign within a list of symptoms. Patients satisfying inclusion criteria were enrolled once a written informed consent was signed.
In the present paper, we propose a multinomial logistic model to analyse coinfection between arbovirus and malaria. There were four outcomes determining four groups of patients: arbovirus monoinfections (with respect to the 5 tested arbovirus), malaria monoinfections, arbovirus-malaria coinfections and controls defined as patients negative for malaria and for the 5 tested arbovirus. Febrile episodes from this control group were probably due to other circulating pathogens for which all groups were supposed to be equally exposed. We first performed a covariable selection using random forests based on the variable importance measure [14]. Secondly we fitted a parametric multinomial logistic model including the selected covariables and quantified the influent factors on the different outcomes to investigate the following questions: Which factors can explain coinfection? Which risk factors enable to distinguish between malaria and arbovirus? Finaly, we proposed a Wald-type test to test the correlation between malaria infection and arboviral infection and we computed the probability that a patient be coinfected given that malaria is observed. This predictive analysis was illustrated on simulated data.
The paper is organized as follows. In Section 2, we present the working data set. Section 3 describes the statistical model and the variable selection. In Section 4, we present the independence test between arbovirus and malaria infections and we propose a predictive analysis. A concluding discussion is given in Section 5. Additional analysis and results are provided in Supplementary Material.
2 Data description
Our aim is to differentiate febrile syndroms that could be due to arbovirus from febrile syndroms that could be due to malaria. As coinfection in a single patient may change the spectrum of clinical symptoms, we want to identify those features that predict arboviral infection to improve medical and treatment diagnosis in the primary care setting.
We based our analysis on the data from IPD at Kedougou. The initial data set included 15 523 patients and collected various features: patients’ data (like sex, age, occupation, location,…), clinical symptoms, climate indicators and two binary infections status variables indicating (i) the presence or absence of malaria parasites in blood, (ii) the detection of virus or IgM antibodies against virus. Malaria diagnosis relied on the identification of haematozoa using the thick blood smear (TBS) method. Arboviral infections were investigated by the detection of specific anti-arbovirus IgM using ELISA (enzyme-linked immunosorbent assay). We considered an arboviral case as any individual tested positive to the infection with at least one of the five arbovirus (DEN, CHIK, ZIK, YF and RVF).
In the data set, there are four quantitative covariables: the measured body temperature (in Celsius degrees), the number of sick days defined as the number of days between the date of symptoms onset and the date of consultation, the patient’s age (in year) and the rainfall measure (in millimiters) which is a proxy for the season (rainy or dry). The individual rainfall measure corresponds to the rainfall measure of the patient’s month of consultation. The eleven qualitative covariables are the patient’s gender and ten other binary variable, which record presence or absence of ten symptoms: headache, eye pain, muscle pain, join pain, cough, nausea or vomiting, chills, diarrhea, nasal congestion and icterus and/or jaundice. All the variables of the data sets are summarized in Figure 1.
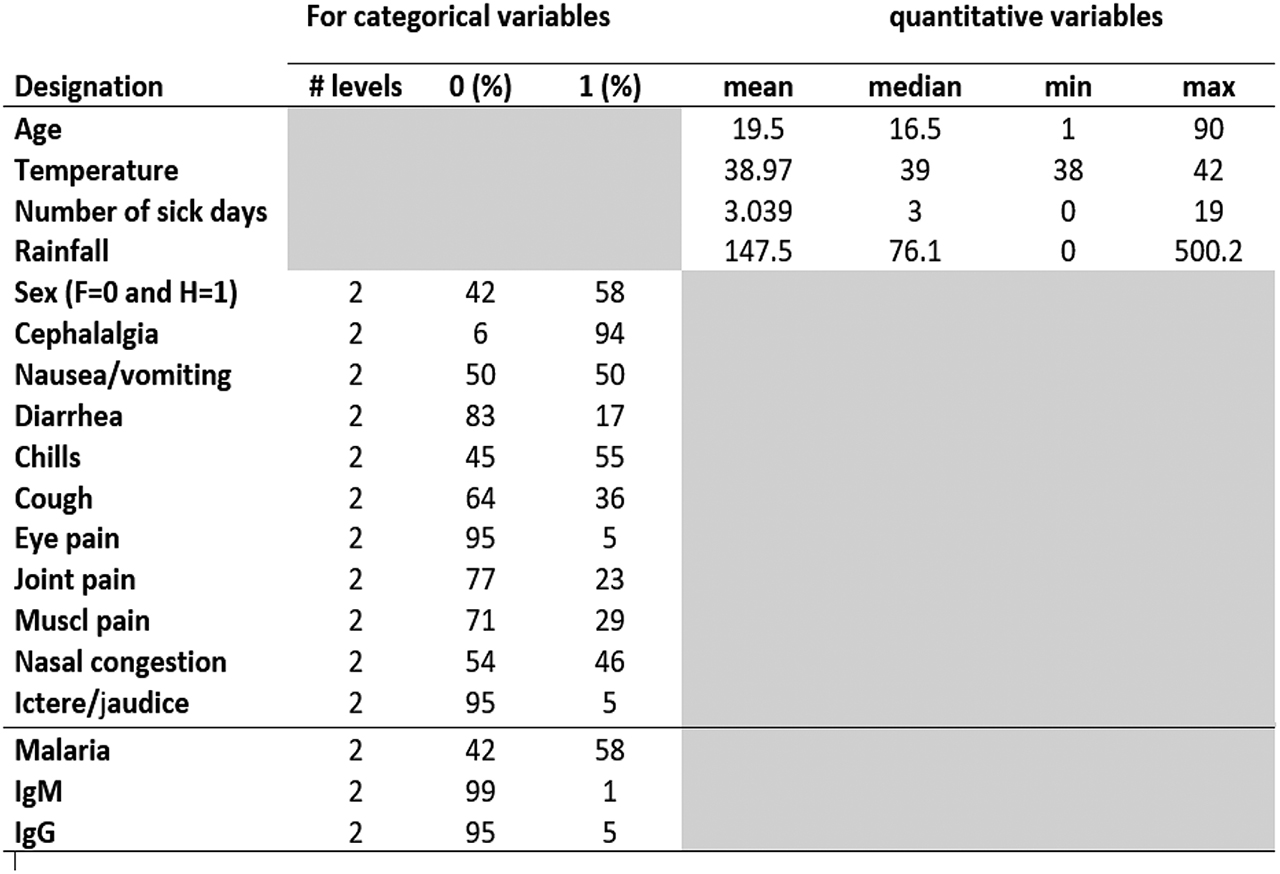
List of variables.
