A point on discrete versus continuous state-space Markov chains
-
Mathias Muia
 and
Martial Longla
and
Martial Longla

Abstract
This article investigates the effects of discrete marginal distributions on copula-based Markov chains. We establish results on mixing properties and parameter estimation for a copula-based Markov chain model with Bernoulli(
1 Introduction
Markov chain models have been widely used in the literature to represent the relationship between consecutive observations in a sequence of Bernoulli trials. Johnson and Klotz [18] employed a Markov chain generalization of a binomial model to analyze the crystal structure of a two-metal alloy in their metallurgical studies. Crow [9] investigated the applications of two-state Markov chains in telecommunications in his study focusing on approximating confidence intervals. Brainerd and Chang [7] used two-state Markov chains to address problems in linguistic analysis. These examples illustrate that Markov chain models can provide a solid foundation for modeling a wide range of two-state sequential phenomena.
Moreover, in the study of sequences consisting of different alternatives, there has been notable interest in using group or run tests to evaluate the randomness of the sequences. These tests are based on the count of changes between outcomes in the sequence, aiming to assess whether the sequence displays randomness (denoted as the null hypothesis,
1.1 Copulas and Markov chains
A 2-copula is a bivariate function
The copula
This article focuses on a stationary Markov chain based on a copula from the Frechet family of copulas. The Fréchet family of copulas has the form
where
Studies involving inferential statistics for discrete cases closely similar to the one considered here have been presented in the works of Billingsley [4], Billingsley [3], Goodman [13], Klotz [19], Klotz [20], Price [29], Lindqvist [21], and others. Goodman [13] considered a single sequence of alternatives consisting of a long chain of observations to derive some long-sequence group tests. Klotz [20] presented small and large sample distribution theory for the sufficient statistics of a model for Bernoulli trials with Markov dependence. He provided estimators for the model parameters and showed that the uniform most powerful unbiased test of independence is the run test. On the other hand, Price [29] and Lindqvist [21] focused on estimating the model parameters only. Price [29] used Monte Carlo techniques to investigate finite sample properties for the parameters of a dependent Bernoulli process. Lindqvist [21] considered the weaker assumption of non-Markovian dependence and showed that the MLE,
The rest of this article is organized as follows: in Section 2, we introduce our model and detail the transition probabilities of the discrete Markov chain model considered. Mixing properties of the Markov chain model are discussed in Section 2.1. Section 3 covers parameter estimation, where we derive MLEs and their asymptotic distributions. In Section 4, we provide a test for independence in the sequence. This article concludes with a simulation study in Section 5.
2 Model
Consider a stationary Markov chain model based on the copula
Copula (2.1) is from the Frechet/Mardia family of copulas given by (1.1) with
Longla [23] showed that a stationary Markov chain with copula (2.1) and uniform marginals has
If the marginals are Bernoulli(
Theorem 1
Let
and
Proof
Due to stationarity of the Markov chain,
where the second equality follows from Sklar’s theorem (Sklar [30]). The rest of the probabilities are computed using the hypothesis that the Markov chain is stationary with Bern(
Using the definition of conditional probability,
Distribution of
|
|
|||
|---|---|---|---|
|
|
0 | 1 |
|
| 0 |
|
|
|
| 1 |
|
|
|
|
|
|
|
1 |
The statistical behavior of the distribution at
Transition matrix (2.3) is similar to the one considered by Klotz [20]. In our case, we have a frequency parameter
Proposition 2
The nth transition matrices for (2.3) and (2.4) are, respectively,
and
Proof
For
Solving this equation yields
where
2.1 Mixing
Most of the dependence and mixing coefficients are heavily influenced by the copula of the model of interest [22]. Longla [23] proposed a set of copula families that generate exponential
We define two mixing coefficients in this article: the
For random variables
where
Theorem 3
Let
Proof
Consider the coefficient defined by equation (2.9) with
where
After computing the four quantities,
From Table 2, we end up with
For
Distribution of
|
|
|||
|---|---|---|---|
|
|
0 | 1 |
|
| 0 |
|
|
|
| 1 |
|
|
|
|
|
|
|
1 |
3 Parameter estimation asymptotic normality
The characteristics of the model parameter estimators, including the shape of their asymptotic distributions, rely on the chosen marginal distribution.
3.1 Markov chain with uniform marginals
Assuming
The copulas
as demonstrated in Proposition 4.
Proposition 4
Let
The random variables
The random variable (3.2) is an unbiased and consistent estimator of a. Moreover,
The MLE of a is the method of moment estimator given by (3.2).
Proof
We prove independence in the sequence by induction. For
since
(3.3)establishing independence for the base case.
Induction step: Suppose independence holds for
(3.4)We now prove it for
Thus, by induction, independence holds for all
satisfies
which implies that
The proof follows from the properties of the estimator of the Bernoulli parameter for an i.i.d. Bernoulli
Let
(3.5)The likelihood function is
(3.6)It follows that
3.2 Stationary Markov chain with Bern(
p
) marginal distribution
The literature has extensively discussed the statistical inference for finite Markov chains. When transition probabilities of the Markov chain are expressed as
Considering transition matrix (2.3) for instance, the likelihood function of the sample is
and the log-likelihood is given by
Differentiating (3.9) with respect to
The equations in (3.10) can be rewritten in the form:
Solving for
where
There is no closed-form solution for equation (3.13) but numerical solutions can be obtained.
The sufficient conditions for MLEs and their asymptotic properties are specified in Condition 5.1 of Billingsley [4], as presented in the following.
Condition 5
Let
The set
The
For each
.
This condition can be used to verify the following theorem:
Theorem 6
Let
Note that
Proof of Theorem (6)
The proof of Theorem (6) follows by first verifying that the requirements outlined in Condition (5) are met for each of the cases,
When
In this case, we are left with
and the log-likelihood is expressed as
The following proposition provides the MLE of
Proposition 7
Let
Proof
The proof of Proposition (7) follows from verifying the requirements of Condition (5). The variance of
Klotz showed that the MLE,
In this work, different asymptotically equivalent estimators for
Proposition 8
Let
Proof
For the Markov chain generated when
Applying the properties of a geometric sum twice and simplifying, we obtain
Therefore, for large
Similarly, for
From (3.18) and (3.19), we note that the asymptotic variance of the sample mean is the same as that of
The following result provides the asymptotic properties of the sample mean for the stationary Markov chain based on copula (2.1).
