Oral History Metadata and AI: A Study from an LGBTQ+ Archival Context
-
Anthony Cocciolo


Abstract
The purpose of this study is to explore the utility of generative AI technologies in creating oral history metadata. In particular, we will explore its ability to create descriptive metadata, specifically the Dublin Core description field, for oral histories that have existing transcripts. The oral history context this research is situated in is LGBTQ+ oral histories from three repositories in the United States. Research participants with knowledge of the area of library and archival science (N=14) will rate the AI-generated description created by ChatGPT 4 compared to the description created by hand, and describe qualitatively why one is better than the other. Results indicate that users prefer the AI-generated description 51.2 % of the time, compared to preferring the descriptive metadata created by a human 26.2 % of the time and being undecided about which is preferable 21.4 % of the time. Despite research that indicates that AI can reflect the bias of the datasets used to train it, we found that the AI created culturally-appropriate content 80.4 % of time compared with 75.6 % of the time when created by a human. The use of ChatGPT 4 is recommended as a tool to analyze interview transcripts to create descriptive metadata for oral histories documenting the LGBTQ+ community, although the content should be reviewed before being provided to users.
1 Introduction
The availability of generative AI technologies, such as ChatGPT, has led to widespread exploration of the possibilities of this technology: what is it capable of, what is it good or not good for, what blind spots does it have, among many other questions. This study aims to explore the utility of generative AI technologies in creating oral history metadata. In particular, we will explore its ability to create descriptive metadata, specifically the Dublin Core description field, for oral histories with existing transcripts. The oral history context in which this research is situated is LGBTQ + oral histories from repositories in the United States. Research participants with knowledge of the area of library and archival science will rate the AI-generated descriptions created by ChatGPT 4 compared to the descriptions created by hand and describe qualitatively why one is better than the other.
The purpose of oral history metadata, especially descriptive metadata, is to help oral histories become discoverable and accessible to the public. For example, descriptive metadata can highlight names, places, date ranges, and topics to help a researcher readily recognize if a particular oral history is relevant to their research topic. Oral histories can be found in library catalogs, archival finding aids, and on the World Wide Web by searching this metadata.
Oral history is a popular method for capturing the stories of LGBTQ + individuals. For example, the Oral History Society in the UK writes that:
Lesbian, gay, bisexual, trans and queer identities have historically been regarded as being different or shameful and so do not feature to any significant degree in the archives or the history books. This is because queer communities didn’t tend to keep letters, diaries etc in case they fell into the wrong hands and few ‘selfies’ were taken in gay bars back in the day for the same reason. As a result, a major way for queer communities to capture and record their heritage is through the collection of oral history testimonies where an individual’s lived experience can be accessed by encouraging them to talk about a specific time, situation, issue or circumstance from their past. (Oral History Society 2024)
Given the history of discrimination against LGBTQ persons, and in addition to having research participants rate and describe which description they prefer, this study will also ask if they detect any bias against LGBTQ + persons in the descriptions. The reasons for exploring this is that Generative AIs trained on massive text corpora or image databases, such as large segments of the World Wide Web, have created tools that sometimes reflect the biases of the societies in which these texts or images are situated. For example, Broussard (2023) and Buolamwini (2023) identify numerous examples of how African-American communities, among other historically marginalized groups, can experience a level of bias by tools that use AI technologies, such as ones that use facial recognition and fail at a much higher rate at identifying non-white faces compared to white faces. The documented evidence of bias in generative AI systems raises questions about which other contexts bias may arise when using AI systems. Would these societal biases against LGBTQ + communities be reflected in text texts created by AI systems? Thus, this study will explore the two inter-related issues: can AI create oral history metadata, and in doing so can it do it in a way where it doesn’t introduce societal bias into its description? Before discussing the methods and results, a brief discussion of relevant literature is included in the next section.
