A nonparametric test for comparing survival functions based on restricted distance correlation
-
Qingyang Zhang


Abstract
In this article, we propose an omnibus test for comparing two survival functions under non-proportional hazards. The test statistic is based on a product-limit estimate of the restricted distance correlation, which is closely related to the
1 Introduction
To evaluate the treatment effect for survival data, we often need to compare the survival functions of the treatment and control groups. The most popular approach to comparing survival functions is the log-rank test, and it is well known that under proportional hazards, the log-rank test is optimal and equivalent to the score test in Cox regression model. When the proportional hazard assumption is moderately or severely violated, however, the log-rank test might be suboptimal. In many clinical studies, especially cancer immunotherapy trials [1,19,24], the violation of proportional hazards assumption is often encountered, and different patterns of non-proportional hazards are frequently observed, e.g., delayed treatment effect, diminishing effect, and crossing survival curves, making the traditional log-rank test underpowered. One way to address this challenge is using the weighted log-rank test, and a popular weight function is the Fleming-Harrington (FH) weight with parameters
where
where
In addition to the maxCombo test, there are many other omnibus tests developed for survival data. To name a few, Fleming et al. generalized the Kolmogorov-Smirnov (KS) test for arbitrarily right-censored data [8]. Koziol et al. and Schumacher modified the Crámer-von Mises (CVM) test under the assumption of randomly censoring [12,20]. All these KS- or CVM-based methods can be viewed as a weighted
In this study, we shall develop a new omnibus test for comparing survival functions. The test statistic is based on a restricted version of distance correlation and related to the unweighted
The remainder of this study is structured as follows: Section 2 introduces the notion of restricted distance correlation, and proposes a consistent estimator. Section 3 evaluates the performance of the new and existing tests under different non-proportional hazards settings. Section 4 discusses the method with some future perspectives.
2 Restricted distance correlation test
In this section, we introduce the restricted distance correlation test for survival data and establish its statistical consistency. We begin with the notations. For subject
It is noteworthy that testing (1) amounts to testing the independence between the survival time
where
One remarkable property of distance correlation is that it is 0 if and only if
where
As a special case of (3), in the following, we give the explicit formula of squared distance correlation between the survival time
Noteworthily, the squared distance covariance between
For clinical trials with survival endpoints, an administrative censoring is often applied at the end of the study period so that no event can be observed after time
The null and alternative hypotheses based on the restricted distance correlation can be formulated as:
Under the restriction of total study duration, the null hypothesis in (6) can be interpreted as the independence between
Assuming independent censoring, i.e.,
Theorem 1 establishes the statistical consistency of (7), under mild regularity conditions (proof is given in Appendix A.2).
Theorem 1
Assuming independent censoring,
In general, the null distribution of distance correlation is impractical to derive as it depends on the underlying distributions of
Though the formula for
which is a
3 Two extensions of the proposed test
A limitation of the restricted distance correlation test is that it is only for two-sided alternatives, therefore not suitable for superiority tests that can be formulated as:
To this end, we also suggest a directional test by incorporating the sign information in
where
Second, as suggested by the reviewers, we extend the proposed distance correlation test to the Gaussian kernel, which can be equivalently used in the distance correlation formulation [6,10,22]. We derived the distance covariance between
where
The expected distances
4 Simulation study
In this section, we conduct simulation studies to evaluate the performance of the restricted distance correlation test under different settings. In particular, we investigate the empirical statistical power and type I error rate under both two-sided and one-sided settings.
4.1 Two-sided alternatives
We compare the distance correlation tests (based on Euclidean distance and Gaussian kernel, respectively) with five existing tests, namely, (1) the robust maxCombo test, (2) two-stage test, (3) KS test, (4) CVM test, and (5) log-rank test. The log-rank test is used as a gold standard for proportional hazard, and it was implemented using R function survdiff in the survival package. The robust maxCombo test was implemented using the logrank.maxtest function in the nph package. The two-stage test by Qiu and Sheng [16] was implemented by the two-stage function in the TSHRC package. For KS, CVM, and our restricted distance correlation tests,
In the simulation, we set
where
Proportional hazards:
Delayed treatment effect:
Crossing survival curves:
Diminishing effect:

Survival curves in the simulation study (a: proportional hazards, b: delayed treatment effect, c: crossing survival curves, and d: diminishing effect), where red represents the control arm and blue represents the treatment arm.
