Eigenschaften von Hör- und Lesetexten in Hochschulzugangssprachtests am Beispiel der DSH
-
Jupp Möhring
studierte Deutsch als Fremdsprache, Soziologie und Journalistik an der Universität Leipzig. Er ist an der Technischen Universität Dresden und dem Institut für Testforschung und Testentwicklung tätig. Seine Arbeits- und Forschungsschwerpunkte sind die studienvorbereitende und -begleitende Förderung von Deutschkompetenzen internationaler Studierender, korpuslinguistische Fragestellungen und das zuverlässige Testen von Sprachkompetenzen.


Zusammenfassung
Die DSH-Spezifikationen zu den Prüfungsteilen Hören und Lesen bieten den DSH-Standorten Anhaltspunkte zur Gestaltung von Inputtexten. Gleichzeitig verbleibt viel Spielraum zur konkreten Ausgestaltung von Texten und Aufgaben bei den DSH-Autorinnen und -Autoren und wenig ist über die Eigenschaften und die Vergleichbarkeit der an den Prüfungsstandorten genutzten Texte bekannt. In diesem Beitrag werden 115 authentische Hör- und Lesetexte von elf DSH-Standorten1 auf ihre Lesbarkeit und weitere lexikalische Eigenschaften hin untersucht.
Abstract
The DSH test specifications for the listening and reading sections of the examination provide the DSH locations with guidelines for the design of input texts, but at the same time the DSH authors have a great deal of leeway in the concrete design of texts and tasks and little is known about the characteristics and comparability of the texts used at the DSH locations. In this article, 115 authentic listening and reading texts from eleven DSH locations are analysed in terms of their readability and other lexical features.
1 Einleitung
Deutschland[1] ist das wichtigste nicht englischsprachige Gastland für internationale Studierende (DAAD/DZHW 2023: 14). Die überwiegende Mehrheit der 2022 knapp 370.000 internationalen Studierenden in Deutschland strebt dabei einen Abschluss in Deutschland an (ebd.: 38). Trotz eines wachsenden Angebots an englischsprachigen Studiengängen besuchen rund 43 % der internationalen Studierenden rein deutschsprachige Studiengänge (Falk/Kercher/Zimmermann 2022: 19; Wisniewski et al. 2022: 58–60). Diese Gruppe muss die sogenannte sprachliche Studierfähigkeit in der Fremdsprache Deutsch in der Regel in Form eines bestandenen Hochschulzugangssprachtests (HZST) gemäß der Rahmenordnung über Deutsche Sprachprüfungen für das Studium an deutschen Hochschulen (RO-DT) (HRK/KMK 2019) nachweisen. Der Test Deutsch als Fremdsprache (TestDaF), der seit 2020 neben einer papierbasierten Version auch digital angeboten wird (Kecker/Eckes 2022: 290), war 2022 mit 22.991 Teilnehmenden der wichtigste HZST (g.a.s.t. 2023), gefolgt von der Deutschen Sprachprüfung für den Hochschulzugang (DSH) mit 12.151 Teilnehmenden (FaDaF 2023). HZST sind High-Stakes-Tests auf dem Sprachniveau B2–C1 mit enormen Konsequenzen für Bildungsbiografien und Gesellschaft, weshalb sie einer strengen Qualitätskontrolle hinsichtlich testmethodischer Gütekriterien und einem hohen Standardisierungsgrad unterliegen (sollten) (Deygers/Vanbuel 2022; Wisniewski et al. 2022: 60–65). Der Grad dessen ist für die in Deutschland üblichen HZST trotz der Spezifikation in oben genannter RO-DT (HRK/KMK 2019) sehr variabel und Studien (Wisniewski/Möhring 2021: 210) deuten auf eine Schieflage bei Durchlässigkeit, Qualität und Transparenz der deutschsprachigen HZST hin (Wisniewski et al. 2022: 432–434). Die DSH spielt in diesem Spannungsfeld eine Sonderrolle, da sie dezentral an Hochschulen und Studienkollegs entwickelt und durchgeführt wird. Die DSH-Standorte folgen bei der Testentwicklung der in oben genannter RO-DT festgelegten und zuletzt 2019 überarbeiteten DSH-Musterprüfungsordnung (Appel et al. 2022: 377) und dem 2022 grundständig, 2024 nochmals geringfügig überarbeiteten „Handbuch zur DSH-Erstellung und -Durchführung“ (Qualitätszirkel des FaDaF 2022 und 2024). Kernelemente der DSH sind durch diese Richtlinien, welche zudem in „Kriterienkatalogen“ (Appel et al. 2022: 377) zusammengefasst sind, an allen DSH-Standorten vergleichbar und deren Einhaltung wird im Zuge der (Re-)Registrierung von DSH-Standorten vom FaDaF überprüft (ebd.: 376–377). Gleichwohl weist die DSH im Vergleich zu anderen High-Stakes-Sprachtests einen geringen Standardisierungsgrad auf (Grein 2021: 267), was einerseits eine flexible, enge Anbindung der DSH an die lokalen Sprachanforderungen einzelner Hochschulen ermögliche (Appel et al. 2022: 371; Jung 2022); andererseits seien Reliabilität und Validität der DSH dadurch womöglich begrenzt und unter diesen Vorzeichen der „Nutzen der Prüfung als gering anzusehen“ (Krekeler 2005: 326). Die dezentrale Entwicklung dürfte einer der Gründe sein, warum die DSH ungleich weniger beforscht und dokumentiert ist als große, standardisierte HZST wie TOEFL oder TestDaF. Vorliegende Ergebnisse (Friedland/Sabo 2022; Koreik 2005; Yildirim 2022) sind zudem auf die sich an Forschungsprojekten beteiligenden DSH-Standorte begrenzt und entsprechend nicht generalisierbar, was auch auf die vorliegende Studie zutrifft.
Dieser Beitrag beschäftigt sich mit zentralen Elementen der DSH-Prüfung: den Eigenschaften der Inputtexte der Prüfungsteile Hörverstehen (HV) und Leseverstehen (LV). Die Studie wurde von elf von derzeit 72 DSH-Standorten (FaDaF 2024: 2) unterstützt. Konkret unternimmt der vorliegende Beitrag den Versuch, folgende Forschungsfragen zu beantworten:
FF1: Wie unterscheiden sich Hör- und Lesetexte bei der DSH?
FF2: Wie unterscheiden sich DSH-Standorte hinsichtlich der Texteigenschaften ihrer Hör- und Lesetexte?
FF3: Welche Richtwerte können für DSH-Hörtexte und -Lesetexte empfohlen werden?
Einschränkend sei dieser Studie vorangestellt, dass mit den durchgeführten Analysen keine Aussage zur Qualität einzelner Texte oder gar Prüfungsteile getroffen werden kann. Eine belastbare Aussage dazu könnte nur unter einer Berücksichtigung der dazugehörigen Aufgaben und psychometrisch auswertbarer Ergebnisse mit hinlänglich großen Stichproben erfolgen, was für Anschlussstudien ein dringend zu schließendes Desiderat darstellt.
Gleichwohl können die Analysen dabei unterstützen, standortintern und standortübergreifend vergleichbare Inputmaterialien zu entwickeln und passgenaue Materialien zur Test- bzw. Studienvorbereitung zu gestalten, wobei studienvorbereitende Sprachkurse auf die sprachlichen Anforderungen im Studium vorbereiten sollen und nicht auf eine einzelne Sprachprüfung, wie etwa die DSH, welche nur einen kleinen Ausschnitt der sogenannten sprachlichen Studierfähigkeit überprüfen kann. Eine allzu dogmatische Ausrichtung von Lehr- und Lernmaterialien oder Kursangeboten an einzelnen HZST griffe von daher für eine bedarfsgerechte Sprachförderung zu kurz.
2 Hintergrund und Forschungsstand
2.1 Hör- und Lesekompetenz in Hochschulzugangssprachtests DaF
Hör- und Lesekompetenz sind für den Studienerfolg, insbesondere in der sensiblen Studieneingangsphase, essenzielle Elemente sprachlicher Studierfähigkeit (Holzknecht et al. 2022: 10–11; Möhring/Bärenfänger 2018; Wisniewski/Lenhard 2022: 72) und folgerichtig obligatorische Bestandteile aller akkreditierten HZST sowie der von diesen befreienden Sprachtests gemäß RO-DT (HRK/KMK 2019), wobei sich in der RO-DT wenig Konkretes zum zugrunde liegenden Konstrukt sprachlicher Studierfähigkeit findet (Appel et al. 2022: 371; Wisniewski/Lenhard/Möhring 2023: 61; Wollert/Zschill 2017: 4). Zudem ist die Frage nach der „Aussagekraft [der HZST] für die sprachliche Studierfähigkeit“ (Wisniewski/Lenhard/Möhring 2023: 434) und damit einhergehend den Studienerfolg internationaler Studierender insgesamt nicht abschließend beantwortet. Unterschiedlich wird die Bewertung der rezeptiven Fertigkeiten auch in den Testspezifikationen der verschiedenen HZST und deren Äquivalente operationalisiert.
Grundlage für die Bewertung der Lesekompetenz bei der DSH ist ein „wissenschaftsorientierter und studienbezogener“ Lesetext im Umfang von 4.500–6.000 Zeichen (zu „studienbezogen und wissenschaftsorientiert“ vgl. Appel et al. 2022: 374–376), dessen Verständnis keine Fachkenntnisse voraussetzt (Qualitätszirkel des FaDaF 2022: 39–42). Aufgaben zum Text sollen angemessen schwierig (B2–C1), transparent und eindeutig sein. Die genaue Anzahl und Aufteilung von geschlossenen, halboffenen und offenen Aufgaben ist nicht vorgegeben und obliegt der Gestaltung durch die jeweiligen DSH-Standorte. In dem im „Handbuch zur DSH-Erstellung und -Durchführung“ präsentierten Beispiel werden zehn Aufgaben vorgeschlagen (ebd.: 42–50). Für den DSH-Prüfungsteil Lesen wird eine Dauer von 60 min empfohlen, wobei das Leseverstehen zusammen mit dem Prüfungsteil „Wissenschaftssprachliche Strukturen“, der sich ebenfalls auf den Lesetext bezieht, durchgeführt wird. Für beide Prüfungsteile zusammen beträgt die Bearbeitungszeit 90 min (ebd.: 37).
Der Leseteil des papierbasierten TestDaF umfasst drei unterschiedlich anspruchsvolle Teile/Texte, wobei Teil 1 aus acht Kurztexten mit insgesamt 300–450 Wörtern besteht; Teil 2 ist ein populärwissenschaftlicher Bericht von 450–550 Wörtern und Teil 3 basiert auf einem wissenschaftlichen Text von 550–600 Wörtern (HRK/KMK 2004). Die Aufgabenformate sind mit zehn Zuordnungsitems für Teil 1, zehn Multiple-Choice-Items für Teil 2 und zehn Aufgaben zur Beurteilung von Aussagen (ja/nein/X) für Teil 3 (ebd.: 20) festgelegt. Die Bearbeitungsdauer beträgt 60 min (Norris/Drackert 2018). Ein Prüfungsteil zu sprachlichen Strukturen (wie in der DSH) ist im TestDaF nicht vorgesehen.
Auch bei telc C1 Hochschule besteht der Prüfungsteil Lesen aus drei Teilaufgaben/Texten, wobei dem Teil 1 ein populärwissenschaftlicher Text (Zeitschriftenartikel, Essay) von 400–500 Wörtern, Teil 2 ein studienbezogener Sachtext von 650–850 Wörtern und Teil 3 ein weiterer Sachtext im Umfang von 1.000–1.200 Wörtern zugrunde liegt. Die Aufgabenformate sind auch hier festgelegt: mit je sechs Zuordnungsaufgaben zu Teil 1 und 2 sowie elf Aufgaben zur Beurteilung von Aussagen (ja/nein/X) und einer Multiple-Choice-Aufgabe zu Teil 3. Die Bearbeitungszeit beträgt (inklusive Prüfungsteil „Sprachbausteine“) 90 min (telc 2015).
Im digitalen TestDaF erfolgt die Einschätzung der Lesekompetenz noch differenzierter mit sieben Teilaufgaben/Texten (vgl. dazu detailliert Kecker/Eckes 2022: 303–304). Die Bearbeitungsdauer beträgt ca. 55 min.
Ähnlich unterschiedlich sind die Testspezifikationen für die Teilprüfung Hören für die DSH (ein Hörtext), den papierbasierten TestDaF (drei Texte), den digitalen TestDaF (sieben Texte) und telc C1 Hochschule (drei Texte) mit dazugehörig variierenden Hörwiederholungen, Textlängen, Aufgabentypen, etwa integrierten Aufgaben beim digitalen TestDaF (Kecker/Eckes 2022: 294), Textsorten und Handlungsfeldern sowie Anzahl beteiligter Sprechender.
Aufgrund der sehr unterschiedlichen Operationalisierung des Konstrukts sprachliche Studierfähigkeit (Appel et al. 2022: 372) schon in Hinblick auf Länge, Gestaltung, Komplexität, Umfang und Anzahl der auszuwählenden Inputmaterialien bei den oben exemplarisch beschriebenen HZST unterbleibt in diesem Beitrag ein ohnehin nur eingeschränkt realisierbarer Vergleich der Inputmaterialien verschiedener Sprachtests zugunsten einer vertieften Betrachtung der Materialien unterschiedlicher Standorte in der DSH. Die Beschränkung auf die Analyse von Hör- und Lesetexten aus authentischen DSH-Prüfungen ist damit allein in der Diversität der HZST begründet. Gleichwohl wäre die Untersuchung der Oberflächenmerkmale der Inputtexte in standardisierten HZST im Zusammenspiel mit den Testaufgaben, Ergebnissen und der prognostischen Validität für Studienerfolg und Studienbiografien lohnenswert. Die Ausklammerung standardisierter HZST in diesem Beitrag soll also keinesfalls eine bereits zufriedenstellende Forschungslage suggerieren. Offen bleiben muss auch eine Diskussion, welche der in den verschiedenen HZST gewählten Operationalisierungen am zuverlässigsten funktioniert, etwa ob mehrere kürzere Hör- oder Lesetexte in einem HZST womöglich der Gefahr von Differential Item Functioning (Aryadoust/Goh/Kim 2011), also einer Benachteiligung einzelner Teilnehmendengruppen (Geschlecht, Alter, Herkunftsregion), besser begegnen als längere Einzeltexte oder ob Letztere dem Konstrukt sprachlicher Studierfähigkeit besser entsprechen als kürzere Texte. Während standardisierte HZST im Zuge der Qualitätssicherung äquivalente Testschwierigkeit und Funktionalität über verschiedene Testversionen gewährleisten (sollten) und sich hierzu regelmäßig externen Gutachten unterziehen, etwa im Zuge der Zertifizierung mit dem ALTE Q-Mark (Wisniewski et al. 2022: 63), sind Verfahren des Test Equating (Eckes 2003: 54–55) für die dezentralen DSH-Prüfungen nicht vorgesehen, also weder eine standortinterne Verankerung neuer DSH-Versionen mit der objektiven Testschwierigkeit von Vorgängerversionen der DSH noch eine standortübergreifende. Unter diesem Gesichtspunkt erscheint eine Betrachtung der Texteigenschaften, welche eine mit relativ geringem Aufwand sowohl standortintern als auch -übergreifend kontrollierbare Facette der Testschwierigkeit und -qualität darstellen können, besonders lohnenswert.
