Grid Resource Allocation with Genetic Algorithm Using Population Based on Multisets
-
Absalom E. Ezugwu
 ,
Nneoma A. Okoroafor
,
Nneoma A. Okoroafor

Abstract
The operational efficacy of the grid computing system depends mainly on the proper management of grid resources to carry out the various jobs that users send to the grid. The paper explores an alternative way of efficiently searching, matching, and allocating distributed grid resources to jobs in such a way that the resource demand of each grid user job is met. A proposal of resource selection method that is based on the concept of genetic algorithm (GA) using populations based on multisets is made. Furthermore, the paper presents a hybrid GA-based scheduling framework that efficiently searches for the best available resources for user jobs in a typical grid computing environment. For the proposed resource allocation method, additional mechanisms (populations based on multiset and adaptive matching) are introduced into the GA components to enhance their search capability in a large problem space. Empirical study is presented in order to demonstrate the importance of operator improvement on traditional GA. The preliminary performance results show that the proposed introduction of an additional operator fine-tuning is efficient in both speed and accuracy and can keep up with high job arrival rates.
1 Introduction
The problem of selecting and allocating grid computing resources that are distributed across geographical locations to user applications is very complex, especially when the network capacities linking each of the execution sites vary. Most often, the information regarding user application resource requirement demands is often not fully provided. In other words, job resource requirement information is not fine grained such that the scheduler is unable to make decision as per which resources are best suited for executing a specific grid application.
Generally, equipping the scheduler with sufficient information, either on the side of the resource provider with regard to the available resource configuration information or on the side of the grid user with regard to the resource requirement demands of the application, can drastically improve the performance of the scheduling tasks positively, while the lack of it will affect the process negatively. Resource allocation in grid environments is significantly complicated by the heterogeneous and dynamic nature of grids. In general, the resource information is an important part of the input data to the performance model. More so, it is usually very difficult to obtain performance model of each resource across multiple sites due to these uncertainties.
In Ref. [24], grid computing is said to have a layered architecture that is divided into two-level hierarchy of scheduling. In the first level, the global scheduler assigns submitted user applications to remote resources, after which the local schedulers would generate schedules for the local resources that they manage. The global scheduler has limited knowledge of the potential capacity of the available local resources and likewise has no control over them. On the other hand, the local scheduler seems to be unaware of other resources available to the user applications and has also no knowledge of other submitted applications that subsequently require the services of these available resources.
The essence of the above paragraph is to emphasize the difference that exists between resource allocation and scheduling. Resource allocation here simply means the assignment of jobs (tasks) to the corresponding resources. Resource allocation may involve data staging and binary code transferring before the job starts execution. On the other hand, scheduling is the allocation of jobs to a resource over a period of time [24]. It is also interesting to note that grid scheduling procedure roughly comprises four phases: information collection, resource selection, job mapping, and resource allocation [8, 35]. These concepts will be explained in detail in the subsequent section.
In this paper, a proposal is made to apply the concept of a multiset genetic algorithm (MGA) [16] to address the problem of resource allocation in the grid computing environments. The essence of this hybridization is to enhance genetic algorithm (GA) performance to solve combinatorial optimization problem, specifically grid resource allocation. Another advantage of the proposed hybridization is the use of population-based multiset to control the growing population pool of individuals that are maintained by GA. Relevant discussions on GA and their applications are presented in Refs. [12, 13, 14, 30, 34].
In this work, a computational grid is considered to be made up of clusters of computing nodes. A cluster is said to consist of multiplicities of execution points or machines that are either homogeneous or heterogeneous in terms of system and performance configurations. Based on this assumption of the grid properties, the proposed resource allocation model is addressed in this paper.
The remainder of the paper is organized as follows. In Section 2, we present the related work. In Section 3, we present the research problem formulation. Section 4 describes the proposed system. Sections 5 and 6 present the proposed approach to solve the resource allocation problem: MGA, resource matching model, and indexed-based search procedure. Section 7 reports on the experimental configuration and computational results. Section 8 presents concluding remark and future direction.
2 Related Work
Resource matching and allocation using hybrid GAs are well-studied areas of research [6, 8, 17, 19, 22, 25, 32] and still are the subject of many studies. In Ref. [3], scheduling heuristics for dynamic job scheduling on large-scale distributed systems was addressed. The heuristics comprised of hybridization of GA, simulated annealing (SA), and Tabu Search (TS). In these hybridizations, a population-based heuristic, such as GA, is combined with two other local search heuristics, such as TS and SA, which deal with only one solution at a time. In Ref. [23], a hybrid GA and variable neighborhood searches (VNS) named GA-VNS are presented for static scheduling of independent tasks within grid environments. The main objective of the proposed algorithm is to reduce the overall cost of task executions without any significant increment in system makespan.
GAs for scheduling are addressed in several works [1, 2, 9, 10, 15, 18, 33, 38]. Some hybrid heuristic approaches have also been reported for the problem. Thus, Abraham et al. [3] addressed the hybridization of GA, SA, and TS heuristics for dynamic job scheduling on large-scale distributed systems. In these hybridizations, a population-based heuristic such as GAs is combined with two other local search heuristics, such as TS and SA, which deal with only one solution at a time.
The motivation behind this paper came from the concept of using population based on multisets to address the problem of traditional representation of population that is often used in evolutionary algorithms [26]. The two main problems identified are the loss of genetic diversity during evolutionary process and the evaluation of redundant individuals [26, 36]. In this paper, the authors proposed a computational representation of populations based on multisets and the adaptation of a GA, referred to as MGA, to deal with this type of representations. Similar work that minimizes the problem of traditional representation of populations used in evolutionary algorithms can be seen in Refs. [4, 5]. Each of this related work presented new formal models for multiset representation of individuals and their populations, which addresses the aforementioned problem. Also, a valuable reference for multisets and their multi-faceted applications can be seen in Refs. [7, 21, 35, 37].
