Conditioning on Post-treatment Variables
-
Judea Pearl


Abstract
In this issue of the Causal, Casual, and Curious column, I compare several ways of extracting information from post-treatment variables and call attention to some peculiar relationships among them. In particular, I contrast do-calculus conditioning with counterfactual conditioning and discuss their interpretations and scopes of applications. These relationships have come up in conversations with readers, students and curious colleagues, so I will present them in a question–answers format.
Question-1 (Is Rule-2 valid?)
Rule-2 of do-calculus does not distinguish post-treatment from pre-treatment variables. Thus, regardless of the nature of Z, it permits us to replace
Example 1Consider the simple causal chain
Answer-1
Yes, something is wrong here, but not with Rule-2. It has to do with the interpretation of
Rule-2 says:
Indeed, if we go to the definition of
which proves Rule-2.
The same result obtains whenever Z blocks all back-door paths from X to Y, as in the canonical confounding model (Figure 1(a)), as well as in the typical selection-bias model (Figure 1(b)).
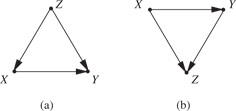
Two models in which

In Model (a),
Question-2 (Why back-door prohibition?)
So, when do we need to worry about conditioning on X-affected covariates, virtual colliders, case control studies, etc.? It seems that Rule-2 allows us to circumvent the prohibition that the back-door criterion imposes against conditioning on a treatment-dependent Z.
Answer-2
The two are not contradictory. Rule-2 is always valid, regardless if Z is pre-treatment or post-treatment. At the same time, the prohibition imposed by the back-door cannot be dismissed, it needs to be considered on two occasions. First, whenever we seek a license to use the adjustment formula and write:
Second, whenever we seek to estimate causal effects in a specific group of units characterized by
Let us deal with these two cases separately.
2.1 License to adjust
Consider the adjustment formula of eq. (1). This formula is not valid when Z is Y-dependent, as in our causal chain
If we apply it blindly, we get the sum in (eq. (1)), instead of the correct answer, which is
To see what goes wrong with blind adjustment, let us trace its derivation, for a pre-treatment Z:
This works fine when we can substitute
If we avoid the substitution
which is the correct answer for
Blind adjustment is valid, however, when Z is pure descendant
[1] of X, as in Figure 3. We know that the back-door prohibition against post-treatment covariates is lifted in this case [1, p. 339, 2] and, indeed, if we take Z as a covariate and blindly apply the adjustment formula to

