On a mnemonic construction of permutations
-
 ,
,

Abstract
In the past when only “paper and pencil” ciphers were in use, a mnemonic Bellaso’s method was applied to obtain a permutation from a meaningful phrase. It turns out that even nowadays this method and its variations are employed and provide a simple but at the same time efficient tool for some ciphers. To the best of our knowledge the security of such ciphers has not been evaluated yet in all respects. Therefore, in this paper we initiate a study of their security with respect to the probability distribution of permutations obtained by Bellaso’s method.
1 Introduction
Random permutations constitute one of the most important and the most frequent cryptographic primitives. Thus, a considerable effort has been devoted to the design of their generators. Here we only mention an algorithm of R. A. Fischer and F. Yates, first published in 1938; see also [8].
In 1555, when only “paper and pencil” ciphers were available, Giovan
Battista Bellaso [2, 3] introduced a method that enables one
to remember easily a long numerical password; to a colloquial passphrase of
length n a permutation on
Let s be the smallest symbol in w, and let the first, from the left, occurrence of s in w be in the i-th position of w. Then we mark this occurrence of s in w and set
Assume that already
As an example, we note that f assigns to a passphrase “gateway” the permutation 4153627. Moreover, there are other meaningful passphrases producing the same permutation: pathway, parkway, hardway, halfway, handsaw, halfman, mangoes, etc. (see also the end of Section 3.1).
Bellaso’s method was and has been widely in use. From the well-known classical ciphers we mention different variations of transposition ciphers, e.g., transposition tables where a secret permutation is required in the heading line.
There is a strong evidence that methods to generate a permutation by the Bellaso’s are still applied [9]. Recently, several modifications of Bellaso’s method have been considered. Rivest [12] presented and analyzed a method where passphrases play a central role. His main idea: Key is a “bag of words” agreed upon by sender and receiver, and there is a possibility to add/delete some words from this bag. Zajac and his students [14] studied “tweakable random permutations” for so-called Tweakable Block Ciphers [10]. Their goal was to create random, but grammatically and structurally correct sentences. These sentences do not need to be meaningful, but their structure is set in advance.
Further, the standard Shannon principle of designing a symmetric
cipher suggests to interlace a confusion and diffusion layer several times,
where diffusion is realized by a permutation. This permutation could be also
given by a passphrase if there are enough rounds. Also, in many block or
stream ciphers random permutations on
In most applications of paper and pencil ciphers, the simplicity of usage of Bellaso’s method plays a key role. However, to be able to evaluate security of a cipher using Bellaso’s method it is necessary to know the probability distribution of obtained permutations. To our best knowledge, such study has not been carried out yet. We found in the literature only results on a distribution of special classes of permutations, see, e.g., [1], where Bard et al. analyzed the probabilities of random permutations having given cycle structures.
To initiate research in this direction first we will consider a theoretical model. In this model Bellaso’s method will be applied to the set of all words of a given length over an alphabet (not only to the meaningful phrases) assuming that the probability distribution on the set of all words (i.e., on all n-grams) is uniform. We find it quite surprising that Eulerian numbers play an essential role there. As far as we know this is the first occurrence of these famous numbers in cryptography.
In order to understand how good this theoretical model is, how close it mimics a real life application, we will measure the distance of the probability distribution of permutations in our model to the uniform distribution (the ideal one) and to an English language model. In this English language model, the probability distribution on the domain of all possible n-grams is taken from standardized corpora of English language. It turns out that for small values of parameters, there is a good consistency of the two models. We also analyze sensitivity of our model to its parameters.
2 Theoretical model
As mentioned in the introduction, the Bellaso’s method is still nowadays
used in several cryptographic algorithms. Therefore, in order to be able to
evaluate security of a cipher, it is necessary to know the probability
distribution on the pertinent set of permutations in
In this section we will investigate this distribution in a theoretical model
where we assume the uniform distribution on the domain (= all words of
length n on an alphabet
The matrices A and B given below contain pertinent values for
As the size of domain is
In what follows the elements of matrices A and B will be determined in
general. We start by introducing a key notion of this section. It will be
said that a permutation π contains a consecutive pair
Let k be the size of an alphabet
Proof.
