The distribution of /w/ and /ʍ/ in Scottish Standard English
-
Zeyu Li

 and
Ulrike Gut
and
Ulrike Gut

Abstract
The Scottish English phoneme inventory is generally claimed to have a /ʍ/-/w/ contrast, although several studies have suggested that this historical contrast is weakening for Scottish English speakers in the urban areas of Glasgow, Edinburgh and Aberdeen. Little is known about whether the /ʍ/-/w/ contrast is maintained in supraregional Scottish Standard English (SSE). This study sets out to explore, based on the phonemically transcribed ICE-Scotland corpus, the distribution of [ʍ] and [w] in SSE, their acoustic properties and potentially influencing social and language-internal factors. A total of 1,241 <wh-> tokens were extracted from the corpus, together with a matching number of <w-> tokens, and the median of harmonicity was measured. The results show that [ʍ] and [w] produced for words beginning with <wh-> are acoustically distinct from [w] produced for words beginning with <w->. [ʍ] is relatively frequent in SSE, but most speakers use both [ʍ] and [w] interchangeably for <wh-> and some never use [ʍ]. The realisation of <wh-> as [ʍ] is determined by preceding phonetic context and speaker gender.
1 Introduction
In Scottish English, like in some varieties of Irish, US American and Canadian English, the so-called wine-whine merger did not take place, in which historical Old and Middle English /hw/ was replaced by /w/ (Grant 1914: 38; Minkova 2012: 16). Consequently, Scottish English still has the voiceless labial-velar fricative /ʍ/ (Giegerich 1992: 36; Jones 2002: 27; Stuart-Smith 2008: 63; Wells 1982: 408), which is used to pronounce the digraph <wh> in many words such as which, when and what.[1] This results in Scottish English, unlike most other varieties of English, having minimal pairs such as which versus witch, where versus wear and whales versus Wales. Minkova argues that the /ʍ/-/w/ contrast has become a recessive feature in Southern British English since late Old English but was maintained in the north and Scotland mostly due to external motivations such as “literacy, prestige, dialect borrowing, and word frequency” (2012: 35). Some southern speakers even redeveloped the contrast in the sixteenth and seventeenth century due to language contact with Scots pronunciation, which had enjoyed prestige at that time (Minkova 2012: 27–29).
However, it appears that the historical /w/-/ʍ/ contrast is weakening for an increasing number of Scottish English speakers. As early as in the 1980s, Macafee (1983: 32) noted that some speakers in Glasgow use either [ʍ] or [w] in words beginning with <wh->, which Stuart-Smith (2008: 63) confirms with Glasgow data from 1997. Likewise, Johnston (1997: 507) and Chirrey (1999: 227) reported that, at the end of the last century, only some speakers in Edinburgh were consistent in maintaining the /ʍ/-/w/ contrast, while others rather unpredictably varied between these two phonemes. By the beginning of the twenty-first century, Schützler found that /ʍ/ was realised as both [w] and [ʍ] by all Edinburgh speakers in his study (2010). Similarly, in Aberdeen, all the speakers analysed by Brato (2007, 2014 produce both [ʍ] and [w] in words beginning with <wh->.
Chirrey (1999) suggests that this eroding contrast “has a considerable time-depth”, as Edinburgh speakers as old as 73 did not fully preserve the contrast, and significant differences in the use of /ʍ/ and /w/ between older and younger speakers are consistently found across Scotland today: this holds true for the towns of Livingston (Robinson 2005), Glasgow (Timmins et al. 2004), Aberdeen (Brato 2014), and Edinburgh (Schützler 2010), where the younger speakers produce both /ʍ/ and /w/ for <wh->, while older speakers use fewer [w] for <wh-> than the younger ones. Interestingly, younger Glasgow speakers also occasionally produce [ʍ] for /w/ in words such as wear, weather, wine and word (Timmins et al. 2004).
The realisation of the /ʍ/-/w/ contrast in Scottish English is further influenced by the social factors class and gender. In the 27 middle-class Edinburgh speakers analysed by Schützler (2010), gender differences became apparent with a greater erosion of the /ʍ/ – /w/ contrast for male than for female speakers. In a project carried out in Glasgow, speech from 32 socially-stratified speakers, balanced for age and gender was collected and it was found that middle-class speakers, both adolescents and older speakers, use /ʍ/ more frequently than working-class speakers. Middle-class men in particular strongly favour the /ʍ/ variant, while working-class boys and girls show a very low use of /ʍ/ (Lawson and Stuart-Smith 1999; Stuart-Smith et al. 2007; Timmins et al. 2004). The same distribution across speakers of different classes was also found by Brato (2014) in his socially-stratified sample of 44 Aberdeen speakers.
In addition to sociolinguistic predictors for /ʍ/, Schützler (2010) and Brato (2014) also found language-internal factors influencing the realisation of the /ʍ/-/w/ contrast. Their findings show that the /ʍ/ variant favours stressed syllables and the postpausal position, which they explain by “the slightly more effortful /ʍ/” being more easily pronounced, least influenced by coarticulatory factors and receiving more attention with a preceding pause compared to an utterance-medial position (Brato 2014: 40; Schützler 2010: 15). More specifically, Schützler argued that the pre-aspiration effect of [ʍ] tends to be more pronounced in stressed syllables than in unstressed ones, and that the requirement of a pulmonic impulse in articulating [ʍ] favours a preceding pause, which allows speakers to produce it more easily.
