Machine translation as a form of feedback on L2 writing
-
Miyuki Sasaki
 ,
Atsushi Mizumoto
,
Atsushi Mizumoto

Abstract
With advances in artificial intelligence (AI), many language teachers have started exploring the classroom implications of AI-powered technology, including machine translation (MT). To examine the usefulness of MT technology in writing instruction, we conducted a mixed-methods study comparing two types of written feedback: comprehensive direct Teacher Corrective Feedback (TCF), and MT feedback. Participants were 23 Japanese university students in an intact L2 writing classroom. Sample size adequacy was confirmed through a priori power analysis. Participants were instructed to describe a picture prompt in L2 English and then in L1 Japanese. Half the participants received first TCF then MT on their L2 English text, while the order was reversed for the other half. Participants in both conditions were then asked to study the feedback and describe the same picture prompt without the feedback. In the following phase, both groups completed the same tasks in reverse order. Participants also responded to a survey exploring their engagement with the feedback. Results reveal that: 1) TCF improved complexity; 2) MT improved accuracy and fluency; and 3) variation in outcomes may be explained by the different ways in which participants engaged with both TCF and MT. Implications for appropriate classroom use of MT are discussed.
1 Introduction
The evolution of second language (L2) writing instruction has been characterized by a quest for effective feedback mechanisms. Historically, teacher corrective feedback (TCF) has been central to this endeavor, supporting both text production and language development (Hyland and Hyland 2019). Yet despite its enduring significance, the exclusivity of TCF in writing pedagogy has been progressively challenged (Atkinson and Tardy 2018). The limitations of TCF, including the intensive time commitment required from educators (e.g., Lee 2019) and the risk that it may lead to text appropriation by the teacher (Sommers 1982) have prompted a search for alternative strategies. In pursuit of this goal, the potential of machine translation (MT) as a supplementary or alternative feedback mechanism is an area yet to be fully explored.
Earlier versions of MT had accuracy problems at lexical, syntactic, and pragmatic levels, thus limiting its use as an instructional tool (Lee 2020). However, recent advances in artificial intelligence (AI), especially following the advent of Neural MT, have made MT a viable tool for facilitating both writing and language development (Wu et al. 2016). MT’s promise lies in its efficiency as well as its ability to reflect students’ intended meaning by translating their text from their first language (L1). This study therefore investigates the impact of TCF versus MT feedback, a novel approach that conceptualizes MT as reverse reformulation (from L1 to L2; see below).
Being an early attempt to compare the effects of TCF and MT as feedback, the study employs a mixed-methods approach, exploring not only quantitative changes in three linguistic aspects (complexity, accuracy, and fluency, or CAF) in participants’ pre- and post-revision texts but also their cognitive and affective engagement with feedback on their initial revision (Han and Hyland 2015).
2 Literature review
TCF can be classified in terms of: (1) how it is provided (direct correction vs. indirect, e.g., underlining); and (2) how comprehensively it is provided (A. focus on a particular item; B. comprehensive correction; and C. reformulation, i.e., the teacher’s rewriting the student’s entire L2 text). As mentioned above, TCF has been intensively studied from various perspectives since the formative years of L2 writing instruction (Hyland and Hyland 2019). However, we only focus here on studies closely related to research questions dealing with content and methodology.
2.1 Evolution of TCF in L2 writing: effects and drawbacks
Effects of TCF have been controversial in the field of L2 writing since Truscott (1996) claimed its uselessness. However, subsequent empirical studies and recent meta-analyses and comprehensive reviews (e.g., Li and Vuono 2019) have shown that TCF is generally useful. For example, Kang and Han (2015) conducted a meta-analysis of 21 empirical studies and concluded that TCF does improve grammatical accuracy in L2 writing. These researchers also compared the effectiveness of various types of TCF, including direct versus indirect and focused versus comprehensive. Although the results were statistically inconclusive, they found that direct TCF is more effective than indirect TCF and that focused TCF is more effective than comprehensive TCF in terms of “substantial” (Li and Vuono 2019: 102) effect sizes. Despite these findings, we opted to use direct comprehensive TCF as the counterpart to MT because it is more similar to MT feedback than other types of TCF (e.g., indirect or focused) as it covers each learner’s entire L2 text.
Although TCF has been regarded as one of L2 “writing teachers’ most important tasks” (Hyland and Hyland 2019: xiii), it has its own drawbacks. Of these, as mentioned earlier, two of the most relevant to our study are its inefficiency and the possibility of appropriation. First, comprehensive feedback “can be exhausting for teachers to give and overwhelming for students to receive” (Ferris and Hedgcock 2023: 341), which explains why focused feedback is often recommended as a more realistic approach (e.g., Lee 2019). Yet, comprehensive TCF continues to be widely used as a result of students’ preferences, teachers’ beliefs, or institutional requirements (e.g., Lee 2008), especially in EFL contexts.
A second concern is the risk of appropriation, which has evolved over time since it was first problematized by Sommers (1982) as the teacher taking ownership of the students’ voice by rewriting their texts. In contrast, in addition to introducing five recent studies of dialogic appropriation (i.e., between teacher and student writer), Tardy (2019) demonstrated in a case study how appropriation can emerge from multiple dialogic interactions between mentor and writer, the latter being not only an L2 student but a writer with sociocultural obligations (e.g., having to fulfill a senior co-author’s intention outside the writing class). Though such appropriation processes may enable students to reflect their own voice in their writing, such interactions take up a great deal of time for both teachers and students.
2.2 Machine translation (MT) as a learning and teaching tool in L2 writing
Before 2016, when the field entered the era of Neural MT, MT output contained so many lexico-grammatical errors that most of it was categorized as “ill-formed examples of L2” (García and Pena 2011: 473) to be corrected in post-editing when used as teaching or learning aids in L2 writing. However, after 2016, many researchers started to view MT outputs as good models. In fact, Yulianto and Supriatnaningsih (2021) reported that free and fast MT platforms such as Google Translate and DeepL were arguably comparable with human translation if the two languages belonged to the same broad family (e.g., French and English). Among those studies examining MT as a tool for helping L2 writers after 2016, most relevant to our study are those that require students to write an L1 text, translate it manually into the L2 (Own L2 Text), translate their initial L1 text using MT (MT L2 Text), and finally edit their Own L2 Text by looking at the MT L2 Text. We operationally call this approach “comparative analysis” because in the final stage, students are asked to edit their Own L2 Text by comparing it with their MT L2 Text (Table 1).
Comparative analysis design.
| Stage | Source | Action | Output |
|---|---|---|---|
| 1 | Student’s intention | Students write text in L1 | Own L1 text |
| 2 | L1 text | Students translate Own L1 text into Own L2 text manually | Own L2 text |
| 3 | L1 text | Students translate Own L1 text using MT | MT L2 text |
| 4 | Revise Own L2 text by comparing it with MT L2 text (using other resources such as dictionaries, as needed) | Revised Own L2 text |
One of these earlier and exemplary studies using comparative analysis was conducted by Lee (2020), who had 34 Korean university students with 75–90 TOEFL iBT scores describe a video clip in their L1, translate their text into English, compare their output by MT of their text into English, and finally edit the English text by comparing it with the MT version. Lee’s results showed a positive effect on the edited version of the English texts, which contained fewer lexico-grammatical errors. However, Lee’s qualitative data (interviews and reflection papers) indicated that the students were divided by their L2 proficiency in their appreciation of the value of MT as a learning tool. While lower-proficiency students found MT useful for improving their writing, higher-proficiency students only found it helpful for learning vocabulary but also found MT output inaccurate in longer texts and therefore inappropriate for academic purposes. However, this may be due to the still imperfect quality of MT when Lee conducted her study.
In a later study, Lee (2022) found that higher-level (university) students benefited more from such comparative analysis than lower-level students despite receiving help from (still imperfect though probably better) MT translation. In this mixed-methods study, Lee also reported that students at all proficiency levels found MT helpful to their revisions of various linguistic elements (e.g., vocabulary, grammar, expression) as well as to their efficient and individualized provision of translated texts.
