A novel characterization of the generalized family wise error rate using empirical null distributions
-
Jeffrey C. Miecznikowski
 and
Daniel P. Gaile
and
Daniel P. Gaile

Abstract
We present a novel characterization of the generalized family wise error rate: kFWER. The interpretation allows researchers to view kFWER as a function of the test statistics rather than current methods based on p-values. Using this interpretation we present several theorems and methods (parametric and non-parametric) for estimating kFWER in various data settings. With this version of kFWER, researchers will have an estimate of kFWER in addition to knowing what tests are significant at the estimated kFWER. Additionally, we present methods that use empirical null distributions in place of parametric distributions in standard p-value kFWER controlling schemes. These advancements represent an improvement over common kFWER methods which are based on parametric assumptions and merely report the tests that are significant under a given value for kFWER.
Acknowledgments
The authors are very grateful to David Tritchler for sharing his insights and providing helpful comments on an earlier version of this article.
Appendix
Monotonicity of the kFWER estimators
The proposed kFWER estimator is defined as a function of a set

The only term in (35) involving z or LHS version
The bias of k F W E R ¯ ( Z )
Under certain constraints (zero assumption and large π0) we can show

Figure 8 shows (36) as a function of π0 for certain fixed values of k, N, and


The second derivative in (37) also depends on k, N, and

Second Derivative of



Note, we assume
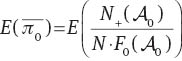


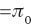
We can also examine
each zi follows the two group model independently,
the zero assumption where f1(z) is near zero for a subset of the sample space near zero, say
and that F0 is the standard normal CDF.
Since we are using the nonparametric form

Bias: The bias in
Sensitivity of estimators to A 0
For our simulations we used the program locfdr default choice of

A0 and π0 sensitivity: The dotted line is the mean
In the following subsections we present results related to the adjusted Bonferroni, Šidàk, and Holm procedures. Additionally we present several methods to empirically estimate null distributions.
Adjusted Bonferroni method
Theorem 1Using the two sample mixture model defined in (1),
Proof. Let
□
Corollary 9.1Using
Proof. A similar argument to Theorem 1 establishes the (RHS) kFWER result.□
Šidàk method
Theorem 2Consider the two sample mixture model defined in (1),

Then (LHS)kFWER(zsid)≤α when using the (LHS) kFWER definition where
Proof. We can assume that psid=F0(zsid). Then we have

Note from (45) we can assume that FB(k–1|N, psid)=1–α and so 1–FB(k–1|N, psid)=α. Hence the last term of the sum in (46) is

Thus, we can rewrite (46) with the understanding that

□
Corollary 9.2Similarly, if we define

Then (RHS)kFWER(zsid)≤α when using the (RHS) kFWER definition where (RHS)
Proof. Similar to the proof for Theorem 2. □
Holm method
Theorem 3Consider the two sample mixture model defined in (1) and
Proof. If r≤k, then our α adjustment is the same as the Bonferroni α adjustment and we can use the Markov inequality as employed in the proof for the adjusted Bonferroni argument.
Assume r>k, then we use the technique employed in Lehmann and Romano (2005). Let

The event {# of null z-values ∈(–∞, zholm)≥k} is equal to the event {yk=zj≤zholm}. In order to reject at least k true nulls, the largest possible value of j is N–N0+k, namely, the situation where the N–N0 true alternatives are the smallest z statistics. Hence, we have that

Corollary 9.3Consider the two sample mixture model defined in (1) and
Proof. Similar to the proof for Theorem 3.□
Theorem 4We assume that each zi follows the two group model independently and that F0is given as the standard normal CDF. We also assume the zero assumption where f1(z) is near zero for a subset of the sample space near zero, say,
Proof. Since F0 is given, π0 is the only parameter to estimate in kFWER. To emphasize the dependence on π0, we will denote our estimator




where C and C′ do not depend on π0. By straightforward calculus the function in (55) is convex in terms of