Figure 2 summarizes the empirical power over 5,000 simulations at the significance level of 0.05. The two distance correlation metrics perform comparably across all settings, with the Gaussian kernel performing slightly better than Euclidean distance. For example, in the proportional hazard setting with a sample size of 100, the test based on Euclidean distance achieves a power of 39%, while the test based on the Gaussian kernel achieves a power of 41%. In the proportional hazards setting, the log-rank test has the highest power. The distance correlation tests are the best among all omnibus tests, and when
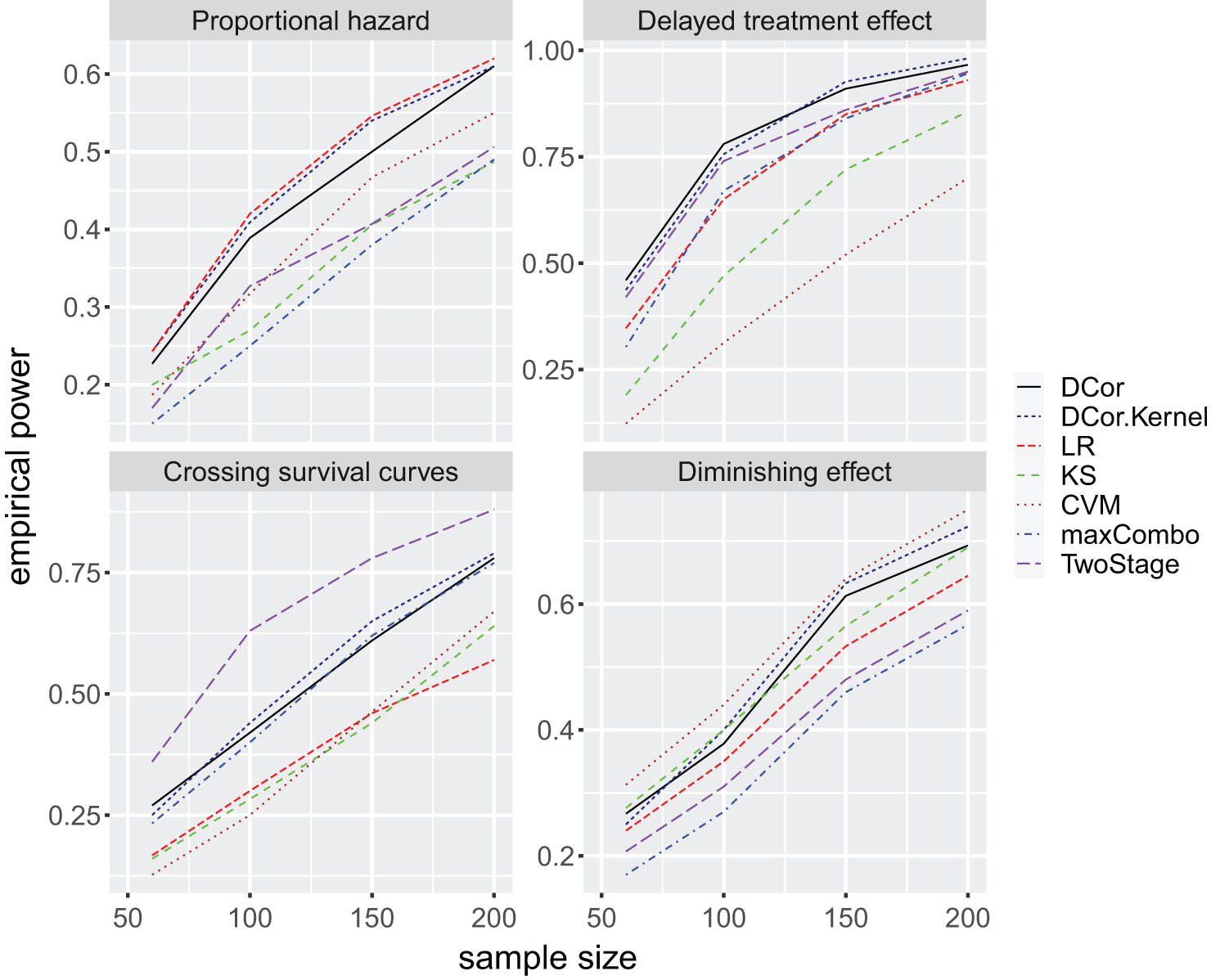
Empirical power over 5,000 simulations for two-sided alternatives.