Lee’s (2020) study was replicated in another mixed-methods study by Yang et al. (2023) with 31 Chinese EFL university students who were comparable to those in Lee (2020). Yang et al.’s results were similar to Lee’s in that the MT L2 texts improved in quality, especially in terms of lexical complexity. In addition, 90 % of the students found MT helpful in improving their writing ability even though they thought that MT translation was not perfect (see Klimova et al. 2023 for more studies using a comparative design).
2.3 MT as a feedback tool: rationale for the study
As explained in the previous section, studies using a comparative analysis design not only used MT like traditional TCF but also addressed the two drawbacks of TCF mentioned earlier. First, unlike traditional reformulation feedback, MT L2 texts more closely reflect L2 writers’ intentions as expressed in their original L1 writing. Further, the provision of MT is time-efficient as well as customized to the student’ needs because it is based on their Own L2 Text, thus better reflecting each student’s voice. Nevertheless, one critical difference between the comparative analysis design and past TCF studies is that effects of TCF are measured without reference to feedback itself during the revision session, thus making it impossible to ascertain whether any knowledge or skills gained from the TCF has become internalized, especially when framed by a cognitive perspective, as were most past TCF studies (see, for example, Peng et al. 2023). In other words, though past MT studies using the comparative analysis design showed that MT was useful as a learning and teaching tool, its effects as L2 writing feedback have not been adequately assessed. Further, though most studies using comparative analysis collect qualitative data from participating students regarding their perceptions of MT’s usefulness along with their affective reaction, none of them considered these questions in relation to other types of TCF. However, As Kahneman and Tversky (1979) suggest, people’s decision-making may vary when an object is considered in isolation versus when compared with alternatives. Thus, it is crucial to systematically compare MT with other types of feedback when we consider L2 writing classrooms where multiple feedback options may be offered.
2.4 Complexity, accuracy, and fluency (CAF) as quantitative measures of the effects of feedback
Recently, an increasing number of studies have treated TCF not simply as a grammar correction tool but as a way of facilitating broader language development through “learners’ engagement with feedback” (Manchón 2020: 14). This position is supported by studies that used not only accuracy as their measure (e.g., Benson and DeKeyser 2019) but also fluency (e.g., Criado et al. 2022), complexity (e.g., Valizadeh 2022), or all three CAF measures (e.g., Zhang and Cheng 2021). Among these measures, TCF was shown to have significant effects on accuracy, whereas the results of studies that investigated its effects on fluency and complexity have been mixed (e.g., Li and Vuono 2019).
2.5 Participant engagement as qualitative measures of the effects of feedback
As many scholars (e.g., Peng et al. 2023) have pointed out, engagement is one of the crucial determinants of TCF effectiveness. Following Ellis (2010: 342), we operationally define engagement as “how learners respond to the feedback they receive.” Compared to the effects of various types of TCF, how L2 writers engage with TCF has not been adequately investigated (e.g., Crosthwaite et al. 2022). Given Han and Hyland’s (2015) systematic and detailed classification of Ellis’s (2010) multi-dimensional framework for investigating engagement with TCF, the results of many subsequent studies support Ellis’s perspective but also reveal complex interactions between cognitive, behavioral, and affective engagement processing. However, the methods they employ (e.g., retrospective interviews) have their own demerits (e.g., memory loss, difficulties with quantification), which need to be overcome (e.g., Mackey and Gass 2022).
2.6 The study
On the basis of previous literature, we asked the following questions:
RQ1: Do direct TCF and MT have different effects on revised L2 texts in terms of complexity, accuracy, and fluency?
RQ2: Do the two feedback types have different effects on L2 writers’ engagement when examined from a multi-dimensional perspective?
RQ3: Which feedback type do participants find more useful or motivating and why?
These three questions will be first answered quantitatively, and the quantitative results will be supplemented by qualitative data to help us interpret the quantitative data.
3 Method
3.1 Participants
A sample of 23 participants were recruited from a second-year university English L2 writing class in Japan. Written consent was obtained from participants after they were informed that they were free to withdraw from the study at any time and that this would not affect their grades in any way. To confirm that sample size was adequate, we performed an a priori power analysis with G*Power version 3.1.9.6 (Faul et al. 2007) to estimate the number of participants needed to reach the recommended threshold of 0.80 with an alpha level of 0.05 (Cohen 1988). Using effect size (f) converted from Hedge’s g (0.68) as reported in Kang and Han’s (2015) meta-analysis of TCF, the analysis confirmed that our sample size reached the desired statistical power threshold because it was over 14, the necessary number of participants in the repeated measure ANOVAs (within-by-within design) employed here. The participants’ mean TOEFL ITP score was 511.3 (SD = 27.6), indicating that their English proficiency was at about CEFR B1 level.
3.2 Procedure
We used a within-participant crossover design (Lui 2016), in which participants were randomly divided into two conditions: MT first-TCF second (MT-TCF; 11 students: 7 females), and TCF first-MT second (MT-TCF; 12 students: 2 females). We chose this design because it would help minimize individual variation caused by two feedback types while addressing the ethical issue of providing treatment to only one group, which can be a problem in a simple experiment-control design.
Data collection took place over four weeks in the same classroom. The treatment was divided into four phases (Table 2):
Data collection activities.
| Phase | Activities |
|---|---|
| 1 (Week 1) | (1) Both groups described Prompt 1 (Jogging), which consisted of eight frames, first in L2 English (20 min), then in L1 Japanese (10 min) without any resources (although the TCF-MT participants did not need the L1 text, we asked both groups to write it to make both conditions as close to each other as possible). |
| 2 (Week 2) | (2) The MT-TCF group received MT feedback whereas the TCF-MT group received TCF on the L2 text they wrote in Week 1 (Jogging), with both being instructed to do their best while reviewing the feedback and using any other resources available (15 min). (3) Both groups described Prompt 1 (Jogging) without any resources, including the feedback they received (15 min). (4) Both groups responded to the Post-TCF/MT Engagement Questionnaire (8 min). (5) Both groups described Prompt 2 (Dinner Party), first in the L2 (20 min), then in the L1 (10 min) without any resources (see Appendix A in Sachs and Polio 2007 for the Dinner Party prompt). |
| 3 (Week 3) | (6) The MT-TCF group received TCF whereas the TCF-MT group received MT feedback on the L2 text they wrote in Week 2 (Dinner Party), with both being instructed to do their best while reviewing the feedback and any other resources available (15 min). (7) Both groups wrote Prompt 2 (Dinner Party) without any resources, including the feedback they received (15 min). (8) Both groups responded to the Post-TCF/MT Engagement Questionnaire (8 min). (9) Both groups responded to the Feedback Comparison Questionnaire (5 min). |
| 4 (Week 4) | (10) Both groups responded to the complexity-accuracy-fluency (CAF) retrospective improvement questionnaire (10 min) |
3.3 Types of feedback
3.3.1 Machine translation (MT)
MT feedback consisted of the Japanese text the participants had written the previous week in addition to its translation into L2 English using DeepL (Figure 1). We chose the DeepL platform (https://www.deepl.com/translator) because several studies (e.g., Yulianto and Supriatnaningsih 2021) have reported that it was one of the best MT applications available at the time. We also added the comparison between the students’ original English text from the previous week and the MT version, with modified segments marked in light blue to make them readily comparable to the TCF feedback.

Example of MT feedback.
3.3.2 Direct comprehensive teacher corrective feedback (TCF)
For English texts in TCF condition, errors were jointly coded following the 40-category classification in Sachs and Polio (2007). The two coders were the first author and an ESL instructor with a doctorate in applied linguistics and 20 years of EFL teaching experience. Inter-coder agreement for Sessions 1 and 2 combined was 0.92, and each disagreement was resolved through discussion. Once agreed, the number of errors was also used to measure accuracy in the L2 texts. As in Sachs and Polio, direct and comprehensive feedback with insertions marked in blue and deletions marked in red (Figure 2) was returned in that format to each TCF participant.