Based on these data we created a new categorical response variable built from four possible combinations of the three infection status variables as follows:
Category 0 corresponds to individuals that are negative for both malaria and the tested arboviral infections; their symptoms could be due to other unknown febrile illnesses. Category 1 corresponds to individuals positive for at least one of the five tested arbovirus and negative for malaria. Category 2 corresponds to individuals negative for tested arbovirus and positive for malaria. Category 3 represents individuals simultaneously positive for malaria and for at least one of the tested arbovirus. The subjects of category 3 are said “coinfected" with malaria and arbovirus.
In this study, arboviral cases are diagnosed by the detection of IgM. We considered that an individual was positive for arboviral infection if he/she was tested positive to IgM. Ignoring individuals with missing data, we obtained a data set of size n = 12288 (IgM data) which is summarized in Table 1. We can see that this data set is very unbalanced (3 arboviral or coinfected cases per 1000 patients) and will require a specific statistical analysis.
IgM data. A summary of the response variables.
| Arbovirus | Malaria | ||
|---|---|---|---|
| + | – | Total | |
| + | 18 (0.15%) | 21 (0.16%) | 39 (0.31%) |
| – | 7 069 (57.53%) | 5 180 (42.16%) | 12 305 (99.69%) |
| Total | 7 087 (57.68%) | 5 201 (42.32%) | 12 288 |
3 Statistical analysis of the coinfection influential factors
The objective of this section is to propose a methodology that can identify the important symptoms for the arbovirus diagnosis and can help making decision for arbovirus treatment in absence of laboratory confirmation.
Variable selection is appreciable in medical data analysis as the diagnosis of the disease could be done on a minimum number of clinical measures. Reducing the number of relevant covariates may also produce more accurate classification results. In a first step, we select relevant covariates that explain the disease status typically via a multinomial logistic model. The statistical analysis is challenging because of the small number of instances of the arboviral class (39) with respect to the total number of observations (12 288). The cases that are more important for the study are rare and few exist on the available training set. We face what is usually known as a problem of imbalanced data sets. To handle this problem, we proposed to randomly remove observations from the majority class to prevent its signal from dominating the fitting procedure. We applied to our imbalanced IgM data set a common undersampling technique to obtain a more balanced data distribution. As the data distribution is changed, it is expected that the fitted models are biased to the goals of the user and are more interpretable in terms of these goals.
In a second step we investigate the robustness of the variable selection using random forests. Introduced by Breiman [15], random forests (RF hereafter) are a robust nonparametric method to deal with classification problems. They require only mild conditions on the data generating model. They are also less sensitive to weaknesses in the data, because the randomized tree generation procedure ensures that all covariates are more equally evaluated. Moreover, RF decision trees often perform well on imbalanced data sets because ensemble methods offer ways to rebalance the distributions in varied ways. In this study, RF models have the advantage of providing a ranking of covariates using the RF score of variable importance that is a useful and effective tool to find important covariates for interpretation.
In a third step, we quantify the effects of the selected covariates using odds ratios. We compute odds ratios for one disease category relative to another one and we contrast the effects of the covariates on the disease category, arboviral monoinfection, malaria monoinfection and coinfection.
3.1 Multinomial logit model
We recall that Y is the response variable indicating the class of the disease: “Other febrile illnesses” (Y = 0), “arboviral monoinfection” (Y = 1), “malaria monoinfection” (Y = 2) and “coinfection” (Y = 3). Let
The multinomial logit model assumes the existence of β1, β2,
where
and x0 = 1 to include the intercept parameters βk0, k = 1, 2, 3. The reference modality is class 0.
