Toward a semiotic pyramid: language studies, AI, and knowledge exchange economy
-
Felix Poschinger
Felix Poschinger works at the Knowledge Exchange Agency at Hamburg University. His research interest focuses on the digital recontextualization of the Humanities with a special focus on contemporary communication systems.

 und
Robert Coon
und
Robert Coon

Abstract
This paper addresses the interrelation between AI and language studies in the (digital) humanities in the context of knowledge exchange economies. We propose a three-dimensional semiotic model (pyramid) that includes AI as an active agent in meaning-creation into the sign system of communication and test its validity on autocompletion and predictive texting. We, therefore, analyzed 360 million tweets on COVID-19 over a period of 2 years and focused on the time-dependent shift of language use in the positive and negative extremes correlating to significant external events. The data suggest that digital language use has significantly changed over the course of the pandemic. Feedback loops are created between AI, utterance, and external reality that fossilize preconceived notions into textual isoglosses by suggesting and completing text entries. We thus argue that AI subtly changes the perception of reality by influencing the choice of wording. To mitigate the impact of AI in meaning-creation, we highlight the structural precautions undertaken by providers; we argue, however, that the (digital) humanities may re-emphasize their intrinsic value within the economy of knowledge exchange according to the subject-specific insights they may provide for language use and AI.
1 Introduction: the digital and the humanities
When ChatGPT was first introduced to the market in November 2022, its reception both by the general public and academia was overwhelming and it still holds strong. While it may be the most popular and promising instance of Artificial Intelligence (AI) (cf. Bubeck et al. 2023), it is far from the only AI in current everyday use. Companies invest in it for targeted marketing, chatbots, or autosuggestions, while private individuals come into contact with it in fitness tracking, search engine results, or spam filters, to name but a few examples. International studies have illustrated that the repeated encounter with AI leads to a general level of awareness of its existence, yet there is a simultaneous lack of understanding what it is exactly (cf. Ipsos 2022; Kennedy et al. 2023; Kozyreva et al. 2020). Not often is this divide more pronounced than in the humanities, in which the misguided paradigm that “there is no reason to assume that AI is anything more than a set of rules devised by humans to help carry out their knowledge tasks more efficiently” (Danesi and Matthews 2019: 204) still remains largely unquestioned.
The following paper will address the issue of AI and digital technologies in the humanities, arguing that the gradual devaluation of the humanities in contemporary knowledge transfer economy may partially be caused by the inability to rethink and reposition itself as a discipline within the digital transformation despite the emergence of a new grove of possibilities in, with and for AI and digital technologies. In order to exemplify this overarching theme, we will focus on one specific instance of AI in relation to language use and the humanities: autocompletion and predictive texting. We will first of all define the terminology, underlying work processes, and their implications. Secondly, we will propose a theoretical semiotic model of communication derived from the traditional frameworks of de Saussure, Ogden/Richards, and Searle. Thirdly, we will present the findings of a statistical analysis of Twitter data on predictive texting that support the proposed theoretical framework and illustrate the interrelation between traditional humanities, digital humanities, and contemporary knowledge exchange economy. Fourthly, we will situate the findings within the context of humanities between marginalization and societal impact.
2 Digital humanities and knowledge exchange
In recent years, the humanities have increasingly been criticized for being a predominantly theoretical domain with a clear-cut distinction between the discipline proper and its applications both on the micro and macro level (cf. Kirsch 2014; Leroi 2015; Straumsheim 2014). Some fields like linguistics articulate this dichotomy in their self-definition and base the corresponding applications of the theoretical frameworks on a hierarchical scale (cf. Lyons 1968), whereas the humanities themselves are confronted with their practically oriented counterpart – the Digital Humanities (DHs). Even though there exist numerous attempts at a definition of the term (cf. Terras et al. 2013), the acknowledgment of a lack thereof in Warwick’s Digital Humanities in Practice may have best described its dilemma: the DHs are both “the application of computational or digital methods to humanities research” and “the application of humanities methods to research into digital objects or phenomena” (2012: xiv). Despite offering the possibility for a new methodology, the DHs have never fully emerged as a separate discipline within the humanities due to structural resistance within the academic community and a culture of marginalization of evolving trends (cf. Joula 2008; Prescott 2011).
The possibility of a new methodology, however, would be beneficial to the humanities in general and allow for an expansion of subject-specific ideas. On the one hand, the humanities have been gradually devalued and demonetized by reallocating significant parts of funding to the sciences, which has resulted in a steady decline of graduate students (cf. Costa 2019: 2). This tendency has correlated with the progressing shift from a resource- to a knowledge-based economy (cf. Powell and Snellman 2004). With knowledge transfer ecosystems between universities, industry, government, and the public as a precondition for social and technological innovation (cf. Caravannis and Campbell 2009), the strategic orientation of universities has steered toward more practicability than theory and a higher degree of knowledge transfer activities (cf. Giuri et al. 2019). In this newly evolving environment, the DHs as an inter- and transdisciplinary field are situated between the theoretical humanities and their external application. Digital Editions, for instance, make research available to the general public, software solutions like Transkribus allow private and academic individuals to work together on research activities and simultaneously offer a low threshold for using and understanding AI, the inherent digital, cocreational methods align with the requirements of transfer and their focus on digitality speaks to contemporary issues. The DHs are a growing field that may, upon equal integration with the humanities, offer new insights and counteract the downward trend of graduates.