Theorem 9
Let
where
Proof
The proof of Theorem (9) follows from Theorem (18.5.2) of Ibragimov and Linnik [16] and the fact that the Markov chain is uniformly mixing. Using steps similar to those used in the proof of Theorem (3), the
Let
converges since
4 Hypothesis testing
4.1 Test of independence
Different tests have been used in the literature to assess the independence of observations in a sequence. These include the
Having
Proposition 10
Let
Proof
For independent observations in a sequence,
The likelihood ratio approach for testing the hypothesis of independence is obtained as follows: for
The likelihood under
The function (4.2) represents the likelihood of an i.i.d Bern(
The likelihood function evaluated at the MLE under
The LRT statistic is therefore
For a given significance level
A result due to Wilks [31] shows that under suitable regularity conditions, if
In a similar manner, for
The limiting distribution of
5 Simulation study
5.1 MLEs of a and p
Tables 3 and 4 present the MLEs of
Average length of 400, 95% confidence intervals, and the coverage probabilities (CPs) for the true values of
|
|
Initial parameters | CIML for “a” | CIML for “p” | CP for “a” | CP for “p” |
|---|---|---|---|---|---|
| 499 |
|
0.1586 | 0.0523 | 0.8925 | 0.9425 |
|
|
0.0950 | 0.0598 | 0.9300 | 0.9500 | |
|
|
0.0821 | 0.0494 | 0.9475 | 0.9500 | |
|
|
0.2172 | 0.0584 | 0.9050 | 0.9425 | |
|
|
0.1273 | 0.0695 | 0.9475 | 0.9575 | |
|
|
0.1100 | 0.0605 | 0.9475 | 0.9525 | |
|
|
0.2671 | 0.1153 | 0.9675 | 0.9050 | |
|
|
0.1479 | 0.1530 | 0.9650 | 0.9625 | |
|
|
0.1275 | 0.1490 | 0.9500 | 0.9475 | |
|
|
0.2237 | 0.2000 | 0.9500 | 0.8350 | |
|
|
0.1014 | 0.2830 | 0.9675 | 0.9175 | |
|
|
0.0869 | 0.2797 | 0.9650 | 0.8825 | |
| 999 |
|
0.1146 | 0.0370 | 0.9125 | 0.9325 |
|
|
0.0674 | 0.0423 | 0.9525 | 0.9500 | |
|
|
0.0585 | 0.0351 | 0.9275 | 0.9350 | |
|
|
0.1554 | 0.0414 | 0.9300 | 0.9200 | |
|
|
0.0902 | 0.0491 | 0.9475 | 0.9350 | |
|
|
0.0782 | 0.0429 | 0.9500 | 0.9400 | |
|
|
0.1854 | 0.0818 | 0.9600 | 0.9225 | |
|
|
0.1042 | 0.1084 | 0.9550 | 0.9550 | |
|
|
0.0899 | 0.1050 | 0.9350 | 0.9575 | |
|
|
0.1373 | 0.1446 | 0.9625 | 0.8825 | |
|
|
0.0693 | 0.2035 | 0.9500 | 0.9275 | |
|
|
0.0597 | 0.1997 | 0.9550 | 0.9600 | |
| 4,999 |
|
0.0524 | 0.0166 | 0.9450 | 0.9600 |
|
|
0.0303 | 0.0189 | 0.9575 | 0.9525 | |
|
|
0.0263 | 0.0157 | 0.9475 | 0.9500 | |
|
|
0.0700 | 0.0186 | 0.9600 | 0.9525 | |
|
|
0.0404 | 0.0220 | 0.9500 | 0.9475 | |
|
|
0.0350 | 0.0192 | 0.9600 | 0.9325 | |
|
|
0.0809 | 0.0370 | 0.9600 | 0.9325 | |
|
|
0.0465 | 0.0486 | 0.9600 | 0.9650 | |
|
|
0.0402 | 0.0471 | 0.9675 | 0.9775 | |
|
|
0.0541 | 0.0678 | 0.9300 | 0.9425 | |
|
|
0.0306 | 0.0913 | 0.9425 | 0.9525 | |
|
|
0.0264 | 0.0899 | 0.9550 | 0.9525 |
Average length of 400, 95% confidence intervals, and the CPs for the true values of
|
|
|
|
CIML for “a” | CIML for “p” | CP for “a” | CP for “p” |
|---|---|---|---|---|---|---|