Consequently, for each k = 1, 2, 3 and each vector of covariates x,
and
From the computation of the maximum likelihood estimates
3.2 Fitting strategy for handling imbalanced IgM data
The IgM data set contains 18 arboviral monoinfection cases, 21 coinfection cases, 5 180 other febrile illness cases and 7 069 malaria monoinfection cases. Trained on the original IgM data set, the fitted logit model only predicted classes 0 and 2, which means it ignores the two minority classes 1 and 3 in favour of the majority classes. Applying resampling strategies to obtain a more balanced data sample is an effective solution to the imbalance problem (see [16] for a survey of existing methods). Two of the most simple resampling approaches are undersampling and oversampling. Since the IgM is highly imbalanced with a large number of observations in the two majority classes, we used a random undersampling strategy that removes observations and reduces the sample size. We sampled without replacement 50 cases from each of the two majority classes to create a balanced sub-sample of size
Undersampling results in loss of information and the risk of removing relevant observations is present. To overcome this problem, we repeated the sampling step a thousand times and worked with 1 000 balanced sub-samples of the IgM data set. The multinomial model was fitted to each sub-sample and a stepwise covariate selection was performed (see Figure 5 in the supplementary material). The observed variability of the 1 000 covariate selections raised robustness questions. To answer this point, we conducted a nonparametric analysis based on the RF algorithm. In recent years, several methods involving the combination of resampling and ensemble learning have appeared in the imbalanced distributions literature ([16]). We found that the importance score based on random forests yielded a convenient way to summarize the information obtained from the 1 000 sub-samples.
3.3 Variable selection using random forests
A random forest is an ensemble of unpruned trees, induced from bootstrap samples of the training data, that uses random covariate selection in the tree construction process. Prediction is made by aggregating the predictions of the ensemble, using the majority vote rule.
One of the most widely used RF score of importance of a given variable is the Mean Decrease of Accuracy (MDA) in predictions. It is based on the out-of-bag (OOB) error. For each tree t of the forest, consider the associated OOBt sample (data not included in the bootstrap sample used to construct t). Denote by errOOBt the misclassification rate of tree t computed on this OOBt sample. Then, randomly permute the observed values of covariate Xj in OOBt to get a perturbed sample and compute
where ntree denotes the number of trees of the RF. The higher the MDA, the more important the variable is. Several variable selection procedures using RF are based on this quantification of variable importance.
Using R packages, we made the following implementation choices: randomForest for RF fitting and MDA calculation, VSURF for selecting the important variables. The main parameters of randomForest were calibrated and set to their default values, ntree=500 and mtry=
Figure 2 ranks the variable importances (MDA) of the 15 covariates across the 1 000 sub-samples. First, rainfall is the most important covariate; a second group of less important covariates is formed by cough, age and joint pain; then comes a group of five covariates: number of sick days, temperature, nausea or vomiting, eye pain and nasal congestion; finally, six unimportant covariates are displayed: muscle pain, chills, cephalalgia, jaudice, diarrhea and sex . The boundary between the two last groups is not clear and we used the VSURF procedure to separate the important covariates from the other ones. We can notice on the plot that both MDA level and variability are larger for relevant variables; as explained by [14], this is expected and the VSURF threshold value is based on MDA standard deviation estimation. Figure 3 summarizes the results of the VSURF selection procedure based on the 1 000 sub-samples. The covariate rainfall (95.2%) is almost always selected. Next, the more often selected variables are cough (29.1%), age (28.3%), joint pain (19.8%), nausea or vomiting (16.4%), number of sick days (16.1%), temperature (16.1%) and nasal congestion (11%), in decreasing order. The other covariates are selected in less than 10% of the samples.
We set different random seeds and we found that, for our purpose of selecting significant covariates, aggregation of 1 000 RF classifiers learned from 1 000 randomly balanced sub-samples yielded stable selected variable sets.
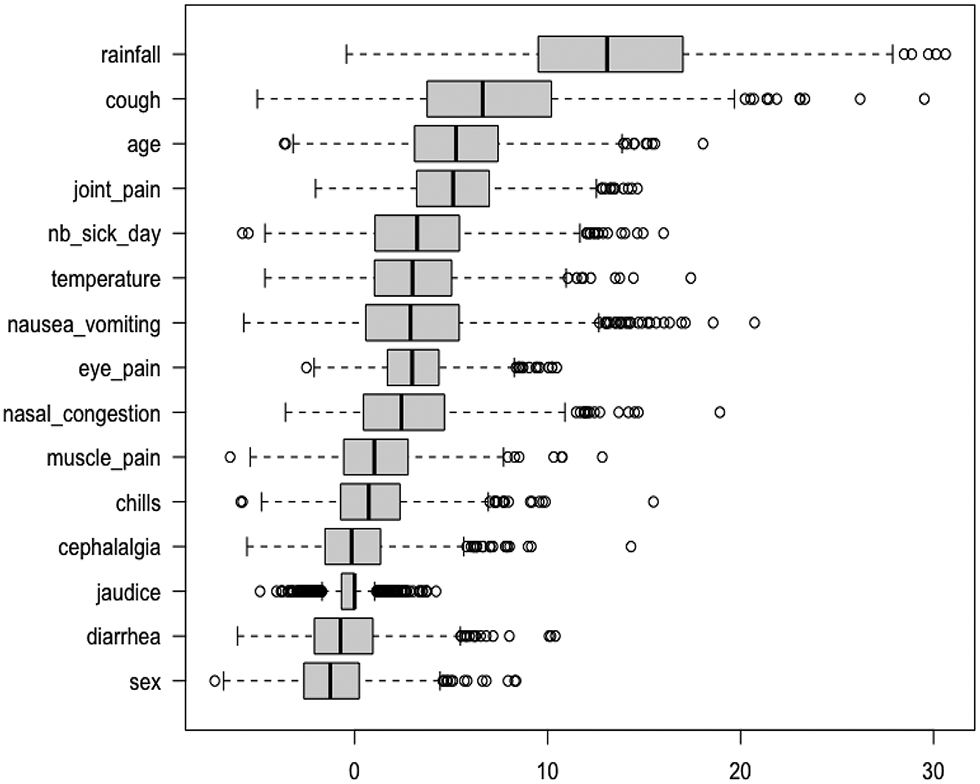
A variable importance plot for the IgM data set. Each boxplot summarizes the distribution of the variable importance among 1000 IgM sub-samples.