On the other hand, the subject-specific digital inquiries and solutions open up a new research area. In the given instance of predictive texting and autocompletion, the digital statistical analysis simultaneously reviews the proposed theoretical model as an application and thereby addresses a larger scale research into the interrelations between AI and the humanities. This study of dependencies of AI and language use is crucial to the contemporary digital society, as AI is present in various forms in everyday life. In communication and language-use especially, a lack of understanding of what effects AI may have on the individual level can lead to language bubbles. It requires knowledge on both digital issues and sign systems in language, which the DH offer. While software developers create AI according to a set system, scholars in the humanities without digital expertise can solely interpret the results but not the process of AI-mediated language-creation itself. This process, however, is a necessary precondition for the interpretation of the language used by AI. We, therefore, offer a DH perspective on the reciprocal relationship of sign systems and language use based on a mediation of AI with regard to predictive texting and autocompletion.
The terms “predictive texting” and “autocompletion” refer to common features on mobile devices to simplify text entry by predicting words or suggesting and completing search query entries. During the rise of key pad mobile phones, predictive texting algorithms based on a defined data set of language like T9 significantly accelerated the texting process by reducing the number of key strokes (cf. Ling 2007). With the emergence of smartphones and digital keyboards, predictive texting and autocompletion systems have largely converged in their functions. Recent studies suggest that instead of using an algorithm to predict words based on statistical values, the latest AI models on smartphones or search engines use a much larger data set for suggesting and completing both text and query entries, which is further customized by time of entry, location, verbal, textual, or cache context as well as demographic features in real time (cf. Farzi and Taherv 2020; Vuong et al. 2021).
The data sets and customization pose certain issues concerning bias and agency in communication, however. First of all, the data sets themselves are inherently biased (cf. Wich et al. 2022). Data sets for language modeling cannot account for every variation, vernacular and other deviations from the perceived standard and, therefore, favor one standard variation by default. Secondly, the customization of suggestions based on, among other variables, personal language use, advertising and a contemporary standard variation data set which prioritizes current themes, and terminology enhances the probability of certain wordings. Thirdly, and a direct result of the customization process, AI suggestions are considered and have been judged to be active agents in the process of meaning-creation (cf. Oster 2015). This legal liability of agency has compelled companies to alter data sets and algorithms to detect and hide derogatory and defamatory content, perceived fake news, and gender insensitive language among others (cf. Baron 2020). The more AI suggestions hide and personalize results, the higher is the degree of agency in meaning-creation and, therefore, in the effect on language use, culminating in textual isoglosses – an AI agency-based boundary of linguistic variation that impacts the reciprocal relationship of sign systems and language use.
3 The semiotic pyramid
In traditional linguistics, semiotics – the study of sign systems – still play a pivotal role in the attempt at defining the interrelations between signs, language, and the shaping of reality. Predating Ferdinand de Saussure as the founding father of modern semiotics, Shakespeare alluded to the intricate nature of signs in language in his play Romeo and Juliet: “What’s in a name? That which we call a rose/By any other name would smell as sweet.” (II.II, l. 170–72) The word “rose,” a linguistic form called the signifier by de Saussure, is an arbitrary assembly of sounds that denotes the concept or the meaning of the form, called the signified by de Saussure, in a reciprocal process (cf. 1959: 66). The “word” rose thus evokes the picture of a thorny flower with red petals and a sweet odor in the mind without the precondition of seeing the flower or indeed the necessity of having ever seen this flower before. The perception of reality is, therefore, shaped by the relation and association between signifier and signified, not the actual object itself.
Ogden and Richards built upon this core principle of semiotics and integrated the actual external reality into their concept. While they agreed with the dichotomy of signifier and signified, they argued that the referent, the physical object that can be seen, touched and smelled, is the root for the signifier and refers directly to the signified. Thus, the bilateral relation needed to be adjusted into a triangle. The ensuing semiotic triangle is widely regarded as one of the centerpieces of today’s semiotics (cf. McElvenny 2014).
However, both theories have to a certain extent neglected to take into consideration the communicative characteristic of utterances. Even though Ogden and Richards propose the idea of two partially overlapping triangles in discourse, the separation of a conversation into two distinct but overlapping spheres is problematic as it does not account for illocutionary speech acts. Searle’s and Vanderveken’s theory on the direction of fit as the basis for the taxonomy of illocutionary acts extended the existing semiotic theories into discourse. They classified four possible directions of fit in language, by which either the utterance fits the state of affairs in the world (word-to-world), the world changes to fit the utterance (world-to-word), the world changes by declaring it being changed through the utterance (double direction), or the change of the world presupposes the utterance (null direction) (cf. 1975: 52). By placing the interrelation between signifier, signified, and referent inside and combining it with discourse, Searle de facto created but never postulated a semiotic square. In this square, the referent conceptualizes the signified through the utterance of the signifier, which is then decoded by the interlocutor. The acceptance or rejection of the illocutionary act, then, refers back to the signified, which in turn creates a feedback loop to the referent and by proxy to the signifier, which finalizes and constitutes the exchange (Figure 1).
