
Taugt die aggregierte Delinquenzrate einer Schulklasse als Maßzahl für die Bestimmung kriminogener Peer-Effekte?
-
Helmut Hirtenlehner
 ,
Johann Bacher
,
Johann Bacher

Zusammenfassung
In der kriminologischen Forschung werden Effekte delinquenter Peerexposition auf das Legalverhalten junger Menschen gerne im Bezugsrahmen statistischer Mehrebenenanalysen bestimmt, in welchen die auf Kontextebene hochaggregierten Selbstauskünfte der befragten Personen als Indikator für die Kriminalitätsbelastung der Freunde verwendet werden. Gerade im europäischen Raum liegen solchen Untersuchungen häufig schulbasierte Stichproben zugrunde. Stillschweigend angenommen wird dabei, dass sich erstens die Freunde eines Jugendlichen aus den Schulkameraden rekrutieren und dass zweitens die aggregierte Delinquenzrate einer Schulkasse eine geeignete Messgröße für die Berechnung des Peer-Effektes darstellt. Dieser Beitrag problematisiert die zweite Annahme und weist nach, dass einerseits das Abstellen auf die unkorrigierte Klassenkriminalitätsrate artifizielle Befunde produziert, weil es den einzelnen Jugendlichen in die Bildung der Expositionsvariablen miteinbezieht (Ego-Bias-Problem), und andererseits der Rückgriff auf herkömmliche Mehrebenenanalysen die reziproken Wirkungsdynamiken zwischen jungen Menschen und ihren Klassenkameraden (Simultanitätsproblem) vernachlässigt. Beide Umstände können auf eine Überschätzung kriminogener Peer-Effekte hinauslaufen. Im gegenständlichen Beitrag werden Modellierungsvarianten, die hier geeignete Abhilfe versprechen, vorgestellt und beispielhaft auf die Ladendiebstahlsdelinquenz von Kindern und Jugendlichen angewandt. Sowohl Instrumentalvariablenregressionsanalysen als auch nicht-rekursive Strukturgleichungsmodelle erbringen Belege für eine moderate Abhängigkeit der Ladendiebstahlsprävalenz adoleszenter Personen vom Umfang der Diebstahlskriminalität ihrer Klassenkameraden.
Abstract
In criminological research, criminogenic peer effects are sometimes estimated using multilevel models for school class based self-report data, whereby the aggregated crime prevalence rate of a class is employed as contextual-level predictor of an individual’s crime involvement. This approach assumes that, first, young people recruit their friends from the pool of their classmates, and second, that the aggregated delinquency rate of a school class is a proper indicator for estimating the delinquent peer effect. This article examines the second assumption and shows that the approach described above leads to biased results. It is faced with two problems: the adolescent whose behavior is explained is included in the calculation of the predictor variable (ego-bias problem) and the mutual influence between the adolescent and his classmates is neglected (simultaneity problem). Both problems may lead to inflated effect statistics. The present work introduces potential remedies and illustrates their application at the example of adolescent shoplifting activity. Both instrumental-variables regression and non-recursive structural equation models reveal significant effects of classmates’ delinquency rate on young people’s shoplifting involvement.
1 Problemstellung
Peer-Effekten kommt in der kriminologischen Forschung eine große Bedeutung zu. Zahlreichen Untersuchungen zufolge erhöht die Anzahl der Kontakte zu delinquenzaffinen Gleichaltrigen die Wahrscheinlichkeit eigener strafbarer Handlungen (Gerstner & Oberwittler 2015; Hirtenlehner & Bacher 2017; Hoeben, Meldrum, Walker & Young 2016; Matsueda & Anderson 1998; Pratt et al. 2010; Svensson & Oberwittler 2010; Warr 2002). Zweifellos repräsentiert Peerdelinquenz eines der robustesten Korrelate selbstberichteter Kriminalität.
Die Schätzung von Peer-Effekten setzt eine Messung der Peerdelinquenz voraus. Zwei grundlegende Ansätze der Erfassung delinquenter Aktivitäten im Freundeskreis lassen sich unterscheiden (Gerstner & Oberwittler 2015): indirekte Messungen, bei denen die Befragten Auskunft über die (wahrgenommene) Kriminalität ihrer Peers geben, und direkte Messungen, bei denen die Kriminalitätsbeteiligung der Peers bei den Freunden selbst erhoben wird. Indirekte Messungen haben den Nachteil, dass sie den Peer-Effekt systematisch überschätzen (Haynie & Osgood 2005; Hoeben et al. 2016; Rebellon & Modecki 2014), da das eigene Verhalten auf die Freunde projiziert und/oder irrtümlicherweise eine Ähnlichkeit mit dem Verhalten der Freunde angenommen wird. Mit der Überbewertung des Peer-Effektes ist häufig auch eine Unterschätzung der Erklärungskraft anderer Prädiktoren des Legalverhaltens verbunden.
Aus den genannten Gründen wird oft ein direkter Weg der Erfassung umgebender Peerdelinquenz bevorzugt, in dem z. B. die »peer-berichtete« Kriminalitätsbelastung der Freunde als unabhängige Variable in statistische Zusammenhangs- und Kausalanalysen einbezogen wird. Aufgrund von Restriktionen in der Datenerhebung wird in solchen Fällen gerne die aus den Selbstangaben der Klassenkameraden errechnete Kriminalitätsprävalenzrate der Schulklasse, die der Jugendliche besucht, als Indikator für das Niveau der Peerdelinquenz verwendet. Manchmal werden auch die individuellen Kriminalitätsinzidenzen der Schüler auf Klassenebene gemittelt. Die Ergebnisse dieser Studien zeigen durchwegs, dass die Kriminalitätswahrscheinlichkeit eines Schülers steigt, wenn die Delinquenzrate in seiner Klasse wächst (Hirtenlehner & Bacher 2017; Kim & Fletcher 2018; Weiss 2019; Windzio 2013).
Das Ablesen des Umfangs delinquenter Peerexposition aus der einschlägigen Täterrate in der eigenen Schulklasse geht von den Annahmen aus, dass sich (1.) die Freunde eines Jugendlichen aus dem Pool der Klassenkameraden rekrutieren und dass sich (2.) die Kriminalitätsrate einer Schulklasse als Messgröße für eine unverzerrte Schätzung des Peer-Effektes eignet. Die erste Annahme soll hier nicht problematisiert werden und vereinfachend daran festgehalten werden, dass die Freunde auch Klassenkameraden sind. Inhaltlich unbestritten bleibt, dass eine gemeinschaftliche Verstrickung in Kriminalität auch Gleichaltrige außerhalb des Klassenverbandes involvieren kann und nicht mit allen Freunden die Schulklasse geteilt wird (Friemel & Knecht 2009; Gerstner & Oberwittler 2015; Oberwittler 2004). Im Fokus des vorliegenden Beitrages steht hingegen die zweite Annahme, nämlich dass die aus den Selbstauskünften der einzelnen Schüler hochaggregierte Klassenkriminalitätsrate eine brauchbare Maßzahl für die Bestimmung des Einflusses der Kontakte zu delinquenten Peers auf das eigene Legalverhalten darstellt. Wie unschwer zu erkennen ist, haften der aus den Angaben der Schüler berechneten Delinquenzrate der Schulklasse zwei grundlegende methodische Probleme an. Wir wollen eines als Ego-Bias- und das andere als Reziprozitäts- oder Simultanitätsproblem bezeichnen[1]. Beide ziehen im Falle einer Nicht-Berücksichtigung bei der Datenanalyse das Risiko einer erheblichen Überschätzung delinquenter Peer-Effekte nach sich. Während aber Zweiterem auch durch ein Panel-Design begegnet werden könnte, würde eine mehrmalige Befragung desselben Personenkreises aufgrund der dokumentierten Stabilität delinquenten Handelns (frühere Kriminalität ist der beste Prädiktor späterer Kriminalität) nur wenig an der Virulenz des Ersteren ändern[2]. Dazu nun im Detail:
(1.) In die Schätzung der Delinquenzrate einer Schulklasse fließt die Delinquenz des Jugendlichen, dessen kriminelles Handeln als Zielvariable Gegenstand der Untersuchung ist, mit ein. Damit ist eine grundlegende Annahme jeglicher Kausalforschung verletzt, nämlich dass Ursache und Wirkung getrennt gemessen werden sollen: Das untersuchte (delinquente) Verhalten eines Jugendlichen ist sowohl abhängige Variable (Wirkung) als auch unabhängige Variable (Ursache), da es in die Berechnung der Kriminalitätsrate einer Schulklasse originär eingeht. Wir wollen dieses Problem als Ego-Bias-Problem bezeichnen und nachfolgend die sich daraus ergebenden fatalen Konsequenzen für die Schätzung des Peer-Effektes aufzeigen, um dann praktikable Modellierungsalternativen vorstellen zu können. Die präferierte Lösung des Ego-Bias-Problems impliziert, dass für die Schätzung des Peer-Effektes nicht die einfach auf Klassenebene hochaggregierte Prävalenzrate (oder die gemittelte Kriminalitätsinzidenz) verwendet wird, sondern der um den Jugendlichen, dessen kriminelles Handeln analysiert wird, bereinigte Täteranteil (oder Inzidenzmittelwert). In die Berechnung der Expositionsvariablen sollten nur die Klassenkameraden (alteri) einbezogen werden. Daraus resultieren allerdings unterschiedliche Werte der Expositionsvariablen für die Schüler einer Klasse, was deren Verwendung als Kontextmerkmal in einer statistischen Mehrebenenanalyse (Snijders & Bosker 2004) unmöglich macht.
(2.) Aber auch nach der Bereinigung um den Ego-Bias verbleibt noch ein zweites Problem, das darin besteht, dass der Jugendliche, dessen strafbares Verhalten als abhängige Variable untersucht wird, selbst einen Einfluss auf das delinquente Handeln seiner Schulkameraden haben kann. Nicht nur die Mitschüler lenken den Befragten, dieser übt auch seinerseits eine gestaltende Kraft auf das Legalverhalten der Klassenkameraden aus. Es liegt somit eine reziproke bzw. bidirektionale Wirkungsdynamik vor. Die sich daraus ergebenden Schwierigkeiten für die Bestimmung des kriminogenen Peer-Effektes sollen im Weiteren als Reziprozitäts- bzw. Simultanitätsproblem bezeichnet werden. Die Tatsache, dass auch die ego-korrigierte Delinquenzrate der Schulklasse vom Handeln des Befragten beeinflusst wird, verletzt mit der Exogenitätsbedingung eine zentrale Annahme aller Regressionsverfahren, nämlich dass der Fehlerterm der abhängigen Variablen nicht mit den Werten der unabhängigen Variablen korreliert (Bushway & Apel 2010).