Note, in going from (6) to (7) we assume



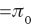
Methods to estimate the null distribution
In this section, we paraphrase two methods described in Efron (2010) for estimating the null distribution. We assume that f0(z) is normal but not necessarily

and we define fπ0(z)=π0f0(z). This implies that

is a quadratic function of z.
The MLE method for empirical null distribution
This method was first introduced in Efron (2007). The maximum likelihood estimator (MLE) method starts with the zero assumption, where we assume that f1(z) is zero for a certain subset

We assume N0 is the number of zi in
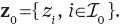
Also, let

and

this being the probability that a
We suppose that the N zi values follow the two-group model (1) with

when
Computations can produce maximum likelihood estimators

The log of (69) is concave in (δ0, σ0, π0) guaranteeing that the MLE solutions are unique. This is described more fully in Section 6.3 of Efron (2010).
The central matching method for empirical null distribution
This method was first introduced in Efron (2004). In this method, we define yk as the number of observations zi in the kth bin,

where we partition the range

Then, with the central matching method, we estimate f0(z) and π0 by assuming that log(f(z)) is quadratic near 0 and equal to (64) with,

Estimating (β0, β1, β2) can be done using least squares with the histogram counts yk around z=0 and matching coefficients between (64) and (73). In other words, via matching, we obtain,