Let π be a permutation with m consecutive pairs. We will prove that
First we describe a recursive construction of all words
It follows from the above construction that a word w that is mapped on π has to contain at least
By the same token, there are
To finish the proof it suffices to show the right equality in (2). There are many proofs of this well-known identity. For example, it represents the number of ways how n balls can be chosen from a set of m white balls and k black balls. The proof is complete. ∎
Hence, the elements in A are closely related to the numbers of
permutations on
For each n and
Proof.
It suffices to note that if a permutation
The next statement provides a closed formula for the number of permutation
on
For each
Proof.
By Theorem 2.1 and (1),
To facilitate notation we set
As the matrix of the system is of rank n, this system has a unique solution. By substituting
in the j-th equation of the system, we get
Rearranging terms leads to
However, by Hagen’s identity [7]
we have, for each
The proof follows. ∎
It turns out that
This statement follows from [13], where it is shown that
The next corollary provides a direct proof of the identity
The number of permutations of length n with m ascents equals the number of permutations with m consecutive pairs.
Proof.
Let
We illustrate the above proof by an example. The permutation
3 Statistical analysis of the theoretical model
In this section we will study how the probability distribution on
Obviously,
As for the probability p of a permutation π, it depends on the probability distribution on the domain. It is
where the sum runs over all n-grams in
In the theoretical model introduced in the previous section, the uniform
distribution is assumed on the domain
3.1 Consistency of the theoretical model with the English language model
First we focus on to what extent the English language model is consistent
with the theoretical one. In the theoretical model and in the English
language model we denote the probability distribution of permutations by P
and Q, and the probability of a permutation
For our English language model we selected texts of different lengths from the
Open American National Corpus (AONC, www.anc.org/data/oanc/download/).[1]
We have chosen texts of size
The distance of the two distributions
The obtained results tend to indicate that the statistical distance
increases with increasing n and decreases with the increasing corpus size.
Figure 1 shows the statistical distance of the English
language model to the theoretical one for
It is clear that the distance of the two models depends also on the total
number of n-grams occurring in the given corpus; i.e., on the number of n-grams with a non-zero probability. As expected, our experiments show that
the ratio
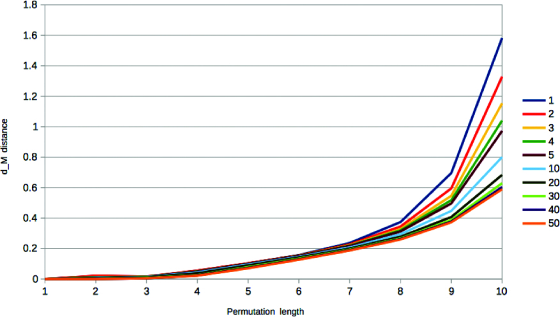
The statistical distance of the English language model to the theoretical one
for

Ratio
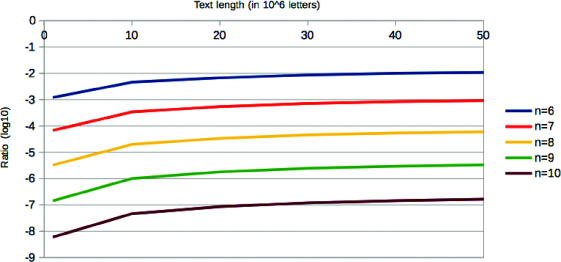
Ratio
At the end of this subsection we point out that although the ratio
For
For
3.2 Comparing the distributions P and Q to the uniform one
This subsection is devoted to comparing the probability distributions in our theoretical model and the English language model to the uniform probability distribution R. By Corollary 2.5, we get
In Table 1 we present for each permutation π of
length
Number of consecutive pairs m, the probability p of π for the given size k of alphabet and the distance to the uniform distribution.
