Regression analysis of interval-censored failure time data under semiparametric transformation models with missing covariates
-
Yichen Lou


Abstract
This paper discusses regression analysis of interval-censored failure time data arising from semiparametric transformation models in the presence of covariates that are missing at random (MAR). We define a specific formulation of the MAR mechanism tailored to the interval censoring, where the timing of observation adds complexity to handling missing covariates. To overcome the limitations and computational challenges present in the existing methods, we propose a multiple imputation procedure that can be easily implemented with the use of the standard software. The proposed method makes use of two predictive scores for each individual and the distance defined by these scores. Furthermore, it utilizes partial information from incomplete observations and thus yields more efficient estimators than the complete-case analysis and the inverse probability weighting approach. An extensive simulation study is conducted to assess the performance of the proposed method and indicates that it performs well in practical situations. Finally we apply the proposed approach to an Alzheimer’s Disease study that motivated this work.
1 Introduction
This paper discusses regression analysis of interval-censored failure time data arising from semiparametric transformation models in the presence of missing at random covariates. By interval-censored data, we usually mean that the failure time of interest is observed or known only to belong to an interval instead of being known exactly, and they can often occur in various fields such as periodic follow-up studies and clinical trials [1], 2]. Also they include right-censored data as a specific case [3]. For regression analysis of failure time data, semiparametric transformation models have become more popular due to their flexibility in capturing diverse covariate effects [4], [5], [6], [7], [8]. In particular, they include the proportional hazards and odds models as special instances.
One example of interval-censored data that motivated this study is given by the Alzheimer’s Disease Neuroimaging Initiative (ADNI). This longitudinal multi-center follow-up study, launched in 2004, aims to identify the biomarkers for early detection and monitoring of Alzheimer’s Disease (AD). Among others, one variable of interest is the onset of AD conversion [9], 10], and due to the periodic follow-up nature, only interval-censored are available for the occurrence time of AD conversion. Furthermore, there exist missing values on some covariates or biomarkers. More details about the study will be given below.
Missing covariates occur in almost every field and it is well-known that their impact on statistical analyses and the results can be substantial if not properly taken into account [11]. In particular, the missing mechanism plays an important role and two types of commonly studied mechanisms are missing completely at random (MCAR) and missing at random (MAR). Correspondingly two commonly used analysis approaches are the complete-case analysis and the inverse probability weighting (IPW). The former bases the analysis solely on complete cases or excludes the observations with missing values, and it is easy to see that although easily implementable, it may be less efficient and produce biased estimates under some specific MAR schemes [12]. The IPW approach introduces weights to the complete-case analysis aiming to mitigate potential estimation biases associated with the former by modeling the missing mechanism instead of the distribution of partially observed variables [13]. Thus its validity is highly contingent on an accurate model of the missing mechanism. Also as the former, it may be inefficient.
Several methods have been developed for regression analysis of interval-censored failure time data with missing covariates. For example, Wen and Lin [14] considered the problem for current status data, a special case of interval-censored data, meaning that the censoring interval includes either zero or infinity or the failure time of interest is either left- or right-censored. Li et al. [15] and Zhou et al. [16] also investigated the problem for the cases where the failure time follows the additive hazards model and the proportional hazards model, respectively. In particular, the latter relies on high-dimensional integrals, resulting in a complex algorithm that may be challenging to generalize to other hazard models. Nevertheless, there does not seem to exist an established procedure for estimating the semiparametric transformation model based on interval-censored data with missing covariates.
The multiple imputation approach has been commonly used for the analysis of missing data. However, the conventional multiple imputation procedures face challenges when dealing with interval-censored outcomes and can result in substantial biases as pointed out by Zhou et al. [16]. In this paper, we introduce a novel multiple imputation procedure tailored for regression analysis of interval-censored data arising from the semiparametric transformation model under the MAR assumption. The key innovation involves leveraging two predictive scores for each subject and subsequently forming a neighborhood set. This set comprises fully observed data points with similar predictive scores, serving as the imputation set for missing observations. The idea was initially proposed by Long et al. [17] for complete data and later extended to right-censored data under the Cox model by Hsu and Yu [12]. In the proposed method, we use Turnbull’s self-consistency estimator [18] for the predictive scores to integrate survival outcome information, and the sieve maximum likelihood estimation procedure is employed after the imputation. It is intuitive and can be readily implemented using the standard software.
The remainder of the paper is organized as follows. In Section 2, we will first introduce some notation and assumptions that will be used throughout the paper and then discuss the structure of the observed data and the missing mechanism. Section 3 will briefly review the existing estimation procedure for the situation of no missing covariates and the two naive methods mentioned above, and the proposed multiple imputation approach will be presented in Section 4. A simulation study is conducted to assess the performance of the proposed method in Section 5 and suggests that it works well in practical situations. In Section 6, we apply the proposed approach to the ADNI study discussed above, and Section 7 concludes with some discussion and concluding remarks.
2 Notation and assumptions
Consider a failure time study that involves n independent subjects. For subject i, let T
i
denote the failure time of interest, and suppose that there exist two sets of covariates denoted by
In the above, α and β denote q × 1 and p × 1 vector of regression coefficients, respectively. G(⋅) is a pre-specified, strictly increasing transformation link function, and Λ0(t) denotes an unknown increasing baseline cumulative hazard function.