While the speech of socially diverse Scottish speakers in the urban centres is well researched, including middle-class speakers from Edinburgh, Aberdeen and Glasgow, little is still known about whether the /ʍ/-/w/ contrast is maintained in the speech of other middle-class Scottish English speakers from other regions of Scotland as well. We would like to investigate middle-class speech from all over Scotland, which we refer to as Scottish Standard English (SSE) here. Nor does any prior research exist that explores whether the influencing factors, both social and linguistic, found for various types of urban Scottish English also determine the distribution of /w/ and /ʍ/ in the SSE. While many authors claim that the /ʍ/-/w/ contrast is present in contemporary SSE (Giegerich 1992: 36; Jones 2002: 27; Stuart-Smith 2008: 63), to the best of our knowledge, no empirical studies have been carried out so far to substantiate this. It is thus the first aim of this study to explore, based on a large corpus of SSE, whether the /ʍ/-/w/ contrast is maintained by SSE speakers. Some first evidence for a larger presence of /ʍ/ in the standard variety in Scotland might be deduced from those studies of urban Scottish English that compared two or more speaking styles differing in the level of formality. Some of them found that in the most formal speaking style, i.e. word lists, in which the speakers’ target pronunciation presumably is closest to the standard due to a high level of attention given to the pronunciation of each word, more [ʍ] are produced than in less formal styles such as passage reading and conversations (Brato 2007). Stuart-Smith et al. (2007) further found that the social factors of class and age as well as an age*gender interaction only significantly influenced the realisation of <wh-> words in Glaswegian speech in the conversations but not in the word lists (where all speakers produced more [ʍ] than [w]), which points to an underlying representation of a prestigious accent of Scottish English that is shared by Scottish speakers and that surfaces in formal contexts. Our first hypothesis to be tested therefore is that [ʍ] is realised frequently for <wh-> in SSE and that many SSE speakers maintain a systematic contrast between /ʍ/ and /w/.
2 Acoustic properties of [ʍ]
In the literature, there is little consensus on the exact articulation of /ʍ/ in Scottish English: while Giegerich (1992: 36) refers to it as a voiceless bilabial fricative, Wells (1982: 408) classifies the consonant as a voiceless labial-velar fricative, but also suggests representing it as the diphone /hw/ or /xw/. By contrast, Robinson (2005: 186f.) defines it as a “voiceless lip-rounded consonant with audible friction at both velar and bilabial articulations”. Schützler (2010: 13), finally, describes the phonetic realisation of /ʍ/ as “a hybrid between an approximant and a fricative [that] can be interpreted as the combination of a voiced and a voiceless component, or at least as a partially devoiced approximant, thus: [xw]<[hw]< [w̥].”
All empirical studies on the realisation of the /ʍ/-/w/ contrast that have been carried out so far have observed ‘mixed’ or ‘in-between’ realisations of /ʍ/ in their auditory analyses (e.g. Brato 2007, 2014 for Aberdeen speakers[2]). Robinson (2005: 187), for instance, reports on realisations of /ʍ/ by Livingston speakers as a predominantly voiceless fricative with less bilabial articulation, which she referred to as [hʍ]. Timmins et al. (2004) and Stuart-Smith et al. (2007) found breathy-voiced labial velar approximants, which they labelled [wh], “a category of variants which sounded as if they were neither properly [w] nor [hw]” (Timmins et al. 2004: 16) and which also acoustically fell between the two sounds.
However, only one study so far has analysed the acoustic properties of the different realisations of /ʍ/ and /w/ in Scottish English. Lawson and Stuart-Smith (1999: 2543) found for Glaswegian teenagers aged 13–14 that [ʍ] often, but not always, showed a period of voiceless friction before the abrupt onset of the first (F1) and second (F2) formants. In those cases where no friction was visible in the spectrogram, sometimes the abrupt start of F1 and F2 was still found. The acoustic properties of [w] consisted of a low F1 with a low, weaker F2 and without any period of voiceless friction, while the ‘mixed’ categories that were observed in the auditory analyses did not seem to have any consistent acoustic correlates.
It is the second aim of this study to further explore the acoustic properties of the realisations of [ʍ] and [w] in SSE. We will test the hypothesis that in SSE a voiceless friction part will be consistently used for [ʍ], but not for [w] (Lawson and Stuart-Smith 1999: 2543). Moreover, we will hypothesise that the acoustic properties of [ʍ] and [w] are clearly distinct in SSE.
3 Aim and hypotheses
The aim of this study is to investigate the realisation of /ʍ/ and /w/ in SSE. While an ongoing /ʍ/-/w/ merger and its determining factors social class, age and gender as well as phonetic context have been found for various urban varieties of Scottish English, their actual realisation and distribution in contemporary SSE are still largely unknown. The present study will try to fill this research gap by testing the following hypotheses:
/ʍ/ is largely present in SSE as claimed in Giegerich (1992: 36), Jones (2002: 27) and Stuart-Smith (2008: 63).
There will be measurable voiceless friction for [ʍ], and the acoustic properties of [ʍ] and [w] will be distinct as suggested by Lawson and Stuart-Smith (1999: 2543).
Both the social factors age and gender and language-internal phonetic factors influence the distribution of [ʍ] and [w] as found by Schützler (2010) and Brato (2014).
4 Method
The data were drawn from ICE-Scotland, the Scottish component of the International Corpus of English project (ICE; Greenbaum 1991) that aims to collect comparable corpora of all national varieties of English spoken around the world. ICE-Scotland is currently being compiled at the University of Münster (Schützler et al. 2017) and constitutes the first corpus of the ICE corpora family to contain time-aligned phonemic transcriptions. These were created in a two-step process: first, automatic phonemic annotations in SAMPA were created using WebMAUS (Schiel 2004) and were subsequently corrected manually by a team of five independent phonetically-trained transcribers including the two authors of this article. During the manual correction, misplaced phoneme boundaries were adjusted, missing or superfluous phonemes were inserted or removed respectively and incorrect SAMPA labels were corrected. Furthermore, each <wh-> token was analysed auditorily for two rounds. A binary choice was made between the realisation of [w] and [ʍ] perceptually by a transcriber in the first round, and the second author checked all the transcriptions and corrected them whenever necessary. The sound quality was relatively good as only formal contexts were included for analysis.