Example of teacher corrective feedback (TCF).
3.4 Quantitative measures
To quantitatively compare the effects of TCF and MT (RQ1), we used the three above-mentioned CAF measures (complexity, accuracy, and fluency). For complexity, we adopted an aggregated component score that included clause complexity, phrase complexity, and syntactic sophistication (Kyle 2016). This was chosen over conventional measures such as mean length of T-units, which have been criticized as being unsuitable for measuring various stages of writing development (Norris and Ortega 2009). To calculate this aggregated component score, we used the Tool for the Automatic Analysis of Syntactic Sophistication and Complexity (TAASSC) developed by Kyle (2016). For the accuracy measure, we used the number of errors per 100 words, following Zhang and Cheng (2021), who evaluated the effects of comprehensive direct TCF on their participants’ academic writing development. We selected this measure because it better reflects accuracy in the revised texts than measures such as percentage of error-free clauses (Zhang and Cheng 2021) when many items may require correction in a single clause. Lastly, to gauge fluency, we measured the total word count produced within the allotted time.
3.5 Qualitative data
3.5.1 Post-TCF/MT engagement questionnaires
We developed two post-TCF/MT questionnaires to address RQ2, which compared the effects of the two feedback types (TCF and MT) on participants’ engagement. In crafting our questionnaires, we closely followed Dörnyei’s (2003) step-by-step procedure. First, we created a pilot version of each of the Post-TCF/MT Engagement Questionnaires based on the two dimensions of engagement used in Han and Hyland (2015: 33) and drawn from Ellis’s (2010) multi-dimensional perspective on engagement processes with feedback:
Cognitive: (a) Awareness: noticing; (b) Awareness: understanding; (c) Meta-cognitive operations; (d) Cognitive operations deployed to process written TCF and generate revisions.
Affective: (a) Immediate emotional reaction; (b) Attitudinal response.
Based on examples in Han and Hyland’s Table 1 and Appendix F along with the findings of their case study, we initially devised six items for Post-TCF Cognitive engagement, eight for Post-MT Cognitive engagement, and five each for Post-TCF and Post-MT Affective engagement, including a single open-ended item designed to explore information not elicited by the close-ended items. All items in the questionnaires were written in Japanese and translated into English by the first author, with the translations checked by the second author for validity and accuracy.
We tested these items with four volunteers from L2 writing classes similar to the one in our study and had them do exactly the same task as described above (Table 2). Based on the results of the pilot study, we revised the original items to make them fit the task at hand in three ways. First, we merged items related to the categories of “Awareness: noticing” and “Awareness: understanding” because we were unable to distinguish between them. Instead, we created a distinction between “Immediate problem-solving operations” and “Future-oriented operations,” the former being directly related to the feedback or the text and the latter unrelated to it (Table 6a). Lastly, because the results of the pilot study showed that the participants were unable to identify meta-cognitive operations regulating mental processes in the 15 min allotted for reviewing the feedback, we removed metacognitive items. As regards “Affective engagement,” our pilot study participants used all four original close-ended items but added no additional information. We therefore kept the original four items while retaining one open-ended item for the final version. The final version of the Post-TCF/MT Engagement Questionnaire is presented in Tables 6a (Cognitive) and 6b (Affective).
3.5.2 Feedback comparison questionnaire
To answer RQ 3, we asked the following two questions, which were also tested as part of the pilot study, in order to elicit open-ended responses.
Which do you think will be more useful: MT or TCF?
Which do you think will be more motivating: MT or TCF?
3.5.3 Complexity-accuracy-fluency (CAF) retrospective improvement questionnaire
In Phase 4 (Table 2), an open-ended question was prepared to elicit our participants’ own account of their greatest improvement in one aspect of CAF (e.g., complexity) in their revision based on one specific feedback type (TCF or MT). For example, as Table 5 shows, Ken (all names are pseudonyms) made the greatest improvement in complexity (from 0.40 to 1.10) of all the participants when given TCF, and was therefore asked why he made such an improvement. This question was accompanied by detailed explanations using examples of the most improved parts in the participants’ original versus revised texts so as to jog their memory (10 min).
3.6 Data analysis
Before comparing the effects of the two feedback types in terms of CAF (RQ1), we examined data normality using a Shapiro–Wilk test as well as histograms (Figure 3). Due to non-normal variables, we used a robust 20 % trimmed-mean alternative to a two-way repeated measures ANOVA using Wilcox’s (2021) function. This analysis was accompanied by bootstrapping with 599 replicates for fair evaluation (Plonsky et al. 2015). The number of bootstrap samples (B) was 599, the default value appropriate for a 0.05 alpha level (Wilcox 2021). We selected these methods because no non-parametric alternatives to two-way within-by-within ANOVA are available for non-normal data (see Larson-Hall and Herrington 2010 for robust statistics in applied linguistics).
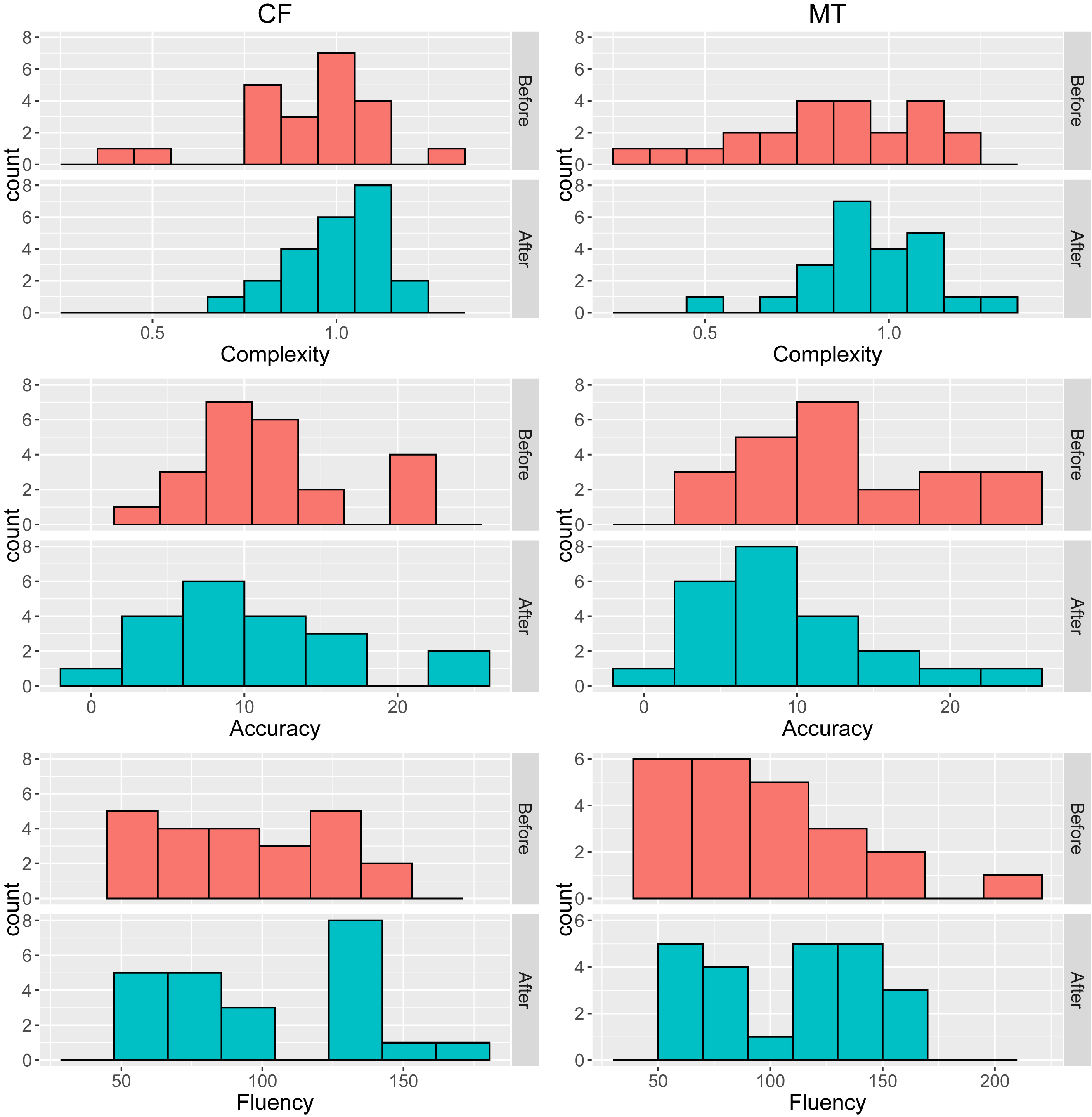
Histograms of all variables.