As mentioned above, the model above offers significant flexibility and includes various widely used models as special cases. For instance, it yields the proportional hazards model and the proportional odds model with G(x) = x and G(x) = log(1 + x), respectively. Also two commonly used classes of transformation functions are the Box-Cox transformation and logarithmic transformations, represented by G(x) = [(1 + x)
ρ
− 1]/ρ and G(x) = log(1 + ρx)/ρ, respectively, with ρ ≥ 0. One can easily show that under the model above, the survival function of T
i
takes the form
For the observed data, suppose that each subject is observed at a sequence of observation times
In the following, for simplicity, we will assume that the missing mechanism is MAR [19] or we have
and
In other words, the probability that data are missing depends only on the observed parts but not on the missing parts. The MAR reduces to MCAR if the probability above is constant [20], 21]. Note that here for mathematical simplicity, we assume that the missing mechanism relies solely on the covariates that have no missing components, not the covariates that contain some missing values.
3 Naive estimation procedures
In this section, we will first briefly review the estimation approach when there were no missing covariates and then introduce two aforementioned naive estimation procedures for the missing covariates. Note that under the assumptions above, if we have the full data without missing, the benchmark log-likelihood function has the form
For the situation, several methods have been given in the literature to estimate the unknown parameter θ = ( α , β , Λ0) [1]. In particular, one can employ the sieve maximum likelihood approach that approximates the unknown function Λ0(t) using Bernstein polynomials before the maximization [8], 22].
More specifically, define the parameter space
In the above, M n ensures that the Λ0n is bounded and
with the degree m = o(n ν ) for some ν ∈ (0, 1). The sieve maximum likelihood estimator of θ is then defined as the value of θ that maximizes the log-likelihood function ℓ ( θ ∣O) over Θ n . By approximating the nonparametric function using Bernstein polynomials, it transforms the semiparametric problem into a parametric one, making it much easier to handle and manipulate.
Now suppose that there exist missing covariates. As mentioned above, one commonly used approach is the complete-case analysis that bases the estimation only on the samples with complete data and maximizes the observed log-likelihood function
with the use of the sieve approach mentioned earlier. As described above, one advantage of this method is its ease of implementation. However, if the proportion of missing data is large, it can result in significant information loss, reduced efficiency and substantial bias as will be demonstrated in the simulation study below.
As discussed above, instead of the complete-case analysis, one may employ the inverse probability weighted (IPW) approach, which is essentially a two-step approach. It first assumes a model for the probability of being observed as
It is easy to see that this approach can make use of the observed information from both complete and incomplete cases and thus is expected to yield more efficient estimators than the complete-case analysis [13]. On the other hand, one drawback is that one needs the correctly specified missing probability to obtain a stable and valid IPW estimator. Furthermore, even with the correctly specified model, the procedure may encounter challenges if some values of
4 Multiple imputation estimation
Now we present the proposed multiple imputation estimation procedure. As mentioned previously, the basic idea behind it is to construct two predictive scores for each individual and then build a neighborhood set that comprises fully observed individuals for each individual with missing information. Subsequently, we generate a pseudo-observation value for the individual with a missing covariate from its neighborhood set for the imputation. After imputing all of the missing values, we treat the imputed dataset as the observed data to carry out the estimation based on the log-likelihood function given in (2) as described in the previous section. In the following, for simplicity, we will focus on the situation of q = 1. The proposed algorithm can be easily generalized to the case where q > 1 and more details on it will be given in Appendix A.
For each individual, we define two predictive scores,
A reasonable idea is to incorporate information from the interval-censored survival outcome, cumulative baseline hazard, missing indicator, and fully observed covariates into the working models. To achieve this, we first obtain the nonparametric survival function estimator
Given the predictive score
Note that in (5), the first part with weight ω
1 governs the observed distribution by modeling the relationships between X and
To ensure a proper imputation scheme that fully encompasses the uncertainty in the imputed values, we employ the bootstrap strategy to approximate the uncertainty in parameter estimates [24], [25], [26]. The detailed multiple imputation procedures are outlined as follows.
[Step 1] Bootstrap Sampling.
Obtain a bootstrap sample
[Step 2] Self-Consistency Algorithm.
Apply Turnbull’s self-consistency algorithm to B (s) to obtain
Perform the same procedure on O to obtain
[Step 3] Model Fitting.
Fit models H 1(⋅) and H 2(⋅) using
Calculate the initial predictive scores
Standardize the scores by subtracting the sample mean and dividing by the standard deviation, resulting in standardized scores
[Step 4] Impute Missing Values for X.
For each missing value X k associated with individual O k in O, apply the estimated working models
Standardize these scores by subtracting the sample mean of the bootstrap predictive scores and dividing by the standard deviation of the bootstrap predictive scores, resulting in standardized scores
Use the pre-specified ω 1 to calculate the distance D k = {D(k, [1]), …, D(k, [n (s)])} between O k and the individuals in
Define a neighborhood set consisting of nearest neighbor (NN) subjects from B (s) by sorting distances in ascending order. Then, randomly draw a pseudo observation value for X k from the observed values of X (s) within this neighborhood set.
[Step 5] Final Estimation.