2.2 Texteigenschaften als Facette von Hör- und Lesetests
Die Qualität und die Angemessenheit einer Sprachtestaufgabe sind stets von zahlreichen Variablen abhängig, etwa den Themen, der Vertrautheit der Teilnehmenden mit Formaten, dem Vor- und Weltwissen von Teilnehmendengruppen, Typ der Items, der Qualität und Komplexität der Items (Krekeler 2005: 248–254; Westbrook 2019: 13–33), Art der Bewertung (automatisch/menschlich) und im Falle menschlicher Bewertungen der Qualität der Bewertendenschulung (ALTE 2012; EALTA 2016; Grein 2021; Karges 2023). Für Hör- und Lesetests spielen die Eigenschaften der entsprechenden Inputtexte zweifellos eine entscheidende Rolle, wobei ein für einen Testzweck gut geeigneter Hör- oder Lesetext keineswegs Garant für eine gute Testaufgabe oder in Summe einen guten Test ist. Alderson fasst dies in seinem Referenzwerk zur Messung von Lesekompetenz treffend zusammen: „lt is clearly possible to ask easy questions of difficult texts, and difficult questions of easy texts. A reading score may be high or low because of item difficulty rather than text difficulty and vice versa“ (Alderson 2000: 85–86). Textvorgaben für Sprachtests umfassen häufig Angaben zu Themenbereichen, Textsorten, kommunikativen Situationen, Länge, Struktur, Grad der Authentizität (ebd.: 60–68) und häufig auch unscharfe Angaben zu GER-Niveau (Althaus 2018) und Schwierigkeit. Als messbare Variable der HZST-Inputtexte wird häufig nur die Textlänge angegeben (siehe Kap. 2.1).
In den letzten Jahren wurden zahlreiche computerlinguistische Verfahren entwickelt, welche die (subjektive) Einschätzung von Expertinnen und Experten im Bereich der Testentwicklung zur Eignung und Validität von Hör- und Lesetexten in Sprachtests empirisch unterstützen und ergänzen können (Alderson 2000: 68–78). Dazu gehören der systematische Abgleich mit Wortschatzlisten, etwa zur Worthäufigkeit oder zu akademischen Wortschatzinventaren, Maße zur lexikalischen Komplexität und Diversität, zur syntaktischen Komplexität oder in Kombination verschiedener, mithin auch relativ grober syntaktischer und lexikalischer Maße zur Komplexität bzw. Lesbarkeit (Readability) im Allgemeinen (Green/Ünaldi/Weir 2010: 192–196; Hacking/Rubio/Tschirner 2019; Holzknecht et al. 2022: 11–12; Krekeler 2005: 240–247). Neben der Entwicklung von Sprachtests spielen diese Maße und Analysen zunehmend eine Rolle bei der Gestaltung von Lehr- und Lernmaterialien sowie der Auswahl von für verschiedene Sprachkompetenzniveaus passenden Texten (van der Knaap 2018; Vázquez-Ingelmo et al. 2023).
Gleichwohl in diesem Beitrag computerlinguistische Maße sowohl auf Hör- wie auch auf Lesetexte angewendet werden, sind diese fertigkeitenspezifisch einzuordnen und keinesfalls 1:1 vergleichbar (Li et al. 2024). Außerdem ist ihre Wirksamkeit auf Sprachtests von unterschiedlichen Co-Variablen abhängig. Zum einen sind Eigenschaften gesprochener Sprache regelmäßig verschieden von konzeptionell und medial schriftlichen Texten (McLean/Matthews/Milliner 2024; Oesterreicher/Koch 2016; Schwitalla 2012), was sich zum Beispiel in einer kürzeren Satzlänge, geringeren Informationsdichte und höheren Redundanz bei Hörtexten ausdrückt. Zudem kann man bei Lesetexten schwierige Passagen (im Rahmen der vorgegebenen Zeit) beliebig oft wiederholen, während man Hörtexte in HZST in der Regel nur ein- oder zweimal hört (vgl. ausführlich zur Rolle der Hörwiederholungen in High-Stakes-Tests Grotjahn 2012; Holzknecht/Harding 2024). Das Verständnis gesprochener Texte ist zudem maßgeblich von phonetisch-artikulatorischen Merkmalen wie Lautstärke, Sprechgeschwindigkeit, Betonung, Pausen, Akzent, Elisionen etc. abhängig (Westbrook 2019: 12–29). Die in das Verstehen involvierten kognitiven Prozesse sind beim Hören und Lesen demnach verschieden und nur indirekt beobachtbar. Die Aussagekraft und Generalisierbarkeit von rein text- bzw. transkriptbasierten Studien – wie der vorliegenden – dürfte dadurch für Lesetexte ungleich höher sein. Da die DSH-Hörtexte obligatorisch transkribiert vorliegen, jedoch in der Regel vorgetragen und nicht aufgezeichnet werden (Qualitätszirkel des FaDaF 2022: 20–21), müssen die oben genannten Merkmale als in zukünftigen Studien zu berücksichtigendes Desiderat offenbleiben.
Die bislang mehrheitlich für Kontexte für Englisch als Fremdsprache (EFL) durchgeführten Studien beschäftigen sich neben einer deskriptiven Beschreibung und Einschätzung der Texteigenschaften der Inputmaterialien insbesondere mit der Vergleichbarkeit von Testversionen und der Ähnlichkeit von Testmaterialien zu authentischen, den Testkonstrukten entsprechenden Texten (Evidenz und Validität), der empirischen Ermittlung von Lernzielen und Lerninhalten sowie dem Einfluss von Texteigenschaften auf die Aufgabenqualität und -schwierigkeit.
In einer mit N = 77 Englischlernenden durchgeführten Studie zur Aufgabenschwierigkeit in einem C1-Hörtest für EFL stellen Révész und Brunfaut (2013) signifikante Effekte von lexikalischen Eigenschaften, insbesondere der Dichte hochfrequenter (Funktions-)Wörter und des akademischen Wortschatzes, auf die Aufgabenschwierigkeit fest, während phonologische und syntaktische Eigenschaften eine untergeordnete Rolle spielen.
Holzknecht et al. (2022) beschäftigen sich in einer innovativen Studie mit der Schieflage zwischen HZST für das Englische, der Lesekompetenz von „English as a medium of instruction“ (EMI) – Studierenden und den Leseanforderungen an EMI-Universitäten in drei verschiedenen L2-Kontexten in Europa und Afrika. Auch sie identifizieren Wortschatz und hierbei insbesondere Worthäufigkeit sowie Satzlänge als entscheidende Schwierigkeitsparameter für Lesetexte im Hochschulkontext (ebd.: 55–56).
Auch für Hör-Items bei einem international eingesetzten Englischtest stellen Loukina et al. (2016) fest, dass empirisch ermittelte Maße zur Textkomplexität (bei Hörtexten und den dazugehörigen Aufgaben) maßgeblich zur Erklärung von Itemschwierigkeit beitragen, wobei lexikalische Maße unter Berücksichtigung der Worthäufigkeit besonders stark zur Varianzaufklärung beitrugen. Sie stellen weiterhin fest, dass parallel durchgeführte Schwierigkeitseinschätzungen von Testexpertinnen und -experten im Vergleich zu computerlinguistisch ermittelten Komplexitätsparametern weit weniger zuverlässig ausfielen (ebd.: 3251).
Die lexikalischen Eigenschaften von Hör- und Lesetexten in schulischen High-Stakes-Tests für die Sprachen Französisch, Deutsch und Spanisch in England untersuchen Dudley und Marsden (2024). Sie finden unerwartet hohe und nicht dem Lehrplan entsprechende Wortschatzanforderungen in den Tests, die als mögliche Ursache für ein mithin schlechtes Abschneiden der Schülerinnen und Schüler benannt werden. Sie plädieren für eine stärkere Verlinkung von Unterricht und Tests, wobei Wortschatzstudien einen wertvollen Beitrag leisten können (ebd.: 23).
Mit einem Vergleich von Texten in HZST und den Leseanforderungen in der Studieneingangsphase beschäftigen sich Green, Ünaldi und Weir (2010) (für den englischen Hochschulkontext) sowie Möhring und Bärenfänger (2018) (für das Deutsche). Beide Studien stellen heraus, dass die empirische Erfassung von Texteigenschaften einen maßgeblichen Beitrag zur Validität von HZST leistet und zu einer Standardisierung beitragen kann.
Lexikalische und syntaktische Texteigenschaften erwiesen sich insgesamt als eine belastbare Facette der Schwierigkeit von Hör- und Lesetests, obgleich sie für eine vollständige Testvalidierung stets in der Interaktion mit Aufgaben und Testteilnehmenden betrachtet werden müssen.
3 Studie und Methoden
3.1 Studie
Der Beitrag beschäftigt sich mit authentischen Prüfungstexten der Prüfungsteile Hören und Lesen von DSH-Standorten (Kap. 3.2). Die Texte wurden mit drei verschiedenen Analysetools (Kap 3.3) hinsichtlich verschiedener Texteigenschaften untersucht, wobei der Schwerpunkt auf lexikalischen Variablen lag. Im Anschluss werden die Ergebnisse vergleichend für die Fertigkeiten Hören und Lesen sowie die beteiligten DSH-Standorte dargestellt (Kap. 4).
3.2 Datenerhebung und -aufbereitung
Die Studie war auf die Unterstützung von Standorten (Hochschulen und Studienkollegs), welche die DSH entwickeln und anbieten, angewiesen. Für die Akquise wurden eine Homepage mit Informationen zum Forschungsvorhaben sowie eine sichere Cloud-Lösung für den Upload von Prüfungstexten eingerichtet. Standorte wurden gebeten, nach Möglichkeit sechs aktuelle Texte pro Fertigkeit (Hören/Lesen) einzureichen. Die Bitte um Teilnahme erging über zahlreiche Kanäle, insbesondere im Zuge der DSH-Forschungsinitiative (Domes/Appel 2022).
Teilnehmenden Standorten wurde zugesichert, dass sie anonymisiert und die zum Teil noch zu Prüfungszwecken genutzten Texte nicht an Dritte weitergegeben oder veröffentlicht werden. Auch das Jahr der Text- bzw. Testerstellung und des Einsatzes in DSH-Prüfungsdurchläufen wurde zur Wahrung berechtigter Interessen der teilnehmenden DSH-Standorte nicht erfasst. Da sich die Angaben zur „Auswahl und Bearbeitung der Vorlagen“, also der Hör- und Lesetexte, im aktuellen DSH-Handbuch aus dem Jahr 2022 (Qualitätszirkel des FaDaF 2022: 20, 39) im Zuge der Überarbeitung (Appel et al. 2022: 378) seit der Version des Handbuchs von 2012 jedoch kaum verändert haben, kann diese Variable vernachlässigt werden.
Von derzeit 72 registrierten DSH-Standorten (FaDaF 2024) beteiligten sich elf Standorte (~ 15 %) aus sieben Bundesländern mit insgesamt 113 Texten (Hören N = 57; Lesen N = 56). Weiterhin wurden die im DSH-Handbuch vorgeschlagenen und als für das Testkonstrukt illustrativ geltenden (Appel et al. 2022: 380) Beispieltexte für die Prüfungsteile HV und LV (je N = 1) in der Untersuchung berücksichtigt, wodurch insgesamt 115 Texte mit einem Gesamtumfang von ca. 100.000 laufenden Wörtern (Token) einbezogen werden konnten (Tabelle 1).
Die Texte wurden von den Standorten in verschiedenen Formaten bereitgestellt. Für die Analyse mussten sie bereinigt und maschinenlesbar aufbereitet werden, wozu unter anderem das Entfernen von Absatz- und Zeilenmarkierungen sowie Silbentrennungen und die Konvertierung in das TXT-Format gehörten. Einige Standorte stellten die Texte zusammen mit den Aufgaben zur Verfügung, die hier unberücksichtigt bleiben und ebenso gelöscht wurden.
DSH-Prüfungstexte Hörverstehen und Leseverstehen
| Ort | Fertigkeit | AnzahlTexte | MittelwertAnzahl Token | Std.-abw. |
Min |
Max |
Token gesamt | |||||||||
| DSH | HV | 1 | 970 | – | – | – | 970 | |||||||||
| Sample | LV | 1 | 763 | – | – | – | 763 | |||||||||
| Gesamt | 2 | |||||||||||||||
| Ort1 | HV | 6 | 995 | 45.3 | 939 | 1.059 | 5.970 | |||||||||
| LV | 6 | 810 | 33.3 | 751 | 838 | 4.861 | ||||||||||
| Gesamt | 12 | |||||||||||||||
| Ort2 | HV | 6 | 933 | 46.7 | 874 | 1.001 | 5.598 | |||||||||
| LV | 6 | 729 | 37.0 | 691 | 777 | 4.374 | ||||||||||
| Gesamt | 12 | |||||||||||||||
| Ort3 | HV | 6 | 790 | 51.2 | 719 | 865 | 4.739 | |||||||||
| LV | 6 | 827 | 68.6 | 719 | 887 | 4.964 | ||||||||||
| Gesamt | 12 | |||||||||||||||
| Ort4 | HV | 6 | 834 | 80.7 | 756 | 951 | 5.004 | |||||||||
| LV | 6 | 763 | 52.8 | 688 | 821 | 4.575 | ||||||||||
| Gesamt | 12 | |||||||||||||||
| Ort5 | HV | 5 | 905 | 76.7 | 820 | 1.006 | 4.523 | |||||||||
| LV | 5 | 774 | 73.7 | 667 | 858 | 3.868 | ||||||||||
| Gesamt | 10 | |||||||||||||||
| Ort6 | HV | 5 | 934 | 55.2 | 861 | 999 | 4.668 | |||||||||
| LV | 5 | 790 | 43.3 | 733 | 838 | 3.949 | ||||||||||
| Gesamt | 10 | |||||||||||||||
| Ort7 | HV | 6 | 944 | 55.8 | 871 | 1.013 | 5.663 | |||||||||
| LV | 6 | 795 | 31.4 | 746 | 832 | 4.767 | ||||||||||
| Gesamt | 12 | |||||||||||||||
| Ort8 | HV | 6 | 934 | 36.6 | 885 | 976 | 5.603 | |||||||||
| LV | 6 | 723 | 18.2 | 694 | 746 | 4.340 | ||||||||||
| Gesamt | 12 | |||||||||||||||
| Ort9 | HV | 6 | 1.342 | 116.7 | 1.190 | 1.454 | 8.050 | |||||||||
| LV | 6 | 915 | 75.1 | 825 | 1.005 | 5.490 | ||||||||||
| Gesamt | 12 | |||||||||||||||
| Ort10 | HV | 3 | 923 | 26.8 | 893 | 945 | 2.768 | |||||||||
| LV | 3 | 715 | 21.0 | 691 | 731 | 2.144 | ||||||||||
| Gesamt | 6 | |||||||||||||||
| Ort11 | HV | 2 | 977 | 24.0 | 960 | 994 | 1.954 | |||||||||
| LV | 1 | 754 | – | – | – | 754 | ||||||||||
| Gesamt | 3 | |||||||||||||||
| Total | HV | 58 | 957 | 155.5 | 719 | 1.454 | 55.510 | |||||||||
| LV | 57 | 787 | 72.3 | 667 | 1.005 | 44.849 | ||||||||||
| Gesamt | 115 | 100.359 | ||||||||||||||
3.3 Instrumente
Für die Textanalysen wurden drei verschiedene Tools eingesetzt, die kostenfrei und online (browserbasiert) von wissenschaftlich etablierten Institutionen angeboten werden. Es wurde darauf geachtet, dass die Tools auch ohne computerlinguistische Vorkenntnisse, etwa zur Replikation der Analysen für weitere Prüfungstexte an den DSH-Standorten, bedient werden können. Im Folgenden werden der LIX-Rechner (Lenhard/Lenhard 2014–2022), der MultilingProfiler (Finlayson/Marsden/Anthony 2023) sowie die Common Text Analysis Platform CTAP (Chen/Meurers 2016) kurz vorgestellt. Statistische Analysen wurden durchgeführt mit jamovi und SPSS.
