Investigating syntactic complexity and language-related error patterns in EFL students’ writing: corpus-based and epistemic network analyses
-
Nang Kham Thi

 ,
De Van Vo
and
Marianne Nikolov
,
De Van Vo
and
Marianne Nikolov

Abstract
Students’ writing proficiency is measured through holistic and analytical ratings in writing assessment; however, recent studies suggest that measurement of syntactic complexity in second language writing research has become an effective measure of writing proficiency. Within this paradigm, we investigated how automated measurement of syntactic complexity helped distinguish the writing proficiency of students from two Higher Education institutions. In addition, we also examined language-related errors in students’ writing to further indicate the differences in the error patterns of the two groups. Data was drawn from a corpus of 1,391 sentences, comprising 58 texts produced by first-year undergraduate students from Myanmar and Hungary. Automated tools were used to measure the syntactic complexity of students’ writing. We performed a corpus-based analysis, focusing on syntactic complexity, while language-related error patterns in writing were investigated through an epistemic network approach. Findings suggested that the Myanmar students tended to write longer essays comprising simpler sentences, whereas the Hungarian students preferred shorter texts with more complex sentences. Most complexity measures were also found to distinguish the texts produced by the two groups: length of production units, sentence complexity, and subordination indices. An examination of the language-related error patterns revealed statistically significant differences in the error patterns in student writing: errors were found to be more prevalent in Myanmar students’ essays. Implications for enhancing teaching L2 writing in educational contexts are discussed.
1 Introduction
Across 21st century competency frameworks around the world, most researchers, employers, and policy makers stress the need for competencies in communication, collaboration, ICT-related competencies, and social and/or cultural skills (Voogt and Roblin 2012). As a result of globalization, it is necessary to acquire multicultural social interaction and communication skills, in which competency in a foreign language has been emphasized and proficiency in academic writing plays a key role (Binkley et al. 2012). Furthermore, since English is the global lingua franca, enhancing second language (L2) learners’ English writing skills is one of the core objectives in foreign language courses around the world.
To the best of our knowledge, learners’ L2 writing performance is influenced by a number of individual and contextual factors including their L2 proficiency level, first language, previous writing experiences, how L2 writing is learnt, and other socio-cultural norms and expectations. For example, cultural background was supposed to be a key factor influencing writing in a second language (e.g., Atkinson 1999; Atkinson and Ramanathan 1995; Myles 2002; Uysal 2008) and studies investigating whether writers from shared cultural backgrounds display typical writing patterns in their texts indicated shared preferences in rhetorical patterns in terms of organization, macro-level rhetorical patterns, coherence, and use of transition devices. Moreover, as writing is consciously learnt in a certain way in one culture, the cultural-specific nature of schemata is very likely to influence when students write in a second language. Myles (2002) noted that during writing under pressure, L2 writers rely on rhetorical norms from their first language for synthesis of meaning. However, this does not necessarily mean that those who know how to write a summary in their first language will also be able to summarize well in English, as they have varying proficiency levels and writing experience.
In promoting learners’ academic writing performance, it is of great importance to understand their background proficiency levels. In the case of learning academic writing in English, the use of a variety of sentence structures with embedded clauses and specialized vocabulary are the main demands in developing learner proficiency. Biber et al. (2011) and Schleppegrell (2001) stated that syntactic constructions in academic writing are more complex and highly specialized compared to those in everyday language. Therefore, assessing the range and varied use of grammatical structures (i.e., syntactic complexity) has been included as a major assessment criterion in evaluating learners’ writing proficiency.
As an alternative to holistic and analytical rating assessment, measuring syntactic complexity of student writing through automated tools has become a promising way to assess learners’ writing proficiency. To this end, this study investigated the syntactic complexity in the writing of first-year undergraduate EFL students from two Higher Education institutions in Hungary and Myanmar. Moreover, we examined the language-related error patterns (grammar, usage, vocabulary, and mechanics) in students’ writing to better understand the role of errors in L2 writing proficiency.
2 Theoretical background
2.1 Syntactic complexity and writing proficiency
The role of syntactic complexity in academic writing is obvious as it has been one of the important measures of L2 writing proficiency in the past decades. As Wolfe-Quintero et al. (1998) suggested, syntactic complexity is defined not in terms of how many production units (e.g., clauses, T-units, or sentences) are present in writing, but in terms of how varied and sophisticated these production units are. Major purposes of using syntactic complexity measures in L2 writing research include evaluating the effects of a pedagogical intervention on the development of grammar, writing ability; investigating task-related variations in L2 writing; and assessing differences in L2 texts written by learners across proficiency levels and over time (for a review, see Crossley 2020; Ortega 2003).
The relationship between syntactic complexity and language proficiency has been examined extensively (Lu 2011; Ortega 2003; Wolfe-Quintero et al. 1998). Research on L2 writing suggests that, despite differences among studies, indices of complexity increase as students become more proficient in the target language (Barrot and Agdeppa 2021; Crossley 2020; Lu 2010, 2011; Ortega 2003; Wolfe-Quintero et al. 1998). In other words, they tend to produce more complex syntactic structures in longer and more varied sentences. Barrot and Agdeppa (2021) revealed that an interaction exists between language proficiency and syntactic complexity measures such as length of production unit indices, degree of phrasal sophistication indices, and weighted clause ratio. Other studies have been conducted to examine changes in learners’ syntactic complexity over time (e.g., (Barrot and Gabinete 2021; Bulté and Housen 2014; Yoon and Polio 2017) and have reported developments characterized by the measures of syntactic complexity. Bulté and Housen (2014), for example, found a significant increase in the length of linguistic units at all levels of syntactic organization (e.g., phrase, clause, sentence, and T-unit) over the course of a semester-long academic English language programme. Overall, these empirical studies have suggested that syntactic complexity is an objective index of L2 writing proficiency.
At a syntactic level, complexity has been operationalized through indices that measure the construct at the phrase, clause, or sentence level, such as the length of phrases, clauses, T-units, and sentences. In a research synthesis of college-level L2 writing, Ortega (2003) found that three measures tapping length of production (mean length of sentence, mean length of T-unit, mean length of clause), one measure reflecting the amount of coordination (mean number of T-units per sentence), and two gauging the amount of subordination (mean number of clauses per T-unit and mean number of dependent clauses per clause) were the most frequently used syntactic complexity measures in the literature.
Recognizing syntactic complexity as a multidimensional construct comprising different dimensions (Norris and Ortega 2009), in this study we used two computational tools, Coh-Metrix (McNamara et al. 2014) and L2SCA (Lu 2010), to analyze the writing samples in our dataset. We included three indices of syntactic complexity from Coh-Metrix: syntax similarity, left embeddedness (number of words before main verb), and number of modifiers per noun clause. Additionally, we employed the full set of 14 indices from L2SCA. Each index measures one of the 5 dimensions of syntactic complexity: length of production unit, amount of subordination, amount of coordination, degree of phrasal sophistication, and overall sentence complexity (for details, see Lu 2010). The selection of these indices was not only motivated by how these measures incorporated the early L2 syntactic complexity measures reviewed by Wolfe-Quintero et al. (1998) but also advised by the findings of previous studies that examined syntactic complexity in L2 writing (e.g., Crossley et al. 2010; Lu 2010; Maamuujav et al. 2021; Yoon and Polio 2017). For example, sentence length and sentence variety were found to be significant predictors of writing quality (Lu 2010) and texts that contain more nouns (e.g., complex noun phrase constituents and complex phrases) and phrasal complexity were also found to be typical in academic writing (Biber et al. 2011; Crossley and Mcnamara 2014).