| 499 | 0.1 | 0.6 | 0.0821 | 0.0494 | 0.9475 | 0.9500 |
| 0.1 | 0.7 | 0.0950 | 0.0598 | 0.9300 | 0.9500 | |
| 0.1 | 0.9 | 0.1593 | 0.0524 | 0.8925 | 0.9425 | |
| 0.3 | 0.6 | 0.1267 | 0.0726 | 0.9500 | 0.9575 | |
| 0.3 | 0.7 | 0.1460 | 0.0803 | 0.9275 | 0.9550 | |
| 0.3 | 0.9 | 0.2514 | 0.0658 | 0.9325 | 0.9550 | |
| 0.7 | 0.6 | 0.1275 | 0.1484 | 0.9475 | 0.9475 | |
| 0.7 | 0.7 | 0.1479 | 0.1530 | 0.9650 | 0.9625 | |
| 0.7 | 0.9 | 0.2671 | 0.1153 | 0.9675 | 0.905 | |
| 0.9 | 0.6 | 0.0868 | 0.2797 | 0.9600 | 0.9625 | |
| 0.9 | 0.7 | 0.1014 | 0.2830 | 0.9675 | 0.9175 | |
| 0.9 | 0.9 | 0.2237 | 0.2000 | 0.9500 | 0.8350 | |
| 999 | 0.1 | 0.6 | 0.0585 | 0.0351 | 0.9275 | 0.9350 |
| 0.1 | 0.7 | 0.0674 | 0.0423 | 0.9525 | 0.9500 | |
| 0.1 | 0.9 | 0.1146 | 0.0370 | 0.9125 | 0.9325 | |
| 0.3 | 0.6 | 0.0896 | 0.0512 | 0.9500 | 0.9450 | |
| 0.3 | 0.7 | 0.1034 | 0.0567 | 0.9450 | 0.9325 | |
| 0.3 | 0.9 | 0.1787 | 0.0464 | 0.9475 | 0.9350 | |
| 0.7 | 0.6 | 0.0899 | 0.1050 | 0.9350 | 0.9575 | |
| 0.7 | 0.7 | 0.1042 | 0.1084 | 0.9550 | 0.9550 | |
| 0.7 | 0.9 | 0.1854 | 0.0818 | 0.9600 | 0.9225 | |
| 0.9 | 0.6 | 0.0596 | 0.1997 | 0.9550 | 0.9550 | |
| 0.9 | 0.7 | 0.0693 | 0.2035 | 0.9500 | 0.9275 | |
| 0.9 | 0.9 | 0.1373 | 0.1446 | 0.9625 | 0.8825 | |
| 4,999 | 0.1 | 0.6 | 0.0263 | 0.0157 | 0.9475 | 0.9500 |
| 0.1 | 0.7 | 0.0303 | 0.0189 | 0.9575 | 0.9525 | |
| 0.1 | 0.9 | 0.0524 | 0.0166 | 0.9450 | 0.9600 | |
| 0.3 | 0.6 | 0.0401 | 0.0229 | 0.9300 | 0.9450 | |
| 0.3 | 0.7 | 0.0463 | 0.0254 | 0.9350 | 0.9425 | |
| 0.3 | 0.9 | 0.0803 | 0.0208 | 0.9525 | 0.9325 | |
| 0.7 | 0.6 | 0.0402 | 0.0471 | 0.9675 | 0.9775 | |
| 0.7 | 0.7 | 0.0465 | 0.0486 | 0.9600 | 0.9650 | |
| 0.7 | 0.9 | 0.0809 | 0.0370 | 0.9600 | 0.9325 | |
| 0.9 | 0.6 | 0.0264 | 0.0899 | 0.9550 | 0.9525 | |
| 0.9 | 0.7 | 0.0306 | 0.0913 | 0.9425 | 0.9525 | |
| 0.9 | 0.9 | 0.0541 | 0.0678 | 0.9300 | 0.9325 |
In Table 3, the confidence intervals for
Table 4 shows that confidence intervals lengthen as
Furthermore, the results presented in Tables 3 and 4 demonstrate a noteworthy symmetry in the CIMLs when comparing parameter pairs equidistant from
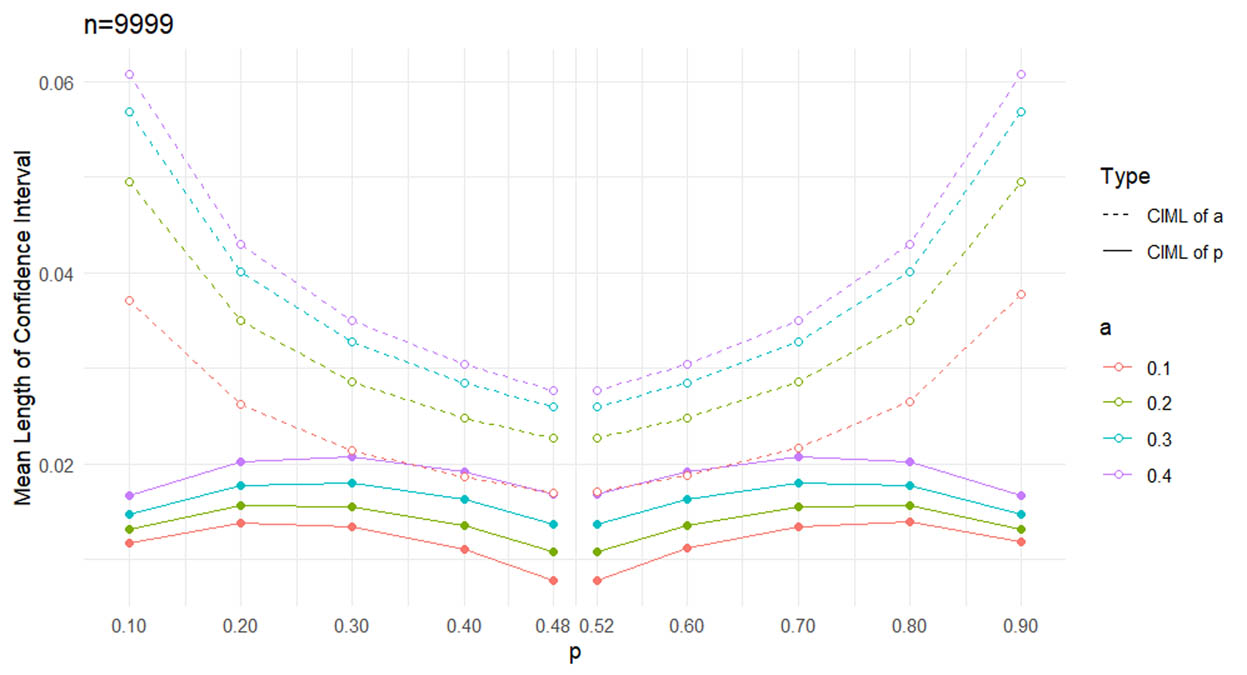
Symmetry in mean lengths of confidence intervals for “p” about
The observed behavior of the CIML for
For
Overall, the behavior of the CIML for
This symmetry reflects the underlying properties of the mixture copula model. The behavior suggests that the model treats the transition probabilities in a symmetric manner around
5.2 Test for independence
5.2.1 Likelihood ratio test for independence
Tables 5 and 7 present the results of the likelihood ratio test for independence in the Markov chain generated by copula model (2.1) and Bernoulli(
Likelihood ratio test results
| a | p |
|
Decision on
|
|---|---|---|---|
| 0.1 | 0.1 | 1.9648 | Fail to reject |
| 0.1 | 0.2 | 75.3318 | Reject |
| 0.1 | 0.3 | 465.3507 | Reject |
| 0.1 | 0.4 | 1302.2148 | Reject |
