A corpus-based behavioral profile analysis of polysemy and antonymy: the case of the ancient Greek size adjectives mikrós and mégas
-
Thanasis Georgakopoulos
 und
Marialena Lavda
und
Marialena Lavda


Abstract
This article explores the semantic relationships between the antonymous adjectives mikrós (‘small’/‘little’) and mégas (‘big’/‘large’) in Classical Greek. Adopting a cognitive and usage-based perspective, the study applies the Behavioral Profile approach to investigate the polysemy of these adjectives and to assess the strength of their antonymic relationship. Specifically, it aims to determine whether the functional similarity among antonymous words is greater or lesser than that found within the senses of polysemous words. By focusing on how antonymous senses of different lexemes cluster together in a joint network, the study examines the extent to which antonymy, rather than polysemy, governs the organization of these senses. The analysis points to an upgraded role of antonymy in semantic structure.
1 Introduction
This article examines the various senses associated with the antonymous adjectives mikrós (‘small’/‘little’) and mégas (‘big’/‘large’) across five distinct authors representing various genres in Classical Greek. Adopting a cognitive and usage-based perspective, this study not only investigates the polysemic status of the two adjectives but also critically examines their antonymic relation. Specifically, by drawing upon the Behavioral Profile (henceforth, BP) approach, it aims to determine whether the degree of functional similarity among antonymous words exceeds or falls short of that observed within the senses of polysemous words. Put differently, considering, for instance, a pair of meanings x.M1 (see ex. [1]) and x.M2 (see ex. [2]) for mikrós and a meaning M1 (see ex. [3]) for its antonymic counterpart mégas, our goal is to determine whether x.M1 exhibits greater functional similarity to x.M2 – which belongs to the same polysemy network – or to M1 – which is part of the antonymic network.
x.M 1 - ‘power_ability’
| hoû | tí | àn | mâllon | spoudáseié | tis |
| rel.gen.sg.n | indef.acc.sg.n | ptcl | more | be.eager:3sg.opt.aor | indef.nom.sg.m |
| kaì | smikròn | noûn | ékhōn | ánthropos | |
| conj | small.acc.sg.m | mind(m).acc.sg | have:ptcp.nom.sg.m | human(m).nom.sg | |
| “which has the highest conceivable claims to the serious interest even of a person who has but little intelligence” (Plato, Gorgias 500c) | |||||
x.M 2 - ‘power_control’
| hína | toínun | mḕ | toût’ | empodôn |
| for | ptcl | neg | dem.nom.sg.n | impede:ptcp.nom.sg.m |
| génētai | tôi | Thēbaíous | genésthai | |
| become.3sg.sbjv.aor.mid | ptcl | Thebes(m).acc.pl | become.inf.aor.mid | |
| mikroùs | ||||
| small.acc.pl.m | ||||
| “In order, then, that this unwillingness may not stand in the way of the weakening of Thebes” (Demosthenes, For the People of Megalopolis 16.25) | ||||
M 1 - ‘x.power_ability’
| éprakse | deiná, | deinà | d’ | antédōke | soí |
| do:3sg.aor | evil.acc.pl.n | evil.acc.pl.n | ptcl | give:3sg.aor | 2sg.dat |
| kaì | tôid’ | ékhei | gàr | hē | |
| conj | dem.dat.sg.n | have:3sg.prs | ptcl | art.nom.sg.f | |
| Díkē | méga | sthénos | |||
| Justice(f).nom.sg | big.acc.sg.n | strength(n).acc.sg | |||
| “He did terrible things, and repaid them to you and Orestes; for Justice has great strength” (Euripides, Electra 957) | |||||
The term ‘functional similarity’ is applied in line with the principles of the BP approach referring to the degree of shared semantic, morphosyntactic, and pragmatic behavior exhibited by senses of particular lexical items (see Divjak and Gries 2009; Gries and Divjak 2010: 338; Gries 2012): the greater the number of shared features between two senses, the higher their degree of functional similarity.
Gries and Otani (2010: 129) claim that we are able to specify a direction in this hypothesis, as they assert that “intuitively at least, the degree of functional similarity of antonymous words should be […] larger than that of the senses of polysemous words”, although they do not explore this hypothesis in detail within their work. Similarly, according to Sullivan (2012: 319), the adjective hard in a phrase like hard water demonstrates a stronger connection with its antonymous counterpart soft in the corresponding phrase soft water than with other senses of hard. Note, however, that Sullivan also makes this remark incidentally, as her primary focus lies on the differentiation between antonymy and synonymy rather than on the distinction between antonymy and polysemy. Given these preliminary remarks and results we can formulate the hypothesis that in a joint network that includes the senses of both antonyms, senses will be organized primarily by antonymy and secondarily by polysemy. To address this question, we first compute the degree of similarity among the various senses of each adjective separately. Following this, we include the similarity scores of the senses of both adjectives in the same analysis to explore the relationship between polysemy and antonymy. In both steps, we employ hierarchical agglomerative clustering (HAC), a method within the BP approach that groups senses into clusters based on their distributional similarity.
So far, most research on antonymy has concentrated on words or lemmata, rather than senses. This tendency is rooted in the broadly accepted idea that antonymy is a contrastive relation between words, established predominantly by the antonymous adjectives’ frequency of co-occurrence in the same context (see, e.g., Charles and Miller 1989; Justeson and Katz 1991). Senses, however, are proved to be more revealing for antonymy, as shown in Sullivan (2012), and in the current study, we view antonymy through this lens.
In this study, we specifically focus on the semantic domain of size. We opted to analyze adjectives within this semantic domain due to the attention they have received in corpus linguistics literature (see, e.g., Charles and Miller 1989; Muehleisen 1997) and, in particular, within the BP approach (see, e.g., Gries and Otani 2010). Especially, the antonymous adjective pairs big-little and large-small have been the focus of research on antonymy for decades (see, e.g., Charles and Miller 1989; Deese 1964, Lyons 1977, Sullivan 2012, among others). This ensures that our results can be directly compared to previous studies in this domain. Furthermore, size adjectives typically demonstrate a high degree of polysemy, including concrete and more abstract meanings, while also showcasing a diverse array of syntactic and semantic combinations (see, e.g., Syrpa 2020 for a full description of the adjective big). Considering their extensive polysemy and polyfunctionality, an approach such as the BP approach, which acknowledges the multidimensional nature of lexical items, is highly appropriate for analyzing the antonymous pair mikrós and mégas.
The paper is structured as follows: Section 2 lays the theoretical foundation of the study, with a primary focus on the lexical relation of antonymy from a cognitive linguistics perspective, as well as on studies employing a corpus linguistics approach to the analysis of antonyms. Section 3 outlines the methodology, offering an extensive overview of the BP approach, as well as discussing the data used in this study. Section 4 presents the results of the analysis and their interpretation. Finally, Section 5 provides a critical evaluation of the findings, concludes the paper, and suggests potential avenues for future research.
2 Theoretical background
This section aims to elucidate the shift in research focus on antonymy from the word level to the level of senses and to establish a connection between our study and the primary corpus-based studies that underpin it. Note that it is not intended to provide an exhaustive overview of all aspects of antonymy (for a concise history, see Jones 2002: 9–24).
2.1 Antonymy: from antonymous words to antonymous senses
Antonymy stands as one of the most fundamental lexico-semantic relations, particularly among adjectives (Fellbaum 1995: 284; Murphy 2003: 169). Cruse (1986: 197) highlights the paradoxical linguistic behavior of antonyms, emphasizing their simultaneous resemblance and divergence: they share similarities in distribution and meaning, yet they also diverge notably along a prominent dimension of meaning. Traditionally, antonymy has mostly been viewed as a relation between words, where oppositeness is treated as a fixed configuration in the lexicon (Charles and Miller 1989; Deese 1964; Justeson and Katz 1991; Miller and Fellbaum 1991; among others; for a critical review, see Murphy and Andrew 1993; Paradis and Willners 2011; Sullivan 2012). Charles and Miller (1989: 242) could not be clearer on this point, asserting that “antonymy is a lexical relation between word forms, not a semantic relation between word meanings” (see also Gross et al. 1989). In this perspective, meanings are perceived as existing solely within a language rather than in human cognition (on the core principles of this tradition, see Geeraerts 2010: 87). However, Cognitive Linguistics has shifted this view, portraying antonyms as dynamic and contextually sensitive, construable within specific contexts (Cruse 1986; Jones et al. 2012; Kostić 2015; Kotzor 2021; Paradis 2011).
This context-sensitive approach redirects focus from the word level to the level of senses. One study that paved the way for this shift in focus is Murphy and Andrew’s (1993) work on the conceptual basis of antonymy, in which they demonstrate that contextual factors, such as the noun phrases the adjectives modify, can alter the interpretation of the adjective (cf. the meanings of fresh in expressions such as fresh shirt and fresh fish; Murphy and Andrew 1993: 309). Their experiments revealed variability in antonymic pairings among participants depending on context, suggesting that antonymy operates at the level of senses rather than words. Justeson and Katz (1991: 6) similarly acknowledge the semantic dimension of opposition, albeit with findings that somewhat straddle between the two theoretical perspectives. Finally, Sullivan (2012) offers the most systematic exploration of antonymy at the level of senses, analyzing the adjectives hard, soft, rough, and smooth through the BP approach. Her study finds that antonymy manifests most meaningfully at the sense level rather than at the word-/lemma-level, and concludes that studying antonymy at the sense level reveals nuanced patterns inaccessible at the word or lemma (Sullivan 2012: 307, 323). In this paper, we subscribe to this view, and our findings further support it.
Note, however, that while this sense-level perspective prevails, it does not entirely preclude the existence of antonymy at the word level. Although meaning is context-dependent, high frequency of co-occurrence of specific antonym pairs can lead to their conventionalization. What begins as a conceptual relationship can, through repeated use, become lexically motivated (Kostić 2015). This frequent co-occurrence strengthens their association in memory, facilitating their conventionalization, which ultimately leads to the entrenchment and automatic activation of the lexical pair (Kotzor 2021).