R version 4.2.1 was used for all analyses. For reproducibility, all data and the R code used in this study are available in OSF (https://osf.io/emny7).
4 Results
4.1 Research question 1: effects of TCF versus MT on CAF
Table 3 shows the descriptive statistics for the CAF measures before and after each feedback session. Due to non-normal variables (p < 0.05, Shapiro-Wilk), the table also reports the median and 20 % trimmed mean. Figure 3 shows histograms for each variable before and after the TCF and MT sessions.
Descriptive statistics for CAF measures before and after feedback.
| Measure | Condition | Time | Mean | SD | Median | 20 % trimmed mean | Shapiro–Wilk test (p) |
|---|---|---|---|---|---|---|---|
| Complexity | TCF | Before | 0.937 | 0.220 | 1.000 | 0.947 | 0.223 |
| After | 1.011 | 0.136 | 1.034 | 1.023 | 0.513 | ||
| MT | Before | 0.850 | 0.259 | 0.864 | 0.877 | 0.433 | |
| After | 0.951 | 0.177 | 0.933 | 0.956 | 0.508 | ||
| Accuracy | TCF | Before | 11.777 | 4.789 | 11.340 | 11.011 | 0.081 |
| After* | 10.500 | 6.363 | 8.335 | 9.500 | 0.118 | ||
| MT | Before | 13.260 | 6.441 | 12.370 | 12.621 | 0.309 | |
| After | 9.427 | 5.649 | 8.540 | 8.629 | 0.063 | ||
| Fluency | TCF | Before | 93.478 | 34.200 | 96.000 | 93.800 | 0.090 |
| After | 100.652 | 35.652 | 91.000 | 99.067 | 0.046 | ||
| MT | Before | 96.087 | 36.883 | 89.000 | 91.200 | 0.101 | |
| After | 109.478 | 35.230 | 113.000 | 109.333 | 0.154 |
-
Note. n = 23 except for *, for which three cases are missing (n = 20).
Table 4 summarizes the results of the 20 % robust trimmed-mean test and its bootstrap-t method corresponding to a two-way repeated measures ANOVA for main effects and interactions (i.e., TCF or MT and time). Figure 4 visually represents these interactions, revealing no significant main effects for TCF or MT feedback.
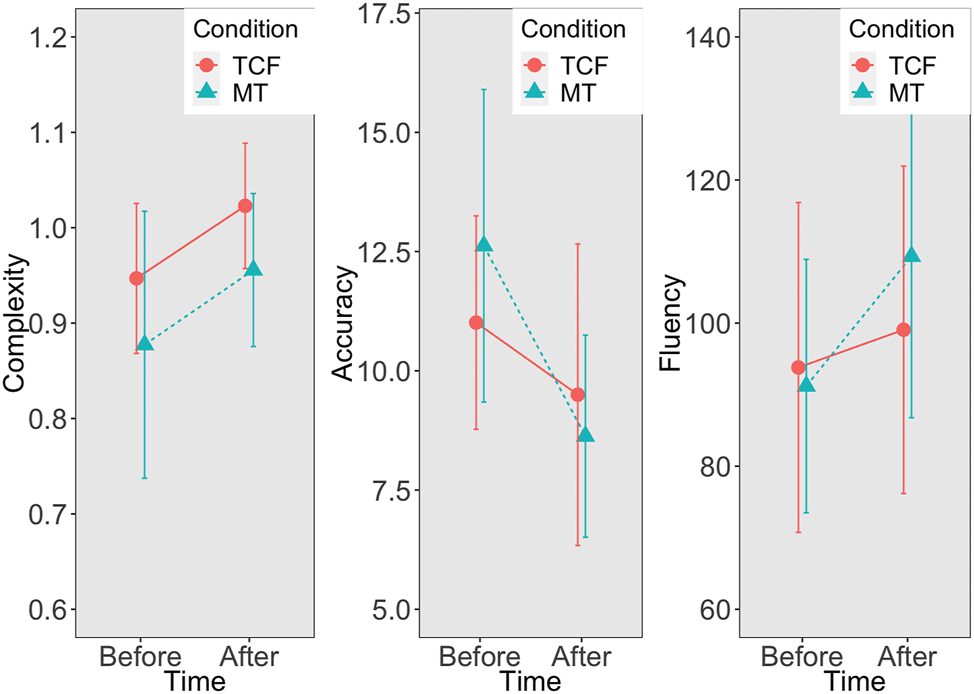
Interaction plots of two main effects. Note. Means and standard errors were calculated based on 20 % trimmed means. Error bars show 95 % confidence intervals.
Results of robust trimmed-means test and bootstrapping method.
| Source | Complexity | Accuracy | Fluency | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Q | p | bootstrap (p) | Q | p | bootstrap (p) | Q | p | bootstrap (p) | |
| Condition (TCF/MT) | 1.927 | 0.165 | 0.179 | 0.051 | 0.822 | 0.835 | 0.574 | 0.449 | 0.442 |
| Time (before/after) | 7.017 | 0.008a | 0.022 | 5.143 | 0.024a | 0.043a | 7.859 | 0.005a | 0.012a |
| Interaction (condition × time) | 0.001 | 0.971 | 0.970 | 0.620 | 0.431 | 0.446 | 3.882 | 0.049a | 0.080 |
-
Note. ap < 0.05. Twenty percentage trimmed means were used for both tests.
Additionally, interaction between condition and time was not significant except for the bootstrap-trimmed means of accuracy (p = 0.049), which was close to the alpha level of 0.05. This suggests that neither condition significantly outperformed the other in either the pre- or post-CAF measures. However, significant main effects of time were observed in all CAF measures and were corroborated by a parametric two-way ANOVA.
To better understand these time effects, we conducted post-hoc tests using paired-sample robust t-tests with 20 % trimmed means. Figure 5 summarizes the trimmed-mean differences for each CAF measure in TCF and MT conditions.