A model in which Z is a pure descendant of X, thus satisfying the (extended) back-door condition and permitting adjustment for Z.
The latter equality is obtained through the conditional independence
2.2 Identifying unit-specific effects
We are now ready to discuss the second task for which back-door admissibility is needed: estimating unit-specific effects.
In many applications, the query of interest is not to find
By the counterfactual query
We call
Obviously, when Z is a pre-treatment covariate, we have
This license is similar to Rule-2, but it is applied to a different expression; whereas ignorability allows us to remove a subscript, Rule-2 allows us to remove a do-operator.
We can see the difference in graph
Rule-2 in itself does not give us this license because it is applicable to a different query
Question-3 (the key question)
Should we be concerned with the difference between
Answer-3
We certainly should, because the two questions have different semantics and deliver different answers, whenever Z does not satisfy the back-door condition. This can be demonstrated in graph
In this graph,
While
which is totally alien to
Intuition supports this inequality. If we let X be education, Z be skill and Y be salary,
Question-4 (Q d o o r Q c
Which query,
Answer-4
Question-5 (selection bias)
What about selection bias problems, where the selection mechanism is often outcome-dependent?
Answer-5
If we aim at estimating
To demonstrate, assume that variable Z in Figure 3 stands for ‘‘selection’’ to the data, and our task is to recover the causal effect
which established the recovery of the target effect from the biased data
As another example, consider the following model (after [8])
and obtain a lower bound
Two points are worth noting (1): the lower bound has the form of
This bounding method does not work for the graph
we see that, even if we are given the last term,
It is important to note that, if we set out to estimate this bound, our target of identification would be a
Conclusions
Rule-2 of do-calculus is valid for both pre-treatment and post-treatment variables. The rule may appear as violating traditional warnings against conditioning on post-treatment variables, but such warnings apply only to stronger claims, not the one made by Rule-2. The stronger claims are (1): the identification of causal effects by adjustment and (2) the identification of unit-specific effects through counterfactual independence (i.e. ‘‘ignorability’’). The assumptions needed for these two tasks are satisfied by the back-door criterion and that is where the special handling of post-treatment covariates becomes necessary.
Funding statement: Funding: This research was supported in parts by grants from NSF #IIS-1302448 and ONR #N00014-10-1-0933 and #N00014-13-1-0153.
Acknowledgment
I thank Elias Bareinboim, Sander Greenland, Karthika Mohan and many bloggers on http://www.mii.ucla.edu/causality/ for being part of these conversations.
References
1. PearlJ. Causality: models, reasoning, and inference, 2nd ed. New York: Cambridge University Press, 2009.10.1017/CBO9780511803161Suche in Google Scholar
2. ShpitserI, VanderWeeleT, RobinsJ. 2010. On the validity of covariate adjustment for estimating causal effects. In Proceedings of the twenty-sixth conference on uncertainty in artificial intelligence. Corvallis, OR: AUAI:527–36.Suche in Google Scholar
3. RosenbaumP, RubinD. The central role of propensity score in observational studies for causal effects. Biometrika1983;70:41–55.10.1093/biomet/70.1.41Suche in Google Scholar
4. ShpitserI, PearlJ. Complete identification methods for the causal hierarchy. J Mach Learn Res2008;9:1941–79.Suche in Google Scholar
5. BareinboimE, PearlJ. Transportability from multiple environments with limited experiments: Completeness results. In WellingM, GhahramaniZ, CortesC, LawrenceN, editors. Advances of Neural Information Processing 27 (NIPS Proceedings). 2014, 280–288. http://ftp.cs.ucla.edu/pub/stat_ser/r443.pdf.Suche in Google Scholar
6. PearlJ, BareinboimE. External validity: from do-calculus to transportability across populations. Stat Sci2014;29:579–95.10.1214/14-STS486Suche in Google Scholar
7. BareinboimE, TianJ, PearlJ. Recovering from selection bias in causal and statistical inference. In BrodleyCE, StoneP, editors. Proceedings of the Twenty-eighth AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2014. Best Paper Award, http://ftp.cs.ucla.edu/pub/stat_ser/r425.pdf10.1609/aaai.v28i1.9074Suche in Google Scholar
8. GarciaFM. Definition and diagnosis of problematic attrition in randomized controlled experiments. Working paper, 2013. Available at SSRN: http://ssrn.com/abstract=2267120Suche in Google Scholar
9. BalkeA, PearlJ. Probabilistic evaluation of counterfactual queries. In Proceedings of the twelfth national conference on artificial intelligence, vol. I. Menlo Park, CA: MIT Press, 1994:230–7.Suche in Google Scholar
©2015 by De Gruyter
Artikel in diesem Heft
- Frontmatter
- Randomization Inference in the Regression Discontinuity Design: An Application to Party Advantages in the U.S. Senate
- A Boosting Algorithm for Estimating Generalized Propensity Scores with Continuous Treatments
- To Adjust or Not to Adjust? Sensitivity Analysis of M-Bias and Butterfly-Bias
- Comment
- Comment on Ding and Miratrix: “To Adjust or Not to Adjust?”
- Targeted Learning of the Mean Outcome under an Optimal Dynamic Treatment Rule
- On the Intersection Property of Conditional Independence and its Application to Causal Discovery
- Assumption Trade-Offs When Choosing Identification Strategies for Pre-Post Treatment Effect Estimation: An Illustration of a Community-Based Intervention in Madagascar
- Causal, Casual and Curious
- Conditioning on Post-treatment Variables
Artikel in diesem Heft
- Frontmatter
- Randomization Inference in the Regression Discontinuity Design: An Application to Party Advantages in the U.S. Senate
- A Boosting Algorithm for Estimating Generalized Propensity Scores with Continuous Treatments
- To Adjust or Not to Adjust? Sensitivity Analysis of M-Bias and Butterfly-Bias
- Comment
- Comment on Ding and Miratrix: “To Adjust or Not to Adjust?”
- Targeted Learning of the Mean Outcome under an Optimal Dynamic Treatment Rule
- On the Intersection Property of Conditional Independence and its Application to Causal Discovery
- Assumption Trade-Offs When Choosing Identification Strategies for Pre-Post Treatment Effect Estimation: An Illustration of a Community-Based Intervention in Madagascar
- Causal, Casual and Curious
- Conditioning on Post-treatment Variables