On the usefulness of formal judgment tasks in syntax and in second-language research: The case of resumptive pronouns in English, Turkish, and Mandarin Chinese
-
John Hitz
 and
Elaine J. Francis
and
Elaine J. Francis

Abstract
Gibson and Fedorenko (2013, The need for quantitative methods in syntax and semantics research, Language and Cognitive Processes 28(2), 88–124) have argued against the continued use of informally collected acceptability judgments as the primary methodology in theoretical syntax and semantics research. We provide further support for their position with data from Mandarin and Turkish-language judgment tasks which examined the acceptability of resumptive pronouns (RPs) in relative clauses. Based on previous studies which relied on informal judgments, we expected that RPs should be permitted in certain types of Mandarin relative clauses, but ungrammatical in comparable Turkish relative clauses. The results failed to replicate this contrast: RPs were more acceptable than expected in Turkish, and less acceptable than expected in Mandarin. Furthermore, the Mandarin Chinese experiment showed an unexpected gradient effect. We argue that these results challenge existing theoretical accounts, support the more widespread adoption of experimental tasks in theoretical linguistics and in second-language research, and consistently support the Filler-Gap Domain complexity ranking as proposed by Hawkins (2004, Efficiency and complexity in grammars, Oxford: Oxford University Press). We use the complexity ranking and its supporting evidence as a case study demonstrating that quantitative data, such as the evidence obtained from formal sentence judgment tasks, are indispensable in the defense or criticism of linguistic theories.
1 Introduction
Judgments of the acceptability of any given syntactic structure are the bedrock of arguments in linguistics and in second language acquisition. To take a well-known example, wh-islands constraints have received a great deal of attention in mainstream linguistics and in the second language acquisition literature:
*The boy whoi Mary described [the way [that Bill attacked ti]] is here.
(Hawkins and Chan 1997: 191)
Based on acceptability judgments such as (1), practitioners of mainstream generative grammar have argued that knowledge of the constraints forbidding illicit wh-movements, whether formulated in terms of Shortest Move (Chomsky 1995), Subjacency (Chomsky 1977), or some other principle, must be innately specified in Universal Grammar (henceforth, UG). Second language acquisition theorist Roger Hawkins (2005) accepts the argument that acquisition of an uninterpretable wh-feature (a feature invisible to the semantic grammar component) allows native speakers of English to understand that the wh-movements exemplified in in (1) are illicit, and goes on to argue that, after the critical period (i. e., as teens or adults), native speakers of languages such as Cantonese or Mandarin Chinese cannot obtain the uninterpretable feature that is necessary to develop a sensitivity to movement violations such as (1), because this feature is not selected during their acquisition of Chinese. Without prolonged exposure to English during the critical period, it will be impossible for them to develop an interlanguage grammar allowing wh-movement, [1] and consequently, sensitivity to constraints on wh-movement in English. For this reason, it is argued, adult L1 Chinese learners of English find English sentences such as (1) acceptable. Thus, acceptability judgments of sentences such as (1) (and their Chinese equivalents) are part of the foundation of arguments about the nature of the language faculty, and about the nature of second language acquisition.
The viability of any linguistic argument based on acceptability judgments can only be as sound as its foundation–the acceptability judgments themselves. Such judgments can vary according to many different factors, including declarative knowledge of grammar rules, dialect, discourse context, frequency of use, and the limitations of working memory (Schütze 1996; Hofmeister and Norcliffe 2013). For these reasons, some prominent linguists have argued that acceptability judgments be performed formally or experimentally whenever possible so as to avoid the formulation of a complex chain of reasoning based on faulty foundations or premises (Gibson and Fedorenko 2013; Gibson et al. 2013; Wasow and Arnold 2005). Traditionally, however, acceptability judgments as reported in the syntax literature have been informal, meaning that they are not administered to large numbers of participants, and do not employ a factorial design or tests of statistical significance, as is the case for formal acceptability judgment tasks. Informal acceptability judgments may consist of one researcher using personal introspection or consulting with one native speaker of the language to determine the acceptability of a given construction (Gibson and Fedorenko 2013), or a linguist who shares his or her judgments with a group of other linguists at a conference (Sprouse and Alemeida 2013a). Defenders of informal acceptability judgments counter that the use of formal judgment tasks is not usually necessary, and that the use of informal judgments rarely leads to arguments based on mistaken premises (Phillips 2009; Sprouse and Alemeida 2013a; Sprouse et al. 2013). Sprouse and Almeida (2013b: 202) claim that existing data based on informal acceptability judgments is in no way flawed: “… the current state of evidence suggests that questions about the veracity of existing judgment data may have been a (historically driven) distraction: there appears to be no evidence that the existing data is faulty, and growing evidence that the traditional methods are appropriate for the majority of phenomena of interest to syntacticians.”
Following Gibson and Fedorenko (2013) and Gibson et al. (2013), we endorse the use of formal acceptability judgment tasks (henceforth AJTs) or other quantitative methods to ascertain the nature of the types of grammatical constraints that might affect a language. The current study presents three previously unpublished experiments from Hitz’s (2012) dissertation, providing further support for this position. While Gibson and Fedorenko’s (2013) experiments focused on implications for mainstream research in syntax, the experiments reported here have important implications both for mainstream syntax research and for research in second language acquisition (henceforth SLA). We will show how formal AJTs can provide data relevant to the accurate formulation of grammatical constraints in native language grammars, which can in turn inform our understanding of potential L1 transfer effects in the interlanguage grammars of L2 learners.
Hitz intended to elucidate the impact of language transfer in the second language acquisition of English relative clauses (henceforth, RCs) by native speakers of Turkish and Chinese, with respect to the acceptability of resumptive pronouns in RCs. Resumptive pronouns are pronouns which occur in the original (non-displaced) position of a displaced noun phrase, in a position where an empty gap would otherwise go. Although resumptive pronouns (henceforth RPs) commonly occur in RCs and other filler-gap constructions across the world’s languages, languages differ as to whether such pronouns are used productively or not. In English, for example, RPs have a marginal status and are typically judged by native speakers as unacceptable, although they do occur in spontaneous speech (Asudeh 2012: 41–43). In languages such as Hebrew and Arabic, however, RPs are used productively and are fully grammatical (or even required) in certain types of clauses (Asudeh 2012: 27). Furthermore, among languages which allow the productive use of resumptive pronouns, there are differences with regard to which structural positions license RPs and which positions license gaps. Such cross-linguistic differences in the productivity and structural licensing of RPs create challenges for L2 learners. For example, L2 learners of English sometimes produce and/or accept ungrammatical sentences such as in (2a):
*The relativesi who we visited themi last night enjoyed the evening.
The relativesi who we visited __i last night enjoyed the evening.
In (2a), the speaker has inserted a RP (them) in what would normally be the empty gap (or trace) position of the extracted object, as indicated by ‘__’ in (2b). Relying on the informal acceptability judgments put forth in the linguistic literature on English, Chinese, and Turkish RCs, Hitz (2012) assumed that Turkish and English share a common structural feature: both languages license only gaps (not RPs) in simple (monoclausal) relative clauses, as illustrated in (2a)–(2b). This is in contrast to Chinese RCs, in which RPs are said to be acceptable in non-subject positions. Thus, the Chinese equivalent of (2a) should be acceptable. Given this purported distribution of RPs in Turkish and Chinese RCs, Hitz (2012) hypothesized that native speakers of Chinese would accept RPs in English RCs, as in (2a), at a higher rate than native speakers of Turkish would, due to the effects of L1 transfer. He further hypothesized that for reasons related to processing complexity (Hawkins 2004), RPs would be beneficial for L2 learners’ processing of relative clauses, with this benefit showing up most strongly in the most complex clause types. Thus, even the Turkish group might accept RPs at a higher rate than the control group, and both learner groups should accept RPs in prepositional object relatives at a higher rate than in subject relatives. Contrary to the L1 transfer hypothesis, no statistically significant group differences between the L1 Chinese and L1 Turkish speakers were found. Rather, the two learner groups (but not the native speaker group) accepted RPs to a greater extent in direct object and prepositional object RCs as compared with subject RCs (as would be expected on a processing account), but there was no difference between the two learner groups (thus apparently no L1 transfer effect).
To investigate the reason for this lack of group differences, Hitz conducted two follow-up experiments investigating the acceptability of RPs in Turkish RCs and in Mandarin Chinese RCs according to native speakers of these languages. The results show that a likely reason for a lack of group differences in the English tasks can be traced to faulty assumptions about the distribution of RPs in Turkish and Chinese. Specifically, these follow-up experiments revealed that RPs were more acceptable than expected in Turkish RCs, and less acceptable than expected in Chinese RCs. Thus the two languages were much more similar to each other than the prevailing linguistics literature about the RP distributions in both languages had indicated. As to the reason for the difference between the control group (which consistently failed to accept RPs) and the two learner groups (which accepted RPs in non-subject positions to some extent), either a transfer account or a processing account is equally plausible given the similar results for the Turkish and Chinese tasks, and in fact both of these factors could be at work at the same time. The data from these experiments do not let us draw any firm conclusions on this matter.
To sum up, the apparently faulty transfer hypotheses formulated by Hitz (2012) in his investigations of the second-language acquisition of English RCs can be attributed to the trust he placed in the informal judgments of the distribution of RPs as reported in linguistic studies of Chinese and Turkish RCs. The results of Hitz’s (2012) experiments have both theoretical and methodological implications. For theories of formal syntax, the results point toward revised formulations of the anti-locality conditions proposed to account for the different RP distributions in Turkish (Kornfilt 2000) and Chinese (Hu and Liu 2007): the restrictions on allowable RP positions apparently need to be more permissive for Turkish but stricter for Mandarin Chinese. From our own functionalist perspective, these data lend support to Hawkins’ (2004) model of performance-grammar correspondence and, more specifically, the idea that RP distributions across languages are at least partially a reflex of processing complexity as defined in terms of filler-gap domain size. Notably, both the similarities and differences that were found between RP distributions in Turkish and Chinese corresponded to filler-gap domain sizes for these languages as defined by Hawkins (2004). Finally, with respect to methodology in linguistics, it appears that using formal AJTs or other quantitative measures can reduce the possibility that SLA researchers will make mistaken claims for or against language transfer, or that theoretical linguists will use inaccurate linguistic descriptions to build theories of syntax.