2 Literature Review
2.1 Generative AI
Generative AI, such as ChatGPT created by Open AI, surprised the world when it was launched in 2022 because of the way it was able to respond quickly to a wide variety of prompts in a conservational fashion, such as writing and debugging computer code, ability to write essays and poetry, among a wide assortment of other tasks (Wikipedia 2024a). Trained on large corpora of text, including vast swaths of the World Wide Web with interventions from human trainers, in 2023, ChatGPT was reported to have “brok[en] the Turing Test” (Biever 2023). The Turing test, created by Alan Turing and originally called the “imitation game,” tests if a human evaluator can tell the difference between a human and a computer on the other end of a computer terminal after various prompts. In a test of over 1.5 million users playing a game based on the idea of the Turing test, 60 % of users were able to correctly guess that they were playing against an AI, which indicates that the odds are not necessarily good that an average person can tell the difference between a bot and human, at least in brief interactions (Jannai et al. 2023).
While generative AI systems can be incredibly impressive, they can also exhibit a variety of blind spots. In 2024, Google added AI assistance to its search results, and some bizarre results were widely circulated over the Internet and the media, such as its endorsement that “eating rocks because doing so ‘can be good for you,’ and the other suggested using nontoxic glue to thicken pizza sauce” (Rogers 2024). Beyond bizarre results, a significant issue is the evidence of ongoing bias demonstrated by AI systems. Broussard (2023) argues that the bias is a result of not only the texts that the AI models are trained on but also the social context of software development:
The idea is, you design a program for the greatest number of situations, but there will always be edge cases that are weird or fall outside the realm of normal. The problem is, “normal” is usually whatever the developer’s own experience is. People also consistently overestimate how much of the world is made up of people like themselves. This is why so much technology is optimized for able-bodied, white, cis-gender, American men, because this population makes up the majority of software developers. Whiteness is perceived as the invisible default for software system users, while any racial or ethnic affiliation other than white is perceived as visible or aberrant. Visibility translates to being outside the realm of normal – an edge case. (24).
Thus, the issue of bias in AI systems is “more than a glitch” but interwoven into these systems in multiple, albeit unintentional, ways. Problematic bias in criminal justice, standardized testing, medical diagnosis, and facial recognition have been identified (Broussard 2023; Buolamwini 2023). Buchanan and Imbrie (2022, 89) write that “From how data is collected to the goals used to optimize algorithmic performance and beyond, one simple fact remains: machine learning systems routinely discriminate.” Given that AI systems reflect the bias of the societies that created them, do AI systems exhibit bias against LBGTQ + persons? Early research indicates this may be the case, however, their tests have been on earlier AI systems, such as predecessors to ChatGPT 4. For example, Dzogang (2023) tested ChatGPT 3 to create sentences and found that “References to LGBTQ + groups triggered significantly more toxic prompt completions than the baseline reference to ‘person.’” The problem is amplified when intersectional identities are taken into account. For example, Dzogang finds that “The original GPT-3 model outputs severely toxic comments in over 8 % of completions with references to “gay black person,” thus exhibiting greater levels of bias than just using the term “gay.” To address the bias against LGBTQ + persons, Felkner et al. (2022) developed WinoQueer, which is a “benchmark dataset for quantifying anti-LGBTQ + bias in large language models,” which they then use to show that “off-the-shelf LLMs [large language models] show substantial anti-queer bias on our test set.” This project aims to contribute to this body of literature around bias in AI systems and LGBTQ + communities and explore if the metadata created exhibits signs of bias.
While bias in AI systems may seem like the most significant challenge to this emerging technology, the challenge of hallucinations may be just as great. Hallucinations occur when the AI presents information that is not substantiated by facts but may be presented very confidently with no indication that there is no evidence for what it is saying. In a study of ChatGPT 3 that asked for answers based on scientific articles, Athaluri et al. (2023) found that 16 % of the articles referenced by ChatGPT 3 were the product of AI hallucination as the DOI did not work, nor was there any way to find the article via a web search. In this study, the authors conclude that “AI Hallucination is an area of concern that limits the use of ChatGPT in scientific writing and analysis” (5). While this particular project is more interested in bias and the ability of generative AI to create oral history metadata, AI hallucination is a significant issue that one should be attuned to when exploring the use of this technology.