After completing the imputation for all missing covariates, proceed with the sieve maximum likelihood procedure using the log-likelihood function to obtain the final estimator
The entire imputation procedure will be repeated K times, generating K multiple imputed data sets. Then the overall estimates and their variances will be obtained by applying Rubin’s combination rule [27]:
and
respectively. In equations (7) and (8), the second term accounts for the between-imputation variance, while the first term corresponds to the within-imputation variance. To calculate the within-imputation variance, various approaches can be employed. One method is the profile likelihood function method [28], while another involves the inverse of the Hessian matrix of the log-likelihood function [29]. In the following, we adopt the latter approach, treating ℓ( θ ∣O) as a function of the finite-dimensional parameters after the sieve. This approach is straightforward to implement and has shown strong performance in numerical studies. For the numerical studies below, the Quasi-Newton algorithm, a tool of unconstrained nonlinear optimization, built-in fminunc in Matlab is used.
5 A simulation study
In this section, we present some results obtained from a simulation study conducted for assessing the finite sample performance of the multiple imputation estimation procedure proposed in the previous sections. In the study, it was assumed that there existed a 2-dimensional observed covariate
For the generation of censoring intervals L
i
and R
i
, each subject was assumed to undergo examinations at k equally spaced time points within the interval (0.02, 2.48). At each time point, a subject was examined or observed for the events of interest with a probability of 1 − q, independent of the examinations at other time points. For subject i, L
i
and R
i
were then defined as the last actual observation time before T
i
and the first actual observation time after T
i
. For the results given below, we set k = 10 and q = 0.2, resulting in the right censoring rate ranging from 20 % to 30 %. For the missing mechanism, we considered a MAR scenario with
For comparison, in addition to the proposed imputation approach, we also considered the full data analysis (FULL), complete-case analysis (CCA) and the IPW approach. Note that the full data analysis can serve as a benchmark, representing the situation with no missing covariate. For the IPW approach, two missing scheme working models were used: one correctly specified (IPW–I), involving
Tables 1 and 2 present the results for the continuous X and the discrete X under the PH model, respectively. They include the estimated bias (Bias) given by the average of the estimates minus the true value, the sample standard deviation (SD) of the estimates, the average of the estimated standard errors (ESE), and the 95 % empirical coverage probability (CP). One can see that the proposed model performs well for all situations considered. In particular, the bias is comparable to that given by the full data analysis and the coverage probabilities consistently approach the 95 % nominal level. In contrast, complete-case analysis yielded severe biases, and the IPW estimator requires the correctly specified missing scheme working model to give valid results. Furthermore, the results indicate that the varying sizes of NN yielded similar results. In addition, we also considered the PO model instead of the Cox model and studied the situation of q = 2. All of the obtained results are given in the Supplementary Material to save space and give similar conclusions.
Simulation results with continuous X under PH model.
| n = 200 | n = 400 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Approach | Parameters | Bias | SD | ESE | CP | Bias | SD | ESE | CP |
| FULL | α = −0.8 | −0.0235 | 0.1090 | 0.1053 | 0.944 | −0.0089 | 0.0762 | 0.0734 | 0.944 |
| β 1 = 0.5 | 0.0170 | 0.1835 | 0.1720 | 0.932 | 0.0127 | 0.1232 | 0.1208 | 0.952 | |
| β 2 = −0.6 | −0.0103 | 0.2017 | 0.1959 | 0.952 | −0.0050 | 0.1389 | 0.1374 | 0.944 | |
| CCA | α = −0.8 | 0.1037 | 0.1329 | 0.1277 | 0.845 | 0.1261 | 0.0876 | 0.0882 | 0.669 |
| β 1 = 0.5 | −0.0620 | 0.2216 | 0.2080 | 0.980 | −0.0759 | 0.1491 | 0.1453 | 0.911 | |
| β 2 = −0.6 | 0.0198 | 0.2445 | 0.2388 | 0.953 | 0.0322 | 0.1654 | 0.1661 | 0.948 | |
| IPW-I | α = −0.8 | −0.0424 | 0.1568 | 0.1568 | 0.949 | −0.0181 | 0.1057 | 0.1029 | 0.935 |
| β 1 = 0.5 | 0.0307 | 0.2794 | 0.2711 | 0.937 | 0.0164 | 0.1876 | 0.1849 | 0.938 | |
| β 2 = −0.6 | −0.0420 | 0.3125 | 0.3075 | 0.941 | −0.0211 | 0.2142 | 0.2065 | 0.948 | |
| IPW-II | α = −0.8 | 0.1033 | 0.1338 | 0.1360 | 0.849 | 0.1268 | 0.0880 | 0.0899 | 0.674 |
| β 1 = 0.5 | −0.0636 | 0.2217 | 0.2199 | 0.937 | −0.0767 | 0.1489 | 0.1487 | 0.919 | |
| β 2 = −0.6 | 0.0220 | 0.2468 | 0.2554 | 0.949 | 0.0325 | 0.1654 | 0.1697 | 0.947 | |
| NN-1 | α = −0.8 | −0.0188 | 0.1517 | 0.1539 | 0.947 | −0.0008 | 0.1068 | 0.1037 | 0.952 |
| β 1 = 0.5 | −0.0264 | 0.1967 | 0.2022 | 0.956 | −0.0251 | 0.1379 | 0.1425 | 0.956 | |
| β 2 = −0.6 | 0.0132 | 0.2285 | 0.2342 | 0.951 | 0.0117 | 0.1667 | 0.1643 | 0.949 | |
| NN-3 | α = −0.8 | −0.0097 | 0.1497 | 0.1533 | 0.960 | 0.0046 | 0.1047 | 0.1039 | 0.953 |
| β 1 = 0.5 | −0.0312 | 0.1931 | 0.2003 | 0.953 | −0.0311 | 0.1345 | 0.1419 | 0.953 | |
| β 2 = −0.6 | 0.0142 | 0.2226 | 0.2315 | 0.960 | 0.0120 | 0.1620 | 0.1637 | 0.945 | |
| NN-5 | α = −0.8 | 0.0002 | 0.1478 | 0.1526 | 0.959 | 0.0085 | 0.1034 | 0.1030 | 0.954 |
| β 1 = 0.5 | −0.0357 | 0.1900 | 0.1990 | 0.956 | −0.0351 | 0.1333 | 0.1406 | 0.960 | |
| β 2 = −0.6 | 0.0102 | 0.2180 | 0.2295 | 0.960 | 0.0104 | 0.1620 | 0.1625 | 0.949 | |
| NN-10 | α = −0.8 | 0.0255 | 0.1465 | 0.1539 | 0.955 | 0.0190 | 0.1010 | 0.1042 | 0.954 |
| β 1 = 0.5 | −0.0419 | 0.1853 | 0.1957 | 0.955 | −0.0410 | 0.1294 | 0.1397 | 0.953 | |
| β 2 = −0.6 | −0.0181 | 0.2121 | 0.2270 | 0.961 | 0.0172 | 0.1573 | 0.1613 | 0.955 | |
Simulation results with discrete X under PH model.