Die genutzten Werkzeuge können wertvolle Einblicke in die lexikalischen und strukturellen Aspekte der DSH-Texte bieten. Gleichwohl weist jede dieser Methoden spezifische Einschränkungen auf und keiner der ermittelten Werte kann per se als alleinstehendes Gütekriterium gelten. So bezieht der LIX-Rechner zwar die Wortlänge, jedoch nicht die Worthäufigkeit, syntaktische Vielfalt und semantische Tiefe ein. Auch die Einordnung des in einem Text enthaltenen Wortschatzes in Häufigkeitsbereiche mit dem MultilingProfiler umfasst nur einen isolierten Parameter. Die Forschungslage (vgl. Kap. 2.2) deutet jedoch stark auf einen Zusammenhang quantitativ messbarer Textoberflächenmerkmale mit Text- und Testschwierigkeit hin. Sollte sich diese Annahme in weiterführenden Studien bestätigen, wäre es äußerst wünschenswert, wenn DSH-Standorte nicht auf verschiedene Tools, sondern auf ein für die spezifischen Anforderungen der HZST-Erstellung zugeschnittenes Werkzeug mit einer gut beforschten Auswahl linguistischer Maße zurückgreifen könnten.
3.3.1 LIX-Rechner
Es gibt eine Reihe von Lesbarkeitsindizes, die aus verschiedenen Maßen einen Wert zur mutmaßlichen Lesbarkeit eines Texts aggregieren, wie etwa den Flesch Index oder den Gunning Fog Index (Krekeler 2005: 244–247); für einen aktuellen Überblick siehe Başaran (2023). Eine explizit auch für das Deutsche entwickelte Methode, den Lesbarkeitsindex zu ermitteln, ist LIX (Lesbarkeitsindex) nach Björnsson (1968). Die LIX-Formel stellt ein für die pädagogische Praxis hinreichend genaues Instrument zur Einschätzung der Textschwierigkeit dar (Nickel 2011: 30). Die Formel basiert auf zwei Variablen: der durchschnittlichen Satzlänge und dem prozentualen Anteil von langen Wörtern (mit mehr als sechs Buchstaben) (Köster 2005: 37). Der LIX-Index (siehe Abbildung 1) liegt zwischen 20 (einfach), etwa im Bereich der Kinder- und Jugendliteratur (KJL), und 70 (komplexer Fachtext).

Lesbarkeitsindex verschiedener Textsorten LIX (aus Köster 2005: 37)
Der für die vorliegende Studie genutzte LIX-Rechner wird von Lenhard/Lenhard (2014–2022) auf der Homepage https://www.psychometrica.de/lix.html bereitgestellt. Zu analysierende Texte können in ein dafür vorgesehenes Textfeld eingefügt oder eingetippt werden. Neben dem LIX-Wert werden die Anzahl der Wörter, die Anzahl der Sätze, die durchschnittliche Satzlänge, der Anteil langer Wörter und eine verbale Schwierigkeitseinschätzung präsentiert. Ebenso wird im Begleittext der Ressource auf Einschränkungen des LIX und technische Besonderheiten hingewiesen. Für diese Studie wurde die Option „Zeilenumbrüche als Satzende interpretieren“ deaktiviert (siehe Abbildung 2).
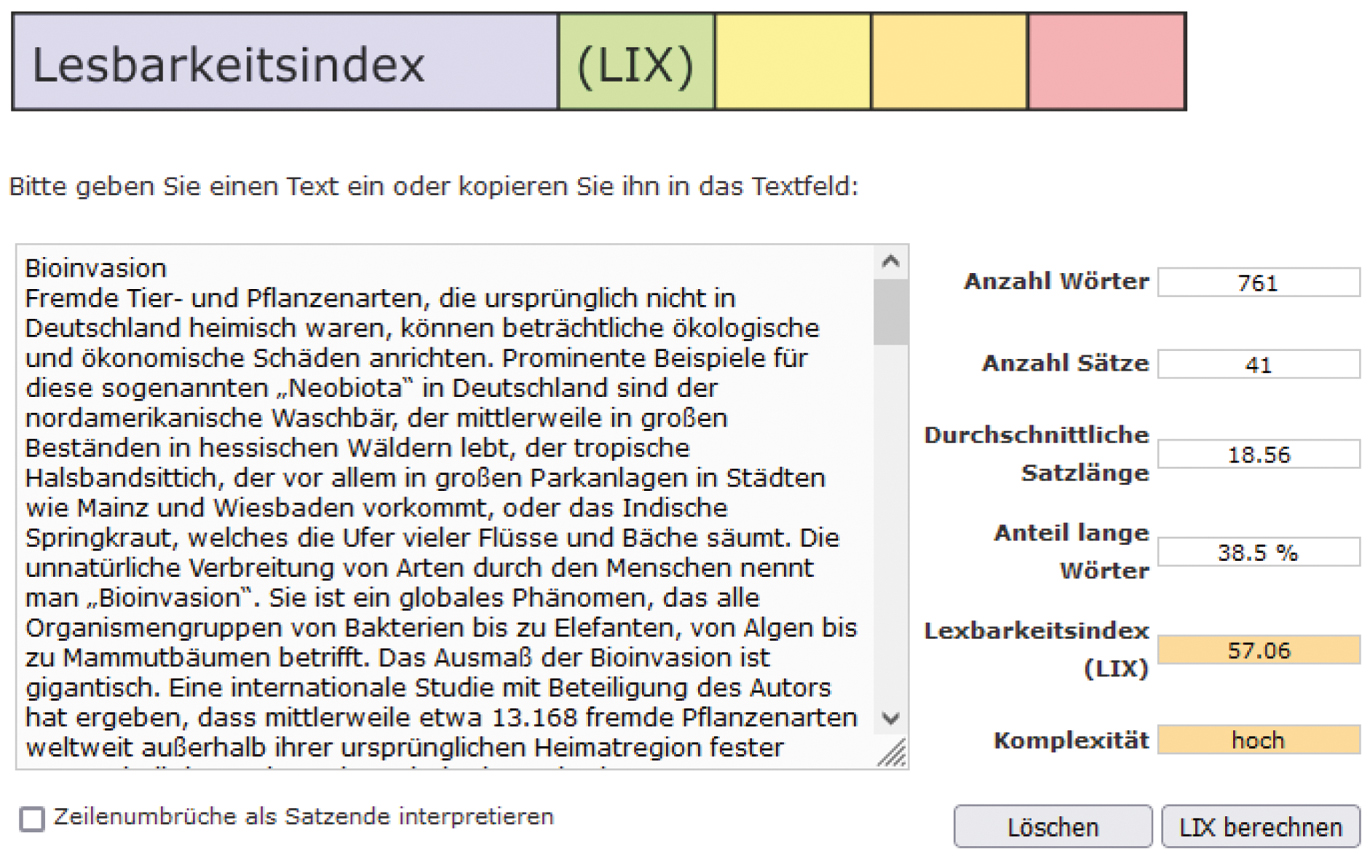
DSH-Beispieltext Lesen „Bioinvasion“ im LIX-Rechner
3.3.2 MultilingProfiler
Korpusbasierte Worthäufigkeitslisten stellen ein umfangreich beforschtes Instrument dar, insbesondere im Bereich der Leseforschung (Larson 2017; Laufer 2020; Tschirner 2019), aber auch für die Beschreibung und Erforschung der Hörkompetenz (Li et al. 2024; McLean/Matthews/Milliner 2024). Sie werden, wenngleich nicht unkritisch hinterfragt (Bauer/Doetjes 2023: 316), zunehmend in Ergänzung zu und Überprüfung von intuitiv ermittelten, kommunikativ-pragmatischen Lernwortschatzinventaren (Kilian 2021: 74–88; Wallner/Möhring 2013) genutzt und tragen maßgeblich zur Bestimmung von objektiven Wortschatzerwartungen für die Niveaustufen des Gemeinsamen Europäischen Referenzrahmens für Sprachen (Europarat 2001 und 2018) und darauf bezogener Sprachtests bei (Chen et al. 2023; Li et al. 2024; Milton/Alexiou 2009; Tschirner 2019). Auch für den Bereich der sprachlichen Studierfähigkeit und des Studienerfolgs internationaler Studierender erwiesen sich häufigkeitsbasierte Wortschatzbestände als aussagekräftige Variablen (Li et al. 2024; Milton/Treffers-Daller 2013; Möhring 2022: 388–389, 401–403). Der MultilingProfiler 3.0 (Finlayson/Marsden/Anthony 2022) ermöglicht unter https://multilingprofiler.net/ häufigkeitsbasierte Textdeckungsuntersuchungen für Französisch, Deutsch und Spanisch. Für alle Sprachen besteht die Möglichkeit zum Abgleich von Texten mit den häufigsten 1.000, 2.000, 3.000, 4.000 und 5.000 Wortfamilien sowie einer Reihe curriculabasierter Speziallisten und zur Ergänzung durch eigene Wortlisten (Finlayson/Marsden/Anthony 2023: 2). Die Worthäufigkeitslisten für das Deutsche basieren auf dem Häufigkeitswörterbuch von Tschirner/Möhring (2019). Trotz einiger – gut dokumentierter – Einschränkungen, etwa der (bislang) nicht implementierten Wortartenannotation (POS-Tagging) oder fehlender Disambiguierung (Finlayson/Marsden/Anthony 2023: 17–18), bietet das Tool im Vergleich zu bislang verfügbaren Tools, wie etwa dem AntWordProfiler (Anthony 2014), eine besonders nutzerfreundliche Möglichkeit, Textdeckungsuntersuchungen für deutsche Texte durchzuführen (Dudley/Marsden 2024: 9–10). Eigene Texte können in das „Profile Window“ eingefügt werden; für diese Studie wurden die Einstellungen „List type: Frequency List“, „Language: German“, „Level: Top 5.000 Words“ und „Remove Inflected Forms: All forms selected“ gewählt. Nach dem Einfügen eines Texts wird dieser durch Betätigung des „Profile Text“-Feldes analysiert, nicht in der gewählten Liste enthaltene Wortformen werden farbig markiert (siehe Abbildung 3). „Download Stats (.csv)“ ermöglicht das Herunterladen der detaillierten Textdeckungswerte für die fünf Häufigkeitsbänder.
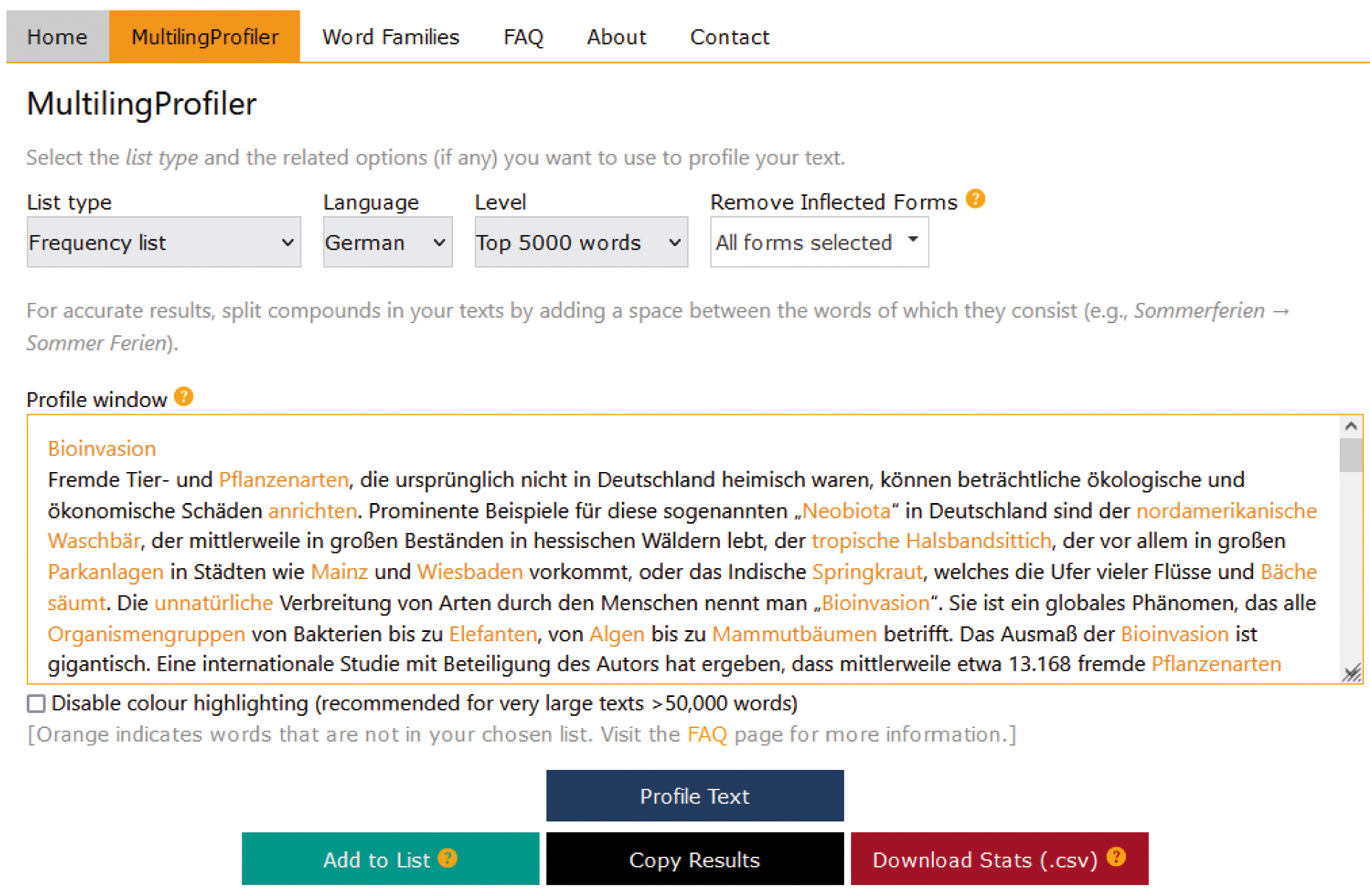
DSH-Beispieltext Lesen „Bioinvasion“ im MultilingProfiler
3.3.3 Common Text Analysis Platform CTAP
Etwas weniger intuitiv und erst nach (kostenfreier) Anmeldung nutzbar ist CTAP unter http://ctapweb.com (Chen/Meurers 2016). Die Plattform bietet die Möglichkeit, eigene Texte und Korpora in Bezug auf bis zu 1.102 linguistische Maße, davon ca. 500 für Deutsch, zu untersuchen. Eigene Texte müssen zunächst über den „Corpus Manager“ importiert, die gewünschten Maße im „Feature Selector“ ausgewählt und die Analyse im Anschluss im „Analysis Generator“ durchgeführt werden, wobei hier auf die Sprachauswahl „German“ zu achten ist. Nach Abschluss der Analyse sind die Ergebnisse im Bereich „Results“ abrufbar oder auch direkt auf der Plattform visualisierbar. Die vorliegende Studie beschränkte sich bei der Auswahl auf wenige, die lexikalische Vielfalt (Lexical Richness) betreffende Maße.
