Modern and post-modern portfolio theory as applied to moneyline betting
-
David A. Harville


Abstract
Modern and post-modern portfolio theory were devised by Harry Markowitz (among others) for purposes of allocating some monetary resources among a number of financial assets so as to strike a suitable balance between risk and expected return. The problem it addresses bears a considerable resemblance to one encountered in making “moneyline” bets on the outcomes of contests in sports like American football. In distributing some allotted funds among a number of such bets, it may be desired to account for the risk. By introducing suitable modifications, the procedures employed in modern and post-modern portfolio theory for the allocation of resources among financial assets can be adapted for use in the distribution of funds among multiple bets. As in the case of financial assets, the most appropriate measures of risk are ones like the semi-deviation or semi-variance that penalize only negative or below-target returns. The various procedures are illustrated and compared by applying them retrospectively to moneyline bets on the outcomes of the college football “bowl” games from the 2020 season.
1 Introduction
Betting on the outcomes of sporting events is an activity with widespread appeal. Typically, there are a number of such events that may be of interest to a would-be bettor and about which they may possess at least some seemingly relevant information. That interest and information needs to be parlayed into decisions as to which bets to place and how to distribute among those bets whatever funds are to be devoted to that activity. Those decisions may be based at least in part on the differences among the prospective bets in what is perceived to be the expected returns and also on differences in the perceived risks. In some cases, those differences may be substantial.
The issues faced by a would-be bettor are similar to those faced by a would-be investor in the financial markets. Deciding which bets to place corresponds to deciding which financial assets to purchase, and the decisions faced by a bettor in distributing the allotted funds among the selected bets are similar to those faced by an investor in allocating a total amount among the selected financial assets. A basic problem encountered by both the bettor and the investor in the selection process and in the allocation of resources is that of striking a suitable balance between the expected return and the underlying risk. The problem of striking such a balance in the allocation of financial resources was addressed by Markowitz (1952) in groundbreaking work which eventually led to the awarding of a Nobel Prize. His work underlies what has come to be known as modern portfolio theory or (depending on the definition of risk) post-modern portfolio theory.
Modern and post-modern portfolio theory can be adapted for use by bettors in addressing their version of the allocation problem. However, there are some meaningful differences between that version and the version faced by an investor in the finantial markets. In devising and implementing an adaptation of modern or post-modern portfolio theory to be used for betting purposes, those differences need to be taken into account. The problem of devising and implementing a suitable adaptation is addressed in what follows.
Depending on the sport and possibly on the part of the world, there can be a number of different kinds of bets that can be made on a sporting event. The focus herein is on a version of the allocation problem encountered in making bets on the outcomes of basketball or American football games, with emphasis on the case where a bet is to be made for each of a number of games that a specified one of the two opposing teams will win the game outright (i.e., without regard to the margin of victory)—subsequently, American football is referred to simply as football. Basketball and football, both professional as in the case of the NBA (National Basketball Association) and NFL (National Football League) and collegiate as in the case of the NCAA (National Collegiate Athletic Association), are of widespread interest and are the subject of a great deal of betting activity. Clearly, betting on a team to win outright can (at least in the case of a “longshot”) be very risky, so that in making multiple bets of this kind control of the overall level of risk could be an important consideration. Moreover, allocation procedures devised for these sports and for bets of this kind can be adapted for use in other circumstances, often with minimal modifications.
The potential payoff from a bet on a team to win a game outright is generally determined (at least in the United States) by something called the moneyline, and a bet of that kind is sometimes referred to as a moneyline bet. For any game for which moneyline betting is available, there are typically two moneylines, one for each team. A team’s moneyline consists of a number, either a positive number above (or conceivably equal to) 100 or a negative number below −100; a positive moneyline indicates that the team is an underdog, while a negative moneyline indicates that the team is favored to win or (in the case of a moneyline only marginally below −100 like −105 or −110) that it is a slight underdog or is evenly matched with its opponent. For every 100 dollars bet on a team with a positive moneyline of ml (where ml ≥ 100), the bet results in a net return of ml dollars or a loss of $100 depending on whether the team wins or loses. For example, the result of a 200-dollar bet on a team with a moneyline of 320 is either a profit of $640 or a loss of $200. Alternatively, if the team’s moneyline is negative, say −ml (where ml > 100), then a bettor must risk a loss of ml dollars for every 100 dollars in potential profits. Thus, a 500-dollar bet on a team with a moneyline of −250 would lead either to a profit of $200 or a loss of $500. In the case of a bet on a game that ends in a tie (as can happen in an NFL game, albeit infrequently), no money changes hands—a result of this kind is referred to as a push. Moneylines originate with entities known as sportsbooks and can vary (slightly for the most part) over time as well as from one sportsbook to another; bets are governed by whatever moneylines are posted at the time the bets are made.
In differentiating between the two opposing teams in a basketball or football game, it is convenient and somewhat conventional to use the site of the game as a distinguishing feature and to refer to one team as the home team and the other as the visiting team—in the case of a neutral site, one of the two teams can arbitrarily (for identification purposes only) be labeled the home team. Accordingly, consider the quantity, say dif, obtained from the final score of a game upon subtracting the score of the visiting team from that of the home team, and observe that a moneyline bet can be regarded as a bet that dif > 0 or alternatively a bet that dif < 0, depending on whether the bet is on the home team to win or the visiting team to win. Thus, moneyline bets are bets of a kind that can be characterized as depending on the final score of the game and on depending on it only through the value of dif. In fact, they are one of two prominent kinds of bets that can be characterized in that way; the other is a kind of bet customarily referred to as a point spread bet or simply as a spread bet.
