Using ATLAS.ti to interpret keyword co-occurrence analysis: a case study on the representation of vaccin* across pseudoscience and conspiracy websites
-
Yuze Sha
 and
Isobelle Clarke
and
Isobelle Clarke


Abstract
In this study we use ATLAS.ti to interpret the results of a keyword co-occurrence analysis (KCA) of fake vaccination news. Specifically, KCA is used to uncover the most dominant patterns of co-occurring keywords across a corpus of 37,676 texts from 235 pseudoscience and conspiracy websites that mention vaccin*. KCA enables researchers to examine linguistic patterns of fake news from multiple angles, including discourse, register, style, and attitude. Yet, the interpretation of KCA can be time-consuming, especially when texts are long. Consequently, in this study, we leverage ATLAS.ti’s code co-occurrence analysis functionality, which streamlines and accelerates the interpretation of KCA results by providing access to extended concordances that highlight the patterns of keyword co-occurrence. Taking the second most prominent dimension as a demonstration, we interpret this pattern of keyword variation across our vaccination corpus as distinguishing texts that are questioning the COVID-19 pandemic, especially in relation to higher power control, from texts that are discussing childhood vaccines, especially with respect to the dangers they pose. The implications of these linguistic repertoires in relation to fake news and anti-science strategies are discussed.
1 Introduction: fake news, anti-vaccination discourse, anti-vaccination websites
The rapid advancement of online communication technologies has expanded the public’s daily access to a myriad of information sources. This influx of information can negatively impact the public’s capacity to make rational decisions (Van Zandt 2004). This challenge is further impeded by the presence of fake news (Zhang and Ghorbani 2020). Fake news is deliberately fabricated content that mimics the form of news media but lacks adherence to journalistic processes or intentions (Lazer et al. 2018).
In recent times, fake news has permeated various spheres, including politics (e.g., Subramanian 2017) and science, particularly concerning vaccination, a public health measure credited with preventing 4–5 million deaths annually (WHO 2019). Studies have highlighted the detrimental effects of vaccine misinformation, including the resurgence of vaccine-preventable diseases (e.g., measles) in many countries (Hotez 2020). Consequently, ongoing research efforts aim to delineate the discursive characteristics of anti-vaccination discourse (e.g., Bean 2011; Hardaker et al. 2024), especially on social media (e.g., Maci 2019; Orlandi et al. 2022).
Although recent anti-vaccination studies have focused on social media, the impact of anti-vaccination websites remains substantial. These platforms act as primary sources of much information quoted across anti-vaccination online communities and social media posts. Studies (e.g., Betsch et al. 2012; Finney Rutten et al. 2019; Fox 2011) have shown that individuals, especially patients and caregivers, consult the internet for health-related information, especially vaccination information. The Pew Internet and American Life Project (Fox 2011) found that 80 percent of internet users seek health information online (Kata 2012). Among these seekers, a substantial 70 percent report that their findings on such health information websites influenced their treatment decisions.
With the capacity of websites to influence health decisions, studies have sought to understand anti-vaccination websites’ content and persuasiveness (e.g., Bean 2011; Kata 2012; Moran et al. 2016; Sak et al. 2015). For example, in a content analysis of 480 websites, Moran et al. (2016) uncovered that 66.9 percent of the websites used pseudoscience as a persuasive strategy, such as confusing correlation for causation. Of the 480 websites, 59.2 percent referred to expert opinions to give weight to their statements and persuade their readers. In another study, Bean (2011) drew on the findings from Davies et al. (2002), Kata (2010), and Wolfe et al. (2002), who explored themes across anti-vaccination websites, to assess if the themes had evolved. Specifically, Bean (2011) used content analysis to analyse 25 anti-vaccination websites for recurring and changing emphases in content, design, and credibility. The content features were summarized into four categories: safety and effectiveness; civil liberties; alternative treatments; and conspiracy theories or search for truth. Compared to findings from Davies et al. (2002), Kata (2010), and Wolfe et al. (2002), Bean (2011) found that whilst much had remained the same, there were some new themes in response to new emerging health trends and threats, such as the H1N1 outbreak. This study highlights the importance of revisiting anti-vaccination websites, as is done in the present study, around a decade after the aforementioned studies, especially following the COVID-19 pandemic.
Like Bean (2011), many studies investigating anti-vaccination websites have employed content analysis, using human coders allocated with predefined code sets from earlier studies (e.g., Sak et al. 2015), or integrating these schemes with either a qualitative examination of data samples (e.g., Moran et al. 2016) or the emerging themes through an iterative examination process (e.g., Bean 2011). Whilst using human coders offers distinct advantages, such as uncovering subtle thematic variations, it also risks affecting the objectivity of the results. Additionally, the process can be time-consuming, especially for large datasets, which may limit the scope of the analysis.
To address this, in the present study we applied the corpus-assisted discourse analytical approach known as keyword co-occurrence analysis (KCA) to anti-vaccination website texts to uncover groups of keywords that co-occur across them, which we systematically explore for themes, discourses, registers, styles, and attitudes.
2 Keyword co-occurrence analysis
KCA is aimed at uncovering the dominant patterns of keyword co-occurrence across the texts of a corpus (Clarke et al. 2021, 2022]). Keywords are terms appearing with unusual frequency compared to a reference corpus. Keywords are instrumental in highlighting the aboutness of the dataset, such as discourses (Baker 2004) and register (McEnery 2016). Yet one challenge when it comes to keyword studies is aggregation – the keywords in the keyword list may all point to the discourses, but prising apart the discourses is a task for the analyst (for a detailed discussion, see Clarke et al. 2021). In previous keyword studies, to interpret the keyword results, researchers have often manually categorized keywords into semantic or thematic groups based on a close reading of corresponding concordances (e.g., Brookes 2022). While manual analysis offers depth, the categories created and the keywords assigned to the categories are susceptible to compromise, especially when corpora are large and when keywords occur frequently (Clarke et al. 2021).