Auswahl linguistischer Maße in CTAP
Lexikalische Vielfalt misst den Grad der Wortschatzredundanz durch einen Vergleich der in einem Text enthaltenen, laufenden Wortformen (Token) zu den verschiedenen Wortformen (Types). Da dieser Quotient stark von der Textlänge abhängt, werden für den Vergleich unterschiedlich langer Texte standardisierte Type-Token-Maße genutzt (Treffers-Daller/Parslow/Williams 2018). Die für diese Studie aus den in CTAP verfügbaren Features gewählten Maße setzen sich wie folgt zusammen: Lexical Richness Type Token Ratio (Segments of Length 50) (TTR SoL50) berechnet jeweils den Quotienten aus Types/Token für Texteinheiten im Umfang von 50 Token und errechnet den Mittelwert der Einzelwerte. Die Lexical Richness Type Token Ratio (Corrected TTR Words) (CTTR) berechnet das Typ-Token-Verhältnis für Wörter (ohne Interpunktion und Zahlen) eines Textes mit der Formel CTTR = Anzahl Types/sqrt(2*Anzahl der Token) (CTAP à Feature Selector à Feature Details).
4 Analysen und Ergebnisse
4.1 Fertigkeit und Lesbarkeit (LIX)
Mehrheitlich ergab die Analyse der Hör- und Lesetexte mit LIX eine mittlere Komplexität. Vor allem Lesetexte wiesen zum Teil auch eine höhere Komplexität auf, während etwa ein Viertel der Hörtexte eine niedrige Komplexität zeigten (siehe Tabelle 2).
Komplexität nach LIX pro Fertigkeit/Anzahl der Texte
| Fertigkeit | ||||
| Komplexität | HV | LV | Gesamt | |
| sehr hoch | 0 | 2 | 2 | |
| hoch | 7 | 19 | 26 | |
| mittel | 38 | 36 | 74 | |
| niedrig | 13 | 0 | 13 | |
| Gesamt | 58 | 57 | 115 | |
Die im Handbuch zur DSH (Qualitätszirkel des FaDaF 2022) und auf der dazugehörigen Homepage https://www.dsh-fadaf.de/was-ist-die-dsh/ vorgeschlagenen Texte aus den DSH-Beispielprüfungen lagen für Lesen: Text „Bioinvasion“ mit LIX = 57.06 [hoch] und für Hören: Text „Wege zwischen Himmel und Erde“ mit LIX = 44.9 [niedrig] eher in den Randbereichen der untersuchten Stichprobe (siehe Tabelle 2 und 3).
LIX, Anteil lange Wörter und durchschnittliche Satzlänge nach Fertigkeit
| Fertigkeit | N | Mittelwert | Std.-abw. | Min | Max | |
| LIX | HV | 58 | 49.22 | 4.74 | 40.31 | 59.26 |
| LV | 57 | 53.60 | 4.72 | 45.46 | 67.35 | |
| Anteil lange Wörter [%] | HV | 58 | 34.29 | 3.67 | 28.30 | 42.60 |
| LV | 57 | 36.06 | 3.06 | 27.90 | 42.60 | |
| Ø Satzlänge | HV | 58 | 14.93 | 2.21 | 10.59 | 20.51 |
| LV | 57 | 17.54 | 2.90 | 12.56 | 25.65 |
Im Folgenden wird untersucht, inwieweit sich die mit dem LIX-Rechner ermittelten Werte für die Variablen LIX, Anteil lange Wörter und durchschnittliche Satzlänge zwischen den Texten zur Überprüfung der Fertigkeiten Hör- und Leseverstehen unterscheiden. Eine multivariate Varianzanalyse (MANOVA) zeigte einen signifikanten Unterschied zwischen den Hör- und Lesetexten für die Variablen LIX, Anteil lange Wörter und durchschnittliche Satzlänge als abhängige Variablen: F(3, 111) = 10.04, p < .001. Post hoc wurde für jede abhängige Variable eine Varianzanalyse (ANOVA) durchgeführt. Es zeigte sich für alle Variablen ein signifikanter Unterschied zwischen Hör- und Lesetexten (siehe Tabelle 4).
Post-hoc-ANOVAs zum Unterschied Hören vs. Lesen bei LIX, Wort- und Satzlänge
| F | df1 | df2 | p | partielles η2 | |
| LIX | 24.69 | 1 | 113 | < .001 | 0.18 |
| Anteil lange Wörter | 7.87 | 1 | 113 | 0.006 | 0.07 |
| Durchschnittliche Satzlänge | 29.65 | 1 | 113 | < .001 | 0.21 |
4.2 Fertigkeit und Wortfrequenz (MultilingProfiler)
Die mit den häufigsten 1.000, 3.000 und 5.000 Wörtern erreichte Textdeckung lag bei den Hörtexten im Durchschnitt über der Schnittmenge der Lesetexte (siehe Tabelle 5).
Textdeckung der Hör- und Lesetexte mit den häufigsten 1.000, 3.000 und 5.000 Wörtern des Deutschen
| Textdeckung | % bis 1.000 | % bis 3.000 | % bis 5.000 | ||||
| HV | LV | HV | LV | HV | LV | ||
| N | 58 | 57 | 58 | 57 | 58 | 57 | |
| Mittelwert | 72.27 | 68.15 | 83.61 | 80.38 | 87.90 | 85.00 | |
| Std.-abw. | 3.12 | 3.09 | 2.59 | 3.17 | 2.55 | 2.97 | |
| Min | 64.00 | 61.70 | 78.30 | 74.20 | 82.10 | 78.20 | |
| Max | 79.50 | 77.10 | 88.80 | 87.60 | 92.50 | 90.50 | |
Exemplarisch für die häufigsten 3.000 Wörter des Deutschen illustriert Abbildung 5 die bei den 58 Hörtexten größere Schnittmenge mit hochfrequentem Wortschatz. Die Textdeckungen der DSH-Beispieltexte betragen mit den 3.000 häufigsten Wörtern für Lesen 81,3 % und für Hören 87,6 %, für die 5.000 häufigsten Wörter für Lesen 85,9 % und für Hören 90,8 %.
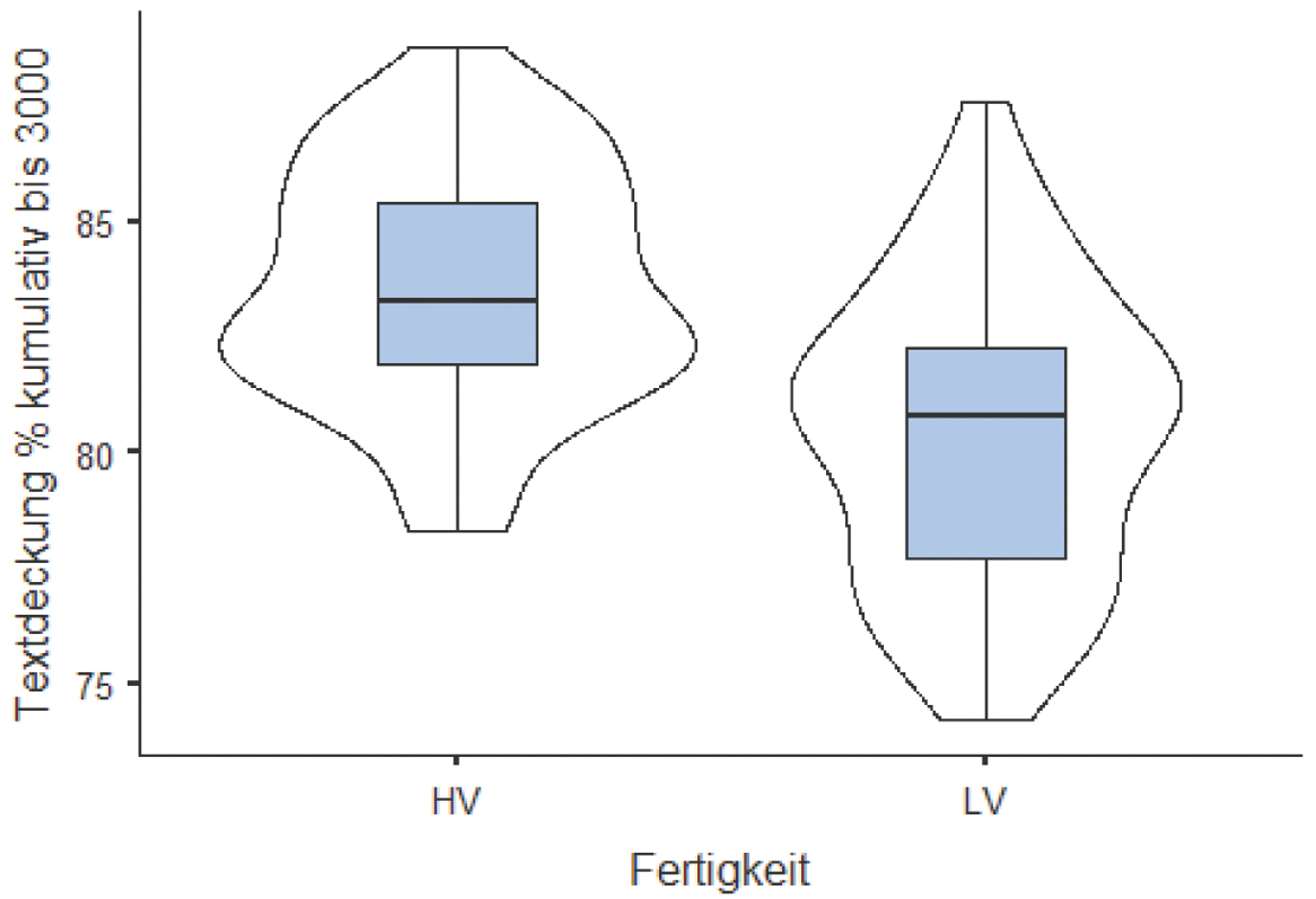
Textdeckung der Hör- und Lesetexte mit den häufigsten 3.000 Wörtern des Deutschen
Der Unterschied zwischen den Fertigkeiten Hören und Lesen zeigte sich in einer MANOVA für die abhängigen Variablen für die Textdeckung mit den häufigsten 1.000, 3.000 und 5.000 deutschen Wörtern mit F(3, 111) = 16.9, p < .001 signifikant. Post hoc wurde für die drei Häufigkeitsstufen als abhängige Variablen eine Varianzanalyse (ANOVA) durchgeführt. Es zeigte sich für alle Variablen ein signifikanter Unterschied zwischen Hör- und Lesetexten (siehe Tabelle 6).
Post-hoc-ANOVAs zum Unterschied Hören vs. Lesen bei der Textdeckung
| F | df1 | df2 | p | partielles η2 | |
| Textdeckung % bis 1.000 | 50.7 | 1 | 113 | < .001 | 0.31 |
| Textdeckung % bis 3.000 | 35.9 | 1 | 113 | < .001 | 0.24 |
| Textdeckung % bis 5.000 | 31.4 | 1 | 113 | < .001 | 0.22 |
4.3 Fertigkeit, Wortlänge und lexikalische Vielfalt (Lexical Richness, CTAP)
Die mit CTAP ermittelte durchschnittliche Wortlänge liegt für die Hörtexte (M = 5.94) unter, für die Lesetexte (M = 6.15) knapp über sechs und damit der Schwelle, die etwa bei LIX als „langes Wort“ benannt wird. TTR SoL50 und CTTR liegen ebenfalls je für die Hörtexte etwas niedriger als bei den Lesetexten (siehe Tabelle 7).
Token, Types, Wortlänge und lexikalische Vielfalt
| Fertigkeit | Number of Word Types | Number of Tokens | Mean Token Length in Letters | TTR SoL50 | CTTR | |
| N | HV | 58 | 58 | 58 | 58 | 58 |
| LV | 57 | 57 | 57 | 57 | 57 | |
| Mittelwert | HV | 460 | 964 | 5.94 | 0.862 | 10.4 |
| LV | 430 | 792 | 6.15 | 0.883 | 10.7 | |
| Std.-abw. | HV | 56.2 | 159 | 0.324 | 0.0231 | 0.862 |
| LV | 38.0 | 73.4 | 0.273 | 0.0173 | 0.652 | |
| Minimum | HV | 361 | 721 | 5.40 | 0.790 | 8.34 |
| LV | 357 | 674 | 5.63 | 0.820 | 8.21 | |
| Maximum | HV | 623 | 1470 | 6.82 | 0.910 | 12.2 |
| LV | 528 | 1007 | 6.76 | 0.920 | 11.8 |
Eine multivariate Varianzanalyse (MANOVA) zeigte einen signifikanten Unterschied zwischen den Hör- und Lesetexten für die Variablen durchschnittliche Wortlänge, TTR SoL50 und CTTR als abhängige Variablen: F(3, 111) = 12.9, p < .001. Post hoc wurde für jede abhängige Variable eine Varianzanalyse (ANOVA) durchgeführt. Es zeigte sich für alle Variablen ein signifikanter Unterschied (p < .05) zwischen Hör- und Lesetexten (siehe Tabelle 8).