Der vorliegende Beitrag greift die angesprochenen Problematiken auf, um ihre Konsequenzen zu illustrieren und praktikable Lösungsangebote zu unterbreiten. Nachfolgend sollen zunächst in Abschnitt 2 die Folgen der logischen Abhängigkeit der aggregierten Klassenkriminalitätsrate vom Legalverhalten des betrachteten Schülers anhand eines einfachen Rechenbeispiels mit fiktiven Daten verdeutlicht werden. Anschließend stellt Abschnitt 3 Lösungsansätze für die skizzierten Problemfelder in ihren methodologischen Grundlagen dar. Besondere Beachtung finden dabei die Korrektur der Expositionsvariablen um die Kriminalitätsbeteiligung des einzelnen Schülers und die statistische Modellierung des Peer-Effektes mittels Instrumentalvariablenregressionsanalysen und nicht-rekursiven Strukturgleichungsmodellen. Die vorgestellten Abhilfestrategien werden dann in Abschnitt 4 exemplarisch implementiert und evaluiert. Das Anwendungsbeispiel befasst sich mit der Bedeutung der Ladendiebstahlsdelinquenz der Klassenkameraden für die eigene Einlassung auf die Entwendung von Waren aus Verkaufsräumen. Eine Zusammenfassung der wesentlichen Erkenntnisse (Abschnitt 5) schließt den Beitrag ab.
2 Ein einfaches Beispiel zur Illustration der Ego-Bias-Problematik
Um ein erstes Verständnis der aus dem Ego-Bias-Problem resultierenden Verzerrungen zu gewinnen, wird ein einfaches lineares Wahrscheinlichkeitsmodell für die Prävalenz delinquenten Verhaltens untersucht. Die Zielvariable differenziert also nur zwischen dem Vorkommen oder Nicht-Vorkommen von Kriminalität. Das Modell nimmt an, dass die Wahrscheinlichkeit für das Begehen einer delinquenten Handlung nur von einem dichotomen Risikofaktor x mit den Werten »1« für »vorhanden« und »0« für »nicht vorhanden« abhängt. Fehlt der Risikofaktor, ist die Tatbegehungswahrscheinlichkeit
wobei
Wir wollen nun annehmen, dass jede Klasse nur aus zwei Schülern besteht, von denen ein Schüler den Risikofaktor aufweist und der andere nicht. Insgesamt liegen Informationen für zehn Klassen vor. Tabelle 1 stellt die Datenkonstellation dar, wobei für die Regressionsparameter Werte von
Einfaches Datenbeispiel zur Verdeutlichung der Ego-Bias-Problematik
| Klasse | Schüler | Risikofaktor x | Erwartungswert des delinquenten Verhaltens y | Beobachteter Wert von y | Täterrate in der Klasse |
| 1 | 1 | 1 | 0,6 | 1 | 1,0 |
| 1 | 2 | 0 | 0,1 | 1 | 1,0 |
| 2 | 3 | 1 | 0,6 | 1 | 0,5 |
| 2 | 4 | 0 | 0,1 | 0 | 0,5 |
| 3 | 5 | 1 | 0,6 | 1 | 0,5 |
| 3 | 6 | 0 | 0,1 | 0 | 0,5 |
| 4 | 7 | 1 | 0,6 | 1 | 0,5 |
| 4 | 8 | 0 | 0,1 | 0 | 0,5 |
| 5 | 9 | 1 | 0,6 | 1 | 0,5 |
| 5 | 10 | 0 | 0,1 | 0 | 0,5 |
| 6 | 11 | 1 | 0,6 | 1 | 0,5 |
| 6 | 12 | 0 | 0,1 | 0 | 0,5 |
| 7 | 13 | 1 | 0,6 | 0 | 0,0 |
| 7 | 14 | 0 | 0,1 | 0 | 0,0 |
| 8 | 15 | 1 | 0,6 | 0 | 0,0 |
| 8 | 16 | 0 | 0,1 | 0 | 0,0 |
| 9 | 17 | 1 | 0,6 | 0 | 0,0 |
| 9 | 18 | 0 | 0,1 | 0 | 0,0 |
| 10 | 19 | 1 | 0,6 | 0 | 0,0 |
| 10 | 20 | 0 | 0,1 | 0 | 0,0 |
Die Daten wurden so konstruiert, dass die beobachteten Durchschnittswerte erwartungstreue Schätzungen darstellen. Es gilt also:
Die Durchführung einer linearen Regression erbringt die erwarteten Ergebnisse (siehe »Modell ohne Peereffekt« in Tabelle 2). Die Konstante und der Steigungskoeffizient zeigen die vorab festgelegten Werte.
Ergebnisse einer linearen Regression für die Daten der Tabelle 1
| Modell ohne Peereffekt | Modell mit Klassen-delinquenzrate | |||
| Unabhängige Variable | b | p | b | p |
| Konstante | +0,100 | 0,470 | –0,250 | 0,034 |
| Risikofaktor x | +0,500 | 0,018 | +0,500 | 0,001 |
| Delinquenzrate in der Klasse | – | – | +1,000 | 0,005 |
b = Regressionskoeffizient, p = α-Fehlerniveau
Ergebnisse von OLS Regressionen. Auf eine Mehrebenenanalyse wurde verzichtet, da eine Kontexteinheit nur von 2 Personen gebildet wird. Die Signifikanz der Delinquenzrate der Klasse wurde korrigiert, indem als Fallzahl die Zahl der Klassen und nicht die Zahl der Personen verwendet wurde. Der signifikante Effekt der Delinquenzrate ist auch nach dieser Korrektur vorhanden.
Wird nun das Modell um einen Peer-Effekt erweitert und dieser mittels der aggregierten Delinquenzrate in der Klasse (siehe Spalte »Täterrate« in Tabelle 1) geschätzt, wird ein signifikanter Peer-Effekt von
3 Probate Analysestrategien
In dem oben dargestellten Beispiel wurden die Konsequenzen des Ego-Bias-Problems verdeutlicht. Dieses erwächst daraus, dass der Wert des Schülers in der abhängigen Variablen auch in die Berechnung der unabhängigen Variablen (der Delinquenzrate oder der mittleren Kriminalitätsinzidenz einer Schulklasse) miteinfließt. Eine intuitive Lösung der Problematik besteht darin, den Befragten aus der Bildung der Expositionsvariablen auszuschließen, indem nicht der einfach hochaggregierte Klassendurchschnitt
als Prädiktor zur Schätzung des Peer-Effekts verwendet wird, sondern der um Ego, den Schüler i, korrigierte Durchschnittswert (ego-korrigierte Klassenkriminalität). Die ego-korrigierte Delinquenzbelastung einer Schulklasse errechnet sich für jeden Schüler aus den Selbstauskünften allein der Klassenkameraden
und fällt somit für jeden Schüler unterschiedlich aus. Die Bereinigung um den Ego-Bias impliziert, dass verschiedene Schüler ein und derselben Klasse ungleiche Messwerte der delinquenten Peerexposition im Klassenverband aufweisen. Damit liegt allerdings keine für eine statistische Mehrebenenanalyse taugliche Kontextvariable mehr vor[3]. Ego-korrigierte Klassenkriminalität muss als Individualvariable behandelt werden.
Auch nach Beseitigung des Ego-Bias verbleibt indes das Reziprozitäts- oder Simultanitätsproblem. Nicht nur wird Ego von seinen Klassenkameraden beeinflusst, sondern er beeinflusst mit seinem Handeln auch ebendiese.
Das Simultanitätsproblem wurde u. a. in einem oft zitierten Beispiel aus der Statuserwerbsforschung von Duncan, Haller & Portes (1968) ausführlich behandelt. Duncan und Kollegen untersuchten die beruflichen Ansprüche eines Jugendlichen in Abhängigkeit von den beruflichen Ansprüchen seines besten Freundes und weiteren Kovariaten. Die Autoren nehmen an, dass sich die beiden Jugendlichen in ihren beruflichen Ansprüchen gegenseitig beeinflussen. Zusätzlich wird von einem Effekt des sozioökonomischen Status der Eltern und der Intelligenz des Jugendlichen ausgegangen, wobei vermutet wird, dass der sozioökonomische Status der Eltern sowohl auf die beruflichen Ansprüche des eigenen Kindes als auch auf jene des Freundes wirkt. Bei der Intelligenz wird von keiner gegenseitigen Beeinflussung ausgegangen: Die Intelligenz eines Jugendlichen formt nur seine eigenen beruflichen Ansprüche und nicht jene des Freundes. Das von den Autoren untersuchte Pfadmodell ist schematisch in Abbildung 1 angeführt.
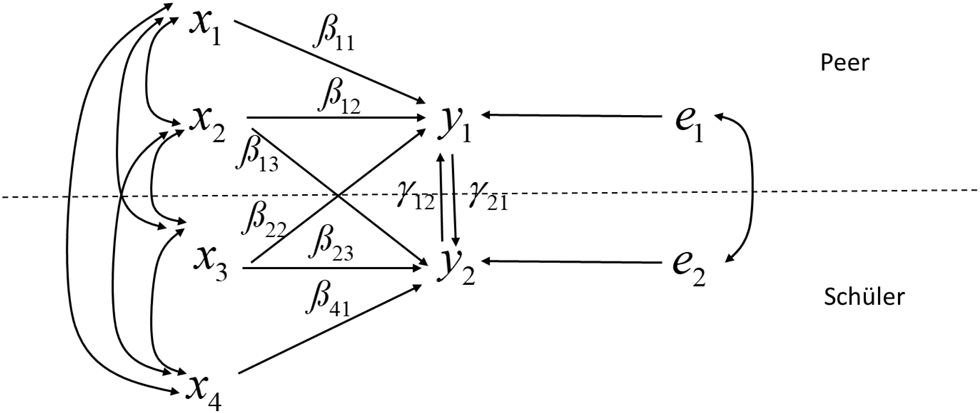
Formale Struktur des nicht-rekursiven Pfadmodells von Duncan et al. (1968)
x1 = Intelligenz des Freundes,
x2 = sozioökonomischer Status der Eltern des Freundes,
x3 = sozio-ökonomischer Status der Eltern des Jugendlichen,
x4 = Intelligenz des Jugendlichen,
y1 = berufliche Ansprüche des Freundes,
y2 = berufliche Ansprüche des Jugendlichen,
e1 = Fehlerterm für y1,
e2 = Fehlerterm für y2.