Instead, KCA uses a multivariate statistical technique, called multiple correspondence analysis (MCA) to group the keywords based on their frequent co-occurrence across a corpus, aiming to deliver rich, multidimensional insights. KCA is based on the notion of linguistic co-occurrence – frequent patterns of co-occurring linguistic features are not random, but instead point to at least one shared communicative function (Biber 1988). Prior research employing KCA has illuminated that patterns of keyword co-occurrence not only point to discourses and functions, but also sub-registers (Clarke et al. 2021), argumentative repertoires, and manipulative disinformation strategies (Clarke 2023). These applications of KCA have shown its capacity to account for the multiple senses, topics, (sub)registers, functions, and discourses that keyword co-occurrence can express.
KCA involves the following four broad steps: (i) compute keywords using a traditional keyword analysis (i.e., comparing the relative frequencies of the words in a target corpus to those in a reference corpus using a particular statistic of one’s choice, e.g., log-likelihood, log ratio, difference coefficient); (ii) analyse each text in the corpus for the occurrence of these keywords and record in a categorical data matrix; (iii) subject the data matrix to MCA to reveal dimensions comprising the most common patterns of co-occurring keywords; and finally (iv) interpret these dimensions of keyword co-occurrence, guided by the principles of linguistic co-occurrence (Biber 1988) and the indicative nature of keywords in discourse (Baker 2006).
Despite the method’s strengths, the interpretation of dimensions in any dimension reduction method, such as MCA, is difficult, especially in the context of KCA where the variables are linguistic features, and the goal is to select a short, descriptive label that captures the crux of the dimension and the opposition of many features (Friginal and Hardy 2019). In previous KCA studies, analysts read texts most associated with each dimension and explored each keyword associated with the dimension in these texts to understand the relevant keywords’ contexts and uses. After labelling the co-occurrence pattern, they attempt to falsify it against less associated texts following the same approach. Although effective, the interpretation process can be laborious, especially when texts are long and dimensions comprise numerous keywords.
To address this, we explored technological solutions to expedite the interpretation process and found ATLAS.ti’s (2023) code co-occurrence function to be complementary for KCA. In the rest of the paper, we present Dimension 2 from a KCA of texts mentioning vaccination from pseudoscience and conspiracy websites to demonstrate how to use ATLAS.ti for analysing KCA results. The reason for skipping Dimension 1 is because Dimension 1’s results oppose long texts with short texts (for a more detailed description, see Clarke and Grieve 2019).
3 Methodology
3.1 Vaccination subcorpus of the pseudoscience and conspiracy sources corpus
The data for this study comes from a larger project investigating different branches of anti-science (see Clarke 2023). The general corpus for this project comprises texts (all content on a single web page – i.e., article and comments) from 235 websites labelled as “conspiracy-pseudoscience” by Media Bias/Fact Check (https://mediabiasfactcheck.com), which is a comprehensive and continuously updated resource of online media sites that have been rated for various levels of bias. The corpus was filtered by retaining texts according to “seed” words and phrases associated with the anti-science branches relevant to the larger project. The present study drew on the vaccination subcorpus, which was filtered based on the seed words vax and vaccin*, which spans 21 years (from 2000 to 2021). Duplicated texts were removed from the corpus using a Python script to avoid skewing the data. Table 1 presents the composition of the corpus before and after deduplication.
Composition of the vaccination subcorpus of the pseudoscience and conspiracy sources corpus.
| Number of texts | Number of words (tokens) | |
|---|---|---|
| Before deduplication | 52,111 | 62,449,596 |
| After deduplication | 37,921 | 31,941,747 |
Table 1 shows that nearly half of the anti-vaccination content is duplicated, demonstrating, like climate denial literature (Dunlap and Jacques 2013), that anti-vaccination content is recycled and reposted across other websites whenever convenient.
3.2 Generation of keywords and MCA
Keywords were computed in Sketch Engine by comparing the vaccination subcorpus to the English 2020 web corpus (enTenTen20) using the simple maths method (N = 100; Kilgariff 2009) and capping the number of keywords to the top 1,000 results (Kilgariff et al. 2014). We further reduced this list according to the keywords that were dispersed across more than 5 percent of the texts in the vaccination subcorpus, resulting in 177 keywords. Each text was then computationally analysed for the presence or absence of these 177 keywords, and this was recorded in a categorical data matrix. This matrix was then subjected to MCA in R using the FactoMineR package (Husson et al. 2024).
MCA produced a series of dimensions detailing the most common patterns of co-occurring keywords across the corpus and which texts display those patterns (for a more detailed discussion, see Clarke et al. 2021). Specifically, the MCA assigned each text and each category of a keyword (e.g., presence of RNA, absence of RNA) a coordinate and contribution score for each dimension. Categories of keywords with contributions above the average contribution score on a dimension are the most important contributors to the dimension. All contributions for a particular dimension add up to 100, so the average contribution is 0.28.[1] Coordinates indicate the nature of the association between the keywords in terms of proximity, where keywords that co-occur often across the texts of the corpus will have coordinates closer to each other on one side of an axis. Keywords with strong contributions and positive coordinates co-occur often together in many texts, while keywords with strong contributions and negative coordinates co-occur often together in a different set of texts with each set rarely or never co-occurring with the other set. Thus, a dimension represents a pattern of keyword variation.
We interpreted these MCA results in ATLAS.ti by (i) creating subcorpora comprising the texts most associated with each dimension, (ii) creating codes aligned with the keywords most associated with each dimension, and (iii) using the code co-occurrence function to observe paragraphs in the texts where the keywords co-occur. This facilitated a more systematic and expedited visualization of keyword co-occurrence in texts by pointing to paragraphs where the keywords most strongly associated with each side of the dimension co-occur rather than searching each text one keyword at a time.
3.3 Corpus construction on ATLAS.ti
3.3.1 Creating the subcorpora
To build our subcorpora in ATLAS.ti, we selected the top 50 texts most associated with the positive and the negative side of each dimension. These 100 texts were then imported into ATLAS.ti and we used the Group function to categorize them into two subcorpora based on their associative polarity (e.g., “Dimension 2_positive” and “Dimension 2_negative”; see Figure 1). These texts represent the most prototypical texts of the discourse (or shared function, etc.), tending to include many, if not all, of the keywords most strongly associated with the particular pole of the dimension.