Post-hoc-ANOVAs zum Unterschied Hören vs. Lesen bei Wortlänge und lexikalischer Vielfalt
| F | df1 | df2 | p | partielles η2 | |
| Mean Token Length in Letters | 13.18 | 1 | 113 | < .001 | 0.10 |
| TTR SoL50 | 31.58 | 1 | 113 | < .001 | 0.22 |
| CTTR | 4.72 | 1 | 113 | 0.032 | 0.04 |
4.4 Texteigenschaften und DSH-Standorte
In die statistische Analyse zu Unterschieden zwischen den DSH-Standorten wurden nur diejenigen (Orte 1–9) einbezogen, die mindestens fünf Texte je Fertigkeit eingereicht haben. Das DSH-Sample sowie die Orte 10 und 11 wurden wegen der geringen Textzahl und damit einhergehend ungleicher/fehlender Varianz ausgeschlossen, werden aber in der grafischen Darstellung mit präsentiert (siehe Abbildung 6 und 7). Im Folgenden werden die Texte für die Fertigkeiten Lesen und Hören separat analysiert.
4.4.1 Lesetexte DSH-Standorte
Es wurde eine MANOVA durchgeführt, um festzustellen, ob es einen Unterschied zwischen DSH-Standorten bei den neun in 4.1–4.3 beschriebenen Texteigenschaften gibt. Es konnte ein signifikanter Unterschied festgestellt werden: F(72, 220) = 1.55, p < .01, Wilk´s Lambda = .08. Post hoc durchgeführte ANOVAs zeigten einen signifikanten Unterschied für CTTR: F(8, 43) = 2.55, p < .05, partielles η2 = 0.32. Für die acht weiteren Variablen zeigten sich jedoch keine Unterschiede unter dem Niveau p < .05. Für die Textdeckung mit den häufigsten 5.000 Wörtern konnte mit F(8, 43) = 1.96, p = .075 ein starker Trend identifiziert werden (siehe Abbildung 6).
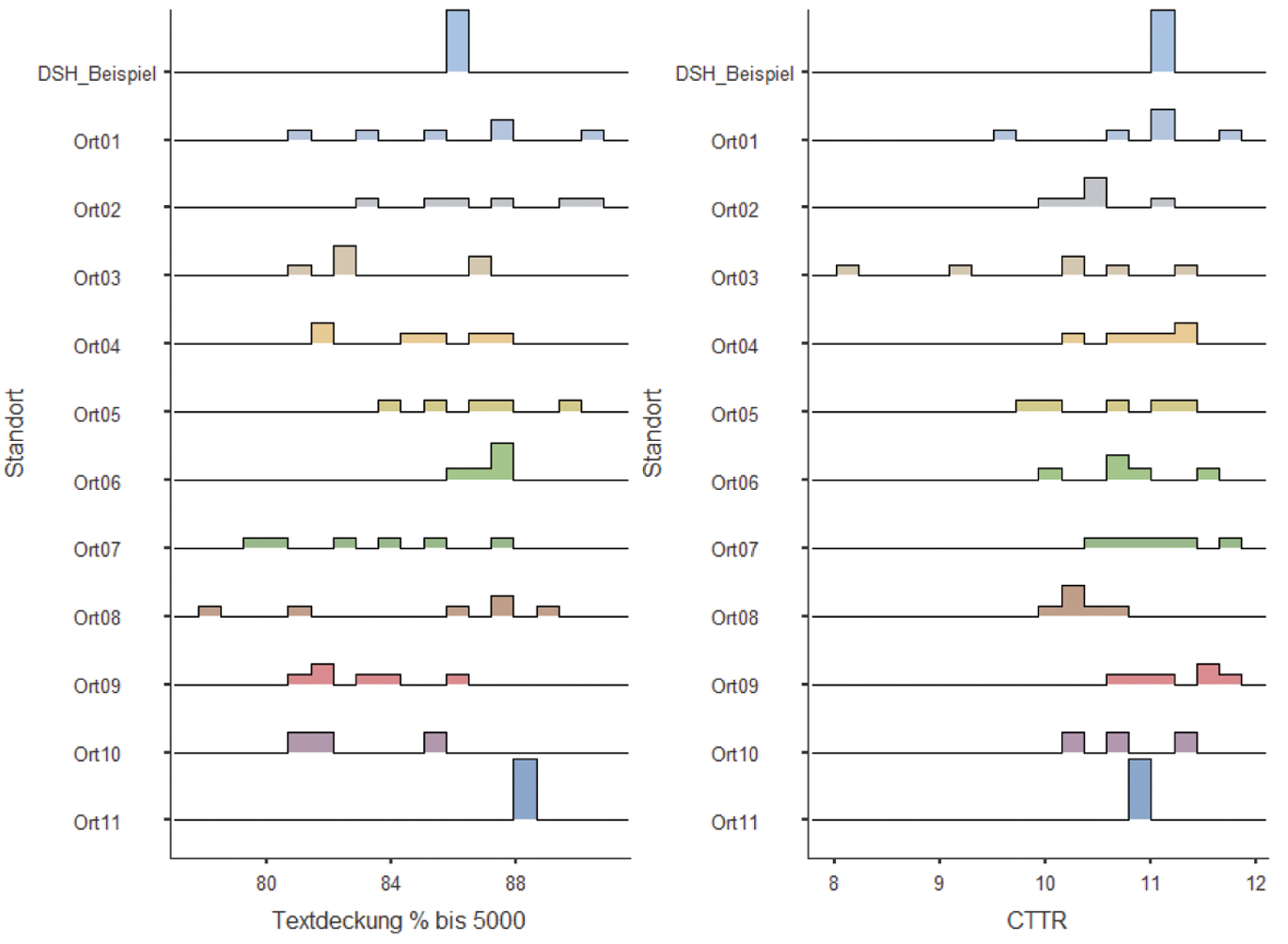
Standortunterschiede Lesetexte, Textdeckung bis 5.000 und CTTR
Der signifikanten ANOVA mit CTTR als abhängiger Variable wurde mit einem Tukey-post-hoc-Test für die neun Standorte nachgegangen. Es konnte ein signifikanter Unterschied (p < .05) zwischen Ort03 und Ort09 festgestellt werden.
4.4.2 Hörtexte DSH-Standorte
Auch eine für die Hörtexte durchgeführte MANOVA wies mit F(72, 220) = 2.83, p < .001, Wilk´s Lambda = .02 auf Standortunterschiede hinsichtlich der neun Texteigenschaften hin. Post hoc durchgeführte ANOVAs zeigten für sieben Maße signifikante Unterschiede mit p < .05 mit überwiegend starken Effekten auf (siehe Tabelle 9).
Post-hoc-ANOVAs Standortunterschiede Hörtexte
| F | df1 | df2 | p | partielles η2 | |
| Textdeckung % bis 1.000 | 1.96 | 8 | 43 | 0.075 | 0.27 |
| Textdeckung % bis 3.000 | 2.03 | 8 | 43 | 0.066 | 0.27 |
| Textdeckung % bis 5.000 | 2.87 | 8 | 43 | 0.012 | 0.35 |
| LIX | 9.69 | 8 | 43 | < .001 | 0.64 |
| Anteil lange Wörter [%] | 6.27 | 8 | 43 | < .001 | 0.54 |
| Durchschnittliche Satzlänge | 4.68 | 8 | 43 | < .001 | 0.47 |
| Mean Token Length in Letters | 6.62 | 8 | 43 | < .001 | 0.55 |
| TTR SoL50 | 4.96 | 8 | 43 | < .001 | 0.48 |
| CTTR | 5.30 | 8 | 43 | < .001 | 0.50 |
Abbildung 7 veranschaulicht die festgestellten Unterschiede exemplarisch für die Variablen Textdeckung bis 5.000, LIX und TTR SoL50.
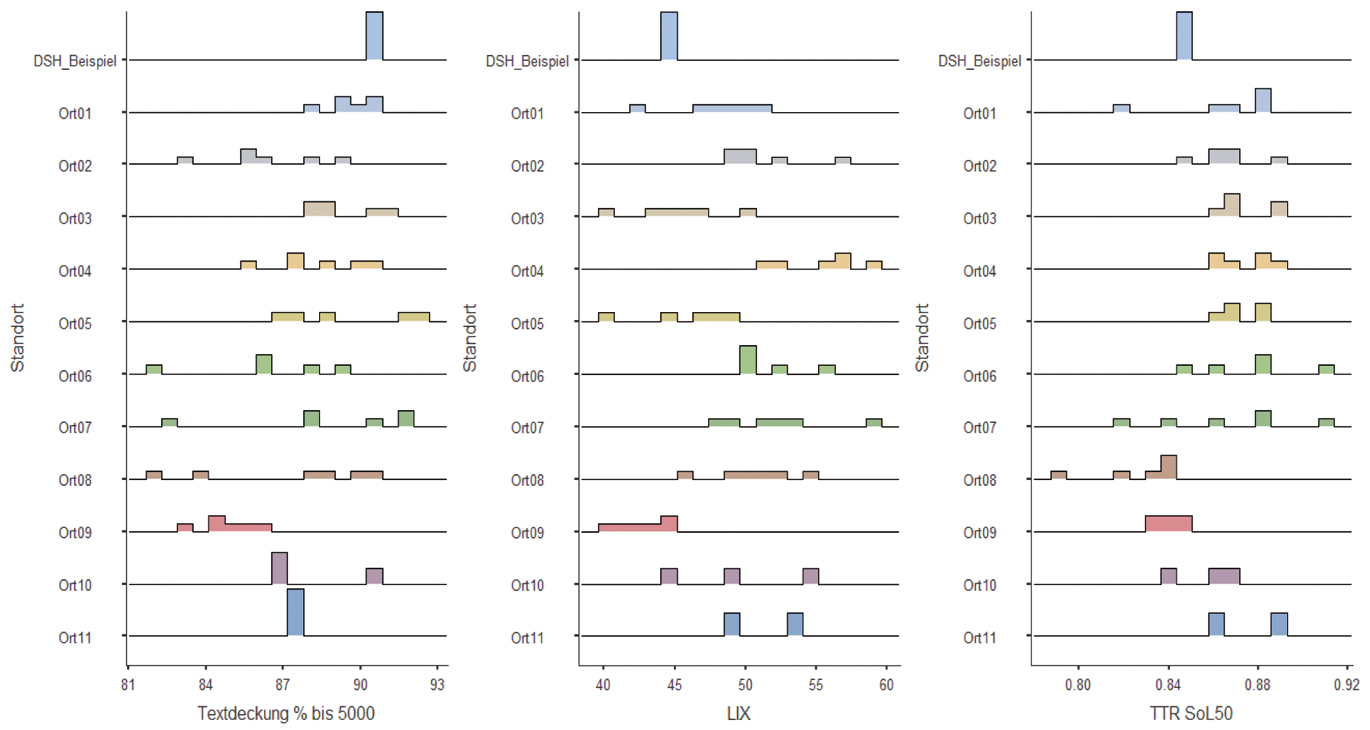
Standortunterschiede Hörtexte, Textdeckung bis 5.000, LIX und TTR SoL50
Jeder signifikanten ANOVA wurde mit paarweisen Tukey-post-hoc-Tests für die Gruppen Ort01 bis Ort09 nachgegangen. Es zeigten sich folgende signifikanten Unterschiede zwischen den Standorten mit * ~ p < .05, ** ~ p < .01 und *** ~ p < .001:
Textdeckung % bis 5.000
Ort01 vs. Ort09*
LIX
Ort01 vs. Ort04*, Ort02 vs. Ort03*, Ort02 vs. Ort09**, Ort03 vs. Ort04***, Ort03 vs. Ort06*, Ort03 vs. Ort07**, Ort04 vs. Ort05***, Ort04 vs. Ort09***, Ort05 vs. Ort07*, Ort06 vs. Ort09**, Ort07 vs. Ort09*** und Ort08 vs. Ort09**
Anteil lange Wörter [%]
Ort01 vs. Ort04*, Ort02 vs. Ort03*, Ort02 vs. Ort09**, Ort03 vs. Ort04**, Ort03 vs. Ort08*, Ort04 vs. Ort09***, Ort07 vs. Ort09*, Ort08 vs. Ort09**
Durchschnittliche Satzlänge
Ort04 vs. Ort05**, Ort04 vs. Ort09*, Ort05 vs. Ort07*, Ort07 vs. Ort09*
Mean Token Length in Letters
Ort01 vs. Ort04**, Ort02 vs. Ort09***, Ort03 vs. Ort04**, Ort04 vs. Ort09***, Ort08 vs. Ort09**
TTR SoL50
Ort08 vs. Ort01*, Ort08 vs. Ort02*, Ort08 vs. Ort03**, Ort08 vs. Ort04**, Ort08 vs. Ort05**, Ort08 vs. Ort06**, Ort08 vs. Ort07*
CTTR
Ort08 vs. Ort01**, Ort08 vs. Ort02***, Ort08 vs. Ort03*, Ort08 vs. Ort04**, Ort08 vs. Ort05***, Ort08 vs. Ort06***, Ort08 vs. Ort07**, Ort08 vs. Ort09*
5 Diskussion der Ergebnisse
Abschließend sollen die eingangs formulierten Forschungsfragen anhand der Ergebnisse diskutiert werden.
FF1: Wie unterscheiden sich Hör- und Lesetexte bei der DSH?
Insgesamt konnte festgestellt werden, dass sich die Konzepte Mündlichkeit (Hören/gesprochene Wissenschaftssprache) und Schriftlichkeit (Lesen/geschriebene Wissenschaftssprache) in den ermittelten Eigenschaften der DSH-Prüfungstexte widerspiegeln. Alle neun untersuchten Variablen zeigten signifikante Unterschiede zwischen den Fertigkeiten, wobei Hören stets am weniger komplexen, leichteren Ende der Skala verortet war. Mit den häufigsten 1.000, 3.000 und 5.000 Wörtern des Deutschen erreicht man bei den Hörtexten durchweg eine durchschnittlich höhere Textdeckung als bei den Lesetexten; die Hörtexte wiesen einen um etwa vier Punkte niedrigeren Lesbarkeitsindex LIX auf. Die lexikalische Vielfalt war beim Hören ebenfalls niedriger als beim Lesen.