| n = 200 | n = 400 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Approach | Parameters | Bias | SD | ESE | CP | Bias | SD | ESE | CP |
| FULL | α = −0.8 | −0.0134 | 0.1739 | 0.1799 | 0.953 | −0.0104 | 0.1279 | 0.1263 | 0.947 |
| β 1 = 0.5 | 0.0164 | 0.1666 | 0.1638 | 0.944 | 0.0088 | 0.1173 | 0.1149 | 0.951 | |
| β 2 = −0.6 | −0.0125 | 0.1662 | 0.1670 | 0.962 | −0.0074 | 0.1172 | 0.1173 | 0.951 | |
| CCA | α = −0.8 | 0.1650 | 0.2264 | 0.2233 | 0.866 | 0.1616 | 0.1569 | 0.1558 | 0.803 |
| β 1 = 0.5 | −0.0885 | 0.2103 | 0.2012 | 0.916 | −0.1015 | 0.1383 | 0.1400 | 0.886 | |
| β 2 = −0.6 | 0.0373 | 0.2149 | 0.2065 | 0.932 | 0.0496 | 0.1410 | 0.1432 | 0.360 | |
| IPW-I | α = −0.8 | −0.0159 | 0.2984 | 0.3098 | 0.947 | −0.0222 | 0.2032 | 0.2071 | 0.953 |
| β 1 = 0.5 | 0.0313 | 0.2818 | 0.2783 | 0.929 | 0.0114 | 0.1858 | 0.1869 | 0.940 | |
| β 2 = −0.6 | −0.0385 | 0.2897 | 0.2765 | 0.941 | −0.0151 | 0.1838 | 0.1845 | 0.941 | |
| IPW-II | α = −0.8 | 0.1645 | 0.2281 | 0.2395 | 0.891 | 0.1620 | 0.1570 | 0.1616 | 0.810 |
| β 1 = 0.5 | −0.0907 | 0.2107 | 0.2127 | 0.928 | −0.1026 | 0.1385 | 0.1435 | 0.889 | |
| β 2 = −0.6 | 0.0350 | 0.2180 | 0.2203 | 0.940 | 0.0491 | 0.1410 | 0.1472 | 0.940 | |
| NN-1 | α = −0.8 | 0.0040 | 0.3062 | 0.3278 | 0.942 | −0.0086 | 0.2128 | 0.2209 | 0.939 |
| β 1 = 0.5 | −0.0052 | 0.1813 | 0.1888 | 0.961 | −0.0040 | 0.1291 | 0.1319 | 0.945 | |
| β 2 = −0.6 | 0.0120 | 0.1855 | 0.1901 | 0.955 | 0.0088 | 0.1281 | 0.1342 | 0.960 | |
| NN-3 | α = −0.8 | 0.0203 | 0.2990 | 0.3172 | 0.945 | 0.0003 | 0.2084 | 0.2161 | 0.948 |
| β 1 = 0.5 | −0.0099 | 0.1765 | 0.1859 | 0.963 | −0.0074 | 0.1266 | 0.1308 | 0.948 | |
| β 2 = −0.6 | 0.0202 | 0.1825 | 0.1872 | 0.954 | 0.0144 | 0.1264 | 0.1326 | 0.952 | |
| NN-5 | α = −0.8 | 0.0379 | 0.2930 | 0.3130 | 0.941 | 0.0110 | 0.2028 | 0.2138 | 0.946 |
| β 1 = 0.5 | −0.0151 | 0.1744 | 0.1830 | 0.962 | −0.0113 | 0.1251 | 0.1297 | 0.947 | |
| β 2 = −0.6 | 0.0272 | 0.1787 | 0.1858 | 0.958 | 0.0201 | 0.1236 | 0.1315 | 0.955 | |
| NN-10 | α = −0.8 | 0.0445 | 0.2773 | 0.2993 | 0.939 | 0.0331 | 0.1994 | 0.2087 | 0.940 |
| β 1 = 0.5 | −0.0253 | 0.1702 | 0.1785 | 0.964 | −0.0192 | 0.1216 | 0.1273 | 0.951 | |
| β 2 = −0.6 | 0.0374 | 0.1758 | 0.1822 | 0.945 | 0.0294 | 0.1217 | 0.1291 | 0.955 | |
Note that in the above, it was assumed that the covariate X was related to the covariate Z . To further evaluate the robustness of the proposed method, we also considered the situation where X is independent of Z and Table 3 gives the estimation results obtained with n = 200, X following the normal distribution with the mean 0 and the variance of 0.5, and the other set-ups being the same as in Table 1. One can see that they are similar to those given in Table 1 and again suggest that the proposed method performs well.