2.2 The behavioral profile method
The Behavioral Profile (BP) method is a corpus-based approach to lexical semantics, which was developed 20 years ago and continues to gain popularity. It has been applied to the study of polysemy of lexical items in synchrony (e.g., Berez and Gries 2009; Georgakopoulos 2020; Gries 2006; Jansegers et al. 2015; Liu and Dou 2023), to the analysis of near-synonyms (Divjak 2006; Divjak and Gries 2006; Divjak and Gries 2009; Divjak 2010; Huang and Chen 2022; Liu and Espino 2012), and to the analysis of antonyms (Gries and Otani 2010; Sullivan 2012).[1] Notably, in the last decade, the approach expanded its applicability to the study of the diachronic evolution of lexemes (Jansegers and Gries 2020; Liu 2022). Its basic premise lies in the correlation between distributional similarity and functional/semantic similarity, which is rooted in the distributional theory of semantics proposed by scholars such as Firth (1957) and Harris (1954). It posits that distinctions or similarities among words and senses manifest in their contextual preferences, including various features spanning from lexical collocations to syntactic colligations, and many other aspects (e.g., pragmatic properties; Divjak 2010; Gries and Divjak 2010). The BP method enables the analysis of larger sets of words or senses, thereby facilitating a more detailed and extensive exploration of the data. Importantly, in the analysis of adjectives, it allows for the inclusion not only of the base forms of the adjectives but also of their inflected forms (see Gries and Otani 2010).
Since a crucial aspect of the method involves identifying a word’s contextual preferences, the procedure inherently entails extracting a high number of contextual features from the corpus sentences wherein the word appears. It is precisely these tokens’ morphosyntactic, semantic, and pragmatic features (collectively referred to as ID Tags, following Atkins’ 1987 terminology) and their distributional frequencies that play a crucial role in uncovering a word’s behavioral profile. The more fine-grained and detailed the study of the distributional characteristics of lexical items, the more precise the results. This approach to meaning is particularly useful, especially considering that our sample comes from a dead language, and intuitions are not available (cf. Georgakopoulos et al. 2020).
The specific four steps of the process as applied to antonyms are outlined as follows (Divjak and Gries 2009: 61; Gries and Divjak 2010: 338; Gries and Otani 2010: 128):
Retrieval of all instances of the lemmas of the antonyms from a corpus in the form of a concordance (at least at the level of sentence/utterance where the word occurs).
Thorough manual annotation of many properties of the use of the word forms, i.e., annotation of the ID tags.
Generation of a co-occurrence table indicating how often each ID tag occurs with a particular sense; the series of co-occurrence percentages (i.e., the BP vectors) shown in this table is what is called the behavioral profile.
Evaluation of the table through hierarchical agglomerative cluster analysis (HAC), which is the main exploratory technique used in BP studies. HAC represents the semantic relationships between the senses based on their distributional (dis)similarity, visualized through a dendrogram.
Through this process, it is anticipated that the correlation between distributional similarity and functional similarity will emerge, with elements demonstrating similarities appearing more tightly linked to each other than to other elements. As is evident from the fourth step of the process, the BP approach offers the possibility of a more complex statistical analysis of the data, not limited to observed frequencies and percentages (Gries 2012). This quantitative nature of the analysis enhances the accuracy and validity of the results.
3 Methodology & data
3.1 Corpus data
The current study focuses on adjectival meanings in Classical Greek (500-336 BCE), using texts from five Classical authors, i.e., Aristotle, Demosthenes, Euripides, Herodotus, and Plato. This selection ensures a diverse representation of genres including philosophy, orations, tragedy, and history. The data were retrieved from PhiloLogic4 (https://artflsrv03.uchicago.edu/philologic4/Greek/; last accessed December 2022), a full-text search, retrieval, and analysis tool from the Project for American and French Research on the Treasury of the French Language (ARTFL), with texts available from the Perseus Digital Library (Perseus Project, http://www.perseus.tufts.edu/hopper/).
3.2 Methods of corpus query
In line with the protocol of the BP approach, we initially extracted 4,487 instances of the two adjectives (that is the full set of examples from our tailor-made corpus), comprising 1,187 tokens of the lemma mikrós and 3,300 of mégas. These instances included both the valid and the non-valid tokens. Tokens were marked as valid only if they had an attributive or predicative syntactic use, since in both cases they modify nouns explicitly, and this results in a more homogeneous, comparable and less complex data group. Instances where the element did not seem to modify a noun, such as when it functioned as a complement of a prepositional phrase or was used as a noun or an adverb, were considered invalid. For example, smikrón often appeared in adverbial phrases with the prepositions epí and katá, forming the expressions epí smikrón and katá smikrón, both meaning ‘by a little’. These cases were classified as invalid.
To maintain consistency between the two adjectives, 500 tokens were randomly selected from the valid ones for the study. The tokens were randomly sorted using the “=rand()” formula in MS Excel 2016. Similar to other BP studies (e.g., Gries and Otani 2010; Sullivan 2012), we incorporated a portion from each lemma in both the comparative and superlative forms (2 % of each lemma in each degree of comparison), namely mikróteros and meízōn as well as mikrótatos and mégistos, respectively. It is worth noting that Sullivan (2012) used a smaller percentage of superlative forms (1.1 %) compared to comparative forms (2.2 %). In the present study, however, we extracted an equal percentage of comparative and superlative forms (2 %).
In the second step, we manually annotated the 1,000 tokens for various morphological, syntactical, and semantic properties (ID tags). These ID tags were customized specifically for the analysis of ancient Greek, as some of them are expected to be language-specific. For example, in a language like ancient Greek, where nouns are morphologically marked for gender, one might include an ID tag for gender, whereas in English, where adjectives are not grammatically gendered, such an ID tag would not be applicable. The annotation scheme contained 18 ID tags, with varying numbers of levels (which again may differ depending on the language under consideration). The semantic ID tags have the highest number of levels, while other ID tags, usually syntactic ones, have a minimum of two levels. Table 1 shows the ID tags each token was annotated for, their type, and their levels.
ID tags and their levels.
| ID tag type | ID tag | Levels |
|---|---|---|
| Semantic | Sense | age, amount_quantity, dimension, duration, importance, intensity, size_animal, size_human, size_man_made, title_significance, power_ability, power_control, power_physical, value, volume |
| Inanimate modified noun | yes, no | |
| Gender | feminine, masculine, neutral | |
| Negation | constituent, sentential, N/A | |
| Noun sense | abstract_entity, animal, animal_group, artifact, body_part, cause, change, change_possession, char_quality, cognitive_process, creation, deity, emotion, event_act, event_state, human, human_group, institution, intel_quality, location, natural_entity, natural_phenomenon, physical_property, possession, quality, quantity, time | |
| Prepositional phrase | abstract_goal, abstract_location, accompaniment, area, benefit, cause, distributive, exchange, exclusion, goal, manner, referential, source, static_location, time, N/A | |
| Morpho-syntactic | Number | singular, plural |
| Case | nominative, genitive, dative, accusative, vocative | |
| Article | yes, no | |
| Tense | present, aorist, imperfect, perfect, future, pluperfect | |
| Voice | active, middle, passive | |
| Mode | imperative, indicative, infinitive, optative, participle, subjunctive | |
| Transitivity | yes, no | |
| Number of V | 1sg, 2sg, 3sg, 1pl, 2pl, 3pl, 3du | |
| Sentence type | declarative, interrogative | |
| Clause type | main, independent | |
| Type of dp | noun clause, adverbial clause, N/A | |
| Syntactic use | attributive, predicative |
Although the method is rather objective – given that the criteria applied in the different steps adhere to specific, replicable protocols – the classification of data can sometimes become subjective, as acknowledged by Divjak and Gries themselves (Divjak and Gries 2009: 277). As the morphosyntactic tagging of the tokens was a relatively simple and straightforward process, this limitation primarily pertains to word sense tagging. To mitigate this limitation, we adopt a practice employed in a few corpus-linguistic studies, wherein the data coding is conducted by multiple annotators (see Diessel 2008; Glynn 2010; 2016; Zeschel 2010).[2] Specifically, the data were coded independently by the two authors of the current paper and a PhD student specializing in Ancient Greek Linguistics. The first coder coded the entire dataset. Subsequently, the second coder (the co-author) and the third coder coded a randomly selected 10 % of the data (100 tokens), focusing solely on the most challenging semantic ID tag, namely the sense of the adjective. Following this, inter-coder reliability was calculated using the Fleiss’ κ (Fleiss 1971), as more than two coders were involved. For the mikrós dataset, κ = 0.77 (z = 24.1, p < 0.001), indicated substantial agreement, while for the mégas dataset, κ = 0.82 (z = 26.90, p < 0.001), indicated almost perfect agreement.
Regarding the levels of the sense of the modified noun, we followed Sullivan’s method of using the classification system developed by the Corpora e Lessici dell’Italiano Parlato e Scritto (CLIPS) project by Federico Albano Leoni, “General Ontology for Nouns and Verbs” (http://webilc.ilc.cnr.it/clips/Ontology.htm; last accessed December 2022). We tried to use classes that were not too specific, so as to keep the number of senses included reasonable while at the same time avoiding using too general hyperclasses. It is important to note that we consistently coded for the literal sense of the noun, even when the intended meaning was figurative. Consider, for instance, the phrase pros húdōr smikrón (Plato, Theaetetus 201b), which translates to ‘in the short time’, as húdōr (‘water’) stands metonymically for the water clock (klepsúdra), a means of measuring time. In this case, we coded the noun as belonging to the ID tag level artifact, which is the literal meaning of the expression, rather than time, which is the intended meaning of this expression.
Regarding the annotation of the senses of the two adjectives, we relied on the sense distinctions provided in the three most significant ancient Greek-English dictionaries: LSJ (Liddell and Scott 1996), the Brill Dictionary (Montanari 2015), and the Cambridge Greek Lexicon (Faculty of Classics, University of Cambridge & Diggle 2021), as well as on the corpus data (for the full list of meanings included in the three dictionaries, see Appendix/Tables A.1–A.3). Since different dictionaries offer different sense distinctions, we needed to establish a consensus on the pool of senses to rely on for word sense tagging. Take, for instance, examples (4) and (5), which the Brill Dictionary would consider as belonging to the same sense (see Appendix/Table A.1/sense 3.3), while the Cambridge Greek Lexicon would treat them as belonging to different senses (see Appendix/Table A.3/senses 7 and 12). Since our strategy aimed at accepting more fine-grained distinctions, we also maintained the distinction between them, namely we distinguish between the senses ‘intensity’ and ‘volume’. It is worth noting that, in addition to our strategy adopted for practical reasons, there are also purely linguistic reasons for keeping these two senses separate. Specifically, the sense of ‘volume’ encompasses additional meanings compared to ‘intensity’, and the two senses appear in different collocations (with ‘volume’ exclusively modifying the noun phōnḗ ‘voice’).