User interface of ATLAS.ti.
3.3.2 Creating the codes
We then created codes based on the keywords most associated with each pole of the dimension from the MCA results. Figure 2 shows the keywords that are contributing above the average contribution (“ctr”) for Dimension 2 and their respective coordinate (“coord”).
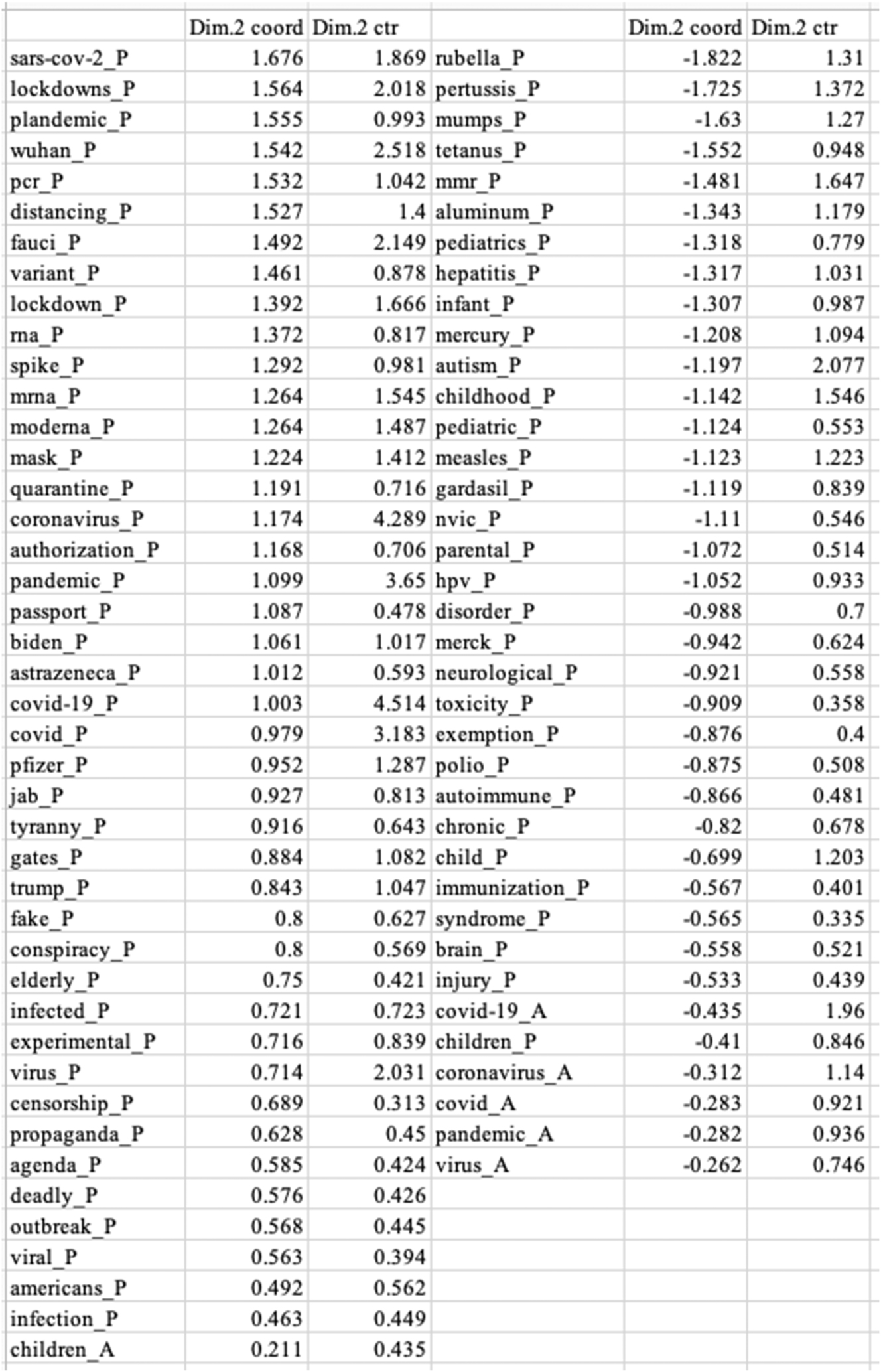
The keywords most strongly contributing to positive and negative Dimension 2 (“_P” for presence; “_A” for absence).
We employed the Text Search function (see Figures 3 and 4) of ATLAS.ti to pinpoint and code paragraphs within the texts most associated with Dimension 2 that contained the target keywords.
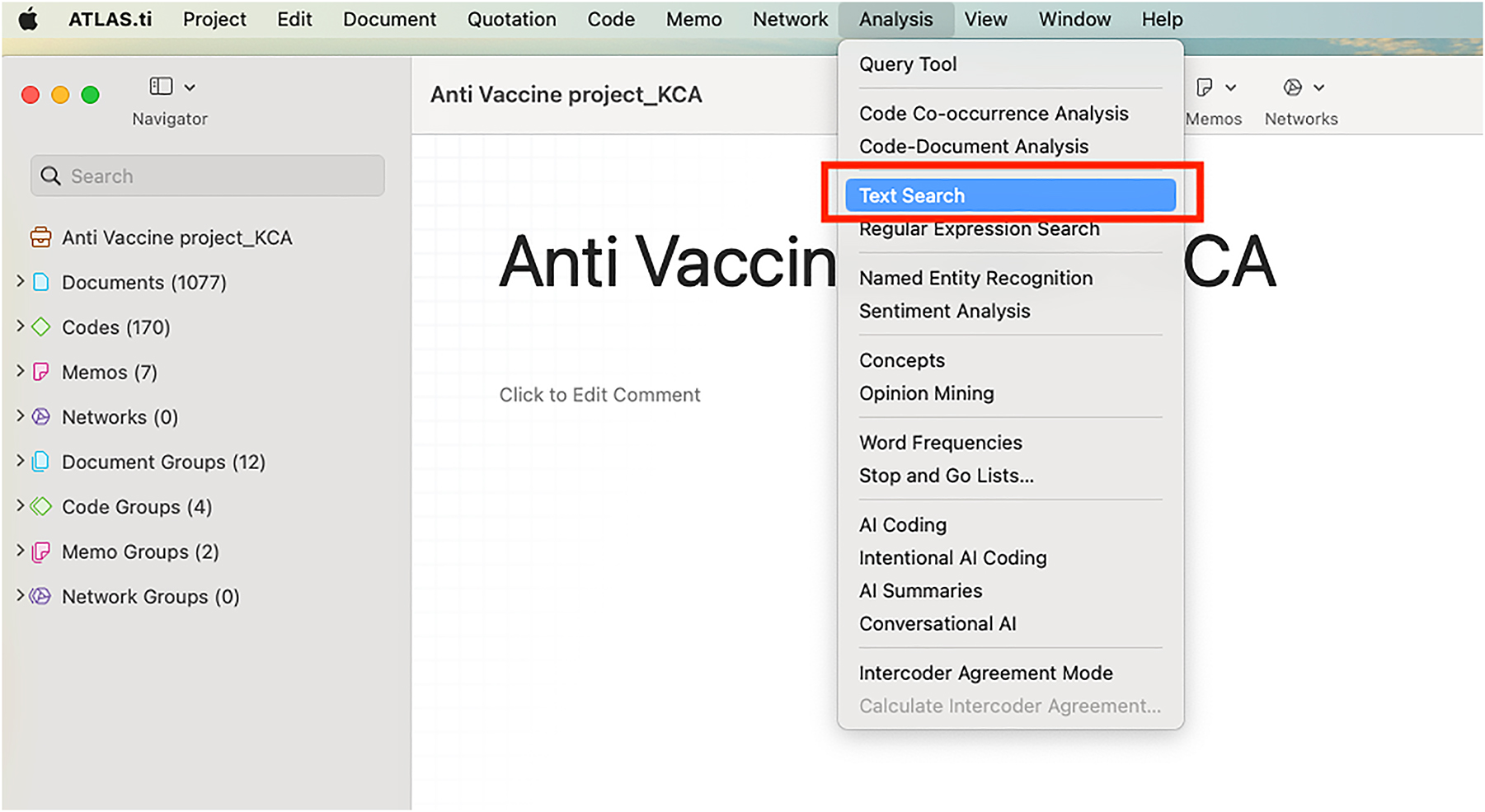
Text search functionality on ATLAS.ti.