In Abbildung 1 bilden die x-Variablen die exogenen Variablen, die im Unterschied zu den endogenen y-Variablen nicht von anderen Variablen im Modell beeinflusst werden. Die Variable
Technisch betrachtet stellt im obigen Beispiel die Intelligenz eine Instrumentenvariable dar. Instrumentenvariablen spielen in der ökonomischen Forschung seit langem eine zentrale Rolle und die Instrumentenvariablenschätzung wird in jedem ökonometrischen Lehrbuch (Angrist & Pischke 2009; Cameron & Trivedi 2010; Johnston 1984) ausführlich erörtert. Die Idee dazu wurde erstmals von Philipp Wright, einem Ökonomen, in den 1920er Jahren – vermutlich gemeinsam mit seinem Sohn Sewall Wright – formuliert (Stock & Trebbi 2003). Sewall Wright gilt zugleich als Erfinder der Pfadanalyse, auf der die Ausführungen von Duncan et al. (1968) basieren.
Instrumentenvariablen finden zunehmend auch in der kriminologischen Forschung Beachtung (Angrist 2006; Bollen 2012; Bushway & Apel 2010; Kim & Fletcher 2018). Sie können in nicht-experimentellen Forschungen zur Behandlung unterschiedlicher Problematiken eingesetzt werden (Bollen 2012; Bushway & Apel 2010), u. a. zur Lösung des genannten Simultanitätsproblems, also der wechselseitigen Beeinflussung von zwei Variablen, in Abbildung 1 eben
Eine Schätzung des Einflusses von
Die Instrumentenvariable wirkt direkt auf
Die Instrumentenvariable von
Die Instrumentenvariable von
Mitunter wird noch als weitere vierte Bedingung die Homogenität der Wirkung der durch die Instrumentenvariable gemessenen Variablen auf die interessierende abhängige Variable angeführt (Lousdal 2018). Damit ist gemeint, dass der Effekt der untersuchten unabhängigen Variablen in unterschiedlichen Teilpopulationen des Samples gleich groß ausfällt. Diese Annahme wird aber allgemein in jeder Regressionsanalyse getroffen und ist somit kein Spezifikum der Verwendung von Instrumentenvariablen.
In Abbildung 1 erfüllt
Für eine Variable kann auch mehr als eine Instrumentenvariable spezifiziert werden. Das Modell der Abbildung 1 könnte also um weitere Instrumentenvariablen
Ist man nur an der Schätzung des Peer-Effekts (in dem Beispiel die Wirkung von
Die Bestimmung von Instrumentenvariablen markiert eine inhaltliche Aufgabe und muss theoriegeleitet erfolgen. Formal sollten die ausgewählten Instrumentenvariablen hinsichtlich der Variablen, deren Instrumente sie darstellen, eine hohe Varianzaufklärungskraft bzw. Korrelation aufweisen.[5] Ist dies der Fall, wird von »starken« Instrumentenvariablen gesprochen, anderenfalls von »schwachen« Instrumentenvariablen.
Zur Prüfung der Relevanzbedingung wird ein F-Test vorgeschlagen (siehe dazu später). Die beiden anderen Bedingungen lassen sich nur bedingt statistisch testen (siehe ebenfalls Abschnitt 4).
Nach der Auswahl von Instrumentenvariablen kann mit der eigentlichen Schätzung des Peer-Effekts begonnen werden.[6] Dafür bestehen zwei Möglichkeiten:
Schrittweise Schätzung im Rahmen der traditionellen Instrumentalvariablenanalyse (als Abfolge zweier aufeinander aufbauender Regressionsanalysen) oder
Simultanschätzung im Rahmen eines non-rekursiven Strukturgleichungsmodells (der Einschluss von Instrumentenvariablen wird hier für die Herstellung von Identifizierbarkeit benötigt).
Beide Varianten werden im Anwendungsbeispiel implementiert und sollen daher nachfolgend kurz beschrieben werden.
Bei der schrittweisen Schätzung, die ab nun als Instrumentalvariablenanalyse oder Instrumentalvariablenregression bezeichnet werden soll, wird zunächst in einem ersten Schritt eine Regressionsanalyse für
Entsprechend der Empfehlung in der Literatur werden neben der Instrumentenvariable
In einem zweiten Schritt wird eine Regressionsanalyse für
Die Instrumentenvariable
Das dargestellte schrittweise Vorgehen führt zu verzerrten, aber konsistenten Schätzwerten des Peer-Effekts, wenn die oben genannten drei Bedingungen erfüllt sind (Bascle 2008; Baum, Schaffer & Stillman 2003; 2007; Johnston 1984). Konsistent bedeutet, dass der geschätzte Effekt sich mit größer werdender Stichprobe dem wahren Wert annähert. Das Ausmaß der Verzerrung hängt u. a. von der Erklärungskraft der Instrumentenvariable(n) und der Stichprobengröße ab (Bascle 2008). Für valide inferenzstatistische Schlussfolgerungen ist wie bei der gewöhnlichen Regression Homoskedastizität, Unkorreliertheit und Normalverteilung der Fehlerterme erforderlich (Bascle 2008; Baum et al. 2007). Allerdings stehen robuste Berechnungsverfahren zur Verfügung (siehe dazu später), die Verletzungen dieser Annahmen zulassen.
Zur Durchführung der schrittweisen Schätzung wurden unterschiedliche Verfahren entwickelt. Am populärsten ist die sogenannte Two-Stage-Least-Squares-Technik (TSLS, 2SLS), bei der auf die Kleinste-Quadrate-Methode zurückgegriffen wird. Daneben sind noch weitere Kleinste-Quadrate-Methoden und Maximum-Likelihood-Verfahren verfügbar (Staiger & Stock 1997). Die sogenannte Limited-Maximum-Likelihood-Methode resultiert in geringeren Verzerrungen und schneidet bei schwachen Instrumentenvariablen besser ab als die 2SLS-Technik. Bei Verletzung der Homoskedastizitätsannahme und/oder bei korrelierten Residuen wird die Generalized Method of Moments (GMM) empfohlen (Baum et al. 2003; 2007).
Bei der Simultanschätzung mittels eines nicht-rekursiven Strukturgleichungsmodells wird das Gesamtmodell in einem Schritt berechnet, wobei i. d. R. Maximum-Likelihood-Verfahren zum Einsatz kommen. Der Begriff »simultan« verweist hier auf den Umstand, dass der Peer-Effekt und der Einfluss des eigenen Handelns auf die Alteri zugleich (wechselseitig auspartialisiert) ermittelt werden. Instrumentenvariablen müssen in die Modellgleichungen aufgenommen werden, um trotz reziproker Wirkungspfade eine Identifizierbarkeit des Gleichungssystems zu erlangen. Die simultane Schätzung führt bei richtiger Spezifikation des Modells zu effizienteren Schätzern als die schrittweise Methode, hat aber den Nachteil, dass sich Fehlspezifikationen in anderen Modellteilen auch auf die Schätzung des Peer-Effekts auswirken können (Williams 2015).
Nach erfolgter Berechnung der Modellparameter ist die Güte der Schätzergebnisse zu beurteilen. Abhängig von der Schätzmethode und dem verwendeten Ansatz (schrittweise vs. simultan) stehen unterschiedliche Maßzahlen zur Bewertung der Ergebnisqualität zur Verfügung. Neben den interessierenden Effekten sollte – sofern möglich – geprüft werden, wie gut die gewählten Instrumentenvariablen die an sie gestellten Bedingungen erfüllen.
Zusammenfassend wird für die Schätzung »direkter« Peer-Effekte bei querschnittlichen Klassenzimmerbefragungen somit folgende Vorgangsweise empfohlen:
Verwendung von ego-korrigierten Klassenkriminalitätsmaßen als Indikator für kriminogene Peereinflüsse an Stelle von einfach auf Klassenebene hochaggregierten Prävalenzraten und Durchschnittswerten.
Schätzung des Peer-Effektes mittels schrittweiser Instrumentalvariablenanalysen (wofür gängige Statistikprogramme integrierte Module zur Verfügung stellen – z. B. IVREGRESS oder IVREG2 in STATA) oder simultan im Rahmen eines nicht-rekursiven Strukturgleichungsmodells.
4 Ein Anwendungsbeispiel aus dem Bereich der Ladendiebstahls-delinquenz junger Menschen
4.1 Datenbasis und methodisches Vorgehen
Die im vorausgehenden Abschnitt entwickelten Modellierungsstrategien sollen nachfolgend auf die von Hirtenlehner & Bacher (2017) zur Prüfung der Interaktion von Peerdelinquenz und Sanktionsrisikowahrnehmung genutzten Daten einer Dunkelfeldbefragung zur Ladendiebstahlsdelinquenz junger Menschen angewandt und anschließend evaluiert werden.[8] Ebendort findet sich eine ausführliche Beschreibung des Stichprobendesigns und der verwendeten Operationalisierungen. Hier soll nur kurz festgehalten werden, dass rund 3.000 ober- und niederösterreichische Schüler der Jahrgangsstufen 7 und 8 computergestützt im Klassenverband befragt wurden. Das Sample rekrutiert sich aus insgesamt 184 Schulklassen aus 92 zufällig ausgewählten Schulen. An jeder Schule wurde zufallsbasiert eine 7. und eine 8. Klasse selektiert, in denen dann eine Vollerhebung durchgeführt wurde.
Als abhängige Variable wird die 1-Jahres-Prävalenz des Ladendiebstahls (1 = in den letzten zwölf Monaten mindestens eine Ladendiebstahlshandlung verübt, 0 = in den letzten zwölf Monaten keinen Ladendiebstahl begangen) untersucht, als unabhängige Variablen werden die in Tabelle 3 aufgelisteten Schüler- und Kontextmerkmale eingeführt.