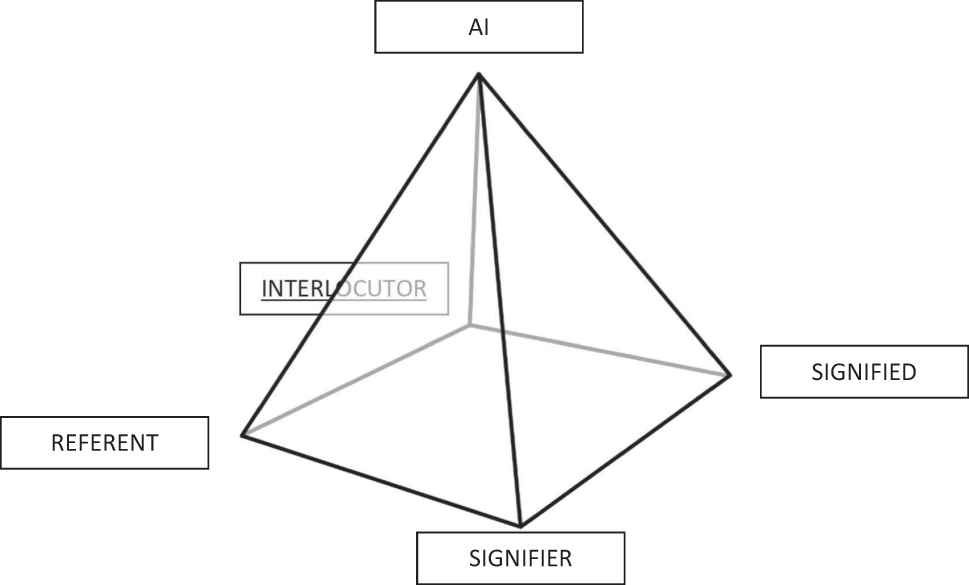
Semiotic pyramid.
When AI is inserted into the exchange as an agency in meaning-creation, the two-dimensional framework is expanded into a third dimension (Figure 2).
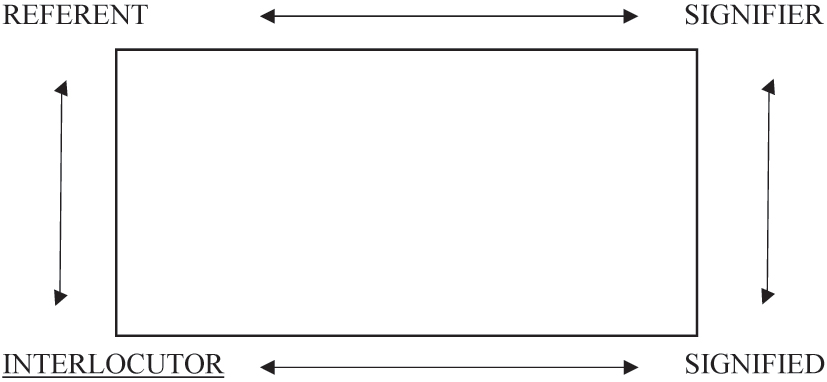
Searle and Vanderdeken’s semiotic model of fit.
In the example given, AI predicts text and suggests results. It, therefore, becomes an active part in language-creation without being part of the discourse per se. It stands above the two-dimensional communicative sphere, yet connects to every pillar of the semiotic pyramid. Firstly, the referent no longer constitutes a natural speech act. By relying on suggested text and predictions based on statistical values, the referent forfeits the locutionary completion and more crucially deflects the illocutionary force to AI. Even though the initial intention of the utterance remains with the referent, it is mediated through the involvement of AI and can no longer be solely attributed to the referent. Therefore, we propose a split of the illocutionary force into two distinct but interrelated instances: the intended and mediated illocutionary force. Secondly, the signifier is thus created by AI in relation to the referent’s statistical preferences. By further taking into account the four dimensions of customization as outlined above, AI interferes in the reciprocal process of conceptualization between referent, signifier, and signified. The referent’s fragmented locutionary act is mediated through AI to create the signifier. The signifier does not evoke the originally intended signified but a mediated instance of it that is shaped by the illocutionary force of the AI. Thirdly, it thereby reshapes the world to fit the exact time and place of the uttering. Lastly, the interlocutor is tasked with decoding the mediated illocutionary force rather than the signified itself. The acceptance of rejection by the interlocutor thus does not serve as a feedback loop to complete the utterance in discourse, but to complete the conceptualization of the AI-mediated signified, handing more and detailed data to AI about the communicative success or failure of the initial suggestion or prediction. While all of the corners of the semiotic square are still connected, the original ties are severed, since all instances of conceptualization run through the AI.
In order to analyze this theory, we have to first of all understand its implications. Natural speech acts are altered in digital communication. Predictive texting and autocompletion change the established process of the relation between language-use and sign systems. Both the underlying data sets and the feedback based on preference cause a bias in the model, though. This bias, then, solidifies language use in textual isoglosses. Repeated exposure to textual isoglosses, in turn, changes the perception of language and, therefore, reality in accordance with the conceptualization of reality within the relation of signifier and signified. Repeated exposure also introduces the notion of time as an important variable in the creation of textual isoglosses. The analyzed data should, therefore, show a change in word frequency in the extremes with regard to time, utterance, and external reality.