‘intensity’
| Milḗsioi | pántes | hēbēdòn | apekeíranto |
| Milesians(m).nom.pl | all.nom.pl.m | from.the.youth.upwards | cut:3pl.aor |
| tàs | kefalàs | kaì | pénthos |
| art.acc.pl.f | head(f).acc.pl | conj | grief(n).acc.sg |
| méga | prosethḗkanto | ||
| big.acc.sg.n | add:aor.3pl.mid | ||
| “all the people of Miletus, young and old, shaved their heads and made great public lamentation” (Herodotus, The Histories 6.21.1) | |||
‘volume’
| endeiknúmenos | eis | tòn | anterastḗn, | |
| point:ptcp.nom.sg.m | to | art.acc.sg.m | rival.in.love(m).acc.sg | |
| kaì | légōn | megálēi | têi | phōnêi |
| conj | say:ptcp.nom.sg.m | big.dat.sg.f | art.dat.sg.f | voice(f).dat.sg |
| “he pointed to his rival lover, and spoke with a loud voice” (Plato, Amatores 133b) | ||||
Additionally, we aimed to maintain consistency between the lists of senses for the two adjectives for the sake of comparability. For instance, we divided the ‘small in amount’ sense of mikrós as found in the Cambridge Greek Lexicon, into two separate senses: ‘amount quantity’ (see, ex. [6]) and ‘value’ (see, ex. [7]), reflecting a similar distinction found in the adjective mégas.
‘x.amount quantity’
| ho | tḕn | mikràn | ousían |
| rel.nom.sg.m | art.acc.sg.f | small.acc.sg.f | estate(f).acc.sg |
| paralabṑn | parà | toû | patrós |
| receive:ptcp.nom.sg.m | by | art.gen.sg.m | father(m).gen.sg |
| “I, who inherited that slender estate from my father.” (Demosthenes, Against Phaenippus 42.23) | |||
‘x.value’
| dià | mikròn | argúrion | mḕ |
| through | small.acc.sg.n | silver(n).acc.sg | neg |
| metéxei | tês | póleōs | |
| participate:3sg.prs | art.gen.sg.f | city(f).gen.sg | |
| “[he] is losing his citizen-rights, for lack of a trifling sum of money” (Demosthenes, Against Timocrates 201) | |||
Finally, for comparability purposes, we used the same sense labels for both adjectives, indicating their difference by adding the symbol ‘x’ before the sense label for the adjective mikrós. In the aforementioned example, we used the labels ‘amount’ and ‘value’ for mégas and the labels ‘x.amount’ and ‘x.value’ for mikrós. This strategy also facilitated a clearer portrayal of the antonymous senses in a joint diagram. The final list of senses for both adjectives is provided in Table 2, along with a more precise description of each meaning, presented as a paraphrase.
The final list of meanings of the antonymous adjectives.
| Sense | Definition (mégas) | Definition (mikrós) |
|---|---|---|
| 1) ‘age’ | Old, full-grown, adult, elder (human and animal) | Little, young (human and animal) |
| 2) ‘amount quantity’ | Great in amount (countable) | Small in amount (countable) |
| 3) ‘dimension’ | Great in size of natural entities/body parts/institutions/area | Small in size of natural entities/body parts/institutions/area |
| 4) ‘duration’ | Long | Short, brief |
| 5) ‘importance’ | Of great importance, serious/grave | Of little importance, trivial |
| 6) ‘intensity’ | Great of properties/feelings/situations/qualities | Minor/little of properties/feelings/situations/qualities |
| 7) ‘power ability’ | Powerful (for ability) | Weak (for ability) |
| 8) ‘power control’ | Great, mighty of humans/kings/gods/states | Insignificant, weak of humans/kings/gods/states |
| 9) ‘power physical’ | Strong, great in power or strength of natural phenomena/physical power | Weak, small in power or strength of natural phenomena/physical power |
| 10) ‘size (animal)’ | Big in size of animals | Small in size of animals |
| 11) ‘size (human)’ | Big in size/stature of humans | Small in size/stature of humans |
| 12) ‘size (man-made)’ | Big in size of man-made things/artifacts | Small in size of man-made things/artifacts |
| 13) ‘title (significance)’ | Title of gods/kings/festivals, “the great” | Title of gods/kings/festivals, “the lesser/little” |
| 14) ‘value’ | Costly, of high price/value, large amount of money | Cheap, of low price/value, small amount of money |
| 15) ‘volume’ | Loud, of high volume | Soft, of low volume |
Note that only a subset of the 15 senses was included in the analysis. We considered only those senses that met the threshold of 10 tokens in our corpus. Table 3 presents the frequency each sense is attested. The cells shaded in grey indicate the senses that were excluded from further analysis for not meeting the threshold.
Frequency of each sense for both adjectives in the corpus.
| Sense_mégas | Frequency | Sense_mikrós | Frequency |
|---|---|---|---|
| intensity | 144 | x.intensity | 79 |
| importance | 94 | x.importance | 136 |
| dimension | 52 | x.dimension | 58 |
| power_control | 38 | x.power_control | 22 |
| title_signif | 31 | x.title_signif | 4 |
| power_ability | 47 | x.power_ability | 27 |
| value | 27 | x.value | 30 |
| size_man_made | 25 | x.size_man_made | 25 |
| amount_quantity | 15 | x.amount_quantity | 49 |
| size_human | 9 | x.size_human | 17 |
| size_animal | 7 | x.size_animal | 7 |
| volume | 7 | x.volume | 3 |
| power_physical | 3 | x.power_physical | 2 |
| duration | 1 | x.duration | 24 |
The final two steps of the BP method involve generating a co-occurrence table and conducting a statistical evaluation of the data. These steps were carried out following the protocol outlined in Levshina (2015: chapter 15). Table 4 is an extract from the initial spreadsheet used for data collection and annotation, with each row representing an occurrence of the adjective and each column corresponding to a linguistic feature.
Random excerpt of co-occurrence table for mégas and mikrós (input).
| Text | Sense | Inanimate modified noun | Noun sense | Tense |
|---|---|---|---|---|
| “παρὰ δὲ τὴν πόλιν ῥέειν ποταμὸν μέγαν…” | Dimension | Yes | Natural entity | Present |
| “…ὅτι μικρὸν ἀναλώσαντες χρόνον…” | Duration | Yes | Time | Aorist |
Table 5 presents the absolute frequencies for the levels of the ID tags negation and syntactic use for both adjectives. They indicate the number of times each level is realized for each adjective, in the current data. The sum of the absolute frequencies needs to be equal to the total number of tokens, namely 500 for each adjective.
Absolute frequencies of ID tag levels of ID tags (selection).
| ID tag | Level of ID tag | mégas | mikrós |
|---|---|---|---|
| Negation | Constituent | 9 | 71 |
| Sentential | 19 | 46 | |
| N/A | 472 | 383 | |
| Syntactic use | Attributive | 418 | 362 |
| Predicative | 82 | 138 |
In order to be able to compare them, the absolute frequencies need to be converted to relevant frequencies, as seen in Table 6. Table 6 is the output that was produced by the script from our input data (Table 4). Table 6 makes up the behavioral profile of the words. This translates to each word being identified by the total of relative frequencies of co-occurrence elements in a clause/sentence.
Relevant frequencies of two ID tags.
| ID tag | Level of ID tag | mégas | mikrós |
|---|---|---|---|
| Negation | Constituent | 0.018 | 0.142 |
| Sentential | 0.038 | 0.092 | |
| N/A | 0.944 | 0.766 | |
| Syntactic use | Attributive | 0.836 | 0.724 |
| Predicative | 0.164 | 0.276 |
The final step, namely the evaluation of the behavioral profiles with statistical techniques, was performed using the R statistical software package (R Core Team 2022). Our results will not be assessed based on frequencies and percentages of co-occurrence but rather on hierarchical agglomerative cluster analysis (HAC). This statistical technique yields dendrograms that merge data points at different levels in the vertical axis based on their (dis)similarities; the lower they are merged the more similar they are. HAC divides the data into clusters based on similarity. Data items that are in the same cluster are more similar to each other than to data items from different clusters. Thus, HAC results in the production of numerous clusters, which enables the comparison of the data (Divjak and Gries 2006: 36). The graphs will be computed using the Canberra measure of distance and the amalgamation using Ward’s method for cluster analysis, both of which have been used in several BP studies (see Divjak and Gries 2006; Divjak and Gries 2009; Divjak 2010; Levshina 2015). The plotted graphs are presented in the following section.
4 Results
4.1 The hierarchical agglomerative cluster results
This section presents the output of the BP script as a cluster dendrogram. First, we ran the script for each adjective separately, resulting in the dendrograms shown in Figures 1 and 2.[3] Then, we ran the script using a .txt file that included the datasets for both adjectives, producing a joint dendrogram shown in Figure 3. Each dendrogram illustrates how the different senses are grouped together. Regarding the remaining notations on the dendrograms, the red figures show the Approximately Unbiased (au) p-value, whereas the green figures show the Bootstrap Probability (bp) value (the former is considered more accurate than the latter). Note that the alpha was set at 0.10 (see Levshina 2015).