In the following pages, we first of all discuss the use and non-use of experimental data as the basis for argumentation in linguistics, and then present one of the reasons why experimental evidence is necessary: to provide a clear pattern of data that can support a particular theory. We then examine the data from three AJTs, as previously summarized.
1.1 The use and non-use of formal AJTs in mainstream linguistics
Phillips (2009) claimed that there are no cases in which faulty informal acceptability judgments have become the basis for faulty linguistic theorizing. In response, Gibson and Fedorenko (2013) cite several previous studies and three additional cases in which apparently faulty informal judgments have formed the basis for theoretical claims in the literature. Of the three cases they discuss, the first involves multiply embedded relative clauses in English, while the second and third involve English interrogatives containing multiple wh-expressions. For all three cases, the authors provide experimental evidence showing that formally collected acceptability judgments fail to replicate grammaticality contrasts presented in the literature. In their reply to Gibson and Fedorenko (2013), Sprouse and Almeida (2013a) come to the defense of informal acceptability judgments. They argue that little can be concluded from the three case studies cited by Gibson and Fedorenko (2013) due to the small size and the non-random nature of the sample, and go on to cite a 95 % convergence rate between the informal judgments of linguistic structures provided by researchers in randomly selected issues of Linguistic Inquiry (for 150 minimal pairs) and judgments of these same structures provided by experimental participants in a series of formal acceptability judgment tasks developed by Sprouse et al. (2013) (for 2,400 items based on the structures in the original 150 minimal pairs). In short, of the total number of informal acceptability judgments investigated by Sprouse et al., only 5 % of them were not in agreement with the results of formal AJTs of the same linguistic phenomena. These results lead Sprouse and Almeida (2013a) to conclude that neither formal nor informal acceptability judgment tasks are necessarily better than one another in any absolute sense, and that selecting the type of judgment task depends on the type of linguistic phenomena that are being investigated. For Sprouse and Almeida (2013a), formal acceptability judgments should be preferred in two areas: firstly, in testing hypotheses about the roles of syntactic constraints versus working memory constraints, and secondly, in exploring the mechanisms that underlie gradient acceptability judgments.
An issue that Sprouse and Almeida (2013a) do not address is how linguists can identify those gradient patterns of judgments that might shed light on the relative contributions of gradient and non-gradient mechanisms in sentence generation. If linguists primarily use informal acceptability judgments, they run the risk of misidentifying gradient patterns as categorical patterns. As Wasow (2007) observes, informal acceptability judgments as used in research on generative grammar tend to allow only two options: “acceptable” or “unacceptable,” and may therefore potentially misconstrue a gradient phenomenon in need of a more complex explanation as a simpler categorical phenomenon. An examination of the English and Chinese-language AJTs to be discussed in Sections 2 and 3 reveal a gradient pattern of data that informal judgments of the same linguistic phenomena did not show, and therefore demonstrates that the use of formal acceptability judgments may shed light on linguistic phenomena in need of a more sophisticated explanation than can be provided by means of a categorical grammatical rule.
Even aside from the issue of gradience, the current study shows a different relative pattern of judgments than expected for the acceptability of RPs in both Turkish and Chinese. Given the relatively low error rate reported in Sprouse et al. (2013), why should it be that two experiments on two different languages and populations of speakers yielded unexpected patterns of results? It could be that certain types of linguistic phenomena (in this case, RP distributions) may be more prone to variability across speakers or errors in informal judgments than others. Given that the nature of the phenomenon was what the two experiments had in common, this provides a plausible post-hoc explanation for the results. However, as Gibson et al. 2013: 233) point out in their reply to Sprouse and Almeida (2013a), there is no way of knowing in advance which grammaticality contrasts will be among those that cannot be replicated in a formal experiment. Thus, there is no reliable manner of determining whether to trust informal judgments in any particular case, except perhaps for obvious constraints on constituent order (e. g., *book a), for which informal judgments could almost certainly be trusted.
If informal judgments are not always reliable for showing contrasts in grammaticality, as Gibson et al. (2013) argue, then neither are they up to the task of theory building:
The experiments are necessary in all cases because they provide the only way to objectively measure discrepancies between theory and reality. Theories evaluated only by the intuitions of the investigators involved, are almost necessarily post hoc. This is because, lacking quantitative standards, we have little possibility to be wrong and discover discrepancies between theory and data. Such discrepancies drive scientific progress, and while expert intuitions provide a rich source of hypotheses to investigate, reliable evaluation of such hypotheses requires more sophisticated quantitative methods.
(Gibson et al. 2013: 10)
The AJTs presented here support Gibson et al. (2013) position: they cast doubt on previous theoretical proposals for syntactic constraints on RPs in Turkish and Mandarin, while supporting the Filler-Gap Domain complexity ranking for relative clause types as proposed by Hawkins (2004). The problems for existing theoretical proposals will be elaborated within the experiment discussions in Sections 3–4. To highlight the positive contribution of this work in supporting Hawkins’ (2004) theory, we outline the major features of the theory in the following section.
1.2 Hawkins’ (2004) theory of RP use and relative clause complexity
Hawkins (2004) presents a theory of RP use and relative clause complexity which is embedded within his more general model of performance-grammar correspondence. The Performance-Grammar Correspondence Hypothesis (henceforth, PGCH), on which this general model is based, is as follows:
Grammars have conventionalized syntactic structures in proportion to their degree of preference in performance, as evidenced by patterns of selection in corpora and by ease of processing in psycholinguistic experiments.
(Hawkins 2004: 3)
The hypothesis states that many syntactic constraints which disallow a particular structural configuration have their origins in constraints on language processing, and that we can find evidence for this in patterns of usage and in psycholinguistic experiments on languages that are not subject to these syntactic constraints but which instead allow more than one syntactic option. Applied to the case of RPs, we can observe that crosslinguistically, RPs tend to be grammatically required more often as RC complexity increases. This observation was first developed by Keenan and Comrie (1977) and formulated in terms of a Noun Phrase Accessibility Hierarchy that measured complexity in terms of the function of the relativized element, where subject RCs are simplest, followed by direct object, indirect object, oblique, and genitive RCs. In Keenan and Comrie’s (1977) sample of 26 languages that have grammatically licensed RPs, all require a gap in subject RCs, the majority require a gap in direct object RCs, and the majority require an RP in indirect object and oblique RCs. Likewise, in performance, we can observe that children acquiring their first language (McKee and McDaniel 2001) and adults acquiring a second language (Tezel 1998) are more likely to produce or accept an “ungrammatical” RP (i. e., an RP that is used in a position deemed ungrammatical by adult native speakers of the target language) as RC complexity increases. Similarly, for languages that optionally allow either gap or RP in particular positions, such as Hebrew (Ariel 1999) and Cantonese (Francis et al. 2015), corpus and experimental data show that speakers are more likely to produce an RP as RC complexity increases. These three types of evidence (crosslinguistic patterns of syntactic constraints, language acquisition, and language use) support Hawkins’ proposal that RP use (whether grammatically required or not) is linked to RC complexity, which is in turn linked to processing complexity.
As a refinement of Keenan and Comrie’s Noun Phrase Accessiblity Hierarchy, Hawkins (1999, 2004) proposes a revised ranking of RC complexity based on the notion of Filler-Gap Domain, which is defined as follows:
An FGD [Filler-Gap-Domain] consists of the smallest set of terminal and non-terminal nodes dominated by the mother of a filler and on a connected path that must be accessed for gap identification and processing; for subcategorized gaps the path connects the filler to a co-indexed subcategorizor and includes, or is extended to include, any additional arguments of the subcategorizor on which the gap depends for its processing; for non-subcategorized gaps the path connects the filler to the head category that constructs the mother node containing the co-indexed gap; all constituency relations and co-occurrence requirements holding between these nodes belong in the description of the FGD.
(2004: 175)
The terms filler, subcategorizer, and gap are illustrated in the following example:
[NPThe girli [whoiSarah helped ___i]]
In this example, the filler, girl, must be held in working memory until it can be associated or co-indexed with the appropriate gap after helped. [2] The subcategorizor, helped, is the constituent that determines the RC’s argument structure. In this case, the subcategorizor requires an agent, Sarah, and a theme. The filler-gap domain consists of the constituents and nodes after the. Following Hawkins’ basic style of tree diagram, Figure 1 illustrates the FGD in sentence (3):
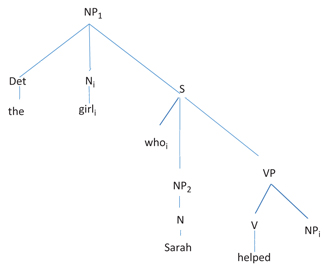
The FGD in an English RC (Adapted from Hawkins 1999: 250).
The FGD in sentence (3) consists of 8 nodes: Ni, the filler girl; NP1, the mother of the filler; S; the filler copy (whoi); NP2; N (Sarah); VP; and V, the subcategorizer helped. The FGD in an English subject RC consists of 6 nodes (since the VP is not included), and the FGD of an RC with a relativized object of a preposition consists of 10 nodes (since PP and P are added). [3] Thus, for English, Hawkins’ FGD complexity ranking aligns with Keenan and Comrie’s Noun Phrase Accessibility Hierarchy: subject < direct object < oblique object.
As detailed in the following sections, the results of all three experiments are consistent with the predictions of Hawkins’ (2004: 178–180) complexity ranking, and as such, provide support for the PGCH. For English, the two non-native speaker groups rated direct object and prepositional object RCs containing an RP slightly (but significantly) higher than subject RCs containing an RP. This can be interpreted as a performance-based complexity effect, although (as we will see) an account based on L1 transfer cannot be ruled out. For Mandarin Chinese, native speakers rated subject and direct object RCs with an RP as unacceptable, while rating indirect object RCs with an RP as marginally acceptable. Although the similarity between subject and object RCs was unexpected based on previous studies that relied on informal judgments, this similarity is predicted by Hawkins’ complexity ranking for Chinese (which, to be explained below, differs from the complexity rankings for English and Turkish in that subject RCs and object RCs have equal FGDs). Finally, for Turkish, native speakers rated direct object and indirect object/oblique RCs with an RP significantly higher than subject RCs with an RP. Again, the results were contrary to studies of Turkish syntax which have claimed that RPs are unacceptable in all three positions, but compatible with Hawkins’ complexity ranking.