Regressoren in den untersuchten Lösungsvarianten
| Variante 1: Schrittweise schätzung mittels IV | Variante 2: Simultane Schätzung mittels SEM | |
| Schülermerkmale i (Ego) | ||
| Niedrige Selbstkontrolle ( | ja | ja, IV a) |
| Niedrige Sanktionsrisikowahrnehmung ( | ja | ja, IV a) |
| Niedrige Moralität ( | ja | ja, IV a) |
| Geschlecht ( | ja | ja, IV a) |
| ego-korrigierte Klassenmerkmale(Durchschnittswerte allein der Klassenkameraden) | ||
| Ladendiebstahlsbelastung ( | ja | ja |
| Niedrige Selbstkontrolle ( | ja, nur IV b) | – |
| Niedrige Sanktionsrisikowahrnehmung ( | ja, nur IV b) | – |
| Niedrige Moralität ( | ja, nur IV b) | – |
| Anteil Jungen ( | ja, nur IV b) | – |
| Weitere Kontextmerkmale auf Klassenebene | ||
| Schulform ( | ja | ja |
| Schulstufe ( | ja | ja |
a) Instrumentenvariable (IV) für die Delinquenz des Schülers Ego bei der Schätzung mittels Strukturgleichungsmodell
b) Instrumentenvariable (IV) für die Delinquenz der Klassenkameraden
c) Hauptschule bzw. Neue Mittelschule
Bei der Auswahl der unabhängigen Variablen wurde angenommen, dass entsprechend Hirtenlehner & Bacher (2017) die Delinquenz eines Schülers abgesehen von der Kriminalitätsbelastung der Freunde von der Moralität, der Selbstkontrolle, der Sanktionsrisikowahrnehmung und dem Geschlecht des Individuums abhängt. Da dieses Erklärungsmodell für alle Schüler gilt, also für den untersuchten Schüler Ego und dessen Klassenkameraden, werden auf der Individualebene und der Klassenebene dieselben Einflussfaktoren vermutet. Als Kontextmerkmale auf Klassenebene, die sowohl die Delinquenzrate der Schulkameraden (= ego-korrigierte Klassenkriminalität) als auch das Legalverhalten des betrachteten Schülers beeinflussen, werden die Schulform und die Schulstufe spezifiziert. Durch diese beiden Variablen sollen Selektionseffekte (die nicht-zufällige Verteilung junger Menschen auf die verschiedenen Schultypen) und weitere Sozialisationseffekte erfasst werden.[9] Die Daten wurden mit IBM-SPSS Version 24 aufbereitet.[10] Fehlende Werte in den unabhängigen Variablen wurden mittels der EM-Methode (Reisinger, Svecnik & Schwetz 2012) geschätzt.[11] In der Zielvariablen liegen keine Missing Values vor. Die Syntax zur Berechnung der ego-korrigierten Klassenmerkmale ist im Anhang dokumentiert.
Entsprechend den erörterten Analysestrategien soll zunächst eine schrittweise Schätzung des Peereinflusses mittels Instrumentalvariablenanalyse (Variante 1) vorgenommen werden, daran anschließend dann eine simultane Schätzung der reziproken Wirkungsdynamik mittels Strukturgleichungsmodellierung (Variante 2). Für die Berechnung der Modellparameter werden in beiden Varianten lineare Wahrscheinlichkeitsmodelle eingesetzt. Wir haben uns für einen linearen Modellierungsansatz entschieden, weil die daraus gewonnenen Regressionsgewichte am einfachsten zu interpretieren sind und methodologische Arbeiten darauf hinweisen, dass logistische Analysen zu identen Befunden führen (Hellevik 2009). Da bezüglich der Prädiktoren gerichtete Hypothesen vorliegen, wird für alle Signifikanztestungen ein einseitiges Fehlerniveau verwendet.
Bei der Auswertung zu berücksichtigen ist jedenfalls, dass a) aufgrund des Stichprobenplans hierarchisch organisierte Daten mit einer Clusterstruktur vorliegen und b) aufgrund der dichotomen Natur der Zielvariablen die Annahme der Homoskedastizität der Fehlerterme automatisch verletzt ist. Aus den genannten Gründen sind spezielle Schätzverfahren zu wählen (siehe unten).
Um das Ausmaß der Verzerrung aufzuzeigen, das aus der Vernachlässigung des Ego-Bias- und des Simultanitätsproblems resultiert, wurde als Ausgangsbasis mit Mplus Version 8.2. (Muthén & Muthén 2017)[12] eine Mehrebenenanalyse gerechnet, in welcher entsprechend der bisherigen Praxis die hochaggregierte Klassenkriminalitätsrate (der Anteil der delinquenten Schüler in einer Klasse) als Kontextvariable verwendet wurde. Der Rückgriff auf die Mehrebenenanalyse ist dabei der geschachtelten Datenstruktur geschuldet. Um eine ausreichende Fallzahl auf Klassenebene zu erhalten, wurden nur Klassen mit mehr als 9 Schülern in die Analyse aufgenommen.[13] Als Schätzverfahren wurde angesichts der Verletzung der Homoskedastizitätsannahme eine Maximum-Likelihood-Methode mit robusten Standardfehlern (MLR) verwendet. Dabei wurde ein signifikanter Peer-Effekt von ß = 0,86 (p < 0,001) ermittelt (siehe Tabelle 5), der besagt, dass sich bei einem Anstieg der Klassenkriminalitätsrate um 10 % die Delinquenzwahrscheinlichkeit des untersuchten Schülers um 8,58 % erhöhen würde. Dies entspräche einem sehr starken Peereinfluss. Eine solche Interpretation ist allerdings wegen der Vernachlässigung des Ego-Bias- und des Reziprozitätsproblems als inkorrekt zu betrachten.
4.2 Instrumentalvariablenanalyse
Mplus 8.2. stellt unseres Wissens kein spezielles Modul für die Instrumentalvariablenanalyse zur Verfügung. Diese kann aber leicht realisiert werden, indem bei der Datenaufbereitung mit SPSS die Erwartungswerte für die ego-korrigierte Delinquenzrate der Mitschüler berechnet und als Variable an das Programm übergeben werden. Die vorgeschaltete Regression erbringt in IBM-SPSS Version 24 eine erklärte Varianz von 49,4 %, wobei die verwendeten Instrumentenvariablen eine Varianzaufklärungsleistung von 17,6 % aufweisen. Der korrespondierende F-Wert von 162,68 überschreitet den in der Literatur genannten Schwellenwert von 10 (z. B. Baum et al. 2007) um ein Vielfaches. Demzufolge liegen also »starke« Instrumentenvariablen vor, wobei allerdings einschränkend anzumerken ist, dass der F-Test für die vorhandene Datenstruktur nur bedingt anwendbar ist (siehe unten). Eine statistisch korrektere Betrachtung legt den Schluss nahe, dass keine schwachen, aber auch keine allzu starken Instrumente gewählt wurden.
Innerhalb der Instrumentalvariablen besitzt die Selbstkontrolle der Klassenkameraden (ß = 0,22) die höchste Determinationskraft, gefolgt von der Moralität und der Sanktionsrisikowahrnehmung der Mitschüler (ß = 0,20 und ß = 0,14).
Ergebnisse der vorgeschalteten Regressionsanalyse zur Berechnung der prognostizierten Werte der ego-bereinigten Klassen-delinquenz
| b | se(b) | ß | P | |
| Konstante | -0,306 | 0,016 | 0,000 | |
| Kovariaten: Schülermerkmale | ||||
| Niedrige Selbstkontrolle | 0,001 | 0,001 | 0,020 | 0,144 |
| Niedrige Sanktionsrisikowahrnehmung | 0,000 | 0,001 | 0,006 | 0,371 |
| Niedrige Moralität | 0,000 | 0,001 | -0,005 | 0,402 |
| Geschlecht (1 = Junge, 0 = Mädchen) | 0,000 | 0,002 | -0,002 | 0,451 |
| Schulform (1 = Gymnasium, 0 = Sonstige) | -0,014 | 0,002 | -0,111 | 0,000 |
| Schulstufe (1 = 8. Stufe, 0 = 7. Stufe) | 0,010 | 0,002 | 0,079 | 0,000 |
| Instrumentenvariablen: ego-korrigierte Klassenmerkmale | ||||
| Niedrige Selbstkontrolle | 0,014 | 0,001 | 0,217 | 0,000 |
| Niedrige Sanktionsrisikowahrnehmung | 0,009 | 0,001 | 0,136 | 0,000 |
| Niedrige Moralität | 0,006 | 0,001 | 0,195 | 0,000 |
| Anteil Jungen | 0,010 | 0,006 | 0,031 | 0,042 |
| R2 Gesamt | 0,494 | |||
| F-Wert Gesamt | 90,137 | 0,000 | ||
| R2 der Instrumentenvariablen | 0,176 | |||
| F-Werte für R2 der Instrumentenvariablen | 162,683 | 0,000 |
b = unstandardisierter Regresssionskoeffizient,
se(b) = Standardfehler von b,
ß = standardisierter Regressionskoeffizient,
p = α-Fehler (einseitig)
Datenquelle: Ladendiebstahlsstudie (Hirtenlehner & Bacher 2017), ungewichtete Daten, alle Klassen mit mehr als 9 befragten Schülern, n = 2.807
Ergebnisse der Schätzung der unterschiedlichen Modellvarianten zur Bestimmung des kriminogenen Peer-Effekts
| Vernachlässigung des Ego-Bias- und des Simultanitätsproblems | Variante 1 a: Manuelle IV-Schätzung (IBM-SPSS 24 & Mplus 8.2.) | Variante 1 b: Integrierte IV-Schätzung (Stata14, Modul IVREG2) | Variante 2: Schätzung mittels SEM (Mplus 8.2.) | |||||
| Parameter | p | Parameter | p | Parameter | p | Parameter | p | |
| Konstante | 0,010 | 0,0185 | 0,032 | 0,0000 | 0,032 | 0,0000 | 0,033 | 0,0000 |
| Niedrige Selbstkontrolle | 0,024 | 0,0000 | 0,026 | 0,0000 | 0,026 | 0,0000 | 0,026 | 0,0000 |
| Niedrige Sanktionsrisikowahrnehmung | 0,013 | 0,0020 | 0,016 | 0,0005 | 0,015 | 0,0005 | 0,016 | 0,0005 |
| Niedrige Moralität | 0,027 | 0,0000 | 0,031 | 0,0000 | 0,031 | 0,0000 | 0,031 | 0,0000 |
| Geschlecht (1 = Junge, 0 = Mädchen) | 0,011 | 0,0690 | 0,014 | 0,0435 | 0,013 | 0,0505 | 0,014 | 0,0041 |
| Peer-Effekt | 0,858 | 0,0000 | 0,206 | 0,0725 | 0,191 | 0,0495 | 0,142 | 0,0270 |
| Schulform | -0,010 | 0,0010 | -0,011 | 0,1165 | -0,010 | 0,0740 | -0,010 | 0,0900 |
| Schulstufe | -0,011 | 0,0005 | 0,005 | 0,2990 | 0,006 | 0,2235 | 0,007 | 0,1670 |
Datenquelle: Ladendiebstahlsstudie (Hirtenlehner & Bacher 2017), ungewichtete Daten, alle Klassen mit mehr als 9 befragten Schülern, n = 2.807, p = α-Fehler (einseitig)
Nach Einlesen der prognostizierten ego-korrigierten Mitschülerkriminalitätswerte in Mplus kann der Peereinfluss bestimmt werden. Mplus 8.2. berechnet einen Peereffekt von 0,21 mit einer tendenziellen Signifikanz (p < 0,10). Im Vergleich zur bisher verwendeten inkorrekten Schätzung reduziert sich der Effekt deutlich von 0,858 auf 0,206 (siehe Tabelle 5).