2.2 Oral History and its Metadata
Oral history “collects memories and personal commentaries of historical significance through recorded interviews,” which then get “transcribed, summarized or indexed and then placed in a library or archives” (Ritche 2003, 19). Frisch observes that oral history is “a powerful tool for discovering, exploring and evaluating the nature of the process of historical memory – how people make sense of their past, how they connect individual experience and its social contexts and how the past becomes part of the present, and how people use it to interpret their lives and the world around them” (Frisch 1990, 188). Descriptive metadata provides a means to make the oral histories findable to potential researchers and provide background context on its creation, among other uses. The Oral History Metadata Task Force (2020) surveyed 58 cultural heritage professions about their descriptive metadata practices for oral history and found that the “biggest takeaway of our survey is no surprise to those working with oral history: there is no ‘one size fits all’ solution for metadata capture and creation” (3). In their survey, Dublin Core is one of the most commonly referenced tools mentioned in creating descriptive metadata, which provides basic descriptive metadata fields like “title,” “date,” “contributor,” and “description.” The follow-up work from the Oral History Metadata Task Force (2021) suggests several fields that creators and catalogers should consider when creating oral history metadata. One such field that will be the focus of this study is the “interview summary” field, which provides a “narrative description of interview content” (10). This study will explore if generative AI is an appropriate tool to create metadata for this field and compare it to the field created manually.
3 Methods
The research procedure used here is to a) assemble the LGBTQ + oral histories, b) generate the Dublin Core description field in ChatGPT 4 for each transcript, c) create a survey in Survey Monkey where research participants will provide their feedback on the AI and hand-generated descriptions, d) recruit research participants, and e) collect data from research participants. More details on each component will be detailed below, followed by the results in the subsequent section.
3.1 Assembling Oral Histories
To determine if an AI can create a description field for oral histories in an accurate and culturally appropriate manner (e.g., free of anti-LGBTQ + bias), 12 oral histories from three repositories in the United States were assembled. These repositories were selected because they contain oral histories with a recording, a transcript, and a summary or descriptive field, with the transcript being a requirement in identifying collections and repositories as this was needed to provide to the AI. The three repositories and related collections that were selected include:
Lesbian Herstory Archives – Three Collections (Lesbian Style Project, New York Preservation Archive Project, Dyke TV Collection)
New York City Trans Oral History Project
Johns Hopkins Libraries – Baltimore Queer Oral History Collection
Interviews were selected randomly within collections. For example, the New York City Trans Oral History project features 216 interviews with transcripts on its website, and three were chosen randomly to include in this research project (New York City Trans Oral History Project 2024).
3.2 Creating the AI-Generated Description
To create the AI-generated descriptive summaries of the transcripts, the following prompt was given to ChatGPT 4: “Hello ChatGPT. I would like you to summarize an interview so that it could be used as a description field in a Dublin core metadata field,” and then an export of the transcript available as text was provided. These transcripts were created during February 2024 and May 2024, with a “Plus” account for ChatGPT, which cost $20/month and was required to upload the long transcripts.
3.3 Creating an Interface for Research Participants in Survey Monkey
The 12 oral histories are presented to research participants in Survey Monkey, including the link to the recording, the link to the transcript, the descriptive field created by hand and the descriptive field created by the AI, as well as questions to collect the participant’s preferences and opinions about the descriptions. The participants were not told that an AI creates one of the descriptions, or that the study is concerned with AI, to prevent the potential bias against AI to factor into the study. With that said test subjects may be able to suspect that an AI wrote some of the text. Figure 1 shows the Survey Monkey interface that research participants interacted with.