In our discussion of each experiment that follows, we will show how Hawkins’ FGD complexity ranking can help explain the pattern of data we have obtained, and we will argue that informal sentence judgments, as used in most of the previous studies of the RP distributions in Mandarin and Turkish, could not provide a convincing basis to support or refute a particular theoretical position.
2 Acceptability judgment task 1: English
In order to illustrate our point regarding the need for quantitative data in linguistic argumentation, and to provide support for the Hawkins’ FGD complexity ranking, we turn to Hitz’s study of language transfer in second language acquisition (SLA). SLA scholars have hotly debated the importance of language transfer, and have not been able to reach a consensus about its importance (Odlin 2003). Because further investigation seemed justified, an English-language acceptability judgment task was designed and administered to native speakers of English, Mandarin Chinese, and Turkish.
2.1 Hypotheses
The majority of published studies appear to agree that RPs are highly acceptable in some Chinese RCs, whereas they are for the most part banned from English and Turkish RCs. [4] That being the case, we postulated that L1 influence would cause L1 Mandarin Chinese speakers to find RPs in English RCs with relativized direct objects and objects of prepositions more acceptable than L1 Turkish speakers at statistically significant levels. This hypothesis was motivated by SLA studies performed by Gass (1979) and Hyltenstam (1984), which claim that L2 learners are likely to accept resumptive pronouns in the L2 if they are grammaticalized in the L1. Furthermore, we postulated that both L2 groups would find RPs in English RCs most acceptable in prepositional object RCs, somewhat less acceptable in direct object RCs, and least acceptable in subject RCs, due to the increasing levels of processing complexity in these three RC types, as operationalized in terms of Hawkins’ (2004) idea of filler-gap domains as discussed previously in Section 1.2. In contrast, native English speakers should find RPs categorically unacceptable across all RC types. [5]
2.2 Methodology
2.2.1 Design
An acceptability judgment task was constructed following principles described by Cowart (1997). The experimental items in the task consisted of eight token sets representing six experimental conditions each for a total of 48 experimental items. A sample token set is given in Table 1.
Sample token set for acceptability judgment task 1: English.
| Subject RC with Resumptive Pronoun |
| The relativesi [whoitheyi visited us last night] enjoyed the evening. |
| Subject RC with Gap |
| The relativesi [whoi____i visited us last night] enjoyed the evening. |
| Direct Object RC with Resumptive Pronoun |
| The relativesi [whoi we visited themi last night] enjoyed the evening. |
| Direct Object RC with Gap |
| The relativesi [whoi we visited ____i last night] enjoyed the evening. |
| Prepositional Object RC with Resumptive Pronoun |
| The relativesi [who we paid a visit to themi] last night enjoyed the evening. |
| Prepositional Object RC with Gap |
| The relativesi [who we paid a visit to ___i] last night enjoyed the evening. |
In a token set, the experimental items have the same vocabulary, and differ from one another only in terms of the factors manipulated by the experimenter. As shown in the sample token set in Table 1, two factors were manipulated: Pronoun (presence/absence of a RP), a factor with two levels, and RC Type, a factor with three levels (Subject, Direct Object, Prepositional Object) that differ from one another in their position on the FGD complexity ranking, as discussed in Section 1.2 above.
Hawkins (1999, 2004) argues that resumptive pronouns aid in the processing of RCs, and tend to increase in acceptability across languages with the size of the filler-gap domain: “The presence of this resumptive or copy pronoun can be argued to make the processing of head and relative clause easier, since an empty category no longer needs to be inferred from its environment but is given formal expression” (257). We therefore expected that the non-native English speakers would be more likely to accept RPs in the direct and prepositional object conditions than in the simpler subject RCs.
Table 1 illustrates that the experimental items had relativized subjects, direct objects, and objects of prepositions, RC types whose FGDs increase in length respectively – 6 in a gapped subject RC, 8, in a gapped direct object RC, and 10 in gapped RC with a relativized object of a preposition.
For the third relative clause type shown in Table 1, items with stranded prepositions were used: The relatives who we paid a visit to last night enjoyed the evening. Alternatively, fronted prepositions could have been used, such as The relatives to whom we paid a visit last night enjoyed the evening. RCs with stranded prepositions were chosen in light of Bardovi-Harlig’s (1987) finding that L2 English learners acquired stranded prepositions before they acquired pied-piped prepositions, even in EFL contexts, mainly because stranded prepositions occur more frequently in the L2 input with which L2 English learners are surrounded.
Fifty-six filler sentences of varying length and acceptability were combined with the 48 experimental sentences for a grand total of 104 items. All items were randomized according to procedures described in Cowart (1997) and organized in the form of a written questionnaire which was distributed to participants in two versions in which items were ordered differently from one another. Participants were asked to rate items on a 4 point scale in which 1=certainly incorrect, 2=possibly incorrect, 3=possibly correct, and 4=certainly correct.
2.2.2 Participants
Thirty-three native speakers of Turkish, 35 native speakers of Mandarin Chinese, and 34 native speakers of English were recruited from the student body at Purdue University in West Lafayette, Indiana, USA, to participate in the study. They were majoring in a variety of academic subjects, and none had coursework or training in linguistics. Demographic data concerning the participants appear in Table 2.
Participants’ demographic data for acceptability judgment task 1: English.
| Number of Participants | Mean Age | Sex | |
|---|---|---|---|
| L1 Mandarin Chinese | 35 | 22 | 11 Males,24 Females |
| L1 Turkish | 33 | 28 | 17 Males, 16 Females |
| Native Speakers of English | 34 | 21 | 17 Males, 17 Females |
2.2.3 Experimental procedures
At the beginning of each testing session, biodata forms were distributed. Non-native speakers completed the Michigan Placement Test in approximately 30 minutes, followed by a short break of 10–15 minutes. [6] All participants completed a written questionnaire containing the English-language sentence judgment task. The instructions, derived from Cowart (1997: 57), were read aloud, after which participants answered four practice items with the facilitation of the experimenter. The non-native speakers completed the task in approximately 45 minutes to 1 hour, while the native speakers took about 30 minutes to complete the same task. All participants were paid 10 dollars for each hour of their participation.
2.2.4 Statistical tests used to analyze the data
This study employs a 3-way factorial research design, with Language (L1 Background) as a between-subjects factor. RC Type and Pronoun (Presence/Absence of RP) were within-subjects factors.
A mixed-model analysis of variance was used to analyze the patterns of acceptability judgments. This procedure is a parametric statistical test that can ideally state that the variation between the different L1 groups’ acceptability judgments is caused by an interaction of three different fixed factors: L1 background, RC type, and the presence/absence of RPs. In this respect, it is similar to standard ANOVA procedures. The test differs from a standard ANOVA in that it has one random factor (research participants) in addition to the fixed factors, [7] and in its output, which does not include an error term because it is already factored into the statistical test itself (SAS Institute Inc. 1999: 2175). Despite the fact that this test does not include an error term in its output, the survey results have been adjusted so that the effects of sample sizes can be accounted for. Least Squares Means tests with Tukey adjustments were applied to the data to identify which particular differences between L1 groups’ acceptability judgments caused main effects and interactions. [8]
2.3 Results and discussion
The results of the Michigan English Placement test administered to L1 Turkish and Chinese speakers show almost identical results. Out of a total of 80 multiple-choice questions, the L1 Chinese speakers answered 91 % correctly, and the L1 Turkish speakers answered 92 % correctly. A Mann-Whitney test showed no statistically significant differences between the proficiency test scores (z=−0.542, p=0.410).
None of the transfer-related hypotheses were supported; there were no statistically significant differences between native speakers of English, Turkish, and Chinese in their judgments of RCs with relativized direct objects and objects of prepositions in the resumptive condition. [9]Figure 2 shows that there were few outstanding differences between the native and non-native speakers on AJT 1.
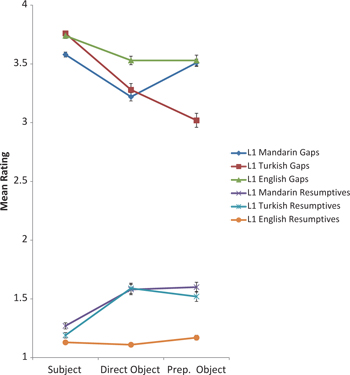
English AJT: Mean ratings of experimental items.
The data from AJT 1 demonstrate another reason to perform formal sentence judgment tasks: their ability to depict gradient patterns of data. Although AJT 1 did not show a predicted transfer effect, it did display a gradient pattern of data in that the non-native speakers of English found non-subject RCs in the RP condition to be more acceptable than the subject RCs. Statistical comparisons within L1 groups showed that L1 Turkish and L1 Chinese speakers both found direct object RCs with RPs to be more acceptable than subject RCs with RPs. For L1 Chinese speakers, this difference approached significance (t=3.410, p=0.069), while for L1 Turkish speakers this difference was highly significant (t=4.190, p=0.004). Similarly, within-groups comparisons showed that the L1 Chinese speakers found RCs with prepositional RCs in the RP condition to be more acceptable than subject RCs with RPs at a statistically significant level (t=3.640, p=0.033). For Turkish speakers, on the other hand, the apparent difference between prepositional RCs with RPs and subject RCs with RPs was not significant (t=2.74, p=0.355). To the extent that RPs were more acceptable in non-subject positions as compared with subject positions, these findings for the two L2 groups are consistent with Hawkins’ FGD complexity ranking and may reflect a slightly greater processing cost for comprehending non-subject RCs.
In contrast to the non-native speakers, within-groups comparisons of native English speakers’ judgments of items with RPs showed no statistically significant differences: the comparison of ratings assigned to subject RCs in the resumptive condition with ratings assigned to direct objects with RPs was not statistically significant (t=−0.120, p=1.000), nor was the comparison between ratings assigned to subject RCs with RPs and RCs with relativized objects of prepositions with RPs (t=0.480, p=1.000). The consistently low ratings given to RCs with RPs by native adult English speakers are congruent with informal acceptability judgments of these structures, and with experimental evidence obtained by McKee and McDaniel (2001).
As stated earlier, we reasoned that the absence of any transfer effect might have been caused by incorrect assumptions about the distributions of RPs in Chinese and Turkish RCs. In order to explore this possibility, we designed AJTs in these languages.