2.2 Studies of language-related errors in L2 writing
Despite the relative difficulty in assessing students’ academic writing proficiency, the ability to use grammar accurately is regarded as a crucial element in the assessment criteria applied by L2 writing instructors (Romano 2019). Furthermore, linguistic accuracy contributes to clarity and idea development in writing which in turn helps students attain high scores in task fulfillment. Therefore, writing accuracy in L2 writing is considered essential to the evaluation of students’ academic writing proficiency and learning success, especially in tertiary education (Biber et al. 2011; Mazgutova and Kormos 2015).
For the purpose of improving writing instruction, previous studies have analyzed students’ errors in L2 writing, targeting a wide variety of errors such as errors in word forms, verb forms, subject-verb agreement, articles, word choice, noun plurals, and sentence structure (e.g., Dahlmeier et al. 2013; Olsen 1999; Phuket and Othman 2015; Zheng and Park 2013). Olsen (1999), for example, studied the written texts of Norwegian EFL learners and found a relationship between the students’ language proficiency and their errors in writing: less proficient learners have a higher number of grammatical, orthographical, and syntactical errors. Moreover, other studies (Dahlmeier et al. 2013; Phuket and Othman 2015) targeted the errors found in university undergraduate students’ writing. For example, Dahlmeier et al. (2013) took a corpus-based approach and analyzed undergraduate university students’ errors in the NUS Corpus of Learner English (NUCLE). The authors found that wrong collocations/idioms/prepositions, local redundancies, articles or determiners, noun numbers, and mechanics were the top five error categories. Similarly, another study by Phuket and Othman (2015) analyzed the narrative essays composed by Thai university students and found the most frequent types of errors including translated words from Thai, word choice, verb tense, preposition, and comma.
What emerges from these studies is that accuracy is one of the main criteria in evaluating the performance of L2 writers and that understanding their errors in writing inform writing instruction and materials development in EFL academic settings.
3 Present study
3.1 Research contexts
Though Myanmar was once a British colony, English was regarded as a foreign language in school settings. After independence in 1948, English ceased to be the official language and lost its importance in schools and colleges (Allott 1985). However, it regained its power in 1981 when English was taught as a compulsory subject in the first grade in all primary schools and re-introduced as a medium of instruction for the science stream and economics in secondary schools and post-secondary education starting in 1986 (Kyu 1993). In recent years, learning English has become in demand not only to supplement the compulsory English subject in schools but also to offer more opportunities to study or work abroad (Tin 2014). In Higher Education, English is a compulsory subject in all disciplines in undergraduate courses and taught as a specialized subject in English literature, linguistics, and language teaching courses.
In Hungary, the knowledge of foreign languages is important in order to communicate with the neighboring countries since Hungarian belongs to the Finno-Ugric family of languages, whereas its neighboring countries use Indo-European languages. Though German and English have been the two dominant foreign languages to be learnt in the Hungarian educational system since the fall of Soviet occupation, students’ interests in learning English have increased due to its status of the lingua franca of science, business, and Higher Education (Nikolov and Csapó 2010).
Although differences are present in the two contexts relating to educational, cultural, and sociolinguistic characteristics, it is undeniable that L2 learners across formal learning contexts (e.g., learning English at the university level) have a common goal of studying English for academic purposes. Particularly, comprehension and production of English for academic purposes require not only communicative but also strategic and pragmatic competence, and the culturally appropriate use of English. It is against this backdrop that the current study aims to investigate the syntactic complexity of EFL undergraduate students from two countries and examine their language-related errors in writing.
3.2 Research questions
We studied the written texts of Myanmar and Hungarian university students, analyzed the texts with reference to syntactic complexity measures, and compared the language-related error patterns in their writing. Thus, the following three research questions guided our study:
What textual characteristics do the Myanmar and Hungarian EFL students’ essays exhibit?
To what extent do syntactic complexity measures differentiate the essays produced by the students from the two countries?
To what extent are there differences in the language-related error patterns in the essays produced by the students from the two countries?
4 Methods
4.1 Participants
Two classes of first-year undergraduate English majors: 30 students (19 females and 11 males) from a Myanmar university and 28 students (15 females and 13 males) from a Hungarian university were recruited in the first and second semester of 2020/2021 Academic Year. The Myanmar students were native speakers of Burmese and those from the other sample were Hungarian native speakers. They were of typical university age, ranging from 17 to 18 years (Myanmar) and from 18 to 19 years (Hungary). The students’ English proficiency level was defined by the programme level. At the time of the study, both groups were enrolled in university undergraduate studies which required them to have intermediate (B1–B2) levels according to the CEFR (Common European Framework of Reference for Languages) scale. The students voluntarily participated and were informed that their written texts were anonymously analyzed for research purposes.
4.2 Instruments
As shown in Figure 1, we used the following proficiency essay practice writing tasks (i.e., four-paragraph guided essays without separate introduction and conclusion paragraphs). The essays entailed four guided prompts to elicit responses (giving a narrative account of personal experiences or sharing views on a proposed statement). Though the writing topics were different, they were supposed to elicit free constructed responses (Norris and Ortega 2000), allowing the students to produce language with relatively few constraints and with meaningful communication as the goal for L2 production. When responding to the writing tasks, they were required to write an essay in 300–400 words using one of the essay options.

Topics of the writing tasks.
4.3 Data analysis
Two software packages (Coh-Metrix and L2SCA) were used to extract 17 features to cover the multidimensional nature of the syntactic complexity construct. Statistical analyses were carried out, using the R statistical program. To answer RQ1, descriptive statistics of the textual features of the students’ essays (e.g., essay length, paragraph length, and sentence length) were compared. Furthermore, independent samples t-tests were used to compute for the difference between the sentence length of the essays produced by the two groups. As for RQ2, we first exported the essays into Coh-Metrix and L2SCA to automate the syntactic complexity measures. We then conducted independent samples t-tests on 17 measures of syntactic complexity to examine the differences in the essays produced by the two groups.
To address RQ3 regarding the language-related error patterns of the students, we probed into the discourse networks of each country using an ENA analysis, which is an analytical method to describe individual (group) cognitive framework patterns through a quantitative analysis of discourse data. It is used to identify meaningful and quantifiable patterns in discourse or reasoning. ENA moves beyond the traditional frequency-based assessments by examining the structure of the co-occurrence or connections in coded data. It can be used to compare units of analysis in terms of their plotted point positions, individual networks, mean plotted point positions, and mean networks, which average the connection weights across individual networks. Networks may also be compared by using network difference graphs which are calculated by subtracting the weight of each connection in one network from the corresponding connections in another (for details, see Shaffer et al. 2016).
For the purpose of performing the ENA analysis, many steps were taken. First, we collected the corrective feedback points (i.e., errors) on the students’ essays marked by the class teachers. We then separated and coded each sentence into a record line and coded the frequency of errors marked on each essay. Finally, adapting the error typology of Dikli and Bleyle (2014), we classified the coded errors into four categories: grammar (subject-verb agreement, pronoun, verb form, verb tense, run-ons, sentence structure, and omission of object), usage (article, noun ending, preposition, word form, idiom, adverb, and conjunction), lexical (word choice and collocation), and mechanical (punctuation, spelling, and capitalization) errors (see Appendix). Table 1 provides a sample excerpt from an actual coded file serving for the ENA analysis.