Simulation results under an independent missing covariate.
| PH model | PO model | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Approach | Parameters | Bias | SD | ESE | CP | Bias | SD | ESE | CP |
| FULL | α = −0.8 | −0.0344 | 0.1731 | 0.1682 | 0.946 | −0.0213 | 0.2695 | 0.2708 | 0.951 |
| β 1 = 0.5 | 0.0035 | 0.1606 | 0.1587 | 0.955 | 0.0028 | 0.2774 | 0.2628 | 0.939 | |
| β 2 = −0.6 | −0.0166 | 0.1660 | 0.1639 | 0.951 | −0.0146 | 0.2761 | 0.2668 | 0.942 | |
| CCA | α = −0.8 | 0.1209 | 0.2160 | 0.2050 | 0.881 | 0.0417 | 0.3682 | 0.3662 | 0.948 |
| β 1 = 0.5 | −0.0894 | 0.2033 | 0.1934 | 0.910 | −0.0220 | 0.3857 | 0.3545 | 0.933 | |
| β 2 = −0.6 | 0.0264 | 0.2081 | 0.2010 | 0.950 | −0.1359 | 0.3897 | 0.3644 | 0.924 | |
| IPW-I | α = −0.8 | −0.0522 | 0.2661 | 0.2653 | 0.940 | −0.0285 | 0.4189 | 0.4424 | 0.957 |
| β 1 = 0.5 | 0.0194 | 0.2674 | 0.2792 | 0.941 | 0.0183 | 0.4335 | 0.4308 | 0.920 | |
| β 2 = −0.6 | −0.0552 | 0.2673 | 0.2625 | 0.926 | −0.0479 | 0.4338 | 0.4313 | 0.944 | |
| IPW-II | α = −0.8 | 0.1210 | 0.2162 | 0.2174 | 0.892 | 0.0412 | 0.3692 | 0.3955 | 0.957 |
| β 1 = 0.5 | −0.0919 | 0.2036 | 0.2086 | 0.923 | −0.0238 | 0.3863 | 0.3768 | 0.940 | |
| β 2 = −0.6 | 0.0250 | 0.2091 | 0.2145 | 0.953 | −0.1392 | 0.3909 | 0.3960 | 0.950 | |
| NN-1 | α = −0.8 | −0.0262 | 0.2722 | 0.2675 | 0.939 | −0.0244 | 0.4496 | 0.4978 | 0.960 |
| β 1 = 0.5 | −0.0159 | 0.1775 | 0.1766 | 0.950 | 0.0043 | 0.2850 | 0.2781 | 0.949 | |
| β 2 = −0.6 | −0.0032 | 0.1708 | 0.1807 | 0.968 | −0.0209 | 0.2886 | 0.2814 | 0.949 | |
| NN-3 | α = −0.8 | −0.0114 | 0.2629 | 0.2640 | 0.942 | −0.0206 | 0.4361 | 0.4761 | 0.949 |
| β 1 = 0.5 | −0.0178 | 0.1737 | 0.1743 | 0.952 | 0.0044 | 0.2846 | 0.2761 | 0.945 | |
| β 2 = −0.6 | 0.0040 | 0.1682 | 0.1785 | 0.968 | −0.0179 | 0.2877 | 0.2795 | 0.947 | |
| NN-5 | α = −0.8 | 0.0021 | 0.2605 | 0.2622 | 0.951 | −0.0141 | 0.4279 | 0.4698 | 0.959 |
| β 1 = 0.5 | −0.0196 | 0.1720 | 0.1725 | 0.957 | 0.0033 | 0.2839 | 0.2746 | 0.944 | |
| β 2 = −0.6 | 0.0068 | 0.1668 | 0.1774 | 0.963 | −0.0160 | 0.2864 | 0.2781 | 0.949 | |
| NN-10 | α = −0.8 | 0.0387 | 0.2508 | 0.2575 | 0.949 | −0.0037 | 0.4264 | 0.4482 | 0.946 |
| β 1 = 0.5 | −0.0224 | 0.1676 | 0.1698 | 0.954 | 0.0035 | 0.2835 | 0.2726 | 0.941 | |