3 Acceptability judgment task 2: Mandarin Chinese
3.1 Hypotheses
In this study, our hypotheses were based on the “consensus opinion” mentioned in the introduction, which states that Mandarin Chinese does not allow RPs in RCs with relativized subjects, that they are optional and alternate with gaps in RCs with relativized direct objects, and that they are mandatory in RCs with relativized indirect objects and objects of prepositions (Keenan and Comrie 1977; Xu and Langendoen 1985; Hawkins and Chan 1997; Hsiao 2003; Hu and Liu 2007). Therefore, we expected sentences with RPs to receive low acceptability ratings in subject RCs, but significantly higher ratings in direct object and indirect object RCs. With respect to gapped clauses, we expected subject RCs and direct object RCs to receive high acceptability ratings, with significantly lower ratings given to indirect object RCs.
3.2 Methodology
3.2.1 Design
As illustrated in (4), Chinese has an unusual word order typology in which SVO clause order is combined with a head-final NP structure. The relative clause (Paul zhaogu de) precedes its head noun (nuren), and thus the gap (in this case, an object gap) precedes its filler.
| [SPaul | [VP | Zhaogu__i] | de] | nage | nureni | likai | le |
| Paul | look.after__ | REL | DET | woman | leave | PERF |
‘The woman that Paul looked after has left’
Due to this unusual word order, Hawkins (2004: 180) proposes that subject RCs and object RCs do not differ in terms of FGD in a transitive clause. Thus, the RC types represented in our Chinese stimuli showed a slightly different pattern of FGDs than those in the English stimuli. Because the direct object intervenes between the subcategorizing verb and the head noun, the FGD for a subject RC in a transitive sentence must include the direct object (unlike in English, where the direct object does not intervene between the head noun and the verb). Therefore, for a transitive clause structure, both subject and object RCs have a FGD of 8. [10] Indirect object RCs (which are comparable to the prepositional object RCs in our English stimuli) must include both the subject and the direct object within the FGD, increasing the FGD to 10 in our stimuli. A tree diagram in the style of Hawkins (2004: 178) illustrates the RC from sentence (4) in Figure 3.
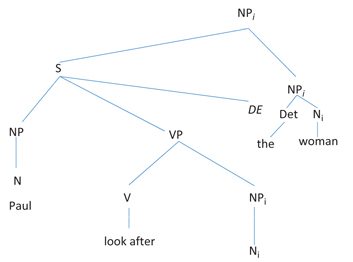
The FGD of a Chinese RC.
The experimental items in AJT 2 consisted of 24 sentences containing Mandarin Chinese RCs with relativized subjects, direct objects, and indirect objects. The design was almost identical to that of the English AJT, except that there was only one participant group: native speakers of Mandarin. As in the English AJT, two within-group factors were manipulated: RC Type (subject, direct object, and indirect object), and Pronoun (presence/absence of RP). Experimental items consisted of four token sets, which were developed with the assistance of a native speaker of Mandarin Chinese and an L2 speaker of Mandarin Chinese, both of whom had training in linguistics. A sample token set illustrating all six conditions can be seen in Table 3. [11]
Sample token set for acceptability judgment task 2: Mandarin Chinese.
| Subject RC with Resumptive Pronoun | ||||||||||
| [S tai | zhaogu | Paul | de] | nage | nureni | likai | le | |||
| 3SG | look.after | Paul | REL | DET | woman | leave | PERF | |||
| ‘The woman that she looked after Paul has left’ | ||||||||||
| Subject RC with Gap | ||||||||||
| [S__i | VP zhaogu | Paul | de] | nage | nureni | likai | le | |||
| __ | look.after | Paul | REL | DET | woman | leave | PERF | |||
| ‘The woman that looked after Paul has left’ | ||||||||||
| Direct Object RC with Resumptive Pronoun | ||||||||||
| [S | Paul | [VP | zhaogu | tai] | de] | nage | nureni | likai | le | |
| Paul | look.after | 3SG | REL | DET | woman | leave | PERF | |||
| ‘The woman that Paul looked after her has left’ | ||||||||||
| Direct Object RC with Gap | ||||||||||
| [S | Paul | [VP | zhaogu | __i] | de] | nage | nureni | likai | le | |
| Paul | look.after | __ | REL | DET | woman | leave | PERF | |||
| ‘The woman that Paul looked after has left’ | ||||||||||
| Indirect Object RC with Resumptive Pronoun | ||||||||||
| [S | Paul | [VP | gei | tai | zhaogu] | de] | nage | nureni | likai | le |
| Paul | give | 3SG | care | REL | DET | woman | leave | PERF | ||
| ‘The woman that Paul showed concern to her has left’ | ||||||||||
| Indirect Object RC with Gap | ||||||||||
| [S | Paul | [VP | gei | __i | zhaogu] | de] | nagen | nureni | likai | le |
| Paul | give | __ | care | REL | DET | woman | leave | PERF | ||
| ‘The woman that Paul showed concern to has left’ | ||||||||||
The experimental tokens were supplemented by 24 grammatical and ungrammatical fillers, which were translated from English by a native speaker of Mandarin Chinese. The entire instrument had 48 items altogether, which were randomized according to procedures discussed in Cowart (1997) and then distributed to participants in two separate versions of the questionnaire with different sequences of items. As in AJT 1, participants rated the items on a 4 point scale (1=certainly incorrect, 2=possibly incorrect, 3=possibly correct, and 4=certainly correct).
After the results of the acceptability judgment task were reviewed and analyzed, it was found that one of the token sets had flawed items in the indirect object condition. As a result, all six items from the flawed token set were excluded from the pool of analyzable data. Thus, three token sets that contained a total of 18 experimental items were included in the pool of analyzable data. [12]
3.2.2 Participants
All 32 participants were native speakers of Mandarin Chinese and were studying at Purdue University in a variety of academic majors. Of the 32 participants, 16 were males, 16 were females, and 7 had previously participated as non-native speakers in the English AJT. The majority of participants (30) were citizens of the People’s Republic of China; the remaining participants (2) were citizens of Taiwan. [13] The participants’ average age was 22.2 years old.
3.2.3 Procedures
Firstly, the experimenter distributed the participant biodata form. After these forms were collected, paper copies of the judgment task were distributed, and participants completed the AJT on paper. The directions for completing the questionnaire were written in English and Mandarin Chinese. The experimenter read the directions in English because he did not know Mandarin, and asked if there were any questions about them. He explained that the same directions were written in Mandarin on the questionnaire. Then, he asked the participants to read and evaluate 5 practice sentences. Most participants completed the questionnaire in approximately 20 minutes, and each volunteer received 10 dollars for participating.
3.2.4 Tests of statistical significance
This study used a 2-way factorial research design, with subjects repeated on the RC Type and Pronoun variables. As in the English-language AJT, the statistical procedure employed a mixed model, this time with two fixed factors, RC Type and Pronoun, and one random factor, participants. The RC Type variable has three levels: subject, direct object, and indirect object, and the Pronoun variable has two levels: presence/absence of RP. After the mixed-model procedure determined the variables that qualified as main effects and interactions, Tukey-Adjusted Least Squares Means Tests (hereafter, TALMS tests) were used to determine the differences between item types that caused the main effects and interactions. [14]
3.3 Results and discussion
There was a highly significant main effect of Pronoun (F (1,31), F=332.370, p < 0. 001) due to the overall greater acceptability of gapped clauses as compared with resumptives. The lack of any main effect of RC Type (F (2,62), F=2.160, p=0.124) results from the highly significant interaction between Pronoun and RC Type (F (2,62), F=54.830, p < 0.001), whereby acceptability ratings for gapped clauses vs. resumptives went in opposite directions across the three types of RCs. This interaction is shown in Figure 4.
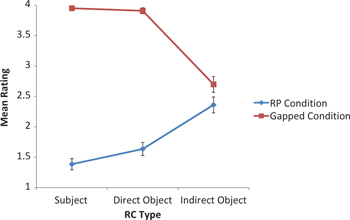
Mean ratings of Mandarin Chinese RCs.
The lower line in Figure 4 shows that RPs gain in acceptability as the level of embedding increases across RC types. In contrast, the acceptability of gapped RCs decreases in tandem with the level of embedding, as indicated by the upper line. TALMS tests verify that these trends were statistically significant for some comparisons. RPs were more acceptable in indirect object RCs than in subject RCs at a statistically significant level (t=5.980, p < 0.001), and were also more acceptable in indirect object RCs than in direct object RCs (t=–4.460, p < 0.001). However, gapped RCs decreased in acceptability as their syntactic complexity increased. Gapped indirect object RCs were less acceptable than gapped direct object RCs at a statistically significant level (=7.380, p < 0.001), and were also less acceptable than gapped subject RCs (t=–7.640, p<0.001).
These results run contrary to our original hypotheses based on the consensus opinion in Chinese linguistics. We had predicted that RPs would be highly acceptable in direct and indirect object RCs, and unacceptable only in subject RCs. Although our predictions with respect to subject RCs were borne out, our results showed that RPs were in fact unacceptable in direct object RCs (average rating: 1.635) and were only of borderline acceptability in indirect object RCs (average rating: 2.364). With respect to gapped clauses, our predictions were correct for subject RCs and direct object RCs: both were highly acceptable, with ratings of 3.948 and 3.906, respectively. These results therefore cast doubt on theoretical proposals based on the consensus opinion in Chinese linguistics. For example, Hu and Liu (2007: 269) propose that RPs are disallowed in subject position but are optional in direct object position, with the latter optionality explained in terms of an alternation between null and overt RPs. However, if (overt) RPs are judged as equally unacceptable in subject and direct object position, as the current study has shown, the most straightforward syntactic analysis would be to treat direct object relatives as similar to subject relatives but different from indirect object relatives (which do permit overt RPs).
Also contrary to our original predictions, indirect object RCs with gaps (average rating: 2.697), were more acceptable than indirect object RCs with RPs (average rating: 2.365). Although these did not differ statistically (t=–2.040, p=0.334), we had predicted a difference in the opposite direction. The judgments of the indirect object RCs are gradient in that they were neither completely acceptable, nor completely unacceptable to the experimental participants. This finding contrasts with the majority of published and presumably informal sentence judgments of Chinese indirect object RCs, which state categorically that gapped indirect objects are unacceptable, and that indirect object RCs with resumptives are acceptable (Keenan and Comrie 1977: 93; Hawkins and Chan 1997: 192; Hu and Liu 2007: 269). Thus, our data illustrate that gradient effects cannot as easily be uncovered by informal sentence judgments or be predicted in advance, and illustrate the need for quantitative data that might depict or at least control for any possible gradient effects.