Point spread betting differs from moneyline betting primarily in that winning is defined relative to a value of dif that (in general) differs from 0. This value is commonly referred to as the betting line or the (point) spread and can be either positive or negative; it is to be denoted herein by the symbol bl. A spread bet (like a moneyline bet) can be placed on either the home team or the visiting team; a spread bet on the home team is a bet that dif > bl, whereas a spread bet on the visiting team is a bet that dif < bl. For every 100 dollars that would accrue to a bettor from a successful spread bet, they must risk losing an amount that is typically $110 (but is occasionally $115 for spread bets on one team and $105 for spread bets on the other)—when dif = bl (which can happen if bl is an integer as is sometimes the case), the bet results in a push (i.e., no money changes hands). A betting line is initiated and maintained (somewhat independently) by each sportsbook, with changes being introduced from time to time reflecting (at least in part) an attempt to maintain a reasonable balance between the total amount bet on the home team and that bet on the visiting team—analogous to the policy governing the placing of a moneyline bet, a spread bet is based on whatever betting line is posted at the time the bet is placed. Because of the way in which it is determined, the betting line can be regarded as a “consensus” (point) predictor for the value of dif—it can be thought of as reflecting the so-called wisdom of the crowd.
The general form of a spread bet is similar to that of a moneyline bet—in spread betting, the role of a moneyline is assumed by the amount (usually $110, but occasionally $115 or $105) placed at risk for every $100 in potential profit. Accordingly, a procedure devised for distributing an allotted sum among a number of moneyline bets can (with only minor modifications) be used to distribute an allotted sum among a number of spread bets. More generally, it can be used to distribute an allotted sum among an assortment of bets consisting of both moneyline bets and spread bets; such an assortment may even include a moneyline bet and a spread bet on the same game as in a case considered by Berkowitz, Depken II, and Gandar (2018a).
Moneyline bets and spread bets are by no means the only kinds of bets that can be made on a basketball or football game. Among the other kinds of bets are over/under bets (which typically pertain to the number of points scored by one of the teams or the total number scored by both), first-half bets (which are based on the score after the first half of play rather than on the final score), bets that can be made while the game is in progress (such as halftime bets), and bets pertaining to a statistic that reflects some aspect of the performance of one of the teams or of an individual player (e.g., the number of touchdowns scored by a football team). The extent of the modifications needed to accomodate the inclusion of various such bets (in a procedure devised for distributing an allotted sum among a number of moneyline bets) could vary considerably depending on the characteristics of the bets to be included.
Subsequently, in Section 2, the problem of distributing an allotted sum among a number of moneyline bets is formulated and some distinguishing features are identified and discussed. That is followed (in Section 3) by the introduction of an example (extracted from the 2020 college football season) and (in Section 4) by the presentation and illustration of procedures for distributing the allotted sum among the bets in a way that strikes a suitable balance between risk and expected return. The final section (Section 5) is devoted to some concluding remarks.
2 Formulation of the problem
2.1 Actual and expected net proceeds from a moneyline bet
For any particular basketball or football game (for which moneyline betting is available), a moneyline bet can be placed on the home team or alternatively on the visiting team. Let hml represent the moneyline pertaining to a moneyline bet on the home team and vml that pertaining to a moneyline bet on the visiting team. Further, let hrtn represent the winnings per dollar wagered from a successful moneyline bet on the home team and vrtn the analogous quantity for a successful moneyline bet on the visiting team, and observe that
Note that the net proceeds (per dollar wagered) from a moneyline bet, say hnet in the case of a moneyline bet on the home team and vnet in the case of a moneyline bet on the visiting team, is determined by hrtn or vrtn together with the outcome of the game as reflected in the value of the variable dif (which equals the final score of the home team minus the final score of the visiting team). Specifically,
Let us regard dif as a random variable, in which case the events defined by the inequalities dif > 0 and dif < 0 and by the equality dif = 0 are random events. Further, let p = Pr(dif > 0) (i.e., the probability of the game being won by the home team) and q = Pr(dif < 0) (i.e., the probability of the game being won by the visiting team). For the sake of simplicity, let us assume that Pr(dif = 0) = 0, as would be the case in basketball or college football; or, alternatively, redefine p as p = Pr(dif > 0|dif ≠ 0) and q as q = Pr(dif < 0|dif ≠ 0) (and recall that the event dif = 0 results in a “push”). Then,
and the expected value of the net proceeds from a moneyline bet is
depending on whether the bet is on the home team or on the visiting team.
The moneylines hml and vml are established by the so-called sportsbook. One way to approach the establishment of hml and vml is to specify a value for p or for p/q (the odds of the game being won by the home team) and to require that
where α is a small positive constant to be specified; α is interpretable as the fraction of the money expected to be taken in from the losing bettors that is expected to be diverted from distribution to the winning bettors and retained by the betting proprietor, and it reflects what is commonly known as the “vig” (as in vigorish) or the “juice”. Condition (2) is reexpressible in the form
where vrat = (vrtn + 1)/tot and tot = hrtn + vrtn + 2. Moreover, condition (3) is satisfied (uniquely) by taking
or equivalently by taking
and ultimately by taking the moneylines hml and vml to be those for which the corresponding hrtn and the corresponding vrtn satisfy condition (4). Clearly, the moneylines generated by this approach could vary greatly depending on how p or p/q is specified.
An alternative way of establishing hml and vml is to adopt an “empirical” approach that makes use of the relative amounts bet on the two opposing teams. Let hdol represent the total amount bet (by all bettors) on the home team and vdol the total amount bet on the visiting team, and observe that if hrtn and vrtn (and hence hml and vml) satisfy the condition formed by the two equalities
then (regardless of which team wins the game) a fraction α of the total amount wagered on the two teams is retained by the betting proprietor. Observe also that condition (5) is equivalent to the condition
where
or in the form
The betting proprietor has no direct control over
The implementation of such an approach is facilitated by observing that (since
It can be shown that there exists a strictly decreasing function, say
In practice, the moneylines appear to be established via a somewhat convoluted and competitive process undertaken by multiple sportsbooks; the operative moneylines may be changed from time to time in response to “imbalances” in the betting pattern or to other issues. The moneylines affect the profits of the betting proprietor not only through their effect on the profit margin but also through their effect on the volume of betting. There is a tradeoff; increasing hrtn and vrtn increases the volume at the expense of smaller margins. To the extent that the moneylines are determined by imposing condition (2) or (5), it is the choice of α that determines where the balance is struck between volume and margin. Some data-driven insights into the operations of the sportsbooks are provided by Levitt (2004).