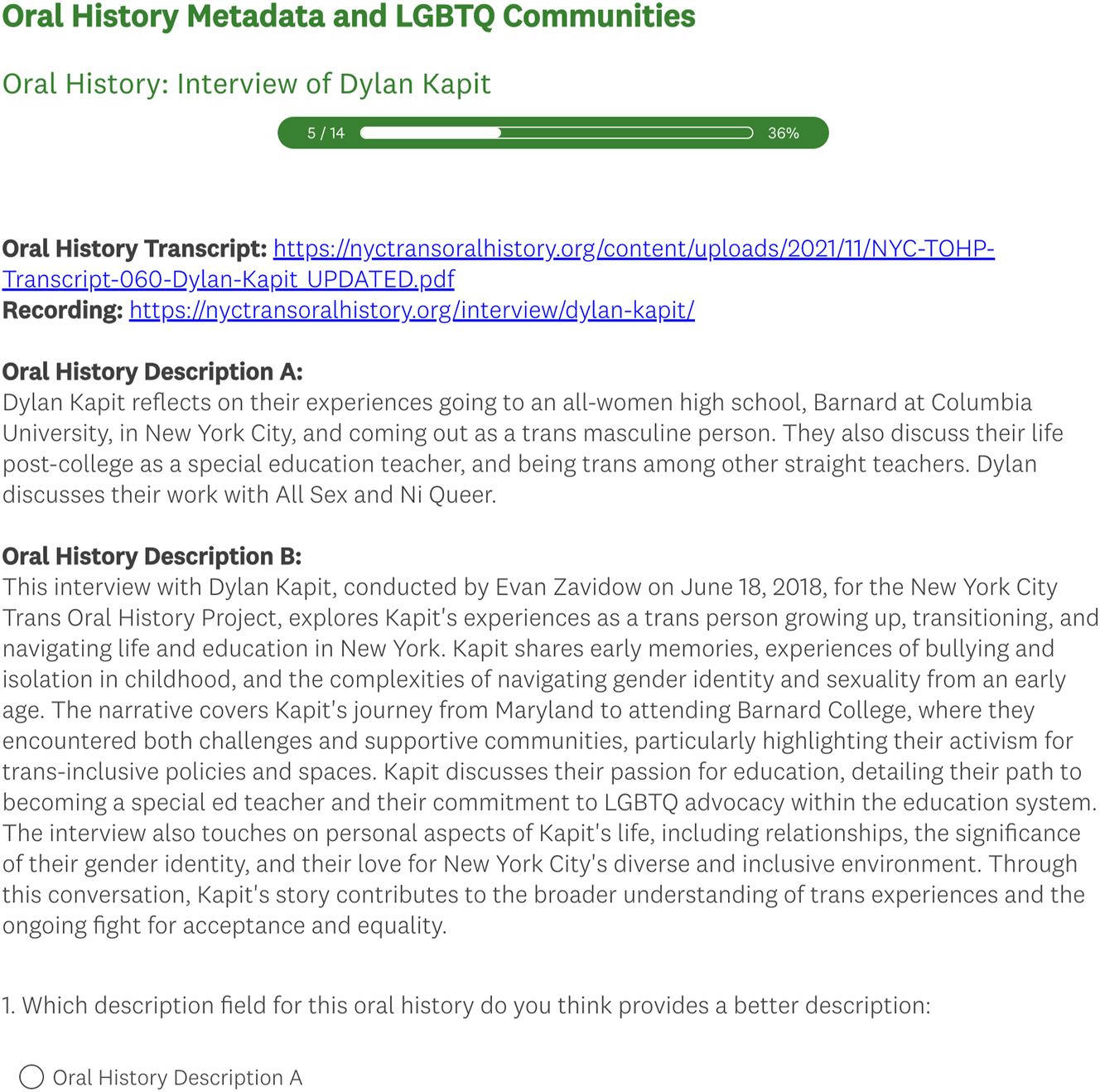
Survey Monkey interface used by research participants.
3.4 Research Participant Recruitment
The appropriate research participants that were identified are students or recent graduates in the M.S. in Library and Information (MSLIS) program at an American Library Association accredited graduate program in an urban area of the eastern United States. This group was identified as having some knowledge of cataloging library and archival material and being familiar with things like the description field in Dublin Core metadata. Participants were recruited using the school’s internal Google Group, at which point they were presented with the informed consent form, answered some basic demographic questions, and then were presented with the 12 oral histories on each page of the survey. Participants were provided a $50 Amazon gift card for their time, and the participants were informed that the survey should take about an hour to complete. Participants were told that they did not need to read the entire transcript or listen to the entire oral history recording. However, they should skim through each and read through the two sets of descriptive summaries before answering the questions.