Although our results do not verify the consensus view on which our hypotheses were based, they are consistent with Hawkins’ (2004) prediction that RPs and gaps in any language should be distributed in accordance with hierarchies of RC complexity which predict a greater probability of grammaticalized RPs in more complex RCs, and a greater probability of grammaticalized gaps in simpler RCs (2004: 186). This prediction is borne out in the differences found between subject and direct object RCs (which preferred gaps) and indirect object RCs (for which there was no clear preference). Furthermore, Hawkins (2004: 180) makes the specific observation that in languages like Chinese, with a SVO clause order and head-final NP, subject RCs and direct object RCs do not differ terms of FGD size. As in other language types, the subject NP is included within the FGD for a direct object relative. Unlike other language types (and as noted above), the direct object in a subject relative intervenes between the head noun and the subcategorizing verb, thus requiring the direct object NP to be included within the FGD of a subject relative and making the FGD of a subject relative just as long as for an object relative (whereas for other language types, subject relatives would have a shorter FGD than object relatives). Because there are other factors besides FGD size which can affect a grammar, Hawkins’ theory does not make specific predictions regarding which structures will be found acceptable in a given language. However, our finding that there was a strong and equal preference for gaps over RPs in both subject and direct object RCs is consistent with Hawkins’ observations regarding the equivalent FGD size of subject and object relatives in languages like Chinese.
Our results, as it turned out, were also largely consistent with the experimental results of Yuan and Zhao (2005), Su (2004), Ning (2008), Ning et al. (2014), and Francis et al. (2015). [15]Yuan and Zhao (2005) designed an acceptability judgment task in Mandarin Chinese in order to determine the distribution of gaps and RPs in Mandarin Chinese, as a control condition in a study on L2 acquisition of Mandarin. The results for their native speaker group show that RPs were rated as significantly less acceptable than gaps for both subject RCs and direct object RCs, while subject and direct object RCs did not differ from each other. Further, their results showed that that RPs and gaps were equally acceptable in RCs with relativized indirect objects, although participants generally rated indirect object RCs lower than gapped subject and object RCs. Similarly, in an acceptability judgment task, Ning (2008) found that her participants consistently rated subject RCs and object RCs alike: gapped clauses were consistently preferred over clauses with RPs to the same degree for both subject and object RCs. Likewise, Su’s (2004) production data are in line with that of Yuan and Zhao (2005) and Ning (2008); in an elicitation task administered to 31 adult native speakers of Mandarin (as a control condition in a study of L1 acquisition of Mandarin), RCs with resumptives were never produced in subject and direct object contexts. (Indirect object RCs were not tested.)
More recent studies of Mandarin RCs by Ning et al. (2014) and of Cantonese RCs by Francis et al. (2015) support the claim that RPs aid in sentence processing at greater levels of complexity, but not the claim that subject and direct object RCs are equal to one another in complexity. Ning et al. (2014) performed an eye-tracking study on 16 participants who read sentences containing subject, direct object, and indirect object RCs of varying lengths in RP and gapped conditions. The researchers found that RPs did not facilitate language processing in subject RCs, or in short direct object RCs, but that they did facilitate language processing in direct object RCs which were lengthened by adding an adverbial before the head noun. For indirect object RCs, there was no difference between the RP and gapped conditions. Their overall conclusion is similar to ours: that RPs in gap-filler constructions can facilitate processing of more complex dependencies. Francis et al. (2015) asked 22 native speakers of Cantonese to complete AJTs and production tasks, and found that RPs were more acceptable and were produced more often as the structural complexity of the RCs in these tasks increased, a finding that they believe supports Hawkins’ (2004) Performance-Grammar Correspondence Hypothesis. Contrary to the results of AJT 2, however, they found that RPs were more acceptable and were produced more often in direct object RCs as compared with subject RCs.
The data from Francis et al. (2015) and Ning et al. (2014), while compelling, do not disprove Hawkins’ claim that Mandarin subject and direct object RCs are equal to one another in one measure of complexity. Ning et al. (2014) did not measure acceptability or production, but instead used eye-tracking to assess subtle effects in reading comprehension. It is likely that their eye-tracking measures were sensitive to some aspect of online processing that acceptability judgments (Ning 2008; Yuan and Zhao 2005), reading time (Ning 2008), and production measures (Su 2004) were not. Furthermore, the subject-object asymmetry that they found was only present in one condition – the long-RC condition. The results for Cantonese from Francis et al. (2015) present a more serious challenge to Hawkins’ proposal. Cantonese is closely related to Mandarin and shares the same word order typology. Therefore, Hawkins (2004) predicts no subject-object asymmetry in RP use. However, Hawkins himself acknowledges that other factors besides FGD size may affect processing complexity, and that even the same complexity factors may be grammaticalized differently in different languages. Francis et al. (2015: 76) note that the subject-object asymmetry that they found is consistent with a frequency-based effect, since subject RCs are more common than object RCs in corpora of Mandarin (Hsiao and MacDonald 2013). We can therefore speculate that different dimensions of RC complexity may affect RP distributions in Mandarin vs. Cantonese.
In summary, the experimental findings of three studies of Mandarin RPs (Ning 2008; Su 2004; Yuan and Zhao 2005), which deviated from the scholarly consensus in Chinese linguistics and which did not figure in Hitz’s (2012) original hypotheses, turn out to align closely with the findings reported above in experiment 2. Notably, all of these studies relied on experimental data, whereas the scholarly consensus in Chinese linguistics is mostly based on studies that used informally collected judgments. The current results, in combination with those of other experimental studies, cast doubt on previous syntactic analyses (e. g., Hu and Liu 2007) while supporting the predictions of Hawkins’ (2004) FGD complexity ranking.
4 Acceptability judgment task 3: Turkish
4.1 Hypotheses
AJT 3 was designed in order to determine the distribution of RPs in Turkish RCs. The large body of literature on Turkish RCs has generally argued that they do not allow RPs in RCs with relativized subjects, direct objects, indirect objects, and oblique objects (Keenan and Comrie 1977; Tezel 1998; Lewis 2000; Kornfilt 2000; Cağri 2005). Moreover, Kornfilt (2000) has argued that a syntactic constraint, the A’-Disjointness requirement, [16] prevents the occurrence of RPs in Turkish RCs. This view was the basis for the experimental hypotheses in the current study: we predicted that gapped clauses would be highly acceptable across all conditions, while clauses with RPs would be unacceptable across all conditions, similar to the predictions for English in AJT 1.
The consensus view described above has been challenged. Meral (2004) argues that resumptive pronouns may alternate “freely” with gaps in Turkish RCs with relativized subjects, direct objects, indirect objects, and oblique objects, and are mandatory in some RCs with relativized objects of postpositions. Meral (2004) states that resumptive pronouns are acceptable in all Turkish RC types. Differing slightly from this, Göksel and Kerslake (2004) state that RPs are acceptable in all non-subject RCs. The results from Experiment 3 support Göksel and Kerslake (2004).
4.2 Methodology
4.2.1 Design
Similar to Chinese, Turkish NPs are head-final and therefore relative clauses come before the nouns they modify and fillers come before gaps. Unlike Chinese, however, the basic clause order is SOV. Turkish relative clauses take two forms. In the first type, the subject is relativized and an –en suffix is added to the verb; in the second, the direct, indirect, or oblique object is relativized and the -dik suffix is added to the verb. These RC types are illustrated in (5) and (6) below. Turkish is a pro-drop language, so overt subjects appear in RCs in which the object is relativized only for pragmatic reasons (Cağri 2005).
| Hasan’ın | tanı- dığ- I | ada |
| Hasan-GEN | know-DIK-1SG | island |
‘The island that Hasan knows.’
(Kornfilt 2000:126)
The structure for Turkish closely resembles that for Chinese, as shown in the following Hawkins-style tree diagram (Figure 5). However, because Turkish is consistently head-final in both the NP and the VP (with the subcategorizing verb adjacent to the head noun), FGDs for subject RCs are shorter than for object RCs (Hawkins 2004: 180). In this respect, Turkish resembles English but differs from Chinese. In a simple transitive clause, subject RCs have an FGD of 6 while direct object RCs have an FGD of 8. Indirect object RCs in a ditransitive clause have an FGD of 10, and so do oblique object RCs. The direct object RC from sentence (6) is illustrated in the following figure.
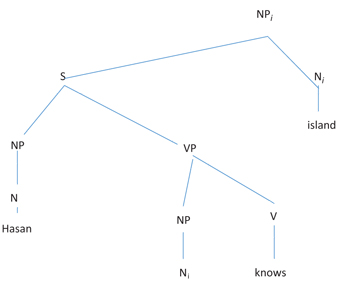
Tree diagram of a Turkish RC.
In experiment 3, one factor, RC Type, had three levels: subject RC, direct object RC, and RC with a relativized indirect object/relativized oblique object, [17] while the other factor, Pronoun (Presence/Absence of RP), had two levels. A sample token set is given in Table 4.