Had the moneylines been established by imposing condition (2), the underlying p and α would have been as follows:
Alternatively (and similarly), had they been established by imposing condition (5) or equivalently condition (6), the underlying
In light of results (10) and (11), it could be of interest to consider the quantity p defined (in terms of hrtn and vrtn and ultimately in terms of hml and vml) by the expression
If the moneylines had been determined by the sportsbook based on the imposition of condition (2), then this quantity would represent the probablity they had used in doing so. Alternatively, if the moneylines had been determined based on the imposition of condition (5), then this quantity could be regarded as a probability that had been determined by the bettors themselves; a probability determined in such a manner is said to have been determined by the “wisdom of the crowd”. In regard to the underlying α, it is informative [in contemplating results (10) and (11)] to consider the case of two “evenly matched” teams (where p or
Now, suppose that the operative p and q are those adopted by a would-be bettor, and observe that from the perspective of a would-be bettor, the moneylines hml and vml are a given. Accordingly, what could be of some interest are the two “breakeven” points, say pmin and qmin, consisting respectively of the smallest value of p for which hmu ≥ 0 and the smallest value of q for which vmu ≥ 0. From result (1), it is evident that
Moreover, if the moneylines were those established by imposing condition (2) or condition (6), then it would be the case that
as can be readily verified. More generally, regardless of how the sportsbook may have arrived at the moneylines, it is invariably the case that
—if pmin + qmin were less than 1, there would exist fractions p* and q* such that p* > pmin, q* > qmin, and p* + q* = 1, and a bettor could achieve a profit regardless of the outcome of the game by betting a fractional amount p* on the home team and a fractional amount q* on the visiting team.
It is also the case that the probabilities pmin/(pmin + qmin) and qmin/(pmin + qmin) obtained upon normalizing pmin and qmin are equal to what would have been the underlying p and q or underlying
While there are some similarities between the placing of a moneyline bet on the outcome of a basketball or football game and making an investment in a financial asset, there are also a number of differences. These differences vary in their relevance and importance and include the following:
The net proceeds from a moneyline bet, represented herein (on a per dollar basis) by hnet or vnet, can be regarded as a binary or (if a tie is a possible outcome) trinary variable. By way of comparison, the net proceeds from an investment in a financial asset can generally be regarded as a continuous variable.
An investment in a financial asset may be maintained for an extensive length of time, and in the context of such an investment, the expected value of a random quantity can be interpreted as an average value over a number of time periods (e.g., Estrada 2008). In contrast, a basketball or football game (the outcome of which determines the net proceeds from a moneyline bet) is a one-time event of relatively short duration.
The transaction costs encountered in investing in financial assets tend to be relatively minimal and to be in the form of “add-ons”. The transaction costs encountered in moneyline betting are “built-in” and are generally more substantial; their existence is reflected in result (14).
Some financial assets can be sold short; if the net proceeds per dollar from an investment in such an asset equal x, then (aside from any transaction costs) the net proceeds per dollar from the corresponding short sale of that asset equal −x. Aside perhaps from the case of a game where the moneyline for a bet on one of the two opposing teams is the same as that for a bet on the other, there is nothing comparable to a short sale in moneyline betting.
2.2 Multiple bets
Now, suppose that one wishes to distribute a specified sum among some number, say K, of different moneyline bets. Accordingly (for i = 1, 2, …, K) let x
i
represent a random variable whose value is either the winnings per dollar wagered, say r
i
, from the ith bet or −1, depending on whether or not the ith bet is successful—when hml or vml equals the moneyline for the ith bet, r
i
= hrtn or r
i
= vrtn (where hrtn and vrtn are as defined in Subsection 2.1). Further, let w
1, w
2, …, w
K
represent K “weights” (so that w
1, w
2, …, w
K
are nonnegative and sum to 1), and consider a procedure for distributing the total amount in which (for i = 1, 2, …, K) a portion w
i
of the total is allocated to the ith bet. Then, the net proceeds per dollar from the collection of K bets is
For i = 1, 2, …, K, denote by p i the probability of the ith bet being successful, and let q i = 1 − p i and μ i = E(x i ). Then, recalling result (1),
Further, let
where μ = (μ 1, μ 2, …, μ K )′.
Perhaps foremost among the metrics that might be used to evaluate the combination
Let
where V is the variance-covariance matrix of x and σ ij is the ijth element of V. Further, the ith residual x i − μ i equals q i (r i + 1) with probability p i and equals −p i (r i + 1) with probability q i . Accordingly,
More generally, denoting by
To factor in the variance
Clearly,
Now, suppose that
The pair of
Let us continue to suppose that
where I is a subinterval of the interval (20) and
are members of the efficient frontier (22), (2)
An alternative (to the variance) measure of risk is the so-called semi-variance, which was considered early on (in the context of the allocation of funds among financial assets) by Markowitz (1959, ch. IX) and is to be denoted herein by the symbol
where
It is worth noting that
While the semi-variance may be a more suitable measure of risk than the variance, its use as a measure of risk makes the task of finding an efficient pair of mean- and risk-values and that of finding a corresponding vector of weights more challenging from a computational standpoint. That led Estrada (2008) to suggest (in the context of allocating resources among financial assets) an “approximation” for which the computational demands are similar to those incurred when the variance is adopted as the measure of risk. As reexpressed in the present context, this approximation is that obtained when the semi-variance is replaced (as the measure of risk) by a quadratic form
where Γ is the K × K matrix with ijth element γ ij defined as follows:
Note that in the special case where w
i
= 1 and w
j
= 0 for j ≠ i,
and for j ≠ i
As applied to an individual one, say the ith one, of the K moneyline bets, the two alternative measures of risk are σ
ii
and γ
ii
(or their square roots
For −1 < b < ∞, σ ii /γ ii is a decreasing function of b; as b increases from −1 to ∞, σ ii /γ ii decreases from ∞ to 0. More specifically, as b increaes, σ ii /γ ii decreases as follows:
| −1 < b < μ i | b = μ i | μ i < b < r i | b = r i | r i < b < ∞ |
|
|
|
|
|
|
Moreover, when μ i > 0 (i.e., when the expected value of the net proceeds from the ith moneyline bet is positive), the decrease of σ ii /γ ii as b increases from −1 to μ i can be further characterized as follows:
| −1 < b < 0 | b = 0 | 0 < b < μ i |
|
|
|
|
The mean of w′x and the different measures of the risk of w′x depend on various characteristics of the distribution of the vector x of binary random variables. Typically, the distribution of x is not known, but there exists information about this distribution, which may take the form of an N × 1 observable random vector y. In some cases, it may be possible to devise point estimators of the relevant characteristics of the distribution of x that are sufficiently accurate that they can be treated as the “true values”. More generally, a Bayesian approach could be adopted, and the distribution of x could be taken to be the conditional distribution of x given y.