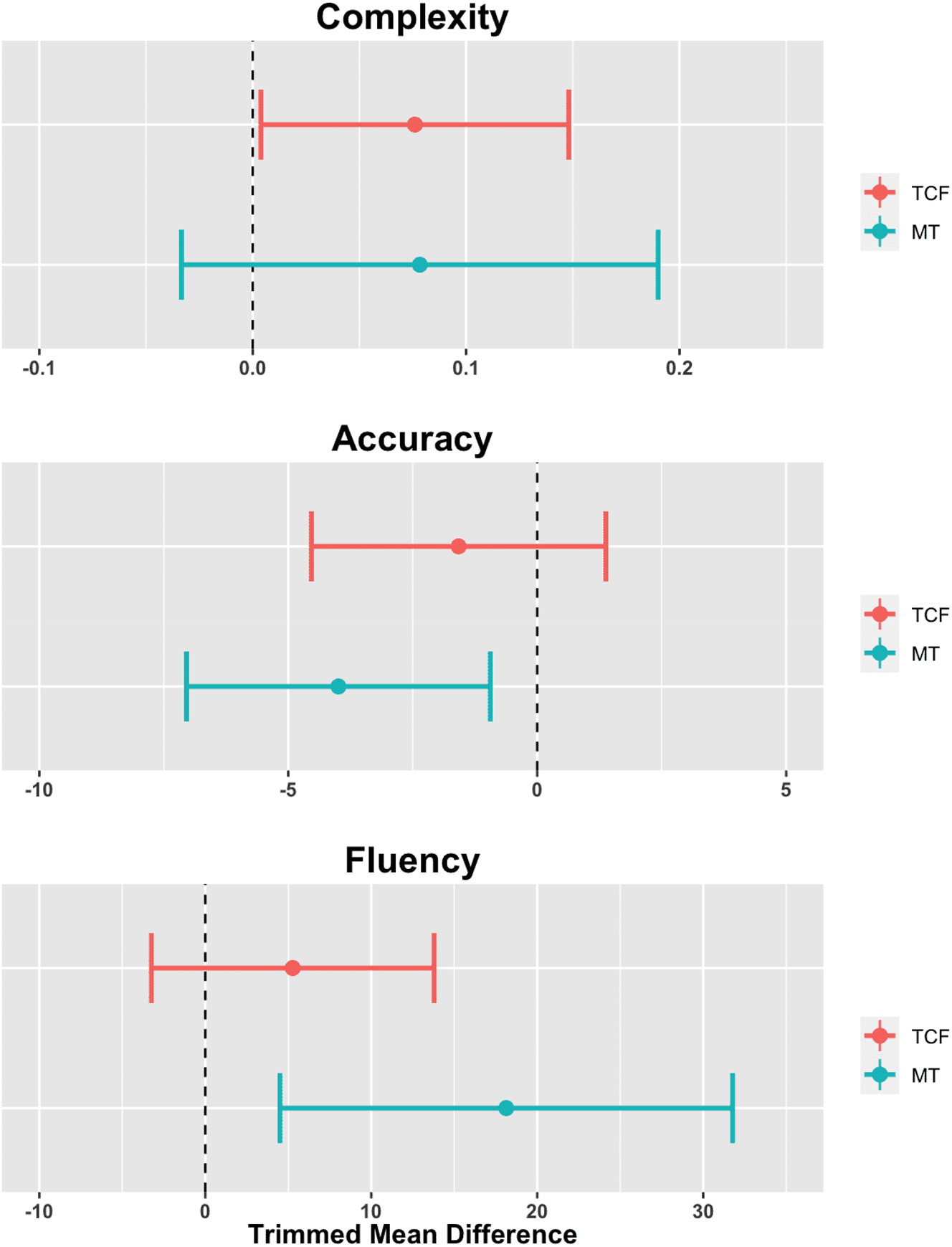
Post-hoc trimmed-means difference for each CAF measure in TCF and MT conditions. Note. Error bars show 95 % confidence intervals.
As regards complexity, a significant mean difference was observed in TCF condition, Mdiff = 0.075 [0.004, 0.148], Yt (14) = 2.260, p = 0.004, with a medium effect size (ξ) of 0.347 [0.000, 0.688]. In contrast, MT condition showed no such difference, Mdiff = 0.078 [−0.190, 0.033], Yt (14) = 1.504, p = 0.154, ξ = 0.284 [0.000, 0.732]. Effect sizes ranged from 0 to 1 (see raw trimmed-mean differences for easier interpretation in Figure 5).
For accuracy, defined as number of errors per 100 words with lower values indicating better performance, MT condition showed significant medium effect size change post-feedback, Mdiff = −3.99 [−7.043, −0.941], Yt (14) = −2.807, p = 0.014, ξ = 0.453 [0.090, 0.807]. In contrast, TCF condition showed no significant change, Mdiff = −1.58 [−4.534, 1.378], Yt (11) = −1.175, p = 0.265, ξ = 0.231 [0.000, 0.672].
In terms of fluency, MT condition exhibited a significant change, Mdiff = 18.133 [4.501, 31.765], Yt (14) = 2.853, p = 0.013, ξ = 0.303 [0.000, 0.633]. However, TCF condition showed no significant difference, Mdiff = 5.267 [−3.248, 13.781], Yt (14) = 1.327, p = 0.206, ξ = 0.082 [0.000, 0.460].
In summary, while neither TCF nor MT feedback proved more effective than the other, post-hoc analysis revealed significant gains in complexity for TCF and in accuracy and fluency for MT when comparing pre- and post-feedback texts.
4.2 High-achieving participants’ responses to the CAF retrospective improvement questionnaire
As explained above, we administered a CAF retrospective improvement questionnaire to find out why one type of feedback (TCF or MT) facilitated improvement in certain CAF aspects of L2 texts. Even though we collected responses to this questionnaire from all participants, due to space limitations, we focus here on the responses of the top six participants (Top 2 for each aspect of CAF; Table 5). When a participant ranked high on more than two measures, the higher-ranking participant of the two candidates was chosen as the respondent for that variable.
Responses to CAF retrospective improvement questionnaire.
| Feedback | Measurementa | Participant | Responseb |
|---|---|---|---|
| TCF | Complexity | Ken | I tried to add parts I wanted to write in the revision when I saw the picture the second time. |
| Pre 0.40 | |||
| Post 1.10 | |||
| Complexity | Shou | I think I tried to use more complex sentence structures because I felt that I needed to show improvement in my writing after receiving feedback. | |
| Pre 0.80 | |||
| Post 1.00 | |||
| MT | Accuracy | Genya | I could check the words I did not know how to express in English in the MT translation. I also compared my errors in the original English text with the MT translation and revised the English text, and I was able to improve it. |
| Pre 23.8 | |||
| Post 3.8 | |||
| Accuracy | Yuri | When I received the MT feedback, I compared it with my own English writing and checked what was wrong with it. When I revised the original writing, I had enough time to check if my writing was accurate compared with the first time. | |
| Pre 15.0 | |||
| Post 5.0 | |||
| MT | Fluency | Yuki | The English translation gave me power. Because I am Japanese, I can use Japanese better [than English]. In comparison, my ability to use English is not sufficient, and that’s why the English translation gave me power (and I could write a lot). |
| Pre 64 | |||
| Post 131 | |||
| Fluency | Maya | Reading the MT translation made me notice my own errors in my original English expressions and then come up with better expressions. Because I learned transitional expressions in English from the MT translation, I became more aware of how to make sentences cohere better rather than by just writing sentence by sentence. The MT feedback gave me a greater variety of expressions I could use, and I could relate them to the expressions I had used in the original text in the revision session, which led to a longer text. | |
| Pre 107 | |||
| Post 135 |
-
Notes. aComplexity is defined as an aggregated component score that includes clause complexity, phrase complexity, and syntactic sophistication. Accuracy is defined as number of errors per 100 words. Fluency is defined as total number of words produced within the allotted time. bUnderlined segments represent future-oriented writing in revisions.
Table 5 shows that these high-achieving students all actively engaged with the feedback. Furthermore, more than half of all responses (4 out of 6) show that their behavioral engagement sometimes went beyond the text they were reviewing (i.e., the underlined segments).
4.3 Research question 2: engagement with TCF versus MT
Table 6a presents percentages of participants who chose different types of cognitive engagement in answer to the Post-TCF/MT Engagement Questionnaire. First, more participants (91.3 %; Item No. 1 in green) noticed the TCF, while 45.5 and 72.7 % compared the MT with, respectively, the Japanese and English texts they wrote the previous week (Items No. 1 and 5 in green). Second, for both TCF and MT, approximately half to two-thirds of participants (TCF: Items No. 1–3, M% = 69.6 %; MT: Items No. 1–7, M% = 52.6 %) engaged with immediate problem-solving (IPS) operations, such as “I wonder why the item was corrected” for TCF and “I wondered how my Japanese text was translated” for MT. In contrast, a greater number of participants (Items No. 4–6 in blue; M% = 27.5 %) engaged with future-oriented (FO) cognitive operations; e.g., “I wonder how I would write the part that did not exist in the original text”) when given TCF compared to MT (Items No. 8 and 9 in blue: M% = 15.9 %).