Selecting target document (groups).
Subsequently, we entered the target keyword for coding and set the query’s scope. Different from previous studies (e.g., Clarke et al. 2021), our interpretation of the dimensions of keyword co-occurrence concentrated on how the keywords co-occurred in individual paragraphs (see Figures 5 and 6) rather than entire texts, for the purpose of accelerating the interpretation process. This approach enables us to isolate specific segments within the most strongly associated texts where the keywords associated with a particular side of a dimension appear together, facilitating a more detailed examination of the factors contributing to their co-occurrence.

Defining a query.

Results and bulk coding on ATLAS.ti.
For each side, we then used ATLAS.ti’s Bulk Code function (top right in Figure 6) to mark every occurrence of each keyword within the top 50 texts. Once the coding process was completed, the instances of keywords within paragraphs were marked, thereby enabling the subsequent code co-occurrence analysis.
3.3.3 Analytical framework
After constructing and annotating our corpus, our objective, as with other KCA studies, was to delineate what the patterns of keyword co-occurrence point to. To guide this interpretation, we used the analytical framework established in Clarke et al. (2025), which outlines five preliminary areas of enquiry (see Table 2).
KCA analytical framework.
| Construct | Definition | Prompt |
|---|---|---|
| Topic or subject matter | The subject matter/aboutness of the text | What do the texts concern? What are the texts about? |
| Discourse | “[S]et[s] of meanings, metaphors, representations, images, stories, statements and so on that in some way together produce a particular version of events” (Burr 2015: 74–75) | Are the patterns of co-occurring keywords being used in texts to focus on a particular event and/or aspect? If so, what? How is vaccination being represented? What aspect of vaccination is being zoomed in on? |
| Register | A variety of language associated with both a particular situation of use and with pervasive linguistic features that serve important functions within that situation of use (Biber and Conrad 2009: 33) “Registers are described for their typical lexical and grammatical characteristics … and also … for their situational contexts, for example whether they are produced in speech or writing, whether they are interactive, and what their primary communicative purposes are” (Biber and Conrand 2009: 6) The function of linguistic features in the situational context |
How are the keywords functioning in the texts? Are the keywords characteristic of a particular language variety? What is/are the purpose(s) of the texts? Do the texts share a specific or primary communicative purpose? Are all the texts a particular register? |
| Style | The use of linguistic features that reflect aesthetic preferences, associated with particular authors or historical periods | Do the keywords reflect aesthetic preferences of particular authors/historical periods? |
| Vaccine attitude | The vantage point of vaccines and vaccination expressed in the tweet | Are the texts overtly pro- or anti-vaccination? Are the texts disinterested in vaccination? |
The interpretation process began by using the Global Filter function (see Figure 7) in ATLAS.ti to isolate the target Dimension 2 subcorpora for examination. We then utilized the Code Co-occurrence Analysis function in ATLAS.ti to analyse and summarize the patterns of co-occurrence throughout the subcorpus (see Figure 8).

Setting a Global Filter on ATLAS.ti.

Code co-occurrence analysis on ATLAS.ti.
Figure 9 displays the table of results from this analysis. The frequency with which two codes (representing keywords in this study) co-occur in the same paragraph is displayed in the middle. The intensity of colouring indicates the strength of co-occurrence within the paragraphs of this subcorpus, with deeper colours signifying stronger associations. By selecting a specific column, the right side of the table reveals detailed concordances of these co-occurrences.

Code co-occurrence analysis table.
To identify paragraphs where more than two keywords co-occurred, we used the Global Filter function to initially filter concordances that had been coded with specific keywords. Subsequently, we used code co-occurrence analysis to explore their co-occurrences with other keywords. For instance, to explore how the keywords associated with negative Dimension 2 (as presented in Figure 2) co-occur in texts we set “Dimension 2_neg 50” (the document group) and MMR (one of the target keywords) as the Global Filter criteria (see Figure 10). We then explored the code co-occurrence analysis table to view the co-occurrence of MMR with autism (another target keyword) and all other keywords associated with the negative side of Dimension 2 (see Figure 11). We repeated this for all keywords strongly contributing to each dimension.