| π | m | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3 | 1 | 0.3125 | 0.18519 | 0.13672 | 0.112 | 0.09722 | 0.08746 | 0.08057 | 0.07545 | 0.0715 | 0.05197 | |
| 2 | 0 | 0.0625 | 0.06173 | 0.05859 | 0.056 | 0.05401 | 0.05248 | 0.05127 | 0.0503 | 0.0495 | 0.04481 | |
| 2 | 0 | 0.0625 | 0.06173 | 0.05859 | 0.056 | 0.05401 | 0.05248 | 0.05127 | 0.0503 | 0.0495 | 0.04481 | |
| 2 | 0 | 0.0625 | 0.06173 | 0.05859 | 0.056 | 0.05401 | 0.05248 | 0.05127 | 0.0503 | 0.0495 | 0.04481 | |
| 2 | 0 | 0.0625 | 0.06173 | 0.05859 | 0.056 | 0.05401 | 0.05248 | 0.05127 | 0.0503 | 0.0495 | 0.04481 | |
| 2 | 0 | 0.0625 | 0.06173 | 0.05859 | 0.056 | 0.05401 | 0.05248 | 0.05127 | 0.0503 | 0.0495 | 0.04481 | |
| 2 | 0 | 0.0625 | 0.06173 | 0.05859 | 0.056 | 0.05401 | 0.05248 | 0.05127 | 0.0503 | 0.0495 | 0.04481 | |
| 2 | 0 | 0.0625 | 0.06173 | 0.05859 | 0.056 | 0.05401 | 0.05248 | 0.05127 | 0.0503 | 0.0495 | 0.04481 | |
| 2 | 0 | 0.0625 | 0.06173 | 0.05859 | 0.056 | 0.05401 | 0.05248 | 0.05127 | 0.0503 | 0.0495 | 0.04481 | |
| 2 | 0 | 0.0625 | 0.06173 | 0.05859 | 0.056 | 0.05401 | 0.05248 | 0.05127 | 0.0503 | 0.0495 | 0.04481 | |
| 2 | 0 | 0.0625 | 0.06173 | 0.05859 | 0.056 | 0.05401 | 0.05248 | 0.05127 | 0.0503 | 0.0495 | 0.04481 | |
| 2 | 0 | 0.0625 | 0.06173 | 0.05859 | 0.056 | 0.05401 | 0.05248 | 0.05127 | 0.0503 | 0.0495 | 0.04481 | |
| 1 | 0 | 0 | 0.01235 | 0.01953 | 0.024 | 0.02701 | 0.02915 | 0.03076 | 0.03201 | 0.033 | 0.0384 | |
| 1 | 0 | 0 | 0.01235 | 0.01953 | 0.024 | 0.02701 | 0.02915 | 0.03076 | 0.03201 | 0.033 | 0.0384 | |
| 1 | 0 | 0 | 0.01235 | 0.01953 | 0.024 | 0.02701 | 0.02915 | 0.03076 | 0.03201 | 0.033 | 0.0384 | |
| 1 | 0 | 0 | 0.01235 | 0.01953 | 0.024 | 0.02701 | 0.02915 | 0.03076 | 0.03201 | 0.033 | 0.0384 | |
| 1 | 0 | 0 | 0.01235 | 0.01953 | 0.024 | 0.02701 | 0.02915 | 0.03076 | 0.03201 | 0.033 | 0.0384 | |
| 1 | 0 | 0 | 0.01235 | 0.01953 | 0.024 | 0.02701 | 0.02915 | 0.03076 | 0.03201 | 0.033 | 0.0384 | |
| 1 | 0 | 0 | 0.01235 | 0.01953 | 0.024 | 0.02701 | 0.02915 | 0.03076 | 0.03201 | 0.033 | 0.0384 | |
| 1 | 0 | 0 | 0.01235 | 0.01953 | 0.024 | 0.02701 | 0.02915 | 0.03076 | 0.03201 | 0.033 | 0.0384 | |
| 1 | 0 | 0 | 0.01235 | 0.01953 | 0.024 | 0.02701 | 0.02915 | 0.03076 | 0.03201 | 0.033 | 0.0384 | |
| 1 | 0 | 0 | 0.01235 | 0.01953 | 0.024 | 0.02701 | 0.02915 | 0.03076 | 0.03201 | 0.033 | 0.0384 | |
| 1 | 0 | 0 | 0.01235 | 0.01953 | 0.024 | 0.02701 | 0.02915 | 0.03076 | 0.03201 | 0.033 | 0.0384 | |