As this study targets SSE and we expect it to be most likely to obtain speech that maintains the /ʍ/ – /w/ contrast in formal contexts (see also Douglas 2020), only the following text categories of ICE-Scotland were searched: broadcast discussions, broadcast interviews, broadcast news and broadcast talks, legal presentations, demonstrations, non-broadcast talks, unscripted speeches as well as parliamentary debates.[3] It is noteworthy that there is a likelihood that many speakers in this sub-corpus might have moderately to strongly anglicised speech in comparison with general middle-class Scottish population. After excluding all speakers who produced fewer than two <wh-> words and those for whom no information on their age is available, the final dataset comprised 138 speakers (aged 17–70, originating from all over Scotland, of whom 64 are female). They produced a total of 1,388 words containing initial <wh->.
The degree of acoustic periodicity of each token was measured by extracting the median of harmonicity (also referred to as harmonics-to-noise ratio, see e.g., Boersma 1993) using Praat (Boersma and Weenink 2017), which expresses the relationship between voiced (harmonic) and friction (noise) parts in a sound. Following Hamann and Sennema (2005), the median of harmonicity was measured with time steps of 0.01 s, a minimum pitch of 75 Hz, a silence threshold of 0.1 and 1 period per window. A value of 20 dB means that nearly all of the energy lies in the harmonic part, while for 0 dB the energy in the sound signal is equally distributed between voicing and friction. Twenty-three of the <wh-> tokens had to be excluded because of background noise or speaker overlap, which prevented a reliable acoustic analysis. A further 124 tokens had to be excluded because Praat yielded no values or values that had to be interpreted as measurement errors. Thus, the final token number of measured tokens of <wh-> words is 1,241 (see Appendix for a list of lexical items).
Furthermore, a matching number of tokens with initial <w-> (as e.g. in water and went) was extracted from the corpus. We attempted to include for each speaker an equal number of words beginning with <w->, matched in terms of preceding context (pausal or non-pausal) to the <wh-> words they had produced. However, this was not possible in all cases, as especially the necessary amount of post-pausal /w/ were not always available. The median of harmonicity of each <w-> token was also extracted using Praat, with measurement errors being excluded. There are 1,227 tokens of <w-> in the final dataset.
For the statistical analysis, linear mixed-effects regression models with median of harmonicity as dependent variable, and speaker and word as random intercepts were used. Fixed predictors including the social factors age and gender (m/f) and the internal factors preceding/following phonetic context as well as the presence of script were tested. Preceding phonetic context was coded as either pause, voiced and voiceless; the following phonetic context as either the dress vowel as in the word when, the kit vowel as in which, the lot vowel as in what and the price vowel as in why. Furthermore, the ICE text categories were divided into scripted (e.g., broadcast news) and unscripted (e.g., broadcast interviews). The models were fitted using the R-package {lme4} (Bates et al. 2015).
5 Results
Figure 1 compares the median of harmonicity of <wh-> and <w-> words observed in the data. Of the 1,241 <wh-> tokens, 37% had been transcribed in the corpus as [ʍ], while 63% had been transcribed as [w]. The pronunciation of all of the <w-> words extracted from the corpus had been transcribed as [w]. As Figure 1 shows, the realisation of [ʍ] for <wh-> displays the lowest harmonicity values (mean = 5.48, sd = 3.62, n = 464), which is followed by <wh-> tokens produced as [w] (mean = 9.02, sd = 4.64, n = 785), with <w-> tokens showing the highest median of harmonicity (mean = 10.47, sd = 4.56, n = 1,227). There were statistically significant differences between the mean values of the three groups as determined by a one-way ANOVA (F(2, 2,473) = 214, p < 0.001, ω 2 = 0.147). Post hoc testing shows that the degree of median of harmonicity of [ʍ] is significantly lower than that of both <wh-> words transcribed in the corpus as [w] (p < 0.001, Cohen’s d = -0.275) and <w-> words (p < 0.001, Cohen’s d = -0.416). However, Cohen’s d shows that the differences between the values of <wh->-[w] and <w-> tokens have a very small effect size (p < 0.001, Cohen’s d = -0.143).
![Figure 1:
Median of harmonicity for <wh-> words (transcribed in the corpus as [ʍ] and [w] respectively) and <w-> words.](/document/doi/10.1515/cllt-2021-0052/asset/graphic/j_cllt-2021-0052_fig_001.jpg)
Median of harmonicity for <wh-> words (transcribed in the corpus as [ʍ] and [w] respectively) and <w-> words.
The /ʍ/-/w/ contrast in SSE was further analysed with a mixed-effects linear regression model in R using lme4 package in order to investigate potential language-internal and external factors affecting their distribution and acoustic properties. Table 1 illustrates the potential effects of label (i.e. transcription in the corpus), age, gender, preceding context, following context and presence of script in predicting the median of harmonicity of the tokens. The results of the full model show that three factors, both linguistic and social, exerted statistically significant effects: label, gender and preceding context. The effects of age, following context and presence of script, on the other hand, did not reach statistical significance. Figures 2 –6 show the effects of these factors on the acoustic properties of <wh-> tokens predicted by the model.
Linear mixed effect regression model of median of harmonicity as dependent variable, with speaker and word as random intercepts.
| Fixed effects | Levels | Estimate | Std. error | t-value | p < | |
|---|---|---|---|---|---|---|
| (Intercept) | 7.276 | 0.923 | 7.887 | 0.000 | *** | |
| label | /w/ | 3.011 | 0.253 | 11.900 | 0.000 | *** |
| age | −0.031 | 0.016 | −1.946 | 0.054 | ||
| gender | male | −1.086 | 0.399 | −2.719 | 0.007 | ** |
| preceding context | voiced | 1.781 | 0.247 | 7.217 | 0.000 | *** |
| voiceless | 0.628 | 0.341 | 1.841 | 0.066 | ||
| following context | kit | −1.197 | 0.738 | −1.622 | 0.175 | |
| lot | 0.444 | 0.617 | 0.719 | 0.497 | ||
| price | −0.445 | 0.615 | −0.725 | 0.485 | ||
| presence of script | unscripted | −0.248 | 0.382 | −0.648 | 0.518 | |
|
|
||||||
| Random effects | Type | Variance | Std. Dev | |||
|
|
||||||
| speaker | (Intercept) | 2.5453 | 1.5954 | |||
| word | (Intercept) | 0.4407 | 0.6639 | |||
|
|
||||||
| Min. | Median | Max. | ||||
|
|
||||||
| Scaled residuals | −3.110 | −0.001 | 3.233 | |||
-
Levels of significance: p < .05 (*), p < .01 (**), p < .001 (***).