Sample token set for acceptability judgment task 3: Turkish.
| Subject RC with Resumptive Pronoun | |||||||||||
| [S | Kendisii | biz-i | öv-en] | adami | çok | sevilen | bir | kişi-dir | |||
| he-NOM. | 1.PL-ACC. | praise-SRa | man | very | loved | one | person-PRED | ||||
| ‘The man who he praises us is a much-loved individual’ | |||||||||||
| Subject RC with Gap | |||||||||||
| [S___i | biz-I | öv-en] | adami | çok | sevilen | bir | kişi-dir | ||||
| 1.PL-ACC. | praise-NSR | man | very | loved | one | person-PRED | |||||
| ‘The man who praises us is a much-loved individual’ | |||||||||||
| Direct Object RC with Resumptive Pronoun | |||||||||||
| [S | pro | Kendisi-nii | öv- | düğ- | ümüz] | adami | çok | sevilen | bir | kişi- | dir |
| pro | he-ACC. | praise-NSRb-1.PL | man | very | loved | one | person | PRED | |||
| ‘The man who we praised him is a much-loved individual’ | |||||||||||
| Direct Object RC with Gap | |||||||||||
| [S | pro___i | öv- | düğ-ümüz] | adami | çok | sevilen | bir | kişi- | dir | ||
| pro | praise-NSR-1.PL | man | very | loved | one | person-PRED | |||||
| ‘The man who we praised is a much-loved individual’ | |||||||||||
| Indirect Object RC/ Oblique Object RC with Resumptive Pronoun | |||||||||||
| [S | pro | Kendisi-nei | iltifat | et-tiğ-imiz] | adami | çok | sevilen | bir | kişi- | dir | |
| pro | he-DAT | compliment | do-NSR-1.PL | man | very | loved | one | person-PRED | |||
| ‘The man who we gave compliments to him is a much-loved individual’ | |||||||||||
| Indirect Object RC/ Oblique Object RC with Gap | |||||||||||
| [S | pro___i | iltifat | et-tiğ-imiz] | adami | çok | sevilen | bir | kişi- | dir | ||
| pro___ | compliment | do-NSR-1.PL | man | very | loved | one | person-PRED | ||||
| ‘The man who we gave compliments to is a much-loved individual’ | |||||||||||
The instrument contained 4 token sets consisting of 24 experimental items in addition to 24 fillers for a total of 48 items altogether. The items were randomized according to procedures described by Cowart (1997) and distributed to participants in two different questionnaire forms in which items were ordered differently from one another.
4.2.2 Participants
AJT 3 was administered to a total of 16 native speakers of Turkish who were recruited from the student body at Purdue University in 2010. As the majority were graduate students, the average age was 32 years old; 8 were males, and 8 were females. None had training in linguistics. Nine participants in this study had previously participated in the English-language AJT.
4.2.3 Experimental procedures and statistical tests used to analyze the data
These were identical to the ones listed for AJT 2.
4.3 Results and discussion
Results from the mixed model statistical test show highly significant main effects for RC Type, Pronoun, and for their interaction. [18] Pairwise TALMS test comparisons showed that one condition was primarily responsible for all statistically significant differences between individual types of items. Subject RCs with RPs were rated significantly lower than all other conditions, including direct object RCs with RPs (t=4.780, p = 0.001) and indirect/oblique object RCs with RPs (t=5.650, p < 0.001). All other pairwise TALMS test comparisons that did not involve subject RCs in the RP condition were not statistically significant.
This difference between subject relatives with RPs and all other sentence types can be seen clearly in Figure 6. [19]
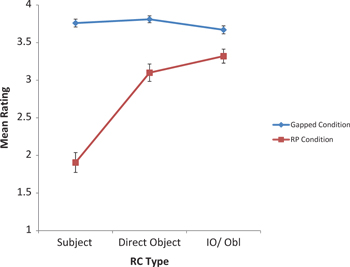
Mean ratings of Turkish RCs.
Note: The error bars indicate the standard error of the mean. Exact values of each data point and the standard deviations can be seen in Appendix C, Table 9.
These results differed from our original predictions. Although gapped RCs were rated highly in all conditions as expected, RPs were also found to be acceptable in both direct object RCs (average rating 3.109) and in RCs with relativized indirect objects and in oblique object RCs (3.328), contrary to the claims made by Keenan and Comrie (1977), Tezel (1998), Kornfilt (2000), and Cağri (2005) that RPs are unacceptable in normal Turkish RCs. It should be recalled that in the non-subject conditions, RCs with RPs did not differ from gapped RCs at statistically significant levels, despite the apparent slight differences shown in Figure 6. These results therefore cast doubt on formal syntactic proposals such as Kornfilt’s (2000) formulation of the A’-Disjointness requirement – a constraint on the binding of pronouns by antecedents in A’ positions. Kornfilt (2000) formulates this constraint for Turkish in such a way as to prevent RPs in all positions within the highest clause (i. e., subject, direct object, indirect object, oblique object). The current results suggest that RPs are more likely banned from highest subject position only, similar to Irish (McCloskey 1990) and Hebrew (Borer 1984).
Although failing to support Kornfilt’s (2000) analysis, the current data are consistent with Hawkins’ (2004) FGD complexity ranking, which predicts a greater likelihood of acceptable RPs in non-subject as compared with subject positions. Furthermore, Turkish RCs with relativized direct, indirect, and oblique objects are more complex from a morphological perspective than Turkish subject RCs, in addition to having larger FGDs as per Hawkins’ complexity metric. For example, non-subject Turkish RCs must have a morpheme that indicates agreement in number with the RC subject, and that is appended to the morpheme used to mark a non-subject RC, -dik. In contrast, Turkish subject RCs contain no such agreement morpheme. In other words, L1 Turkish speakers might find Turkish non-subject RCs more difficult to process than subject RCs for two different reasons: a) the larger filler-gap domain in non-subject RCs as compared with subject RCs, and b) the comparatively elaborate morphology in non-subject RCs as compared with subject RCs. For more detailed information on these issues, see Özge et al. (2010).
The results for the resumptive conditions were similar to those for Mandarin Chinese, except that in Mandarin, direct object RCs with RPs patterned more similarly to subject RCs, and the complexity effect for RPs (i. e., enhanced acceptability in more deeply embedded positions) was only shown in the indirect object condition. Thus, the Turkish data, which showed increased acceptability for non-subject RCs with RPs as compared with subject RCs with RPs, patterned in much the way that we had originally hypothesized for Mandarin. The Mandarin data itself patterned slightly differently than expected in that direct object RCs with RPs were no more acceptable than subject RCs with RPs. Importantly, though, both Mandarin and Turkish showed increased acceptability for RPs in some non-subject conditions, in contrast to English, for which RPs were judged by the native speaker control group in AJT 1 as equally unacceptable across all RC types. Of these three languages, only the English native speaker results were as expected. We believe that these results from AJT 2 and AJT 3 might help explain the otherwise puzzling results of AJT 1. The lack of any differences between L1 Turkish and L1 Chinese groups as well as the slight but significant difference between subject and non-subject conditions for both learner groups might be attributed to the fact that RPs are apparently licensed in some non-subject positions in both Turkish and Mandarin. In other words, the results of AJT 2 and AJT 3 tell us that L1 transfer cannot be ruled out as an explanation for the results of AJT 1.
Overall, the results obtained from AJT 3 contrast with most published information about the distribution of RPs and gaps in Turkish RCs, all of which appears to be based on informal sentence judgments. More research needs to be done on the distribution of RPs in Turkish RCs, and we believe that informal sentence judgments are not capable of clarifying this issue in sufficient detail. Furthermore, support for the Hawkins’ FGD complexity ranking is illustrated here by the increasing acceptability of RPs in subject, direct object, and indirect object/oblique contexts.
5 Conclusion
In this section, we will review each experiment in light of the article’s goal of illustrating the need for quantitative research in theory building, discuss the limitations of each experiment, and describe avenues for further research.
5.1 English-language AJT 1: The crosslinguistic transfer of RPs
AJT 1 showed that formal sentence judgment tasks are needed to portray any possible gradient effects. The gradient effect shown in the non-native speakers’ judgments of RCs in the RP condition could not be elucidated by informal sentence judgments.
More generally, AJT 1 showed that SLA researchers interested in researching language transfer need to base their L1-related hypotheses on experimental data. Currently, many SLA researchers still base their L1-related hypotheses on informal sentence judgments (Jarvis and Pavlenko 2008: 49), and this situation needs to change.
The motivation for the gradient data is consistent with Hawkins’ FGD complexity ranking. Non-native speakers may have found RPs to be more acceptable in non-subject RCs as compared with subject RCs due to the greater processing complexity of non-subject RCs. However, the results of AJT 2 and 3 show that an L1 transfer account, or an account that combines processing complexity and L1 transfer, cannot be ruled out.
We encourage future SLA researchers interested in language transfer of RPs to base their transfer-related hypotheses on experimental data for the L1 (instead of only testing L2 performance), to use a larger variety of token sets in a Latin Square design, and to include more complex RCs with deeper levels of embedding. If we had included more items like these, the very slight gradient effect likely would have become more apparent. [20] Finally, we have only data obtained from receptive tasks. These need to be supplemented with productive tasks as well.
5.2 AJT 2: The distribution of gaps and RPs in Mandarin Chinese
AJT 2 showed that the actual distribution of gaps and RPs in Mandarin Chinese RCs as revealed by experimental data is quite different from the patterns shown by informal sentence judgment tasks. Thus, our own results, in combination with the experimental results of other researchers (Ning 2008; Yuan and Zhao 2005), cast doubt on previous formal syntactic analyses which assumed that RPs are banned from subject RCs but optional in direct object RCs (e. g., Hu and Liu 2007). On the positive side, our results concur with the FGD complexity ranking of Hawkins (2004), and in particular the prediction that RP distributions should be the same in subject and direct object RCs for languages like Mandarin. The precise formulation of constraints on RP distributions in Chinese RCs is quite controversial as shown in the discussion of AJT 2, and more experimental research is clearly needed.
AJT 2 shows another motivation for formal sentence judgments: a gradient data pattern, which informal sentence judgments cannot adequately reveal, but which syntactic analyses of RP distributions ought to take into account. As with the English RCs in AJT 1, RPs gain in acceptability as the filler-gap domain expands, a finding that supports the FGD complexity ranking of Hawkins (2004).
The limitations of AJT 2 are similar to AJT 1. The gradient pattern could have been more pronounced if the experiment had included additional conditions with more complexity and embedding. Also, the small number of token sets and the lack of a Latin Square Design do limit our ability to generalize these findings, but, as we have stated earlier, the validity of the results may be strengthened by their consistency with those of other experiments. More production data on the distribution of RPs in Mandarin across a wider range of RC types of varying levels of complexity is needed.
5.3 AJT 3: The distribution of gaps and RPs in Turkish
AJT 3 showed that our experimental data were at odds with all informal judgments regarding the distribution of gaps and RPs in Turkish RCs except for those of Göksel and Kerslake (2004), and therefore call into question formal syntactic analyses proposed by Kornfilt (2000). The results are, however, again consistent with Hawkins’ FGD complexity metric, as RPs in non-subject positions are more acceptable than in subject positions. As far as we are aware, ours is the first and only experimental study to address these issues. As such, it remains unclear as to what extent RPs are grammaticalized in Turkish and under what conditions they are used. In addition, it is not known which type of RC complexity (FGD size, morphological complexity, or some combination) might be affecting participants’ judgments. Further experimental research is needed to answer these questions.