| 0 | 0 | 0 | 0 | 0.00391 | 0.008 | 0.01157 | 0.01458 | 0.01709 | 0.0192 | 0.021 | 0.03272 | |
| 1.91667 | 1 | 0.7284 | 0.5625 | 0.456 | 0.38272 | 0.32945 | 0.28906 | 0.25743 | 0.232 | 0.08967 |
Table 2 contains the distance
The distance
| n | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|
| 0.03944773 | 0.08966773 | 0.09373096 | 0.15266043 | 0.16253677 | 0.22488947 | 0.24373486 | 0.30403801 |
Tables 3 and 4 contain the same information for the English model as Tables 1 and 2 do for the theoretical one. In this case the value of k was fixed to 26 but the different sizes of corpora have been considered. We point out that while the probabilities of individual permutations with the same number of consecutive pairs are equal in Table 1 they are different in Table 4. The reason is that the probability distribution of n-grams in the domain of the English model is not the uniform one.
The distance
| 0.036 | 0.035 | 0.038 | 0.037 | 0.036 | 0.037 | 0.04 | 0.047 | 0.042 | 0.041 | |
| 0.075 | 0.078 | 0.077 | 0.077 | 0.077 | 0.077 | 0.077 | 0.087 | 0.09 | 0.093 | |
| 0.128 | 0.13 | 0.13 | 0.13 | 0.129 | 0.128 | 0.127 | 0.127 | 0.126 | 0.125 | |
| 0.196 | 0.193 | 0.193 | 0.192 | 0.191 | 0.187 | 0.186 | 0.184 | 0.181 | 0.181 | |
| 0.281 | 0.274 | 0.27 | 0.267 | 0.265 | 0.259 | 0.255 | 0.253 | 0.25 | 0.25 | |
| 0.421 | 0.395 | 0.382 | 0.374 | 0.368 | 0.353 | 0.341 | 0.336 | 0.332 | 0.331 | |
| 0.74 | 0.64 | 0.6 | 0.572 | 0.554 | 0.509 | 0.475 | 0.46 | 0.452 | 0.449 | |
| 1.628 | 1.394 | 1.219 | 1.083 | 0.976 | 0.86 | 0.748 | 0.699 | 0.677 | 0.665 |
The probability p of π for
| π | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 0.04551 | 0.04569 | 0.04628 | 0.04639 | 0.04656 | 0.0468 | 0.04729 | 0.05029 | 0.05129 | 0.05154 | |
| 0.04281 | 0.04257 | 0.0426 | 0.04278 | 0.04286 | 0.04308 | 0.04294 | 0.04365 | 0.04386 | 0.04386 | |
| 0.04379 | 0.04351 | 0.04356 | 0.04346 | 0.04328 | 0.04344 | 0.04297 | 0.04418 | 0.04481 | 0.04527 | |
| 0.04318 | 0.04362 | 0.04313 | 0.04279 | 0.04309 | 0.04332 | 0.04334 | 0.04338 | 0.04354 | 0.04377 | |
| 0.04416 | 0.04376 | 0.04392 | 0.04409 | 0.04419 | 0.04364 | 0.04351 | 0.04384 | 0.04431 | 0.04456 | |
| 0.04623 | 0.04652 | 0.04602 | 0.04583 | 0.04562 | 0.04543 | 0.04488 | 0.04602 | 0.04602 | 0.04573 | |
| 0.04727 | 0.04775 | 0.04726 | 0.04742 | 0.04745 | 0.04751 | 0.04747 | 0.04658 | 0.04662 | 0.04669 | |