2.3 Optimality
Continuing with the discussion of Section 2.2, let us consider further the choice of the vector w of weights. In doing so, let us restrict attention to situations where the choice is to be based solely on the value of
For points on the efficient frontier, ρ can be regarded as a function, say
There is some appeal in taking the function
where k is a (suitably chosen) strictly positive constant—the emphasis on the risk can be increased by increasing k. Clearly, when
Refer, for example, to Fishburn (1977) for some highly relevant discussion.
In regard to maximizing the function
which [assuming that
3 Illustrative example
Each week during an NCAA Division I-FBS college football season, there is an opportunity to bet on the next “round” of games. For most of the season, the next round of games consists of those games to be played within the next six or seven days. However, at the end of what is referred to as the “regular” season, there is an opportunity to bet on any of a number of additional games known as “bowl” games, which are played over the course of a several-week period by those of the teams that were the most “successful” during the regular season.
Following the 2020 regular season, there were 25 bowl games. The dates on which those games were played and the opposing teams in each of those games are listed in the first three columns of Table 1. For purposes of identification, one of the opposing teams is referred to as the home team and the other as the visiting team; all twenty-five of the 2020 “bowl games” can be regarded as having been played at a neutral site. It is worth noting that because of the covid-19 pandemic, there were considerably fewer bowl games following the 2020 regular season than there were following other recent seasons.
NCAA college football bowl games (2020 season): dates, opposing teams, moneylines, and predicted outcomes.
| Date | Home team | Visiting team | bl | PDiff | hml | vml | pmin | qmin |
|
|
|---|---|---|---|---|---|---|---|---|---|---|
| 12/21 | App State | North Texas | 21.0 | 22.35 | −1100 | 700 | 0.917 | 0.125 | 0.880 | 0.957 |
| 12/22 | Nevada | Tulane | −3.0 | −5.42 | 125 | −145 | 0.444 | 0.592 | 0.429 | 0.338 |
| 12/22 | BYU | UCF | 6.5 | 7.02 | −250 | 205 | 0.714 | 0.328 | 0.685 | 0.707 |
| 12/23 | La Tech | Ga Southern | −6.0 | −3.49 | 200 | −240 | 0.333 | 0.706 | 0.321 | 0.393 |
| 12/23 | Memphis | Fla Atlantic | 9.5 | 6.42 | −350 | 280 | 0.778 | 0.263 | 0.747 | 0.690 |
| 12/24 | Houston | Hawaii | 13.0 | 6.65 | −475 | 360 | 0.826 | 0.217 | 0.792 | 0.694 |
| 12/25 | Buffalo | Marshall | 3.5 | 2.26 | −160 | 140 | 0.615 | 0.417 | 0.596 | 0.567 |
| 12/26 | Coastal Caro | Liberty | 7.0 | 9.64 | −270 | 220 | 0.730 | 0.312 | 0.700 | 0.774 |
| 12/26 | UTSA | La Lafayette | −14.0 | −17.01 | 400 | −550 | 0.200 | 0.846 | 0.191 | 0.094 |
| 12/26 | Georgia St | Western Ky | 4.5 | 4.70 | −190 | 160 | 0.655 | 0.385 | 0.630 | 0.643 |
| 12/29 | Miami (Fla) | Oklahoma St | −2.0 | −1.32 | 110 | −130 | 0.476 | 0.565 | 0.457 | 0.459 |
| 12/29 | Texas | Colorado | 10.0 | 8.68 | −420 | 320 | 0.808 | 0.238 | 0.772 | 0.742 |
| 12/30 | Wake Forest | Wisconsin | −6.5 | −8.58 | 200 | −240 | 0.333 | 0.706 | 0.321 | 0.258 |
| 12/30 | Oklahoma | Florida | −3.0 | −1.13 | 130 | −150 | 0.435 | 0.600 | 0.420 | 0.465 |
| 12/31 | Tulsa | Miss State | 2.5 | 1.43 | −140 | 120 | 0.583 | 0.455 | 0.562 | 0.544 |
| 12/31 | San Jose St | Ball State | 7.5 | 4.70 | −300 | 240 | 0.750 | 0.294 | 0.718 | 0.637 |
| 12/31 | Army | W Virginia | −7.5 | −7.20 | 250 | −320 | 0.286 | 0.762 | 0.273 | 0.289 |
| 1/01 | Georgia | Cincinnati | 7.0 | 7.70 | −280 | 230 | 0.737 | 0.303 | 0.709 | 0.721 |
| 1/01 | Northwestern | Auburn | 3.5 | −0.66 | −175 | 150 | 0.636 | 0.400 | 0.614 | 0.479 |
| 1/01 | Alabama | Notre Dame | 19.5 | 17.55 | −1100 | 700 | 0.917 | 0.125 | 0.880 | 0.911 |
| 1/01 | Clemson | Ohio State | 7.5 | −0.68 | −320 | 250 | 0.762 | 0.286 | 0.727 | 0.479 |
| 1/02 | NC State | Kentucky | −2.5 | −2.10 | 115 | −135 | 0.465 | 0.574 | 0.447 | 0.435 |
| 1/02 | Indiana | Mississippi | 6.5 | 10.18 | −250 | 205 | 0.714 | 0.328 | 0.685 | 0.779 |
| 1/02 | Iowa State | Oregon | 4.5 | 1.71 | −210 | 175 | 0.677 | 0.364 | 0.651 | 0.552 |
| 1/02 | Texas A&M | N Carolina | 7.0 | 7.64 | −250 | 205 | 0.714 | 0.328 | 0.685 | 0.722 |
For each of the 25 games, a moneyline bet could have been made on the home team or alternatively on the visiting team. For purposes of illustration, let us consider the problem that would have been faced by a prospective bettor in deciding on which teams to bet in which games and in determining how to distribute some designated funds among the various bets. The betting terms (betting lines and moneylines) posted by a prominent sportsbook (and that potentially would have been available to a prospective bettor) are posted in columns 4, 6, and 7 of Table 1. Corresponding to the moneylines hml and vml are the breakeven points pmin and qmin and the probability
For each of the two moneyline bets on each of the 25 bowl games, the expected value, the standard deviation, and the semi-deviation of the net proceeds per dollar were determined by applying formulas (15), (18), and (26). In doing so, the moneylines were taken to be as listed in Table 1, and the value of b (in determining each semi-deviation) was taken to be 0.1. For each game, the probability of the game being won by the home team was taken to be the quasi-Bayesian probability. The results are listed in Table 2—to facilitate a determination of what the actual net proceeds would have been from various moneyline bets, the actual outcome of each game is also included in Table 2.