Die soeben vorgenommene Analyse mit SPSS und Mplus trägt der Clusterstruktur der Daten und der Heteroskedastizität Rechnung. Sie trifft aber die Annahme, dass die Fehlerterme innerhalb eines Clusters, also einer Schulklasse, unkorreliert sind. Diese Annahme ist insofern problematisch, als der untersuchte Jugendliche in die Berechnung der ego-korrigierten Klassenkriminalitätswerte aller seiner Mitschüler eingeht, sodass klassenintern korrelierte Fehlerterme zu vermuten sind. STATA14 bietet mit IVREG2 (Baum et al. 2003; 2007) ein leistungsstarkes Modul für die Instrumentenvariablenregression an. IVREG2 stellt die sogenannte Generalized Method of Moments (GMM) zur Verfügung, die sowohl korrelierte Fehlerterme innerhalb der Cluster als auch Heteroskedastizität zulässt. Zudem stehen umfangreiche Tests für die Prüfung der Modellannahmen zur Verfügung, nämlich[14]:
Tests auf fehlende Identifikation (»underidentification tests«). Mit diesen Tests wird geprüft, ob überhaupt Instrumentenvariablen in ausreichender Zahl vorhanden sind. Die H0-Hypothese lautet, dass dies nicht der Fall ist. Erwünscht sind somit signifikante Abweichungen von der H0-Hyopthese.
Tests auf fehlende Relevanz (»weak identification tests«). Mit diesen Tests wird geprüft, ob schwache oder starke Instrumentenvariablen vorliegen. Die H0-Hypothese lautet, dass nur schwache Instrumentenvariablen vorliegen, und sie sollte daher verworfen werden.
Tests auf Exogenität (»overidentification tests«). Mit diesen Tests wird untersucht, ob die Fehlerterme unabhängig von den Instrumentenvariablen sind. Anwendbar sind sie nur, wenn mehr als eine Instrumentenvariable verwendet wird. Erwünscht ist in diesem Fall ein insignifikantes Ergebnis, da die H0-Hypothese lautet, dass die Fehlerterme und die Instrumentenvariablen unkorreliert sind. Vorausgesetzt wird, dass mindestens ein exogenes Instrument vorliegt, wobei sich diese Voraussetzung selbst nicht prüfen lässt.
Übersicht 1 fasst die verfügbaren Tests zusammen.
Verfügbare Tests in STATA 14
| Test | Fragestellung | Standardvariantea) | Robuste Varianteb) |
| Fehlende Identifikation | H0: Es liegt keine ausreichende Zahl an Instrumentenvariablen vor. | Anderson canonical correlation LM Statistic | Kleibergen-Paap rk LM Statistic |
| Fehlende Relevanz | H0: Es liegen nur schwache Instrumente vor. | Cragg-Donald Wald F Statistic | Kleibergen-Paap rk Wald F Statistic |
| Vorhandene Exogenität | H0: Fehlerterme der abhängigen Variablen und die Instrumentenvariable sind unkorreliert, gegeben es liegt zumindest eine exogene Instrumentenvariable vor. | Sargan Statistic | Hasen J Statistic |
a) Bei der Standardvariante wird Homoskedastizität, Unkorreliertheit und identische Verteilung der Fehlerterme für beliebige Ausprägungskombinationen der unabhängigen Variablen angenommen (i.i.d. Bedingung = independent identical distrubuted error terms)
b) Bei der robusten Schätzung werden die Annahmen der Standardvariante nicht getroffen.
Führt man die schrittweise Instrumentalvariablenanalyse mit IVREG2 durch, wird ein numerisch zwar etwas kleinerer Peer-Effekt von 0,19 ermittelt, welcher jetzt aber statistisch signifikant ausfällt (p < 0,05; siehe Tabelle 5). Wenn man der Struktur der gegebenen Daten adäquat Rechnung trägt, kann damit ein systematischer überzufälliger Peereinfluss nachgewiesen werden. Ein Anstieg der Delinquenzrate der Klassenkameraden um 10 % zieht ein um 1,91 % erhöhtes Kriminalitätsrisiko des untersuchten Schülers nach sich.
Tabelle 6 zeigt die Ergebnisse der einschlägigen Modellprüfung.
Ergebnisse der Modellprüfung für die IV-Schätzung mit IVREG2 in Stata 14
| Testgröße | Wert | Signifikanz |
| Test auf fehlende Identifikation | ||
| Kleibergen-Paap rk LM Statistic | 32,58 | 0,000 |
| Test auf Relevanz der Instrumentenvariablen | ||
| Cragg-Donald Wald F Statistic | 162,68 | |
| Kleibergen-Paap rk Wald F Statistic | 11,31 | |
| Kritische Werte nach Stock-Yogo (2005): | ||
| 5 % maximal IV relative bias | 16,85 | |
| 10 % maximal IV relative bias | 10,27 | |
| 20 % maximal IV relative bias | 6,71 | |
| 30 % maximal IV relative bias | 5,34 | |
| 10 % maximal IV size | 24,58 | |
| 15 % maximal IV size | 13,96 | |
| 20 % maximal IV size | 10,26 | |
| 25 % maximal IV size | 8,31 | |
| Test auf Exogenität | ||
| Hansen J Statistic | 0,824 | 0,844 |
Der Test auf fehlende Identifikation (»underidentification test«) erbringt das positive Ergebnis, dass die H0-Hypothese, wonach keine ausreichende Zahl an Instrumentalvariablen vorliegt, verworfen werden kann.
Der F-Test (»Cragg-Donald Wald F Statistic«)[15] zur Beurteilung der Relevanz ist in dem Beispiel nur bedingt interpretierbar, da er von unabhängigen und identisch verteilten Fehlertermen ausgeht (siehe Übersicht 1). Wäre diese Annahme erfüllt, wäre der Test signifikant und die H0-Hypothese, dass nur schwache Instrumentenvariablen vorliegen, könnte verworfen werden. Die »Kleibergen-Paap rk Wald F Statistic« stellt das robuste Pendant zum F-Test dar. Allerdings fehlen für sie allgemein akzeptierte Schwellenwerte (Baum et al. 2007, 490). Empfohlen wird daher (ebenda), die kritischen Werte von Stock & Yogo (2005) zu verwenden oder auf den Schwellenwert von 10 zurückzugreifen. Mit Blick auf die von Stock & Yogo (2005) angeführten Schwellen müssten wir von einem maximalen relativen Schätzfehler von ca. 10 % ausgehen. Der Schwellenwert von 10 wird nur knapp überschritten, was indiziert, dass wir keine starken, aber auch keine allzu schwachen Instrumentenvariablen benutzen.
Der Hansen J-Test schließlich prüft die Exogenitätsbedingung. Erwünscht ist hier ein insignifikantes Ergebnis, welches sich auch einstellt. Vorausgesetzt wird freilich, dass mindestens eine der Instrumentenvariablen exogen ist.
Als Zwischenfazit lässt sich somit festhalten, dass ein signifikanter Peer-Effekt in Erscheinung tritt, wenn in der Schätzung die vorhandene Datenstruktur (Heteroskedastizität und Korreliertheit der Fehler innerhalb der Schulklassen) korrekt berücksichtigt wird. Die Wahrscheinlichkeit, dass ein junger Mensch einen Ladendiebstahl begeht, wächst mit der Ladendiebstahlsbelastung seiner Klassenkameraden.
4.3 Strukturgleichungsmodellierung
Alternativ lässt sich der Einfluss der Mitschüler auf das eigene Legalverhalten auch im Rahmen einer linearen Strukturgleichungsmodellierung (SEM) bestimmen. Nicht-rekursive Kovarianzstrukturanalysen erlauben es, den Effekt delinquenter Klassenkameraden auf das eigene Handeln und die Wirkung des persönlichen Handelns auf die Kriminalität der Mitschüler – also die reziproke Beziehungsdynamik – in einem Rechengang zu schätzen. Die Berechnung der Modellparameter erfolgte hier wiederum im Maximum-Likelihood-Verfahren mit robusten Standardfehlern. Um das Gleichungssystem identifizierbar zu machen, muss jeweils mindestens eine Instrumentenvariable als Prädiktor der ego-bereinigten Klassenkriminalitätsrate und der Ladendiebstahlsprävalenz des individuellen Schülers spezifiziert werden.
Die Simultanschätzung mittels SEM liefert in Mplus 8.2. einen kriminogenen Peer-Effekt in der Höhe von 0,14, der numerisch zwar kleiner als jener der Instrumentalvariablenregression ausfällt, sich aber ebenfalls statistischer Signifikanz erfreuen darf (p < .05; siehe Tabelle 5). Alle Modellprüfgrößen deuten auf eine sehr gute Anpassungsleistung hin (siehe Tabelle 7), sodass hier der in Kapitel 3 genannte Vorteil der simultanen Schätzung, nämlich deren größere Effizienz, tatsächlich zum Tragen kommt.