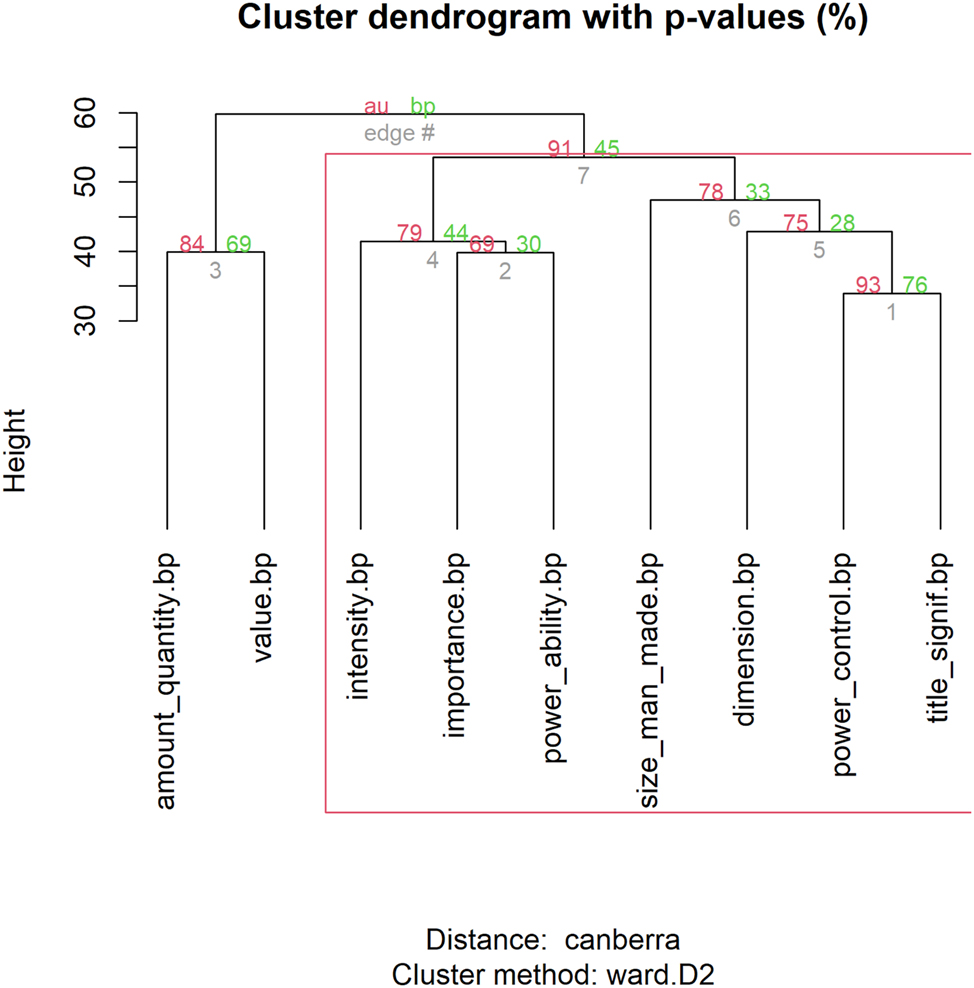
Hierarchical cluster analysis of 9 senses of mégas.
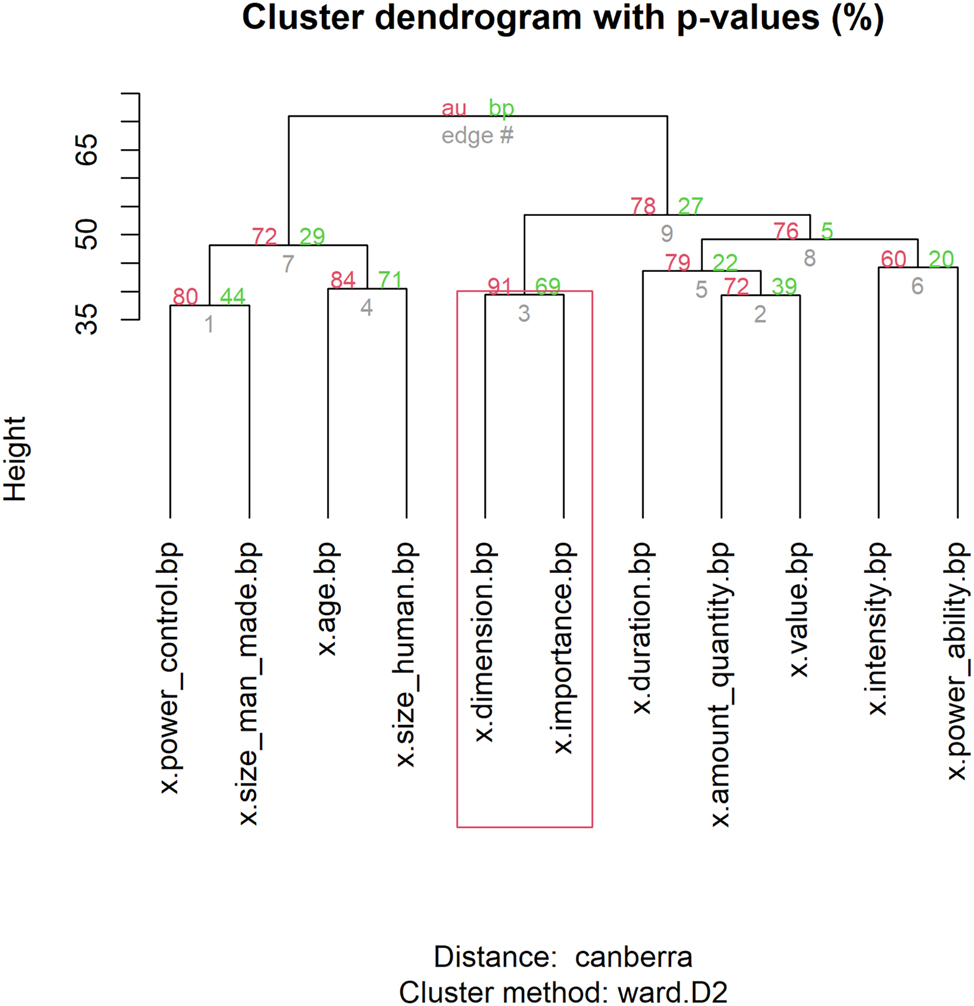
Hierarchical cluster analysis of 11 senses of mikrós.
In Figure 1 for mégas, two main branches are evident. The first branch (left) contains the senses: (1) amount_quantity, (2) value. The second branch (right) includes a greater number of senses: (3) intensity, (4) importance, (5) power_ability (first sub-branch); (6) size_man_made (7) dimension, (8) power_control, (9) title_significance (second sub-branch). The two clusters make sense semantically because they distinguish between different types of ‘magnitude’: The first cluster captures a more concrete and measurable aspect of magnitude, focusing on entities that can be clearly measured or valued numerically. For instance, in example (8), mégas modifies a noun from the semantic class artifact, in the subcategory of money, which is an entity that can be both counted and valued in numerical terms.
‘value’
| apikoménē | dè | kat’ | ergasíēn |
| arrive:ptcp.nom.sg.f | ptcl | down | work(f).acc.sg |
| elúthē | xrēmátōn | megálōn | hupò |
| release:3sg.aor.pass | money(n).gen.pl | big.gen.pl.n | by |
| andròs | Mutilēnaíou | Xaráksou | |
| man(m).gen.sg | Mytilenean.gen.sg.m | Kharaxus(m).gen.sg | |
| ‘but upon her arrival was freed for a lot of money by Kharaxus of Mytilene’ (Herodotus, The Histories 2.135.1) | |||
The second cluster represents abstract and qualitative attributes, reflecting a wider range of meanings related to power, significance, and impact that are not strictly quantifiable but are central to social or conceptual contexts (see examples 9–13). The division between the two clusters effectively organizes the senses based on how they express ‘greatness’, whether it is grounded in concrete, countable terms or abstract, qualitative attributes.
The minimum distance between the items is observed between ‘power_control’ and ‘title_significance’ (min(megas.dist): 33.97, as calculated using the dist() function in R. Consequently, these senses are merged lower on the tree. Consider examples (9) and (10), which illustrate these senses in specific contexts.
‘power_control’
| hoîón | moi | dokeîs | kaì | tóte | |
| ptcl | 1sg.dat | think:2sg.prs | conj | then | |
| endeíknusthai, | hōs | hai | megálai | póleis | |
| mark.inf.prs.mid | conj | art.nom.pl.f | big.nom.pl.f | city(f).nom.pl | |
| epì | tàs | smikràs | katá | tò | phúsei |
| on | art.acc.pl.f | small.acc.pl.f | down | art.acc.sg.n | nature(f).dat.sg |
| díkaion | érxontai | ||||
| righteous.acc.sg.n | come:3pl.prs.ind | ||||
| “I think you were also pointing out then, that the great states attack the little ones in accordance with natural right” (Plato, Gorgias 488c) | |||||
‘title_signif’
| límnēn | ek | tês | háles | gínontai, |
| lake(f).acc.sg | from | art.gen.sg.f | salt(m).nom.pl | become.3pl.prs |
| apíketo | es | Kolossàs | pólin | megálēn |
| arrive:3sg.aor | to | Colossae(f).acc.pl | city(f).acc.sg | big.acc.sg.f |
| Phrugíēs | ||||
| Phrygia(f).gen.sg | ||||
| “and the lake from which salt is obtained, he came to Colossae, a great city in Phrygia” (Herodotus, The Histories 7.30.1) | ||||
The semantic connection between the two senses of mégas involves a progression from describing outstanding characteristics of power and influence (sense: ‘power_control’) to formally recognizing and honoring these characteristics with a title (sense: ‘title_significance’). Their close association can also be explained by their distributional similarity. To identify the features that distinguish this cluster from all other senses, we examined the absolute differences in the proportions of each value for every variable (for details and code, see Levshina 2015: 313–315).
To compare the features that differentiate the senses ‘power_control’ and ‘title_signif’ from all other senses, we first extracted the rows from the megas.bp data frame corresponding to these two senses (c1 in the code). The remaining rows, corresponding to all other senses, were then extracted into a separate data frame (c2 in the code).
We calculated the column means for each subset (c1.bp for ‘power_control’ and ‘title_signif’, and c2.bp for the other senses). By computing the differences between these column means, we were able to quantify how each feature contributes to distinguishing these two senses from the others. Finally, the differences were sorted in descending order to identify the most distinguishing features.
The analysis revealed that the top differentiating feature is the absence of an inanimate modified noun for the adjective, with an average difference of 44 %. The second key parameter is the ID tag sem_modif_noun.institution (see the noun pólis in both [9] and [10]), with an average difference of 35 %, followed by sem_modif_noun.human, with an average difference of 29 %.
Turning to the second cluster of senses, ‘power_ability’ and ‘importance’ are grouped together because they exhibit similar behavioral profiles. Specifically, both tend to modify nouns associated with the event type ACT, a characteristic they also share with the sense ‘intensity’, which explains their close association in the dendrogram. This is illustrated in examples (11)–(13), which all feature nouns of this category.