Excerpt of a coded file containing language-related errors in the Myanmar students’ essays.
| Metadata columns | Code columns | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Stanza column | Unit column | |||||||||
| Line | Student | Country | G.verbForm | G.structure | U.Adverb | U.conjunction | M.punctuation | M.spelling | L.wordChoice | L.collocation |
|
|
||||||||||
| 15 | E30 | Myanmar | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 1 |
| 22 | E30 | Myanmar | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 0 |
| 10 | E31 | Myanmar | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 |
| 4 | E34 | Myanmar | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 |
| 13 | E14 | Myanmar | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 |
| 2 | E20 | Myanmar | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 |
| 6 | E20 | Myanmar | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
| 13 | E22 | Myanmar | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 |
| 17 | E22 | Myanmar | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 12 | E26 | Myanmar | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 |
5 Results
5.1 What textual characteristics do the Myanmar and Hungarian EFL students’ essays exhibit?
Our first research question concerned the textual characteristics of the Myanmar and Hungarian EFL students’ essays. Descriptive statistics indicated that the texts were of varying length with simple and complex sentences. Table 2 presents the average numbers of paragraphs, sentences, and words in the 58 essays. Particularly at the paragraph level, the Myanmar group tended to produce longer paragraphs (M = 101.77, SD = 24.38) in comparison to those written by their Hungarian counterparts (M = 97.61, SD = 13.08). Further differences were found at the sentence level: the students from Myanmar attempted to generate more than 27 sentences, whereas the Hungarian students wrote around 20 sentences in their essays. Also at word level, the students from the Myanmar group tended to produce more words in comparison to their Hungarian peers although the writing tasks required them to write between 300 and 400 words.
Descriptive statistics: paragraph, sentence, and word counts.
| Country | Paragraph count | Sentence count | Word count | Paragraph length | Sentence length | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Mean | SD | Mean | SD | Mean | SD | Mean | SD | Mean | SD | |
| Myanmar | 4.10 | 0.31 | 27.20 | 7.37 | 417.27 | 97.53 | 101.77 | 24.38 | 15.34 | 7.10 |
| Hungary | 4.07 | 0.26 | 20.54 | 3.94 | 397.39 | 52.09 | 97.61 | 13.08 | 19.14 | 7.79 |
Moreover, we found a statistically significant difference in the sentence length in the essays produced by Myanmar (M = 15.34, SD = 7.10) and Hungarian students (MM = 19.15, SD = 7.97), t = 9.31, df = 1,154.6, p < 0.001. Figure 2 demonstrates the distribution of sentence length in the two groups. Overall, the Hungarian students seemed to generate both shorter and longer sentences, ranging from 8 to 24 words in a sentence, whilst their Myanmar peers used a smaller range of words (8–16) in a sentence. Students in the Hungarian cohort applied more diverse sentences: 69.22 % complex sentences and 30.78 % simple ones, compared to those in the other group who used fewer complex sentences (43.50 %) and more simple sentences (56.50 %) in their essays.
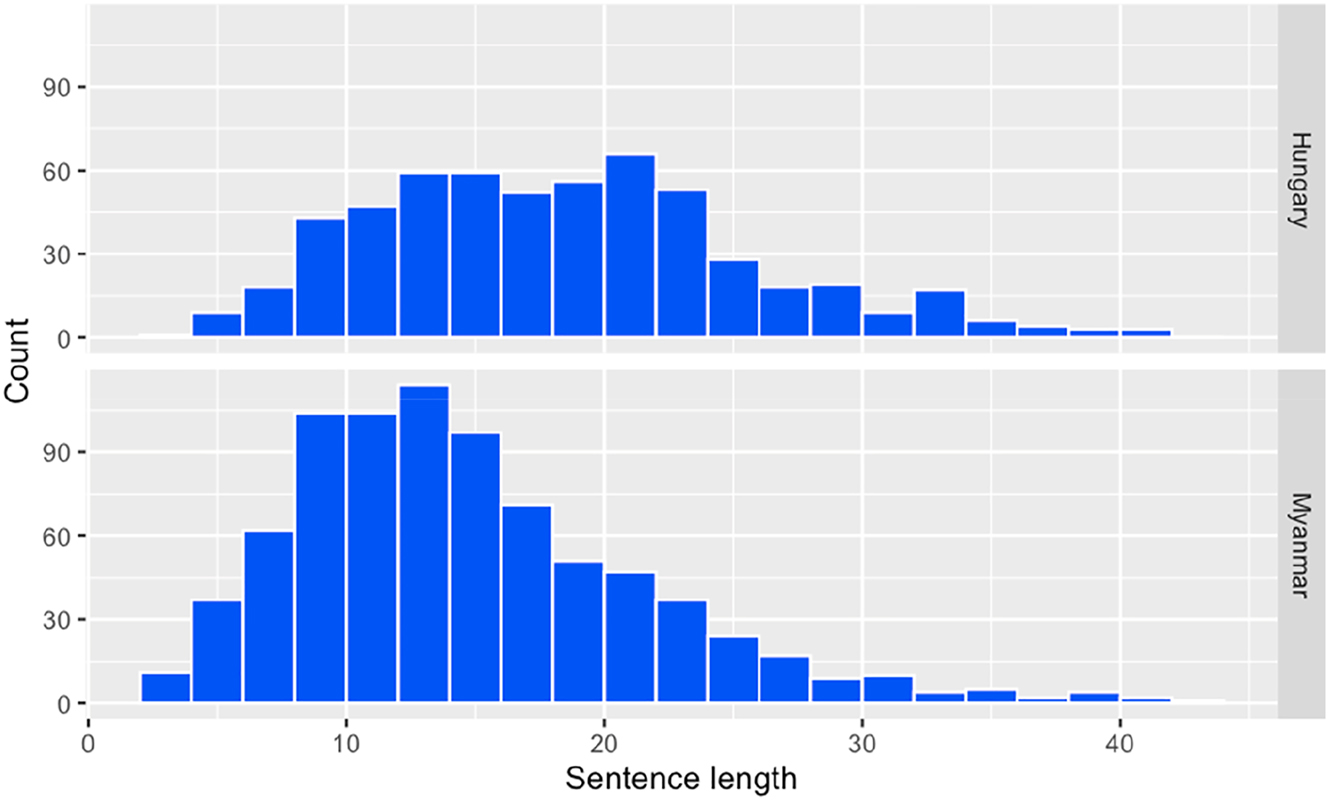
Distribution of sentence length (words) in the students’ essays.
5.2 To what extent do syntactic complexity measures differentiate the essays produced by the students from the two countries?
Detailed information regarding the syntactic complexity measures identified in the essays is summarized in Tables 3 and 4. Overall, the findings from the two syntactic complexity analyzers consistently demonstrated that most complexity indices were found to distinguish the essays produced by the two groups, indicating that the essays produced by the Hungarian students had greater syntactic complexity in comparison to those of the Myanmar cohort.
Results of independent samples t-tests of three syntactic complexity measures computed by Coh-Metrix.
| Syntactic complexity measures | Index code | Myanmar | Hungary | Independent samples t-test | |||
|---|---|---|---|---|---|---|---|
| Mean | SD | Mean | SD | t | p | ||
| Sentence syntax similarity | SYNSTRUTt | 0.12 | 0.03 | 0.08 | 0.02 | −5.16 | <0.001 |
| Left embeddedness, words before main verb | SYNLE | 3.43 | 1.01 | 4.15 | 0.99 | 2.78 | 0.007 |
| Number of modifiers per noun phrase | SYNNP | 0.67 | 0.16 | 0.63 | 0.09 | −1.17 | 0.245 |
-
Index code is a typical code presented in Coh-Metrix program. The bold values identify p less than 0.05.