3 Problem Formulation
In this paper, the problem of allocating jobs to highly ranked grid resources is considered. This is achieved by taking into consideration user job resource requirements, job priorities, job-specific preferences, resource capabilities, resource utilization, and resource throughput. Two types of jobs are considered in this paper, CPU-bound (or compute-intensive) jobs and memory-bound (or data-intensive) jobs. Usually, jobs are submitted alongside with their requirements. A job is considered as a single unit of work within a grid application, which is typically allocated to be executed on available resource. In essence, a job consists of an executable statement, a request, and some input data. A job requirement specifies the resource requirements and preferences to execute the job.
The grid resource types considered in this paper are basically computational systems, storage servers, and network servers. Each of these set of resource types is associated with one or more attributes with specific values. Examples of associated attributes for a typical computational resource include processing speed “ps”, available memory size “ms”, associated I/O bandwidths “bw”, and so on. For the storage and network resources, varying or fixed memory capacities and network bandwidth strengths are the essential attributes considered as most relevant.
For every job submitted for execution in the grid, there is an associated job requirement that depends on some corresponding dependencies and constraints associated with each dependency on a resource instance of a particular resource type. One main dependency considered in this paper is the number of resource type that a job may require, with varying constraints on the selected resource capacities. For example, a job resource requirement with dependencies on two computational nodes may specify minimum CPU speed of 1.33 MHz, 300 MB available memory, and 200 MBps of link bandwidth for the first node and CPU speed of 3.33 MHz, 500 MB available memory, and 400 MBps of link bandwidth for the second node as constraints.
The above problem formulation can be summarized using the following parameterized steps:
Let J={j1, j2, …, ji }, i=1, 2, …, m be the set of jobs to be matched to suitable candidate resources.
Let R={r1, r2, …, rj }, j=1, 2, …, n be the set of available candidate resources.
Every job Ji ∈J is assigned a priority, which depends on the capacity of the required resources attributes t={ps, ms, bw}.
H(rj, tk) defines the capacities of the resource attributes of type tk for resource rj ∈R. Therefore,
Γ(ji, tk) defines the equivalent resource capacity required by the user job i for each Ji ∈J.
The variable Si,j =0, 1 for each job Ji ∈, defines the probability (in terms of success or failure) of matching a job to a specific resource, where Si,j =1 if Ji is matched to the required resource rj ∈R, and Si, j =0, if otherwise.
These lists of parameters are applied to the adaptive resource matching model described in Section 6. Similarly, the model is introduced as an additional adaptive matching operator to the proposed GA resource allocation system described in this paper.
Nevertheless, the paper proposes an alternative resource allocation mechanism that efficiently addresses the general resource selection problem in a typical grid computing environment. An adaptation to a GA-based multiset population is introduced. The proposed job resource allocation mechanism uses the multiset-based population indexing to group and coordinate the allocation of available related resources that satisfy the resource requirements of a specific user job. In this paper, a grid node is expressed as a collection of resources in which those resources have multiple occurrences. Therefore, the cardinality property and other related operation on multiset are exploited to maximize utilization of grid resource. In the next section, a description of the proposed system is presented and discussed.
4 System Description
The proposed efficient resource selection model is presented and described in this section. The model comprises of three major phases of scheduling tasks. The first phase is the job analysis and requirement gathering phase, the second phase is the resource selection and allocation phase, while the third phase is the job execution phase. Figure 1 gives the detailed description of the schematic flow of the resource allocation model. Next are the explanations of each of the three main phases aforementioned.

Optimization Algorithm Operators.
4.1 Job Analysis Phase
In this paper, two classes of jobs are considered, CPU-bound jobs and memory-bound jobs. The system’s first task is to analyze and generate requirement report for the user-submitted job (job preparation) based on these two categories of jobs. The process starts when a user sends job request to the job analyzer system. The job analyzer analyzes the job and generates requirement report according to the job’s resource needs. In order to harmonize the implementation with the bio-inspired GA (genotype coding), which technique is explained later, the requirement values are set to either 1 or 0. For example, if the value of processing speed or memory size generated from the requirement report is 1, then the job needs high-speed or high-memory resources. The job analysis report generated in this phase is as shown in Table 1.
Job Requirement Description.
| Job ID | PS | MS | BW |
|---|---|---|---|
| J1 | 1 | 1 | 1 |
| J2 | 1 | 1 | 0 |
| J3 | 0 | 1 | 1 |
| J4 | 1 | 1 | 0 |
| J5 | 1 | 0 | 1 |
Job resource requirement report is generated by using the descriptions for each value codes that are generated for jobs and resources. Suppose we consider a set of cluster machines characteristics such as processing speed, memory size, and network bandwidth. Let us choose two levels of ordering pattern, say high (H) and low (L), to make the characterization decisions. Here, we have selected three machine configuration specifications and two ordering decision levels, high and low, to characterize the classification of resources for a particular cluster. If the value of configuration capability of a resource (processor, memory, and bandwidth) is greater than a certain capacity Threshold, then it is considered as High (H); otherwise, Low (L). The binary value 1 is assigned to H, and 0 is assigned to L.
A resource ranking strategy is presented, which is done through the assessment of grid resource computing capability. More so, we present a study on resource ranking methods by extracting some sets of specific information about the resource specifications and computing qualities. The ranking and selection model is discussed and considered from the perspective of resource performance function.
4.2 Resource Fitness Evaluation Phase
The resource fitness evaluation phase is responsible for generating the resource capability table with respect to the three resource configuration parameters, that is, the resource processing speed, memory size, and network bandwidth. The value of each column will be either 1 or 0. If the resource is good in memory and processing speed but has low bandwidth, then the values will be given as 1 for memory and processing speed and 0 for bandwidth. The resource capability report (Table 2) is very essential for the general operation of the MGA.