We also investigated the type I error rate control under different sample sizes. Figure 3 presents the type I error rate over 10,000 simulations (under the null model

Type I error rate over 10,000 simulations for two-sided alternatives.
4.2 One-sided alternatives
For one-sided alternatives, we compare our directional distance correlation test (equations (11) and (12)) with (1) log-rank test, (2) RMST test, and (3) the robust maxCombo, under the same simulation settings as detailed in Section 3.1. The two-stage, CVM, and KS tests are excluded in the analysis because they are not suitable for one-sided alternatives. Figure 4 displays the empirical power over 5,000 simulations at the significance level of 0.05. Same as what we observed in the two-sided case, in the proportional hazards setting, the log-rank test has the highest statistical power. Our distance correlation test has similar power to RMST, both higher than maxCombo. In the delayed treatment effect setting, the RMST and distance correlation tests substantially outperform the log-rank and maxCombo tests. Specifically, the maxCombo test is the most powerful test for detecting differences between crossing survival curves (Setting C). In the diminishing effect setting, the distance correlation test has the greatest power, slightly higher than the log-rank test. Overall, our distance correlation test have satisfactory power across different settings. Figure 5 summarizes the empirical sizes of the four tests, where it can be seen that all four tests control the type I error rate, and three RMST tests are slightly conservative.

Empirical power over 5,000 simulations for one-sided alternatives.

Type I error rate over 10,000 simulations for one-sided alternatives.
5 Discussion and conclusions
In recent clinical studies, especially in cancer immunotherapy studies, the violation of the proportional hazards assumption is often encountered; thus, the traditional log-rank test may not be optimal. In this work, we propose a simple and versatile test to compare survival curves under non-proportional hazards. The test statistic is derived from a restricted version of the widely used distance correlation metric, which is essentially the
One major limitation of the proposed test is the lack of an analytical formula for computing

Power comparison for the permutation test and chi-squared test.
Another practical limitation is the assumption of independent censoring, meaning that the censoring time is independent of both groups and survival time. When the censoring depends on groups, the permutation test may have an inflated type I error rate; even, the survival curves are equal. To illustrate this, we performed simulations (Figure 7) and found that the type I error rate inflation is non-negligible when there is a substantial difference in the censoring rate between two arms. Therefore, it is important to check whether the two arms have similar censoring distributions before using a distance correlation test. Possible approaches for estimating censoring distributions or censoring rates include the reverse KM curve and the person-time follow-up rate [25].

Type I error rate inflation under different censoring rates in two arms (the
There are several possible extensions of our test. Throughout this study, for illustrative purposes, we have focused on the two-sample comparison. However, our method can be readily applied to compare multiple survival functions. In the
where
In addition to right-censored data, our test might also be applicable to other censoring types. For instance, when the data are left-censored, one may utilize the Left-KM (LeftKM) method to estimate the survival functions in the distance correlation. Under independent censoring, Gomez et al. [9] proved the consistency of the LeftKM estimator, and we may use this result to establish the statistical consistency of the restricted distance correlation test.
Acknowledgement
The author would like to thank the editor and two reviewers for their valuable suggestions and remarks.
-
Funding information: The work was supported by an NSF DBI Biology Integration Institute (BII) Grant (Award No. 2119968; PI-Ceballos).
-
Conflict of interest: The author states that there is no conflict of interest.
A.1 Derivation of equation (4)
The squared distance covariance between
where
the following results can be shown using elementary probability:
Furthermore, we can show
Summarizing the aforementioned results, we have
It is also straightforward to show
Finally, by Theorem 5.1 of Edelmann et al. [4], we have
where
A.2 Proof of Theorem 1
By Yu and Li [27], for any
and
As
By equations (A4) and (A5),
Next, we show the almost sure convergence of the denominator, i.e.,
Similar to the proof for
Again by equations (A4) and (A5),
To show the almost sure convergence of
This completes the proof.