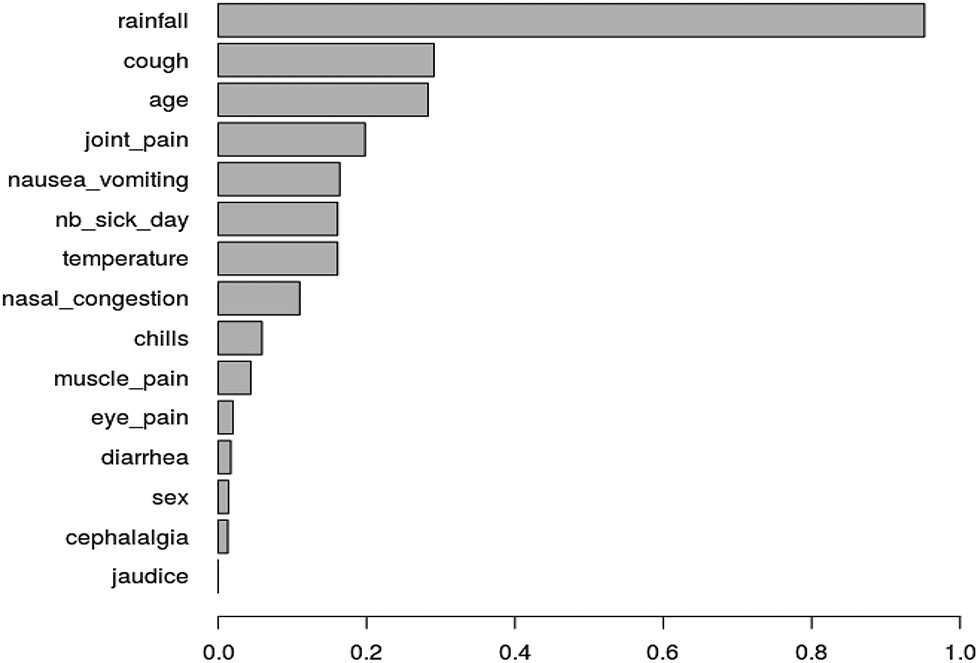
Ranking by VSURF: for each variable, the length of the bar corresponds to the empirical probability to be selected by VSURF among 1000 IgM sub-samples.
3.4 Influence of selected covariates on disease status
In the previous sections, the RF variable importance results on the IgM sub-samples produced a robust ranking of the covariates. From these results, we decided to fit multinomial model with eight covariates (age, temperature, number of sick days, rainfall, nausea or vomiting, cough, nasal congestion and joint pain) to the data set of our analysis and to further quantify the effects of the covariates in this model.
Within the multinomial logit model, we can quantify the effect of a variable in terms of an odds ratio or its logarithm. The odds that Y = k occurs for an individual with covariates X = x is the ratio of
Thus the multinomial logit model is a linear regression model in the log odds. The parameter component βkj can be interpreted as the change in the log odds per unit change in the continuous covariate Xj, if all other covariates are held constant. The odds ratio (OR) of category k for a d units increase of Xj, all other covariates remaining constant, is defined as
Once β is estimated, one can estimate any odds or odds ratios. An OR equal to one means that a change in covariate Xj has no effect on the odds of category k; if ORk(d) > 1 (ORk(d) < 1), the effect of an increase of Xj is to increase (decrease) the odds of category k. The risk ratio
For each covariate, we computed the odds ratios ORk, k = 1, 2, 3 and their confidence intervals for each disease. Figure 4 display the OR by which the odds increases for a certain change in a covariate, holding all other covariates constant. The ORs associated with binary variables (nausea/vomiting, cough, nasal congestion and joint pain) were computed by comparing the two modalities: 0 for absence and 1 for presence of the symptom. We computed the ORs resulting from increasing temperature from 38 to 40 degrees Celsius (d = 2) and from increasing Number of sick days from 2 to 6 days (d = 4). The outer quartiles of Age are 8 and 28 years (d = 20), so we computed the half-sample OR for age. Similarly, we computed the half-sample OR for a rainfall of 14 mm compared to a rainfall of 370 mm (d = 356).