4 Autocompletion and predictive texting: Twitter study
4.1 Methodology
In order to test the semiotic pyramid theory and its underlying implications, we had to create a new methodological approach, in which we approximate the suggested effect of autocompletion by proving a time-dependent shift of language use on smartphone devices on the extremes that correlates with significant events in external reality (cf. Baron 2020: 412; Hazan et al. 2022: 3). We chose to analyze data accordingly and, therefore, use a proof by proxy because of several issues. First of all, a direct proof of concept on language change based on autocompletion with existing data would have required an assessment of the degree of bias in the training data and an overall account of AI feedback data on each and every individual level. Since initial training data sets by companies are not available, and the exact reasoning processes of AI algorithms concerning the integration of feedback data are a “black box” (Wenskovitch and North 2020: 31), this approach would have falsified the conclusions. Alternatively, a separate autosuggestion AI could have been developed, trained with an open data set, and used in a sterile testing environment; however, this approach would not be replicable with existing data in a digital environment and thus would not account for existing phenomena or the agency of AI in meaning-creation. Secondly, a direct proof of concept with time-dependent parameters would have to have been done on an individual level to account for the analyzed language variation. In order to achieve a representative sample on an individual level, the sheer size of the data set necessary would have rendered it impossible to analyze conclusively.
Instead, we decided to analyze an open Twitter data set on COVID-19 for scientific research (Banda et al. 2023) in order to examine our hypothesis of a time-dependent shift of language use based on word frequency and correlation. The data set is provided and hosted by Georgia State University. They began crawling data from the stream API based on relevant identifiers on March 11, 2020 up to March 15, 2023, yielding over 360 million unique tweets. Twitter data serve the purpose of our investigation well. It is almost exclusively used via smartphone, allows autocompletion via the digital keyboard, and its character limitation necessitates a textual orality that is unique to digital written communication (cf. Soffer 2020). The data on the COVID-19 pandemic are used because of the global significance of the event, which resulted in a widespread and varied digital discourse as well as a perceived radicalization of discourse (cf. Dehgan and Nagappa 2022; Schulze et al. 2022). This allows for a better analysis of the extremes and language-change therein.
In order to analyze the data in R and in accordance with Twitter’s Terms of Service, we hydrated the ID data set via Hydrator,[1] using a private developer ID. We then first of all cleaned the data set by str_remove_all mentions, hashtags, and links, iconv emojis to ASCII, str_replace_all punctuations by spaces, str_squish repeated whitespace, and changed all cases str_to_lower. Afterward, we tokenized the tweets to words and removed stop words via the stop_words data set in the tidytext variable. Notably, we did not remove any numbers due to the specifics of the term “COVID-19.” In order to account for any possibly unrelated tweets, we only counted numbers adjacent to a relevant key term. In the now clean data set, we used the findFreqTerms function to iterate from the first entry to the maximum and grouped the results according to time stamps and frequency. We did not remove retweets as they serve as much a communicative purpose as backchanneling by repeating the utterance.
4.2 Analysis
The quantitative analysis of Twitter data follows a pattern that was to be expected. After an initial outburst regarding the appearance of the virus and its global spreading, the numbers decrease on a monthly base. In 2020, the numbers remain on a high level and decline slowly from 4.2 million tweets per day on average in April to 3.8. million in May to 3.1 million in July to 2.0 million in September to 1.5 million in November. In 2021, the numbers start to dwindle from 1.2 million tweets per day on average in Q2 to 0.6 million in Q4. In 2022, the numbers level out to around 200.000 tweets per day; however, we identified five separate anomalies in communicative output as highlighted in Table 3. We used these spikes as markers to analyze the most distinct change in word frequency, suggest a link to a significant event and evaluate the distribution and sentiment over time (Figure 3).
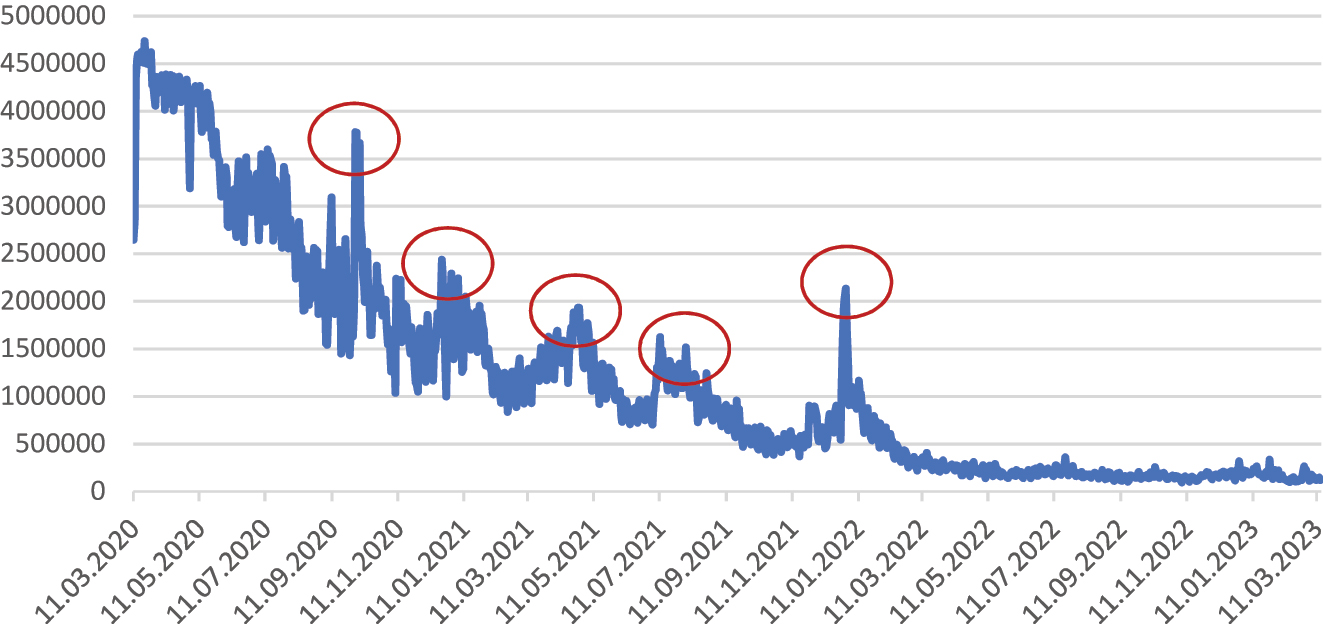
Number of tweets regarding COVID-19 from March 2020 to March 2023.