A.3 Derivation for the Gaussian kernel
Let
The squared distance covariance based on
where
When
References
[1] A study of idasanutlin with cytarabine versus cytarabine plus placebo in participants with relapsed or refractory acute myeloid leukemia. https://clinicaltrials.gov/ct2/show/NCT02545283. Search in Google Scholar
[2] Crámer, H. (1928). On the composition of elementary errors. Skand Aktuar, 11, 141–180. 10.1080/03461238.1928.10416872Search in Google Scholar
[3] Ditzhaus, M. Genuneit, J., Janssen, A. & Pauly, M. (2021). CASANOVA: Permutation inference in factorial survival designs. Biometrics, 79, 203–215. 10.1111/biom.13575Search in Google Scholar PubMed
[4] Edelmann, D., Richards, D., & Vogel, D. (2020). The distance standard deviation. Annals of Statistics, 48(6), 3395–3416. 10.1214/19-AOS1935Search in Google Scholar
[5] Edelmann, D., Welchowski, T., & Benner, A. (2022). A consistent version of distance covariance for right-censored survival data and its application in hypothesis testing. Biometrics, 78, 867–879.10.1111/biom.13470Search in Google Scholar PubMed
[6] Edelmann, D., & Goeman, J. (2022). A Regression Perspective on Generalized Distance Covariance and the Hilbert-Schmidt Independence Criterion. Statistical Science, 37(4), 562–579. 10.1214/21-STS841Search in Google Scholar
[7] Fernandez, T., Gretton, A., Rindt, D., & Sejdinovic, D. (2023). A Kernel log-rank test of independence for right-censored data. Journal of the American Statistical Association, 118, 542, 925–936.10.1080/01621459.2021.1961784Search in Google Scholar
[8] Fleming, T. R., O‘Fallon, J., & O‘Brien, P. (1980). Modified Kolmogorov-Smirnov test procedure with application to arbitrarily right-censored data. Biometrics, 36(4), 607–625.10.2307/2556114Search in Google Scholar
[9] Gomez Julia, O., Utzet, F., & Moeschberger, M. (1992). Survival analysis for left censored data. Survival Analysis: State of the Art. Springer, (pp 269–288). 10.1007/978-94-015-7983-4_16Search in Google Scholar
[10] Gretton, A. Herbrich, R., Smola, A., Bousquet, O., & Scholkopf, B. (2005). Kernel methods for measuring independence. Journal of Machine Learning Research, 6, 2075–2129. Search in Google Scholar
[11] Kim, J. S. (1991). Piecewise exponential estimator of the survivor function. IEEE Transactions on Reliability, 40(2), 134–2794. 10.1109/24.87112Search in Google Scholar
[12] Koziol, J. A. (1978). A two sample Cramer-von Mises test for randomly censored data. Biometrical Journal, 20(6), 603–60810.1002/bimj.4710200608Search in Google Scholar
[13] Lee, S. H. (2007). On the versatility of the combination of the weighted log-rank statistics. Computational Statistics and Data Analysis, 51(12), 6557–6564. 10.1016/j.csda.2007.03.006Search in Google Scholar
[14] Lin, R. S. Lin, J., Roychoudhury, S., Anderson, K., Hu, T., & Huang, B. (2020). Alternative analysis methods for time to event endpoints under nonproportional hazards: A comparative analysis. Statistics in Biopharmaceutical Research, 12(2), 187–198.10.1080/19466315.2019.1697738Search in Google Scholar
[15] Panda, S., Shen, C., Perry, R., Zorn, J., Lutz, A., & Priebe, C. (2023). High-dimensional and universally consistent k-sample tests. https://arxiv.org/abs/1910.08883. Search in Google Scholar
[16] Qiu, P. & Sheng, J. (2008). A two-stage procedure for comparing hazard rate functions. Journal of Royal Statistical Society - Series B, 70(1), 191–208.10.1111/j.1467-9868.2007.00622.xSearch in Google Scholar
[17] Rizzo, M. L., & Székely, G. J. (2016). Energy distance. WIREs Computational Statistics, 8, 27–38. 10.1002/wics.1375Search in Google Scholar
[18] Roychoudhury, S., Anderson, K., Ye, J., & Mukhopadhyay, P., (2023). Robust Design and Analysis of Clinical Trials With Nonproportional Hazards: A Straw Man Guidance From a Cross-Pharma Working Group. Statistics in Biopharmaceutical Research, 15(2), 280–294.10.1080/19466315.2021.1874507Search in Google Scholar
[19] Rufibach, K., Heinzmann, D., & Monnet, A. (2020). Integrating phase 2 into phase 3 based on an intermediate endpoint while accounting for a cure proportion-With an application to the design of a clinical trial in acute myeloid leukemia. Pharmaceutical Statistics, 19, 44–58. 10.1002/pst.1969Search in Google Scholar PubMed