Resource Capability Description.
| Resource ID | PS | MS | BW |
|---|---|---|---|
| R1 | 1 | 1 | 1 |
| R2 | 1 | 1 | 0 |
| R3 | 0 | 1 | 1 |
| R4 | 1 | 1 | 0 |
| R5 | 1 | 0 | 1 |
4.3 Resource Selection Phase
This phase consists of three main components, which include resource fitness component, resource indexing component, and resource matcher component. The resource fitness component is responsible for generating lists of highly ranked resources sorted according to their computing fitness. The resource fitness component receives its report from the output generated by the computation from the GA operators tuning. The resource indexing component generates the list of indices for all the sorted resources according to Table 2 and, as such, prepares the resources for easier access, searching, insertion, deletion, and selection processes. The resource matcher component receives the resource capability report, job requirement report, and indexing profile and uses such information to map the respective resources with the job and provide the optimal list of resources. In Section 6, a detailed discussion of a typical resource matching model is presented, while in Section 7, a discussion on the indexing pattern is presented.
4.4 Job Execution Phase
The job execution phase provides an avenue where after selecting the respective resource, jobs are scheduled in the selected resource by the local scheduler. During job execution, if any of the jobs fail to proceed, then the job will be reallocated to the next available resource that has the capacity to execute it from the resource fitness list table. However, during the process of job interruption, the local scheduler takes care of the selection of next capable resource, submits the job from its last saved state, and continues to monitor the job until it reaches its completion stage. Thereafter, the local scheduler returns the feedback to the user through the global scheduler. As the fitness evaluation phase is linked with the GA mechanism, it is better left out for later discussion under the GA operator functionalities presented subsequently.
5 GA Parameters
Algorithm: The GA starts with a population that is made up of individuals, representing basic solution to the problem usually in the form of a bit vector {P0, P1, …, Pmax}, where each population comprises of m entries {R1, R2, …, Rm } and each entry Ri ={rk , s, t, 1≤k≤n and rk ={0, 1}}. Let {r1, r2, …, rn } represents the set of unique resources that are available. The selection probability={0, 1}, where the selected resources are represented by the value 1 and the unselected resources are represented by the value 0. The chromosome fitness values in a given population are evaluated based on the computational capability (or processing power) associated with the specific resource (see equation 4). Subsequently, the fitness function fitness(R*) defined later in this section is used to compute and store the best-fit chromosome generated from a given population.
In dealing with the GA, the outlined solutions are only possible where the minimum attribute specification requirement of each resource has been chosen to be allocated. The solutions are generated using the best-fit heuristics from the bin-packing problem. The heuristic is strictly deterministic; it starts by considering the first resource to see whether it can be allocated to the user job, and if not, it moves on to the second resource and so on. In order to generate more different solutions, the crossover rate, mutation rate, and the resource selection scheme are changed by doing a random permutation. To avoid population flooding, a rescaling operator is introduced as part of the genetic operator to control the number of copies of the individuals. After this initialization step, an iterative process (each cycle of it is called a generation) that involves the following pseudocode is performed (Figure 2).

Pseudo-code of the Genetic Algorithm Scheduling Steps.
The essence of introducing the repair operator is to ensure that all bits of the chromosomes do not exceed 1, when the fitness exceeds the desired capacity. The repair operator achieves this by making all the bit of the chromosome equal to 0 at the point when the fitness operator exceeds the desired capacity. These steps are all tunable by some parameters, resulting in different instances of the same GA. We discuss each of these steps in the following paragraphs.
5.1 Chromosomes Formulation
Three variables were considered for the chromosome formulation (ps, ms, and bw). The first part of a chromosome contains the binary representation of the first variable (ps: x1), the second part contains the second variable (ms: x2), while the third part represents the third variable (bw: x3). Let ai and bi be the lower and upper bound of the ith variable, respectively. The range of the ith variable (ri) becomes (bi – ai). If d is the number of decimal places on each variable, then the number of genes required for the binary representation of the ith variable (gi) is
The chromosome consists of a total of (g1+g2+g3) genes, as there are only three variables (x1, x2, and x3). The first generation of chromosome is randomly created by filling all the gene slots with 0 or 1. For each gene slot, a random number (between 0 and 1) is generated. If this number is <0.5, the value 0 is assigned into the gene slot; otherwise, the value 1 is assigned.
5.2 Population Selection Mechanisms
Tournament and rank-based selection mechanisms have been used to select individuals for the genetic operations [27, 29]. A tournament size of k=5 was employed, which is selected arbitrarily; this is a rank-based selection in which chromosomes in the population are sorted according to their fitness values, and then the first k chromosomes are selected for the best chromosome crossover method. The probability that a resource ri is selected from the tuple (r1, r2, …, rm) of a node to be a member of the next generation of highly ranked node at each experiment is given by
Additional selection string operators (adaptive matching and indexing) are introduced in Section 6 to check the problems of premature convergence, which is common with GA.
5.3 Crossover
The crossover operator is one of the most important genetic functions in evolutionary algorithms. This is a process where chromosomes exchange segments via recombination. An investigation of the standard one point crossover method and a “eugenic” best chromosome crossover method was carried out, in which a certain percentage of offspring was forced to be generated from the chromosomes with the highest fitness values. The new individual that emerges will be defined as their crossover. Instead of adopting a random crossover, a uniform crossover is rather chosen, where the probability that the ith variable of the new individual is equal to the ith variable of the first or second parent is proportional to the fitness of the first or second parent. See Ref. [11] for further details.
5.4 Mutation
Mutation is a genetic operator used to maintain genetic diversity from one generation of population of chromosomes to the next. Mutation is an important part of the genetic search, which helps to prevent the population from stagnating at any local optima. Two mutation operators (swap and random) are used to introduce some extra variability into the population. A swap mutation swaps two selected genes from randomly selected genes in the chromosome; this is the primary method used to introduce variability. Random mutation changes a randomly selected gene value to another possible value; this method generally has an adverse effect on fitness due to poor “distribution”, but it can introduce “lost” gene values back into the chromosome, thus helping to prevent premature convergence. Using a combination of these two methods shows better results than using them individually. See Refs. [11, 29] for further details.