Co-occurrence analysis of more than two keywords (Global Filter setting).
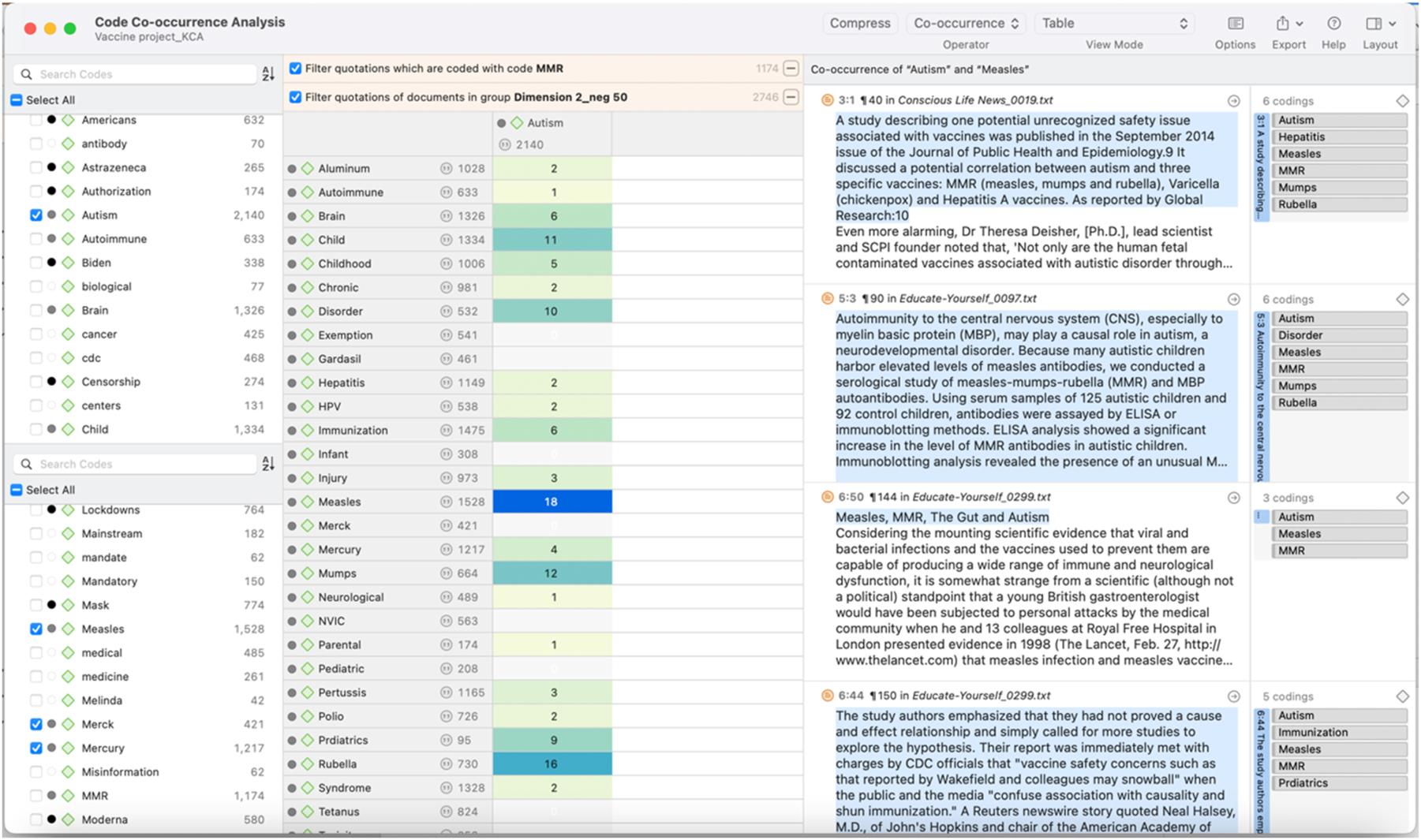
Co-occurrence analysis of more than two keywords (co-occurrence table).
4 Results
We present our interpretation of Dimension 2 in this paper. It should be noted that whilst the interpretations and the concordances presented below are based on the 50 most prototypical texts, these patterns were also observed in less strongly associated texts. After we had interpreted the top 50 texts, we sought to falsify our interpretations by exploring a random set of texts that were less strongly associated with the particular pole of the dimension. If the interpretations were falsified we refined the interpretation and repeated the process of falsification until no more refinement was needed.
4.1 Positive Dimension 2
The keywords most associated with the positive side of Dimension 2 co-occur in texts that discuss the COVID-19 pandemic and question the legitimacy of government regulations related to the pandemic, including those concerning COVID-19 vaccines.
4.1.1 Questioning the legitimacy of government regulations
A prominent representational discourse found across positive Dimension 2 texts concerns governmental control and regulations during COVID-19. Figure 2 shows that many keywords strongly contributing to positive Dimension 2 are related to COVID-19 (COVID, COVID-19, coronavirus, and SARS-CoV-2) and COVID-19-related policies (lockdown, mask, and social distancing). Additionally, names of prominent political figures like Biden, Trump, and Fauci and keywords related to government actions, such as agenda and authorization, are prevalent. These keywords are used to question the legitimacy and reasoning behind governmental interventions, including vaccination campaigns, accusing the government of a sinister agenda. Also, keywords such as fake and experimental frequently co-occur with both policy-related and virus-related keywords often to suggest that the pandemic is not real, as illustrated in (1).

|
4.1.2 COVID vaccination
COVID vaccination is a prominent theme. This is realized by keywords related to different COVID vaccine types (Moderna, mRNA, and Pfizer). Notably, these vaccine-related keywords often co-occur with the keyword experimental to directly describe the vaccine in phrases like “experimental mRNA technology” (see (2)), “experimental test vaccine”, or “experimental gene therapy mRNA drugs”, rather than simply referring to it as a “vaccine”. Such texts describe the vaccines as being hastily developed and question their need, safety, and efficacy. Notably, the reference to mRNA vaccine as “experimental gene therapy” is used to suggest that the vaccine is altering people’s genetic code and poses damage to individuals’ health. Referring to the vaccine as “experimental” contributes further to the discourse of governmental control as those who get the vaccine are positioned as test subjects.