Modellfit, Residuen und Modifikationsindizes des berechneten Strukturgleichungsmodells
| Prüfgrößen | Schwellena) | Empirischer Wert |
| Modellfit | ||
| Root-Mean-Square-Error-of-Approximation (RMSEA) | < 0,05 | 0,000 |
| Comperative-Fit-Index (CFI) | > 0,95 (0,97) | 1,000 |
| Tucker-Lewis-Index (TLI) | > 0,95 (0,97) | 1,092 |
| Standardized-Root-Mean-Square-Residual (SRMR) | < 0,05 | 0,005 |
| Standardisierte Residuen | > 1,96 | keine |
| Modifikationsindizes | > 3,84 | keine |
a) Die angeführten Akzeptanzschwellen (mit Ausnahme des Modifikationsindizes) stammen aus Geiser (2011, 60–62). Für den Modifikationsindex ergibt sich der Schwellenwert aus der Tatsache, dass er eine Chi-Quadrat-Verteilung mit einem Freiheitsgrad besitzt.
Das empirische Modell ist in Abbildung 2 auch graphisch dargestellt. Wie den Ergebnissen entnommen werden kann, wirkt auf Seite der Schulkameraden nur eine Variable signifikant auf die ego-bereinigte Klassenkriminalitätsrate, nämlich die durchschnittliche Selbstkontrolle der Mitschüler. Auf Seiten der einzelnen Untersuchungsperson tragen alle betrachteten Individualmerkmale signifikant zur Erklärung der Einlassung auf Straftaten bei. Dazu kommt der schon angesprochene direkte Effekt der Peerdelinquenz. Wenn der Anteil der kriminalitätserfahrenen Klassenkameraden um 10 % steigt, wächst die Wahrscheinlichkeit eigener Straffälligkeit um 1,4 %.
Ein systematischer Einfluss der Kriminalität des einzelnen Schülers auf die Delinquenzbelastung der Klassenkameraden konnte hingegen nicht beobachtet werden. Letzteres ist vor dem Hintergrund der Abwesenheit von Möglichkeiten der Mitschülerselektion zu beurteilen. Eine einmal getroffene Klasseneinteilung bleibt in Österreich vier Jahre lang weitgehend stabil – der einzelne Schüler kann nicht bestimmen, mit wem er das Klassenzimmer teilt.
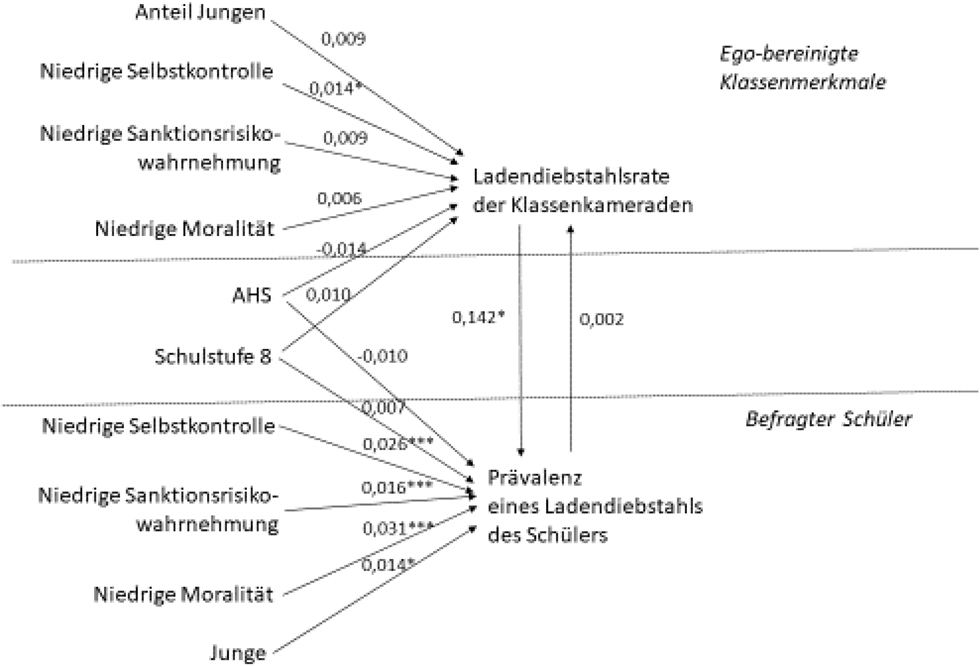
Ergebnisse der Schätzung des non-rekursiven Strukturgleichungsmodells
* p < 0,05 ** p < 0,01 *** p < 0,001 p = α-Fehler (einseitig)
Das berechnete Modell zeigt wie schon erwähnt eine exzellente Anpassungsqualität, und auf der individuellen Ebene werden auch mehrere signifikante Bedingungsfaktoren ermittelt. Dies darf aber nicht darüber hinwegtäuschen, dass die Varianzaufklärungsleistung auf der Ebene der Klassenkameraden (R² = 0,17) unbefriedigend ausfällt. Hier wird nur ein signifikanter Effekt, nämlich der der ego-korrigierten Selbstkontrolle auf die ego-bereinigte Ladendiebstahlsquote, ausgewiesen. Dieser Befund steht im Einklang mit den Ergebnissen von IVREG2, denen zufolge keine allzu starken Instrumentalvariablen vorliegen. Die in Tabelle 4 berichtete Signifikanz der Steigungskoeffizienten in der vorgeschalteten Regression zur Berechnung der Erwartungswerte der ego-bereinigten Klassendelinquenz ist nur darauf zurückzuführen, dass dort die Clusterstruktur der Daten nicht adäquat berücksichtigt wurde, was auf eine Unterschätzung der Standardfehler und eine Überschätzung der Signifikanzen hinauslief (Bacher 2009). Rechtfertigen lässt sich die Vernachlässigung der geschachtelten Struktur der Daten mit dem Verweis darauf, dass es vormals eben nur um die Ermittlung der Prognosewerte ging.[16] Wird auch in diesem Schritt der hierarchischen Organisation der Daten Rechnung getragen, was mit IVREG2 möglich ist, ergibt sich ebenfalls nur ein signifikanter Effekt der mangelnden Selbstkontrolle. Wichtig für unsere Zwecke ist in erster Linie der Umstand, dass die berechneten Regressionskoeffizienten (Vorzeichen und Größe) bei beiden Schätzvarianten (gewöhnliche OLS-Regression mit SPSS und GMM-Schätzung mit IVREG2) identisch ausfallen.
5 Zusammenfassung
Anliegen der vorliegenden Arbeit war es, den Fragen nachzugehen, ob die aggregierte Delinquenzbelastung einer Schulklasse als Maßzahl für die Testung kriminogener Peer-Effekte taugt, welche Probleme mit der Verwendung dieser Messgröße verbunden sind und wie der Einfluss der Mitschüler auf das eigene Legalverhalten möglichst unverzerrt bestimmt werden kann. In der (deutschsprachigen) kriminologischen Forschung wird die Bedeutung delinquenter Peerexposition für die Kriminalitätshäufigkeit junger Menschen gerne gestützt auf Schülerbefragungen geprüft, indem ein Mehrebenenmodell gerechnet wird, in welchem die Kriminalitätsprävalenzrate der Schulklasse, die der Jugendliche besucht, prädiktorenseitig als Kontextmerkmal einbezogen wird (Hirtenlehner & Bacher 2017; Weiss 2019; Windzio 2013). Selbst wenn man die Annahme stehen lässt, dass sich die Freunde aus den Klassenkameraden rekrutieren, ist ein solches Vorgehen als zweifelhaft zu betrachten. Zum einen liegt ein Ego-Bias vor, da der Jugendliche, dessen Verhalten man erklären will, zugleich in die Bildung der Expositionsvariablen miteinfließt und dadurch die Messung der Regressoren kontaminiert. Zum zweiten besteht ein Simultanitäts- bzw. Reziprozitätsproblem, da der betreffende Jugendliche nicht nur selbst von seinen Mitschülern beeinflusst wird, sondern dieser mit seinem eigenen Handeln auch auf das Legalverhalten der Klassenkameraden einzuwirken vermag. Das Abstellen auf die hochaggregierte Klassenkriminalitätsrate als Kontextebenenprädiktor wird daher regelmäßig zu einer Überschätzung der realen Peereinflüsse führen. Es kann – wie anhand eines fiktiven Beispiels gezeigt wurde – sogar ein substanzieller Peer-Effekt errechnet werden, wenn ein solcher in den Daten gar nicht vorhanden ist.
Eine statistisch korrekte Bestimmung des Effektes delinquenter Peerexposition kann nur erreicht werden, indem (1.) anstelle der einfach auf Klassenebene hochaggregierten Kriminalitätsprävalenzrate ein ego-korrigierter Messwert verwendet wird, in den nur die Klassenkameraden einfließen, und (2.) bei der Schätzung auch der reziproken Wirkungsdynamik zwischen Schülern und ihren Klassenkameraden Rechnung getragen wird. Letzteres impliziert, dass für die ego-bereinigte Klassenkriminalität Instrumentenvariablen spezifiziert werden müssen, die bestimmte Bedingungen erfüllen. Nach erfolgter Selektion solcher Instrumentenvariablen stehen zwei Analysestrategien zur Verfügung – ein schrittweises Vorgehen im Rahmen der etablierten Instrumentalvariablenregression (Bushway & Apel 2010) und eine Simultanschätzung der reziproken Wirkungspfade im Bezugsrahmen der Strukturgleichungsmodellierung (Williams 2015). Die beiden Ansätze unterscheiden sich darin, dass bei der Instrumentenvariablenregression nur der (um die Rückkoppelungswirkung korrigierte) Einfluss der Kriminalität der Klassenkameraden auf die Delinquenz des Schülers berechnet wird, während bei der Strukturgleichungsmodellierung beide Effekte – jener der Klassenkameraden auf den Schüler und umgekehrt jener des Schülers auf die Klassenkameraden – zugleich geschätzt werden.
Für das untersuchte Anwendungsbeispiel konnte bei korrekter Spezifikation der vorhandenen Datenkonstellation ein statistisch signifikanter kriminogener Peer-Effekt wiederholt nachgewiesen werden. Sowohl Instrumentalvariablenanalysen als auch nicht-rekursive Strukturgleichungsmodelle geben zu erkennen, dass die eigene Bereitschaft zum Entwenden von Waren aus Geschäften mit dem Anteil ladendiebstahlserfahrener Klassenkameraden wächst. Dieser Befund passt zur Beobachtung, dass junge Menschen ihre Ladendiebstahlshandlungen häufig im Beisein gleichaltriger Peers begehen (Farrington 1999).