The first spike in early October 2020 coincided with Donald Trump, then president of the United States, being tested positive for COVID-19 and hospitalized (cf. Miller et al. 2020: A1). The second spike in early January 2021 coincided with the emergency use approval for vaccines by the World Health Organization (cf. Boseley 2021: 21). The third spike in May 2021 coincided with the COVAX challenge and the surge of the virus in India (cf. Webster 2021: 2054). The fourth spike manifests as a plateau between late July 2021 and early September 2021, thematically ranging between the vaccine passports, vaccine mandates, and a viral video from the podcaster Joe Rogan about the supposed effects of ivermectin (cf. Izadi and Yahr 2021: C3). The last spike between the years 2021 and 2022 coincided with no significant event other than the turn of the year in general and regulations regarding its celebration.
During the first spike, there is no significant statistical change in word frequency, phi correlation, or sentiment that we could detect other than “trump” and hospital-related terms with an increase in overall mentions in relation to the daily average by 0.52 and 0.42, respectively, and a phi correlation of 0.58. The spike in overall communication seems to be solely centered on the news that the president of the United States had been hospitalized.
The second spike shows an increase in the frequency of vaccine-related terms[2] in relation to the daily average by 0.71. The sentiment around these terms during the spike is predominantly neutral (0.91) or positive (0.07). To analyze this change further, we excluded the timeframe of the spike and looked solely at the frequency distribution of vaccine-related terms and their sentiment over the course of the other three spikes. During the third and fourth spike, vaccine-related terms are distributed rather equally (0.42 and 0.46, respectively), while the fifth spike has a lower word frequency by comparison with 0.12. The sentiment analysis for spike three and four reveal a change in the extremes, though. While the bulk of utterances is still neutral (0.85 and 0.82), the overall sentiment tendency is declining with 0.08 positive/0.07 negative and 0.06 positive/0.12 negative, respectively. A phi correlation of the five most frequent negative words in proximity to the analyzed terms over the course of spike three and four illustrate the change in language use:
Even though most correlations of negative sentiment can only be considered negligible to low, it is important to consider that the quantitative majority (0.85 and 0.82) of vaccine-related utterances are classified as neutral. In this scenario, the phi correlation coefficient of the negative term “lies” in relation to the entirety of utterances in spikes 3 and 4 is surprisingly high. Furthermore, and over time, the phi correlation coefficient of negative sentiments slightly rises, suggesting an increase of similar wordings (Tables 1 and 2).
Phi correlation of negative words in spikes 3 and 4.
| -n words spike 3 | Phi correlation |
|---|---|
| Liesa | 0.216 |
| Fake | 0.105 |
| Cancer | 0.088 |
| Misinformation | 0.062 |
| Conspiracy | 0.056 |
| -n words spike 4 | Phi correlation |
|---|---|
| Lies | 0.247 |
| Fake | 0.115 |
| Cancer | 0.096 |
| Misinformation | 0.068 |
| Conspiracy | 0.061 |
-
aIncluding inflections.
The third spike shows no significant statistical change in word frequency, phi correlation, or sentiment that we could detect other than a gradual rise of the terms “longcovid” and “boosters.” Both terms see a steady incline from peak two to three onward.
The fourth spike or plateau shows multiple anomalies, which in turn relate back to the prolonged increase in the quantity of utterances. The data highlight an increase in word frequency in relation to daily average for “ivermectin” (0.81), “passports,” “certificates” (0.72), and “mandates” (0.58). The sentiment around these terms varies greatly (Table 3).
Sentiment distribution in spike 4.
| Term | Positive | Neutral | Negative |
|---|---|---|---|
| Ivermectin | 0.14 | 0.49 | 0.37 |
| Passports/certificates | 0.09 | 0.76 | 0.15 |
| Mandates | 0.08 | 0.74 | 0.18 |
Ivermectin is strongly correlated with “worm” (0.67), which we classified as negative and which can be traced to Joe Rogan and news coverage about it. Passports/certificates and mandates show a similar distribution of sentiment with a higher degree of negative sentiment than expected. The negative sentiment of mandates correlates most strongly with “bad” (0.14), while passports/certificates correlate most strongly with “false” (0.16). The fifth spike shows no significant statistical change in word frequency, phi correlation, or sentiment that we could detect.