‘power_ability’
| méga | dè | humîn | lógōn |
| big.acc.sg.n | ptcl | 2pl.dat | account(m).gen.pl |
| tônde | martúrion | eréomen | |
| art.gen.pl.m | proof(n).acc.sg | say:1pl.prs | |
| “We will give you a convincing proof of what we say” (Herodotus, The Histories 4.118.4) | |||
‘importance’
| hópōs | Asías | apò | gaíēs | êlthen |
| conj | Asia(f).gen.sg | from | land(f).gen.sg | come.3sg.aor |
| es | Eurṓpēn | pólemos | mégas | |
| to | Europe(f).acc.sg | war(m).nom.sg | big.nom.sg.m | |
| “how from the land of Asia a great war crossed into Europe” (Aristotle, Rhetoric 3.14.1415a) | ||||
‘intensity’
| perì | theoùs | ḕ | perì | gonéas | ḕ |
| about | god(m).acc.pl | conj | about | parent(m).acc.pl | conj |
| perì | pólin | ēdikēkṑs | tôn | megálōn | |
| about | city(f).acc.sg | do wrong.ptcp.nom.sg.m | art.gen.pl.f | big.gen.pl.f | |
| tina | kaì | aporrḗtōn | adikiôn, | ||
| indef.acc.sg.f | conj | forbidden.gen.pl.f | wrongdoing(f).gen.pl | ||
| “that is, of committing some great and infamous wrong against gods, parents, or State” (Plato, Laws 9.854e) | |||||
However, it should be noted that a single feature is not sufficient for two senses to be considered similar. Instead, the entire behavioral profile of each sense must be taken into account, rather than isolated features. With this caveat in mind, consider Table 7, which lists the top four differentiators for each branch in the dendrogram (each representing two or more senses) as shown in the HAC results in Figure 1.
Top four differentiating features for each branch in the dendrogram for mégas.
| Cluster of senses | Top differentiators |
|---|---|
| power_ability title_signif |
1. inanimate modified noun.no 2. sem.modif.noun.institution 3. sem.modif.noun.human 4. article.yes |
| importance power_ability |
1. sem.modif.noun.event_act 2. gender.neuter 3. article.no 4. if_in_pp_N/A |
| amount_quantity value |
1. number.plural 2. number_v.N/A 3. sem.modif.noun.change_possession 4. transitive_v.N/A |
| importance intensity power_ability |
1. sem.modif.noun.event_act 2. sem.modif.noun.event_state 3. article.no 4. number.singular |
| dimension power_control title_signif |
1. sem.modif.noun.institution 2. inanimate modified noun.no 3. number.singular 4. article.yes |
| dimension power_control size_man_made title_signif |
1. sem.modif.noun.institution 2. inanimate modified noun.no 3. number_v.3sg 4. sem.modif.noun.artifact |
Turning to mikrós, Figure 2 presents the plot resulting from the hierarchical cluster analysis of 11 senses of the adjective. In this Figure, two main branches are also evident. The first branch (left) includes the senses: (1) x.power_control, (2) x.size_man_made (first sub-branch); (3) x.age, (4) x.size_human (second sub-branch). The second branch (right) includes a greater number of senses: (5) x.dimension, (6) x.importance (first sub-branch); (7) x.duration, (8) x.amount_quantity, (9) x.value (second sub-branch); (10) x.intensity, (11) x.power_ability (third sub-branch). The senses in the first cluster revolve around physical and intrinsic attributes of living beings and objects. They describe qualities that are inherent to entities, such as age, size, and strength (see examples 16–17). In contrast, the second major cluster focuses on abstract attributes and quantities, combining measurable quantities with abstract properties, states, or conditions. Consider, for instance, example (14), which focuses on a measurable quantity, such as the size of an area, and example (15), where mikrós modifies the noun prâgma (‘matter’), representing not only a concrete, measurable entity but also an abstract concept, such as the perceived significance or importance of a matter.
‘x.dimension’
| léleiptai | dḗ, | katháper | en | taîs | smikraîs | |
| leave:3sg.pfv.mid | ptcl | just.us | in | art.dat.pl.f | small.dat.pl.f | |
| nḗsois, | pròs | tà | tóte | tà | nûn | |
| island(f).dat.pl | towards | art.acc.pl.n | then | art.acc.pl.n | now | |
| hoîon | nosḗsantos | sṓmatos | ostâ | |||
| ptcl | be.sick:ptcp.gen.sg.n | body(n).gen.sg | bones(n).acc.pl | |||
| “And, just as happens in small islands, what now remains compared with what then existed is like the skeleton of a sick man” (Plato, Critias 111b) | ||||||
‘x.importance’
| ei | Sophokleî | aû | proselthṑn | kaì |
| if | Sophocles(m).dat.sg | again | come:ptcp.nom.sg.m | conj |
| Euripídēi | tis | légoi | hōs | |
| Euripides(m).dat.sg | indef.nom.sg.m | say:3sg.prs.opt | conj | |
| epístatai | perì | smikroû | prágmatos | |
| know.3sg.prs.ind | about | small.gen.sg.n | matter(n).gen.sg | |
| rhḗseis | pammḗkeis | poieîn | ||
| speech(f).acc.pl | long.acc.pl.f | make:inf.prs | ||
| “And what if someone should go to Sophocles or Euripides and should say that he knew how to make very long speeches about a small matter” (Plato, Phaedrus 268c) | ||||
The shortest distance between items in this dendrogram is observed between ‘x.power_control’ and ‘x.size_man_made’ (min(mikros.dist): 37.55). Consider examples (14) and (15), which illustrate these senses in specific contexts.
‘x.power_control’
| hóti | spánion | ên | heureîn | ándras | polù |
| conj | rare | be.3sg.impf | find:inf.prs | man(m).acc.pl | very |
| diaférontas | kat’ | aretḗn, | állōs | te | |
| prevail:ptcp.acc.pl.m | down | virtue(f).acc.sg | otherwise | ptcl | |
| kaì | tóte | mikràs | oikoûntas | póleis | |
| conj | then | small.acc.pl.f | inhabit:ptcp.acc.pl.m | city(f).acc.pl | |
| “because it was rare to find men who greatly excelled in virtue, especially as in those days they dwelt in small cities” (Aristotle, Politics 3.1286b) | |||||
‘x.size_man_made’
| kaì | stéfanos | mèn | hápas, | kàn | mikròs |
| conj | crown(m).nom.sg | ptcl | every.nom.sg.m | even.if | small.nom.sg.m |
| êi, | tḕn | ísēn | philotimían | ||
| be.3sg.prs.sbjv | art.acc.sg.f | equal.acc.sg.f | honour(f).acc.sg | ||
| éxei | tôi | megálōi | |||
| have:3sg.prs | art.dat.sg.m | big.dat.sg.m | |||
| “that every crown, however small, implies the same regard for honor as if it were large” (Demosthenes, Against Timocrates 24.183) | |||||
In this case, the semantic linkage between the two senses of mikrós involves the notion of reduction or diminishment in some form. ‘x.power_control’ suggests a lack of power, authority, or significance, while ‘x.size_man_made’ refers to something being small or limited in size. Here, physical size is metaphorically extended to refer to power or significance: a ‘small’ state, for example (see example 16), can metaphorically imply weakness. The underlying metaphor in this case is unimportant is small (on the metaphors important is big and unimportant is small, see Yu, Yu and Lee 2017; Grady 1997). From a distributional perspective, the most important feature distinguishing this cluster from all other senses is the inanimate modified noun (level: yes), with an average difference of 26 %. The next three key factors are gender.feminine (13 %), transitive_V.yes (7 %), and article.no (6.5 %).
In the second cluster of senses, ‘x.amount_quantity’ and ‘x.value’ are grouped together because of their shared behavioral profiles. As noted for mégas, both senses share the semantic feature of being linked to entities that are quantifiable or measurable in numerical terms. From a distributional perspective, they are primarily associated with nouns from the categories of possession and quantity. Consider examples (18)–(19) in which mikrós modifies a noun of the category possession.
‘x.amount_quantity’
| tḕn | mikràn | ousían | paralabṑn | |
| art.acc.sg.f | small.acc.sg.f | estate(f).acc.sg | receive:ptcp.nom.sg.m | |
| toû | patròs | |||
| art.gen.sg.m | father(m).gen.sg | |||
| “[…] who inherited that slender estate from my father” (Demosthenes, Speeches 42.23) | ||||
‘x.value’
| hṓsper | en | Ambrakíai | mikròn |
| as | in | Ambracia(f).dat.sg | small.nom.sg.n |
| ên | to | tímēma | |
| be.3sg.impf | art.nom.sg | property(n).nom.sg | |
| “[…] as in Ambracia the property-qualification was small” (Aristotle, Politics 5.1303a) | |||
As with mégas, Table 8 presents the four most important features that differentiate the groups of senses, as clustered in Figure 2, from all other senses.
Top four differentiating features for each branch in the dendrogram for mikrós.
| Cluster of senses | Top differentiators |
|---|---|
| x.power_control x.size_man_made |
1. sem.modif.noun.artifact 2. sem.modif.noun.event_institution 3. gender.feminine 4. inanimate modified noun.yes |
| x.amount_quantity x.value |
1. gender.neuter 2. sem.modif.noun.possession 3. inanimate modified noun.yes 4. sem.modif.noun.quantity |
| x.dimension x.importance |
1. inanimate modified noun.yes 2. gender.neuter 3. sem.modif.noun.abstract_entity 4. tense.present |
| x.age x.size_human |
1. inanimate modified noun.no 2. sem.modif.noun.human 3. gender.masculine 4. negation.N/A |
| x.duration x.amount_quantity x.value |
1. inanimate modified noun.yes 2. sem.modif.noun.possession 3. gender.neuter 4. sem.modif.noun.time |
| x.intensity x.power_ability |
1. gender.feminine 2. sem.modif.noun.event_state 3. number.singular 4. negation.constituent |
| x.power_control x.size_man_made x.age x.size_human |
1. inanimate modified noun.no 2. sem.modif.noun.human 3. sem.modif.noun.artifact 4. number.plural |
| x.duration x.amount_quantity x.value x.intensity x.power_ability |
1. inanimate modified noun.yes 2. number.singular 3. case.accusative 4. sem.modif.noun.change_possession |