As with AJTs 1 and 2, AJT 3 could have benefitted from a larger number of token sets. Also, it is possible that subject RCs in the RP condition could have become more acceptable if more postpositional or adverbial phrases intervened between the RP and the head noun: compared to the other subject RCs in the RP condition in AJTs 1 and 2, participants rated them fairly high (1.906), and some participants found them to be consistently acceptable.
It can be seen that the experimental results of AJTs 1, 2, and 3 have important limitations and raise more questions than they resolve in regards to only one small area of syntactic research: resumptive pronouns. However, at least three things are clear: (1) syntactic analyses of RPs in Mandarin (e. g., Hu and Liu 2007) and Turkish (e. g., Kornfilt 2000) may need to be revised such that the relevant syntactic constraints are more restrictive for Mandarin (treating direct object RCs on par with subject RCs) but less restrictive for Turkish (allowing RPs in non-subject positions); (2) acceptability judgments correlated with RC complexity for L2 English speakers and for L1 Mandarin and Turkish speakers, consistent with Hawkins’ FGD complexity ranking, thus providing some support for his PGCH; and (3) informally collected sentence judgments provide little hope of establishing reliable data on RP distributions or of revealing subtle, gradient distinctions. Thus, following Gibson and Fedorenko (2013), we endorse the continued use of formal sentence judgment tasks or other quantitative measures in both theoretical syntax research, which relies on particular contrasts in acceptability to form complex chains of reasoning, and in second-language research, which relies on particular contrasts in acceptability to form hypotheses about language transfer.
Acknowledgments
We would like to acknowledge the extremely helpful contributions of Dr. April Ginther, the Co-Chair of John Hitz’s Ph.D. dissertation committee, who provided valuable guidance regarding logical argumentation, organization of ideas, research design, and statistical analyses. We would like to thank another member of the dissertation committee, Dr. John Sundquist, for giving many detailed and helpful comments throughout, and respectfully recognize the contributions of Dr. Linda Bergmann, a dissertation committee member whose feedback enabled us to explain our arguments in the clearest possible way. We are very grateful to the Purdue Statistics Department, and especially to Faye Zheng, our research consultant, who helped us choose the appropriate statistical model. We offer our sincere thanks to Dr. Charles Lam and Dr. Lixia Cheng, who helped enormously with the design of the Mandarin AJT, and to Dr. Xin Li, who helped us to evaluate and critique the individual items. We express our sincere gratitude to Evrim Eser Hitz, Nevin Eser, and Ayşe Eser for their assistance with the word choices and experimental items in the Turkish AJT. We would like to thank the anonymous reviewers who provided some incisive, detailed, and useful comments about an earlier draft of this article that was submitted to another journal. And, finally, we are very grateful to the anonymous reviewers and editorial staff of Linguistics. We really appreciate their detailed comments on the first submission of this article, and their patience with our work.
References
Ariel, M. 1999. Cognitive universals and linguistic conventions: The case of resumptive pronouns. Studies in Language 23(2). 217–269.10.1075/sl.23.2.02ariSearch in Google Scholar
Asudeh, Ash. 2012. The logic of pronominal resumption. Oxford: Oxford University Press.10.1093/acprof:oso/9780199206421.001.0001Search in Google Scholar
Bardovi-Harlig, Kathleen. 1987. Markedness and salience in second language acquisition. Language Learning 37. 385–407.10.1111/j.1467-1770.1987.tb00577.xSearch in Google Scholar
Borer, Hagit. 1984. Restrictive relatives in Modern Hebrew. Natural Language and Linguistic Theory 2. 219–260.10.1007/BF00133282Search in Google Scholar
Cağri, Ilhan. 2005. Minimality and Turkish relative clauses. College Park, MD: University of Maryland dissertation.Search in Google Scholar
Chomsky, Noam. 1977. On wh-movement. In Peter W. Culicover, Thomas Wasow & Adrian Akmajian (eds.), Formal syntax, 71–132. New York: Academic Press.Search in Google Scholar
Chomsky, Noam. 1995. The minimalist program. Cambridge, MA: MIT Press.Search in Google Scholar
Comrie, Bernard. 1989. Language universals and linguistic typology, 2nd edn. Chicago, IL: University of Chicago Press.Search in Google Scholar
Cowart, Wayne. 1997. Experimental syntax. Thousand Oaks, CA: Sage Publications.Search in Google Scholar
Francis, Elaine J., Charles Lam, Carol Chun Zheng, John Hitz & Stephen Matthews. 2015. Resumptive pronouns, structural complexity, and the elusive distinction between grammar and performance: Evidence from Cantonese. Lingua 162. 56–81.10.1016/j.lingua.2015.04.006Search in Google Scholar
Gass, Susan. 1979. Language transfer and universal grammatical relations. Language Learning 29(2). 327–344.10.1111/j.1467-1770.1979.tb01073.xSearch in Google Scholar
Gibson, Edward & Evelina Fedorenko. 2013. The need for quantitative methods in syntax and semantics research. Language and Cognitive Processes 28(2). 88–124.10.1080/01690965.2010.515080Search in Google Scholar
Gibson, Edward, Steven Piantadosi & Evelina Federenko. 2013. Quantitative methods in syntax/semantics research: A response to Sprouse and Almeida (2012). Language and Cognitive Processes 28(3). 229–240.10.1080/01690965.2012.704385Search in Google Scholar
Göksel, Asli & Celia Kerslake. 2004. Turkish: A comprehensive grammar. New York: Routledge.10.4324/9780203340769Search in Google Scholar
Hawkins, John. 1999. Processing complexity and filler-gap dependencies across grammars. Language 75(2). 244–285.10.2307/417261Search in Google Scholar
Hawkins, John. 2004. Efficiency and complexity in grammars. Oxford: Oxford University Press.10.1093/acprof:oso/9780199252695.001.0001Search in Google Scholar
Hawkins, Roger. 2005. Revisiting Wh-movement: The availability of an uninterpretable [wh] feature in interlanguage grammars. In Laurent Dekydtspotter, Rex Sprouse & Audrey Liljestrand (eds.), Proceedings of the 7th generative approaches to second language acquisition conference (GASLA 2004), 124–137. Somerville, MA: Cascadilla Proceedings Project.Search in Google Scholar
Hawkins, Roger & Cecilia Chan. 1997. The partial availability of universal grammar in second language acquisition: The failed functional features hypothesis. Second Language Research 13(3). 187–226.10.1191/026765897671476153Search in Google Scholar
Hitz, John. 2012. A study of the constraints affecting resumption in Turkish and Mandarin Chinese relative clauses, and the transfer of these constraints to English as a second language. West Lafayette, IN: Purdue University dissertation.Search in Google Scholar
Hofmeister, Phillip & Elisabeth Norcliffe. 2013. Does resumption facilitate sentence comprehension? In Phillip Hofmeister & Elisabeth Norcliffe (eds.), The core and the periphery: Data-driven perspectives on syntax inspired by Ivan A. Sag, 225–246. Stanford, CA: CSLI Publications.Search in Google Scholar
Hsiao, Franny. 2003. The syntax and processing of relative clauses in Mandarin Chinese. Cambridge, MA: MIT dissertation10.1016/S0010-0277(03)00124-0Search in Google Scholar
Hsiao, Yaling & Maryellen C. MacDonald. 2013. Experience and generalization in a connectionist model of Mandarin Chinese relative clause processing. Frontiers in Psychology 4. 1–19.10.3389/fpsyg.2013.00767Search in Google Scholar
Hu, Xiaoling, & Chianping Liu. 2007. Restrictive relative clauses in English and Korean learners’ second language Chinese. Second Language Research 23(3). 263–287.10.1177/0267658307077642Search in Google Scholar
Hyltenstam, Kenneth. 1984. The use of typological markedness conditions as predictors of second language acquisition. In Roger Andersen (ed.), Second languages: A cross-linguistic perspective. Rowley, MA: Newbury House.Search in Google Scholar
Jarvis, Scott & Aneta Pavlenko. 2008. Crosslinguistic influence in language and cognition. New York: Routledge.10.4324/9780203935927Search in Google Scholar
Keenan, Edward & Bernard Comrie. 1977. Noun phrase accessibility and universal grammar. Linguistic Inquiry 8(1). 63–99.10.4324/9781315880259-11Search in Google Scholar
Kornfilt, Jaklin. 2000. Some syntactic and morphological properties of relative clauses in Turkish. In Alexiadou, Artemis, Paul Law, Andre Meinunger & Chris Wilder (eds.), The syntax of relative clauses, 121–159. Amsterdam & Philadelphia: John Benjamins10.1075/la.32.04korSearch in Google Scholar
Leavitt, Frederick. 2002. Evaluating scientific research: Separating fact from fiction. Long Grove, IL: Waveland Press.Search in Google Scholar
Lewis, Geoffrey. 2000. Turkish grammar, 2nd edn. Oxford: Oxford University Press.Search in Google Scholar
Littell, Ramon, Walter Stroup & Rudolf Freund. 2002. SAS for linear models, 4th edn. Cary, NC: SAS Institute.10.1002/9780470057339.vas007Search in Google Scholar
McCloskey, James. 1990. Resumptive pronouns, A’-Binding and levels of representation in Irish. In Randall Hendrick (ed.), Syntax of modern Celtic languages (Syntax and Semantics 23), 199–248. San Diego, CA: Academic Press Inc.10.1163/9789004373228_008Search in Google Scholar
McKee, Cecile, & Dana McDaniel. 2001. Resumptive pronouns in English relative clauses. Language Acquisition 9(2). 113–156.10.1207/S15327817LA0902_01Search in Google Scholar
Meral, Hasan. 2004. Resumptive pronouns in Turkish. Istanbul, Turkey: Bogazici University MA dissertation.Search in Google Scholar