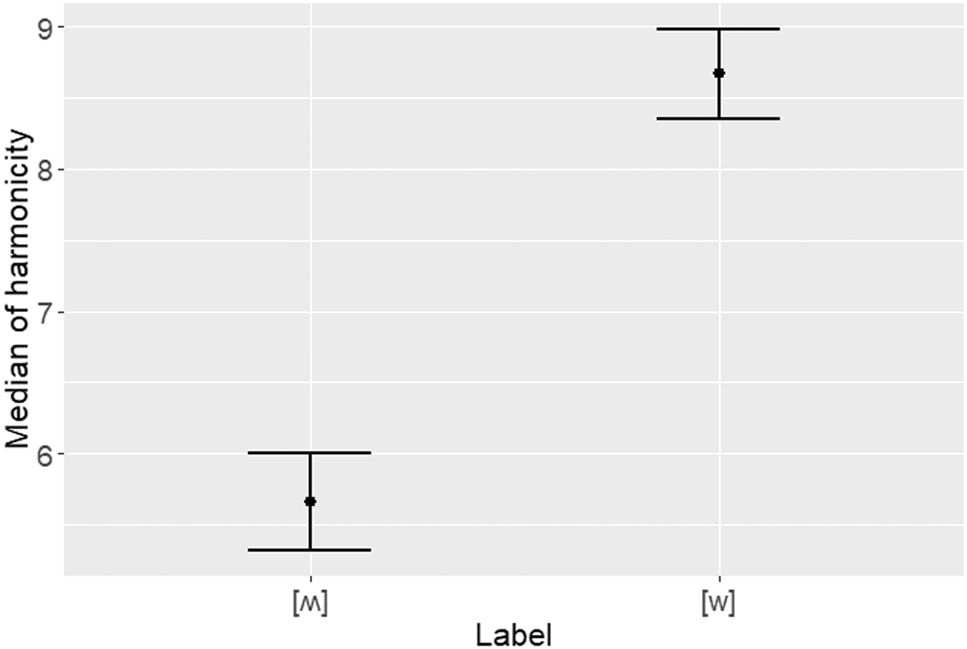
label and the acoustic properties of <wh-> tokens.
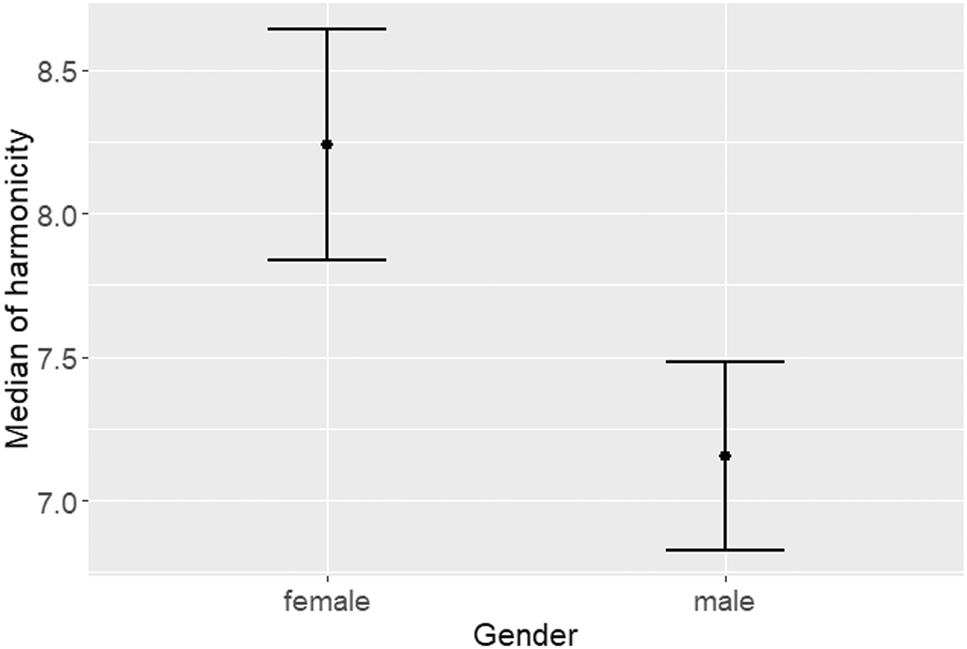
Effects of gender on the acoustic properties of <wh-> tokens.