3.5 Research Participant Data Collection and Demographics
During July 2024, 14 survey responses were collected for MSLIS students and recent graduates. Of the respondents, 57.1 % identified with she/her pronouns, 14.3 % identified with she/they pronouns, 28.6 % identified with he/him pronouns, and 85.7 % identified as being part of the LGBTQ + community. Some 50 % identified as a current MSLIS student, and 50 % identified as a recent MSLIS alumni. A total of 71 % are 25–34 years of age, 14.3 % are 18–24 years of age, 7.1 % are 35–44 years of age, and 7.1 % are 45–54 years of age.
4 Results
Results indicate that participants prefer the descriptive metadata created by AI to those created manually by humans. Some 51.2 % of the time, participants preferred the descriptive metadata created by the AI (86 cases out of 168), with 26.2 % of the time preferring the descriptive metadata created by a human (44 cases out of 168), and 21.4 % of the time being undecided about which was preferred (36 out of 168 cases). Some 80.4 % of the time, participants agreed or strongly agreed that the AI had generated a culturally appropriate description, compared with 75.6 % when participants agreed or strongly agreed that the human-generated description was culturally appropriate.
Qualitative feedback indicates why the AI-created description is preferred to the human-created description. One issue is if the human-created metadata can simply be too brief compared to the AI-generated metadata. For example, several respondents commented on the disparity in the lengths of some descriptions and preferred the more detailed description provided by the AI. For example, one respondent writes:
Description B [AI-generated] is just so much more thorough. It includes details about Thomas’ experiences in an in-depth way, and includes far more keywords that may be useful to a researcher. Description A [human-created] is so vague it is hard to imagine anyone reading that and wanting to read/listen to the interview. (25–34 year old MSLIS graduate with she/her pronouns).
However, there are cases where the human-created description can be too verbose and the AI-created description achieves a more appropriate length. For example, in one case that included a very long human-created description, a respondent writes:
Option A is way too long [human-created]. I think Option B [AI-generated] captures perfectly what a viewer might want to know about the interview and its subjects to know whether or not it would be relevant for them. (25–35 year old MSLIS student with she/they pronouns).
Another issue with human-created metadata is if it strays too far from the transcript, such as the description writer introducing their own opinion about the oral history interview. For example, one respondent writes that:
Description B [AI-generated] stuck more to statements of fact – it tells you what the interview is about – whereas A [human-generated] uses emotive language that tells us more how the author felt about the interview. Because of the emotive language, A [human-generated] came off sounding like a sales pitch or an advertisement. (35–44 year old MSLIS graduate with he/him pronouns).
Beyond having more length and detail, the AI description is sometimes commended for knowing the interview transcript and the subject matter that the interview implicates. For example, one respondent writes that:
Description B [AI-generated] has a much more sophisticated understanding of both ballroom culture and Dior’e’s story than Description A [human-generated]. B is more structured and has more flow, whereas A feels a bit scattered and informal. (35–44 year old MSLIS graduate with he/him pronouns).
In the above case, the AI is credited with having a “sophisticated understanding of ballroom culture,” which is incredible to hear, considering that it was written by an AI. Regarding the AI introducing bias, there is no evidence that respondents found that the AI-generated responses had bias. Respondents commented on the sensitivity of the AI to the interview subjects, such as the two responses below:
[AI-generated description is] “More sensitive to the interviewee’s experience and further defines and details those reflections in a succinct manner” (18–24 year old MSLIS student with she/her pronouns).
“Description B [AI-generated] has more structure, tells more of a story, and engages us more with the subject of the interview, all while presenting the information in a sensitive and empathetic way. Description A hurts – it’s brutally short and artless.” (35–44 year old MSLIS graduate with he/him pronouns).