| 0.04216 | 0.04228 | 0.04284 | 0.04324 | 0.04374 | 0.0439 | 0.04462 | 0.04483 | 0.04484 | 0.04496 | |
| 0.04334 | 0.04381 | 0.04377 | 0.04372 | 0.04345 | 0.04384 | 0.04392 | 0.04484 | 0.04519 | 0.04527 | |
| 0.04904 | 0.04902 | 0.04891 | 0.04892 | 0.04875 | 0.04824 | 0.04826 | 0.04699 | 0.04657 | 0.04645 | |
| 0.04188 | 0.04234 | 0.04248 | 0.04267 | 0.04272 | 0.04305 | 0.04396 | 0.04381 | 0.04349 | 0.04361 | |
| 0.04262 | 0.0426 | 0.04323 | 0.04332 | 0.04352 | 0.0439 | 0.04462 | 0.0449 | 0.04446 | 0.04456 | |
| 0.03934 | 0.03944 | 0.03937 | 0.03937 | 0.0393 | 0.03878 | 0.03803 | 0.03778 | 0.03794 | 0.0379 | |
| 0.04428 | 0.04448 | 0.04391 | 0.04364 | 0.0434 | 0.04304 | 0.04207 | 0.04081 | 0.0405 | 0.04004 | |
| 0.04097 | 0.04068 | 0.04054 | 0.04054 | 0.04054 | 0.04061 | 0.04028 | 0.03963 | 0.03901 | 0.03906 | |
| 0.0377 | 0.03747 | 0.03739 | 0.03723 | 0.03722 | 0.03713 | 0.03692 | 0.03767 | 0.03802 | 0.0379 | |
| 0.04458 | 0.04432 | 0.04378 | 0.04367 | 0.04337 | 0.04279 | 0.04201 | 0.04088 | 0.04076 | 0.04032 | |
| 0.03746 | 0.03771 | 0.03778 | 0.03792 | 0.03813 | 0.0384 | 0.03844 | 0.03819 | 0.03812 | 0.03801 | |
| 0.03739 | 0.03693 | 0.03696 | 0.03654 | 0.03653 | 0.03654 | 0.03707 | 0.03636 | 0.03634 | 0.03658 | |
| 0.03912 | 0.03915 | 0.03929 | 0.03955 | 0.03935 | 0.03944 | 0.03938 | 0.0383 | 0.03755 | 0.0375 | |
| 0.04123 | 0.0411 | 0.04094 | 0.04106 | 0.04116 | 0.04079 | 0.04089 | 0.04015 | 0.0399 | 0.03964 | |
| 0.03612 | 0.03609 | 0.03647 | 0.03673 | 0.03667 | 0.03679 | 0.03704 | 0.03711 | 0.03705 | 0.03715 | |
| 0.03726 | 0.0374 | 0.03747 | 0.03733 | 0.03744 | 0.03773 | 0.03809 | 0.03784 | 0.03774 | 0.03767 | |
| 0.03254 | 0.03173 | 0.03211 | 0.03178 | 0.03164 | 0.03182 | 0.03202 | 0.03197 | 0.03206 | 0.03195 | |
| 0.075066 | 0.077922 | 0.076702 | 0.077230 | 0.07736 | 0.077287 | 0.077045 | 0.086630 | 0.090028 | 0.092582 |
4 Conclusions
In this paper we have initiated a study of the security of ciphers employing
Bellaso’s method with respect to the probability distribution of permutations
generated in this way. As usual we have assumed that the uniform
probability distribution of permutations is the ideal one. The intuition
suggests that for n large, Bellaso’s mnemonic method does not provide a
distribution on
Acknowledgements
We are indebted to Noga Alon for inspiring discussions on the topic of the paper and for the proof of Corollary 2.5. We are also grateful to anonymous reviewers for helpful comments and remarks.