5.5 Rescaling
In addition to the aforementioned GA parameters, a rescaling genetic operator is introduced to control the number of copies of the individuals; based on this, the schema defined in Refs. [4, 11] is adapted. Also in the work of Manso and Correia [26], it was stated that the introduction of repeated elements in the multipopulation (MP) causes an increase in the number of copies of the corresponding multi-individual (MI) and the rescaling operator avoids the best individuals getting too many copies. Therefore, a control measure is introduced to control the number of repeated elements. The rescaling function r implements a linear fitness scaling algorithm, as described by Golderg [20]. The rescaling operator, therefore, ensures that each MI has at least one copy and that the total number of individuals in MP is not greater than a constant, defined as the double of the number of MI. Experimental results show that this value is a good compromise between selection pressure and genetic diversity.
5.6 Fitness Function
The user is allowed to specify the relative importance of fitness constraints such as CPU speed, memory size, associated network bandwidth, and so on for a specific resource object. The fitness function of a schedule is computed by determining the individual resource capacity and isolating the resource with the highest capacity for allocation. In this work, the proposed hybrid GA uses the current state of the resource configuration to compute the node fitness and chooses the resource with the highest performance capability on the basis of its quantitative evaluation. The fitness function estimates the current processing capability for each potential node. With this metric, the algorithm selects and distributes jobs to the most qualified and freely available grid nodes.
In this study, three resource attributes are considered and used for estimating the fitness of nodes. These sets of attributes include processing speed, memory size, and network bandwidth. Each computed node r is sorted in ascending order according to their respective computation capability; first, the aggregate fitness of all machines ri ∈R per node is estimated. Therefore, we express the fitness of each resource fitness of a node R as follows:
where
where
R is the set of all candidate machines ri ;
psi is the processor or CPU clock speed of machine ri ;
msi is the memory size of machine ri and it is a constant attribute;
bwi is the communication speed (Mbps) of machine ri ; and
β1,β2, and β3 are the weights of the first to third terms, respectively; the three weight parameters must sum up to 1, e.g. β1=0.5, β2=0.4, and β3=0.1.
Finally, the selection is sorted in descending order based on aggregated resource fitness, and the resource with the largest fitness function as shown in equation (5) will be recognized as the best.
6 Adaptive Selection Operator
In general, there is a need to overcome the problem of premature convergence associated with GAs, that is, the situation where a population under consideration reaches a suboptimal state, in which case the offspring is often observed to be inferior to the parent individual. In this paper, some string matching and scheduling operators of computing resources have been introduced to overcome this problem. These operators include the mutation operator explained earlier in Section 5 and two other main additional operators, the adaptive selection operator and the indexing operator. The last two operators are afterward explained in details.
6.1 Adaptive Matching Operator
To establish a generalized matching string operator for the proposed resource allocation framework, we adapted part of the basic matching concept defined in Ref. [28] and introduced some new parameters suitable enough for the evolutionary process. In this paper, a job ji ∈J is specifically described by its priority based on the amount of resource capacity it will require to be executed on a resource rj ∈R. Similarly, a resource rj ∈R is described based on its instantaneous available capacity. A resource in this case can have multiple capacities based on the resource attributes as earlier on described in Section 4. For instance, the capacity of a resource rj is described by H(rj, ttk), where tk indicates the type of attribute capacity (tk ={psk , msk , bwk }). And in the same way, we describe the resource requirement of a job ji by Γ(ji, ttk). A mapping string scheme with a set of variables M(ji, trj) and Zj =0, 1 is described. The variable M(ji, trj) indicates whether a job ji ∈J is matched to the required resource rj ∈R, and the variable Zj , indicates whether a job ji ∈J is matched to the required resources.
The following resource capacity constraint can be expressed to ensure that the sum of the fraction of the resource capacity required by the user jobs does not exceed the total available capacity and to also ensure that the user job is mapped to the appropriate resource for its execution.
for each rj ∈R and its capacity tk .
The number of resource used to match user jobs can be determined. This is essential where cost is involved. The user may want to limit job execution to a small set of efficient resource to reduce extra cost. Therefore, in order to compute the number of resources used in running user application, variable Sr is defined with values 0 and 1, which is expressed as Sr =0, if resource ri ∈R is not matched to any one of jobs ji ∈J, and Sr =1, if otherwise, for each ri ∈R by the following two sets of linear inequalities:
and
for each resource ri ∈R, where mJ (ji) is the number of jobs considered. For a resource r, the sum of M(ji, trj) over jobs is equal to the number of jobs matched to these resources; if no job is matched with these resources, its value is equal to 0. In this case, based on the first inequality, Sr is equal to 0 because Sr must be less than or equal to 0 to make the inequality stand. On the other hand, if some jobs get matched to this resource, the sum of M(ji, trj) over all jobs is greater than or equal to 1. Based on the second inequality, Sr is equal to 1 because Sr must be >0 to satisfy the inequality. Then the number of used resources can be formalized as a linear expression, Σr∈RSr .
Also, we can define a model for job preferences on resources. There are instances where a job may provide a criterion to rank all satisfying resources. For example, a job may prefer a machine with higher CPU speed and use CPU speed as a ranking criterion; therefore, a ranking scheme can be developed, which is expressed as a variable Q(ji, trj), the given rank of resource r by job j. This string ranking scheme can be formalized as a linear expression given as follows:
The matching process utilizes this ranking scheme to find a matching scheme containing as many preferred resources as possible.
6.2 Indexed-Based Resource Searching Operator
The resource indexing method involves storing records in sequential order and incorporating a file indexing mechanism along with the sorted resource list. A file index is a list of key/block pairs arranged with the keys in a specific order.