Respondents often find that the AI-created metadata was more sensitive to issues that may occur within the LGBTQ + community, such as the transition of genders and the use of “dead names,” than the human-created metadata. “Deadnaming” is the act of “referring to a transgender or non-binary person by a name they used before transitioning, such as their birth name” (Wikipedia 2024b). For example, one respondent writes that:
I think that choice A [human-created] frames the subject’s dead name first rather than their preferred name, so I prefer choice B [AI-generated] because of that. (25–34 year-old MSLIS student with she/her pronouns).
The AI also has a firmer grasp of using pronouns than some manually-created descriptions. For example, one respondent writes:
Oral History Description A [human-created] uses she/her pronouns, and Oral History Description B [AI-generated] uses they/them or non-gendered language. Oral History Description B is overly descriptive, but I think the pronouns are more accurate due to the anonymous nature of the interview. (25–34 year old MSLIS student with he/him pronouns).
The manually created metadata has the disadvantage of being created in the past, when sensitivity to gender pronouns and use of preferred names may not have been as well understood as they are in 2024. Thus, it can be difficult to attribute those issues to bias or simply changing cultural practices. However, it is remarkable that the AI was able to generate summaries of these interviews with what seemed to respondents like “sensitivity.”
Some respondents seemed to suspect that an AI created some of the descriptions. For example, one respondent writes:
There’s something about Option B [AI-generated description] that feels AI-generated. I think the last sentence in particular adds an optimistic summation that I often see in AI writing, and it feels out of step with the archivist’s usual attempts at ’objective’ descriptions. (25–34 year old MSLIS graduate with she/her pronouns).
However, only some participants seemed aware that this project involved AI. For example, one respondent comments that they may think this project is about good writing versus bad writing. One respondent writes:
This is an interesting exercise in comparing bad writing with good writing. Both descriptions say much the same thing and are the same length, but Description B [AI-generated] uses words significantly more purposefully and effectively. (35–44 year old MSLIS graduate with he/him pronouns).
Interestingly, and in very much alignment with the findings from this study, AI-generated text is held up as an example of good writing.
5 Discussion
This study found that research participants preferred the oral history descriptions created by AI as compared to a human for a variety of reasons, including:
Detailed coverage of the transcript and use of keywords with knowledge of significant aspects of the community, such as ballroom culture, while also striking an appropriate length.
“Sensitive,” good attention to pronouns and preferred names, and less biased than human-created metadata
“Good writing”
This study did not find any examples of AI introducing bias toward the LGBT + community, as was found in research on earlier AI systems (Dzogang 2023). This is a credit to the creators at Open AI who have clearly invested time and effort in ChatGPT 4 to address these issues identified in previous iterations.
Given this study’s result, ChatGPT4 is recommended as a tool to analyze interview transcripts to create descriptive metadata for oral histories documenting the LGBTQ + community. While AI can introduce bias and hallucination, such as making up inaccurate information, neither presented themselves as a significant issue in this study. It can be mitigated by reviewing the description before publishing if it does happen. Having an extensive transcript helps ground the AI in a reality that it can work with. When using these descriptions, special attention should be paid to the final sentences of the description, which may include the introduction of “optimistic summation[s] which is unnecessary and can be distracting.
What does this study imply for human-created descriptive metadata? More resources or guidance may be needed on how to create an interview description, perhaps even learning from what is good about the description made by the AI. For example, looking at the Oral History Metadata Taskforce’s (2021) Metadata Elements for Oral History, they provided dozens of fields that can be created for any given interview, however, provide little detail on what should be provided in the “Interview summary” field: “Narrative description of interview content. Could be formatted as an abstract.”
While AI may have improved its ability create summaries or abstracts, the human capacity to do so may be eroding. For example, courses in abstracting and indexing were standard in the library and information science schools, however, many have been phased out and replaced with skills and knowledge deemed more important for the times. Alternatively, more attention may need to be paid to AI “prompt engineering,” where the information professional works with the AI to create prompts to get appropriate kinds of responses as well as invest time in quality control, checking the responses, and ensuring that the tool is working as expected (e.g., free from bias or hallucinations).