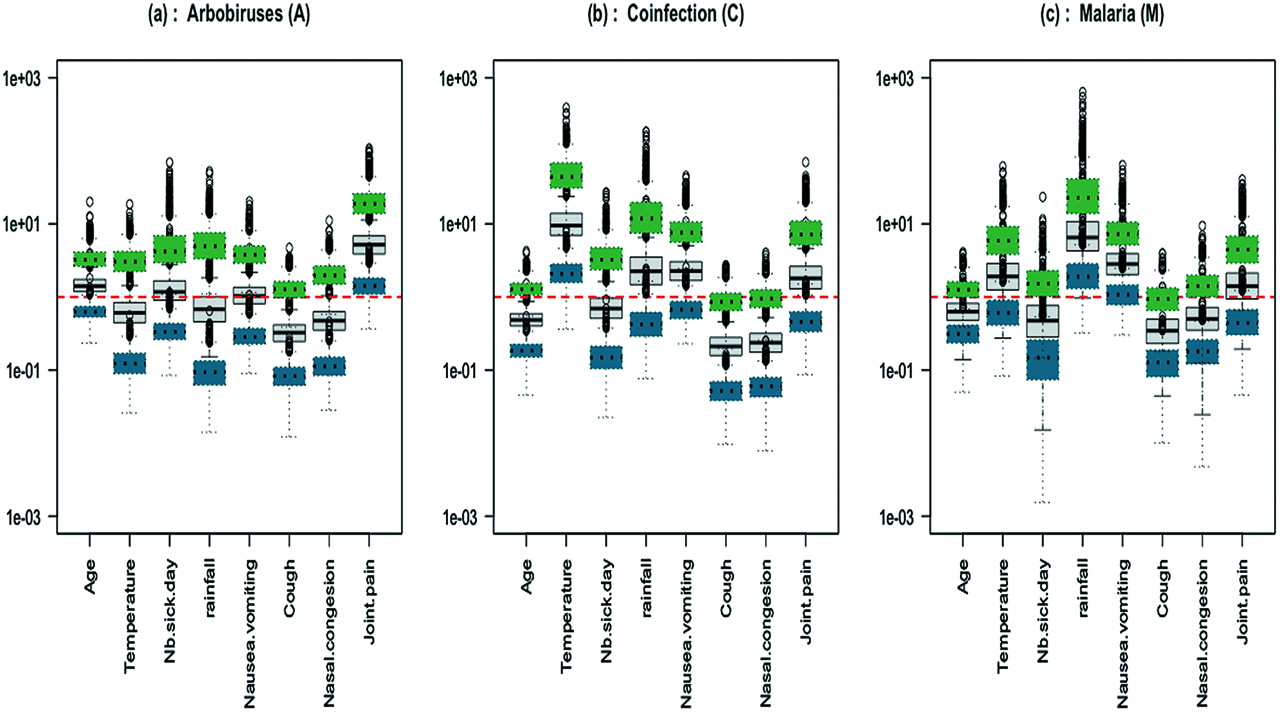
IgM data: boxplots of 1000 odds ratios with respect to the reference category (grey full line boxplot); boxplots of the associated confidence intervals are shown in dotted line (green for upper and blue for lower bound); (a) Arbovirus (b) Coinfection (c) Malaria.
The ORs defined previously are relative to the reference category Y = 0. We also computed the ORs between two diseases Y = k and Y = l in order to differentiate the effect of each covariable between the three clinical groups, arbovirus vs malaria, coinfection vs arbovirus and coinfection vs malaria (Figure 5):
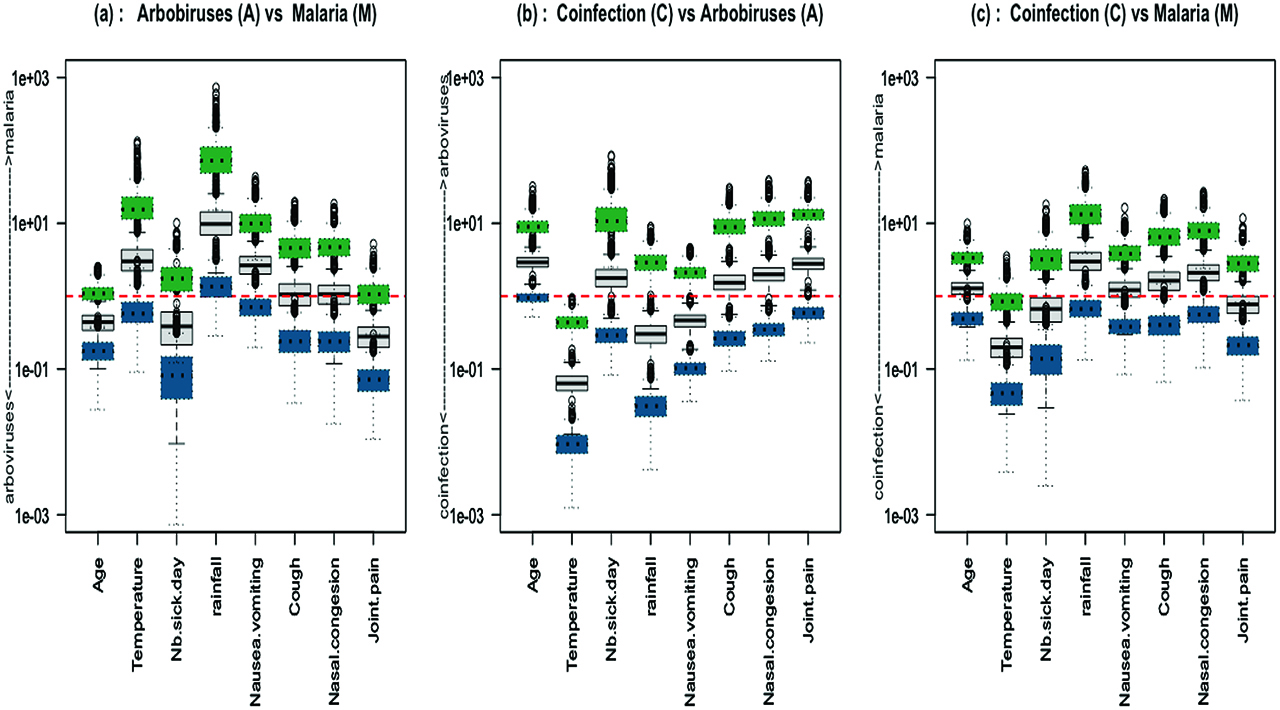
IgM data: boxplots of 1000 odds ratios between two categories (grey full line boxplot); boxplots of the associated confidence intervals are shown in dotted line (green for upper and blue for lower bound); (a) Arbovirus vs Malaria (b) Coinfection vs Arbovirus (c) Coinfection vs Malaria.