Resources are sorted based on the following linear inequalities (see equation 10). Two resource nodes R1 and R2 are said to be unequal if R1≠R2; similarly, the following conditions follow if, for any resource component r,
where the multiplicity of r in R is denoted by mR (r) and t represents the attribute capacities of r∈R, expressed as t={ps, ms, bw}.
The resource list entries and the index are arranged sequentially according to the resource rank values. The original records on the resource list can be arranged in any convenient order based on the initial sorting criteria. This usually means that new records are simply appended to the end of the file, so the records are ordered by the time of insertion. The index mechanism, however, provides direct access to the sorted resource list instead of relying on the traditional sequential access method often used by schedulers to locate candidate resources.
One main advantage of the indexing mechanism is that multiple indices, each with a different key, can be created for the same record file. In one index, the key can be the resource processing speed value; in another, it can be the resource memory size value or even the required communication network bandwidth value. Because the indices are small compared with the resource file itself, therefore, they do not increase the total data storage of the overall system memory.
The resource indexing approach is based on the following steps:
Start with the resource with rank R1 in the indexed list to the resource whose rank value is less than the targeted rank by 1. Next, get the summation of all the resource(s) pair numbers.
The “block number” gives the summation of all the rank pair positions, which represent the index of the first resource having the required rank value equal to or greater than the job resource requirement rank value.
An indexing example: From the illustration depicted in Figure 3, in finding a candidate resource that matches the job resource request of rank 4 (R4), the process is done in such a way that the summation=4+2=6 fetches the index of the targeted resource rank. As shown in the illustration below, index 6 is the index of the first resource with rank 4 because there is no resource for rank 3. Similarly, to find a suitable resource for a job with request for a resource of rank 6(R6), the summation=4+2+3+6=15 gives index 15, which points to the index of the first resource with rank 6.

Resource Searching With Indexer.
To insert a new ranked resource item in an indexed file, two steps are necessary:
First step is to insert its full record into the main file.
Second step is to insert an entry, consisting of the key and the block number where the new record is stored, into the index.
7 Experimental Configuration
Simulation and evaluation of environment are constructed to evaluate the MGA resource allocation technique. The simulation process was performed on the MATLAB platform with several resource state repositories. One type of resource was considered for this experiment, which is the compute server (with the following attributes: processing speed, memory size, and associated bandwidth). Six of the compute server resource instances were defined. The resource instances belonging to the same resource type differ in their total and available capacities that can be consumed by a user-submitted job. The user job somewhat consists of request log that includes certain specified resource requirement attributes such as resource processing speed, memory size, and associated i/o bandwidth.
The arrival of jobs at a time interval is modeled as Poisson random process given by
where λ is the average number of jobs that have arrived in a given time interval, the random variable t represents the number of jobs arriving in a given time interval (0, 1, 2, …), and e=2.71828.
The number of jobs submitted was varied at a time in a batch. The time between the submission of a batch of jobs and the return of matched results was measured. The simulation was performed for ten batches of jobs evaluated for 20 iterations. The fitness function returns the best available resource that matches the user job. An individual resource in the population pool of resources is randomly selected, and any two jobs in that chromosome are randomly selected and swapped. This approach ensures that all the solutions in the search space are more thoroughly examined. The evaluation is determined by taking the average over the 20 iterations. Figure 4 shows the comparative evaluation result obtained on resource selection using classical GA (CGA), mGA, GA-simulated annealing (GA-SA) and GA-Tabu Search (GA-TS) scheduling heuristics.
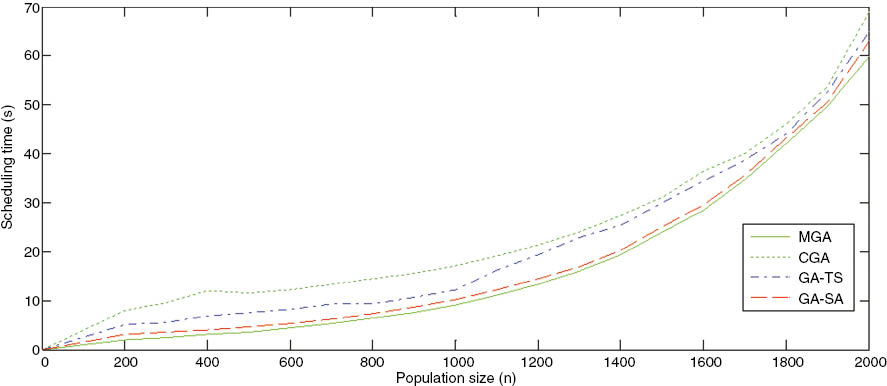
Comparison of Resource Scheduling Time for CGA, MGA, GA-TS, and GA-SA.
In a related simulation experiment conducted, the new scheduling heuristic is compared with the performance of a CGA and two other hybrid heuristic algorithms, GA-SA and GA-TS, as presented in Ref. [31]. The simulation has been executed for three randomly generated grid jobs, which appear in batches of 20, 60, and 100, respectively. The gird resource environment consists of 30 resources (processors) from cluster of computational nodes. The three search heuristics were subjected to the same number of resources, iteration, and execution time epoch for each of the problem sets, and the average execution time taken to converge is computed
The simulation results for the four search heuristics execution for each of the three problem sets were computed and compared, as shown in Figure 5. Analysis of the four results shows that the CGA took more time to reach its best solution with fitness of 125 s, next is the GA-TS with an average execution time convergence of 121 s, followed by GA-SA with fitness of 116 s, while the MGA had its best solution at 110 s for the first problem. For the second problem with 60 job pool, the CGA is still outperformed by the remaining three hybrids GAs, with MGA having the least average execution time of 158 s. For the third problem with job pool of 100, CGA shows its convergence in best solution fitness of 219 s, whereas MGA achieved 173 s in the same interval and continues its reduction. Achieving better solutions by MGA is obvious when compared with the remaining two search heuristics. The additional cost of computation by MGA in the process of searching and selecting the best resources presents a drawback in terms of search speed of the proposed system. However, the general goal is to achieve high precision in the selection of most suitable resource for the user-submitted jobs.