Percentages of participants engaging with post-TCF/MT engagement questionnaire (max. n = 23).
| Feedback type | Item no. | Sub-construct | Item | Immediate problem-solving (IPS) or future-oriented (FO) | % (n) |
|---|---|---|---|---|---|
| TCF | 1 | Awareness: noticing | I compared the corrected parts with my own errors | IPS | 91.3 (21) |
| 2 | Cognitive operations | In addition to (1), I wondered why the item was corrected | IPS | 47.8 (11) |
|
| 3 | Cognitive operations | In addition to (1), I memorized the correct forms | IPS | 69.6 (16) |
|
| 4 | Cognitive operations | In addition to (1), I wonder how I would write the part that did not exist in the original text | FO | 26.1 (6) |
|
| 5 | Cognitive operations | I wondered how to further improve the original text by adding things that did not exist before | FO | 39.1 (9) |
|
| 6 | Cognitive operations | I wondered how to include expressions from my Japanese text that did not exist in my English text into my revised English text | FO | 17.4 (4) |
|
| 7 | Others | 4.3 (1) |
|||
| MT | 1 | Awareness: noticing | I compared the MT with my own Japanese text | IPS | 45.5 (10) |
| 2 | Cognitive operations | In addition to (1), I wondered how my Japanese text was translated | IPS | 59.1 (13) |
|
| 3 | Cognitive operations | In addition to (2), I tried to memorize English words and expressions I did not know | IPS | 50 (11) |
|
| 4 | Cognitive operations | In addition to (2), I tried to memorize English words and expressions in the MT that were better than mine | IPS | 45.5 (10) |
|
| 5 | Awareness: noticing | I compared the MT with the English text I wrote last week | IPS | 72.7 (16) |
|
| 6 | Cognitive operations | In addition to (5), I tried to memorize English words and expressions in the MT I did not know | IPS | 50 (11) |
|
| 7 | Cognitive operations | In addition to (5), I tried to memorize English words and expressions in the MT that were better than mine | IPS | 45.5 (10) |
|
| 8 | Cognitive operations | In addition to (5), I wondered how I could write an English text better than the MT text given to me | FO | 22.7 (5) |
|
| 9 | Cognitive operations | I wondered if I could add to the revision some expressions that did not exist in the Japanese text I wrote last week | FO | 9.1 (2) |
|
| 10 | Others | 0 (0) |
-
Notes. Items in green cells refer to Awareness: noticing for immediate problem solving. Items in white cells are for Cognitive operations for immediate problem solving. Items in blue cells are for Future oriented cognitive operations.
Table 6b presents percentages of participants who chose items indicating affective engagement in response to the Post-TCF/MT Questionnaire administered after they were given either TCF or MT. When independently asked, more than half the participants reported feeling positive about both TCF and MT. However, many more felt much more positive and motivated about TCF because they felt they could learn more from it than from MT.
Percentages of participants engaging with the post-TCF/MT affective questionnaire (max. n = 23).
| Feedback type | Item no. | Sub-construct | Item | TCF % (n) | MT % (n) |
|---|---|---|---|---|---|
| TCF/MT | 1 | Emotional response | The feedback made me feel disappointed about my English proficiency | 30.4 (7) |
22.7 (5) |
| 2 | Attitudinal response | I felt positive about the feedback because I could learn something from it | 69.6 (16) |
50 (11) |
|
| 3 | Attitudinal response | The feedback made me feel motivated because I could learn something from it | 43.5 (9) |
13.6 (3) |
|
| 4 | Attitudinal response | I felt nothing | 2 (8.7) |
13.6 (3) |
|
| 5 | Others (give as many details as possible) | 0 (0) |
0 (0) |
4.4 Research question 3: comparison between MT and TCF
Table 7 presents the results of the Feedback Comparison Questionnaire, which addressed Research Question 3. Although Items 2 and 3 in Table 6b and Items 6 and 7 in Table 7, respectively, are similar, their percentages are quite different, probably because Items 2 and 3 in Table 6b were asked independently for each type of feedback (TCF and MT) whereas Items 6 and 7 in Table 7 comparatively. This is especially evident in Item 2, Table 6b, where both MT (50 %) and TCF (69.6 %) received relatively positive evaluations from participants, which contrasts sharply with their comparative choices in Items 6 and 7 in Table 7, where, when asked which of the two feedback types they preferred, about 80 % or more chose TCF as more useful and motivating. In fact, their responses to the open-ended questionnaire almost unanimously (17 out of 18) showed that they found TCF to be more useful because it allowed them to see their specific grammatical problems.
Results of feedback comparison questionnaire.
| Item no. | Item | TCF | MT |
|---|---|---|---|
| 6 | Which do you think will be more useful: TCF or MT? | 78.3 % | 21.7 % |
| 7 | Which do you think will be more motivating: TCF or MT? | 87.0 % | 17.0 % |
5 Discussion
We will now discuss our findings in light of previous studies. Given that very few studies have examined the effects of MT as feedback, we will contrast the results of our study with those of studies focusing on TCF. We know that the results of those past studies that used MT within a comparative analysis design should be treated with caution because they all allowed their participants to use resources, including MT, during the revision sessions. From a cognitive perspective (e.g., Peng et al. 2023), these results are not comparable with those of TCF studies as the improvement evident in those studies’ final revised texts may not reflect knowledge truly acquired by the writers because the improvement demonstrated in the final revised texts of MT studies may simply reflect the fact that writers copied material from the resources available while revising. We will therefore refrain from referring to the results of MT studies unless they are directly relevant.
Quantitatively, three findings emerge in our study: complexity tends to improve with TCF, and accuracy and fluency tend to improve with MT. First, TCF had a positive effect on complexity measured as an aggregated component score that included clause complexity, phrase complexity, and syntactic sophistication. This is noteworthy since TCF was offered only once for a 15 min review before revision. Traditionally, complexity has not been extensively studied along with effects of TCF in L2 writing. Even when complexity was used as an exclusive tool to measure effects of TCF, as in Valizadeh (2022), where direct comprehensive TCF had positive effects on complexity in the post-test (but not in the delayed test), such mixed results were only explained from an outsider (etic) perspective.
In contrast, in our TCF condition, students writing more complex sentences could be explored from three perspectives. First, TCF has only one central focus of attention (the original English text containing error corrections) whereas MT has more than one such source (the Japanese text, its translation, and the original English text). Our questionnaire results (Table 6a), which indicate that TCF led a higher percentage of participants (91.3 %: Item 1) to notice the feedback compared to MT (45.5 %: Item 1; 72.7 %: Item 5), support this assumption. Moreover, when given TCF, more participants (27.5 %: Mean of No. 4–6) engaged with future-oriented cognitive operations compared to MT (15.9 %; Mean of No. 8 and 9). Recall that in both TCF and MT conditions, the revision was made after the writers were required to describe the same picture prompt from the beginning with no resources available after having done their best to review the given feedback and other resources (Table 2). In TCF condition, students may be better able to refine their English originals by “add[ing] parts” (see Ken; Table 5) or by “try[ing] to use more complex sentence structures” (Shou) compared to those who received MT feedback, who may have been busy making the most of a greater number of resources available during the review session.
Our second quantitatively notable result is that MT contributed to improvements in accuracy measured as the number of errors per 100 words. This contradicts the results of Zhang and Cheng (2021), who examined the effects of comprehensive direct TCF and found a significant difference on the same measure between the experimental and the control groups following a 16-week semester with four comprehensive TCF sessions plus three weeks for the delayed session in university English writing classes in China. In our study, in terms of engagement, 72.7 % of students (Item No. 5) in MT condition compared the MT feedback, i.e., the high accuracy level of L2 translations of the meaning they intended to convey, with their original English texts written at their own accuracy level in English, during the 15 min review session (Table 6a). This may explain the improvement in accuracy in their revised texts as both students who ranked high in accuracy (Table 5) mentioned that such a comparison when given MT was useful. However, there was a gap between MT’s contribution to accuracy and participants’ perceptions. A larger number of participants rated TCF positively and deemed it more motivating than MT (Table 6b), especially when the two approaches were directly compared (Table 7), because they thought that TCF more closely catered for their specific grammatical errors.