4.2 Clusters based on oppositeness or relatedness of meaning?
We now return to our original question: in a joint network that includes the senses of both antonyms, are the senses organized by antonymy or polysemy? To address this, we first present the joint dendrogram that includes the senses of mikrós and mégas that meet the threshold of 10 observations in our corpus (see Figure 3).[4]
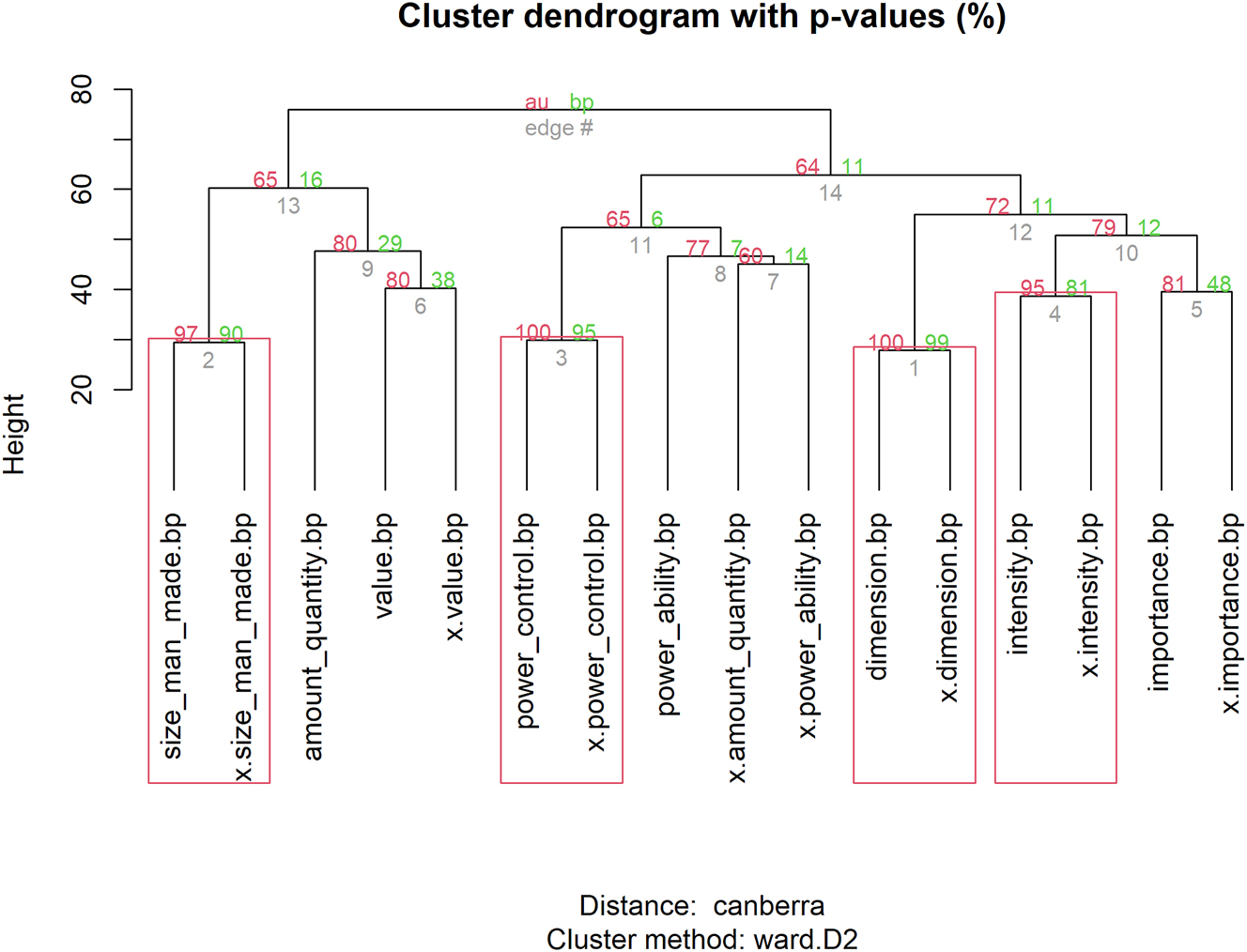
Hierarchical cluster analysis of the senses of mikrós and mégas.
The results from the joint dendrogram (Figure 3) are particularly illuminating. In every instance, antonymous senses cluster together in tight groups, a strong indication of their similarity. Consider, for example, the pairs <size_man_made; x.size_man_made>, <power_control; x.power_control>, <dimension; x.dimension>, <intensity; x.intensity>, and <importance; x.importance>, which form tight clusters. In contrast, polysemy appears to have no influence on the organization. The outcome is categorical: even when two senses of a single lemma are grouped together (as in the polysemy network), the corresponding antonymous sense is also present within that group. This is exemplified by the ‘power_ability’ sense, which loosely joins the <x.amount_quantity; x.power_ability> cluster.
This finding is partly consistent with Sullivan’s (2012) study, which shows that a dendrogram of antonymous and synonymous adjectives (hard, soft, smooth, and rough) is primarily organized by antonymy. In contrast, it differs from Gries and Otani’s (2010) finding, which did not identify any evidence of antonymy. Furthermore, while Sullivan’s study – focusing on the relationship between antonymy and synonymy – demonstrates a secondary organization by synonymy, our study – examining the relationship between antonymy and polysemy – reveals that the joint network of both antonyms is exclusively organized by antonymy, with no indication of secondary structuring by polysemy.[5] This finding further supports the argument that antonymous adjectives should be analyzed at the level of senses rather than words. Future research examining near-synonyms, such as brakhús (‘short’) and makrós (‘long’), will likely provide a more definitive answer to this issue.
That the level of senses is more vital for antonymy than that of words or lemmata is further supported by the fact that antonymous senses of mikrós and mégas often co-occur in the same context (cf. Sullivan 2012: 319). This claim aligns with the majority of existing studies on antonymy, particularly those focusing on substitutability, as previously discussed (Justeson and Katz 1991). Although the current work does not primarily focus on the collocations of antonymous senses, the co-occurrence of the two adjectives in the same context is notably high. Using a tool available from PhiloLogic4, one can determine that the adjectives mikrós and mégas appear together in 390 sentences within our selected corpus.[6] As shown in examples (20)–(21), the distributional behavior of the antonymous adjectives is rather common, sharing the same syntactic elements such as a common verb, subject, or modified noun.
| pánta | tà | kérdē | ho | ||
| all.acc.pl.n | art.acc.pl.n | gain(n).acc.pl | art.nom.sg.m | ||
| lógos | hēmâs | ēnágkake | kaì | smikrà | |
| argument(m).nom.sg | 1pl.acc | force:3sg.pfv | conj | small.acc.pl.n | |
| kaì | megála | homologeîn | agathà | eînai; | |
| conj | big.acc.pl.n | aknowledge:inf.prs | good.acc.pl.n | be.inf.prs | |
| “has compelled us to acknowledge that all gains, both small and great, are good?” (Plato, Hipparchus 232b) | |||||
| hómoioi | dḕ | kaì | hoûtoi | toîs | |
| similar.nom.pl.m | ptcl | conj | dem.nom.pl.m | art.dat.pl.m | |
| arxaíois | Homērikoîs, | hoì | mikràs | ||
| ancient.dat.pl.m | Homeric.dat.pl.m | rel.nom.pl.m | small.acc.pl.f | ||
| homoiótētas | horôsi | megálas | dè | parorôsin | |
| similarity(f).acc.pl | see.3pl.prs | big.acc.pl.f | ptcl | neglect:3pl.prs | |
| “these thinkers are like the ancient Homeric scholars, who see minor similarities but overlook important ones” (Aristotle, Metaphysics 14.1093a) | |||||
5 Conclusions
Drawing on the Behavioral Profile approach, this study examined the degree of functional similarity between antonymous lexemes and compared it to the similarity observed among the senses of polysemous lexemes. Focusing on the semantic domain of size, we analyzed the ancient Greek adjectives mikrós and mégas, an antonymous pair characterized by extensive polysemy in ancient Greek. Our findings provide evidence that antonymous senses of different lexemes are more closely associated with one another semantically than the various senses of a polysemous lexeme. Specifically, we demonstrated that in the joint network, which includes the senses of both mikrós and mégas, the organization is determined by antonymy rather than polysemy: antonymous senses of mikrós and mégas show greater functional similarity to each other than do the senses within either mikrós or mégas alone. This finding corroborates earlier research on antonymous words, which suggests that antonymy plays a more significant role than previously assumed, particularly when contrasted with synonymy (see Sullivan 2012). Moreover, it extends these insights by showing that antonymy also outweighs polysemy when it comes to the degree of similarity.
Future research could consider additional parameters, such as (near-)synonymy, and include a larger dataset. Consistent with most existing studies on antonymy, it would be beneficial to incorporate the near-synonyms of the antonymous adjectives mikrós and mégas, namely brakhús (‘short’) and makrós (‘long’). This approach would enable a more comprehensive and insightful analysis of the clustering of adjective senses and the interaction among the lexico-semantic relations of antonymy, synonymy, and polysemy.
Acknowledgments
This paper builds on the MA thesis of Marialena Lavda. A preliminary version of this research was presented at the 43rd Annual Meeting of the Department of Linguistics at Aristotle University of Thessaloniki in 2023. We would like to thank the attendees for their valuable insights and constructive feedback. Any errors that remain are entirely our own.
-
Research ethics: Not applicable.
-
Informed consent: Not applicable.
-
Author contributions: Conceptualization: TG and ML. Methodology: TG and ML. Data analysis and statistical analysis: TG and ML. Data collection: ML. Writing – Original Draft: TG and ML. Writing – Review & Editing: TG and ML. Visualization: TG and ML. Supervision: TG. All authors have accepted responsibility for the entire content of this manuscript and approved its submission.
-
Use of Large Language Models, AI and Machine Learning Tools: None declared.
-
Conflict of interest: The authors state no conflict of interest.
-
Research funding: None declared.
-
Data availability: All code and datasets used in this study are stored in the Zenodo repository. The dataset can be accessed at https://zenodo.org/uploads/14560220.