[20] Schumacher, M. (1984). Two-sample tests of Cramer-von Mises and Kolmogorov-Smirnov type for randomly censored data. International Statistical Review, 52(3), 263–281.10.2307/1403046Search in Google Scholar
[21] Shen, C., Panda, S., & Vogelstein, J. (2021). The Chi-square test of distance correlation. Journal of Computational and Graphical Statistics, 31(1), 254–262.10.1080/10618600.2021.1938585Search in Google Scholar PubMed PubMed Central
[22] Shen, C., & Vogelstein, J. T. (2005). The exact equivalence of distance and kernel methods in hypothesis Testing. AStA Advances in Statistical Analysis, 105(3), 385–403. 10.1007/s10182-020-00378-1Search in Google Scholar
[23] Székely, G., Rizzo, M., & Bakirov, N., (2007). Measuring and testing dependence by correlation of distances. Annals of Statistics, 35(6), 2769–2794.10.1214/009053607000000505Search in Google Scholar
[24] Wolchok, J. D. (2017). Overall survival with combined nivolumab and iplimumab in advanced melanoma. New England Journal of Medicine, 377, 1345–1356.10.1056/NEJMoa1709684Search in Google Scholar PubMed PubMed Central
[25] Xue, X., Agalliu, I., Kim, M., Wang, T., Lin, J., & Ghavamian, R. (2017). New methods for estimating follow-up rates in cohort studies. BMC Medical Research Methodology, 17, 155. 10.1186/s12874-017-0436-zSearch in Google Scholar PubMed PubMed Central
[26] Yang, S. & Prentice, R. (2010). Improved logrank-type tests for survival data using adaptive weights. Biometrics, 66(1), 30–38.10.1111/j.1541-0420.2009.01243.xSearch in Google Scholar PubMed PubMed Central
[27] Yu, Q. & Li, L. (1994). On the strong uniform consistency of the product limit estimator. Sankhyaaa A, 56(3), 416–430. Search in Google Scholar
[28] Zhang, J., Liu, Y., & Cui, H. (2021). Model-free feature screening via distance correlation for ultrahigh dimensional survival data. Statistical Papers, 62, 2711–2738.10.1007/s00362-020-01210-3Search in Google Scholar
© 2023 the author(s), published by De Gruyter
This work is licensed under the Creative Commons Attribution 4.0 International License.
Articles in the same Issue
- Research Articles
- Joint lifetime modeling with matrix distributions
- Consistency of mixture models with a prior on the number of components
- Mutual volatility transmission between assets and trading places
- Functions operating on several multivariate distribution functions
- An optimal transport-based characterization of convex order
- Test of bivariate independence based on angular probability integral transform with emphasis on circular-circular and circular-linear data
- A link between Kendall’s τ, the length measure and the surface of bivariate copulas, and a consequence to copulas with self-similar support
- Review Article
- Testing for explosive bubbles: a review
- Interview
- When copulas and smoothing met: An interview with Irène Gijbels
- Special Issue on 10 years of Dependence Modeling
- On copulas with a trapezoid support
- Characterization of pre-idempotent Copulas
- Abel-Gontcharoff polynomials, parking trajectories and ruin probabilities
- A nonparametric test for comparing survival functions based on restricted distance correlation
- Constructing models for spherical and elliptical densities
Articles in the same Issue
- Research Articles
- Joint lifetime modeling with matrix distributions
- Consistency of mixture models with a prior on the number of components
- Mutual volatility transmission between assets and trading places
- Functions operating on several multivariate distribution functions
- An optimal transport-based characterization of convex order
- Test of bivariate independence based on angular probability integral transform with emphasis on circular-circular and circular-linear data
- A link between Kendall’s τ, the length measure and the surface of bivariate copulas, and a consequence to copulas with self-similar support
- Review Article
- Testing for explosive bubbles: a review
- Interview
- When copulas and smoothing met: An interview with Irène Gijbels
- Special Issue on 10 years of Dependence Modeling
- On copulas with a trapezoid support
- Characterization of pre-idempotent Copulas
- Abel-Gontcharoff polynomials, parking trajectories and ruin probabilities
- A nonparametric test for comparing survival functions based on restricted distance correlation
- Constructing models for spherical and elliptical densities