| 0.2 | 0.1 | 62.5624 | Reject |
| 0.2 | 0.2 | 0.5426 | Fail to reject |
| 0.2 | 0.3 | 91.6928 | Reject |
| 0.2 | 0.4 | 537.1743 | Reject |
| 0.3 | 0.1 | 178.0430 | Reject |
| 0.3 | 0.2 | 85.5790 | Reject |
| 0.3 | 0.3 |
|
Fail to reject |
| 0.3 | 0.4 | 143.3914 | Reject |
| 0.4 | 0.1 | 315.6163 | Reject |
| 0.4 | 0.2 | 282.6401 | Reject |
| 0.4 | 0.3 | 93.5413 | Reject |
| 0.4 | 0.4 |
|
Fail to reject |
| 0.5 | 0.1 | 598.6498 | Reject |
| 0.5 | 0.2 | 678.1999 | Reject |
| 0.5 | 0.3 | 443.8051 | Reject |
| 0.5 | 0.4 | 175.6443 | Reject |
| 0.6 | 0.1 | 986.4705 | Reject |
| 0.6 | 0.2 | 1060.7808 | Reject |
| 0.6 | 0.3 | 908.5222 | Reject |
| 0.6 | 0.4 | 520.2437 | Reject |
| 0.7 | 0.1 | 1243.0918 | Reject |
| 0.7 | 0.2 | 1596.5124 | Reject |
| 0.7 | 0.3 | 1581.8311 | Reject |
| 0.7 | 0.4 | 1243.7897 | Reject |
| 0.8 | 0.1 | 1548.5890 | Reject |
| 0.8 | 0.2 | 2291.3934 | Reject |
| 0.8 | 0.3 | 2551.6879 | Reject |
| 0.8 | 0.4 | 2361.9013 | Reject |
| 0.9 | 0.1 | 2466.6171 | Reject |
| 0.9 | 0.2 | 3305.7161 | Reject |
| 0.9 | 0.3 | 3631.3346 | Reject |
| 0.9 | 0.4 | 3835.4538 | Reject |
Likelihood ratio test results
| a | p |
|
Decision on
|
|---|---|---|---|
| 0.1 | 0.6 | 279.8288 | Reject |
| 0.1 | 0.7 | 107.8140 | Reject |
| 0.1 | 0.8 | 16.0485 | Reject |
| 0.1 | 0.9 | 0.3192 | Fail to reject |
| 0.2 | 0.6 | 111.3087 | Reject |
| 0.2 | 0.7 | 17.5196 | Reject |
| 0.2 | 0.8 | 0.4450 | Fail to reject |
| 0.2 | 0.9 | 12.1072 | Reject |
| 0.3 | 0.6 | 38.3697 | Reject |
| 0.3 | 0.7 |
|
Fail to reject |
| 0.3 | 0.8 | 15.9764 | Reject |
| 0.3 | 0.9 | 26.5985 | Reject |
| 0.4 | 0.6 | 0.0341 | Fail to reject |
| 0.4 | 0.7 | 17.6239 | Reject |
| 0.4 | 0.8 | 50.2535 | Reject |
| 0.4 | 0.9 | 62.1340 | Reject |
| 0.5 | 0.6 | 16.9398 | Reject |
| 0.5 | 0.7 | 97.3027 | Reject |
| 0.5 | 0.8 | 127.9626 | Reject |
| 0.5 | 0.9 | 165.1340 | Reject |
| 0.6 | 0.6 | 118.6838 | Reject |
| 0.6 | 0.7 | 195.6122 | Reject |
| 0.6 | 0.8 | 209.1521 | Reject |
| 0.6 | 0.9 | 222.3218 | Reject |
| 0.7 | 0.6 | 279.7745 | Reject |
| 0.7 | 0.7 | 328.9172 | Reject |
| 0.7 | 0.8 | 315.8419 | Reject |
| 0.7 | 0.9 | 263.6996 | Reject |
| 0.8 | 0.6 | 522.4635 | Reject |
| 0.8 | 0.7 | 557.5287 | Reject |
| 0.8 | 0.8 | 533.2392 | Reject |
| 0.8 | 0.9 | 284.6627 | Reject |
| 0.9 | 0.6 | 768.7074 | Reject |
| 0.9 | 0.7 | 688.8740 | Reject |
| 0.9 | 0.8 | 545.8894 | Reject |
| 0.9 | 0.9 | 411.5155 | Reject |
The Markov chain is generated using true values of
The chain is simulated for a total of
The test indicates that when
5.2.2 Kolmogorov-Smirnov (KS) distance
We employed the KS distance to compare the copula of the sample with the independence copula. Specifically, we used it to test whether the empirical joint distribution of
where
A large KS distance suggests a significant departure from independence, indicating the presence of dependence in the Markov chain. The results of this test are summarized in Tables 6 and 8.