Abbreviations
- ACC
-
accusative
- AOR
-
aorist
- BP
-
behavioral profile
- CONJ
-
conjunction
- DAT
-
dative
- DEM
-
demonstrative
- F
-
feminine
- GEN
-
genitive
- HAC
-
hierarchical agglomerative clustering
- IMPF
-
imperfect
- INF
-
infinitive
- M
-
masculine
- MID
-
middle voice
- N
-
neuter
- NEG
-
negation
- NOM
-
nominative
- OPT
-
optative
- PASS
-
passive
- PL
-
plural
- PRS
-
present
- PTCL
-
particle
- PTCP
-
participle
- REL
-
relative pronoun
- SBJV
-
subjunctive
The list of meanings of the antonymous adjectives in Brill.
| Brill | |
|---|---|
| mégas | mikrós |
| 1.1. Great/large in build or stature/tall/imposing 1.1.1. Of person 1.1.2. Of animals 1.1.3. Of plants 1.1. Full grown/mature/adult/old/elder |
1. A small, of small dimensions, small in size |
| 2. As a nickname | |
| 3. Little, scarce (in quantity) 4. Low, voice 5. Brief, of short duration (time) |
|
| 2.1. Tall, high, lofty (of mountains, rocks) 2.2. Long 2.3. Large/big 2.4. Wide/broad/vast |
6. Little, of little importance, of little value or interest |
| 3.1. Great, powerful, mighty 3.1.1. Of gods 3.1.2. Of men 3.2. The powerful 3.2.1. Title for a king 3.3. Of things: Strong, violent, powerful 3.3.1. Of voice, sound 3.3.2. Of feelings, moral qualities 3.4. Of style: grand, magnificent 3.5. Substantial, important, critical |
|
| 4.1 serious, weighty, difficult 4.1.1. neg. arrogant, proud, haughty |
|
The list of meanings of the antonymous adjectives in LSJ.
| LSJ | |
|---|---|
| mégas | mikrós |
| 1. Big, great of bodily size, stature 1.1. Full-grown/age 1.2. Vast, high 1.3. Vast, spacious, wide 1.4. Long |
1. In point of size |
| 2. In quantity | |
| 3. In amount or importance (little, petty, trivial, slight, of small account) 4. Of time shortly |
|
| 2. Of degree: great strong, mighty 2.1. Great mighty of gods/ 2.2. Title of monarchs/mighty oath) 2.3. Great strong violent, of the elements and of properties, passions, qualities) 2.4. (Of sounds great loud) (great, mighty, weighty, important) |
|
The list of meanings of the antonymous adjectives in the Cambridge dictionary.
| Cambridge | |
|---|---|
| mégas | mikrós |
| 1. Great in size; 1.1. (Of persons, parts of the body) large, big or well-built 1.2. (Of persons) tall Hom. 1.3. (Of a warrior) tall and mighty, great |
1. Small in size or stature; (of persons) small, little, short |
| 2. (Of a child) small, little | |
| 3. (Of animals, birds, reptiles, fish) small, little | |
| 2. (Of persons) full-grown, adult | 4. Small in size or extent; 4.1. (Of concr. things, such as buildings, cities, ships, objects) small 4.2. (Of spears, daggers, arrows) short |
| 3. (Of animals) large, big, great or full-grown5. | |
| 4. (Of natural expanses or features of the landscape, such as sky, sea, a tract of water or land, a mountain) large, great, extensive, vast6. | |
| 5. Small in amount; 5.1. (Of food, wine, money) little; 5.2. (Of a total number of persons) small 5.3. Small amount, little, for a small amount(of money), cheaply 5.4. Small amounts (of money), small resources or humble circumstances |
|
| 5. (Of man-made things) large, big, great, extensive, vast, grand8. | |
| 6. Great in strength; (of natural elements or phenomena, such as wind, storm, fire, water) great, strong, powerful violent9. | |
| 6. Small in degree, intensity or importance; 6.1. (Of abstr. things, such as misfortune, hope, an accusation, offence, tasks, situations in general 6.2. Small, slight, trivial, small or trivial matter |
|
| 7. (Of sounds, voices) great, mighty, loud11. | |
| 8. (Of deities and divine agencies, their will) great, powerful, mighty 8.1. (Of an oath, under divine sanction)12. |
|
| 9. Great in power, achievement or fame; (of persons) great, mighty, powerful 9.1. (Of a people, family, city, state, or sim.) |
7. (Of the Panathenaia) lesser |
| 8. (Of a person) of small account, humble, lowly 8.1. (Of a goddess, in neg.phr.) 8.2. (Of ancestry) 8.3. (Of a helper) puny |
|
| 10. (Of a person) the great 10.1. (Of the Panathenaia)15. |
|
| 11. Great in skill or attainment; (of persons) great, distinguished | 9. (Of time, life) short 10. (Of speech) short, brief (of a journey) |
| 12. Great in degree; (of personal qualities or attributes, states of mind, sufferings, or sim.) great or intense | |
| 13. Great in importance, consequence or difficulty; (of things, circumstances, events, actions, tasks) great, important, mighty or weighty | |
| 14. (Pejor., of words, plans or deeds, w.connot. of infamy or boastfulness) violent, outrageous, audacious | |
| 15. Great in number; (of herds, flocks, a race, an army) large, great, huge | |
| 16. Great in price or value; (of things) great, costly | |
| 17. Of a favour or kindness, a friend or ally) great, valuable (of gratitude or thanks) of great, sincere | |
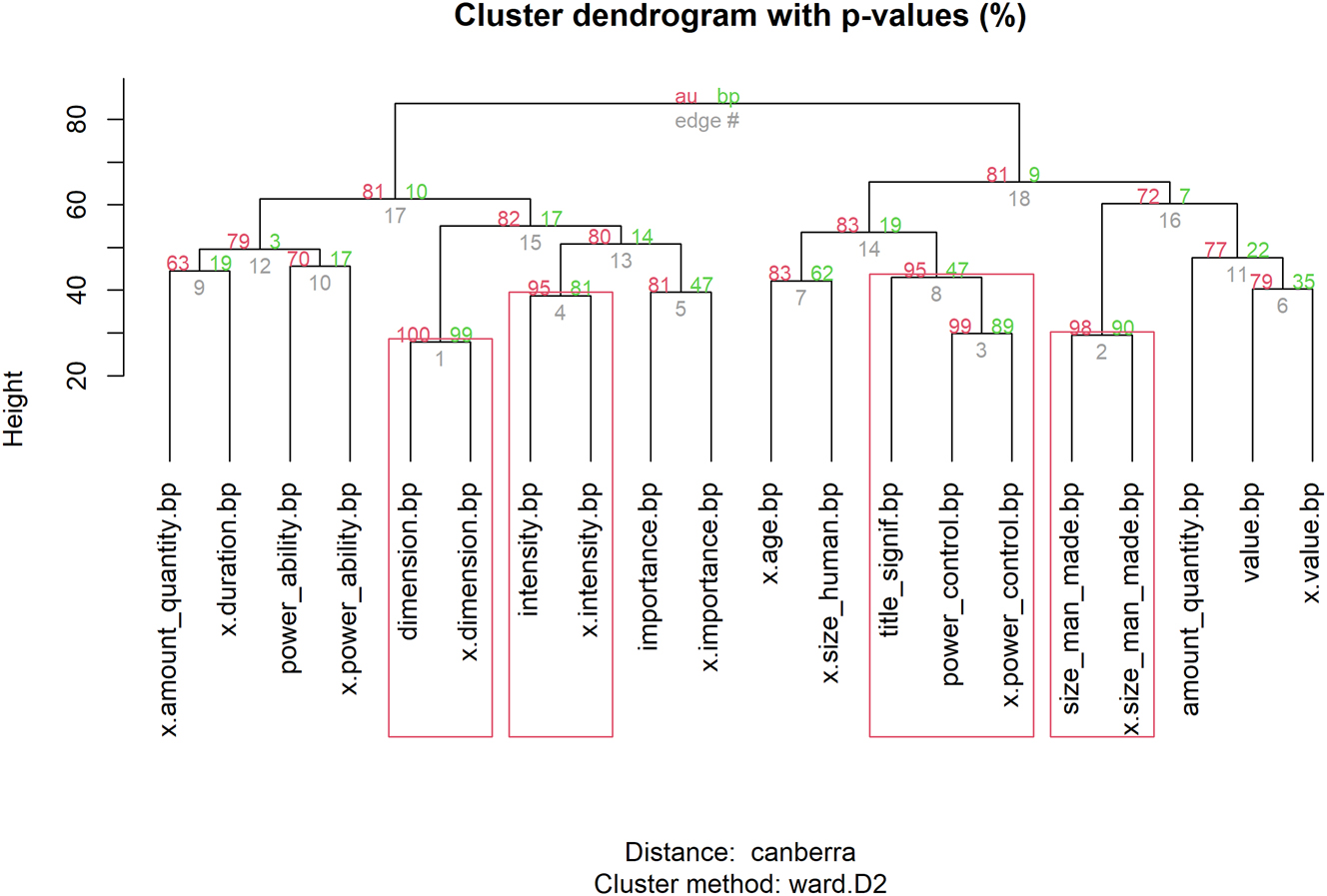
Hierarchical cluster analysis of the senses of mikrós and mégas (full list of senses included).