Die Höhe der ermittelten Regressionskoeffizienten ist als moderat zu beurteilen, was einmal mehr darauf hindeutet, dass korrekte direkte Messungen der Kriminalität im Gleichaltrigenumfeld niedrigere Effekte auf das persönliche Legalverhalten produzieren als Maßzahlen der perzipierten Peerdelinquenz (Hoeben et al. 2016). Der geringe eigene Einfluss auf das Ausmaß der Mitschülerkriminalität ist u. a. dem Umstand geschuldet, dass Kinder und Jugendliche nicht steuern können, wer ihrem Klassenverband angehört. Insofern können Diebstahlsaktivitäten einer Person schulintern kaum Selektionseffekte entfalten.
Obwohl die hier vorgestellten Analysetechniken eine statistisch korrekte Schätzung des von der Gesamtheit der Klassenkameraden ausgehenden kriminogenen Effektes ermöglichen, legen die Ausführungen und Ergebnisse nahe, in Zukunft auch dem Problem der Messung des Umfangs delinquenter Peerexposition mehr Aufmerksamkeit zu widmen. Dem dargestellten Vorgehen liegt die Annahme zugrunde, dass sich die Freunde eines Jugendlichen aus der eigenen Schulklasse rekrutieren. Das muss nicht immer der Fall sein, etwa dann, wenn die Schüler einpendeln und dabei aus unterschiedlichen Städten oder Gemeinden kommen. Klassenkameraden werden daher nur einen begrenzten Ausschnitt des gesamten Freundschaftsnetzwerkes junger Menschen repräsentieren (Friemel & Knecht 2009).
Gravierender wirkt vermutlich die Tatsache, dass nicht alle Schüler einer Klasse miteinander befreundet sind (und folglich auch Freizeit gemeinsam verbringen), sondern die Freunde nur eine Teilgruppe des Klassenverbandes bilden. In die Berechnung der ego-bereinigten Klassenkriminalitätsrate können zahlreiche Individuen einfließen, die als Bezugsperson und Orientierungsgröße eines Schülers wenig relevant sind. Die Kriminalitätsbelastung der Klassenkameraden wird daher nur ein unscharfes, möglicherweise systematisch verzerrtes Bild von der Delinquenz im Freundeskreis junger Menschen zeichnen. Peer-Effekte sollten dadurch abgeschwächt werden. Etwas abgemildert werden kann dieser Bias, indem man Klassenzimmerbefragungen mit ego-zentrierten Netzwerkanalysen kombiniert, wie Gerstner & Oberwittler (2015) es beispielsweise tun. Das Identifizieren der tatsächlichen Freunde unter den Klassenkameraden und die Berechnung der Kriminalitätsprävalenzrate nur auf Basis der als Freunde genannten Mitschüler wird eine zielgenauere Messung delinquenter Peerexposition hervorbringen. Essentiell bleibt dennoch, schon bei der Konstruktion der Erhebungsinstrumente auf die Miteinbeziehung geeigneter Instrumentenvariablen zu achten. In der vorliegenden Anwendung ist das leider nur teilweise gelungen.
6 Anhang
IBM-SPSS 24
Nachfolgende Syntax nimmt zunächst eine EM-Schätzung der fehlenden Werte vor, berechnet anschließend die ego-korrigierten Klassenmittelwerte und führt den ersten Schritt der »Two-Stage-Least-Squares«-Schätzung durch. Abschließend werden die Datenfiles für Mplus und STATA erzeugt und abgespeichert.
cd »C:\bacher\ladendiebstahl\data\«.
GET FILE='Bacher.sav'.
DATASET NAME DataSet1 WINDOW=FRONT.
recode schulform (1=1) (0=0) into ahs.
recode schulstufe (1=1) (0=0) into stufe8.
recode sex (0=0) (1=1) into junge.
crosstab tab=schulform by ahs/schulstufe by stufe8/sex by junge.
MVA VARIABLES=classid flnr sat_morality sat_selfcont sat_deter junge ahs
stufe8 ld12ja stadt
/EM sat_morality sat_selfcont sat_deter junge ahs stufe8 stadt (TOLERANCE=0.001 CONVERGENCE=0.0001 ITERATIONS=25 outfile="bacherEM.sav«).
get file="BacherEM.sav«.
DATASET NAME DataSet1 WINDOW=FRONT.
*Ego-bereinigte Durchschnittswerte berechnen.
aggregate outfile=* mode=addvariables overwrite=yes
/break classid
/xnclass=nu
/xsat_deter xsat_morality xsat_selfcont =
sum(sat_deter sat_morality sat_selfcont)
/xjunge=sum(junge)
/xld12ja=sum(ld12ja)
/yyalle=mean(ld12ja).
*Klassen mit mehr als 9 Schülern auswählen.
select if (xnclass>9).
compute xnclass_i=xnclass – 1.
compute xld12ja_i=(xld12ja – ld12ja)/xnclass_i.
compute xsat_deter_i=(xsat_deter – sat_deter)/xnclass_i.
compute xsat_morality_i=(xsat_morality – sat_morality)/xnclass_i.
compute xsat_selfcont_i=(xsat_selfcont – sat_selfcont)/xnclass_i.
compute xjunge_i=(xjunge – junge)/xnclass_i.
*Standardisieren der Individualmerkmale zur besseren
*Interpretation der Effekte.
desc var=sat_deter sat_morality sat_selfcont/save.
*Berechnung der Erwartungswerte für Delinquenzrate der Schulkameraden.
delete variables yy.
regression var=xld12ja_i xsat_selfcont_i xsat_deter_i xsat_morality_i xjunge_i
ahs stufe8 zsat_selfcont zsat_deter zsat_morality junge
/dep=xld12ja_i/method=enter xsat_selfcont_i xsat_deter_i
xsat_morality_i xjunge_i ahs stufe8
zsat_selfcont zsat_deter zsat_morality junge
/save pred(yy).
*Berechnung des zusätzlichen Erkenntnisgewinns.
regression var=xld12ja_i xsat_selfcont_i xsat_deter_i
xsat_morality_i ahs stufe8 xjunge_i
zsat_selfcont zsat_deter zsat_morality junge
/stat=all
/dep=xld12ja_i
/method=enter ahs stufe8 zsat_selfcont zsat_deter zsat_morality junge
/method=enter zsat_selfcont zsat_deter zsat_morality junge xsat_selfcont_i
xsat_deter_i xsat_morality_i xjunge_i ahs stufe8.
*Stata-Datenfile erzeugen. .
SAVE TRANSLATE OUTFILE='C:\bacher\ladendiebstahl\stata\peerallestataV2.dta'
/TYPE=STATA
/VERSION=13
/EDITION=INTERCOOLED
/keep= classid flnr ahs stufe8 xld12ja_i ld12ja yy yyalle
zsat_selfcont zsat_deter zsat_morality junge
xsat_selfcont_i xsat_deter_i xsat_morality_i xjunge_i
/MAP
/REPLACE.
SAVE TRANSLATE OUTFILE="C:\bacher\ladendiebstahl\mplus\peeralleV2.dat"
/TYPE=TAB
/textoptions decimal = dot
/keep=classid flnr ahs stufe8 xld12ja xld12ja_i ld12ja yy yyalle
zsat_selfcont zsat_deter zsat_morality junge
xsat_selfcont_i xsat_deter_i xsat_morality_i xjunge_i
/MAP
/REPLACE
/CELLS=VALUES.
STATA 14
Die Befehlssyntax für das Einlesen der Daten und die robuste GMM-Schätzung lautet:
use »D:\ladendiebstahl\stata\peerallestata.dta«, clear
ivreg2 ld12ja (xld12ja_i= xsat_selfcont_i xsat_deter_i xsat_morality_i xjunge_i) Zsat_selfcont Zsat_deter Zsat_morality junge ahs stufe8, gmm2s robust first cluster(classid)
Mplus 8.2
Der Input-File für die Schätzung des nicht-rekursiven Strukturgleichungsmodells wird dargestellt.