Expected value, standard deviation, and semi-deviatiion (when b = 0.1) of the net proceeds per dollar from each moneyline bet on each bowl game (and the actual score of each game).
| Home team | Net proceeds from a moneyline bet on the home team | Visiting team | Net proceeds from a moneyline bet on the visiting team | Actual score | ||||
|---|---|---|---|---|---|---|---|---|
| Exp val | Std dev | Semi dev | Exp val | Std dev | Semi dev | |||
| App State | 0.044 | 0.222 | 0.229 | North Texas | −0.652 | 1.631 | 1.076 | 56–28 |
| Nevada | −0.239 | 1.065 | 0.895 | Tulane | 0.118 | 0.799 | 0.640 | 38–27 |
| BYU | −0.011 | 0.637 | 0.596 | UCF | −0.105 | 1.389 | 0.925 | 49–23 |
| La Tech | 0.178 | 1.465 | 0.857 | Ga Southern | −0.140 | 0.692 | 0.689 | 3–38 |
| Memphis | −0.113 | 0.595 | 0.613 | Fla Atlantic | 0.180 | 1.758 | 0.913 | 25–10 |
| Houston | −0.160 | 0.558 | 0.609 | Hawaii | 0.410 | 2.121 | 0.916 | 14–28 |
| Buffalo | −0.078 | 0.805 | 0.724 | Marshall | 0.038 | 1.189 | 0.829 | 17–10 |
| Coastal Caro | 0.060 | 0.573 | 0.523 | Liberty | −0.276 | 1.339 | 0.968 | 34–37 |
| UTSA | −0.532 | 1.457 | 1.047 | La Lafayette | 0.071 | 0.344 | 0.337 | 24–31 |
| Georgia St | −0.018 | 0.731 | 0.657 | Western Ky | −0.072 | 1.246 | 0.882 | 39–21 |
| Miami (Fla) | −0.036 | 1.046 | 0.809 | Oklahoma St | −0.043 | 0.882 | 0.745 | 34–37 |
| Texas | −0.082 | 0.542 | 0.559 | Colorado | 0.085 | 1.838 | 0.947 | 55–23 |
| Wake Forest | −0.226 | 1.313 | 0.947 | Wisconsin | 0.051 | 0.620 | 0.559 | 28–42 |
| Oklahoma | 0.069 | 1.147 | 0.805 | Florida | −0.108 | 0.831 | 0.750 | 55–20 |
| Tulsa | −0.068 | 0.854 | 0.743 | Miss State | 0.004 | 1.096 | 0.811 | 26–28 |
| San Jose St | −0.150 | 0.641 | 0.662 | Ball State | 0.233 | 1.635 | 0.878 | 13–34 |
| Army | 0.010 | 1.586 | 0.928 | W Virginia | −0.066 | 0.595 | 0.591 | 21–24 |
| Georgia | −0.022 | 0.609 | 0.581 | Cincinnati | −0.079 | 1.480 | 0.934 | 24–21 |
| Northwestern | −0.247 | 0.785 | 0.794 | Auburn | 0.302 | 1.249 | 0.762 | 35–19 |
| Alabama | −0.007 | 0.311 | 0.329 | Notre Dame | −0.285 | 2.282 | 1.050 | 31–14 |
| Clemson | −0.371 | 0.656 | 0.794 | Ohio State | 0.824 | 1.748 | 0.761 | 28–49 |
| NC State | −0.065 | 1.066 | 0.827 | Kentucky | −0.016 | 0.863 | 0.725 | 21–23 |
| Indiana | 0.091 | 0.581 | 0.517 | Mississippi | −0.326 | 1.265 | 0.971 | 20–26 |
| Iowa State | −0.186 | 0.734 | 0.737 | Oregon | 0.233 | 1.368 | 0.817 | 34–17 |
| Texas A&M | 0.011 | 0.627 | 0.580 | N Carolina | −0.153 | 1.366 | 0.935 | 41–27 |
Results on the expected value of the net proceeds from each of whatever moneyline bets may be available to a prospective bettor could conceivably be used to carry out an initial screening of those bets or even in arriving at a final decision as to which (if any) bets to make. In particular, it could be desired to restrict consideration to those bets for which the expected value of the net proceeds is positive. In the case of the 25 bowl games, the moneyline bets for which the expected value of the net proceeds is positive were (when identified by team, ordered by expected value, and listed along with the standard deviation and semi-deviation) as follows:
| Team | Exp val | Std dev | Semi dev | Team | Exp val | Std dev | Semi dev |
|---|---|---|---|---|---|---|---|
| Ohio State | 0.824 | 1.748 | 0.761 | La Lafayette | 0.071 | 0.344 | 0.337 |
| Hawaii | 0.410 | 2.121 | 0.916 | Oklahoma | 0.069 | 1.147 | 0.805 |
| Auburn | 0.302 | 1.249 | 0.762 | Coastal Caro | 0.060 | 0.573 | 0.523 |
| Oregon | 0.233 | 1.368 | 0.817 | Wisconsin | 0.051 | 0.620 | 0.559 |
| Ball State | 0.233 | 1.635 | 0.878 | App State | 0.044 | 0.222 | 0.229 |
| Fla Atlantic | 0.180 | 1.758 | 0.913 | Marshall | 0.038 | 1.189 | 0.829 |
| La Tech | 0.178 | 1.465 | 0.857 | Texas A&M | 0.011 | 0.627 | 0.580 |
| Tulane | 0.118 | 0.799 | 0.640 | Army | 0.010 | 1.586 | 0.928 |
| Indiana | 0.091 | 0.581 | 0.517 | Miss State | 0.004 | 1.096 | 0.811 |
| Colorado | 0.085 | 1.838 | 0.947 |
4 Implementation
4.1 Computational considerations
Both the variance
When A = E(Q), A is what Estrada (2008) characterized as endogenous, meaning that it varies with the vector w of weights, whereas when A = V, A is exogenous in the sense that it does not vary with w. There is an implication that (as noted in Section 2.2) the minimization of the variance w′Vw subject to the constraints (21) can be regarded as a quadratic programming problem and addressed accordingly and a further implication that the minimization of w′E(Q)w subject to those constraints presents a more challenging problem.