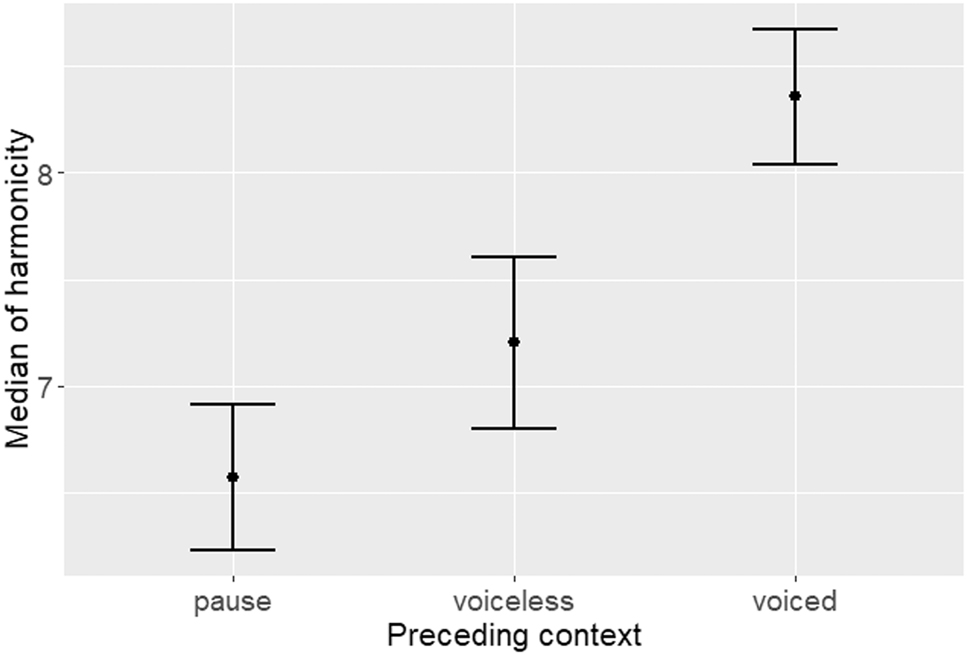
Effects of preceding context on the acoustic properties of <wh-> tokens.
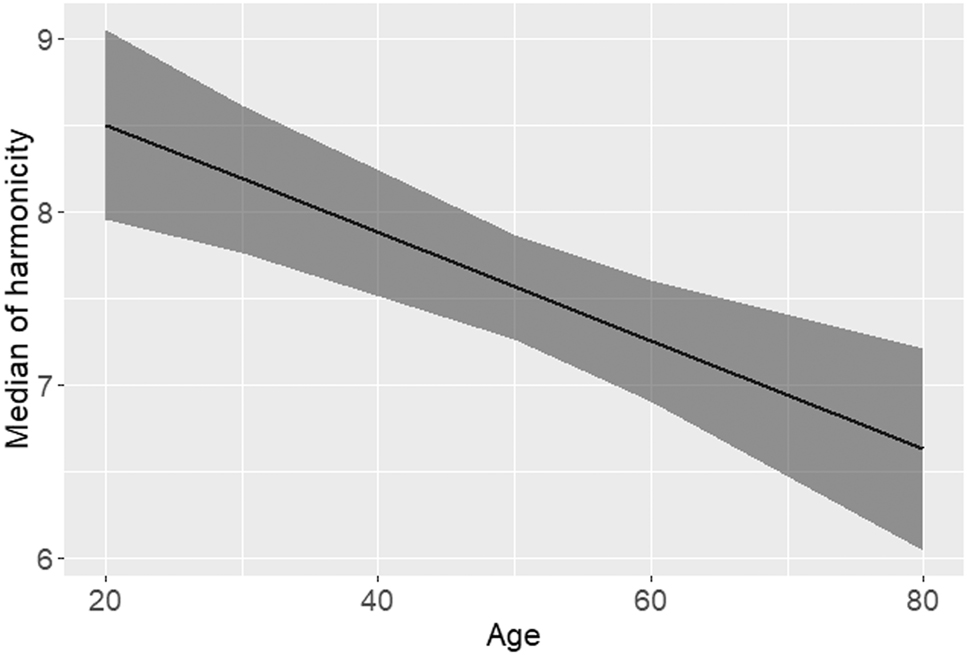
Effects of age on the acoustic properties of <wh-> tokens.
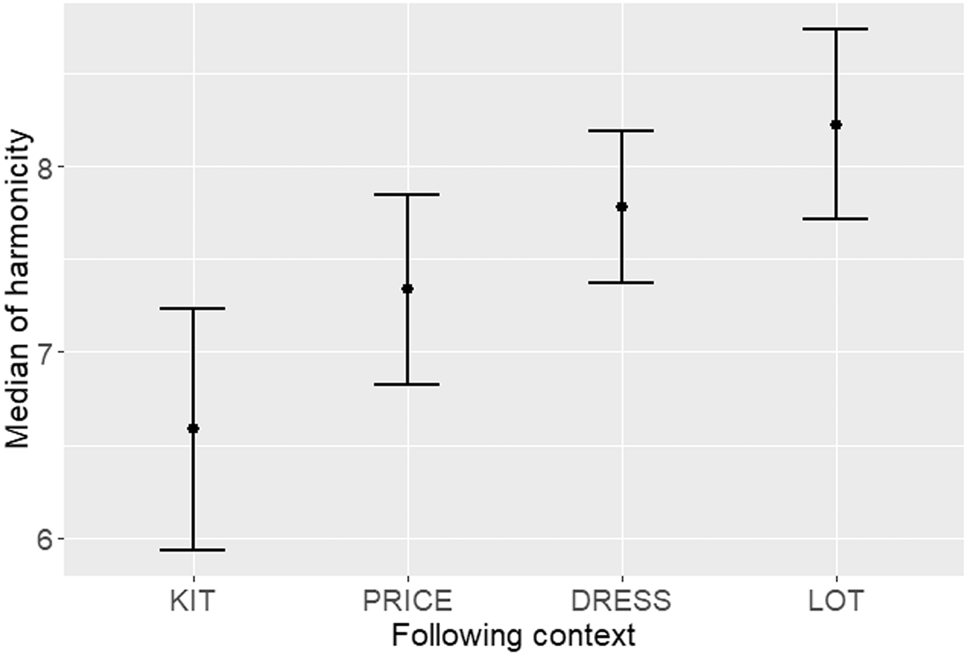
Effects of following context on the acoustic properties of <wh-> tokens.
Figure 2 shows that the acoustic properties measured for all <wh-> words are perfectly in line with their labels, i.e. the transcriptions in the corpus that had been made based on an auditory analysis of the data. Thus, the <wh-> tokens transcribed as [w] and [ʍ] respectively have distinct degrees of median of harmonicity, with the values of [w] being significantly higher than those of [ʍ] (p < 0.001).