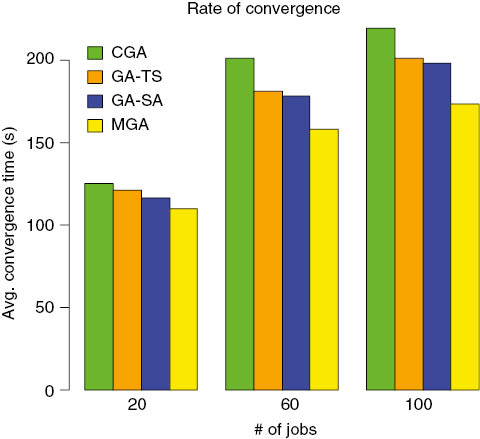
Average Convergence Time for Four Search Algorithm.
Additional empirical study was carried out for the purpose of evaluating the proposed resource selection scheme. This was intended to estimate the performance of varied number selected grid resources in the range of 50, 250, …, 3000 by the proposed model over 400 jobs. Three scheduling metrics were considered, and they include makespan (scheduling length), throughput, and turnaround time. Each of these metrics is computed as follows:
where the finish time of the job ji on resource rj can be defined as
where
In evaluating the performance of the system, two considerations are made. The first is by considering scheduling of selected resource using the proposed MGA with adaptive selection scheme (GA_AS), and the second, by considering the same process using GA with non-adaptive selection scheme (GA_NAS). The result is presented in Figure 6. Simulation result shows that both makespan and turnaround time were significantly reduced with the GA_AS as against the GA_NAS approach (Figure 6A,B). The makespan obtained by using the GA_AS has approximately 3.81% reduction in scheduling length, as compared to the GA_NAS, which has approximately 2.77% reduction. In the case of the turnaround time, the minimum simulation time recorded using GA_AS has approximately 2.86% reduction and 1.61% for GA_NAS. Also, the system throughput was maximized using the GA_AS as against the GA_NAS scheme (Figure 6C). For the GA_AS scheme, 10.45% was recorded as the optimal throughput, while 9.40% was recorded as the maximum throughput for the GA_NAS scheme.
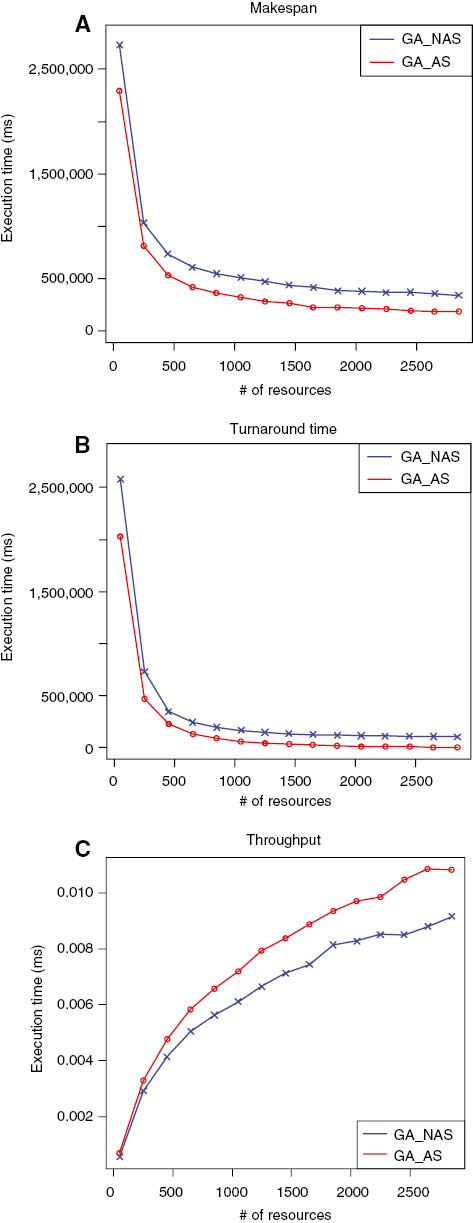
Performance Comparison of Resource Allocation by GA-AS and GA-NAS. (A) Makespan. (B) Turnaround time. (C) Throughput.
In summary, the MGA procedure is a heuristic search algorithm that attempts to optimize the resource allocation schedule. The proposed heuristic has been demonstrated via experiment to have some interesting characteristics, which include the following:
The heuristic attempts to improve upon the existing traditional GAs by integrating two optimization techniques, population-based multisets and adaptive resource matching techniques.
It considers user job resource requirement as a major priority for its GA search processor.
It applies efficient search procedure that arrives at solutions by searching only a small fraction of the total search space.
Procedures and objective functions depend upon the activities of a scheduling system and work with the system input data sets that are based on instantaneous access and, therefore, have costs implied by the calculated instants.
Performance efficiency depends upon the computational cost function (e.g. see operator-fitness function).
8 Conclusion and Future Work
A formal model for the selection and allocation of highly ranked grid resources in a distributed computing environment is proposed. Similarly, a search technique to find an approximate solution is also developed. In the simulation experiment carried out, the MGA search heuristics performed best compared to the classical GA, GA-SA, and GA-TS solution methods on the problems of optimal resource allocation with complex resource mix. The additional operators introduced into the system did not alter the GA performance. In fact, it made the problem easier for the GA to expand its search horizon within a limited time frame. This suggests that the MGA is well-suited for more complicated optimization problems, as the case may be with heterogeneous grid resource allocation. Future work will consider finding structure characterization of real distributed system to evaluate and fine-tune the additional genetic operators introduced in this paper and then compare it against the proposed heuristic. Furthermore, work that includes the consideration of more dynamic factors that will further improve the efficiency of the selection process is worth studying.