Results of independent samples t-tests of 14 syntactic complexity measures computed by L2SCA.
| Syntactic complexity measures | Index code | Myanmar | Hungary | Independent samples t-test | Note | |||
|---|---|---|---|---|---|---|---|---|
| Mean | SD | Mean | SD | t | p | |||
| Length of production unit | MLC | 8.67 | 1.87 | 8.38 | 1.07 | −0.72 | 0.470 | Mean length of clause |
| MLS | 15.17 | 3.28 | 19.72 | 3.26 | 5.20 | <0.001 | Mean length of sentence | |
| MLT | 13.69 | 2.74 | 15.14 | 2.62 | 2.02 | 0.040 | Mean length of T-unit | |
| Sentence complexity | C/S | 1.77 | 0.34 | 2.37 | 0.37 | 6.19 | <0.001 | Sentence complexity ratio |
| Coordination | CP/C | 0.23 | 0.12 | 0.17 | 0.09 | −2.19 | 0.030 | Coordinate phrases per clause |
| CP/T | 0.36 | 0.17 | 0.31 | 0.16 | −1.22 | 0.230 | Coordinate phrases per T-unit | |
| T/S | 1.11 | 0.13 | 1.31 | 0.17 | 5.01 | <0.001 | Sentence coordination ratio | |
| Subordination | C/T | 1.59 | 0.19 | 1.81 | 0.23 | 3.80 | <0.001 | T-unit complexity ratio |
| CT/T | 0.43 | 0.11 | 0.57 | 0.11 | 4.67 | <0.001 | Complex T-unit ratio | |
| DC/C | 0.35 | 0.08 | 0.40 | 0.07 | 2.69 | 0.009 | Dependent clause ratio | |
| DC/T | 0.57 | 0.19 | 0.74 | 0.19 | 3.22 | 0.002 | Dependent clauses per T-unit | |
| Particular structures | CN/C | 0.93 | 0.41 | 0.75 | 0.23 | −2.06 | 0.040 | Complex nominals per clause |
| CN/T | 1.45 | 0.59 | 1.36 | 0.49 | −0.62 | 0.530 | Complex nominals per T-unit | |
| VP/T | 2.00 | 0.29 | 2.32 | 0.38 | 3.42 | 0.001 | Verb phrases per T-unit | |
-
Index code is a typical code presented in L2SCA program. The bold values identify p less than 0.05.
As for the indices calculated by Coh-Metrix, significant differences across the two groups were found in two indices: sentence syntax similarity and left embeddedness (number of words before main verb), but not in the number of modifiers per noun phrase. Particularly, the mean scores of sentence similarity across paragraphs (SYNSTRUTt) in the Myanmar group (M = 0.12, SD = 0.03) were higher than those in the Hungarian cohort (M = 0.08, SD = 0.02). In other words, the sentences in the Myanmar students’ essays revealed more uniform syntactic constructions with less complex syntax that is easier for the reader to process, whereas the sentences in the Hungarian students’ essays were less similar in terms of syntactic structures, resulting in structurally diverse sentences.
To tap the phrase-level complexity, two indices (SYNLE and SYNNP) from Coh-Metrix were employed. The SYNLE index calculates the mean number of words before the main verb with the understanding that more words before the main verb leads to a more complex syntactic structure (Crossley and McNamara 2012). The other index considered the mean number of modifiers per noun phrase with the understanding that noun phrases with more modifiers were supposed to be more complex in syntactic constructions. Based on the independent samples t-test, the mean scores of SYNLE index in the Myanmar students’ essays (M = 3.43, SD = 1.01) were substantially lower than those of the Hungarian students’ essays (M = 4.15, SD = 0.99). In other words, the essays generated by the Hungarian students depicted more complex syntactic structures in comparison to those of their Myanmar counterparts.
In connection with 14 indices computed by L2SCA, the independent samples t-tests indicated significant differences in the two groups (Table 4). Particularly, the two measures of the length of production units: MLS and MLT differentiated the two groups, as the mean scores of the mean sentence length and T-unit were significantly higher in the essays of the Hungarian students, compared to the other group. However, MLC did not separate the proficiency levels, resulting in no statistically significant differences across the two groups.
Likewise, a similar trend was found in the sentence complexity index; independent samples t-tests revealed significant differences across the two groups, favoring the texts of the Hungarian students. However, no significant differences were found across the two groups in terms of the coordination indices except for T/S. All subordination indices related to syntactic complexity indicated significant differences between the two student groups, and thus these indices were supposed to be the clearest separators in differentiating the students’ written texts. For example, when the means of the clauses per T-unit in the two groups were compared, it was found that the Hungarian students’ texts had relatively more clauses per T-units (M = 1.81, SD = 0.23) than the other group (M = 1.59, SD = 0.19). Similar patterns were found in the other subordination indices, favoring the texts written by the Hungarian students.
Clearly, there was a major difference in the amount of subordination at paragraph level when the comparison was made between the two sample paragraphs of the student writing (Extracts 1 and 2) and in the amount of subordination indices of each paragraph analyzed by L2SCA (Figure 3).

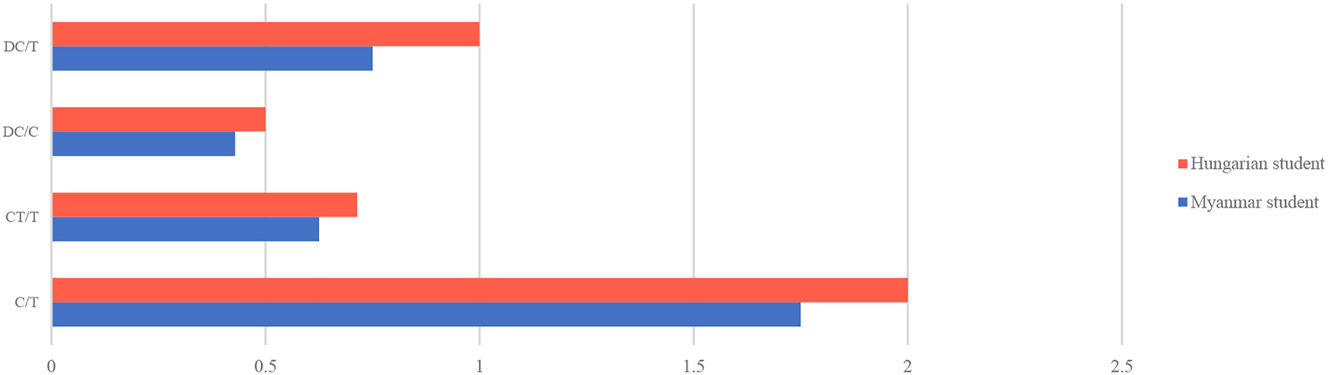
Comparison of the amount of subordination indices of the two paragraphs (Extracts 1 and 2) produced by Hungarian and Myanmar students.
Compared to other measures of syntactic complexity, two features of phrasal sophistication (complex nominals per clause and complex nominals per T-unit) were not able to differentiate the two groups, meaning that these indices discriminated poorly between the two groups of students in the study. In contrast, significant differences were found in verb phrases per T-unit, indicating that the Hungarian students tended to include more verb phrases per T-unit (M = 2.32, SD = 0.38) than the other group (M = 2.00, SD = 0.29).
5.3 To what extent are there differences in the language-related error patterns in the essays produced by the students from the two countries?
Figure 4 demonstrates the frequencies of language-related errors in the essays produced by the two groups. The overall results suggest that errors were more prevalent in the Myanmar cohort regardless of error type. The most frequent errors found in both groups included those in punctuation, word choice, and noun endings though these errors doubled in the texts of the Myanmar students. Punctuation errors were found to be common in both groups, but the Myanmar students had a higher error frequency.