Figure 3 illustrates that the acoustic properties of the initial consonant of <wh-> words are further constrained by speaker gender. More specifically, female speakers produced a significantly higher median of harmonicity, thus more [w]-like realisations containing less friction, than their male counterparts (p = 0.007).
The results of the mixed effects model show that the language-internal predictor preceding context also plays a statistically significant role in predicting the degree of median of harmonicity of the <wh-> words produced by SSE speakers. Figure 4 shows that [ʍ] is most likely preceded by a pause, followed by the preceding context of a voiceless sound, while a preceding voiced context does not promote the production of [ʍ] (p < 0.001).
The factors age, following context and presence of script did not reach statistical significance in the model. However, Figure 5 illustrates a tendency of the median of harmonicity to decrease with increasing speaker age. Older speakers tend to produce more [ʍ] compared with younger speakers.
Equally, Figure 6 suggests potential effects of the following context on the realisation of <wh-> words. The production of [ʍ] is favoured when followed by a kit vowel (e.g. in which). Following price (e.g. in why, while), dress (e.g. in when, where) or lot (e.g. in what) constitute less promoting contexts for the realisation of <wh-> as [ʍ].
Figure 7 shows the realisation of <wh-> and <w-> words by individual speakers observed in the data. For this, we selected those 41 speakers who produced at least ten <wh-> tokens in the corpus.
![Figure 7:
Individual realisations of <wh-> words transcribed as [w], <wh-> words transcribed as [ʍ] and all <w-> words in the corpus.](/document/doi/10.1515/cllt-2021-0052/asset/graphic/j_cllt-2021-0052_fig_007.jpg)
Individual realisations of <wh-> words transcribed as [w], <wh-> words transcribed as [ʍ] and all <w-> words in the corpus.
As can be seen in Figure 7, considerable inter-speaker variation exists in the realisation of <wh-> and <w-> words. Among the 41 speakers, 36 produced both [w] and [ʍ] for <wh-> words, with [ʍ] typically having a lower median of harmonicity than [w], except for s107, s29, s7, s96 and s98, where no acoustic difference between their [w] and [ʍ] realisations for <wh-> words was found. Furthermore, for most speakers [w] produced for <wh-> words is acoustically different from [w] for <w-> words. To be more specific [w] occurring in <wh-> words showed a lower median of harmonicity than [w] occurring in <w-> words (except for s21 and s29). The speakers seemed to consistently maintain measurable voiceless friction in producing [w] for <wh-> words, but not for <w-> words.
The remaining five speakers did not produce [ʍ] at all for <wh-> words (s116, s117, s122, s26 and s62) and thus merged /ʍ/ and /w/ entirely in their speech. Interestingly, unlike those who maintained the contrast [w] produced by these five speakers showed very similar acoustic properties for <wh-> and <w-> words. Specifically, both were characterised by a relatively high degree of median of harmonicity that is having very little friction in their consonants. S62 even showed a higher median of harmonicity for <wh-> than for <w->. As the five speakers are of different genders, from different age groups and regions, there is nothing obvious to explain the observed patterning.
6 Discussion
This study investigated the presence of the /ʍ/-/w/ contrast and their acoustic properties in the formal text categories of ICE-Scotland. The results show that our first hypothesis, i.e. that /ʍ/ is still present in the Standard Scottish variety of English as claimed in Giegerich (1992: 36), Jones (2002: 27) and Stuart-Smith (2008: 63) can be confirmed: 37% of the auditorily analysed <wh-> tokens were realised with the traditional [ʍ] variant. However, significant inter-speaker variability was found in the corpus. About 12% of the SSE speakers seem to have a complete merger of /ʍ/ and /w/, producing [w] categorically for all <wh-> words. All of the other speakers produced both [w] and [ʍ] in words beginning with <wh->, thus showing no difference between these SSE speakers and the middle-class speakers from Edinburgh and Aberdeen studied by Schützler (2010) and Brato (2007, 2014. It is important to note that none of the speakers in the corpus exclusively used the traditional variant [ʍ] for <wh->, which would have reflected the maintenance of the traditional Scottish /w/-/ʍ/ contrast.[4] The speech of the speakers of the standard variety of English spoken in Scotland thus evidences an ongoing merger of /w/ and /ʍ/. In other words, it appears that [ʍ] is only one variant of realising <wh-> for the speaker group studied here.
The results of the acoustic analyses of the corpus confirm our second hypothesis, which predicted that [ʍ] and [w] have distinct acoustic properties, with more friction being produced for [ʍ] than for [w] in <wh-> words. However, the acoustic measurements also showed that [ʍ] and [w] are not categorically distinct and that a similar amount of friction can be found in some tokens that had been transcribed as [ʍ] and [w] in the corpus. We interpret this as corroboration of the impressionistic observations made by Stuart-Smith et al. (2007) and Timmins et al. (2004), who described variants of <wh-> that sounded “as if they were neither properly [w] nor [hw]” (Timmins et al. 2004: 16).
The most striking of the results of the acoustic analysis are however that, overall, there are significant, albeit small differences in the median of harmonicity between a [w] occurring in <wh-> and in <w-> words. Thus [w] when produced by an SSE speaker at the beginning of witch differs acoustically from [w] being produced at the beginning of which. This finding suggests that SSE speakers do make a difference between <wh-> and <w-> words, even if they do not produce a distinctly voiceless labiovelar fricative in all instances of the <wh-> words. It is worth mentioning that the observed difference between [w] realised in <wh-> and <w-> words can only be found for SSE speakers who alternate between [ʍ] and [w] for <wh-> words. Those that completely merged /ʍ/ and /w/, on the other hand, showed similar acoustic properties of [w] occurring in <wh-> and <w-> words. Future research could investigate whether this acoustic difference between ‘different kinds of [w]’ also exists in other varieties of Scottish English. The assumption that this is some way triggered by the orthographic differences between <wh-> and <w-> words, however, cannot be confirmed by the results of our corpus analysis. When comparing the realisation of <wh-> words in free speech to scripted speech, i.e. texts being read out by speakers as in the category broadcast news, no acoustic differences were found.