4.3 Discussion
The analysis of the data illustrates that there has been a change in language use in online communication during the course of the COVID-19 pandemic. We analyzed 360 million tweets with regard to word frequency and timely distribution and carefully chose the most significant variation within five anomalies during a 3-year period to find, determine, and explain the change in language use. Both the content of the tweets based on the most frequently used words and the relation to their emergence in time suggest that they correlate to a specific event in external reality that seems to have triggered the surge of a certain word or phrase, which, in combination with a given sentiment, then became relatively prevalent. The drug “ivermectin,” for instance, saw a spike in frequency during September 2021 when Joe Rogan’s account of COVID-19 went viral. Today, a Google search query autocompletion suggestion lists “ivermectin” as the eighth overall suggestion upon typing “iv.” Similarly, the overall negative sentiment rose during the pandemic with regard to vaccine-related terms. Starting at a negative sentiment distribution of 0.02 with news coverage about the development of new drugs and transmission technology, the sentiment rapidly declined to 0.07 and 0.12 during later spikes, by and large seemingly questioning their effectiveness or the need for vaccinations. Both word frequency and statistical pairing of negative terms rose. While this is no direct proof of concept regarding the influence of predictive texting or autocompletion of entries of language perception and formation, the model of the semiotic pyramid, which includes AI as an agent in meaning-creation within the sign system of communication, is reciprocal and as such necessarily impacts all pillars of the pyramid. The abovementioned example of the drug ivermectin illustrates this theory best. Even though ivermectin was first discovered in 1975 and has been in use for nearly 50 years for treatment of parasites in humans and animals (cf. Campbell 2012), its circulation on Twitter prior to the pandemic has been negligible and mostly linked to new medical discoveries or lectures. Early during the pandemic, however, the drug gained prevalence for its supposed effects on treating COVID-19. The data suggest that in the beginning of the monitoring period, “ivermectin” was still relatively scarcely used and mostly in correlation with the terms “treatment,” “cure,” or “worm.” If a word is rarely used, the feedback loop regarding correlated terms becomes indispensable for the future suggestions or predictions. In the later surge during spike 4, ivermectin is instantaneously highly correlated with “worm” in the negative extreme and “cure” or “hydroxychloroquin” in the positive extreme. This suggests that based on the referent’s preferences, AI would predict and suggest either of the two extremes to be used in the vicinity of the original term. This contextual prediction, then, qualitatively influences the possible conceptualization of the drug in its manifestation as the signified by altering its illocutionary force, as exemplified by the following, due to Twitter’s data regulations transcripted, tweets:
My wife’s daughter went to a doctor in Uniontown MO and he gave her “ivermectin” the worm medicine for her cold smmfh glad we had our shots in Tennessee.
Currently on FB recommending people take 3× the dose of ivermectin to cure the COVID virus.
Based on preference and prediction, the signified changes are according to the statistical values of AI. The process of decodation by the interlocutor, then, does not necessarily concern the intended but certainly the mediated illocutionary force.
A change in the external reality – in this case: the pandemic – affects everyday language use, which then triggers a reconfiguration of the statistical values of the AI that suggests and completes queries. This reconfiguration becomes most prevalent in the extremes as has been shown by Twitter’s own AI in the past (cf. Cherelus and Tennery 2016). It seems to create a feedback loop between AI, utterance, and external reality that fossilizes preconceived notions by suggesting and completing entries in likewise manner as posed. Thereby, AI changes the perception of reality in another form than what has previously been denoted as the “social media bubble”: through creating language, AI more or less subtly influences the user’s choice of wording, through which the user creates their own perception of reality. Through legal action and legislative concern, companies have been made aware of the issue and with the assistance of experts in the field try to mitigate the impact; however, most attempts have simply banned or hidden undesired content. This may constitute a preferable short-term solution to the companies, but it does not solve the underlying issue with AI and simultaneously directly contributes to the formation of textual isoglosses by shifting the focus away from the negative extreme and toward the positive extreme.
5 Rethinking the humanities: societal impact or marginalization?
The role of the humanities in this debate is twofold. On the subject-specific side, the humanities can offer profound insights into the workings of language, sign systems, and processes of meaning-creation through use of language. The existing theories on traditional language use, in this case illocutionary speech acts and semiotics, can be adapted to a digital environment and AI and may in turn contribute to practical solutions regarding structural problems in digital communication. Given that linguistics is but one academic field in many, other disciplines may offer different insights on these and other issues of concern. By shifting their research to the digital environment and the encompassing areas of interest to a higher degree without necessarily adopting digital methodologies in the process, the humanities can strengthen their societal impact by addressing pressing matters involving the individual, the public and private sector, as well as legislation. As such, broadening the field more into the digital would also act as a countermeasure to the gradual devaluation. More societal impact would also address the challenges posed by the knowledge transfer ecosystems to which universities increasingly subscribe. Even though the humanities excel in the area of social commitment, the focal point of knowledge transfer lies with innovation and entrepreneurship. Applying the humanities’ methods into the digital and cocreating solutions through transdisciplinary research could help foster innovation. One example of innovative methods based on original humanities’ methodology is the software Transkribus.
On the strategic side, the utilization of traditional methods in the digital realm could alleviate the intrinsic tension of the dichotomy between the digital and the humanities. The expansion of research into the digital environment could both lessen the DH need to establish itself as an entity in its own right and lead to a decrease in marginalization through tackling niche problems.