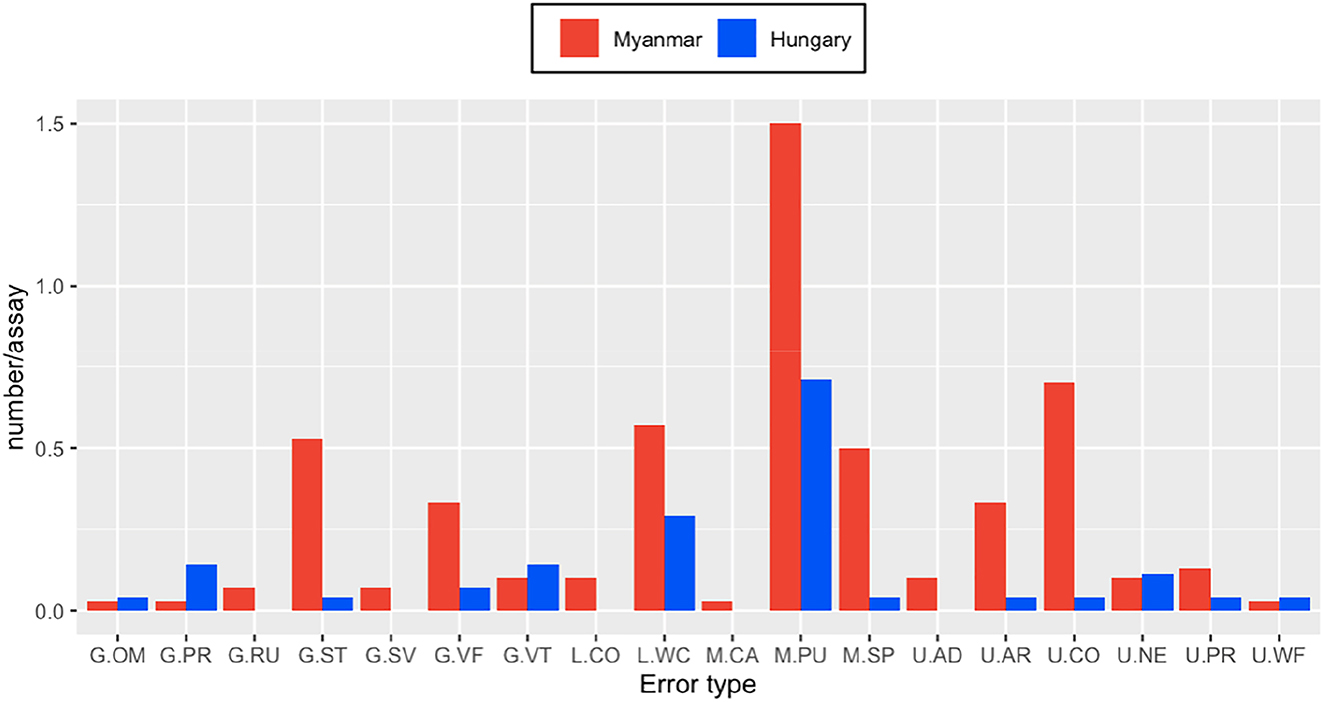
Frequency of language-related errors in the essays produced by Myanmar and Hungarian students. G.OM, Omission of object; G.PR, pronoun; G.RU, run-on; G.ST, structure; G.SV, subject-verb agreement; G.VF, verb form; G.VT, verb tense; L.CO, collocation; L.WC, word choice; M.CA, capitalization; M.PU, punctuation; M.SP, spelling; U.AD, adverb; U.AR, article; U.CO, conjunction; U.NE, noun ending; U.PR, preposition; U.WF, word form.
When examining each error category, the results revealed that the Myanmar students had more grammar errors relating to sentence structure and verb form, whereas these errors did not occur frequently in the texts generated by the Hungarian students. Likewise, usage errors were more dominant in the Myanmar students’ texts (article, conjunction, and preposition errors) as well as lexical and mechanical errors except for capitalization errors.
To further investigate the error patterns in the written texts of the two groups, we conducted the ENA analysis with definition of the units of analysis as all lines of data associated with a single value of country subsetted by a student. For example, one unit consisted of all the lines associated with each student. Our ENA model included the following codes: G.svAgreement, G.pronoun, G.verbForm, G.verbTense, G.runOn, G.structure, G.OmissedObject, U.articles, U.nounEnding, U.preposition, U.wordForm, U.Idiom, U.Adverb, U.conjunction, M.punctuation, M.spelling, M.capitalization, L.wordChoice and L.collocation. In the study, conversations (or stanzas, see Table 1) were defined as all lines of written data produced by a student in his or her essay (Shaffer et al. 2016). The resulting networks were aggregated for all the lines for each unit of analysis in the model. We aggregated networks using a binary summation, in which the networks were visualized using network graphs where nodes correspond to the codes, and edges reflect the relative frequency of co-occurrence or connection between two codes. The result was two coordinated representations for each unit of analysis: (1) a plotted point, which represents the location of that unit’s network in the low-dimensional projected space and (2) a weighted network graph.
Figure 5 demonstrates a sample pattern in the network model presenting the frequency of error occurrence and connections among language-related errors in a student’s essay. Particularly, a network is represented via a single point as a centroid in the space (like the center of mass of an object). Such centroid of the student’s network is presented as a red dot in the model. Darker dots and thicker lines indicate the frequency of error occurrence and closer connections among errors. For example, the following model displays several connections between the mechanical errors (punctuation and spelling), usage errors (conjunction), grammar errors (verb tense), and lexical errors (collocation) in a student essay.

The language-related error patterns in student E48’s essay simulated in an ENA model.
Our competitive model had co-registration correlations of 0.94 (Pearson) and 0.93 (Spearman) for the first dimension and co-registration correlations of 0.82 (Pearson) and 0.83 (Spearman) for the second dimension. Figure 6 shows the subtraction networks of error patterns in the students’ essays. The squares represent the centroid (i.e., mean) for the two student groups and the dots represent the error type in the written texts.

Comparison of language-related error patterns in the students’ essays in ENA analysis. The squares represent the mean (centroid) for each cohort and the black dots represent codes.
The network structures can be characterized as follows: along the X axis, towards the left we find verb tense and pronoun errors; towards the right we find spelling, structure, and collocation errors. Along the Y axis, towards the top is omission of object error, and towards the bottom are conjunction and word choice errors. The highlighted lines in the subtraction networks show the differences between the two groups’ epistemic networks. As depicted in the subtraction network of Hungarian (blue) and Myanmar (red) students’ essays, the blue lines indicate that the Hungarian students’ essays had more associations between pronoun and punctuation errors, and punctuation and word choice errors. In contrast, the essays produced by Myanmar students revealed more connections between word choice and sentence structure errors and spelling and conjunction errors.
Furthermore, we applied independent samples t-tests to examine differences, assuming unequal variance to the location of points in the projected ENA space for units in the essays produced by the Myanmar and Hungary students. Along the X axis, the results of the t-test revealed that the Myanmar cohort’s texts (M = 0.34, SD = 0.40, N = 30) were statistically significantly different from those generated by the Hungarian students (M = −0.36, SD = 0.53, N = 28; t (50.63) = 5.69, p = 0.00, Cohen’s d = 1.51). This indicated that different patterns regarding verb tense, pronoun, spelling, structure, and collocation errors were observed in the two groups’ texts. Nevertheless, there were no significant differences between the two groups regarding the errors along the Y axis (p > 0.05), suggesting that the errors related to omission of object, conjunction, and word choice occurred in the texts of both groups of students.
6 Discussions and conclusion
This study investigated the syntactic complexity and language-related error patterns in the writing of undergraduate EFL students from Myanmar and Hungary. An examination of various dimensions of syntactic complexity revealed that most indices: two indices of Coh-Metrix (SYNSTRUTt and SYNLE), all subordination indices (C/T, CT/T, DC/C, and DC/T) and two indices of length of production unit (MLS and MLT) as well as sentence complexity index (C/S) were found to differentiate the students’ writing. Findings from the analysis of the students’ language-related errors indicated significant differences in their error patterns. We next discuss our findings with reference to previous research on syntactic complexity and language-related errors in L2 writing.