Bibliography
[1] W. Abdulal and S. Ramachandram, Reliability-aware genetic scheduling algorithm in grid environment, in: IEEE International Conference on Communication Systems and Network Technologies, June 2011, pp. 673–677, IEEE, ISBN 978-0-7695-4437-3/11, Katra, Jammu, India.Suche in Google Scholar
[2] W. Abdulal, O. A. Jadaan, A. Jabas and S. Ramachandram, Mutation based simulated annealing algorithm for minimizing makespan in grid computing systems, in: IEEE International Conference on Network and Computer Science (ICNCS 2011). April 2011, Vol. 6. pp. 90–94, IEEE, ISBN 978-1-4244-8679-3, Kanyakumari, India.10.1109/ICECTECH.2011.5942057Suche in Google Scholar
[3] A. Abraham, R. Buyya and B. Nath, Nature’s heuristics for scheduling jobs on computational grids, in: The 8th IEEE International Conference on Advanced Computing and Communications (ADCOM 2000) (pp. 45–52).Suche in Google Scholar
[4] J. N. Aparício, L. Correia and F. Moura-Pires, Expressing population based optimization heuristics using PLATO, pp. 367–383, EPIA 1999 (1999).Suche in Google Scholar
[5] J. N. Aparício, L. Correia and F. Moura-Pires, Populations are multisets-PLATO, pp. 1845–1850. GECCO 1999 (1999).Suche in Google Scholar
[6] S. Binitha and S. S. Sathya, A survey of bio inspired optimization algorithms, Int. J. Soft Comput. Eng.2 (2012), 137–151.Suche in Google Scholar
[7] W. Blizard, Multiset theory, Notre Dame J. Formal Logic30 (1989), 36–66.10.1305/ndjfl/1093634995Suche in Google Scholar
[8] P. Campegiani, A genetic algorithm to solve the virtual machines resources allocation problem in multi-tier distributed systems, in: Second International Workshop on Virtualization Performance: Analysis, Characterization, and Tools (VPACT 2009), Boston, Massachusetts, 2009.10.1109/ICAS.2009.49Suche in Google Scholar
[9] J. Carretero and F. Xhafa, Using genetic algorithms for scheduling jobs in large scale grid applications, J. Technol. Econ. Dev.12 (2006), 11–17.10.3846/13928619.2006.9637716Suche in Google Scholar
[10] J. Carretero, F. Xhafa and A. Abraham, Genetic algorithm based schedulers for grid computing systems, Int. J. Innovative Comput., Inf. Control3 (2007), 1–19.Suche in Google Scholar
[11] H. M. Cartwright, Getting the timing right – the use of genetic algorithms in scheduling, in: Proc. of Adaptive Computing and Information Processing Conference, pp. 393–411 (UNISYS 1994), Brunel, London.Suche in Google Scholar
[12] L. Davis, Job shop scheduling with genetic algorithms, in: Proceedings of an International Conference on Genetic Algorithms and their Applications, (Vol. 140). Carnegie-Mellon University Pittsburgh, PA, 1985.Suche in Google Scholar
[13] E. W. Davis and G. E. Heidorn, An algorithm for optimal project scheduling under multiple resource constraints, Manag. Sci.17 (1971), 803–817.10.1287/mnsc.17.12.B803Suche in Google Scholar
[14] E. W. Davis and J. H. Patterson, A comparison of heuristic and optimum solutions in resource-constrained project scheduling. Manag. Sci.21 (1975), 944–955.10.1287/mnsc.21.8.944Suche in Google Scholar
[15] V. Di Martino and M. Mililotti, Sub optimal scheduling in a grid using genetic algorithms, Parallel Comput.30 (2004), 553–565.10.1109/IPDPS.2003.1213282Suche in Google Scholar
[16] E. A. Ezugwu, D. I. Yakmut, A. P. Ochang, M. S. Buhari, E. M. Frincu and B. S. Junaidu. Multiset genetic algorithm approach to grid resource allocation, in: Innovations in Bio-Inspired Computing and Applications, pp. 1–13, Springer International Publishing, 2016.10.1007/978-3-319-28031-8_1Suche in Google Scholar
[17] M. Gandomkar, M. Vakilian and M. Ehsan, A combination of genetic algorithm and simulated annealing for optimal DG allocation in distribution networks, CCECE/CCGEI, Saskatoon (2005), 645–648.Suche in Google Scholar
[18] Y. Gao, H. Rong and J. Z. Huang, Adaptive grid job scheduling with genetic algorithms, Future Gener. Comput. Syst.21 (2005), 151–161.10.1016/j.future.2004.09.033Suche in Google Scholar
[19] F. Glover, P. K. James and L. Manuel, Genetic algorithms and tabu search: hybrids for optimization, Comput. Oper. Res.22 (1995), 111–134.10.1016/0305-0548(93)E0023-MSuche in Google Scholar
[20] D. E. Golberg, Genetic algorithms in search, optimization, and machine learning, Addion Wesley, 1989.Suche in Google Scholar
[21] A. M. Ibrahim, A. E. S. Ezugwu and A. Abdulsalami, Computational model for cardinality bounded multiset space, Int. J. Appl. Math. Res.1 (2012), 330–341.10.14419/ijamr.v1i3.146Suche in Google Scholar
[22] W. Jakob, A. S. W. Quinte, K.-U. Stucky, Optimised scheduling of grid resources using hybrid evolutionary algorithms, in: Conf. Proc. PPAM 2005, R. Wyrzykowski, ed., LNCS 3911, pp. 406–413, Springer, Berlin, 2006.10.1007/11752578_49Suche in Google Scholar
[23] S. Kardani-Moghaddam, F. Khodadadi, R. Entezari-Maleki and A. Movaghar, A hybrid genetic algorithm and variable neighborhood search for task scheduling problem in grid environment, Procedia Eng.29 (2012), 3808–3814.10.1016/j.proeng.2012.01.575Suche in Google Scholar
[24] P. Latchoumy and P. S. A. Khader, Fault tolerant job scheduler with efficient job execution in grid computing, UACEE International Journal of Computer Science and its Applications2, 233–237.Suche in Google Scholar