|
Despite references to different types of COVID-19 vaccines, the only vaccination reference found in the keyword list was jab. The keywords vaccine or vaccination were not strongly associated with positive or negative Dimension 2. Whilst this is most likely because they are used fairly equally across the texts associated with the positive and the negative sides of Dimension 2 and thus do not contribute to this pattern of variation, the strong association of jab alongside COVID-19-related keywords introduces meaningful connotations. Unlike the more medically oriented and neutral terms vaccine and vaccination, jab carries a more informal tone with violent connotations. The selection of jab over the other choices might also aim to cast the COVID-19 vaccination in a more negative or forceful light, contributing to amplified scepticism or reluctance towards COVID-19 vaccination initiatives. Furthermore, this linguistic choice may serve as a mechanism of delegitimization, attempting to weaken the discourse’s connection to authoritative narratives (see (3)). By avoiding formal medical terminologies, it might serve to reduce the credibility and legitimacy of vaccination efforts and foster doubt, fear of injury, and diminish trust in scientific expertise and authority.

|
4.1.3 Negative consequences
Another prominent discourse stresses the negative consequences of governmental controls during the COVID-19 pandemic, including COVID-19 vaccinations. This narrative is underscored by the co-occurrence of the keywords elderly and deadly with policy-related keywords, such as lockdown(s), quarantine, and experimental (vaccines), which are used in texts often to dispute the need for such interventions by (i) blaming the high infection and death numbers among the elderly as a direct consequence of government interventions, such as claiming that systems for elderly care collapsed due to lockdowns, or (ii) accusing the COVID-19 death rates of being inflated due to the susceptibility of vulnerable populations to infections or death during the flu season, rather than as a direct consequence of COVID-19 (see (4)).

|
Conspiracies about the adverse effects of the COVID-19 vaccination are also promoted in positive Dimension 2 texts. For instance, (5) claims COVID-19 illnesses and deaths, especially those of “the weak and elderly”, are not associated with the virus, but the vaccine.

|
4.2 Negative Dimension 2
By contrast, the keywords most strongly associated with negative Dimension 2 co-occur in texts that are focused on childhood vaccinations and the hazardous substances within them, which they claim cause numerous adverse effects.
4.2.1 Childhood vaccination
The keywords associated with negative Dimension 2 reference children (child, childhood) and childhood vaccinations (measles, mumps, and rubella, polio, pertussis, and tetanus). Many texts also include the keyword Merck, a pharmaceutical company. Such texts accuse Merck of being irresponsible for not conducting long-term safety tests to highlight concerns regarding the quality of vaccines (e.g., Gardasil), as illustrated in (6).

|
Additionally, the keyword pediatric is often used to cite studies from paediatric journals and associations, like Pediatric Annals in (7), to lend professional credibility to their claims. Importantly, while the study mentioned exists, the quote discusses the aetiologies of autism, but the study does not corroborate the connection between vaccines and autism that the website asserts.

|
4.2.2 Hazardous substances
Negative Dimension 2 texts also emphasize the presence of hazardous substances in vaccinations through keywords like aluminum and mercury to assert that they can cause various health issues (toxicity), including injuries (injury), diseases (autoimmune, neurological), and disorders (autism). These texts question the safety of the ingredients in childhood vaccines with phrases like “vaccine-induced autism” encapsulating these concerns. Many texts dispute scientific claims that vaccines do not cause autism by suggesting that there have been limited studies investigating the impact of these aforementioned substances in other vaccines (see (8)).

|
A common narrative throughout negative Dimension 2 texts asserts that vaccinated children face higher risks and suffer from more health issues than their unvaccinated counterparts. An illustrative case is provided in (9), where the Children’s Health Defense website quotes “Dr. Daniel Neides of the Cleveland Clinic” to imply that vaccines cause children to develop neurological disorders, including autism and ADHD.

|
4.3 Addressing the remaining interpretation angles
So far, we have explored the keyword co-occurrence patterns through the lens of topic and discourse. We now turn to the remaining interpretation angles, as detailed in Table 2. From a register perspective, positive Dimension 2 is characterized by an informal, argumentative register (see (4)) through texts which question governmental policies (see (1)) and comprise colloquial references to vaccinations (e.g., jab; see (3)). In contrast, negative Dimension 2 texts are more academic, featuring scientific references to substances and quotes from research studies and experts (see (7), (8), and (9)).
Regarding style, positive Dimension 2 is distinguished by political critiques of COVID-19 policies, reflecting a more provocative and contentious style. By contrast, negative Dimension 2 uses (pseudo)scientific and “evidence-based” arguments, suggesting a more analytical style.
The final aspect examines attitudes towards vaccinations. We found evidence of negative attitudes towards vaccinations on both the positive and negative sides of Dimension 2. Yet, importantly, there was also evidence of actors within texts and authors of texts outright denying being anti-vaccination, as can be seen in (10). Such texts nevertheless continue to call into question the safety of vaccinations, which in effect casts doubt on vaccinations and contributes to an anti-vaccination strategy. Rather than being anti-vaccination, they state that they are against unsafe vaccinations. This demonstrates that anti-vaccination is deemed by some as being “anti-cure” or “anti-antidote” and when this sense is evoked, those accused of being anti-vaccination will deny this label.