KS distance values
|
|
|
KS distance | Decision on
|
|---|---|---|---|
| 0.1 | 0.1 | 0.0027 | Fail to reject |
| 0.1 | 0.2 | 0.0181 | Reject |
| 0.1 | 0.3 | 0.0603 | Reject |
| 0.1 | 0.4 | 0.1188 | Reject |
| 0.2 | 0.1 | 0.0111 | Reject |
| 0.2 | 0.2 | 0.0009 | Fail to reject |
| 0.2 | 0.3 | 0.0297 | Reject |
| 0.2 | 0.4 | 0.0775 | Reject |
| 0.3 | 0.1 | 0.0203 | Reject |
| 0.3 | 0.2 | 0.0211 | Reject |
| 0.3 | 0.3 | 0.0013 | Fail to reject |
| 0.3 | 0.4 | 0.0433 | Reject |
| 0.4 | 0.1 | 0.0284 | Reject |
| 0.4 | 0.2 | 0.0403 | Reject |
| 0.4 | 0.3 | 0.0286 | Reject |
| 0.4 | 0.4 | 0.0020 | Fail to reject |
| 0.5 | 0.1 | 0.0379 | Reject |
| 0.5 | 0.2 | 0.0611 | Reject |
| 0.5 | 0.3 | 0.0617 | Reject |
| 0.5 | 0.4 | 0.0405 | Reject |
| 0.6 | 0.1 | 0.0507 | Reject |
| 0.6 | 0.2 | 0.0786 | Reject |
| 0.6 | 0.3 | 0.0887 | Reject |
| 0.6 | 0.4 | 0.0781 | Reject |
| 0.7 | 0.1 | 0.0606 | Reject |
| 0.7 | 0.2 | 0.0992 | Reject |
| 0.7 | 0.3 | 0.1177 | Reject |
| 0.7 | 0.4 | 0.1200 | Reject |
| 0.8 | 0.1 | 0.0701 | Reject |
| 0.8 | 0.2 | 0.1189 | Reject |
| 0.8 | 0.3 | 0.1510 | Reject |
| 0.8 | 0.4 | 0.1623 | Reject |
| 0.9 | 0.1 | 0.0916 | Reject |
| 0.9 | 0.2 | 0.1445 | Reject |
| 0.9 | 0.3 | 0.1718 | Reject |
| 0.9 | 0.4 | 0.1969 | Reject |
KS distance values
|
|
|
KS distance | Decision on
|
|---|---|---|---|
| 0.1 | 0.6 | 0.1188 | Reject |
| 0.1 | 0.7 | 0.0603 | Reject |
| 0.1 | 0.8 | 0.0181 | Reject |
| 0.1 | 0.9 | 0.0027 | Fail to reject |
| 0.2 | 0.6 | 0.0775 | Reject |
| 0.2 | 0.7 | 0.0297 | Reject |
| 0.2 | 0.8 | 0.0009 | Fail to reject |
| 0.2 | 0.9 | 0.0111 | Reject |
| 0.3 | 0.6 | 0.0433 | Reject |
| 0.3 | 0.7 | 0.0013 | Fail to reject |
| 0.3 | 0.8 | 0.0211 | Reject |
| 0.3 | 0.9 | 0.0203 | Reject |
| 0.4 | 0.6 | 0.0020 | Fail to reject |
| 0.4 | 0.7 | 0.0286 | Reject |
| 0.4 | 0.8 | 0.0403 | Reject |
| 0.4 | 0.9 | 0.0284 | Reject |
| 0.5 | 0.6 | 0.0365 | Reject |
| 0.5 | 0.7 | 0.0574 | Reject |
| 0.5 | 0.8 | 0.0559 | Reject |
| 0.5 | 0.9 | 0.0409 | Reject |
| 0.6 | 0.6 | 0.0781 | Reject |
| 0.6 | 0.7 | 0.0887 | Reject |
| 0.6 | 0.8 | 0.0786 | Reject |
| 0.6 | 0.9 | 0.0507 | Reject |
| 0.7 | 0.6 | 0.1200 | Reject |
| 0.7 | 0.7 | 0.1177 | Reject |
| 0.7 | 0.8 | 0.0992 | Reject |
| 0.7 | 0.9 | 0.0606 | Reject |
| 0.8 | 0.6 | 0.1623 | Reject |
| 0.8 | 0.7 | 0.1510 | Reject |
| 0.8 | 0.8 | 0.1189 | Reject |
| 0.8 | 0.9 | 0.0701 | Reject |
| 0.9 | 0.6 | 0.1969 | Reject |
| 0.9 | 0.7 | 0.1718 | Reject |
| 0.9 | 0.8 | 0.1445 | Reject |
| 0.9 | 0.9 | 0.0916 | Reject |
For this test, we defined the null hypothesis
5.3 Comparison of different estimators for the mean
This section is dedicated to the performance of the different estimators of the Bernoulli parameter. The MLEs are obtained numerically, and their confidence intervals are constructed. The sample mean satisfies the central limit theorem (9). The
The other estimator for the mean (
To use this estimator, the following conditions must be satisfied (i.)