According to Ortega (2003) and Wolfe-Quintero et al. (1998), more proficient L2 learners tend to produce longer and more varied sentences in writing. In our study, through the analyses of the textual characteristics of the students’ essays, we found that the Hungarian students made use of longer sentences with a variety of sentence structures, whereas the Myanmar students used simpler and shorter sentences. Therefore, it is very likely that the Hungarian students are more proficient than the Myanmar peers. To better understand their varying proficiency levels, we compared the students’ writing scores assessed by their class teachers. The results of independent samples t-test indicated no significant differences in the writing scores in the essays produced by Myanmar (M = 8.36, SD = 2.01) and Hungarian students (M = 8.93, SD = 1.6), t = 1.17, df = 53.13, p = 0.245). However, it should be stressed that the mean scores of the Hungarian students were higher than the comparison group, indicating their higher proficiency level. A possible explanation for conflicting results between the findings from the teachers’ writing assessment and automated evaluations might be due to the difference between the nature of classroom writing assessment and computational analyses. Particularly, the teachers used the rating scale which comprises four criteria: task achievement, coherence and cohesion, grammatical range and accuracy, and lexical range and accuracy to assess the students’ essays. However, the computational tools analyzed the syntactic complexity of written texts without considering other rhetorical aspects of writing.
One surprising finding is that although the writing tasks required the students to write in about 300–400 words, the Myanmar students wrote longer essays (M = 417) than their Hungarian peers (M = 397). These variations could partly be attributed to motivation towards L2 writing, influence of the writing model in their L1s (Myles 2002), or other socio-cultural norms in the instructional contexts. For example, in EFL pedagogy, Hungarian university students are taught to use longer and more complex sentences, and to avoid writing longer than necessary for the sake of clarity and conciseness (personal communication, Simon, August 17, 2021). On the other hand, in Myanmar, students are seemingly encouraged to express more ideas in writing, and they also think they might get higher scores if they write longer texts. These socio-cultural norms pertinent to the study contexts might be implicitly reflected in students’ writing.
In a research synthesis conducted by Ortega (2003), indices gauging length of production units (mean length of sentence, mean length of T-unit, and mean length of clause) were the most frequently used syntactic complexity measures and reported to be reliable indicators of proficiency level differences for L2 writers (Wolfe-Quintero et al. 1998). In line with these findings, our study found that most indices of the length of the production units (MLS and MLT) were able to distinguish the two student groups, except for MLC. These findings were consistent with those of Khushik and Huhta (2019), who found that MLS and MLT best distinguished the three CFER levels (A1, A2, and B1) but not MLC. Likewise, Lu (2011) found that all three indices of the length of the production units progressed linearly across proficiency levels.
More importantly, all the subordination indices differentiated very well the essays produced by the Myanmar and Hungarian students. As noted by Wolfe-Quintero et al. (1998), the complexity measure that gauges the amount of subordination (which is computed by counting all the clauses and dividing them over a given production unit of choice) correlated best with writing development. Specifically, in their review of syntactic complexity measures in 39 primary studies, the authors posited that the mean length of T-unit (MLT), clauses per T-unit (C/T), and dependent clauses per clause (DC/C) were the most satisfactory measures which were associated linearly and consistently with programme levels. Likewise, Norris and Ortega (2009) also acknowledged that the amount of subordination (e.g., mean number of clauses per T-unit) could be a useful and powerful index of complexification at intermediate and upper-intermediate levels compared to the amount of coordination which might be potentially more sensitive than the subordination measures (Bardovi-Harlig 1992). Thus, it is fair to say that the essays produced by the Hungarian cohort tend to represent their higher proficiency levels in L2 writing as compared to the other group.
In connection with the language-related error patterns in student writing, the results of the frequency analysis and ENA approach are mostly consistent; the latter demonstrates a fuller picture of common error patterns in writing and the connections among the students’ errors. The most typical errors found in the two groups include those in punctuation, word choice, and noun endings. Our results partially agree with those of Dahlmeier et al. (2013), who found that mechanical errors were one of the top error categories that the students frequently made. One possible explanation of the frequent occurrence of punctuation errors in both groups might concern their knowledge about the target language, their attention, or the influence of their mother tongue. For example, the punctuation rules in the Hungarian language are strict and such rules are in many ways different from English. As a result, Hungarian students end up using commas in the wrong (unnecessary) places when they write in English. Nonetheless, the findings that article errors were also frequent in the students’ writing contradict our results which could be explained by cross-language transfer (Zhu et al. 2021) from the students’ L1s to L2. In our study, the use of articles is present in the students’ L1s (Burmese and Hungarian) and thus, they might possibly find it easy to apply the rules of article systems in English though it was not the case in Dahlmeier et al.’s (2013) study.
Furthermore, the ENA analysis indicated significant differences in the errors regarding verb tense, pronoun, spelling, sentence structure, and collocation between the two groups, whereas no significant differences were found in omission of object, conjunction, and word choice errors. Along with the variations in the most frequent errors of the students from Myanmar and Hungary, our findings partly provide a pattern of the language-related errors of undergraduate students in Higher Education, which could inform the discussion of how to address these errors effectively by providing supplementary grammar instruction for L2 writers.
The results of the study contribute to our understanding of the linguistic features of EFL students’ texts, including error patterns in writing in two educational contexts. As analyzing syntactic features in academic writing have gained importance (Biber et al. 2011; Maamuujav et al. 2021), understanding these features in students’ texts could provide crucial information regarding their L2 writing proficiency and development. Additionally, ENA was performed as a potential approach in educational research (Shaffer et al. 2016); it can be replicated in interpreting the discourse data in learning L2 in school contexts. The successful application in the present study allows us to understand the common error patterns in students’ writing, leading us to provide recommendations to apply the network analyses in future studies.
Some limitations are acknowledged in the present study. The data was drawn from 58 students from 2 universities on limited and varied tasks; these facts limit the generalization of our findings. Large-scale data needs to be mined to explore the linguistic characteristics and error patterns in student writing. Moreover, studies using similar writing tasks, first languages, and students from different proficiency levels should be considered to obtain a fuller picture of the relationship between syntactic complexity and writing proficiency. Furthermore, as academic writing in educational contexts is shaped by cultural norms in specific instructional contexts (McIntosh et al. 2017), studies investigating the similarities and differences between the written discourse of EFL learners with different cultural backgrounds would further pinpoint how syntactic features are considered differently. Therefore, this aspect of syntactic complexity should be revisited and explored in future empirical research.
Acknowledgments
The authors are grateful to the participating teachers and students from the University of Yangon (Myanmar) and University of Pécs (Hungary) for their voluntary collaboration and efforts. The corresponding author is in the Stipendium Hungaricum Scholarship program offered by the Hungarian government.