One way to deal with the problem of minimizing w′E(Q)w with respect to w subject to the constraints (21) is to adopt the alternative proposed by Estrada (in the context of devising the optimum weights for a number of financial assets). As discussed in Section 2.2, that alternative consists of minimizing the quadratic form w′Γw in lieu of the more complex entity w′E(Q)w.
In the present context, the problem of minimizing w′E(Q)w with respect to w subject to the constraints (21) can be reformulated and (at least in principle) solved as a quadratic programming problem without resort to the introduction of an approximation. A way of doing so can be devised by making use of a method (called the MTXY method) developed for situations where the returns are those of financial assets and where the expected values of the returns are taken to be historical averages. This method was described by Markowitz et al. (2020) and earlier by Markowitz et al. (1992, 1993.
For purposes of devising an MTXY-like method that is suitable for use in the present setting, let c
1, c
2, …, c
N
represent the possible values of the K × 1 random vector x (of net proceeds per dollar), and observe that N = 2
K
. Further, let C represent the K × N matrix whose jth column is c
j
; and observe that corresponding to any column vector w = (w
1, w
2, …, w
K
)′ of weights is the vector C′w, with elements
Now, let S
− and S
+ represent subsets of the first N positive integers such that j ∈ S
− if
and upon substituting for E(Q) in the expression
where u is the N × 1 vector whose jth elements are for j ∈ S
− the elements of the N
− × 1 vector
We have established that the semi-variance of w′x is reexpressible as the sum of squares of the elements of the vector u. Moreover, upon letting z = D(C − b 11′)′w + u, we find that (by definition)
Note that equality (34) is reexpressible in the form
and that for j ∈ S
+ the jth elements of the N × 1 vector z are the elements of the N
+ × 1 vector
By including the elements, say u
1, u
2, …, u
N
, of u and the elements, say z
1, z
2, …, z
N
, of z as 2N additional variables, the problem of minimizing the semi-variance
The reformulation comes at the expense of the introduction of an additional 2N = 2
K+1 variables, which can be a very large number for even moderately large values of K. Nevertheless, it would seem that in many applications, the size of K is likely to be such that the computations required to solve the reformulated minimization problem are feasible. The computational feasibility could presumably be enhanced through the design of algorithms that are able to exploit features shared by multiple values of x. Moreover, if one wishes to determine how the minimum value of u′u varies with the value of the quantity
A solution to the problem of minimizing the nonnegative definite quadratic form w′Vw or w′Γ w subject to the constraints (21) can be obtained by making use of any of a number of software packages, some of which may require that the quadratic form be positive definite. One such package is the R package quadprog. The minimization of u′u subject to the constraints imposed by conditions (21), (35), and (36) poses a more challenging problem. At least in principle, one of the same software packages could be used to obtain a solution to this problem—Markowitz et al. (2020) considered the use of the R package CVXR for this purpose and in their Appendix C provided the requisite inputs for this use of that package. However, since the dimensions of u and z increase exponentially (as 2 K ) with the value of K, it would seem that for values of K beyond a certain point (determined by the choice of software package and by the computational resources at one’s disposal), it would as a practical matter become computationally infeasible to effect the constrained minimization of u′u. One way to address this issue (when it comes into play) would be to eliminate from consideration some additional number of bets (thereby decreasing K); the results of Section 2.3 suggest the elimination of those bets corresponding to the values of i for which g(μ i , ρ i ) is the smallest (where ρ i is the risk of the ith bet as determined in isolation on the basis of the operative measure of risk).