Ning, Li-Hsin. 2008. The grammar and processing of resumptive pronouns in Chinese relative clauses. Taipei: National Cheng-Chi University MA thesis.Search in Google Scholar
Ning, Li-Hsin, Kiel Christianson & Chien-Jer Charles Lin. 2014. Processing resumptives in Mandarin relative clauses: An eye-tracking study. Poster presented at the 27th Annual CUNY Conference on Human Sentence Processing, Columbus, OH, 13–15 March.Search in Google Scholar
Odlin, Terrance. 2003. Cross-linguistic influence. In Catherine Doughty & Michael Long (eds.), The handbook of second language acquisition, 436–481. Oxford: Blackwell.10.1002/9780470756492.ch15Search in Google Scholar
Ouhalla, Jamal. 1993. Subject-extraction, negation, and the anti-agreement effect. Natural Language and Linguistic Theory 11. 477–518.10.1007/BF00993167Search in Google Scholar
Özge, Duygu, Theodoros Marinis, & Deniz Zeyrek. 2010. A conflict between filler-gap accounts and incremental processing: evidence from production and parsing of relative clauses in a head final language. Poster presented at the Architectures and Mechanisms for Language Processing Conference (AMLaP) 2010, York, 6–8 September.Search in Google Scholar
Phillips, Colin. 2009. Should we impeach armchair linguists? In Shoishi Iwasaki, Hajime Hoji, Patricia M. Clancy & Sung-Ock Sohn (eds.), Japanese-Korean Linguistics, vol. 17. Stanford, CA: CSLI Publications.Search in Google Scholar
SAS Institute Inc. 1999. SAS/STAT® user’s guide, version 8. Cary, NC: SAS Institute Inc.Search in Google Scholar
Schütze, Carson. 1996. The empirical base of linguistics: grammaticality judgments and linguistic methodology. Chicago: University of Chicago Press.Search in Google Scholar
Sprouse, Jon & Diogo Almeida. 2013a. The empirical status of data in syntax: A reply to Gibson and Fedorenko. Language and Cognitive Processes 28. 222–228.10.1080/01690965.2012.703782Search in Google Scholar
Sprouse, Jon & Diogo Almeida. 2013b. The role of experimental syntax in an integrated cognitive science of language. In Cedric Boeckx & Kleanthes K. Grohmann (eds.), The Cambridge handbook of biolinguistics, 181–202. Cambridge: Cambridge University Press.10.1017/CBO9780511980435.013Search in Google Scholar
Sprouse, Jon, Carson Schütze & Diogo Almeida. 2013. A comparison of informal and formal acceptability judgments using a random sample from Linguistic Inquiry 2001–2010. Lingua 134. 219–248.10.1016/j.lingua.2013.07.002Search in Google Scholar
Su, Yi-Ching. 2004. Relatives of Mandarin children. Paper presented at the Inaugural Conference on Generative Approaches to Language Acquisition (GALANA), Hawaii, December.Search in Google Scholar
Tezel, Zubeyde. 1998. The acquisition of restrictive relative clause configurations in English as a second language. Indiana: Indiana University of Pennsylvania dissertation.Search in Google Scholar
Wasow, Thomas. 2002. Postverbal behavior. Chicago, IL: CSLI Publications.Search in Google Scholar
Wasow, Thomas. 2007. Gradient data and gradient grammars. Proceedings of the 43rd Annual Meeting of the Chicago Linguistic Society, 255–271.Search in Google Scholar
Wasow, Thomas & Jennifer Arnold. 2005. Intuitions in linguistic argumentation. Lingua 115(11). 1481–1496.10.1016/j.lingua.2004.07.001Search in Google Scholar
Xu, Liejiong & Terence Langendoen. 1985. Topic structures in Chinese. Language 61. 1–27.10.2307/413419Search in Google Scholar
Yuan, Boping & Yang Zhao. 2005. Resumptive pronouns in English-Chinese and Arabic-Chinese interlanguages. International Review of Applied Linguistics in Language Teaching (IRAL) 43. 219–237.10.1515/iral.2005.43.3.219Search in Google Scholar
Appendices
Appendix A
The means of the ratings assigned to the items in the various experimental conditions in AJT 1, as well as the standard deviations between them, are illustrated in Table 5.
Mean ratings of experimental items.
| Mandarin Gaps | Turkish Gaps | English Gaps | Mandarin RP | Turkish RP | English RP | |
|---|---|---|---|---|---|---|
| Subject | 3.58 | 3.76 | 3.74 | 1.27 | 1.19 | 1.13 |
| SD=0.35 | SD=0.306 | SD=0.41 | SD=0.44 | SD=0.37 | SD=0.23 | |
| Direct Object | 3.22 | 3.28 | 3.53 | 1.58 | 1.59 | 1.11 |
| SD=0.59 | SD=0.875 | SD=0.61 | SD=0.74 | SD=0.73 | SD=0.24 | |
| Prep. Object | 3.51 | 3.02 | 3.53 | 1.60 | 1.52 | 1.17 |
| SD=0.52 | SD=0.978 | SD=0.75 | SD=0.697 | SD=0.68 | SD=0.35 |
The main effects and interactions of various factors that might have affected participants’ performance in AJT 1 are depicted in Table 6.
Influence of various factors on AJT 1
| Effect | Numerator DF | Denominator DF | F Value | Pr > F |
|---|---|---|---|---|
| Language | 2 | 198 | 0.68 | 0.5053 |
| Type | 2 | 393 | 1.69 | 0.1852 |
| language*type | 4 | 393 | 5.28 | 0.0004 |
| Pronoun | 1 | 198 | 923.63 | <0.0001 |
| type*pronoun | 2 | 393 | 37.04 | <0.0001 |
| language*pronoun | 2 | 198 | 6.20 | 0.0024 |
| language*type* pronoun | 4 | 393 | 6.03 | 0.0001 |
The mixed-model statistical procedure showed a significant main effect for one of the fixed factors, Pronoun (F(1, 198), F =923.63, p <0.001). The significant main effect of Pronoun indicates that, as expected, gapped RCs were rated much higher than resumptive RCs across all language groups and all RC types.
The lack of any main effect for Language (F (2, 198)=0.680, p=0.505) and RC Type (F (2, 393)=1.68, p=0.185) is the result of variation across participant groups and clause types among the different experimental conditions. However, this variation was found to be systematic, as indicated by the significant interactions between Language and RC Type (F (4, 393)=5.280, p=0.0004), Language and Pronoun (F (2, 98)=6.202, p=0.002), RC Type and Pronoun (F(4, 393)=37.040, p <0.001), and between Language, RC Type, and Pronoun (F(4, 393) =6.030, p <0.001). The most interesting of these is the significant three-way interaction between Language (L1 background), RC Type, and Pronoun (Presence/Absence of RP).
We conducted several pairwise comparisons using Tukey-Adjusted Least Mean Squares tests (hereafter, TALMS tests) to check for significant differences in the ratings between L1 groups. Contrary to our expectation for L1 transfer effects, there were no statistically significant differences between the two groups of non-native speakers in regards to their judgments of direct object RCs with RPs (t=−0.030, p=1.000), and in regards to their judgments of RCs with relativized objects of prepositions and RPs (t=1.070, p=0.999). Likewise, the L1 Chinese speakers did not differ at statistically significant levels from the native English speakers in terms of their judgments of similar items on the questionnaire, and the L1 Turkish speakers differed at statistically significant levels from the L1 English speakers on only one condition: gapped RCs with stranded prepositions (t=3.520, p=0.049). [21] These data appear to show that the non-native English speakers were so advanced in their L2 RC acquisition that their acceptability judgments for sentences with RPs closely resembled those of native speakers.
Appendix B
The means of the ratings assigned to the items in the various experimental conditions in AJT 1, as well as the standard deviations between them, are illustrated in Table 7.
Mean ratings of experimental items.
| Subject | Direct Object | Indirect Object | |
|---|---|---|---|
| Gapped Condition | 3.948 | 3.906 | 2.697 |
| SD=0.337 | SD=0.482 | SD=1.300 | |
| RP Condition | 1.385 | 1.635 | 2.36 |
| SD=0.910 | SD=1.076 | SD=1.265 |
The main effects and interactions elicited by the Mixed Model procedure can be seen in Table 8.
Main effects and interactions: L1 Mandarin survey.
| Effect | Numerator DF | Denominator DF | F Value | Pr > F |
|---|---|---|---|---|
| Type | 2 | 62 | 2.16 | 0.1244 |
| Pronoun | 1 | 31 | 332.37 | <0.0001 |
| pronoun*type | 2 | 62 | 54.83 | <0.0001 |
Appendix C
The means of the ratings assigned to the items in the various experimental conditions AJT 3, as well as the standard deviations between them, are illustrated in Table 9.
Mean ratings of experimental items.
| Subject | Direct Object | Indirect/Oblique Object | |
|---|---|---|---|
| Gapped Condition | 3.984 | 3.81 | 3.67 |
| SD=0.422 | SD=0.370 | SD=0.425 | |
| RP Condition | 1.906 | 3.10 | 3.32 |
| SD=0.1.060 | SD=0.921 | SD=0.751 |
The main effects and interactions elicited by the Mixed Model procedure can be seen in Table 10.
Main effects and interactions: L1 Turkish survey.
| Effect | Num DF | Den DF | F Value | Pr > F |
|---|---|---|---|---|
| Type | 2 | 30 | 8.76 | 0.0003 |
| Pronoun | 1 | 15 | 44.4 | <0.0001 |
| Type* Pronoun | 2 | 30 | 9.89 | 0.0001 |
©2016 by De Gruyter Mouton
Articles in the same Issue
- Frontmatter
- Grammatical and pragmatic factors in the interpretation of Japanese null and overt pronouns
- Attraction between words as a function of frequency and representational distance: Words in the bilingual brain
- On the usefulness of formal judgment tasks in syntax and in second-language research: The case of resumptive pronouns in English, Turkish, and Mandarin Chinese
- The prominence of spoken language elements in a sign language
- Extraction from gerunds and the internal syntax of verbs
- Minimizers and EVEN
- Nominal plurals in Antwerp Hasidic Yiddish: An empirical study
Articles in the same Issue
- Frontmatter
- Grammatical and pragmatic factors in the interpretation of Japanese null and overt pronouns
- Attraction between words as a function of frequency and representational distance: Words in the bilingual brain
- On the usefulness of formal judgment tasks in syntax and in second-language research: The case of resumptive pronouns in English, Turkish, and Mandarin Chinese
- The prominence of spoken language elements in a sign language
- Extraction from gerunds and the internal syntax of verbs
- Minimizers and EVEN
- Nominal plurals in Antwerp Hasidic Yiddish: An empirical study