as
A
Tables 9 and 10 present a comparison of the three estimators of
Comparison of the performance of
|
|
Estimator |
|
|||
|---|---|---|---|---|---|
| 0.1 | 0.2 | 0.3 | 0.4 | ||
| 99 |
|
CIML: 0.1862 | CIML: 0.2258 | CIML: 0.2355 | CIML: 0.2245 |
| CP: 0.8625 | CP: 0.9100 | CP: 0.9275 | CP: 0.9400 | ||
|
|
CIML: 0.1896 | CIML: 0.2325 | CIML: 0.2410 | CIML: 0.2272 | |
| CP: 0.9625 | CP: 0.9475 | CP: 0.9575 | CP: 0.9625 | ||
|
|
CIML: 0.1656 | CIML: 0.2399 | CIML: 0.2946 | CIML: 0.3416 | |
| CP: 0.7875 | CP: 0.9000 | CP: 0.9325 | CP: 0.9500 | ||
| 499 |
|
CIML: 0.0828 | CIML: 0.1030 | CIML: 0.1074 | CIML:0.1012 |
| CP: 0.9050 | CP: 0.9150 | CP: 0.9450 | CP: 0.9300 | ||
|
|
CIML: 0.0848 | CIML: 0.1040 | CIML: 0.1078 | CIML:0.1016 | |
| CP: 0.9450 | CP: 0.9550 | CP: 0.9375 | CP: 0.9275 | ||
|
|
CIML: 0.0889 | CIML: 0.1264 | CIML: 0.1550 | CIML: 0.1797 | |
| CP: 0.8825 | CP: 0.9325 | CP: 0.9250 | CP: 0.9675 | ||
| 999 |
|
CIML: 0.0591 | CIML: 0.0732 | CIML: 0.0761 | CIML: 0.0717 |
| CP: 0.9375 | CP: 0.9400 | CP: 0.9375 | CP: 0.9475 | ||
|
|
CIML: 0.0600 | CIML: 0.0735 | CIML: 0.0762 | CIML: 0.0719 | |
| CP: 0.9375 | CP: 0.9700 | CP: 0.9575 | CP: 0.9550 | ||
|
|
CIML: 0.0678 | CIML: 0.0962 | CIML: 0.1179 | CIML: 0.1362 | |
| CP: 0.8825 | CP: 0.9200 | CP: 0.9300 | CP: 0.9550 | ||
| 4,999 |
|
CIML: 0.0267 | CIML: 0.0328 | CIML: 0.0341 | CIML: 0.0321 |
| CP: 0.9425 | CP: 0.9575 | CP: 0.9475 | CP: 0.9350 | ||
|
|
CIML: 0.0268 | CIML: 0.0329 | CIML: 0.0341 | CIML: 0.0321 | |
| CP: 0.9625 | CP: 0.9600 | CP: 0.9400 | CP: 0.9525 | ||
|
|
CIML:0.0356 | CIML: 0.0505 | CIML: 0.0619 | CIML: 0.0716 | |
| CP: 0.9000 | CP: 0.9200 | CP: 0.9425 | CP: 0.9450 | ||
| 9,999 |
|
CIML: 0.0189 | CIML: 0.0232 | CIML: 0.0241 | CIML: 0.0227 |
| CP: 0.9525 | CP: 0.9550 | CP: 0.9500 | CP: 0.9300 | ||
|
|
CIML: 0.0190 | CIML: 0.0232 | CIML: 0.0241 | CIML: 0.0227 | |
| CP: 0.9500 | CP: 0.9570 | CP: 0.9625 | CP: 0.9450 | ||
|
|
CIML: 0.0270 | CIML: 0.0383 | CIML: 0.0470 | CIML: 0.0542 | |
| CP: 0.9025 | CP: 0.9000 | CP: 0.9500 | CP: 0.9500 | ||
A fixed value of
Comparison of the performance of
|
|
Estimator |
|
|||
|---|---|---|---|---|---|
| 0.6 | 0.7 | 0.8 | 0.9 | ||
| 99 |
|
CIML: 0.2242 | CIML: 0.2381 | CIML: 0.2286 | CIML: 0.1912 |
| CP: 0.9575 | CP: 0.9275 | CP: 0.9250 | CP: 0.8900 | ||
|
|
CIML: 0.2272 | CIML: 0.2410 | CIML: 0.2326 | CIML: 0.1896 | |
| CP: 0.9450 | CP: 0.9575 | CP: 0.9450 | CP: 0.9500 | ||
|
|
CIML: 0.4163 | CIML: 0.4529 | CIML: 0.4841 | CIML: 0.5124 | |
| CP: 0.9450 | CP: 0.9525 | CP: 0.9575 | CP: 0.9700 | ||
| 499 |
|
CIML: 0.1013 | CIML: 0.1071 | CIML: 0.1032 | CIML: 0.0832 |
| CP: 0.9200 | CP: 0.9425 | CP: 0.9550 | CP: 0.9075 | ||
|
|
CIML: 0.1016 | CIML: 0.1077 | CIML: 0.1040 | CIML: 0.0848 | |
| CP: 0.9575 | CP: 0.9475 | CP: 0.9475 | CP: 0.9400 | ||
|
|