Finally, MT also improved participants’ fluency between original and revised texts. This result can be viewed in differences in future-oriented cognitive engagement elicited by the TCF and MT conditions. As Shou’s Texts 1 and 2 before and after TCF show, when students in TCF condition were trying to use more complex sentence structures, that is, when they engaged in future-oriented cognitive operations, they tended to generate more new expressions related to the L2 original (e.g., “I felt that I needed to show development in my writing after receiving the feedback” – Shou; Table 5).
Shou’s Text 1 (after TCF)*

*Note: Shou’s fluency [No. of words = 55] is lower than that [M = 96.13, SD = 36.90] of the other participants in the MT condition)
Shou’s Text 2 (Writing for Prompt 2 for the second time; green: fully corrected; blue: new errors, corrected in this new text)

However, as Shou’s Text 2 shows, this operation did not necessarily lead to more accurate or longer texts. In contrast, in MT condition, the product of writers’ future-oriented cognitive engagement with the feedback tended to relate to entirely new content. Based on the qualitative data presented in Table 5 and the information shown in Table 6a, we can speculate that during the review session, the MT participants focused on making the best of MT by memorizing expressions from the feedback so as to create a better text than their English original, as exemplified in Maya’s response to why her revised text became longer than her original:
The MT feedback gave me a greater variety of expressions I could use, and I could relate them to the expressions I had used in the original text in the revision session, which led to a longer text.
Together with their cognitive operations in comparing the MT with the English original (Table 6b), in MT condition, students improved in both accuracy and fluency by learning from the MT feedback, which provided near-perfect translations of what they originally wrote in Japanese (see also Yuki’s excerpt in Table 5).
Lastly, in terms of research design, the results of our study highlight several merits of the methods we applied and suggest areas that remain to be investigated. First, we used a crossover research design in which we could compare MT and TCF in a real L2 writing classroom so as to enable all participants to experience the respective merits of each type of feedback. This method minimizes ethical concerns as well as possible hidden influences of individual differences when comparing completely different groups (e.g., experimental vs. comparison; see Lui 2016). That said, because we used an intact L2 writing class, the sample size was inevitably small. Although we used a priori power analysis to test the sufficiency of the sample size for our statistical analyses, it would be useful to verify the results with a larger sample size. Second, insider (emic) data revealed by the mixed-methods design supplemented the quantitative results in ways that even a large-scale quantitative study may not reveal.
Our study is one of the first to use such data collected through theoretically framed surveys (e.g., Ellis 2010) and improved based on the results of a pilot study (e.g., through the addition of a number of “immediate problem-solving” vs. “future-oriented” items) or based on the quantitative results (CAF retrospective improvement questionnaire). Although questionnaires and post-hoc questions have demerits (Mackey and Gass 2022), if TCF continues to be viewed as a tool for L2 development (Manchón 2020), examining why certain types of TCF are facilitative for certain linguistic aspects of L2 texts should be useful.
In terms of targeted tasks, we chose picture prompts for the writing tasks to avoid unfamiliar content or language in the prompts themselves. To examine the impact of MT on student writing and learning, it will be important to conduct similar studies with a wider variety of genres and task types, both academic and non-academic. Another key factor, especially given the need for larger sample size in future studies, is students’ L2 proficiency level. In a recent MT study using a comparative analysis design, Lee (2022) reported that higher-level L2 proficiency students tended to benefit much more from MT than lower-level students in terms of improvement in the quality of their revised texts. Hence, the benefits received from TCF and MT may also differ depending on the learners’ L2 proficiency.
6 Conclusion
Comprehensive direct TCF and MT as feedback are similar in that they both provide L2 writers with possible canonical forms throughout the written text. Our quantitative results show that based on CAF measures, both types of feedback produced comparable improvements in participants’ writing. In addition, some participants found MT feedback both useful and motivating. Given these findings, MT feedback appears to be a viable alternative to TCF. However, this does not mean that MT can entirely replace TCF. Our analysis also indicates that TCF contributed more to complexity whereas MT helped improve accuracy and fluency. Furthermore, participants tended to feel more positive and much more motivated about TCF than about MT. Given different ways in which TCF and MT contributed to students’ language development and given students’ preferences for TCF, it may be advisable to use MT as a complement to TCF rather than as a replacement.
Using MT as an additional form of feedback has a number of advantages. First, it can reduce teachers’ burden. Instead of spending a large amount of time correcting student writing, teachers can provide fewer language-based comments, using MT for more comprehensive feedback. It also allows teachers to spend more time focusing on aspects of writing other than language – including writing purpose, audience, use of sources, and genre-specific features. MT feedback can also provide a wider variety of sentence structures, vocabulary, and expressions, especially in EFL contexts, where students’ exposure to the target language is relatively limited. Finally, MT can help students use the idea development and organization skills they have already developed in their L1. As we saw in Yuki’s case in Table 5, this benefit may be especially important for students with lower L2 proficiency levels, where the challenge of writing directly in English with limited L2 resources may prevent them from developing and expressing their ideas fully in the target language (e.g., van Weijen et al. 2009).
One challenge in implementing MT feedback is students’ perceptions. As noted above, most participants in this study found TCF more motivating than MT because they thought that TCF was more closely customized to their specific grammar issues even though MT contributed more to accuracy. To maximize student engagement, it may be necessary to explain to them the benefits of MT feedback as documented in Lee (2019) as well as in this study. Since our participants did value MT when asked independently, it should be possible to persuade students to see MT as a viable complement to teacher-provided feedback.
Funding source: MEXT/JPSP KAKENHI
Award Identifier / Grant number: 20H01286
-
Research funding: This work was supported by MEXT/JPSP KAKENHI Grant No. 20H01286.