[25] S. W. Mahfoud and D. E. Goldberg, Parallel recombinative simulated annealing: a genetic algorithm, Parallel Comput.21 (1995), 1–28.10.1016/0167-8191(94)00071-HSuche in Google Scholar
[26] A. Manso and L. Correia, Genetic algorithms using populations based on multisets, New Trends in Artificial Intelligence, EPIA (2009), 53–64.Suche in Google Scholar
[27] Z. Michalewicz, Genetic algorithms+ data structures=evolution programs, Springer Science & Business Media, 2013.Suche in Google Scholar
[28] V. K. Naik, C. Liu, L. Yang and J. Wagner, Online resource matching for heterogeneous grid environments, in: Cluster Computing and the Grid, CCGrid 2005. IEEE International Symposium, 2, pp. 607–614, 2005.10.1109/CCGRID.2005.1558620Suche in Google Scholar
[29] K. Nammuni, J. Levine and J. Kingston, Skill-based resource allocation using genetic algorithms and ontologies, 2002.Suche in Google Scholar
[30] N. K. Naseri and J. Amin, A hybrid genetic algorithm-gravitational attraction search algorithm (HYGAGA) to solve grid task scheduling problem, International Conference on Soft Computing and Its Applications (ICSCA’2012), 2012.Suche in Google Scholar
[31] N. K. Naseri, A. Jula and A. Safaei, Static Grid Task Scheduling problem using a hybrid Genetic Algorithm-Gravitational Attraction Search algorithm (GAGAS). Science Series Data Report, 4, 2012.Suche in Google Scholar
[32] D. Pham and D. Karaboga, Intelligent optimisation techniques: genetic algorithms, tabu search, simulated annealing and neural networks, Springer Science & Business Media, 2012.Suche in Google Scholar
[33] S. B. Priya, M. Prakash and K. K. Dhawan, Fault tolerance-genetic algorithm for grid task scheduling using check point, in: Grid and Cooperative Computing. GCC 2007. Sixth International Conference. IEEE, pp. 676–680, 2007.10.1109/GCC.2007.67Suche in Google Scholar
[34] J. M. Renders and H. Bersini, Hybridizing genetic algorithms with hill-climbing methods for global optimization: two possible ways, Evolutionary Computation, 1994. IEEE World Congress on Computational Intelligence, Proceedings of the First IEEE Conference on. IEEE, 1994.Suche in Google Scholar
[35] D. Singh, A. Ibrahim, T. Yohanna and J. Singh, An overview of the applications of multisets, Novi Sad J. Math. 37 (2007), 73–92.Suche in Google Scholar
[36] S. Wagner and M. Affenzeller, The allele meta-model – developing a common language for genetic algorithms. Artificial intelligence and knowledge engineering applications: a bioinspired approach, Lecture Notes in Computer Science3562 (2005), 202–211.10.1007/11499305_21Suche in Google Scholar
[37] T. Wieder, Generation of all possible multiselections from a multiset, Prog. Appl. Math.2 (2011), 61–66.Suche in Google Scholar
[38] L. Zhang, Y. Chen, R. Sun, S. Jing and B. Yang, A task scheduling algorithm based on PSO for grid computing, Int. J. Comput. Intell. Res.4 (2008), 37–43.10.5019/j.ijcir.2008.123Suche in Google Scholar
©2017 Walter de Gruyter GmbH, Berlin/Boston
This article is distributed under the terms of the Creative Commons Attribution Non-Commercial License, which permits unrestricted non-commercial use, distribution, and reproduction in any medium, provided the original work is properly cited.
Artikel in diesem Heft
- Frontmatter
- Remembering a Conversation – A Conversational Memory Architecture for Embodied Conversational Agents
- A State-of-the-Art Review of Knowledge Discovery in Multiple Databases
- An Ontology-based Approach for Knowledge Integration in Product Collaborative Development
- A Cognitive Theory-based Opportunistic Resource-Pooling Scheme for Ad hoc Networks
- IMIDB: An Algorithm for Indexed Mining of Incremental Databases
- Split FTDNN-DFE Equalizer for Complex Non-linear Wireless Channels with NARMA Approximation
- Parallel Multi-Class Contour Preserving Classification
- BAT and Hybrid BAT Meta-Heuristic for Quality of Service-Based Web Service Selection
- Reducing the Feature Space Using Constraint-Governed Association Rule Mining
- Grey Wolf Algorithm-Based Clustering Technique
- Grid Resource Allocation with Genetic Algorithm Using Population Based on Multisets
- Multiple-Instance Learning via an RBF Kernel-Based Extreme Learning Machine
Artikel in diesem Heft
- Frontmatter
- Remembering a Conversation – A Conversational Memory Architecture for Embodied Conversational Agents
- A State-of-the-Art Review of Knowledge Discovery in Multiple Databases
- An Ontology-based Approach for Knowledge Integration in Product Collaborative Development
- A Cognitive Theory-based Opportunistic Resource-Pooling Scheme for Ad hoc Networks
- IMIDB: An Algorithm for Indexed Mining of Incremental Databases
- Split FTDNN-DFE Equalizer for Complex Non-linear Wireless Channels with NARMA Approximation
- Parallel Multi-Class Contour Preserving Classification
- BAT and Hybrid BAT Meta-Heuristic for Quality of Service-Based Web Service Selection
- Reducing the Feature Space Using Constraint-Governed Association Rule Mining
- Grey Wolf Algorithm-Based Clustering Technique
- Grid Resource Allocation with Genetic Algorithm Using Population Based on Multisets
- Multiple-Instance Learning via an RBF Kernel-Based Extreme Learning Machine