The confidence intervals are derived from the fitted multinomial logit model and their accuracy is based on the parametric assumption that the true data generating distribution does fall in the model.
Figure 4 and Figure 5 display the sampling distribution of ORs based on the fitting of the 1000 sub-samples of the IgM data set. According to Figure 4, we can say that rainfall and vomiting symptoms are hightly correlated with malaria monoinfections whereas joint pain is correlated with arboviral monoinfections. The odds of coinfection increases with high fever. It corroborates the conclusion of the paper Sow et al. [13]. Figure 5(a), (b) and (c) can be interpreted in the same way. They show that a high temperature and the presence of nausea or vomiting symptoms are mostly indicative of malaria parasite infections whereas an increase of age and of number of sick days are indicative of arboviral infections. The effects of nasal congestion and joint pain symptoms on the disease status are not clear enough to be interpreted. The main question of the study was to identify risk factors that can help doctors to diagnose a concurrent malaria and arbovirus infection. From these results, temperature is the only risk factor that differentiates between coinfection and single infections.
4 Predictive analysis
In this section we propose a methodology to discriminate arbovirus positive and arbovirus negative cases among coinfected patients.
4.1 Testing independence between arbovirus and malaria
In the multinomial model given by (1) in Section 3.1, we can test the independence between arboviral and malaria infections.
The joint statistical distribution of arboviral infection (
which is equivalent to
for all
The Wald statistic to test H0 against its two-sided alternative is computed as
with
Joint distribution of arboviral infection and malaria infection.
| A = 0 | A = 1 | Law of M | |
|---|---|---|---|
| M = 0 | π0 | π1 | |
| M = 1 | π2 | π3 | |
| Law of A | 1 |
4.2 Diagnosis of arboviral disease
In absence of rapid arbovirus detection tests, the aim is to provide a decision support tool to determine if an arbovirus could be responsible for the clinical symptoms of the patient coinfection. We propose to base the diagnosis on the conditional probability to be coinfected
In the previous section, it is shown that we can test the independence hypothesis between malaria and arboviral infections. If this test is rejected, then we can derive the probability q to be coinfected given that malaria infection is observed. This probability can be computed in function of the πk probabilities estimated from the multinomial logit model. For X = x,
This probability can be used to differentiate whether the illness to be treated should be arbovirus or malaria. We propose a binary classification rule and we predict an arbovirus illness if the estimated coinfection probability is greater than a threshold value γ:
The evaluation of the classification is based on the confusion matrix and the overall classification accuracy. The confusion matrix is used to compute true arbovirus positives (TP), false arbovirus positives (FP), true negatives (TN) and false negatives (FN). A global performance measure is the miss-classification rate (MCR) defined as:
with
Our analysis is based on a real-life medical data set. In the original IgM data set, arbovirus positive individuals are identified as individuals likely to be in the early stages of arbovirus illness. It is the relevant data set for the classification problem. However, the positive cases constitute only a very small minority class of the data (39 positive cases over 12288 individuals). Based on these data, the computation of the independence test is very sensitive to the fluctuations of the sub-sampling procedure and the classification procedure could not be implemented. Instead, we propose a simulation study based on a balanced data set to illustrate our classification procedure.
4.3 Simulation study
Simulated data. Taking advantage of the previous influencing factors analysis (Section 3.4), we simulated data using a multinomial model similar to the one previously estimated. The eigth covariates were generated from distributions similar to those observed in the real data set. The beta parameters values are given by Table 7 in supplementary material. They were chosen according to the conclusions of the statistical analysis of the influential factors. The larger values emphasize the influence of the associated covariates that are positively correlated to each disease category. For example, the parameter value associated with the number of sick days covariate is larger for the arbovirus category than for the malaria category. Based on this generative model, we computed the probabilities of belonging to each category and generated the Y response to be the modality with the greatest probability. We used this procedure to simulate a data set of size n = 5000 which is summarized in Table 6 and Table 8 in the supplementary material.
Independence between abovirus and malaria. We fitted the multinomial model to the simulated data and tested the independence between malaria and arbovirus. We obtained that the independence hypothesis was rejected with a p-value equal to 1.13 × 10 – 4. Then we derived the probability to be coinfected given that malaria infection is observed and performed the classification procedure.
Diagnosis of arboviral disease. We randomly divided the simulated data set into two part, a training data set of size 3333 and a test data set of size 1667. The classification was applied only to individuals infected with malaria parasites, namely 1925 individuals in the training data set and 626 individuals in the test set. We computed the five-fold cross-validation estimator of the MCR and we chose the classification threshold value γ as the minimizer of the MCR. We can see on Figure 6 that the optimal value of this threshold is γ = 0.45. Five-fold cross-validation was run several times and the optimal value of γ was found to be quite stable. Based on this γ value, we performed the classification to predict the type of illness that has affected the patient. Predicted and actual arbovirus cases were compared using the test set, as presented in Table 3. The rows of the matrix are actual classes and the columns are the predicted classes. We observe that the corresponding test MCR is 7.83%. The ROC curve of the classification is presented in Figure 7 of the supplementary material. Based on the simulated data set, the accuracy of the classification is quite good (92.17%). This suggests that this predictive analysis can be medically valuable to identify arboviral cases among coinfection cases.