Einige der untersuchten Texte wiesen dabei für die jeweilige Fertigkeit besonders „leichte“ oder „schwere“ Kennwerte auf. So lag etwa der Hörtext 05 von Ort07 mit einer hohen Komplexität (LIX = 52.96), einer niedrigen Textdeckung mit den häufigsten 5.000 Wörtern (82,7 %) und einer niedrigen Redundanz (TTR SoL50 = .91 und CTTR = 12.02) deutlich außerhalb der für Hörtexte, jedoch im Rahmen der für Lesetexte üblichen Werte. In der Testentwicklungspraxis böte es sich an, Texte, welche, wie mit diesem Beispiel illustriert, auffällige Werte aufweisen, nochmals auf die lexikalische bzw. syntaktische Passung zum jeweiligen Konstrukt zu überprüfen und ggf. zu überarbeiten.
Die untersuchten Eigenschaften der Lexical Richness bieten für die Hörtexte auch Anlass, bislang unscharfe Angaben der DSH-Vorgaben zu präzisieren, welche die Hörtextlänge in Abhängigkeit der Redundanz auf 5.500–7.000 Zeichen (Qualitätszirkel des FaDaF 2022: 17) festlegt, ohne Informationsdichte oder Redundanz konkret zu operationalisieren. Die Anzahl der Buchstabenzeichen korreliert für die hier untersuchten Hörtexte mit keinem der beiden Maße zur lexikalischen Vielfalt (TTR SoL50: r = -.31 (df(56), p = .99 und CTTR: r = .14 (df(56), p = .15), die als Maß für die lexikalische Redundanz interpretiert werden können. Ein Blick auf die Korrelationsmatrix (siehe Abbildung 8) zeigt, dass zwar besonders kurze Texte eher eine hohe TTR, also einen eher abwechslungsreichen Wortschatz aufweisen und besonders lange Texte eher redundante Lexik, die vertikale Streuung der TTR für ähnliche Textlängen jedoch sehr groß ist.
Dem im DSH-Handbuch vorgeschlagenen Prinzip, dass ein eher redundanter Hörtext etwas länger sein kann (Qualitätszirkel des FaDaF 2022: 17), wird zumindest in Hinblick auf die hier gemessenen Variablen der lexikalischen Redundanz kaum Sorge getragen.
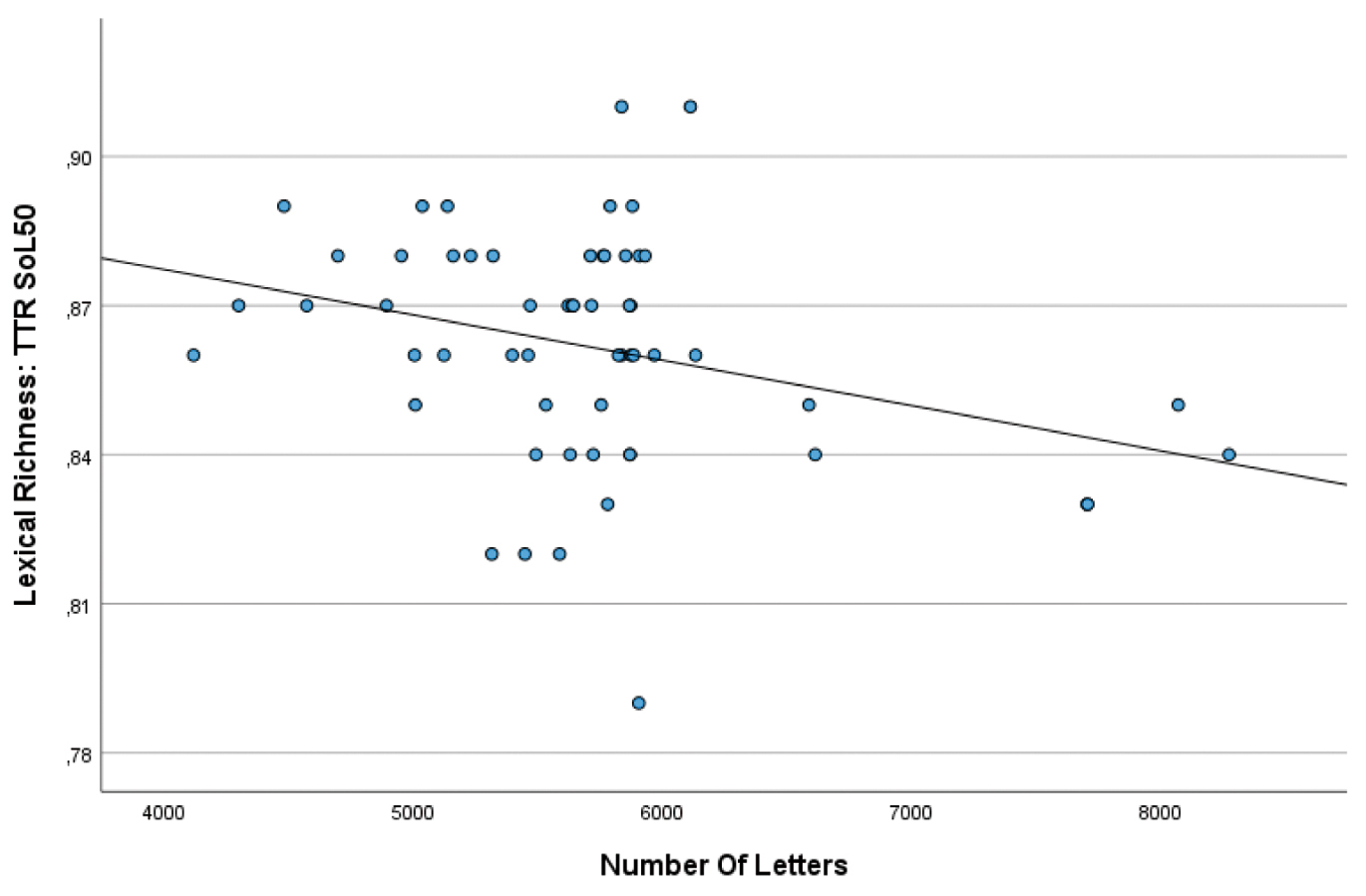
Streudiagramm Textlänge vs. Lexikalische Vielfalt der Hörtexte
Zahlreiche Studien haben bereits nachgewiesen, dass Lernenden mindestens 95 % des Wortschatzes eines Textes bekannt sein müssen, um diesen gut verstehen zu können, und sich frequenzbasierte Ansätze sowohl zur Messung von Wortschatzkompetenz der Lernenden als auch zur Beschreibung der lexikalischen Eigenschaften von Texten gut eignen (Laufer 2020; Möhring 2022; Tschirner 2019). Die in Kapitel 4.2 beschriebenen Häufigkeitsuntersuchungen bieten gute Anhaltspunkte für realistische Wortschatzlernziele zur sprachlichen Studierfähigkeit, die oberhalb der häufigsten 5.000 Wörter liegen sollte, einer Schwelle, die, wie Möhring (2022) zeigt, von vielen, aber längst nicht allen internationalen Studierenden zu Studienbeginn erreicht wird. Dabei decken 5.000 Wörter 90,5 % des leichtesten, jedoch nur 78,2 % des schwersten Lesetextes ab, was eine erhebliche Kluft der Wortschatzanforderungen zwischen verschiedenen Texten bedeutet.
Insgesamt haben sich die für die vorliegende Studie gewählten Maße als zuverlässige Instrumente zur abgrenzenden Beschreibung der Hör- und Lesetexte erwiesen.
FF2: Wie unterscheiden sich DSH-Standorte hinsichtlich der Texteigenschaften ihrer Hör- und Lesetexte?
Die Null-Hypothese, dass die Texte der Standorte sich wegen der gemeinsamen Testspezifikation nicht signifikant unterscheiden, wurde sowohl für Lesen als auch für Hören widerlegt. Insbesondere die Hörtexte unterscheiden sich zwischen den neun in diese Analyse eingeflossenen Standorten deutlich. Abbildung 6 und Abbildung 7 illustrieren sowohl die standortinterne wie auch standortübergreifende Spanne, beispielsweise hinsichtlich der Komplexität (LIX) der Hörtexte. Diese liegt etwa für Ort09 eher im „leichten“ Bereich, während die Werte anderer Orte signifikant höher liegen (vgl. Kap. 4.4.2). Einige Standorte zeigen bei allen eingereichten Texten einer Fertigkeit recht ähnliche Maße, sind also standortintern eher konsistent, andere Standorte trugen Texte mit sehr unterschiedlichen Eigenschaften bei, wie man beispielsweise Abbildung 6 entnehmen kann. Folgt man der eingangs erläuterten Annahme, dass Texteigenschaften wie die oben beschriebenen einen maßgeblichen Effekt auf die psychometrischen Eigenschaften des Tests haben, könnte insbesondere für den Prüfungsteil Hören angenommen werden, dass die zwischen den Standorten sehr verschiedene Interpretation der Vorgaben auch zu einer nicht äquivalenten Überprüfung und Einschätzung sprachlicher Studierfähigkeit führt. Dies abschließend zu beurteilen, wäre jedoch die Aufgabe weiterführender Studien unter Einbezug von Aufgaben, Ergebnissen und standardisierten Paralleltests (Settinieri 2022: 239). Die vorliegenden Ergebnisse allein können nicht zu einer Wertung führen, ob ein Standort bessere oder schlechtere Texte oder Prüfungsteile konstruiert als ein anderer; wohl wird aber die in der Natur einer dezentralen Prüfung liegende Heterogenität bei der Textgestaltung deutlich.
FF 3: Welche Richtwerte können für DSH-Hörtexte und -Lesetexte empfohlen werden?
Die Frage nach empfehlenswerten Richtwerten für DSH-Hörtexte und -Lesetexte kann mit dieser Studie keinesfalls abschließend beantwortet werden. Für eine verbindliche Angabe wären ein umfangreicheres Textkorpus und ein Ausbau der Studie um Aufgaben, Ergebnisse, psychometrische Eigenschaften der Items sowie Verbleibstudien und Untersuchungen zum Studienerfolg der DSH-Absolvierenden, also eine ausführliche Validierungsstudie, sowie eine kritische Überprüfung der ausgewählten Variablen erforderlich. Folgt man jedoch der Annahme, dass die für diese Untersuchung bereitgestellten Texte von elf Standorten die Testspezifikationen der DSH in angemessenem Maße operationalisieren, können die in Tabelle 10 dargestellten Wertebereiche eine nützliche Orientierungshilfe und eine wertvolle Ergänzung der bislang in den DSH-Vorgaben festgelegten Zeichenzahl darstellen. Angegeben sind jeweils pro Feature und pro Fertigkeit als Minimalwert der Mittelwert minus die einfache Standardabweichung, als Maximalwert entsprechend der Mittelwert plus die einfache Standardabweichung sowie die Anzahl und der Anteil der Texte, die in diesem Bereich liegen.
Prototypische Richtwerte für DSH-Texteigenschaften
| Fertigkeit | N | N [%] innerhalb Min/Max |
Min
-1 Std.-abw. |
Max
+1 Std.-abw. |
|
| LIX | HV | 58 | 39 [67.2] | 44.48 | 53.96 |
| LV | 57 | 41 [71.9] | 48.88 | 58.32 | |
| Anteil lange Wörter [%] | HV | 58 | 36 [62.1] | 30.62 | 37.96 |
| LV | 57 | 40 [70.2] | 33.00 | 39.12 | |
| Ø Satzlänge | HV | 58 | 40 [69] | 12.72 | 17.14 |
| LV | 57 | 42 [73.7] | 14.64 | 20.44 | |
| Textdeckung % bis 1.000 | HV | 58 | 38 [65.5] | 69.15 | 75.39 |
| LV | 57 | 40 [70.2] | 65.06 | 71.24 | |
| Textdeckung % bis 3.000 | HV | 58 | 39 [67.2] | 81.02 | 86.20 |
| LV | 57 | 39 [68.4] | 77.21 | 83.55 | |
| Textdeckung % bis 5.000 | HV | 58 | 39 [67.2] | 85.35 | 90.45 |
| LV | 57 | 39 [68.4] | 82.03 | 87.97 | |
| Mean Token Length in Letters | HV | 58 | 39 [67.2] | 5.62 | 6.26 |
| LV | 57 | 38 [66.7] | 5.88 | 6.42 | |
| TTR SoL50 | HV | 58 | 49 [84.5] | 0.84 | 0.89 |
| LV | 57 | 45 [78.9] | 0.87 | 0.90 | |
| CTTR | HV | 58 | 39 [67.2] | 9.54 | 11.26 |
| LV | 57 | 43 [75.4] | 10.05 | 11.35 |
Die Wertebereiche bieten DSH-Autorinnen und -Autoren beispielsweise die Möglichkeit, nach einer eigenen Überprüfung eines Lesetexts mit dem MultilingProfiler zu entscheiden, ob die Textdeckung des eigenen Texts mit den häufigsten 5.000 Wörtern des Deutschen zwischen 82 % und 88 % liegt, wie in vielen anderen DSH-Lesetexten üblich. Sollte man deutlich darunter liegen, ist der Anteil von schwierigem, niedrigfrequentem Wortschatz auffällig hoch. Dank der farbigen Markierung des nicht zu den Top-5.000-Wörtern gehörenden Wortschatzes in MultilingProfiler könnte sofort eine informierte Entscheidung getroffen werden, ob etwa fachsprachliche Inhalte tatsächlich noch vereinfacht werden sollten oder der niedrige Wert auf unproblematische Einträge, etwa Namen oder transparente Komposita, zurückzuführen ist. Weiterhin spielt bei der Entscheidung für oder gegen eine Überarbeitung eine Rolle, ob mutmaßlich schwieriger Wortschatz auch zur Lösung von Aufgaben benötigt wird.
Gleichwohl bedeutet ein Einhalten der Orientierungswerte keineswegs per se, einen besonders gut geeigneten Text vorliegen zu haben, denn die qualitativen Merkmale (vgl. Kap. 2.1) werden damit nicht gemessen. Auch können die Richtwerte nicht auf andere HZST übertragen werden, da diese das Hör- und Lesekonstrukt zum Nachweis sprachlicher Studierfähigkeit sehr verschieden operationalisieren. Auch hierzu wären weiterführende Studien zur Klassifikationsäquivalenz und Konstruktvalidität aller akkreditierten HZST dringend erforderlich.
6 Fazit und Ausblick
In diesem Beitrag wurden authentische DSH-Prüfungstexte in Hinblick auf eine kleine Auswahl der mittlerweile verfügbaren computerlinguistischen Komplexitätsmaße hin untersucht. Neben der Anbindung der Maße an etablierte Studien spielten die Transparenz, niedrigschwellige Bedienung und damit die Replizierbarkeit der Analysen eine ausschlaggebende Rolle für die Wahl der genutzten Werkzeuge. Zahlreiche weitere Maße, wie sie etwa in CTAP verfügbar sind, blieben ebenso unberücksichtigt wie andere Plattformen, beispielsweise DAFlex aus dem multilingualen CEFRlex Portal (Pintard/François 2020). Im Kontext zuverlässiger Einschätzung von Textkomplexität verspricht weiterhin das Projekt Level-Adequate Texts in Language Learning (LATILL) vielversprechende Erkenntnisse zu generieren (Vázquez-Ingelmo et al. 2023).