CIML: 0.2200 | CIML: 0.2381 | CIML: 0.2543 | CIML: 0.2695 | |
| CP: 0.9450 | CP: 0.9650 | CP: 0.9500 | CP: 0.9775 | ||
| 999 |
|
CIML: 0.0716 | CIML: 0.0759 | CIML: 0.0731 | CIML: 0.0595 |
| CP: 0.9275 | CP: 0.9175 | CP: 0.9400 | CP: 0.9225 | ||
|
|
CIML: 0.0719 | CIML: 0.0762 | CIML: 0.0735 | CIML: 0.0600 | |
| CP: 0.9475 | CP: 0.9350 | CP: 0.9625 | CP: 0.9175 | ||
|
|
CIML: 0.1664 | CIML: 0.1803 | CIML: 0.1926 | CIML: 0.2042 | |
| CP: 0.9525 | CP: 0.9725 | CP: 0.9550 | CP: 0.9375 | ||
| 4,999 |
|
CIML: 0.0321 | CIML: 0.0341 | CIML: 0.0329 | CIML: 0.0268 |
| CP: 0.9400 | CP: 0.9425 | CP: 0.9500 | CP: 0.9400 | ||
|
|
CIML: 0.0321 | CIML: 0.0341 | CIML: 0.0329 | CIML: 0.0268 | |
| CP: 0.9550 | CP: 0.9275 | CP: 0.9525 | CP: 0.9625 | ||
|
|
CIML: 0.0876 | CIML: 0.0946 | CIML: 0.1012 | CIML: 0.1073 | |
| CP: 0.9475 | CP: 0.9525 | CP: 0.9500 | CP: 0.9525 | ||
| 9,999 |
|
CIML: 0.0227 | CIML: 0.0241 | CIML: 0.0233 | CIML: 0.0190 |
| CP: 0.9500 | CP: 0.9500 | CP: 0.9475 | CP: 0.9425 | ||
|
|
CIML: 0.0227 | CIML: 0.0241 | CIML: 0.0233 | CIML: 0.0190 | |
| CP: 0.9500 | CP: 0.9450 | CP: 0.9450 | CP: 0.9500 | ||
|
|
CIML: 0.0664 | CIML: 0.0717 | CIML: 0.0767 | CIML: 0.0813 | |
| CP: 0.9700 | CP: 0.9725 | CP: 0.9700 | CP: 0.9650 | ||
A fixed value
In both cases of
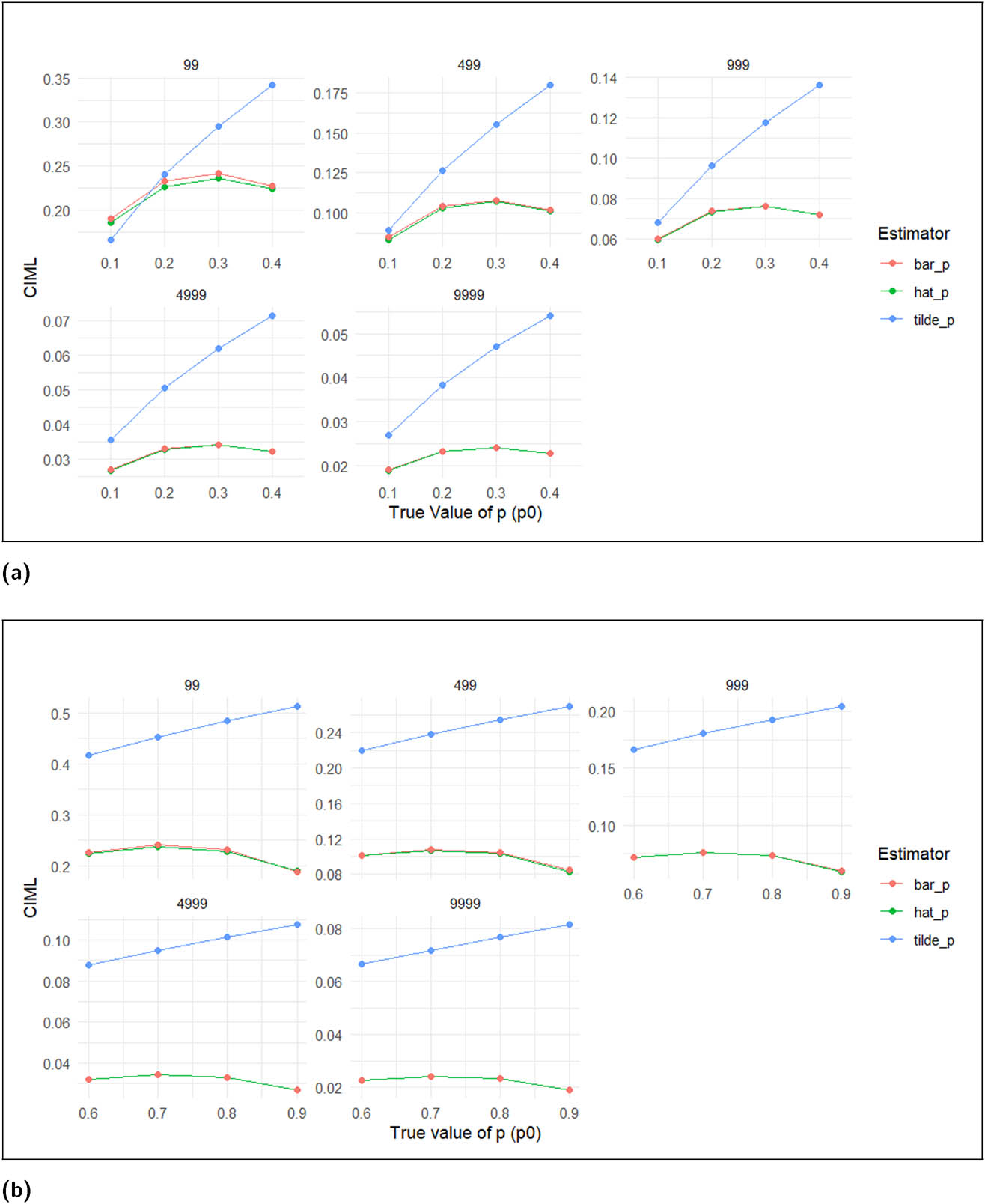
CIML for different values of
Both the MLE and the robust estimator demonstrate sensitivity to sample size, resulting in initially low CPs. However, as the sample size increases, these probabilities approach the desired 95% level. The CPs for the sample mean
The performance of the robust estimator is less optimal with smaller sample sizes but improves as the sample size increases. The robust estimator is designed to be competitive in data containing noise or outliers; however, the data considered here has neither.
While all three estimators provide asymptotically unbiased estimates for the Bernoulli parameter
6 Conclusion
The mixing properties of copula-based Markov chains are highly dependent on the chosen marginal distributions. Some copulas that do not generate mixing with continuous marginals may generate mixing with discrete marginals, so generalizations should be approached with caution. In this article, we have demonstrated that copulas from the Fréchet (Mardia) family generate
Acknowledgments
The authors would like to thank the reviewers for their valuable comments and suggestions, which have greatly contributed to improving this work.
-
Funding information: The authors state no funding involved.
-
Author contributions: All authors share full responsibility for the content of this manuscript. They have jointly agreed to its submission, carefully examined the results, and approved the final version for publication.
-
Conflict of interest: The authors state no conflict of interest.