| β 2 = −0.6 | 0.0131 | 0.1644 | 0.1750 | 0.962 | −0.0150 | 0.2847 | 0.2762 | 0.948 | |
As discussed and shown above, the proposed method can and also is expected to perform better than the CCA and IPW procedures in the presence of missing values. On the other hand, it is well-known that the three methods can give similar performances if the missing rate is low. Thus, as pointed out by a reviewer, it would be helpful to give a guideline on when CCA should not be used. For this, we repeated the study giving Table 3 under PO model and different missing rates by changing the parameter γ
0 in the missing mechanism
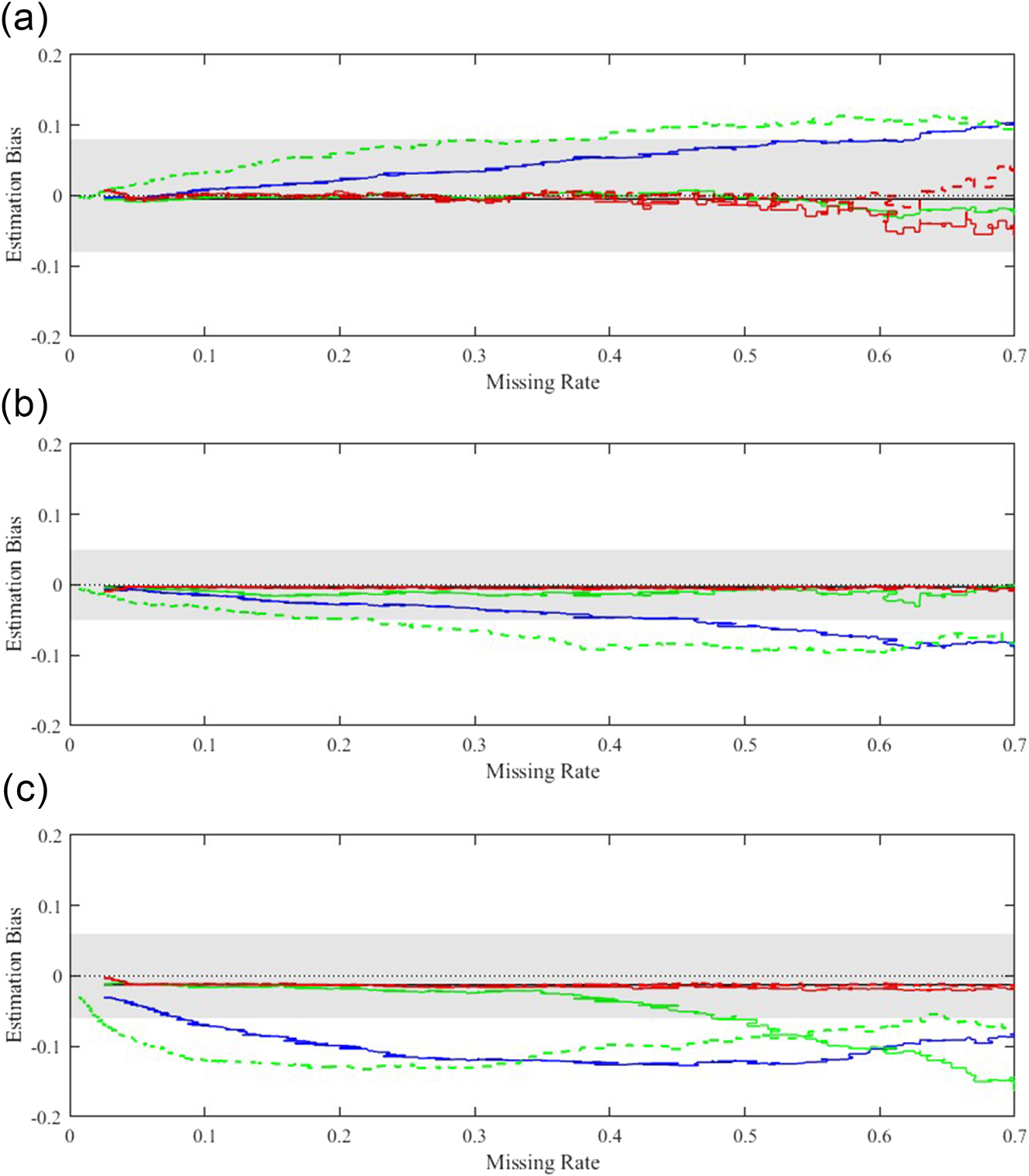
Estimation bias under different missing rate with n = 200: Comparison of methods: FULL (Black, solid line), CCA (BLUE, solid line), IPW-I (Green, solid line), IPW-II (Green, dashed line), NN-1 (Red, solid line), and NN-5 (Red, dashed line). Only 1 and 5 neighbors are used for nearest neighbor imputation. (a) Estimation biases of α. (b) Estimation biases of β 1. (c) Estimation biases of β 2.
6 An application
Now we apply the methodology proposed in the previous sections to the ADNI data discussed before. In the study, the participants are classified into three groups, cognitively normal (CN), mild cognitive impairment (MCI) and Alzheimer’s disease (AD). As discussed above, one of the variables of interest is the onset of AD conversion, and given the nature of the study, only interval-censored data are available on it. More specifically, the onset is only known to fall within the interval between the last observation time when the conversion had not occurred and the first observation time when it had already occurred.
In the analysis below, following others [30], 31], we will focus on the participants in the MCI group with the goal of determining the relationship between the time from the baseline visit date to AD conversion, the failure time of interest, and eight covariates. These covariates are AGE, GENDER, two AD assessment scale test results (ADAS11 and ADAS13), middle temporal gyrus volume (MIDTEMP), Rey Auditory Verbal Learning Test score of immediate recall (RAVLT), functional assessment questionnaire score (FAQ), and APOE4, a gene widely known to be related to AD. The dataset consists of 383 subjects with 213 converting to AD during the study.