References
Atkinson, Dwight & Christine Tardy. 2018. SLW at the crossroads: Finding a way in the field. Journal of Second Language Writing 42. 86–93. https://doi.org/10.1016/j.jslw.2018.10.011.Suche in Google Scholar
Benson, Susan & Robert DeKeyser. 2019. Effects of written corrective feedback and language aptitude on verb tense accuracy. Language Teaching Research 23(6). 702–726. https://doi.org/10.1177/1362168818770921.Suche in Google Scholar
Cohen, Jacob. 1988. Statistical power analysis for the behavioral sciences, 2nd edn. Mahwah, NJ: Lawrence Erlbaum.Suche in Google Scholar
Criado, Raquel, Aitor Garcés-Manzanera & Luke Plonsky. 2022. Models as written corrective feedback: Effects on young L2 learners’ fluency in digital writing from product and process perspectives. Studies in Second Language Learning and Teaching 12(4). 697–719. https://doi.org/10.14746/ssllt.2022.12.4.8.Suche in Google Scholar
Crosthwaite, Peter, Sulistya Ningrum & Icy Lee. 2022. Research trends in L2 written corrective feedback: A bibliometric analysis of three decades of Scopus-indexed research on L2 WCF. Journal of Second Language Writing 58. 100934. https://doi.org/10.1016/j.jslw.2022.100934.Suche in Google Scholar
Dörnyei, Zoltán. 2003. Questionnaires in second language research: Construction, administration, and processing. Mahwah, NJ: Lawrence Erlbaum.Suche in Google Scholar
Ellis, Rod. 2010. Epilogue: A framework for investigating oral and written corrective feedback. Studies in Second Language Acquisition 32(2). 335–349. https://doi.org/10.1017/S0272263109990544.Suche in Google Scholar
Faul, Franz, Edgar Erdfelder, Albert-Georg Lang & Axel Buchner. 2007. G*Power 3: A flexible statistical power analysis program for the social, behavioral, and biomedical sciences. Behavior Research Methods 39(2). 175–191. https://doi.org/10.3758/BF03193146.Suche in Google Scholar
Ferris, Dana R. & John S. Hedgcock. 2023. Teaching L2 composition: Purpose, process, and practice, 4th edn. New York: Routledge.10.4324/9781003004943Suche in Google Scholar
García, Ignacio & María Isabel Pena. 2011. Machine translation-assisted language learning: Writing for beginners. Computer Assisted Language Learning 24(5). 471–487. https://doi.org/10.1080/09588221.2011.582687.Suche in Google Scholar
Han, Ye & Fiona Hyland. 2015. Exploring learner engagement with written corrective feedback in a Chinese tertiary EFL classroom. Journal of Second Language Writing 30. 31–44. https://doi.org/10.1016/j.jslw.2015.08.002.Suche in Google Scholar
Hyland, Ken & Fiona Hyland. 2019. Feedback in second language writing: Contexts and issues, 2nd edn. Cambridge: Cambridge University Press.10.1017/9781108635547Suche in Google Scholar
Kahneman, Daniel & Amos Tversky. 1979. Prospect theory: An analysis of decision under risk. Econometrica 47(2). 263–291. https://doi.org/10.2307/1914185.Suche in Google Scholar
Kang, Eun-Yang & Zhaohong Han. 2015. The efficacy of written corrective feedback in improving L2 written accuracy: A meta-analysis. Modern Language Journal 99(1). 1–18. https://doi.org/10.1111/modl.12189.Suche in Google Scholar
Klimova, Blanka, Marcel Pikhart, Alice Delorme Benites, Caroline Lehr & Christina Sánchez-Stockhammer. 2023. Neural machine translation in foreign language teaching and learning: A systematic review. Education and Information Technologies 28(1). 663–682. https://doi.org/10.1007/s10639-022-11194-2.Suche in Google Scholar
Kyle, Kristopher. 2016. Measuring syntactic development in L2 writing: Fine grained indices of syntactic complexity and usage-based indices of syntactic sophistication. Atlanta, GA: Georgia State University dissertation.Suche in Google Scholar
Larson-Hall, Jenifer & Richard Herrington. 2010. Improving data analysis in second language acquisition by utilizing modern developments in applied statistics. Applied Linguistics 31(3). 368–390. https://doi.org/10.1093/applin/amp038.Suche in Google Scholar
Lee, Icy. 2008. Understanding teachers’ written feedback practices in Hong Kong secondary classrooms. Journal of Second Language Writing 17(2). 69–85. https://doi.org/10.1016/j.jslw.2007.10.001.Suche in Google Scholar
Lee, Icy. 2019. Teacher written corrective feedback: Less is more. Language Teaching 52(4). 524–536. https://doi.org/10.1017/S0261444819000247.Suche in Google Scholar
Lee, Sangmin-Michelle. 2020. The effectiveness of machine translation in foreign language education: A systematic review and meta-analysis. Computer Assisted Language Learning 36(1–2). 103–125. https://doi.org/10.1080/09588221.2021.1901745.Suche in Google Scholar
Lee, Sangmin-Michelle. 2022. Different effects of machine translation on L2 revisions across students’ L2 writing proficiency levels. Language Learning & Technology 26(1). 1–21.Suche in Google Scholar
Li, Shaofeng & Alyssa Vuono. 2019. Twenty-five years of research on oral and written corrective feedback in System. System 84. 93–109. https://doi.org/10.1016/j.system.2019.05.006.Suche in Google Scholar
Lui, Kung-Jong. 2016. Crossover design: Testing, estimation, and sample size. Hoboken, NJ: Wiley.10.1002/9781119114710Suche in Google Scholar
Mackey, Alison & Sue Gass. 2022. Second language research: Methodology and design, 4th edn. New York: Routledge.10.4324/9781003188414Suche in Google Scholar
Manchón, Rosa (ed.). 2020. Writing and language learning: Advancing research agendas. Amsterdam: John Benjamins.10.1075/lllt.56Suche in Google Scholar
Norris, John & Lourdes Ortega. 2009. Towards an organic approach to investigating CAF in instructed SLA: The case of complexity. Applied Linguistics 30(4). 555–578. https://doi.org/10.1093/applin/amp044.Suche in Google Scholar
Peng, Carrie X., Neomy Storch & Ute Knoch. 2023. Greater coverage versus deeper processing? Comparing individual and collaborative processing of teacher feedback. Language Teaching Research. https://doi.org/10.1177/13621688231214910.Suche in Google Scholar
Plonsky, Luke, Jessey Egbert & Geoffrey Laflair. 2015. Bootstrapping in applied linguistics: Assessing its potential using shared data. Applied Linguistics 36(5). 591–610. https://doi.org/10.1093/applin/amu001.Suche in Google Scholar
Sachs, Rebecca & Charlene Polio. 2007. Learners’ uses of two types of written feedback on an L2 writing revision task. Studies in Second Language Acquisition 29(1). 67–100. https://doi.org/10.1017/S0272263107070039.Suche in Google Scholar
Sommers, Nancy. 1982. Responding to student writing. College Composition and Communication 33(2). 148–156. https://doi.org/10.2307/357622.Suche in Google Scholar
Tardy, Christine M. 2019. Appropriation, ownership, and agency: Negotiating teacher feedback in academic settings. In Ken Hyland & Fiona Hyland (eds.), Feedback in second language writing: Contexts and issues, 2nd edn. Cambridge: Cambridge University Press.10.1017/9781108635547.006Suche in Google Scholar
Truscott, John. 1996. The case against grammar correction in L2 writing classes. Language Learning 46(2). 327–369. https://doi.org/10.1111/j.1467-1770.1996.tb01238.x.Suche in Google Scholar
Valizadeh, Mohammadreza. 2022. The effect of comprehensive written corrective feedback on EFL learners’ written syntactic complexity. Journal of Language and Education 8(1). 196–208. https://doi.org/10.17323/jle.2022.12052.Suche in Google Scholar
van Weijen, Daphne, Huub van den Bergh, Gert Rijlaarsdam & Ted Sanders. 2009. L1 use during L2 writing: An empirical study of a complex phenomenon. Journal of Second Language Writing 18(4). 235–250. https://doi.org/10.1016/j.jslw.2009.06.003.Suche in Google Scholar
Wilcox, Rand. 2021. Introduction to robust estimation and hypothesis testing, 5th edn. Amsterdam: Elsevier.10.1016/B978-0-12-820098-8.00007-5Suche in Google Scholar
Wu, Yonghui, Mike Schuster, Zhifeng Chen, Quoc V. Le, Mohammad Norouzi, Wolfgang Macherey, Maxim Krikun, Yuan Cao, Qin Gao, Klaus Macherey, Jeff Klingner, Apurva Shah, Melvin Johnson, Xiaobing Liu, Łukasz Kaiser, Stephan Gouws, Yoshikiyo Kato, Taku Kudo, Hideto Kazawa, Keith Stevens, George Kurian, Nishant Patil, Wei Wang, Cliff Young, Jason Smith, Jason Riesa, Alex Rudnick, Oriol Vinyals, Greg Corrado, Macduff Hughes & Jeffrey Dean. 2016. Google’s neural machine translation system: Bridging the gap between human and machine translation. https://arxiv.org/abs/1609.08144 (accessed 20 December 2021).Suche in Google Scholar
Yang, Yanxia, Xiangqing Wei, Ping Li & Xuesong Zhai. 2023. Assessing the effectiveness of machine translation in the Chinese EFL writing context: A replication of Lee (2020). ReCALL 35(2). 211–224. https://doi.org/10.1017/S0958344023000022.Suche in Google Scholar
Yulianto, Ahmad & Rina Supriatnaningsih. 2021. Google Translate versus DeepL: A quantitative evaluation of close-language pair translation (French to English). Asian Journal of English Language and Pedagogy 9(2). 109–127.10.37134/ajelp.vol9.2.9.2021Suche in Google Scholar
Zhang, Lawrence J. & Xiaolong Cheng. 2021. Examining the effects of comprehensive written corrective feedback on L2 EAP students’ linguistic performance: A mixed-methods study. Journal of English for Academic Purposes 54. 101043. https://doi.org/10.1016/j.jeap.2021.101043.Suche in Google Scholar
© 2024 the author(s), published by De Gruyter, Berlin/Boston
This work is licensed under the Creative Commons Attribution 4.0 International License.