4.2 Illustration
For purposes of illustration, the various procedures for determining the vector w of weights were applied (retrospectively) to the example introduced in Section 3. In doing so, consideration was limited to the nineteen moneyline bets for which the expected value of the net proceeds is positive. Three different measures of risk were considered: the standard deviation
In the case where the measure of risk was taken to be the semi-deviation
The pairs of values of the mean
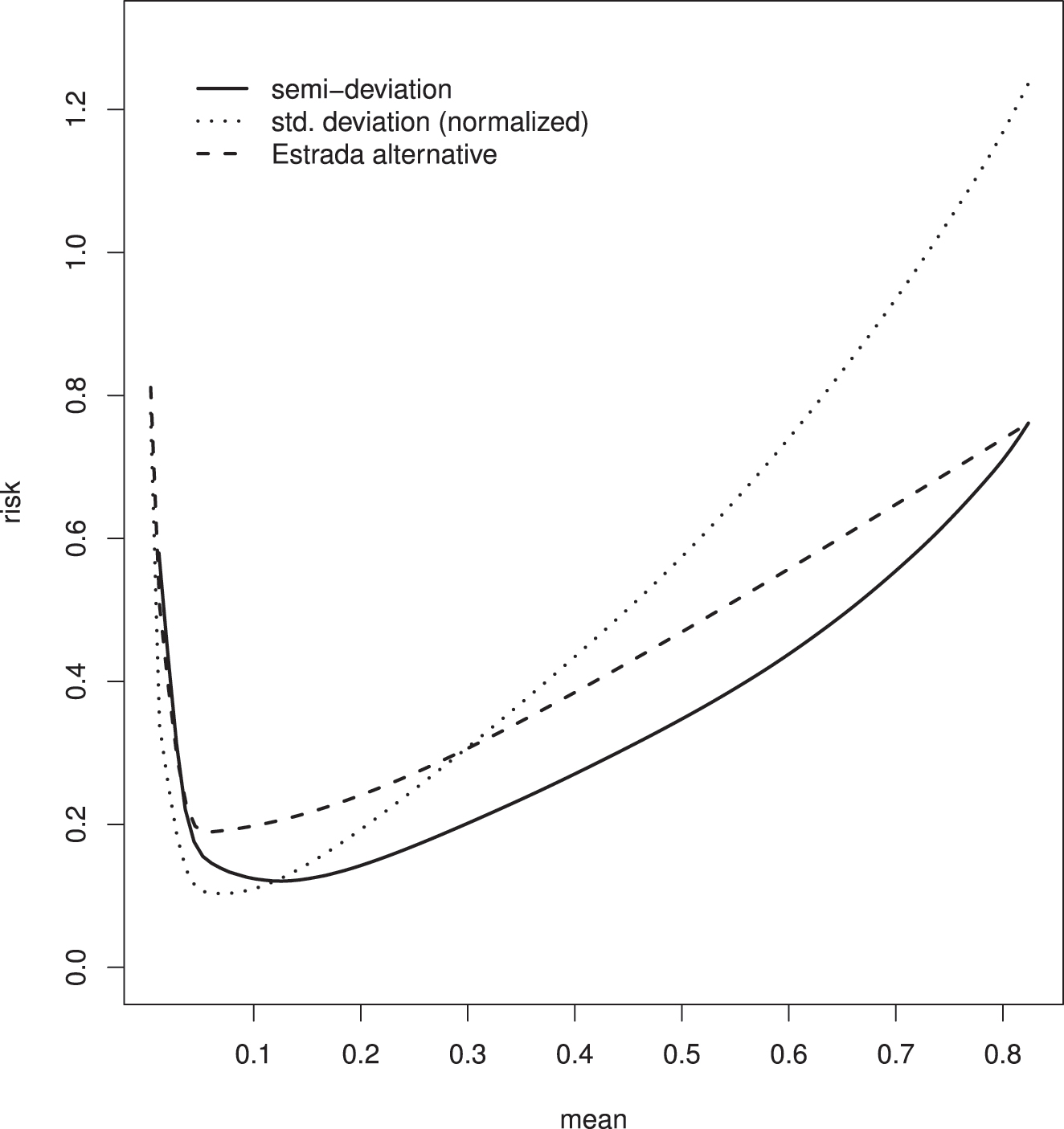
Plot of the efficient frontier (for the example) in the case where the measure of risk is taken to be the “normalized” standard deviation
The point on the efficient frontier where
—refer to expressions (29) and (30). This function attains its maximum value at
| Team | Measure of risk | Team | Measure of risk | ||||
|---|---|---|---|---|---|---|---|
| Semi dev | Std dev | Estrada | Semi dev | Std dev | Estrada | ||
| Ohio State | 0.564 | 0.092 | 1 | La Lafayette | 0.000 | 0.181 | 0 |
| Hawaii | 0.092 | 0.032 | 0 | Oklahoma | 0.000 | 0.017 | 0 |
| Auburn | 0.164 | 0.069 | 0 | Coastal Caro | 0.000 | 0.053 | 0 |
| Oregon | 0.077 | 0.042 | 0 | Wisconsin | 0.000 | 0.033 | 0 |
| Ball State | 0.055 | 0.029 | 0 | App State | 0.000 | 0.247 | 0 |
| Fla Atlantic | 0.019 | 0.019 | 0 | Marshall | 0.000 | 0.009 | 0 |
| La Tech | 0.028 | 0.028 | 0 | Texas A&M | 0.000 | 0.000 | 0 |
| Tulane | 0.000 | 0.061 | 0 | Army | 0.000 | 0.000 | 0 |
| Indiana | 0.000 | 0.081 | 0 | Miss State | 0.000 | 0.000 | 0 |
| Colorado | 0.000 | 0.007 | 0 | ||||
The values of the semi-deviation

Plot (as a function of
5 Concluding remarks
Many of the issues encountered in the distribution of funds among a number of moneyline bets are similar to those encountered in the allocation of monetary resources among a number of financial assets. Among the various considerations are the following:
As in investing in a portfolio of financial assets, it would seem that in making multiple moneyline bets there would be considerable appeal in weighting the individual entities differently from each other so as to strike a suitable balance between the expected value of the net proceeds and the level of (downside) risk. When the nineteen moneyline bets in the example of Sections 3 and 4.2 (the nineteen for which the expected value of the net proceeds is positive) are weighted equally,
There would seem to be considerable appeal in adopting the semi-deviation
There are issues that arise in betting on basketball or football games that go beyond those considered herein. In particular, there is a question of how much to bet in total that adds to the question of how to distribute the total amount among the individual bets. A complicating factor is that typically new “batches” of bets will present themselves at various times in the future, and the decision as to how much to invest in the current batch may have to be made with only minimal information about the future opportunities. One way to address this issue would be to devise an approach in which the total amount invested in the current batch is based on the value of the function
In using the approach described in Section 2 for choosing the vector w of weights, the practice of using estimates of the relevant characteristics of the distribution of x as though they were the true values should be restricted to cases where the estimators are highly accurate. When this practice is not restricted thusly, it can produce misleading results—refer, e.g., to Britten-Jones (1999). Under conditions where the relevant characteristics of the distribution of x are not well-estimated, it is important (through the use of Bayesian ideas or otherwise) to come up with a procedure that accounts for this circumstance. Lai et al. (2011) considered such an approach in the context of optimizing a portfolio of financial assets.