References
[1] Anderson, W., & Goodman, A. (1957). Statistical inference about Markov chains. The Annals of Mathematical Statistics, 28, 89–110. 10.1214/aoms/1177707039Search in Google Scholar
[2] Bedrick, J., & Aragon, J. (1989). Approximate confidence intervals for the parameters of a stationary binary Markov chain. Technometrics, 31, 437–448. 10.1080/00401706.1989.10488592Search in Google Scholar
[3] Billingsley, P. (1961). Statistical methods in Markov chains. The Annals of Mathematical Statistics, 32, 12–40. 10.1214/aoms/1177705136Search in Google Scholar
[4] Billingsley, P. (1961). Statistical Inference for Markov Processes. Institute of Mathematical Statistics-University of Chicago Statistical Research Monographs, Chicago: University of Chicago Press. Search in Google Scholar
[5] Blum, R., Hanson, L., & Koopmans, L. (1963). On the strong law of large numbers for a class of stochastic processes. Albuquerque, NM: Sandia Corporation. 10.1007/BF00535293Search in Google Scholar
[6] Bradley, R. (2007). Introduction to strong mixing conditions (vol. 1, 2), Kendrick Press. Search in Google Scholar
[7] Brainerd, B., & Chang, M. (1982). Number of occurrences in two-state Markov chains, with applications in linguistics. The Canadian Journal of Statistics, 10, 225–231. 10.2307/3556186Search in Google Scholar
[8] Cogburn, R. (1960). Asymptotic properties of stationary sequences (Vol. 3), Berkeley, CA: University of California Press. Search in Google Scholar
[9] Crow, E. (1979). Approximate confidence intervals for a proportion from Markov dependent trials. Communications in Statistics, Part B-Simulation and Computation, 8, 1–24. 10.1080/03610917908812101Search in Google Scholar
[10] David, F. (1947). A power function for tests of randomness in a sequence of alternatives. Biometrika, 34, 335–339. 10.1093/biomet/34.3-4.335Search in Google Scholar
[11] Darsow, F., Nguyen, B., & Olsen, E. (1992). Copulas and Markov processes. Illinois Journal of Mathematics, 36(4), 600–642. 10.1215/ijm/1255987328Search in Google Scholar
[12] Durante, F., & Sempi, C. (2015). Principles of copula theory. Boca Raton, FL: CRC Press. 10.1201/b18674Search in Google Scholar
[13] Goodman, A. (1958). Simplified run tests and likelihood ratio tests for Markoff chains. Biometrika, 45(1/2), 181–197. 10.1093/biomet/45.1-2.181Search in Google Scholar
[14] Goodman, A. (1959). On some statistical tests for mth order Markov chains, Ann. Math. Statist. 30, 154–164. 10.1214/aoms/1177706368Search in Google Scholar
[15] Ibragimov, A. (1959). Some limit theorems for stochastic processes stationary in the strict sense. Dokl. Akad. Nauk SSSR, 125, 711–714. Search in Google Scholar
[16] Ibragimov, A., & Linnik, V. (1975). Independent and stationary sequences of random processes, Wolters: Nordhoff Publications. Search in Google Scholar
[17] Joe, H. (1997). Multivariate models and multivariate dependence concepts. Boca Raton, FL: CRC Press. 10.1201/b13150Search in Google Scholar
[18] Johnson, C., & Klotz, J. (1974). The atom probe and Markov chain statistics of clustering. Technometrics, 16, 483–493. 10.1080/00401706.1974.10489229Search in Google Scholar
[19] Klotz, J. (1972). Markov chain clustering of births by sex. Proc. Sixth Berkeley Symp. Math. Statist. Prob (vol. 4, pp. 173–185), Berkeley, CA: University of California Press. 10.1525/9780520422001-016Search in Google Scholar
[20] Klotz, J. (1973). Statistical inference in Bernoulli trials with dependence. Annals of Statistics, 1, 373–379. 10.1214/aos/1176342377Search in Google Scholar
[21] Lindqvist, B. (1976). A note on Bernoulli trials with dependence, Scandinavian Journal of Statistics, 5, 205–208. Search in Google Scholar
[22] Longla, M., & Peligrad, M. (2012). Some aspects of modeling dependence in copula based Markov chains. Journal of Multivariate Analysis, 111, 234–240. 10.1016/j.jmva.2012.01.025Search in Google Scholar
[23] Longla, M. (2014). On Dependence Structure of Copula-based Markov Chains. ESAIM: Probability and Statistics, 18, 570–583, DOI: 10.1051/ps/2013052. Search in Google Scholar
[24] Longla, M. (2015). On mixtures of copulas and mixing coefficients. Journal of Multivariate Analysis, 139, 259–265. 10.1016/j.jmva.2015.03.009Search in Google Scholar
[25] Longla, M., & Peligrad, M. (2021). New robust confidence intervals for mean under dependence, Journal of Statistics Planning and Inference, 211, 90–106. 10.1016/j.jspi.2020.06.001Search in Google Scholar
[26] Muia, M. (2024). Dependence and Mixing for Perturbations of Copula-based Markov Chains, Ph.D. thesis, ProQuest, Ann Arbor, MI: University of Mississippi. Search in Google Scholar
[27] Nelsen, R. (2006). Introduction to Copulas. Springer Series in Statistics (2nd ed.), New York: Springer-Verlag. Search in Google Scholar
[28] Philipp, W. (1969). The central limit problem for mixing sequences of random variables. Zeitschrift für Wahrscheinlichkeitstheorie und verwandte Gebiete, 12(2), 155–171. 10.1007/BF00531648Search in Google Scholar
[29] Price, B. (1976). A note on estimation in Bernoulli trials with dependence. Communication in Statistics, Part A-Theory and Methods, 5, 661–671. 10.1080/03610927608827383Search in Google Scholar
[30] Sklar, A. (1959). Fonctions de repartition an dimensions et leurs marges (vol. 8, pp. 119–231), Paris: Publ. inst. statist. University. Search in Google Scholar
[31] Wilks, S. (1938). The large sample distribution of the likelihood ratio for testing com posite hypothese. Ann. Math. Stat. 9, 60–62. 10.1214/aoms/1177732360Search in Google Scholar
© 2025 the author(s), published by De Gruyter
This work is licensed under the Creative Commons Attribution 4.0 International License.
Articles in the same Issue
- Research Articles
- Tree-based conditional copula estimation
- Fast estimation of Kendall's Tau and conditional Kendall's Tau matrices under structural assumptions
- On bivariate Archimedean copulas with fractal support
- A point on discrete versus continuous state-space Markov chains
- Dependence modeling in general insurance using local Gaussian correlations and hidden Markov models
- Review Article
- Generalized Hoeffding-Fréchet functionals and mass transportation
Articles in the same Issue
- Research Articles
- Tree-based conditional copula estimation
- Fast estimation of Kendall's Tau and conditional Kendall's Tau matrices under structural assumptions
- On bivariate Archimedean copulas with fractal support
- A point on discrete versus continuous state-space Markov chains
- Dependence modeling in general insurance using local Gaussian correlations and hidden Markov models
- Review Article
- Generalized Hoeffding-Fréchet functionals and mass transportation