Es konnte gezeigt werden, dass sich die unterschiedlichen DSH-Testvorgaben zu HV und LV in den gemessenen Komplexitätsmaßen widerspiegeln. Studienbezogene Schriftlichkeit (LV) und Mündlichkeit (HV) werden also durch die DSH-Standorte differenziert operationalisiert. Insbesondere die untersuchten Hörtexte wiesen jedoch große Unterschiede auf, was in Anbetracht des gemeinsamen Testziels, dem Nachweis sprachlicher Studierfähigkeit, Anlass zu einer weiterführenden Betrachtung von Fairness, Objektivität und Validität der DSH gibt. Inwieweit die vorgestellten oder andere Textmaße als Richtwerte in die Textvorgaben zur DSH aufgenommen werden, obläge der DSH-Qualitätssicherung. Wünschenswert wäre natürlich auch ein größeres, dynamisches Korpus an Prüfungstexten, welches beispielsweise im Zuge der (Re-)Registrierung einer DSH aus den einzureichenden DSH-Prüfungssätzen generiert und regelmäßig ausgewertet werden könnte. Während für die vorliegende Studie nicht auszuschließen ist, dass die teilnehmenden Standorte nach eigener Ansicht besonders gelungene Texte beisteuerten, unterläge ein zentrales Korpus einem geringeren Risiko von Projekteffekten. Ergänzend wären die dazugehörigen Aufgaben und detaillierte Testergebnisse einer weiterführenden Validierung zuträglich.
Gleichwohl ist ein Text stets mehr als das, was man an der Textoberfläche messen kann, und für die Validität und Reliabilität von Hör- und Lesetests spielen neben der Qualität der Inputtexte zahlreiche weitere Faktoren eine Rolle. Computerlinguistische Ansätze zur Beschreibung von Texteigenschaften wie die hier besprochenen können perspektivisch dabei helfen, die Vergleichbarkeit der angebotenen DSH-Prüfungen zu erhöhen. Sie sollten jedoch nicht losgelöst von einer Ermittlung der sprachlichen Anforderungen in der Studieneingangsphase stehen, wie diese etwa für die gesprochene Wissenschaftssprache von Schilling und Cotelo (2023), zum Lesen von Möhring und Bärenfänger (2018) oder mit einem Lernzielkatalog zu „sprachliche[n] Kompetenzen im Studium“ (Bärenfänger/Feike/Magosch 2024) vorgeschlagen wird. Ergebnisse aus Bedarfsanalysen sollten natürlich nicht nur in HZST (Settinieri 2022: 238), sondern insbesondere in studienvorbereitende und -begleitende Lehr- und Lernmaterialien sowie Sprachkursangebote Eingang finden.
Forschung zu und Anbietende von HZST sind angehalten, in Anbetracht einer sich sehr dynamisch entwickelnden Hochschullandschaft und der enormen Tragweite von HZST fortlaufend größtmögliche Zuverlässigkeit und Konstruktvalidität zu gewährleisten. Dies betrifft in der bundesdeutschen Hochschullandschaft außer dem Deutschen als fremder Studiersprache zunehmend auch Englisch. Neben einer engen Zusammenarbeit von Test- und Sprachwissenschaft, Computerlinguistik und Didaktik sollten Fachverbände, politische Entscheidungsträger, die International Offices der Hochschulen sowie die vielerorts als Teil der Studienberatung etablierten Projekte zum Studiendatenmonitoring/Risikomanagement in eine fortlaufende Qualitätssicherung eingebunden werden.
Über den Autor / die Autorin
studierte Deutsch als Fremdsprache, Soziologie und Journalistik an der Universität Leipzig. Er ist an der Technischen Universität Dresden und dem Institut für Testforschung und Testentwicklung tätig. Seine Arbeits- und Forschungsschwerpunkte sind die studienvorbereitende und -begleitende Förderung von Deutschkompetenzen internationaler Studierender, korpuslinguistische Fragestellungen und das zuverlässige Testen von Sprachkompetenzen.
Literaturverzeichnis
Alderson, J. Charles (2000): Assessing reading. Cambridge: University Press (The Cambridge language assessment series).Search in Google Scholar
ALTE – Association of Language Testers in Europe (Hrsg.) (2012): Handbuch zur Entwicklung und Durchführung von Sprachtests: Zur Verwendung mit dem GER. Frankfurt am Main: telc.Search in Google Scholar
Althaus, Hans-Joachim (2018): „Warum C1 keine Lösung ist: Der Nachweis von Deutschkenntnissen für den Hochschulzugang, der GER und warum sie nicht zusammenpassen“. In: Brandt, Anikó; Buschmann-Göbels, Astrid; Harsch, Claudia (Hrsg.): Der Gemeinsame Europäische Referenzrahmen für Sprachen und seine Adaption im Hochschulkontext. Bochum: AKS-Verlag (Fremdsprachen in Lehre und Forschung 51).Search in Google Scholar
Anthony, Laurence (2014): AntWordProfiler. Tokyo: Waseda University.Search in Google Scholar
Appel, Berit; Fazlić-Walter, Ksenija; Overmann, Hans; Stezano Cotelo, Kristin; Wollert, Mattheus (2022): „Die DSH als hochschulische Prüfung – Merkmale und Qualitätssicherung“. In: Informationen Deutsch als Fremdsprache 49 (4), 369–383.10.1515/infodaf-2022-0060Search in Google Scholar
Aryadoust, Vahid; Goh, Christine C. M.; Kim, Lee Ong (2011): „An Investigation of Differential Item Functioning in the MELAB Listening Test“. In: Language Assessment Quarterly 8 (4), 361–385.10.1080/15434303.2011.628632Search in Google Scholar
Bärenfänger, Olaf; Feike, Julia; Magosch, Christine (2024): Sprachliche Kompetenzen im Studium: Lernziele für die studienbezogene Deutschförderung. Stuttgart: Klett Sprachen.Search in Google Scholar
Başaran, Bora (2023): „Die Lesbarkeit; noch ein weiterer Indikator für DaF-Lehrwerke?“. In: Diyalog Interkulturelle Zeitschrift Für Germanistik 3, 590–609.10.37583/diyalog.1407754Search in Google Scholar
Bauer, Karen; Doetjes, Gerard (2023): „Der Lernwortschatz in einem DaF-Anfängerlehrbuch: Wortauswahl und Wiederholungsfrequenz“. In: Zeitschrift für Interkulturellen Fremdsprachenunterricht 28 (1), 311–333.Search in Google Scholar
Björnsson, Carl-Hugo (1968): Lesbarkeit durch Lix. Stockholm: Pedagogiskt centrum, Stockholms skolförvaltn (Pedagogiskt centrum i Stockholm 6).Search in Google Scholar
Chen, Liang-Ching; Chang, Kuei-Hu; Yang, Shu-Ching; Chen, Shin-Chi (2023): „A Corpus-Based Word Classification Method for Detecting Difficulty Level of English Proficiency Tests“. In: Applied Sciences 13 (3), 1–17.10.3390/app13031699Search in Google Scholar
Chen, Xiaobin; Meurers, Detmar (2016): „CTAP: A Web-Based Tool Supporting Automatic Complexity Analysis“. In: Proceedings of the Workshop on Computational Linguistics for Linguistic Complexity (CL4LC). Osaka: The COLING 2016 Organizing Committee, 113–119.Search in Google Scholar
DAAD/DZHW – Deutscher Akademischer Austauschdienst/Deutsches Zentrum für Hochschul- und Wissenschaftsforschung (Hrsg.) (2023): Wissenschaft weltoffen 2023: Daten und Fakten zur Internationalität von Studium und Forschung in Deutschland und weltweit. Bielefeld: wbv Media.Search in Google Scholar
Deygers, Bart; Vanbuel, Marieke (2022): „Advocating an empirically-founded university admission policy“. In: Language Policy 21 (4), 575–596.10.1007/s10993-022-09615-6Search in Google Scholar
Domes, Sonja; Appel, Berit (2022): DSH-Rundbrief Nr. 12: Dezember 2022. Göttingen. Online: https://www.dsh-fadaf.de/wp-content/uploads/2023/03/dsh-rundbrief_dezember_2022.pdf (02.03.2024).Search in Google Scholar
Dudley, Amber; Marsden, Emma (2024): „The lexical content of high‐stakes national exams in French, German, and Spanish in England“. In: Foreign Language Annals 57 (2), 1–28.10.1111/flan.12751Search in Google Scholar
EALTA – European Association for Language Testing and Assessment (2016): EALTA Richtlinien zur Qualitätssicherung bei der Bewertung von Sprachkompetenzen. Online: https://www.ealta.eu.org/documents/archive/guidelines/German.pdf (05.03.2024).Search in Google Scholar
Eckes, Thomas (2003): „Qualitätssicherung beim TestDaF: Konzepte, Methoden, Ergebnisse“. In: Fremdsprachen und Hochschule 69, 43–68.Search in Google Scholar
Europarat (Hrsg.) (2001): Gemeinsamer europäischer Referenzrahmen für Sprachen. Berlin: Langenscheidt.Search in Google Scholar
Europarat (Hrsg.) (2018): Common European Framework of Reference for Languages: Learning, Teaching, Assessment. Companion Volume with New Descriptors. Council of Europe. Strasbourg.Search in Google Scholar
FaDaF – Fachverband für Deutsch als Fremdsprache (2023): DSH-Rundbrief Nr. 13: Juli 2023. Göttingen.Search in Google Scholar
FaDaF – Fachverband für Deutsch als Fremdsprache (2024): DSH-Rundbrief Nr. 14: Januar 2024. Göttingen.Search in Google Scholar
Falk, Susanne; Kercher, Jan; Zimmermann, Julia (2022): „Internationale Studierende in Deutschland: Ein Überblick zu Studiensituation, spezifischen Problemlagen und Studienerfolg“. In: Beiträge zur Hochschulforschung 44 (2–3), 14–39.Search in Google Scholar
Finlayson, Natalie; Marsden, Emma; Anthony, Laurence (2022): MultilingProfiler. University of York.Search in Google Scholar
Finlayson, Natalie; Marsden, Emma; Anthony, Laurence (2023): „Introducing MultilingProfiler: An adaptable tool for analysing the vocabulary in French, German, and Spanish texts“. In: System 118, 1–22.10.1016/j.system.2023.103122Search in Google Scholar
Friedland, Alice; Sabo, Milica (2022): „Schwierigkeit und Trennschärfe von Aufgabentypen – evaluiert durch Ober- und Untergruppenanalysen in den DSH-Prüfungsteilen Leseverstehen und Hörverstehen“. In: Informationen Deutsch als Fremdsprache 49 (5), 455–469.10.1515/infodaf-2022-0066Search in Google Scholar
g.a.s.t. – Gesellschaft für Akademische Studienvorbereitung und Testentwicklung (Hrsg.) (2023): Daten Kompakt: Ausgabe 2023. Bochum.Search in Google Scholar
Green, Anthony; Ünaldi, Aylin; Weir, Cyril (2010): „Empiricism versus connoisseurship: Establishing the appropriacy of texts in tests of academic reading“. In: Language Testing 27 (2), 191–211.10.1177/0265532209349471Search in Google Scholar
Grein, Marion (2021): „Prüferqualifizierung – Fokus auf Mündlichkeit“. In: Ersch, Christina Maria; Grein, Marion; Fierus, Ann-Katrin; Jehle, Nina; Sánchez Anguix, Virginia; Ziegler, Joshua; Riedinger, Miriam (Hrsg.): Evaluieren und Prüfen in DaF / DaZ. Berlin: Frank & Timme, 229–272.10.26530/20.500.12657/43132Search in Google Scholar
Grotjahn, Rüdiger (2012): „Hörverstehen: Konstrukt und Messung“. In: Fremdsprachen lehren und lernen 41 (1), 72–86.Search in Google Scholar
Hacking, Jane F.; Rubio, Fernando; Tschirner, Erwin (2019): „Vocabulary Size, Reading Proficiency and Curricular Design: The Case of College Chinese, Russian and Spanish“. In: Winke, Paula; Gass, Susan M. (Hrsg.): Foreign Language Proficiency in Higher Education. Cham: Springer, 25–44 (Educational Linguistics 37).10.1007/978-3-030-01006-5_3Search in Google Scholar
Holzknecht, Franz; Guggenbichler, Elisa; Zehentner, Matthias; Yoder, Monique; Konrad, Eva; Kremmel, Benjamin (2022): „Comparing EMI university reading materials with students’ reading proficiency utilizing Lexile® measures, Aptis test results, student questionnaire responses, and interviews with lecturers“. Research in EFL reading and reading assessment, Report 2. Online: https://www.britishcouncil.org/sites/default/files/rirg_holzknecht_et_al_layout.pdf (06.03.2024).10.1075/jemi.21006.holSearch in Google Scholar
Holzknecht, Franz; Harding, Luke (2024): „Repeating the Listening Text: Effects on Listener Performance, Metacognitive Strategy Use, and Anxiety“. In: TESOL Quarterly 58 (1), 451–478.10.1002/tesq.3249Search in Google Scholar
HRK/KMK – Hochschulrektorenkonferenz/Kultusministerkonferenz (2004): Rahmenordnung über Deutsche Sprachprüfungen für das Studium an deutschen Hochschulen (RO-DT).Search in Google Scholar
HRK/KMK – Hochschulrektorenkonferenz/Kultusministerkonferenz (2019): Rahmenordnung über Deutsche Sprachprüfungen für das Studium an deutschen Hochschulen (RO-DT).Search in Google Scholar
IBM Corp. Released 2023. IBM SPSS Statistics for Windows, Version 29.0.2.0 Armonk, NY: IBM Corp Jamovi: The jamovi project (2.4.11).Search in Google Scholar
Jung, Matthias (2022): „Standardisierte DaF/DaZ-Tests: Ein notwendiges Übel?“. In: Gültekin-Karakoç, Nazan; Fornoff, Roger (Hrsg.): Beruf(ung) DaF/DaZ: Festschrift zum 65. Geburtstag von Prof. Dr. Uwe Koreik. Göttingen: University Press, 195–210 (Materialien und Studien Deutsch als Fremd- und Zweitsprache – MatDaF 111.2).10.17875/gup2022-2105Search in Google Scholar
Karges, Katharina (2023): „Grenzen im Fremdsprachentesten: Ist A1 gleich A1? Eine Untersuchung zur Itemschwierigkeit in einem mehrsprachigen Leseverstehenstest“: Universität Freiburg; Universität Leipzig. Online: https://kongress.dgff.de/assets/230928_KargesK_DGFF_Poster_Posterpreis.pdf (06.03.2024).Search in Google Scholar