Acknowledgments
The author is indebted to two reviewers, whose contributions led to a number of improvements in the manuscript.
-
Author contributions: All the authors have accepted responsibility for the entire content of this submitted manuscript and approved submission.
-
Research funding: None declared.
-
Conflict of interest statement: The authors declare no conflicts of interest regarding this article.
References
Bailey, D. H., and M. López de Prado. 2013. “An Open-Source Implementation of the Critical-Line Algorithm for Portfolio Optimization.” Algoritnms 6: 169–96. https://doi.org/10.3390/a6010169.Suche in Google Scholar
Berkowitz, J. P., C. A. DepkenII, and J. M. Gandar. 2018a. “Exploiting the ‘Win but Does Not Cover’ Phenomenon in College Basketball.” The Financial Review 53: 185–204. https://doi.org/10.1111/fire.12155.Suche in Google Scholar
Berkowitz, J. P., C. A. DepkenII, and J. M. Gandar. 2018b. “The Conversion of Money Lines into Win Probabilities: Reconciliations and Simplifications.” Journal of Sports Economics 19: 990–1015. https://doi.org/10.1177/1527002517696957.Suche in Google Scholar
Britten-Jones, M. 1999. “The Sampling Error in Estimates of Mean-Variance Efficient Portfolio Weights.” The Journal of Finance 54: 655–71. https://doi.org/10.1111/0022-1082.00120.Suche in Google Scholar
Estrada, J. 2008. “Mean-Semivariance Optimization: A Heuristic Approach.” Journal of Applied Finance 18: 57–72.10.2139/ssrn.1028206Suche in Google Scholar
Fishburn, P. C. 1977. “Mean-Risk Analysis with Risk Associated with Below-Target Returns.” The American Economic Review 67: 116–26.Suche in Google Scholar
Harville, D. A. 2020. College Football Ratings and Predictions. Available at https://davidharville.com/collegefootballratingspredictions.Suche in Google Scholar
Lai, T. L., H. Xing, and Z. Chen. 2011. “Mean-Variance Portfolio Optimization when Means and Covariances Are Unknown.” Annals of Applied Statistics 5: 798–823. https://doi.org/10.1214/10-aoas422.Suche in Google Scholar
Levitt, S. D. 2004. “Why Are Gambling Markets Organised So Differently from Financial Markets?” The Economic Journal 114: 223–46. https://doi.org/10.1111/j.1468-0297.2004.00207.x.Suche in Google Scholar
Markowitz, H. M. 1952. “Portfolio Selection.” The Journal of Finance 7: 77–91. https://doi.org/10.1111/j.1540-6261.1952.tb01525.x.Suche in Google Scholar
Markowitz, H. M. 1959. Portfolio Selection: Efficient Diversification of Investments. New York: Wiley.Suche in Google Scholar
Markowitz, H. M. 1987. Mean-Variance Analysis in Portfolio Choice and Capital Markets. Cambridge: Basil Blackwell.Suche in Google Scholar
Markowitz, H. M., D. Starer, H. Fram, and S. Gerber. 2020. “Avoiding the Downside: A Practical Review of the Critical Line Algorithm for Mean-Semivariance Portfolio Optimization.” In Handbook of Applied Investment Research, edited by J. B. Guerard, and W. T. Ziemba, 369–415. Singapore: World Scientific Publishing Company. (Chapter 16).10.1142/9789811222634_0017Suche in Google Scholar
Markowitz, H. M., P. Todd, G. Xu, and Y. Yamane. 1992. “Fast Computation of Mean-Variance Efficient Sets Using Historical Covariances.” Journal of Financial Engineering 1: 117–32.Suche in Google Scholar
Markowitz, H. M., P. Todd, G. Xu, and Y. Yamane. 1993. “Computation of Mean-Semivariance Efficient Sets by the Critical Line Algorithm.” Annals of Operations Research 45: 307–17. https://doi.org/10.1007/bf02282055.Suche in Google Scholar
Niedermayer, A., and D. Niedermayer. 2010. “Applying Markowitz’s Critical Line Algorithm.” In Handbook of Portfolio Construction: Contemporary Application of Markowitz Techniques, edited by J. B. Guerard, 383–400. New York: Springer. (Chapter 12).10.1007/978-0-387-77439-8_12Suche in Google Scholar
© 2023 the author(s), published by De Gruyter, Berlin/Boston
This work is licensed under the Creative Commons Attribution 4.0 International License.
Artikel in diesem Heft
- Frontmatter
- Research Articles
- Predicting elite NBA lineups using individual player order statistics
- Modern and post-modern portfolio theory as applied to moneyline betting
- Pitching strategy evaluation via stratified analysis using propensity score
- Clustering of football players based on performance data and aggregated clustering validity indexes
- Testing styles of play using triad census distribution: an application to men’s football
Artikel in diesem Heft
- Frontmatter
- Research Articles
- Predicting elite NBA lineups using individual player order statistics
- Modern and post-modern portfolio theory as applied to moneyline betting
- Pitching strategy evaluation via stratified analysis using propensity score
- Clustering of football players based on performance data and aggregated clustering validity indexes
- Testing styles of play using triad census distribution: an application to men’s football