References
Bahadur, R. (1959): “A representation of the joint distribution of responses to N dichotomous items,” Technical report, Defense Technical Information Center Document.Search in Google Scholar
Cai, G. and S. Sarkar (2006): “Modified Simes’ critical values under positive dependence,” J. Stat. Plann. Infer., 136, 4129–4146.Search in Google Scholar
Dudoit, S., M. Van Der Laan and K. Pollard (2004): “Multiple testing Part I. single-step procedures for control of general type I error rates,” Statistical Applications in Genetics and Molecular Biology 3, Article 13.Search in Google Scholar
Efron, B. (2004): “Large-scale simultaneous hypothesis testing,” J. Am. Stat. Assoc., 99, 96–104.Search in Google Scholar
Efron, B. (2007): “Correlation and large-scale simultaneous significance testing,” J. Am. Stat. Assoc., 102, 93–103.Search in Google Scholar
Efron, B. (2010): Large-Scale Inference: Empirical Bayes Methods for Estimation, Testing, and Prediction, volume 1. Cambridge, United Kingdom: Cambridge Univ Pr.10.1017/CBO9780511761362Search in Google Scholar
Efron, B., B. B. Turnbull and B. Narasimhan (2011): locfdr: Computes local false discovery rates, R package version 1.1-7.Search in Google Scholar
Finos, L. and A. Farcomeni (2010): someKfwer: Controlling the Generalized Familywise Error Rate, R package version 1.1.Search in Google Scholar
Finos, L. and A. Farcomeni (2011): “k-fwer control without p-value adjustment, with application to detection of genetic determinants of multiple sclerosis in Italian twins,” Biometrics, 67, 174–181.10.1111/j.1541-0420.2010.01443.xSearch in Google Scholar
Golub, T. R., D. K. Slonim, P. Tamayo, C. Huard, M. Gaasenbeek, J. P. Mesirov, H. Coller, M. L. Loh, J. R. Downing, M. A. Caligiuri, C. D. Bloomfield and E. S. Lander (1999): “Molecular classification of cancer: class discovery and class prediction by gene expression monitoring,” Science, 286, 531–537.10.1126/science.286.5439.531Search in Google Scholar
Guo, W. and J. Romano (2007): “A generalized Šidàk-Holm procedure and control of generalized error rates under independence,” Statistical Applications in Genetics and Molecular Biology, 6, Article 3.10.2202/1544-6115.1247Search in Google Scholar
Holm, S. (1979): “A simple sequentially rejective multiple test procedure,” Scand. J. Stat., 6, 65–70.Search in Google Scholar
Jin, J. and T. Cai (2007): “Estimating the null and the proportion of nonnull effects in large-scale multiple comparisons,” J. Am. Stat. Assoc., 102, 495–506.Search in Google Scholar
Lehmann, E. (1966): “Some concepts of dependence,” Ann. Math. Stat., 37, 1137–1153.Search in Google Scholar
Lehmann, E. and J. Romano (2005): “Generalizations of the familywise error rate,” Ann. Stat., 33, 1138–1154.Search in Google Scholar
Miecznikowski, J. and D. Gaile (2012): “A novel characterization of the generalized family wise error rate using empirical null distributions,” Technical Report #1203, University at Buffalo, Department of Biostatistics, Buffalo, NY.Search in Google Scholar
Miecznikowski, J., D. Gold, L. Shepherd and S. Liu (2011): “Deriving and comparing the distribution for the number of false positives in single step methods to control k-fwer,” Stat. Probabil. Lett., 81, 1695–1705.Search in Google Scholar
Muralidharan, O. (2010): “An empirical bayes mixture method for effect size and false discovery rate estimation,” Ann Appl Stat 4, 422–438.10.1214/09-AOAS276Search in Google Scholar
Pollard, K. S., Y. Ge, S. Taylor and S. Dudoit: multtest: Resampling-based multiple hypothesis testing, R package version 1.22.0.Search in Google Scholar
Pounds, S. and S. Morris (2003): “Estimating the occurrence of false positives and false negatives in microarray studies by approximating and partitioning the empirical distribution of p-values. Bioinformatics, 19, 1236–1242.10.1093/bioinformatics/btg148Search in Google Scholar
R Core Team (2012). R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria. ISBN 3-900051-07-0.Search in Google Scholar
Romano, J. P. and M. Wolf (2005): “Exact and approximate stepdown methods for multiple hypothesis testing,” J. Am. Stat. Assoc., 100, 94–108.Search in Google Scholar
Romano, J. P., and M. Wolf (2010): “Balanced control of generalized error rates,” Ann. Stat., 38, 598–633.Search in Google Scholar
Roquain, E. and F. Villers (2011): “Exact calculations for false discovery proportion with application to least favorable configurations,” Ann. Stat., 39, 584–612.Search in Google Scholar
Sarkar, S. (2008): “Generalizing Simes’ test and Hochberg’s stepup procedure,” Ann. Stat., 36, 337–363.Search in Google Scholar
Singh, D., P. G. Febbo, K. Ross, D. G. Jackson, J. Manola, C. Ladd, P. Tamayo, A. A. Renshaw, A. V. D’Amico, J. P. Richie., et al. (2002): “Gene expression correlates of clinical prostate cancer behavior,” Cancer cell, 1, 203–209.10.1016/S1535-6108(02)00030-2Search in Google Scholar
©2014 by Walter de Gruyter Berlin/Boston
Articles in the same Issue
- Frontmatter
- Statistical inference of regulatory networks for circadian regulation
- A Bayesian clustering approach for detecting gene-gene interactions in high-dimensional genotype data
- A novel characterization of the generalized family wise error rate using empirical null distributions
- Applying shrinkage variance estimators to the TOST test in high dimensional settings
- A boosting approach for adapting the sparsity of risk prediction signatures based on different molecular levels
- Using the theory of added-variable plot for linear mixed models to decompose genetic effects in family data
- Efficient parametric inference for stochastic biological systems with measured variability
Articles in the same Issue
- Frontmatter
- Statistical inference of regulatory networks for circadian regulation
- A Bayesian clustering approach for detecting gene-gene interactions in high-dimensional genotype data
- A novel characterization of the generalized family wise error rate using empirical null distributions
- Applying shrinkage variance estimators to the TOST test in high dimensional settings
- A boosting approach for adapting the sparsity of risk prediction signatures based on different molecular levels
- Using the theory of added-variable plot for linear mixed models to decompose genetic effects in family data
- Efficient parametric inference for stochastic biological systems with measured variability