Appendix 1: A description of syntactic structures counted by L2SCA
| Structure | Code | Description | Examples |
|---|---|---|---|
| Word | W | Number of tokens that are not punctuation marks | I ate |
| Verb phrase | VP | A finite and non-finite verb phrase that is dominated by a clause marker |
ate pizza
was hungry |
| Complex nominal | CN | (a) Nouns with modifiers (e.g., nouns plus adjectives, possessive, prepositional phrase, relative clause, participle, or appositive (b) Nominal clauses, and (c) Gerunds and infinitives that function as subjects |
(a) red car (b) I Know that she is hungry (c) Running is invigorating |
| Coordinate phrase | CP | Adjective, adverb, noun, and verb phrases connected by a coordinating conjunction | She eats pizzas and smiles |
| Clause | C | A syntactic structure with a subject and a finite verb | I ate pizzas because I was hungry |
| Dependent clause | DC | A finite clause that is a nominal, adverbial, or adjective clause | I ate pizza because I was hungry |
| T-unit | T | One main clause plus any subordinate clause or nonclausal structure that is attached to or embedded in it |
I ate pizza
I ate pizza because I was hungry |
| Complex T-unit | CT | A T-unit that includes a dependent clause | I ate pizza because I was hungry |
| Sentence | S | A group of words delimited with one of the following punctuation marks that signal the end of a sentence: period, question mark, exclamation mark, quotation mark, or ellipsis | I went running toady. |
Appendix 2: Coh-Metrix indices used in the study
| Syntactic features | Code | Measures/indices |
|---|---|---|
| Syntactic variety | SYNSTRUTt | Sentence syntax similarity (across paragraphs) |
| Phrase-level complexity | SYNLE | Left embeddedness (words before main verb) |
| Phrase-level complexity | SYNNP | Number of modifiers per noun phrase |
Appendix 3: Error categories used in analysis
| Error category | Error subcategory | Code | Examples from data |
|---|---|---|---|
| Grammar (G) | Omission of object | G.OM | The online criticisms affected [that celebrity] so much that the celebrity was banned from doing any kind of film or music business for one whole year. |
| Pronoun | G.PR | We all have encountered a teacher who makes you [us] feel worthless. | |
| Run-on sentences | G.RU | I try to keep myself on the positive side, often hiding or reporting negative posts as the societies start to handle these with official punishments, I won’t spend my time on unnecessary arguments. | |
| Sentence structure | G.ST | This is very hideous that is youths wasting their precious time on the social media. | |
| Subject-verb agreement | G.SV | It save [saves] time, energy and also increase [increases] productivity. | |
| Verb form | G.VF | We all are using it to keep in touch with our friends and also making [make] new friends. | |
| Verb tense | G.VT | I don’t want to imagine what has [would have] happened if my phone wouldn’t be there and I couldn’t call an ambulance. | |
| Usage (U) | Adverb | U.AD | Last year I had to go to orientation day and because I have never been to Pécs before, [however,] I decided to go sightseeing. |
| Article | U.AR | One event where my favorite device was useful was at the [a] field trip. | |
| Conjunction | U.CO | They have a lot of unsolved conflicts, [and] today one of the most common problems is the lack of respect between the generations. | |
| Noun ending | U.NE | As I mentioned above, we can share informations [information] and we can earn money through social media. | |
| Preposition | U.PR | And more, we can also make friends from worldwide [worldwide]. | |
| Word form | U.WF | Therefore, our thoughts can’t be same and everything will not be identity [identical]. | |
| Lexis (L) | Collocation | L.CO | Teachers teach with videos, live sessions, etc. and students can report [hand in/submit] their homework and assignments through social media. |
| Word choice | L.WC | My life has altered [changed] a lot since I’ve started using a smartphone, for several reasons. | |
| Mechanics (M) | Capitalization | M.CA | She had to teach us Myanmar (Myanmar) and English (English) but most of the time she was not in class. |
| Punctuation | M.PU | If social media is properly used in some manner, it can be a boon [,] but if not, it can be a bane. | |
| Spelling | M.SP | We use social media for communities, sharing and watching about the imformation [information] around the world. |
References
Allott, Anna. J. 1985. Language policy and language planning in Burma. In David Bradley (ed.), Language Policy, Language Planning and Sociolinguistics in South-East Asia, 131–154. Canberra: Australian National University.Search in Google Scholar
Atkinson, Dwight. 1999. TESOL and culture. Tesol Quarterly 33(4). 625–654.10.2307/3587880Search in Google Scholar
Atkinson, Dwight & Vai Ramanathan. 1995. Cultures of writing: An ethnographic comparison of L1 and L2 university writing/language programs. Tesol Quarterly 29(3). 539–568.10.2307/3588074Search in Google Scholar
Bardovi-Harlig, Kathleen. 1992. A second look at T-unit analysis: Reconsidering the sentence. Tesol Quarterly 26(2). 390–395.10.2307/3587016Search in Google Scholar
Barrot, Jessie & Joan Y. Agdeppa. 2021. Complexity, accuracy, and fluency as indices of college-level L2 writers’ proficiency. Assessing Writing 47. 100510.10.1016/j.asw.2020.100510Search in Google Scholar
Barrot, Jessie & Mari Karen Gabinete. 2021. Complexity, accuracy, and fluency in the argumentative writing of ESL and EFL learners. International Review of Applied Linguistics in Language Teaching 59(2). 209–232.10.1515/iral-2017-0012Search in Google Scholar
Biber, Douglas, Bethany Gray & Kornwipa Poonpon. 2011. Should we use characteristics of conversation to measure grammatical complexity in L2 writing development? Tesol Quarterly 45(1). 5–35.10.5054/tq.2011.244483Search in Google Scholar
Binkley, Marilyn, Ola Erstad, Joan Herman, Senta Raizen, Martin Ripley, May Miller-ricci & Mike Rumble. 2012. Defining twenty-first century skills. In Assessment and Teaching of 21st century skills. Springer Science.10.1007/978-94-007-2324-5_2Search in Google Scholar
Bulté, Bram & Alex Housen. 2014. Conceptualizing and measuring short-term changes in L2 writing complexity. Journal of Second Language Writing 26. 42–65.10.1016/j.jslw.2014.09.005Search in Google Scholar
Crossley, Scott A. 2020. Linguistic features in writing quality and development: An overview. Journal of Writing Research 11(3). 415–443.10.17239/jowr-2020.11.03.01Search in Google Scholar
Crossley, Scott A. & Danielle S. McNamara. 2014. Does writing development equal writing quality? A computational investigation of syntactic complexity in L2 learners. Journal of Second Language Writing 26. 66–79.10.1016/j.jslw.2014.09.006Search in Google Scholar
Crossley, Scott A. & Danielle S. McNamara. 2012. Predicting second language writing proficiency: The roles of cohesion and linguistic sophistication. Journal of Research in Reading 35(2). 115–135.10.1111/j.1467-9817.2010.01449.xSearch in Google Scholar
Crossley, Scott A., Tom Salsbury, Danielle S. McNamara & Jarvis Scott. 2010. Predicting lexical proficiency in language learner texts using computational indices. Language Testing 28(4). 561–580.10.1177/0265532210378031Search in Google Scholar
Dahlmeier, Daniel, Hwee Tou Ng & Siew Mei Wu. 2013. Building a large annotated corpus of learner English: The NUS corpus of learner English. In Proceedings of the eighth workshop on innovative use of NLP for building educational applications. 22–31.Search in Google Scholar
Dikli, Semire & Susan Bleyle. 2014. Automated essay scoring feedback for second language writers: How does it compare to instructor feedback? Assessing Writing 22. 1–17.10.1016/j.asw.2014.03.006Search in Google Scholar
Khushik, Ghulam Abbas & Ari Huhta. 2019. Investigating syntactic complexity in EFL learners’ writing across Common European Framework of Reference levels A1, A2, and B1. Applied Linguistics 41(4). 506–532.10.1093/applin/amy064Search in Google Scholar
Kyu, Aye. 1993. Sample reading materials for the one-year diploma in English course of the institute of foreign languages. Singapore: SEAMEO Regional Language Centre.Search in Google Scholar
Lu, Xiaofei. 2010. Automatic analysis of syntactic complexity in second language writing. International Journal of Corpus Linguistics 15(4). 474–496.10.1075/ijcl.15.4.02luSearch in Google Scholar
Lu, Xiaofei. 2011. A corpus-based evaluation of syntactic complexity measures as indices of college-level ESL writers’ language development. Tesol Quarterly 45(1). 36–62.10.5054/tq.2011.240859Search in Google Scholar
Maamuujav, Undarmaa, Carol Booth Olson & Huy Chung. 2021. Syntactic and lexical features of adolescent L2 students’ academic writing. Journal of Second Language Writing 53. 100822.10.1016/j.jslw.2021.100822Search in Google Scholar