Kecker, Gabriele; Eckes, Thomas (2022): „Der digitale TestDaF: Aufbruch in neue Dimensionen des Sprachtestens“. In: Informationen Deutsch als Fremdsprache 49 (4), 289–324.10.1515/infodaf-2022-0057Search in Google Scholar
Kilian, Jörg (2021): Wortschatz lernen und reflektieren: Grundlagen, Befunde, Methoden für den Deutschunterricht in den Sekundarstufen I und II. Hannover: Klett | Kallmeyer.Search in Google Scholar
Koreik, Uwe (2005): TestDaF und DSH – eine Vergleichsstudie. Hohengehren: Schneider (Perspektiven Deutsch als Fremdsprache).Search in Google Scholar
Köster, Juliane (2005): „Wodurch wird ein Text schwierig? – ein Test für die Fachkonferenz“. In: Deutschunterricht (5), 34–39.Search in Google Scholar
Krekeler, Christian (2005): Grammatik und Fachbezug in Sprachtests für den Hochschulzugang. Dissertation an der Universität Duisburg-Essen.Search in Google Scholar
Larson, Myq (2017): „Thresholds, Text Coverage, Vocabulary Size, and Reading Comprehension in Applied Linguistics“. Thesis. Wellington: Waka-Victoria University. DOI: https://doi.org/10.26686/wgtn.17057906.v1.10.26686/wgtn.17057906.v1Search in Google Scholar
Laufer, Batia (2020): „Lexical Coverages, Inferencing Unknown Words and Reading Comprehension: How Are They Related?“. In: TESOL Quarterly 54 (4), 1076–1085.10.1002/tesq.3004Search in Google Scholar
Lenhard, Alexandra; Lenhard, Wolfgang (2014–2022): Berechnung des Lesbarkeitsindex LIX nach Björnsson. Institut Psychometrica Dettelbach.Search in Google Scholar
Li, Zhiqing; Li, Janis Zhiyou; Zhang, Xiaofang; Reynolds, Barry Lee (2024): „Mastery of Listening and Reading Vocabulary Levels in Relation to CEFR: Insights into Student Admissions and English as a Medium of Instruction“. In: Languages 9 (7), 239.10.3390/languages9070239Search in Google Scholar
Loukina, Anastassia; Yoon, Su-Youn; Sakano, Jennifer; Wei, Youhua; Sheehan, Kathy (2016): „Textual complexity as a predictor of difficulty of listening items in language proficiency tests“. In: Matsumoto, Yuji; Prasad, Rashmi (Hrsg.): Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers. Osaka: The COLING 2016 Organizing Committee, 3245–3253.Search in Google Scholar
McLean, Stuart; Matthews, Joshua; Milliner, Brett (2024): „Listening and Lexical Knowledge“. In: Wagner, Elvis; Batty, Aaron Olaf; Galaczi, Evelina (Hrsg.): The Routledge Handbook of Second Language Acquisition and Listening. Oxford: Taylor & Francis Group, 146–160 (The Routledge Handbooks in Second Language Acquisition Series).10.4324/9781003219552-13Search in Google Scholar
Milton, James; Alexiou, Thomaï (2009): „Vocabulary Size and the Common European Framework of Reference for Languages“. In: Richards, Brian; Daller, Michael H.; Malvern, David D.; Meara, Paul; Milton, James; Treffers-Daller, Jeanine (Hrsg.): Vocabulary Studies in First and Second Language Acquisition. London: Palgrave Macmillan UK, 194–211.10.1057/9780230242258_12Search in Google Scholar
Milton, James; Treffers-Daller, Jeanine (2013): „Vocabulary size revisited: the link between vocabulary size and academic achievement“. In: Applied Linguistics Review 4 (1), 151–172.10.1515/applirev-2013-0007Search in Google Scholar
Möhring, Jupp (2022): „Sprachliche Studierfähigkeit im Spiegel produktiver und rezeptiver Wortschatzkompetenz“. In: Informationen Deutsch als Fremdsprache 49 (4), 384–410.10.1515/infodaf-2022-0058Search in Google Scholar
Möhring, Jupp; Bärenfänger, Olaf (2018): „Hochschulzugangsprüfungen und die Studienrealität: Eine empirische Untersuchung zu Lese- und Wortschatzanforderungen in der Studieneingangsphase“. In: Informationen Deutsch als Fremdsprache 45 (4), 540–572.10.1515/infodaf-2018-0073Search in Google Scholar
Nickel, Sven (2011): „Textschwierigkeit objektivieren: Der Lesbarkeitsindex LIX“. In: ALFA-Forum (76), 30–32.Search in Google Scholar
Norris, John; Drackert, Anastasia (2018): „Test review: TestDaF“. In: Language Testing 35 (1), 149–157.10.1177/0265532217715848Search in Google Scholar
Oesterreicher, Wulf; Koch, Peter (2016): „30 Jahre ‚Sprache der Nähe – Sprache der Distanz‘“. In: Feilke, Helmuth (Hrsg.): Zur Karriere von ›Nähe und Distanz‹: Rezeption und Diskussion des Koch-Oesterreicher-Modells. Berlin: De Gruyter, 11–72 (Reihe Germanistische Linguistik 306).10.1515/9783110464061-003Search in Google Scholar
Pintard, Alice; François, Thomas (2020): „Combining Expert Knowledge with Frequency Information to Infer CEFR Levels for Words“. In: Gala, Núria; Wilkens, Rodrigo (Hrsg.): Proceedings of the 1st Workshop on Tools and Resources to Empower People with REAding DIfficulties (READI). Marseille: European Language Resources Association, 85–92.Search in Google Scholar
Qualitätszirkel des FaDaF (Hrsg.) (2012): DSH Deutsche Sprachprüfung für den Hochschulzugang: Handbuch zur DSH-Erstellung und -Durchführung. Göttingen: Fachverband Deutsch als Fremdsprache (FaDaF).Search in Google Scholar
Qualitätszirkel des FaDaF (Hrsg.) (2022): DSH Deutsche Sprachprüfung für den Hochschulzugang: Handbuch zur DSH-Erstellung und -Durchführung. Göttingen: Fachverband Deutsch als Fremdsprache (FaDaF).Search in Google Scholar
Qualitätszirkel des FaDaF (Hrsg.) (2024): DSH Deutsche Sprachprüfung für den Hochschulzugang: Handbuch zur DSH-Erstellung und -Durchführung. Göttingen: Fachverband Deutsch als Fremdsprache (FaDaF).Search in Google Scholar
Révész, Andrea; Brunfaut, Tineke (2013): „Text characteristics of task input and difficulty in second language listening comprehension“. In: Studies in Second Language Acquisition 35 (1), 31–65.10.1017/S0272263112000678Search in Google Scholar
Schilling, Andrea; Stezano Cotelo, Kristin (2023): „Gesprochene Wissenschaftssprache: Die Vorlesung als Gegenstand der Studienvorbereitung?“. In: Informationen Deutsch als Fremdsprache 50 (5), 525–542.10.1515/infodaf-2023-0084Search in Google Scholar
Schwitalla, Johannes (2012): Gesprochenes Deutsch: Eine Einführung. Berlin: Erich Schmidt (ESV basics 33).Search in Google Scholar
Settinieri, Julia (2022): „Sprachprüfungen für den Hochschulzugang im Spannungsfeld von Politik und Methodologie“. In: Gültekin-Karakoç, Nazan; Fornoff, Roger (Hrsg.): Beruf(ung) DaF/DaZ: Festschrift zum 65. Geburtstag von Prof. Dr. Uwe Koreik. Göttingen: University Press, 231–242 (Materialien und Studien Deutsch als Fremd- und Zweitsprache – MatDaF 111.2).10.17875/gup2022-2109Search in Google Scholar
telc (2015): Handbuch Deutsch Hochschule C1. Frankfurt am Main: telc (telc language tests).Search in Google Scholar
Treffers-Daller, Jeanine; Parslow, Patrick; Williams, Shirley (2018): „Back to Basics: How Measures of Lexical Diversity Can Help Discriminate between CEFR Levels“. In: Applied Linguistics 39 (3), 302–327.Search in Google Scholar
Tschirner, Erwin (2019): „Der rezeptive Wortschatzbedarf im Deutschen als Fremdsprache“. In: Peyer, Elisabeth; Studer, Thomas; Thonhauser, Ingo (Hrsg.): IDT 2017: Band 1: Hauptvorträge. Berlin: Erich Schmidt, 98–111.Search in Google Scholar
Tschirner, Erwin; Möhring, Jupp (2019): A frequency dictionary of German: Core vocabulary for learners. London: Routledge (Routledge frequency dictionaries).10.4324/9781315620008Search in Google Scholar
van der Knaap, Ewout (2018): „Zur Bedeutung der Lexik für das literarische Lesen: Didaktische Erkenntnisse einer Textdeckungsuntersuchung“. In: Informationen Deutsch als Fremdsprache 45 (4), 444–463.10.1515/infodaf-2018-0069Search in Google Scholar
Vázquez-Ingelmo, Andrea; García-Holgado, Alicia; Theron, Roberto; Shoeibi, Nastaran; García-Peñalvo, Francisco José (2023): „Design and development of the LATILL platform for retrieving adequate texts to foster reading skills in German“. In: Saltiveri, Toni Granollers i.; Veloso, Montserrat Sendín; Navarro, Juan Enrique Garrido; González, Roberto García; Cairol, Mercè Teixidó; Solé, Marta Oliva; Iranzo, Rosa Mª Gil; Almenara, Afra Pascual; Barrantes, Sergio Sayago; Maritorena, Kepa Landa; Llados, Ferran Joan Lega; Gomà, Jordi Virgili (Hrsg.): XXIII International Conference on Human Computer Interaction. New York: ACM, 1–9.10.1145/3612783.3612796Search in Google Scholar
Wallner, Franziska; Möhring, Jupp (2013): „Wortschatzlisten auf dem Prüfstand“. In: Bergerová, Hana; Schmidt, Marek; Schuppener, Georg (Hrsg.): Lexikologie und Lexikografie: Aktuelle Entwicklungen und Herausforderungen. Ústí nad Labem: Univ. J. E. Purkyně Filozofická Fak, 119–133 (Acta Universitatis Purkynianae Facultatis Philosophicae studia germanica 7.2013).Search in Google Scholar
Westbrook, Carolyn (2019): The impact of input task characteristics on performance on an integrated listening-into-writing EAP assessment. University of Bedfordshire.Search in Google Scholar
Wisniewski, Katrin; Möhring, Jupp (2021): „Die Vergleichbarkeit von Sprachprüfungen zum Hochschulzugang im Licht ausgewählter post entry-Sprachtests“. In: Deutsch als Fremdsprache 58 (4), 195–213.10.37307/j.2198-2430.2021.04.03Search in Google Scholar
Wisniewski, Katrin; Lenhard, Wolfgang (2022): „Deutschkompetenzen als Prädiktoren des Studienerfolgs von Bildungsausländerinnen und Bildungsausländern“. In: Beiträge zur Hochschulforschung 44 (2–3), 60–81.Search in Google Scholar
Wisniewski, Katrin; Lenhard, Wolfgang; Spiegel, Leonore; Möhring, Jupp (Hrsg.) (2022): Sprache und Studienerfolg bei Bildungsausländer/-innen. Münster: Waxmann.Search in Google Scholar
Wisniewski, Katrin; Lenhard, Wolfgang; Möhring, Jupp (2023): Wie wichtig sind Deutschkenntnisse für ein erfolgreiches Studium internationaler Bachelorstudierender? Kernbefunde des SpraStu-Projekts. Hrsg. vom Deutschen Akademischen Austauschdienst (DAAD). DOI: https://doi.org/10.46685/DAADStu-dien.2023.0310.46685/DAADStudien.2023.03Search in Google Scholar
Wollert, Mattheus; Zschill, Stephanie (2017): „Sprachliche Studierfähigkeit: ein Konstrukt auf dem Prüfstand“. In: Informationen Deutsch als Fremdsprache 44 (1), 2–17.10.1515/infodaf-2017-0005Search in Google Scholar
Yildirim, Hülya (2022): Ermittlung niveaustufenspezifischer Indikatoren zur Bewertung von Textproduktionen im Rahmen der Deutschen Sprachprüfung für den Hochschulzugang (DSH). Göttingen: University Press (Materialien und Studien Deutsch als Fremd- und Zweitsprache Band 110).10.17875/gup2022-2035Search in Google Scholar
Online-Ressourcen (Stand: 29.08.2024)
AntWordProfiler: https://www.laurenceanthony.net/software/antwordprofiler/Search in Google Scholar
CEFRlex/DAFlex: https://cental.uclouvain.be/cefrlex/daflex/Search in Google Scholar
CTAP: http://ctapweb.comSearch in Google Scholar
Homepage zur DSH: https://www.dsh-fadaf.de/Search in Google Scholar
Homepage zur Studie: https://tu-dresden.de/gsw/slk/lsk/die-einrichtung/dsh-textkomplexitaetSearch in Google Scholar
LATILL: https://latill.eu/Search in Google Scholar
LIX-Rechner: https://www.psychometrica.de/lix.htmlSearch in Google Scholar
MultilingProfiler: https://www.multilingprofiler.net/Search in Google Scholar
© 2024 Walter de Gruyter GmbH, Berlin/Boston
Articles in the same Issue
- Frontmatter
- Frontmatter
- Einführung in das Themenheft „Begleitforschung zur DSH“
- Analyse von Aufgaben und Items für das Leseverstehen am Beispiel der DSH
- Eigenschaften von Hör- und Lesetexten in Hochschulzugangssprachtests am Beispiel der DSH
- Chunks/formelhafte Sequenzen bei Textproduktionen – eine Praxisreflexion
- Übereinstimmungsraten bei der Beurteilung von mündlichen Prüfungen am Beispiel der DSH
- Zur Berücksichtigung spezifischer Bedürfnisse in Prüfungen zum Nachweis der sprachlichen Studierfähigkeit unter dem Anspruch eines inklusiven Bildungssystems
Articles in the same Issue
- Frontmatter
- Frontmatter
- Einführung in das Themenheft „Begleitforschung zur DSH“
- Analyse von Aufgaben und Items für das Leseverstehen am Beispiel der DSH
- Eigenschaften von Hör- und Lesetexten in Hochschulzugangssprachtests am Beispiel der DSH
- Chunks/formelhafte Sequenzen bei Textproduktionen – eine Praxisreflexion
- Übereinstimmungsraten bei der Beurteilung von mündlichen Prüfungen am Beispiel der DSH
- Zur Berücksichtigung spezifischer Bedürfnisse in Prüfungen zum Nachweis der sprachlichen Studierfähigkeit unter dem Anspruch eines inklusiven Bildungssystems