The third research aim of the present study was to explore possible social and language-internal factors influencing the realisation and distribution of [ʍ] and [w] in SSE. The output of our statistical model shows that both speakers’ gender and preceding phonetic contexts exert main effects on predicting the acoustic patterns of [ʍ]. In terms of gender, male speakers produced a significantly lower degree of median of harmonicity, thus more instances of [ʍ], than their female counterparts. This shows that gender plays a similar role in SSE to middle-class Glasgow English, where men strongly favour the production of the /ʍ/ variant (Lawson and Stuart-Smith 1999; Stuart-Smith et al. 2007; Timmins et al. 2004). Gender, however, seems to influence SSE differently than the Edinburgh speakers studied by Schützler (2010), who reported that male speakers in Edinburgh tend to merge /ʍ/ and /w/.
Our results further show that the realisation of [ʍ] in SSE is constrained by a linguistic factor, namely preceding phonetic context. A preceding pause or a preceding voiceless sound was found to favour the production of /ʍ/, with a preceding voiced context being the least promoting of the variant. This corroborates the findings of Schützler (2010) and Brato (2014) for Edinburgh and Aberdeen speakers that the /ʍ/ variant favours postpausal position since “a pause preceding /ʍ/ will give the speaker time to articulate the slightly more effortful [ʍ]” (Schützler 2010: 15). It is also unsurprising that the voiceless preceding context favours the realisation of /ʍ/ since phonetically there is a measurable voiceless friction for [ʍ].
Although the effects of age did not reach statistical significance in our model, there is a tendency for older SSE speakers to produce more /ʍ/ variants than younger speakers. This finding suggests similar effects of age on SSE to was found for the English spoken by Scots in Livingston (Robinson 2005), Glasgow (Timmins et al. 2004), Aberdeen (Brato 2014) and Edinburgh (Schützler 2010), where /ʍ/ was consistently shown to be favoured by older speakers and younger speakers generally appeared insensitive to the /ʍ/-/w/ contrast.
7 Conclusion
This study constitutes the first corpus-based study of the phonological and phonetic properties of /ʍ/ and /w/ in SSE. It has shown that phonemically annotated corpora can prove a precious source for the analysis of the properties of accents of English. We were able to confirm with acoustic measurements not only previous impressionistic observations of ‘mixed’ or ‘in-between’ realisations of [ʍ] and [w], but also found the first evidence of acoustic differences between [w] realised for <wh-> and for <w-> in SSE. Our finding suggests that most speakers do maintain a representational, i.e. phonemic difference between /ʍ/ and /w/ although this might be almost merged for some on the phonetic level.
Funding source: German Research Council
Award Identifier / Grant number: DFG; GU 548/13-1
Acknowledgements
We are very grateful for the insightful comments by our two reviewers on an earlier version of this article.
-
Research funding: This research was funded by the German Research Council (DFG; GU 548/13-1).
Appendix: Word frequency list
| Word | Frequency | Percent |
|---|---|---|
| What | 330 | 26.5 |
| Which | 325 | 26.1 |
| When | 199 | 16 |
| Where | 126 | 10.2 |
| Why | 66 | 5.4 |
| Whether | 42 | 3.4 |
| What’s | 30 | 2.4 |
| While | 28 | 2.3 |
| Whatever | 13 | 1 |
| Whilst | 9 | 0.7 |
| Anywhere | 6 | 0.5 |
| Meanwhile | 6 | 0.5 |
| Elsewhere | 5 | 0.4 |
| Whisky | 5 | 0.4 |
| Somewhere | 4 | 0.3 |
| White | 4 | 0.3 |
| White | 3 | 0.2 |
| White’s | 2 | 0.2 |
| Whitehouse | 2 | 0.2 |
| Whyte | 2 | 0.2 |
| Everywhere | 2 | 0.2 |
| Nowhere | 2 | 0.2 |
| Overwhelming | 3 | 0.2 |
| Somewhat | 3 | 0.2 |
| Whatsoever | 3 | 0.2 |
| Whereabouts | 2 | 0.2 |
| Whereby | 2 | 0.2 |
| Wherever | 3 | 0.2 |
| Whittled | 2 | 0.2 |
| Worthwhile | 2 | 0.2 |
| Whitehall | 1 | 0.1 |
| Whiting | 1 | 0.1 |
| Overwhelmingly | 1 | 0.1 |
| Whatsoever | 1 | 0.1 |
| Whenever | 1 | 0.1 |
| Where’d | 1 | 0.1 |
| Where’s | 1 | 0.1 |
| Whereas | 1 | 0.1 |
| Whined | 1 | 0.1 |
| Whispered | 1 | 0.1 |
| Total | 1,241 | 100 |
References
Bates, Douglas, Martin Mächler, Ben Bolker & Steve Walker. 2015. Fitting linear mixed-effects models using lme4. Journal of Statistical Software 67(1). 1–48. https://doi.org/10.18637/jss.v067.i01.Search in Google Scholar
Boersma, Paul. 1993. Accurate short-term analysis of the fundamental frequency and the harmonics-to-noise ratio of a sampled sound. Proceedings of the Institute of Phonetic Sciences, 17, 97–110. Amsterdam: University of Amsterdam.Search in Google Scholar
Boersma, Paul & David Weenink. 2017. Praat: Doing phonetics by computer [Computer program]. Version 6.0.31. Available at: http://www.praat.org/.Search in Google Scholar
Brato, Thorsten. 2007. Accent variation in adolescents in Aberdeen: First results for (hw) and (th). In Jürgen Trouvain & William Barry (eds.), Proceedings of the 16th International Congress of Phonetic Sciences, 1489–1492. Saarbrücken: Universität des Saarlandes.Search in Google Scholar