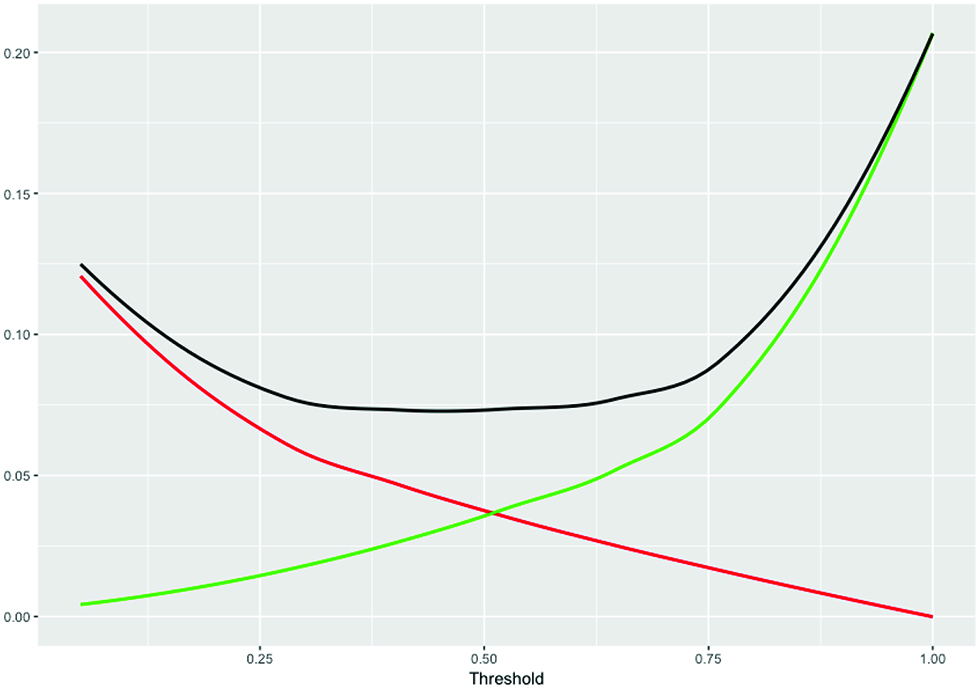
Cross-validation miss-classification rate. The MCR is shown in black as full line. Increasing γ increases the number of FN (green line) and decreases the FP (red line).
Confusion table with γ = 0.45. Each row represents the instances in the actual class and each colum represents the instances in the predicted class. Class 0 for malaria monoinfection and class 1 for coinfection.
| Actual | Predicted | |
|---|---|---|
| 0 | 1 | |
| 0 | 421 | 29 |
| 1 | 20 | 156 |
5 Conclusion
Misdiagnosis of arbovirus coinfections as malaria infections may increase the spread of arbovirus diseases in areas where fast diagnostic assays are not available. This study proposes an appropriate statistical methodology that can assist doctors in the elaboration of the differential diagnosis of febrile cases for arboviruses.
To analyze coinfection data we propose a methodology with three steps: 1. a variable selection with random forests; 2. an analysis of the influent factors through multinomial model fitting and odd ratios computation; 3. a predictive analysis based on coinfection probabilities. From our experiments, we can say that the random forests algorithm is a robust method to select the important variables for the different diseases. The analysis of the odd ratios allows to identify the risk factors that characterize each disease. We observed that higher values of number of sick days and of age are mostly indicative of arboviral disease while higher values of temperature and presence of nausea or vomiting symptoms during the rainy season are mostly indicative of malaria disease. The results also pointed out that a high-grade fever could be considered as a differential diagnostic for malaria and arbovirus coinfection, which is in agreement with the study of [13]. The proposed predictive analysis was illustrated on a simulated data set. We show that using data with enough signal, we can identify coinfected patients to be treated for arbovirus with great accuracy. A future study will apply this methodology to coinfection data between viral and bacterial infections collected in Senegal by Institut Pasteur de Dakar from 2015 to 2017.
Acknowledgement
The authors thank two referees for detailed and helpful comments that greatly improved the manuscript.