If an AI-generated description is used as metadata, should it be cited or credited in some way? If the description created by the AI adheres to the facts of the transcript, as was the case of the descriptions made in this study by ChatGPT, it ought not to be cited. If the human metadata creator is rarely credited, why would the AI get this distinction? Abstracts or summaries created for oral history metadata – as with many other types of metadata – typically do not cite the metadata creator. The standard in citing is that “When a fact is generally accepted or easily observable, you do not need a citation” (Boston University 2024). Thus, if the description is a summarization of easily observable facts from a transcript and nothing more, without introducing any creative or independent content, then it should not need a citation. With that said, libraries and archives also would not want to hide that they are using this technology and, thus, if it is used it should be disclosed somewhere in a digital repository and not necessarily tied to each item in the repository.
One limitation of this study is that while it did use 12 oral histories covering a range of persons and institutions, there may be some topics out there in the LGBTQ + community that will be handled poorly by the AI, leading to bias or other issues. While we did not have evidence of this in this study, such evidence could be revealed in a study that employs a larger swath of oral histories. A final limitation is that while the study participants were heavily part of the LGBTQ + community, they tended to be younger (85.3 % were 18–34 years of age) and thus may not reflect the preferences of all potential researchers of LGBTQ + collections.
6 Conclusions
In summary, this project found that research participants preferred the AI-generated description of oral histories documenting LGBTQ + persons compared to that of the description created by a human. Despite research that indicates that AI can reflect the bias of the datasets used to train it, we found that Chat GPT 4 creates culturally appropriate content at a high rate (80.4 % of the time) and even higher than that made by a human (75.6 % of the time). This is because research participants found the description had more details and keywords, had good writing and length, and was sensitive to subjects and aspects like gender identity characteristics and pronouns. This research indicates that ChatGPT 4 has improved from earlier versions such as ChatGPT 3 when creating text that addresses issues around the LGBTQ + community and individuals. ChatGPT4 is recommended as a tool to analyze interview transcripts and create descriptive metadata for oral histories documenting the LGBTQ + community. However, the content should be reviewed before being provided to researchers as there continues to be a potential for unearthing some bias, hallucination, or other issue when using AI.
References
Athaluri, S. A., S. V. Manthena, V. S. R. Krishna Manoj Kesapragada, V. Yarlagadda, T. Dave, R. Tulasi, and S. Duddumpudi. 2023. “Exploring the Boundaries of Reality: Investigating the Phenomenon of Artificial Intelligence Hallucination in Scientific Writing Through ChatGPT References.” Cureus 15 (4): e37432. https://doi.org/10.7759/cureus.37432.Search in Google Scholar
Biever, C. 2023. “ChatGPT Broke the Turing Test – the Race Is on for New Ways to Assess AI.” Nature 619 (7971): 686–9. https://doi.org/10.1038/d41586-023-02361-7.Search in Google Scholar
Boston University of Public Health. 2024. “When to Cite.” https://www.bu.edu/sph/students/student-services/student-resources/academic-support/communication-resources/when-to-cite/(accessed July 24, 2024).Search in Google Scholar
Broussard, M. 2023. More Than a Glitch: Confronting Race, Gender, and Ability Bias in Tech. Cambridge, MA: MIT Press.10.7551/mitpress/14234.001.0001Search in Google Scholar
Buchanan, B., and A. Imbrie. 2022. The New Fire: War, Peace, and Democracy in the Age of AI. Cambridge, MA: MIT Press.10.7551/mitpress/13940.001.0001Search in Google Scholar