About the author
Felix Poschinger works at the Knowledge Exchange Agency at Hamburg University. His research interest focuses on the digital recontextualization of the Humanities with a special focus on contemporary communication systems.
References
Banda, Juan M., Ramya Tekumalla, Guanyu Wang, Jingyuan Yu, Tuo Liu, Yuning Ding, Katya Artemova, Tutubalina Elena & Gerardo Chowell. 2023. A large-scale COVID-19 Twitter chatter dataset for open scientific research – an international collaboration. Epidemiologia 2(3). 315–324. https://doi.org/10.3390/epidemiologia2030024.Suche in Google Scholar
Baron, Naomi S. 2020. Talking, reading, and writing on smartphones. In Richard Ling, Leopoldina Fortunati, Gerard Goggin, Sun Sun Lim & Yuling Li (eds.), The Oxford handbook of mobile communication and society, 408–424. New York: OUP.10.1093/oxfordhb/9780190864385.013.27Suche in Google Scholar
Boseley, Sarah. 2021. What difference will Oxford/AstraZeneca vaccine make in UK? The Guardian. January 2. 21.Suche in Google Scholar
Bubeck, Sébastian, Varun Chandrasekaran, Eldan Ronen, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Lundberg Scott, Harsha Nori, Palangi Hamid, Marco Tulio Ribeiro & Yi Zhang. 2023. Sparks of artificial general intelligence: Early experiments with GPT-4. https://arxiv.org/abs/2303.12712 (accessed 19 April 2023).Suche in Google Scholar
Campbell, William. 2012. History of Avermectin and Ivermectin, with notes on the history of other macrocyclic lactone Antiparasitic agents. Current Pharmaceutical Biotechnology 13(6). 853–865. https://doi.org/10.2174/138920112800399095.Suche in Google Scholar
Carayannis, Elias & David Campbell. 2009. “Mode 3” and “Quadruple Helix”: Toward a 21st century fractal innovation ecosystem. International Journal of Technology Management 46(3/4). 201–234. https://doi.org/10.1504/ijtm.2009.023374.Suche in Google Scholar
Cherelus, Gina & Amy Tennery. 2016. Microsoft’s AI Twitter bot goes dark after racist, sexist tweets. Reuters March 24.Suche in Google Scholar
Costa, Rosário Couto. 2019. The place of the humanities in today’s knowledge society. Palgrave Communications 5(38). 1–5. https://doi.org/10.1057/s41599-019-0245-6.Suche in Google Scholar
Danesi, Marcel & Stéphanie Walsh Matthews. 2019. AI: A semiotic perspective. Chinese Semiotic Studies 15(2). 199–216. https://doi.org/10.1515/css-2019-0013.Suche in Google Scholar
Dehgan, Ehsan & Ashwin Nagappa. 2022. Politicization and radicalization of discourses in the Alt-Tech ecosystem: A case study on gab social. Social Media + Society 8(3). 1–12.10.1177/20563051221113075Suche in Google Scholar
Documenting the Now. 2020. Hydrator [Computer Software]. Available at: https://github.com/docnow/hydrator (accessed 19 April 2023).Suche in Google Scholar
Farzi, Saeed & Saedeh Tahery. 2020. Customized query auto-completion and suggestion – a review. Information Systems 87. 47–59. https://doi.org/10.1016/j.is.2019.101415.Suche in Google Scholar
Giuri, Paola, Federico Munari, Alessandra Scandura & Laura Toschi. 2019. The strategic orientation of universities in knowledge transfer activities. Technological Forecasting and Social Change. An International Journal 138. 261–278. https://doi.org/10.1016/j.techfore.2018.09.030.Suche in Google Scholar
Hazan, Timothy, Alexandra Olteanu, Gabriella Kazai, Fernando Diaz & Michael Golebiewski. 2022. On the social and technical challenges of web search autosuggestion moderation. First Monday 27(2). 1–17.10.5210/fm.v27i2.10887Suche in Google Scholar
Ipsos. 2022. Global opinions and expectations about artificial intelligence. New York: Ipsos.Suche in Google Scholar
Izadi, Elahe & Emily Yahr. 2021. Joe Rogan has Covid-19, is taking unproven deworming medicine. The Washington Post September 03. C3.Suche in Google Scholar
Joula, Patrick. 2008. Killer applications in digital humanities. Literary and Linguistic Computing 23(1). 73–83.10.1093/llc/fqm042Suche in Google Scholar
Kennedy, Brian, Alec Tyson & Emily Saks. 2023. Public awareness of artificial intelligence in everyday activities. New York: PEW Research Center.Suche in Google Scholar
Kirsch, Adam. 2014. Technology is taking over English departments. The false promise of the digital humanities. The New Republic May 2.Suche in Google Scholar
Kozyreva, Anastastia, Stefan Herzog, Philipp Lorenz-Spreen, Ralph Hertwig & Stephan Lewandowsky. 2020. Artificial intelligence in online environments. Representative survey of public attitudes in Germany. Berlin: Max Planck Institute for Human Development.Suche in Google Scholar
Leroi, Armand Marie. 2015. One republic of learning: Digitizing the humanities. New York Times February 13.Suche in Google Scholar
Ling, Richard. 2007. The length of text messages and use of predictive texting: Who uses it and how much do they have to say? AU Tesol Working Papers 4. 1–18.Suche in Google Scholar