Brato, Thorsten. 2014. Accent variation and change in North-East Scotland: The case of (hw) in Aberdeen. In Robert Lawson (ed.), Sociolinguistics in Scotland, 32–51. Houndmill & New York: Palgrave Macmillan.10.1057/9781137034717_3Search in Google Scholar
Chirrey, Deborah. 1999. Edinburgh: Descriptive material. In Paul Foulkes & Gerard Docherty (eds.), Urban voices: Accent studies in the British Isles, 223–229. London: Arnold.Search in Google Scholar
Douglas, Fiona. 2020. English in Scotland. In Cecil L. Nelson, Zoya G. Proshina & Daniel R. Davis (eds.), Blackwell handbooks in linguistics. The handbook of world Englishes, 17–33. New York: John Wiley & Sons.Search in Google Scholar
Giegerich, Heinz. 1992. English phonology: An introduction. Cambridge: Cambridge University Press.10.1017/CBO9781139166126Search in Google Scholar
Grant, William. 1914. The pronunciation of English in Scotland. Cambridge: Cambridge University Press.Search in Google Scholar
Greenbaum, Sidney. 1991. ICE: The international corpus of English. English Today 7(4). 3–7. https://doi.org/10.1017/s0266078400005836.Search in Google Scholar
Hamann, Silke & Anke Sennema. 2005. Acoustic differences between German and Dutch labiodentals. ZAS Papers in Linguistics 42. 33–41. https://doi.org/10.21248/zaspil.42.2005.272.Search in Google Scholar
Johnston, Paul. 1997. Regional variation. In Charles Jones (ed.), The Edinburgh history of the Scots language, 433–513. Edinburgh: Edinburgh University Press.10.1515/9781474410977-013Search in Google Scholar
Jones, Charles. 2002. The English language in Scotland: An introduction to Scots. East Linton: Tuckwell Press.Search in Google Scholar
Lawson, Eleanor & Jane Stuart-Smith. 1999. A sociophonetic investigation of the ‘Scottish’ consonants (/x/ and /ʍ/) in the speech of Glaswegian children. Proceedings of the International Congress of Phonetic Sciences, 2541–2544. San Francisco: University of California, Berkeley.Search in Google Scholar
Macafee, Caroline. 1983. Glasgow. Amsterdam & Philadelphia: John Benjamins.10.1075/veaw.t3Search in Google Scholar
Minkova, Donka. 2012. Philology, linguistics, and the history of [hw]∼[w]. Studies in the history of the English language II, 7–46. Berlin & New York: De Gruyter Mouton.10.1515/9783110897661.7Search in Google Scholar
Robinson, Christine. 2005. Changes in the dialect of Livingston. Language and Literature 14(2). 181–193. https://doi.org/10.1177/0963947005051289.Search in Google Scholar
Schiel, Florian. 2004. MAUS goes iterative. Proceedings of the IV International Conference on Language Resources and Evaluation, 1015–1018. Lisbon: University of Lisbon.Search in Google Scholar
Schützler, Ole. 2010. Variable Scottish English consonants: The cases of /ʍ/ and non-prevocalic /r/. Research in Language 8. 5–21.10.2478/v10015-010-0010-9Search in Google Scholar
Schützler, Ole, Ulrike Gut & Robert Fuchs. 2017. New perspectives on Scottish Standard English. Introducing the Scottish component of the International Corpus of English. In Sylvie Hancil & Joan Beal (eds.), Perspectives on northern Englishes, 273–301. Berlin: Mouton de Gruyter.10.1515/9783110450903-012Search in Google Scholar
Stuart-Smith, Jane. 2008. Scottish English: Phonology. In Bernd Kortmann & Clive Upton (eds.), Varieties of English. The British Isles, 48–70. Berlin & New York: Mouton de Gruyter.10.1515/9783110208399.1.48Search in Google Scholar
Stuart-Smith, Jane, Claire Timmins & Fiona Tweedie. 2007. “Talkin’ Jockney?”: Accent change in Glaswegian. Journal of Sociolinguistics 11. 221–261. https://doi.org/10.1111/j.1467-9841.2007.00319.x.Search in Google Scholar
Timmins, Claire, Fiona Tweedie & Jane Stuart-Smith. 2004. Accent change in Glaswegian (1997 corpus): Results for consonant variables. Glasgow: University of Glasgow.Search in Google Scholar
Wells, John. 1982. Accents of English, vol. 1. Cambridge: Cambridge University Press.10.1017/CBO9780511611759Search in Google Scholar
© 2022 Zeyu Li and Ulrike Gut, published by De Gruyter, Berlin/Boston
This work is licensed under the Creative Commons Attribution 4.0 International License.
Articles in the same Issue
- Frontmatter
- Transitivity on a continuum: the transitivity index as a predictor of Spanish causatives
- Modelling incipient probabilistic grammar change in real time: the grammaticalisation of possessive pronouns in European Spanish locative adverbial constructions
- The theme-recipient alternation in Chinese: tracking syntactic variation across seven centuries
- Inferring case paradigms in Koalib with computational classifiers
- The distribution of /w/ and /ʍ/ in Scottish Standard English
- Towards a dynamic behavioral profile of the Mandarin Chinese temperature term re: a diachronic semasiological approach
Articles in the same Issue
- Frontmatter
- Transitivity on a continuum: the transitivity index as a predictor of Spanish causatives
- Modelling incipient probabilistic grammar change in real time: the grammaticalisation of possessive pronouns in European Spanish locative adverbial constructions
- The theme-recipient alternation in Chinese: tracking syntactic variation across seven centuries
- Inferring case paradigms in Koalib with computational classifiers
- The distribution of /w/ and /ʍ/ in Scottish Standard English
- Towards a dynamic behavioral profile of the Mandarin Chinese temperature term re: a diachronic semasiological approach