|
5 Discussion and conclusions
In this study, we demonstrated the application process of ATLAS.ti for interpreting the results of a KCA of texts mentioning vaccination from websites known to promote pseudoscience and conspiracy theories.
Due to length restrictions, it was not possible to present all dimensions of keyword variation. But by delving into the second strongest pattern of keyword variation (i.e., Dimension 2), our analysis unveiled a dichotomy between discussions of COVID-19 vaccines and those on childhood vaccinations. Texts mentioning COVID-19 vaccines positioned them under the broader discourse of governmental regulations and control. Such texts were focused on questioning the need for government interventions, like lockdowns, mask wearing, and vaccinations, and promoting the conspiracy of an alternative sinister agenda. Texts delegitimized COVID-19 policies, including vaccination policy from two angles, by (i) stressing the safety of the unvaccinated by downplaying the virus’s severity and (ii) highlighting the risks to the vaccinated by overstating the adverse effects of vaccines. The delegitimization is further achieved through the informal use of jab for vaccine, which could evoke concerns about safety and efficacy by distancing itself from the scientific term and register. The register of these texts is predominantly informal and argumentative, characterized by political critiques.
Texts discussing childhood vaccines are more “academic”, with frequent citations from researchers and doctors and the use of technical terminology related to hazardous substances and associated illnesses. Yet, paradoxically, these texts also include emotional appeals, with many texts directly calling on parents to protect their children against alleged vaccine-induced diseases, disorders, and deaths.
Many of these discourses and strategies are aligned with those found in previous research investigating anti-vaccination websites, such as Bean (2011), which noted the frequent mentions of vaccine ingredients and vaccine-induced diseases and deaths, and accusations that vaccines violate civil liberties. Yet there are some differences, especially within texts covering the COVID-19 pandemic. For example, unlike the “diseases have declined” narrative found in the websites examined in Bean (2011), the COVID-19 vaccination discussions minimize the severity of the virus by claiming that the death and illness statistics are inflated due to the elderly and the vulnerable. Also, rather than solely stressing the mandatory nature of vaccination (Bean 2011), the COVID-19 anti-vaccination discourses posit vaccinations within the framework of government control, delegitimizing the vaccination alongside other policies, such as lockdown and mask wearing, amplifying the scope of its target audience who disagreed with or disliked such regulations. These differences particularly in COVID-19 vaccine discourse thus point to the adaptive nature of anti-vaccination discourses.
In this study, we have illustrated how ATLAS.ti’s code co-occurrence analysis function is complementary to KCA. Using ATLAS.ti we were able to specify the context for codes to co-occur as paragraphs as opposed to full texts. This enabled the observation of patterns of keyword co-occurrence more systematically rather than manually searching for the keywords in the full texts associated with the dimension.
Our results have pointed to some of the ways in which fake news may mimic authentic news, such as through references to experts, genuine citations, technical terminology, and political critique (Lazer et al. 2018). But, as shown, this is coupled with additional strategies like overstating and downplaying, which can add to the challenge of distinguishing fake news. Moreover, some texts exploit vague language, prompting their readers to “fill in the gaps”. For instance, by claiming that the COVID-19 pandemic is fake and that the government interventions are not aimed at preventing the spread of the vaccine but are instead part of a vague, unspecified agenda, readers can create what that agenda is and their own reasons for that agenda. Essentially, fake news can thus be moulded by the reader, making it considerably difficult to distinguish from real news.
The present study also reveals the influence of COVID-19 on anti-vaccination discussions. Even though our dataset spanned 21 years, the COVID-19 pandemic turned out to be dominant within our corpus. Future research should therefore continue to track the evolution of anti-vaccination websites’ strategies to better equip the public to delineate fact from fiction.
Funding source: Leverhulme Trust
Award Identifier / Grant number: ECF-2020-590
-
Research funding: This research was funded by the Leverhulme Trust, grant number ECF-2020-590.
References
ATLAS.ti Scientific Software Development GmbH. 2023. ATLAS.ti Mac (version 23.2.1) [Qualitative data analysis software]. https://atlasti.com.Search in Google Scholar
Baker, Paul. 2004. Querying keywords: Questions of difference, frequency, and sense in keywords analysis. Journal of English Linguistics 32(4). 346–359. https://doi.org/10.1177/0075424204269894.Search in Google Scholar
Baker, Paul. 2006. Using corpora in discourse analysis. London: Bloomsbury.10.5040/9781350933996Search in Google Scholar
Bean, Sandra. 2011. Emerging and continuing trends in vaccine opposition website content. Vaccine 29(10). 1874–1880. https://doi.org/10.1016/j.vaccine.2011.01.003.Search in Google Scholar
Betsch, Cornelia, Noel Brewer, Pauline Brocard, Patrick Davies, Wolfgang Gaissmaier, Niels Haase, Julie Leask, Frank Renkewitz, Britta Renner, Valerie Reyna, Constanze Rossmann, Katharina Sachse, Alexander Schachinger, Michael Siegrist & Marybelle Stryk. 2012. Opportunities and challenges of Web 2.0 for vaccination decisions. Vaccine 30(25). 3727–3733. https://doi.org/10.1016/j.vaccine.2012.02.025.Search in Google Scholar
Biber, Douglas. 1988. Variation across speech and writing. Cambridge: Cambridge University Press.10.1017/CBO9780511621024Search in Google Scholar
Biber, Douglas & Susan Conrad. 2009. Register, genre and style. Cambridge: Cambridge University Press.10.1017/CBO9780511814358Search in Google Scholar
Brookes, Gavin. 2022. “Lose weight, save the NHS”: Discourses of obesity in press coverage of COVID-19. Critical Discourse Studies 19(6). 629–647. https://doi.org/10.1080/17405904.2021.1933116.Search in Google Scholar
Burr, Viven. 2015. Social constructionism, 3rd edn. London: Routledge.10.4324/9781315715421Search in Google Scholar
Clarke, Isobelle. 2023. The discourses of climate change across conspiracy and pseudoscience websites. In Stefania M. Maci, Massimiliano Demata, Mark McGlashan & Philip Seargeant (eds.), The Routledge handbook of discourse and disinformation, 325–341. London: Routledge.10.4324/9781003224495-24Search in Google Scholar