Lyons, John. 1968. Introduction to theoretical linguistics. Cambridge: CUP.10.1017/CBO9781139165570Suche in Google Scholar
McElvenny, James. 2014. Ogden and Richards’ the meaning of meaning’ and early analytic philosophy. Language Sciences 41(B). 212–221. https://doi.org/10.1016/j.langsci.2013.10.001.Suche in Google Scholar
Miller, Zeke, Jill Colvin & Aamer Madhani. 2020. Trump leaves hospital, says ‘I Feel Good’. The Times October 6. A1.Suche in Google Scholar
Oster, Jan. 2015. Communication, defamation and liability of intermediaries. Legal Studies 35(2). 348–368. https://doi.org/10.1111/lest.12064.Suche in Google Scholar
Powell, Walter & Kaisa Snellman. 2004. The knowledge economy. Annual Review of Sociology 30. 199–220.10.1146/annurev.soc.29.010202.100037Suche in Google Scholar
Prescott, Andrew. 2011. Consumers, creators or commentators? Problems of audience and mission in the digital humanities. Arts & Humanities in Higher Education 11(1-2). 61–75. https://doi.org/10.1177/1474022211428215.Suche in Google Scholar
Saussure de, Ferdinand. 1959. Course in general linguistics. New York: Philosophical Library.Suche in Google Scholar
Schulze, Heidi, Julian Hohner, Simon Greipl, Maximilian Girgnhuber, Isabell Desta & Diana Rieger. 2022. Far-right conspiracy groups on fringe platforms: A longitudinal analysis of radicalization dynamics on telegram. Convergence: The International Journal of Research into New Media Technologies 28(4). 1103–1126. https://doi.org/10.1177/13548565221104977.Suche in Google Scholar
Searle, John & Daniel Vanderveken. 1975. Foundations of illocutionary logic. Cambridge: CUP.Suche in Google Scholar
Soffer, Oren. 2020. From textual orality to oral textuality: The case of voice queries. Convergence: The International Journal of Research into New Media Technologies 26(4). 927–941. https://doi.org/10.1177/1354856519825773.Suche in Google Scholar
Straumsheim, Carl. 2014. Digital humanities bubble. Inside Higher Education 8. 6–9.Suche in Google Scholar
Terras, Melissa, Julianne Nyhan & Edward Vanhoutte. 2013. Defining digital humanities. A reader. Farnham: Ashgate.Suche in Google Scholar
Vuong, Tung, Salvatore Andolina, Giulio Jacucci & Tuukka Routsalo. 2021. Spoken conversational context improves query auto-completion in web search. ACM Transactions on Information Systems 39(3). 1–32. https://doi.org/10.1145/3447875.Suche in Google Scholar
Warwick, Claire, Melissa Terras & Julianne Nyhan. 2012. Introduction. In Claire Warwick, Melissa Terras & Julianne Nyhan (eds.), Digital humanities in practice, xii–xx. London: Facet.10.29085/9781856049054Suche in Google Scholar
Webster, Paul. 2021. COVID-19 timeline of events. Nature Medicine 27. 2054–2055. https://doi.org/10.1038/s41591-021-01618-w.Suche in Google Scholar
Wenskovitch, John & Chris North. 2020. Interactive artificial intelligence: Designing for the ‘Two Black Boxes’ problem. Computer 58(8). 29–39. https://doi.org/10.1109/mc.2020.2996416.Suche in Google Scholar
Wich, Maximilian, Tobias Eder, Hala Al Kuwatly & Georg Groh. 2022. Bias and comparison framework for abusive language datasets. AI and Ethics 2. 79–101. https://doi.org/10.1007/s43681-021-00081-0.Suche in Google Scholar
© 2023 the author(s), published by De Gruyter, Berlin/Boston
This work is licensed under the Creative Commons Attribution 4.0 International License.
Artikel in diesem Heft
- Frontmatter
- Language and Culture
- Cultural conceptulisations in Elijah Akintunde’s Yoruba ballad gospel song Ijo Odi ‘Dance of the Deaf’
- Recovering from cultural blindness: multimodal Positive Discourse Analysis of metaphors in hand-drawn sketches about Islam
- Linguistic expressions of despondency: an investigation of Sangness-related Chinese catchwords
- An interpretation of the imagery symbol of the Panopticon in The Eye in the Door
- Social and Historical Semiotics
- Toward a semiotic pyramid: language studies, AI, and knowledge exchange economy
- Human sense and plant blindness
- Semiotic rhetoric of gift giving in ancient China
- Digital tildes (“∼”) may convey more: analyzing innovative uses of tildes in Chinese WeChat messages
Artikel in diesem Heft
- Frontmatter
- Language and Culture
- Cultural conceptulisations in Elijah Akintunde’s Yoruba ballad gospel song Ijo Odi ‘Dance of the Deaf’
- Recovering from cultural blindness: multimodal Positive Discourse Analysis of metaphors in hand-drawn sketches about Islam
- Linguistic expressions of despondency: an investigation of Sangness-related Chinese catchwords
- An interpretation of the imagery symbol of the Panopticon in The Eye in the Door
- Social and Historical Semiotics
- Toward a semiotic pyramid: language studies, AI, and knowledge exchange economy
- Human sense and plant blindness
- Semiotic rhetoric of gift giving in ancient China
- Digital tildes (“∼”) may convey more: analyzing innovative uses of tildes in Chinese WeChat messages