data:
file=peeralleV2.dat;
variable:
NAMES ARE classid flnr ahs stufe8 xld12ja xld12ja_i ld12ja yy yyalle
zsat_selfcont zsat_deter zsat_morality junge
xsat_selfcont_i xsat_deter_i xsat_morality_i xjunge_i;
usevar = ld12ja ahs stufe8 zsat_selfcont zsat_deter zsat_morality junge
xld12ja_i
xsat_selfcont_i xsat_deter_i xsat_morality_i xjunge_i;
cluster=classid;
missing are all (-99);
define:
ANALYSIS: estimator=mlr;
TYPE IS complex;
MODEL:
ld12ja ON zsat_selfcont zsat_deter zsat_morality junge xld12ja_i ahs stufe8 ;
xld12ja_i ON ahs stufe8 xsat_selfcont_i xsat_deter_i xsat_morality_i xjunge_i;
ld12ja ON xld12ja_i;
xld12ja_i ON ld12ja;
OUTPUT: sampstat TECH2 standardized modindices(1) residual;
Literatur
Angrist, J.D. (2006). Instrumental variables methods in experimental criminological research: what, why and how. Journal of Experimental Criminology 2 (1), 23–44.10.1007/s11292-005-5126-xSearch in Google Scholar
Angrist, J.D. & Pischke, J.-S. (2009). Mostly Harmless Econometrics. An Empiricist's Companion. Princeton: Princeton University Press.10.1515/9781400829828Search in Google Scholar
Bacher, J. (2009). Analyse komplexer Stichproben. In M. Weichbold, J. Bacher & C. Wolf (Hrsg.), Umfrageforschung. Herausforderungen und Grenzen (253–272). Wiesbaden: VS Verlag für Sozialwissenschaften.10.1007/978-3-531-91852-5Search in Google Scholar
Bascle, G. (2008). Controlling for endogeneity with instrumental variables in strategic management research. Strategic Organization 6 (3), 285–327.10.1177/1476127008094339Search in Google Scholar
Baum, C., Schaffer, M.E. & Stillman, S. (2003). Instrumental variables and GMM: Estimation and testing. The Stata Journal 3 (1), 1–31.10.1177/1536867X0300300101Search in Google Scholar
Baum, C., Schaffer, M.E. & Stillman, S. (2007). Enhanced routines for instrumental variables/generalized method of moments estimation and testing. The Stata Journal 7 (1), 465–506.10.1177/1536867X0800700402Search in Google Scholar
Bollen, K.A. (2012). Instrumental variables in sociology and the social sciences. Annual Review of Sociology 38 (1), 37–72.10.1146/annurev-soc-081309-150141Search in Google Scholar
Bushway, S.D. & Apel, R.J. (2010). Instrumental variables in criminology and criminal justice. In A. Piquero & D. Weisburd (eds.), Handbook of Quantitative Criminology (595–612). New York: Springer.10.1007/978-0-387-77650-7_29Search in Google Scholar
Cameron, A.C. & Trivedi, P.K. (2010). Microeconomics Using Stata. College Station: Sztata Press.Search in Google Scholar
Duncan, O.D., Haller, A.O. & Portes, A. (1968). Peer influences on aspirations: a reinterpretation. American Journal of Sociology 74 (2), 119–137.10.1086/224615Search in Google Scholar
Farrington, D.P. (1999). Measuring, explaining and preventing shoplifting: A review of British Research. Security Journal 12 (1), 9–27.10.1057/palgrave.sj.8340008Search in Google Scholar
Friemel, T. & Knecht, A. (2009). Praktikable vs. tatsächliche Grenzen von sozialen Netzwerken. Eine Diskussion zur Validität von Schulklassen als komplette Netzwerke. In R. Häußling (Hrsg.), Grenzen von Netzwerken (15–32). Wiesbaden: VS Verlag für Sozialwissenschaften.10.1007/978-3-531-91856-3_2Search in Google Scholar
Geiser, C. (2011). Datenanalyse mit Mplus. Eine anwendungsorientierte Einführung. Wiesbaden: VS Verlag für Sozialwissenschaften.10.1007/978-3-531-93192-0Search in Google Scholar
Gerstner, D. & Oberwittler, D. (2015). Wer kennt wen und was geht ab? Ein netzwerkanalytischer Blick auf die Rolle delinquenter Peers im Rahmen der Situational Action Theory. Monatsschrift für Kriminologie und Strafrechtsreform 98 (3), 204–226.10.1515/mks-2015-980304Search in Google Scholar
Haynie, D.L. & Osgood, W.D. (2005). Reconsidering peers and delinquency: How do peers matter? Social Forces 84 (2), 1109–1130.10.1353/sof.2006.0018Search in Google Scholar
Hellevik, O. (2009). Linear versus logistic regression when the dependent variable is a dichotomy. Quality & Quantity 43 (1), 59–74.10.1007/s11135-007-9077-3Search in Google Scholar
Hirtenlehner, H. (2019). Does perceived peer delinquency amplify or mitigate the deterrent effect of perceived sanction risk? Deviant Behavior 40 (3), 361–384.10.1080/01639625.2018.1426264Search in Google Scholar
Hirtenlehner, H. & Bacher, J. (2017). Interaktive Beziehungsdynamiken am Beispiel der Ladendiebstahlsdelinquenz junger Menschen. Monatsschrift für Kriminologie und Strafrechtsreform 100 (6), 404–429.10.1515/mks-2017-1000601Search in Google Scholar
Hoeben, E.M., Meldrum, R.C., Walker, D.A. & Young, J.T. (2016). The role of peer delinquency and unstructured socializing in explaining delinquency and substance use: A state-of-the-art review. Journal of Criminal Justice 47 (1), 108–122.10.1016/j.jcrimjus.2016.08.001Search in Google Scholar
Hu, L.‐T. & Bentler, P.M. (1999). Cutoff criteria for fit indexes in covariance structure analysis: Conventional criteria versus new alternatives. Structural Equation Modeling: A Multidisciplinary Journal 6 (1), 1–55.10.1080/10705519909540118Search in Google Scholar
Johnston, J. (1984). Econometric Methods. New York: McGraw-Hill.Search in Google Scholar
Kim, J. & Fletcher, J.M. (2018). The Influence of classmates on adolescent criminal activities in the United States. Deviant Behavior 39 (3), 275–292.10.1080/01639625.2016.1269563Search in Google Scholar
Lousdal, M.L. (2018). An introduction to instrumental variable assumptions, validation and estimation. Emerging Themes in Epidemiology 15 (1), 1–7.10.1186/s12982-018-0069-7Search in Google Scholar
Matsueda, R.L. & Anderson, K. (1998). The dynamics of delinquent peers and delinquent behavior. Criminology 36 (2), 269–308.10.1111/j.1745-9125.1998.tb01249.xSearch in Google Scholar
Muthén, L.K. & Muthén, B.O. (2017). Mplus User’s Guide. 8th ed. Los Angeles: Muthén & Muthén.Search in Google Scholar
Oberwittler, D. (2004). Stadtstruktur, Freundeskreise und Delinquenz: Eine Mehrebenenanalyse zu sozialökologischen Kontexteffekten auf schwere Jugenddelinquenz. In D. Oberwittler & S. Karstedt (Hrsg.), Soziologie der Kriminalität (135–170). Wiesbaden: Springer VS.10.1007/978-3-322-80474-7Search in Google Scholar
Pratt, T.C., Cullen, F.T., Sellers, C.S., Winfree, L.T., Madensen, T.D., Daigle, L.E. et al. (2010). The empirical status of social learning theory: A meta‐analysis. Justice Quarterly 27 (6), 765–802.10.1080/07418820903379610Search in Google Scholar
Rebellon, C.J. & Modecki, K.L. (2014). Accounting for projection bias in models of delinquent peer influence: The utility and limits of latent variable approaches. Journal of Quantitative Criminology 30 (2), 163–186.10.1007/s10940-013-9199-9Search in Google Scholar
Reinecke, J. (2014). Strukturgleichungsmodelle in den Sozialwissenschaften. München: De Gruyter Oldenbourg.10.1524/9783486854008Search in Google Scholar
Reisinger, M., Svecnik, E. & Schwetz, H. (2012). Fehlende Werte und keine Normalverteilung? Tipps und Abhilfen für das quantitativ orientierte Forschen. Wien: Facultas.Search in Google Scholar
Snijder, T. & Bosker, R. (2004). Multilevel Analysis. An Introduction to Basic and Advanced Multilevel Modeling. London: Sage.Search in Google Scholar
Staiger, D. & Stock, J.H. (1997). Instrumental variables regression with weak instruments. Econometrica 65 (3), 557–586.10.2307/2171753Search in Google Scholar
Stock, J.H. & Trebbi, F. (2003). Who invented instrumental variable regression? Journal of Economic Perspectives 17 (3), 177–194.10.1257/089533003769204416Search in Google Scholar
Stock, J.H. & Yogo, M. (2005). Testing for weak instruments in linear IV regression. In D.W. Andrews (ed.), Identification and Inference for Econometric Models (80–108). Cambridge: Cambridge University Press.10.1017/CBO9780511614491Search in Google Scholar
Svensson, R. & Oberwittler, D. (2010). It's not the time they spend, it's what they do: The interaction between delinquent friends and unstructured routine activity on delinquency. Journal of Criminal Justice 38 (5), 1006–1014.10.1016/j.jcrimjus.2010.07.002Search in Google Scholar
Warr, M. (2002). Companions in Crime. The Social Aspects of Criminal Conduct. Cambridge: Cambridge University Press.10.1017/CBO9780511803956Search in Google Scholar
Weiss, M. (2019). Einfluss des Klassenkontextes auf die Delinquenzentwicklung. In S. Wallner, M. Weiss, J. Reinecke & M. Stemmler (Hrsg.), Devianz und Delinquenz in Kindheit und Jugend (187–203). Wiesbaden: Springer VS.10.1007/978-3-658-21234-6Search in Google Scholar
Williams, R. (2015). Nonrecursive Models (Extended Version). Indiana: University of Notre Dame; https://www3.nd.edu/~rwilliam/stats2/l93x.pdf [20.04.2019].Search in Google Scholar
Windzio, M. (2013). Räumliche Diffusion expressiver Delinquenz in Schulen und Stadtbezirken. In D. Oberwittler, S. Rabold & D. Baier (Hrsg.), Städtische Armutsquartiere – Kriminelle Lebenswelten? (193–216). Wiesbaden: Springer VS.10.1007/978-3-531-93244-6_7Search in Google Scholar
© 2020 Helmut Hirtenlehner et al., published by Walter de Gruyter GmbH, Berlin/Boston
Dieses Werk ist lizensiert unter einer Creative Commons Namensnennung 4.0 International Lizenz.
Articles in the same Issue
- Frontmatter
- Frontmatter
- Artikel
- Wer bleibt unbehandelt?
- »Ich bin stark und mir passiert nichts« – Forschungspraktische und methodische Erkenntnisse aus einer quantitativen Opferbefragung im Gefängnis
- Taugt die aggregierte Delinquenzrate einer Schulklasse als Maßzahl für die Bestimmung kriminogener Peer-Effekte?
- Strafhärteskalierung
- Forum
- Die (un)mögliche Messung des allgemeinen Rechtsgefühls
- Mitteilungen
- Reviewer 2019
- Buchbesprechungen
- Stern, Jessica: My War Criminal. Personal Encounters with an Architect of Genocide
- Klimke, Daniela/Oelkers, Nina/Schweer, Martin K. W. (Hrsg.): Sicherheitsmentalitäten im ländlichen Raum
Articles in the same Issue
- Frontmatter
- Frontmatter
- Artikel
- Wer bleibt unbehandelt?
- »Ich bin stark und mir passiert nichts« – Forschungspraktische und methodische Erkenntnisse aus einer quantitativen Opferbefragung im Gefängnis
- Taugt die aggregierte Delinquenzrate einer Schulklasse als Maßzahl für die Bestimmung kriminogener Peer-Effekte?
- Strafhärteskalierung
- Forum
- Die (un)mögliche Messung des allgemeinen Rechtsgefühls
- Mitteilungen
- Reviewer 2019
- Buchbesprechungen
- Stern, Jessica: My War Criminal. Personal Encounters with an Architect of Genocide
- Klimke, Daniela/Oelkers, Nina/Schweer, Martin K. W. (Hrsg.): Sicherheitsmentalitäten im ländlichen Raum