References
[1] Mohapatra MK, Patra P, Agrawala RK. Manifestation and outcome of concurrent malaria and dengue infection. J Vector Borne Dis. 2012;49:262–5.10.4103/0972-9062.213508Suche in Google Scholar
[2] Mushtaq M, Qadri M, Rashid A. Concurrent infection with dengue and malaria: an unusual presentation. Hindawi Publishing cooporation Case report in Medecine. 2013;2013:2.10.1155/2013/520181Suche in Google Scholar PubMed PubMed Central
[3] Ali N, Nadeem A, Anwar M, Tariq WU, Chotani RA. Dengue fever in malaria endemic areas. J College Physicians and Surgeons–Pakistan: JCPSP. 2006;16:340–2.Suche in Google Scholar
[4] Arya CS, Mehta LK, Agarwal N, Bharat KA, Mathai G, Moondhara A.. Episodes of concurrent dengue and malaria. Dengue Bull. 2005;29:208–9Suche in Google Scholar
[5] Carme B, Matheus S, Donutil G, Raulin O, Nacher M, Morvan J. Concurent dengue and malaria in cayenne hospital, french guiana. Emerg Infections Dis. 2009;15:668–71.10.3201/eid1504.080891Suche in Google Scholar PubMed PubMed Central
[6] Charrel RN, Brouqui P, Foucault C, De Lamballerie X. Concurrent dengue and malaria. Emerg Infections Dis. 2005;11:1153–4.10.3201/eid1107.041352Suche in Google Scholar PubMed PubMed Central
[7] Deresinski S. Concurrent plasmodium vivax malaria and dengue. Emerg Infectious Dis. 2006;12:1802.10.3201/eid1211.060341Suche in Google Scholar PubMed PubMed Central
[8] Mendonça VR, Andrade BB, Souza LC, Magalhães BM, Mourão MP, Lacerda MV, et al. Unravelling the patterns of host immune responses in plasmodium vivax malaria and dengue co-infection. 2015;14:315.10.1186/s12936-015-0835-8Suche in Google Scholar PubMed PubMed Central
[9] Senn N, Suarkia D, Manong D, Siba PM, Mcbride WJ. Contribution of dengue fever to the burden of acute febrile illnesses in papua new guinea: an age-specific prospective study. Am J Trop Med Hyg. 2011;85:132–7.10.4269/ajtmh.2011.10-0482Suche in Google Scholar PubMed PubMed Central
[10] Baba M, Logue CH, Oderinde B, Abdulmaleek H, Williams J, Lewis J, et al. Evidence of arbovirus co-infection in suspected febrile malaria and typhoid patients in nigeria. J Infect Developing Countries. 2013;7:51–9.10.3855/jidc.2411Suche in Google Scholar PubMed
[11] ANSD. Programme national de lutte contre le paludisme au Senegal, 2009.Suche in Google Scholar
[12] Thiam S, Thior M, Faye B, Ndiop M, Diouf ML, Diouf MB, et al. Major reduction in anti-malarial drug consumption in senegal after nation-wide introduction of malaria rapid diagnostic tests. PloS One. 2011;6:1–7.10.1371/journal.pone.0018419Suche in Google Scholar PubMed PubMed Central
[13] Sow A, Loucoubar C, Diallo D, Faye O, Ndiaye Y, Senghor CS, et al. Concurrent malaria and arbovirus infections in kedougou, southeastern senegal. Malar J. 2016;15:47.10.1186/s12936-016-1100-5Suche in Google Scholar PubMed PubMed Central
[14] Genuer R, Poggi J-M, Tuleau-Malot C. Variable selection using random forests. Pattern Recognit Lett. 2010;31:2225–36.10.1016/j.patrec.2010.03.014Suche in Google Scholar
[15] Breiman L. Random forest. Mach Learn. 2001;45:5–32.10.1023/A:1010933404324Suche in Google Scholar
[16] Branco P, Torgo L, Ribeiro RP. A survey of predictive modeling on imbalanced domains. ACM Comput Surv (CSUR). 2016;49:31:1–31:50.10.1145/2907070Suche in Google Scholar
[17] Genuer R, Poggi J-M, Tuleau-Malot C. Vsurf: an r package for variable selection using random forests. The R J. 2015;7:19–33.10.32614/RJ-2015-018Suche in Google Scholar
Supplementary Material
The online version of this article offers supplementary material (DOI:https://doi.org/10.1515/ijb-2017-0015).
© 2019 Walter de Gruyter GmbH, Berlin/Boston
Artikel in diesem Heft
- Editorial
- Biostatistics in Africa 2019: A Special Issue of The International Journal of Biostatistics
- Research Articles
- A Truncation Model for Estimating Species Richness
- Double Robust Efficient Estimators of Longitudinal Treatment Effects: Comparative Performance in Simulations and a Case Study
- Simulation Extrapolation Method for Cox Regression Model with a Mixture of Berkson and Classical Errors in the Covariates using Calibration Data
- Multinomial Logistic Model for Coinfection Diagnosis Between Arbovirus and Malaria in Kedougou
- Second Order Segmented Polynomials for Syphilis and Gonorrhea Prevalence and Incidence Trends Estimation: Application to Spectrum’s Guinea-Bissau and South Africa Data
- Computationally Stable Estimation Procedure for the Multivariate Linear Mixed-Effect Model and Application to Malaria Public Health Problem
- Bayesian Nonparametrics and Biostatistics: The Case of PET Imaging
- A Law of Large Numbers in the Supremum Norm for a Multiscale Stochastic Spatial Gene Network
- Review
- Unfolding the Genome: The Case Study of P. falciparum
Artikel in diesem Heft
- Editorial
- Biostatistics in Africa 2019: A Special Issue of The International Journal of Biostatistics
- Research Articles
- A Truncation Model for Estimating Species Richness
- Double Robust Efficient Estimators of Longitudinal Treatment Effects: Comparative Performance in Simulations and a Case Study
- Simulation Extrapolation Method for Cox Regression Model with a Mixture of Berkson and Classical Errors in the Covariates using Calibration Data
- Multinomial Logistic Model for Coinfection Diagnosis Between Arbovirus and Malaria in Kedougou
- Second Order Segmented Polynomials for Syphilis and Gonorrhea Prevalence and Incidence Trends Estimation: Application to Spectrum’s Guinea-Bissau and South Africa Data
- Computationally Stable Estimation Procedure for the Multivariate Linear Mixed-Effect Model and Application to Malaria Public Health Problem
- Bayesian Nonparametrics and Biostatistics: The Case of PET Imaging
- A Law of Large Numbers in the Supremum Norm for a Multiscale Stochastic Spatial Gene Network
- Review
- Unfolding the Genome: The Case Study of P. falciparum