In general, individuals were scheduled for follow-up examinations approximately every six months, although some visits were missed. Of the 383 participants, 170 were lost to follow-up before a recorded AD conversion. According to information from the ADNI website, 34 participants died during the follow-up period. Among them, 21 had been diagnosed with AD prior to death, while 13 had not. For ease of interpretation, we introduced a dummy variable based on the following criteria: individuals were categorized as aged 75 and above or below 75. In addition, approximately 20 % or 76 of the MIDTEMP values are missing and there are also three missing values on each of ADAS13 and FAQ. For simplicity, we will exclude the six subjects with missing values on ADAS13 or FAQ.
A more comprehensive summary of the eight covariates used in the analysis is provided in Table 4.
Summary Statistics for Covariates Included in the ADNI study.
| Factor | Description | Type | Size | Mean (SDa) | Median (IQRb) | Range/Min-Max | % missing |
|---|---|---|---|---|---|---|---|
| AGE | Age in years (Greater / Less than 75) | Binary | 377 | – | – | Yes:
|
0 % |
| GENDER | Biological sex (Male/Female) | Categorical | 377 | – | – | Male: 245, Female: 132 | 0 % |
| ADAS11 | AD assessment scale score | Continuous | 377 | 11.54 (4.46) | 11.33 (6) | 2–27.67 | 0 % |
| ADAS13 | AD assessment scale score | Continuous | 377 | 18.68 (6.34) | 18.67 (8.42) | 3–39.67 | 0 % |
| RAVLT | RAVLT immediate recall score | Continuous | 377 | 30.84 (9.15) | 30 (10) | 11–68 | 0 % |
| FAQ | Functional assessment questionnaire score | Continuous | 377 | 3.83 (4.51) | 2 (6) | 0– 21 | 0 % |
| MIDTEMP | Middle temporal gyrus volume (scaled by 1e4) | Continuous | 377 | 1.86 (0.30) | 1.86 (0.37) | 1.05–2.67 | 19.63 % |
| APOE4 | Number of APOE ϵ4 alleles (0, 1, or 2) | Ordinal categorical | 377 | – | – | 0 alleles: 174, 1 allele: 156, 2 alleles: 47 | 0 % |
-
aSD, standard deviation; bIQR, interquartile range.
Tables 5 and 6 present the analysis results given by the proposed approach, IPW approach and CCA approach under the PH and PO models. For the IPW approach, the logistic regression was used to model the missing probabilities and we considered two situations, setting
W
=
Z
as the covariate (IPW-I) or
Analysis results of ADNI study under PH model.
| Factors | Est | Se | p-val | Est | Se | p-val | Est | Se | p-val |
|---|---|---|---|---|---|---|---|---|---|
| CCA | IPW-I | IPW-II | |||||||
| AGE | −0.5018 | 0.1729 | 0.0037 | −0.4897 | 0.2025 | 0.0156 | −0.4835 | 0.1888 | 0.0105 |
| GENDER | −0.0516 | 0.1864 | 0.7821 | −0.5950 | 0.2077 | 0.7744 | −0.0612 | 0.2223 | 0.7830 |
| ADAS11 | −0.0566 | 0.0549 | 0.3025 | −0.4950 | 0.0646 | 0.4438 | −0.0488 | 0.0587 | 0.4056 |
| ADAS13 | 0.1109 | 0.0418 | 0.0080 | 0.1085 | 0.0510 | 0.0333 | 0.1079 | 0.0445 | 0.0155 |
| RAVLT | −0.0475 | 0.0130 | 0.0003 | −0.0448 | 0.0145 | 0.0021 | −0.0445 | 0.0143 | 0.0018 |
| FAQ | 0.0677 | 0.0156 | 0.0000 | 0.0671 | 0.0182 | 0.0002 | 0.0672 | 0.0950 | 0.0006 |
| MIDTEMP | −1.9734 | 0.3645 | 0.0000 | −1.9359 | 0.4154 | 0.0000 | −1.9280 | 0.4125 | 0.0000 |
| APOE4 | 0.3638 | 0.1228 | 0.0037 | 0.3546 | 0.1388 | 0.0107 | 0.3505 | 0.1311 | 0.0075 |
| NN-1 (ω 1 = 0.8) | NN-1 (ω 1 = 0.5) | NN-1 (ω 1 = 0.3) | |||||||