Clarke, Isobelle & Jack Grieve. 2019. Stylistic variation on the Donald Trump twitter account: A linguistic analysis of tweets posted between 2009 and 2018. PLoS One 14(9). 1–27. https://doi.org/10.1371/journal.pone.0222062.Search in Google Scholar
Clarke, Isobelle, Elena Semino, Zsófia Demjén, William Dance, Tara Coltman-Patel & Richard Gleave. 2025. HPV vaccine discourse online: A corpus linguistic approach. London: Routledge.Search in Google Scholar
Clarke, Isobelle, McEnery Tony & Brookes Gavin. 2021. Multiple correspondence analysis, newspaper discourse and subregister: A case study of discourses of Islam in the British press. Register Studies 3(1). 144–171. https://doi.org/10.1075/rs.20024.cla.Search in Google Scholar
Clarke, Isobelle, Gavin Brookes & Tony McEnery. 2022. Keywords through time: A study of representations of Islam in the British press. International Journal of Corpus Linguistics 27(4). 399–427. https://doi.org/10.1075/ijcl.22011.cla.Search in Google Scholar
Davies, Paul, Simon Chapman & Julie Leask. 2002. Antivaccination activists on the World Wide Web. Archives of Disease in Childhood 87(1). 22–25. https://doi.org/10.1136/adc.87.1.22.Search in Google Scholar
Dunlap, Riley & Peter Jacques. 2013. Climate change denial books and conservative think tanks: Exploring the connection. American Behavioral Scientist 57(6). 699–731. https://doi.org/10.1177/0002764213477096.Search in Google Scholar
Finney Rutten, Lila, Kelly Blake, Alexandra Greenberg-Worisek, Summer Allen, Richard Moser & Bradford Hesse. 2019. Online health information seeking among US adults: Measuring progress toward a healthy people 2020 objective. Public Health Reports 134(6). 617–625. https://doi.org/10.1177/0033354919874074.Search in Google Scholar
Fox, Susannah. 2011. 80% of internet users look for health information online. Pew Internet & American Life Project. https://www.pewresearch.org/internet/wp-content/uploads/sites/9/media/Files/Reports/2011/PIP_Social_Life_of_Health_Info.pdf (accessed 15 August 2024).Search in Google Scholar
Friginal, Eric & Jack Hardy. 2019. From factors to dimensions: Interpreting linguistic co-occurrence patterns. In Tony Berber Sardinha & Marcua Pinto (eds.), Multi-dimensional analysis: Research methods and current issues, 145–164. London: Bloomsbury.10.5040/9781350023857.0016Search in Google Scholar
Hardaker, Claire, Alice Deignan, Elena Semino, Tara Coltman-Patel, William Dance, Zsófia Demjén, Chris Sanderson & Derek Gatherer. 2024. The Victorian anti-vaccination discourse corpus (VicVaDis): Construction and exploration. Digital Scholarship in the Humanities 39(1). 162–174. https://doi.org/10.1093/llc/fqad075.Search in Google Scholar
Hotez, Peter. 2020. Combating antiscience: Are we preparing for the 2020s? PLoS Biology 18(3). 1–6. https://doi.org/10.1371/journal.pbio.3000683.Search in Google Scholar
Husson, Francois, Julie Josse, Sebastien Le & Jeremy Mazet. 2024. FactoMineR, version 2.11 [R package]. https://cran.r-project.org/web/packages/FactoMineR/FactoMineR.pdf.Search in Google Scholar
Kata, Anna. 2010. A postmodern Pandora’s box: Anti-vaccination misinformation on the internet. Vaccine 28(7). 1709–1716. https://doi.org/10.1016/j.vaccine.2009.12.022.Search in Google Scholar
Kata, Anna. 2012. Anti-vaccine activists, Web 2.0, and the postmodern paradigm – an overview of tactics and tropes used online by the anti-vaccination movement. Vaccine 30(25). 3778–3789. https://doi.org/10.1016/j.vaccine.2011.11.112.Search in Google Scholar
Kilgariff, Adam. 2009. Simple maths for keywords. https://www.sketchengine.eu/wp-content/uploads/2015/04/2009-Simple-maths-for-keywords.pdf (accessed 15 August 2024).Search in Google Scholar
Kilgariff, Adam, Vít Baisa, Jan Bušta, Miloš Jakubíček, Vojtěch Kovář, Jan Michelfeit, Pavel Rychlý & Vít Suchomel. 2014. The Sketch Engine: Ten years on. Lexicography 1(1). 7–36. https://doi.org/10.1007/s40607-014-0009-9.Search in Google Scholar
Lazer, David, Matthew A. Baum, Yochai Benkler, Adam J. Berinsky, Kelly M. Greenhill, Filippo Menczer, Miriam J. Metzger, Brendan Nyhan, Gordon Pennycook, David Rothschild, Michael Schudson, Steven A. Sloman, Cass R. Sunstein, Emily A. Thorson, Duncan J. Watts & Jonathan L. Zittrain. 2018. The science of fake news. Science 359(6380). 1094–1096. https://doi.org/10.1126/science.aao2998.Search in Google Scholar
Maci, Stefania Maria. 2019. Discourse strategies of fake news in the anti-vax campaign. Lingue Culture Mediazioni – Languages Cultures Mediation 6(1). 15–43. https://doi.org/10.7358/lcm-2019-001-maci.Search in Google Scholar
McEnery, Tony. 2016. Keywords. In Paul Baker & Jesse Egbert (eds.), Triangulating methodological approaches in corpus linguistic research, 20–32. London: Routledge.Search in Google Scholar
Moran, Meghan, Melissa Lucas, Kristen Everhart, Ashley Morgan & Erin Prickett. 2016. What makes anti-vaccine websites persuasive? A content analysis of techniques used by anti-vaccine websites to engender anti-vaccine sentiment. Journal of Communication in Healthcare 9(3). 151–163. https://doi.org/10.1080/17538068.2016.1235531.Search in Google Scholar
Orlandi, Ludovico, Gianluca Veronesi & Alessandro Zardini. 2022. Unpacking linguistic devices and discursive strategies in online social movement organizations: Evidence from anti-vaccine online communities. Information and Organization 32(2). 100409. https://doi.org/10.1016/j.infoandorg.2022.100409.Search in Google Scholar
Sak, Gabriele, Nicola Diviani, Allam Ahmed & Peter Schulz. 2015. Comparing the quality of pro- and anti-vaccination online information: A content analysis of vaccination-related webpages. BMC Public Health 16. 1–12.10.1186/s12889-016-2722-9Search in Google Scholar
Subramanian, Samanth. 2017. Inside the Macedonian fake-news complex. Wired. https://www.wired.com/2017/02/veles-macedonia-fake-news/.Search in Google Scholar
Van Zandt, Timothy. 2004. Information overload in a network of targeted communication. The RAND Journal of Economics 35(3). 542–560. https://doi.org/10.2307/1593707.Search in Google Scholar
WHO. 2019. Immunization. World Health Organization. http://www.who.int/features/factfiles/immunization/en/ (accessed 23 March 2024).Search in Google Scholar
Wolfe, Robert, Lisa Sharp & Martin Lipsky. 2002. Content and design attributes of antivaccination web sites. JAMA 287(24). 3245–3248. https://doi.org/10.1001/jama.287.24.3245.Search in Google Scholar
Zhang, Xichen & Ali Ghorbani. 2020. An overview of online fake news: Characterization, detection, and discussion. Information Processing & Management 57(2). https://doi.org/10.1016/j.ipm.2019.03.004.Search in Google Scholar
© 2025 the author(s), published by De Gruyter, Berlin/Boston
This work is licensed under the Creative Commons Attribution 4.0 International License.