References
[1] Bard G. V., Ault S. V. and Courtois N. T., Statistics of random permutations and the cryptanalysis of periodic block ciphers, Cryptologia 36 (2012), 240–262. 10.1080/01611194.2011.632806Search in Google Scholar
[2] Bauer F. L., Decrypted Secrets. Methods and Maxims of Cryptology, Springer, Berlin, 2007. Search in Google Scholar
[3] Bellaso G. B., Novi et singolari modi di cifrare de l’eccellente dottore di legge Messer Giouan Battista Bellaso nobile bresciano, Lodovico Britannico, Brescia, 1555. Search in Google Scholar
[4] Carlitz L., Kurtz D. C., Scoville R. and Stackelberg O. P., Asymptotic properties of Eulerian numbers, Z. Wahrscheinlichkeitstheor. Verw. Geb. 23 (1972), 47–54. 10.1007/BF00536689Search in Google Scholar
[5] Eulerus L., Institutiones calculi differentialis cum eius usu in analysi finitorum ac doctrina serierum, Academia Scientiarum Imperialis Petropolitanae, Sankt Petersburg, 1755. Search in Google Scholar
[6] Goldreich O., Foundations of Cryptography: Basic Tools, Cambridge University Press, Cambridge, 2001. 10.1017/CBO9780511546891Search in Google Scholar
[7] Hagen J. G., Theorie der Combinationen, Synopsis der höheren Mathematik. Erster Band. Arithmetische und algebrische Analysis, Felix L. Dames, Berlin (1891), 55–68. Search in Google Scholar
[8] Knuth D. E., The Art of Computer Programming. Vol. 2., Addison-Wesley, Boston, 2006. 10.1145/1283920.1283929Search in Google Scholar
[9] Kollar J., Soviet vic cipher: No respector of Kerckhoff’s principles, Cryptologia 40 (2016), no. 1, 33–48. 10.1080/01611194.2015.1028679Search in Google Scholar
[10] Liskov M., Rivest R. L. and Wagner D., Tweakable block ciphers, J. Cryptology 24 (2011), 588–613. 10.1007/3-540-45708-9_3Search in Google Scholar
[11] Petersen T. K., Eulerian Numbers, Birkhäuser, Basel, 2015. 10.1007/978-1-4939-3091-3Search in Google Scholar
[12] Rivest R. L., Symmetric encryption via keyrings and ECC, preprint 2016, http://arcticcrypt.b.uib.no/files/2016/07/Slides-Rivest.pdf. Search in Google Scholar
[13] Worpitzky J., Studien über die Bernoullischen und Eulerschen Zahlen, J. Reine Angew. Math. 94 (1883), 203–232. 10.1515/crll.1883.94.203Search in Google Scholar
[14] Zajac P., Passphrase generator and typing, 2016, http://hanzo.sk/TP/. Search in Google Scholar
© 2017 by De Gruyter
This article is distributed under the terms of the Creative Commons Attribution Non-Commercial License, which permits unrestricted non-commercial use, distribution, and reproduction in any medium, provided the original work is properly cited.
Articles in the same Issue
- Frontmatter
- Analysis of decreasing squared-sum of Gram–Schmidt lengths for short lattice vectors
- The complexity of the connected graph access structure on seven participants
- On a decentralized trustless pseudo-random number generation algorithm
- On a mnemonic construction of permutations
Articles in the same Issue
- Frontmatter
- Analysis of decreasing squared-sum of Gram–Schmidt lengths for short lattice vectors
- The complexity of the connected graph access structure on seven participants
- On a decentralized trustless pseudo-random number generation algorithm
- On a mnemonic construction of permutations