References
Atkins, Beryl T. Sue. 1987. Semantic ID tags: Corpus evidence for dictionary senses. In Proceedings of the third annual Conference of the UW Centre for the new Oxford English dictionary, 17–36.Suche in Google Scholar
Berez, Andrea L. & Stefan Th. Gries. 2009. In defense of corpus-based methods: A behavioral profile analysis of polysemous get in English. In S. Moran, D. S. Tanner & M. Scanlon (eds.), Proceedings of the 24th Northwest linguistics conference. University of Washington working Papers in linguistics, Vol. 27, 157–166. Seattle, WA: Department of Linguistics.Suche in Google Scholar
Charles, Walter G. & George A. Miller. 1989. Contexts of antonymous adjectives. Applied Linguistics 10. 357–375. https://doi.org/10.1017/s0142716400008675.Suche in Google Scholar
Cruse, D. Alan. 1986. Lexical semantics. Cambridge: Cambridge University Press.Suche in Google Scholar
Deese, James. 1964. The associative structure of some common English adjectives. Journal of Verbal Learning and Verbal Behavior 3(5). 347–357. https://doi.org/10.1016/s0022-5371(64)80001-3.Suche in Google Scholar
Diessel, Holger. 2008. Iconicity of sequence: A corpus-based analysis of the positioning of temporal adverbial clauses in English. Cognitive Linguistics 19(3). 465–490. https://doi.org/10.1515/COGL.2008.018.Suche in Google Scholar
Divjak, Dagmar. 2006. Ways of intending: Delineating and structuring near-synonyms. In S. T. Gries & A. Stefanowitsch (eds.), Corpora in cognitive linguistics: Corpus-based approaches to syntax and lexis, 19–56. Berlin & New York: Mouton de Gruyter.10.1515/9783110197709.19Suche in Google Scholar
Divjak, Dagmar. 2010. Structuring the lexicon: A clustered Model for near-synonymy. Berlin & New York: De Gruyter Mouton.10.1515/9783110220599Suche in Google Scholar
Divjak, Dagmar & Stefan Th. Gries. 2006. Ways of trying in Russian: Clustering behavioral profiles. Corpus Linguistics and Linguistic Theory 2(1). 23–60. https://doi.org/10.1515/cllt.2006.002.Suche in Google Scholar
Divjak, Dagmar & Stefan Th. Gries. 2009. Corpus-based cognitive semantics: A contrastive study of phasal verbs in English and Russian. In B. Lewandowska-Tomaszczyk & K. Dziwirek (eds.), Studies in cognitive corpus linguistics (Lodz Studies in Language), 273–296. Peter Lang Verlag.Suche in Google Scholar
Faculty of Classics, University of Cambridge & James Diggle. 2021. The Cambridge Greek lexicon. Cambridge: Cambridge University Press.10.1017/9781139050043Suche in Google Scholar
Fellbaum, Christiane. 1995. Co-occurrence and antonymy. International Journal of Lexicography 8(4). 281–303. https://doi.org/10.1093/ijl/8.4.281.Suche in Google Scholar
Firth, John. 1957. Papers in linguistics, 1934–1951. London: Oxford University Press.Suche in Google Scholar
Fleiss, Joseph L. 1971. Measuring nominal scale agreement among many raters. Psychological Bulletin 76(5). 378–382. https://doi.org/10.1037/h0031619.Suche in Google Scholar
Geeraerts, Dirk. 2010. Theories of lexical semantics. New York: Oxford University Press.10.1093/acprof:oso/9780198700302.001.0001Suche in Google Scholar
Georgakopoulos, Thanasis. 2020. A two-dimensional semantic analysis of falling in modern Greek: A typological and corpus-based approach. Acta Linguistica Petropolitana 16(1). 188–224. https://doi.org/10.30842/alp2306573716105.Suche in Google Scholar
Georgakopoulos, Thanasis, Eliese-Sophia Lincke, Kiki Nikiforidou & Anna Piata. 2020. On the polysemy of motion verbs in Ancient Greek and Coptic: Why lexical constructions are important. Studies in Language 44(1). 27–69. https://doi.org/10.1075/sl.18047.geo.Suche in Google Scholar
Glynn, Dylan. 2010. Corpus-driven cognitive semantics: Introduction to the field. In D. Glynn & K. Fischer (eds.), Quantitative Methods in cognitive semantics: Corpus-driven approaches, 1–42. Berlin & New York: Mouton de Gruyter.10.1515/9783110226423.1Suche in Google Scholar
Glynn, Dylan. 2016. Quantifying polysemy: Corpus methodology for prototype theory. Folia Linguistica 50(2). 413–447. https://doi.org/10.1515/flin-2016-0016.Suche in Google Scholar
Grady, Joseph E. 1997. Foundations of meaning: Primary metaphors and primary scenes. Cognitive linguistics bibliography (CogBib). University of California at Berkeley. (12 September 2024).Suche in Google Scholar
Gries, Stefan Th. 2006. Corpus-based methods and cognitive semantics: The many meanings of to run. In S. T. Gries & A. Stefanowitsch (eds.), Corpora in cognitive linguistics: Corpus-based approaches to syntax and lexis, 57–99. Berlin & New York: Mouton de Gruyter.10.1515/9783110197709.57Suche in Google Scholar
Gries, Stefan Th. 2010. Behavioral profiles: A fine-grained and quantitative approach in corpus-based lexical semantics. The Mental Lexicon 5(3). 323–346. https://doi.org/10.1075/ml.5.3.04gri.Suche in Google Scholar
Gries, Stefan Th. 2012. Behavioral profiles. Methodological and Analytic Frontiers in Lexical Research. 57–80. https://doi.org/10.1075/bct.47.04gri.Suche in Google Scholar
Gries, Stefan Th. & Dagmar Divjak. 2009. Behavioral profiles: A corpus-based approach to cognitive semantic analysis. In V. Evans & S. S. Pourcel (eds.), New directions in cognitive linguistics, 57–75. Amsterdam: John Benjamins.10.1075/hcp.24.07griSuche in Google Scholar
Gries, Stefan Th. & Dagmar Divjak. 2010. Quantitative approaches in usage-based cognitive semantics: Myths, erroneous assumptions, and a proposal. In Dylan Glynn & Kerstin Fischer (eds.), Quantitative Methods in cognitive semantics: Corpus-driven approaches, 333–354. Berlin & New York: Mouton de Gruyter.10.1515/9783110226423.331Suche in Google Scholar
Gries, Stefan Th. & Naoki Otani. 2010. Behavioral profiles: A corpus-based perspective on synonymy and antonymy. ICAME Journal 34. 121–150.Suche in Google Scholar
Gross, Derek, Ute Fischer & George A. Miller. 1989. The organization of adjectival meanings. Journal of Memory and Language 28(1). 92–106. https://doi.org/10.1016/0749-596x(89)90030-2.Suche in Google Scholar
Gundel, Jeanette K., Hedberg Nancy & Ron Zacharski. 1993. Cognitive status and the form of referring expressions in discourse. Language 69. 274–307. https://doi.org/10.2307/416535.Suche in Google Scholar
Harris, Zellig S. 1954. Distributional structure. WORD 10(2–3). 146–162. https://doi.org/10.1080/00437956.1954.11659520.Suche in Google Scholar
Huang (黃姵文), Pei-Wen & Alvin Cheng-Hsien Chen (陳正賢). 2022. Degree adverbs in spoken Mandarin: A behavioral profile corpus-based approach to language alternatives. Concentric 48(2). 285–322.10.1075/consl.22002.cheSuche in Google Scholar
Jansegers, Marlies & Stefan Th. Gries. 2020. Towards a dynamic behavioral profile: A diachronic study of polysemous sentir in Spanish. Corpus Linguistics and Linguistic Theory 16(1). 145–187. https://doi.org/10.1515/cllt-2016-0080.Suche in Google Scholar
Jansegers, Marlies, Clara Vanderschueren & Renata Enghels. 2015. The polysemy of the Spanish verb sentir: A behavioral profile analysis. Cognitive Linguistics 26(3). 381–421. https://doi.org/10.1515/cog-2014-0055.Suche in Google Scholar
Jones, Steven. 2002. Antonymy: A corpus-based perspective. London: Routledge.10.4324/9780203166253Suche in Google Scholar
Jones, Steven, Lynne M. Murphy, Carita Paradis & Caroline Willners. 2012. Antonyms in English: Construals, Constructions and canonicity. Cambridge: Cambridge University Press.10.1017/CBO9781139032384Suche in Google Scholar
Justeson, John S. & Slava M. Katz. 1991. Co-occurrences of antonymous adjectives and their contexts. Computational Linguistics 17(1). 1–19.Suche in Google Scholar
Kostić, Nataša. 2015. Antonymy in cognitive semantics. In Conference Proceedings from the 5th international Conference of the Institute of foreign Languages and the Society of applied Linguistics of Montenegro. Institute of Foreign Languages.Suche in Google Scholar
Kotzor, Sandra. 2021. Antonyms in Mind and brain: Evidence from English and German. London: Routledge.10.4324/9781003026969Suche in Google Scholar
Levshina, Natalia. 2015. How to do linguistics with R: Data exploration and statistical analysis. Amsterdam: John Benjamins.10.1075/z.195Suche in Google Scholar
Liddell, Henry G. & Robert Scott. 1996. A Greek-English lexicon [revised and complemented throughout by Henry Stuart Jones]. Oxford: Clarendon Press.Suche in Google Scholar
Liu, Meili. 2022. Towards a dynamic behavioral profile of the Mandarin Chinese temperature term re: A diachronic semasiological approach. In Corpus Linguistics and linguistic theory. Berlin & New York: Mouton de Gruyter.10.1515/cllt-2021-0046Suche in Google Scholar
Liu, Zhibo & Juhua Dou. 2023. Lexical density, lexical diversity, and lexical sophistication in simultaneously interpreted texts: A cognitive perspective. Frontiers in Psychology 14. https://doi.org/10.3389/fpsyg.2023.1276705.Suche in Google Scholar
Liu, Dilin & Maggie Espino. 2012. Actually, genuinely, really, and truly: A corpus-based behavioral profile study of near-synonymous adverbs. International Journal of Corpus Linguistics 17(2). 198–228. https://doi.org/10.1075/ijcl.17.2.03liu.Suche in Google Scholar
Lyons, John. 1977. Semantics, Vol. I. Cambridge: Cambridge University Press.Suche in Google Scholar
Miller, George A. & Christiane Fellbaum. 1991. Semantic networks of English. Cognition 41(1–3). 197–229. https://doi.org/10.1016/0010-0277(91)90036-4.Suche in Google Scholar
Montanari, Franco. 2015. The Brill dictionary of ancient Greek. Available at: https://dictionaries.brillonline.com/search#dictionary=&id=.Suche in Google Scholar
Muehleisen, Victoria. 1997. Antonymy and semantic range in English. Northwestern University Unpublished Ph.D. dissertation.Suche in Google Scholar
Murphy, Lynne M. 2003. Semantic relations and the lexicon: Antonymy, synonymy and other paradigms. Cambridge: Cambridge University Press.10.1017/CBO9780511486494Suche in Google Scholar
Murphy, Gregory L. & Jane M. Andrew. 1993. The conceptual basis of antonymy and synonymy in adjectives. Journal of Memory and Language 32. 301–319. https://doi.org/10.1006/jmla.1993.1016.Suche in Google Scholar
Paradis, Carita. 2011. A dynamic construal approach to antonymy. Selected Papers on Theoretical and Applied Linguistics 19. 33–42. https://doi.org/10.26262/ISTAL.V19I0.5477.Suche in Google Scholar
Paradis, Carita & Caroline Willners. 2011. Antonymy: From convention to meaning-making. Review of Cognitive Linguistics 9(2). 367–391. https://doi.org/10.1075/rcl.9.2.02par.Suche in Google Scholar
R Core Team. 2022. R: A language and environment for statistical computing. Vienna: R Foundation for Statistical Computing.Suche in Google Scholar
Sullivan, Karen. 2012. It’s hard being soft: Antonymous senses versus antonymous words. The Mental Lexicon 7(3). 306–325. https://doi.org/10.1075/ml.7.3.03sul.Suche in Google Scholar
Syrpa, Panagiota. 2020. Dimensional adjectives in cognitive linguistics: The case of big. Thessaloniki: Aristotle University of Thessaloniki Ph.D. dissertation.Suche in Google Scholar
Yu, Ning, Yu Lu & Christine Lee Yue. 2017. Primary metaphors: Importance as size and weight in a comparative perspective. Metaphor and Symbol 32(4). 231–249. https://doi.org/10.1080/10926488.2017.1384276.Suche in Google Scholar
Zeschel, Arne. 2010. Exemplars and analogy: Semantic extension in constructional networks. In Dylan Glynn & Kerstin Fischer (eds.), Quantitative methods in cognitive semantics: Corpus-driven approaches, 201–219. Berlin & New York: Mouton de Gruyter.10.1515/9783110226423.201Suche in Google Scholar
© 2025 the author(s), published by De Gruyter, Berlin/Boston
This work is licensed under the Creative Commons Attribution 4.0 International License.