Buolamwini, J. 2023. Unmasking AI: My Mission to Protect What is Human in a World of Machines. New York, NY: Random House.Search in Google Scholar
Dzogang, F. 2023. “Addressing LGBTQ+ Bias in GPT-3.” ASOS Technical Blog. https://medium.com/asos-techblog/addressing-lgbtq-bias-in-gpt-3-93e556a1b0fe (accessed August 9, 2024).Search in Google Scholar
Felkner, V., H.-C. Herbert Chang, E. Jang, and J. May. 2022. “Towards WinoQueer: Developing a Benchmark for Anti-queer Bias in Large Language Models.” Arxiv. https://arxiv.org/pdf/2206.11484 (accessed August 9, 2024).Search in Google Scholar
Frisch, M. H. 1990. A Shared Authority: Essays on the Craft and Meaning of Oral and Public History. Albany, NY: State University of New York Press.Search in Google Scholar
Jannai, D., A. Meron, B. Lenz, Y. Levine, and Y. Shoham. 2023. “Human or Not? A Gamified Approach to the Turing Test.” Arxiv. https://arxiv.org/abs/2305.20010 (accessed August 9, 2024).Search in Google Scholar
New York City Trans Oral History Project. 2024. https://nyctransoralhistory.org/interviews/(accessed July 18, 2024).Search in Google Scholar
Oral History Metadata Taskforce. 2020. Oral History Metadata and Description: A Survey of Practices. https://www.oralhistory.org/wp-content/uploads/2021/01/OHA-MTF-White-Paper_2020.pdf (accessed August 9, 2024).Search in Google Scholar
Oral History Metadata Taskforce. 2021. Metadata Elements for Oral History. https://oralhistory.org/wp-content/uploads/2023/03/OHAMTF_Comprehensive-Oral-History-Element-List-for-download-20220517.pdf (accessed August 9, 2024).Search in Google Scholar
Oral History Society. 2024. LGBTQ Oral History. https://www.ohs.org.uk/lgbtq/(accessed Nov 18, 2024).Search in Google Scholar
Ritchie, Donald A. 2003. Doing Oral History: A Practical Guide, 2nd ed. New York: Oxford UP.Search in Google Scholar
Rogers, Reece. 2024. “Google Admits Its AI Overviews Search Feature Screwed Up.” Wired. https://www.wired.com/story/google-ai-overview-search-issues/(accessed August 9, 2024).Search in Google Scholar
Wikipedia. 2024a. ChatGPT. Wikimedia Foundation. https://en.wikipedia.org/wiki/ChatGPT (last modified July 24, 2024).Search in Google Scholar
Wikipedia. 2024b. Deadnaming. Wikimedia Foundation. https://en.wikipedia.org/wiki/Deadnaming (last modified July 22, 2024).Search in Google Scholar
© 2025 the author(s), published by De Gruyter, Berlin/Boston
This work is licensed under the Creative Commons Attribution 4.0 International License.
Articles in the same Issue
- Frontmatter
- Editorial
- Moving into 2025
- Articles
- New Contributions to Iron Gall Ink Inspection Protocols Using Open Source Surface Analysis and Digital Imaging
- Passing Down Local Memories: Generativity and Photo Donations in Preservation Institutions
- Oral History Metadata and AI: A Study from an LGBTQ+ Archival Context
- Exploring Design Aspects of Online Museums: From Cultural Heritage to Art, Science and Fashion
- Can Social Media Pave the Way for the Preservation and Promotion of Heritage Sites?
- Exploring the Potential of Mobile Phone Applications in the Transmission of Intangible Cultural Heritage Among the Younger Generation
- The Application of Interaction Design in Cultural Heritage Tourism: A Systematic Literature Review
- List of Reviewers
- PDT&C Peer-Reviewers in 2023–2024
Articles in the same Issue
- Frontmatter
- Editorial
- Moving into 2025
- Articles
- New Contributions to Iron Gall Ink Inspection Protocols Using Open Source Surface Analysis and Digital Imaging
- Passing Down Local Memories: Generativity and Photo Donations in Preservation Institutions
- Oral History Metadata and AI: A Study from an LGBTQ+ Archival Context
- Exploring Design Aspects of Online Museums: From Cultural Heritage to Art, Science and Fashion
- Can Social Media Pave the Way for the Preservation and Promotion of Heritage Sites?
- Exploring the Potential of Mobile Phone Applications in the Transmission of Intangible Cultural Heritage Among the Younger Generation
- The Application of Interaction Design in Cultural Heritage Tourism: A Systematic Literature Review
- List of Reviewers
- PDT&C Peer-Reviewers in 2023–2024