Mazgutova, Diana & Judit Kormos. 2015. Syntactic and lexical development in an intensive English for Academic Purposes programme. Journal of Second Language Writing 29. 3–15.10.1016/j.jslw.2015.06.004Search in Google Scholar
McIntosh, Kyle, Ulla Connor & Esen Gokpinar-Shelton. 2017. What intercultural rhetoric can bring to EAP/ESP writing studies in an English as a lingua franca world. Journal of English for Academic Purposes 29. 12–20.10.1016/j.jeap.2017.09.001Search in Google Scholar
McNamara, Danielle, Arthur Graesser, Philip McCarthy & Zhiqiang Cai. 2014. Automated evaluation of text and discourse with Coh-Metrix. New York: Cambridge University Press.10.1017/CBO9780511894664Search in Google Scholar
Myles, Johanne. 2002. Second language writing and research: The writing process and error analysis in student texts. Tesl-Ej 6(2). 1–20.Search in Google Scholar
Nikolov, Marianne & Beno Csapó. 2010. The relationship between reading skills in early English as a foreign language and Hungarian as a first language. International Journal of Bilingualism 14(3). 315–329.10.1177/1367006910367854Search in Google Scholar
Norris, John M. & Lourdes Ortega. 2000. Effectiveness of L2 instruction : A research synthesis and quantitative meta-analysis. Language Learning 50(3). 417–528.10.1111/0023-8333.00136Search in Google Scholar
Norris, John M. & Lourdes Ortega. 2009. Towards an organic approach to investigating CAF in instructed SLA: The case of complexity. Applied Linguistics 30(4). 555–578.10.1093/applin/amp044Search in Google Scholar
Phuket, Pimpisa Rattanadilok Na & Normah Binti Othman. 2015. Understanding EFL students’ errors in writing. Journal of Education and Practice 6(32). 99–106.Search in Google Scholar
Olsen, S. 1999. Errors and compensatory strategies: A study of grammar and vocabulary in texts written by Norwegian learners of English. System 27(2). 191–205.10.1016/S0346-251X(99)00016-0Search in Google Scholar
Ortega, Lourdes. 2003. Syntactic complexity measures and their relationship to L2 proficiency: A research synthesis of college-level L2 writing. Applied Linguistics 24(4). 492–518.10.1093/applin/24.4.492Search in Google Scholar
Romano, Francesco. 2019. Grammatical accuracy in EAP writing. Journal of English for Academic Purposes 41. 100773.10.1016/j.jeap.2019.100773Search in Google Scholar
Schleppegrell, Mary J. 2001. Linguistic features of the language of schooling. Linguistics and Education 12(4). 431–459.10.1016/S0898-5898(01)00073-0Search in Google Scholar
Shaffer, David Williamson, Wesley Collier & A. R. Ruis. 2016. A tutorial on epistemic network analysis: Analyzing the structure of connections in cognitive, social, and interaction data. Journal of Learning Analytics 3(3). 9–45.10.18608/jla.2016.33.3Search in Google Scholar
Tin, Tan Bee. 2014. Learning English in the periphery: A view from Myanmar (Burma). Language Teaching Research 18(1). 95–117.10.1177/1362168813505378Search in Google Scholar
Uysal, Hacer Hande. 2008. Tracing the culture behind writing: Rhetorical patterns and bidirectional transfer in L1 and L2 essays of Turkish writers in relation to educational context. Journal of Second Language Writing 17. 183–207.10.1016/j.jslw.2007.11.003Search in Google Scholar
Voogt, Joke & Natalie Pareja Roblin. 2012. A comparative analysis of international frameworks for 21st century competences: Implications for national curriculum policies. Journal of Curriculum Studies 44(3). 299–321.10.1080/00220272.2012.668938Search in Google Scholar
Wolfe-Quintero, Kate, Shunji Inagaki & Hae-Young Kim. 1998. Second language development in writing: Measures of fluency, accuracy, & complexity. Honolulu: University of Hawaii Press.Search in Google Scholar
Yoon, Hyung-Jo & Charlene Polio. 2017. The linguistic development of students of English as a second language in two written genres. Tesol Quarterly 51(2). 275–301.10.1002/tesq.296Search in Google Scholar
Zheng, Cui & Tae-Ja Park. 2013. An analysis of errors in English writing made by Chinese and Korean university students. Theory and Practice in Language Studies 3(8). 1342–1351.10.4304/tpls.3.8.1342-1351Search in Google Scholar
Zhu, Xinhua, Guan Ying Li, Choo Mui Cheong & Hongbo Wen. 2021. Effects of L1 single-text and multiple-text comprehension on L2 integrated writing. Assessing Writing 49. 100546.10.1016/j.asw.2021.100546Search in Google Scholar
© 2023 the author(s), published by De Gruyter, Berlin/Boston
This work is licensed under the Creative Commons Attribution 4.0 International License.
Articles in the same Issue
- Frontmatter
- Introduction
- The fascinating world of language teaching and learning varieties
- Research Articles
- Aspiring multilinguals or contented bilinguals? University students negotiating their multilingual and professional identities
- The (im)possibility of breaking the cycle of rippling circularities affecting Australian language education programs: a Queensland example
- Lernen mit LMOOCs im universitären Deutschunterricht: Entscheidungshilfen für Deutschlehrende
- Enhance sustainability and environmental protection awareness: agency in Chinese informal video learning
- Gamification and learning Spanish as a modern language: student perceptions in the university context
- Seeing innovation from different prisms: university students’ and instructors’ perspectives on flipping the Spanish language classroom
- Investigating syntactic complexity and language-related error patterns in EFL students’ writing: corpus-based and epistemic network analyses
- Using Google Docs for guided Academic Writing assessments: students’ perspectives
- Digital storytelling as practice-based participatory pedagogy for English for specific purposes
- Is individual competition in translator training compatible with collaborative learning? The case of the MTIE Translation Award
- Tackling the elephant in the language classroom: introducing machine translation literacy in a Swiss language centre
- Institutionalised autonomisation of language learning in a French language centre
- The story of becoming an autonomous learner: a case study of a student’s learning management
- The effect of collaborative activities on tertiary-level EFL students’ learner autonomy in the Turkish context
- Learner autonomy and English achievement in Chinese EFL undergraduates: the mediating role of ambiguity tolerance and foreign language classroom anxiety
- Activity Reports
- Lehre am Sprachenzentrum der UZH und der ETH Zürich: Positionspapier
- Communication course for future engineers – effective data presentation and its interpretation during LSP courses
- Dialogic co-creation in English language teaching and learning: a personal experience
Articles in the same Issue
- Frontmatter
- Introduction
- The fascinating world of language teaching and learning varieties
- Research Articles
- Aspiring multilinguals or contented bilinguals? University students negotiating their multilingual and professional identities
- The (im)possibility of breaking the cycle of rippling circularities affecting Australian language education programs: a Queensland example
- Lernen mit LMOOCs im universitären Deutschunterricht: Entscheidungshilfen für Deutschlehrende
- Enhance sustainability and environmental protection awareness: agency in Chinese informal video learning
- Gamification and learning Spanish as a modern language: student perceptions in the university context
- Seeing innovation from different prisms: university students’ and instructors’ perspectives on flipping the Spanish language classroom
- Investigating syntactic complexity and language-related error patterns in EFL students’ writing: corpus-based and epistemic network analyses
- Using Google Docs for guided Academic Writing assessments: students’ perspectives
- Digital storytelling as practice-based participatory pedagogy for English for specific purposes
- Is individual competition in translator training compatible with collaborative learning? The case of the MTIE Translation Award
- Tackling the elephant in the language classroom: introducing machine translation literacy in a Swiss language centre
- Institutionalised autonomisation of language learning in a French language centre
- The story of becoming an autonomous learner: a case study of a student’s learning management
- The effect of collaborative activities on tertiary-level EFL students’ learner autonomy in the Turkish context
- Learner autonomy and English achievement in Chinese EFL undergraduates: the mediating role of ambiguity tolerance and foreign language classroom anxiety
- Activity Reports
- Lehre am Sprachenzentrum der UZH und der ETH Zürich: Positionspapier
- Communication course for future engineers – effective data presentation and its interpretation during LSP courses
- Dialogic co-creation in English language teaching and learning: a personal experience