| AGE | −0.1980 | 0.1622 | 0.2223 | −0.2214 | 0.1651 | 0.1800 | −0.2079 | 0.1598 | 0.1933 |
| GENDER | 0.0054 | 0.1791 | 0.9761 | −0.0192 | 0.1782 | 0.9141 | −0.0095 | 0.1779 | 0.9576 |
| ADAS11 | −0.0607 | 0.0487 | 0.2126 | −0.0581 | 0.0490 | 0.2363 | −0.0580 | 0.0479 | 0.2254 |
| ADAS13 | 0.1046 | 0.0370 | 0.0047 | 0.1042 | 0.0374 | 0.0053 | 0.0480 | 0.0365 | 0.0041 |
| RAVLT | −0.0432 | 0.0115 | 0.0002 | −0.0426 | 0.0116 | 0.0002 | −0.0425 | 0.0116 | 0.0003 |
| FAQ | 0.0802 | 0.0142 | 0.0000 | 0.0791 | 0.0142 | 0.0000 | 0.0794 | 0.0141 | 0.0000 |
| MIDTEMP | −1.8598 | 0.3895 | 0.0000 | −1.9315 | 0.3925 | 0.0000 | −1.8667 | 0.3859 | 0.0000 |
| APOE4 | 0.3461 | 0.1137 | 0.0023 | 0.3400 | 0.1132 | 0.0027 | 0.3416 | 0.1140 | 0.0027 |
| NN-5 (ω 1 = 0.8) | NN-5 (ω 1 = 0.5) | NN-5 (ω 1 = 0.3) | |||||||
| AGE | −0.2115 | 0.1608 | 0.1883 | −0.2042 | 0.1637 | 0.2123 | −0.1923 | 0.1599 | 0.2291 |
| GENDER | −0.0060 | 0.1776 | 0.9730 | 0.0066 | 0.1752 | 0.9700 | 0.0063 | 0.1773 | 0.9719 |
| ADAS11 | −0.0594 | 0.0489 | 0.2241 | −0.0556 | 0.0498 | 0.2644 | −0.0563 | 0.0488 | 0.2491 |
| ADAS13 | 0.1054 | 0.0374 | 0.0048 | 0.1017 | 0.0376 | 0.0068 | 0.1020 | 0.0371 | 0.0059 |
| RAVLT | −0.0425 | 0.0116 | 0.0003 | −0.0425 | 0.0116 | 0.0003 | −0.0431 | 0.0116 | 0.0002 |
| FAQ | 0.0784 | 0.0144 | 0.0000 | 0.0789 | 0.0143 | 0.0000 | 0.0799 | 0.0143 | 0.0000 |
| MIDTEMP | −1.8908 | 0.3862 | 0.0000 | −1.8588 | 0.3765 | 0.0000 | −1.8480 | 0.3812 | 0.0000 |
| APOE4 | 0.3462 | 0.1148 | 0.0026 | 0.3491 | 0.1146 | 0.0023 | 0.3541 | 0.1139 | 0.0019 |
| NN-10 (ω 1 = 0.8) | NN-10 (ω 1 = 0.5) | NN-10 (ω 1 = 0.3) | |||||||
| AGE | −0.2031 | 0.1619 | 0.2096 | −0.2162 | 0.1596 | 0.1754 | −0.2149 | 0.1623 | 0.1855 |
| GENDER | 0.0051 | 0.1809 | 0.9775 | −0.0016 | 0.1745 | 0.9929 | −0.0038 | 0.1775 | 0.9829 |
| ADAS11 | −0.0584 | 0.0485 | 0.2285 | −0.0616 | 0.0492 | 0.2104 | −0.0593 | 0.0493 | 0.2287 |
| ADAS13 | 0.1038 | 0.0368 | 0.0048 | 0.1067 | 0.0375 | 0.0044 | 0.1051 | 0.0375 | 0.0050 |
| RAVLT | −0.0428 | 0.0116 | 0.0002 | −0.0438 | 0.0117 | 0.0002 | −0.0431 | 0.0115 | 0.0002 |
| FAQ | 0.0796 | 0.0143 | 0.0000 | 0.0786 | 0.0142 | 0.0000 | 0.0793 | 0.0142 | 0.0000 |
| MIDTEMP | −1.8635 | 0.3776 | 0.0000 | −1.8751 | 0.3651 | 0.0000 | −1.8924 | 0.3791 | 0.0000 |
| APOE4 | 0.3509 | 0.1149 | 0.0022 | 0.3495 | 0.1144 | 0.0022 | 0.3452 | 0.1140 | 0.0025 |
Analysis results of ADNI study under PO model.
| Factors | Est | Se | p-val | Est | Se | p-val | Est | Se | p-val |
|---|---|---|---|---|---|---|---|---|---|
| CCA | IPW-I | IPW-II | |||||||
| AGE | −0.7184 | 0.2523 | 0.0044 | −0.7091 | 0.2715 | 0.0090 | −0.7010 | 0.2680 | 0.0089 |
| GENDER | −0.1575 | 0.2859 | 0.5818 | −0.1698 | 0.3113 | 0.5854 | −0.1729 | 0.3228 | 0.5923 |
| ADAS11 | −0.0787 | 0.0829 | 0.3428 | −0.0644 | 0.0935 | 0.4911 | −0.0639 | 0.0882 | 0.4691 |
| ADAS13 | 0.1572 | 0.0629 | 0.0125 | 0.1524 | 0.0706 | 0.0309 | 0.1516 | 0.0652 | 0.0201 |
| RAVLT | −0.0562 | 0.0171 | 0.0010 | −0.0535 | 0.0195 | 0.0062 | −0.0531 | 0.0175 | 0.0025 |
| FAQ | 0.1154 | 0.0273 | 0.0000 | 0.1154 | 0.0375 | 0.0021 | 0.1156 | 0.0349 | 0.0009 |
| MIDTEMP | −2.3961 | 0.4800 | 0.0000 | −2.3788 | 0.5486 | 0.0000 | −2.3671 | 0.5682 | 0.0000 |
| APOE4 | 0.4045 | 0.1735 | 0.0197 | 0.4051 | 0.1840 | 0.0277 | 0.3975 | 0.1814 | 0.0284 |
| NN-1 (ω 1 = 0.8) | NN-1 (ω 1 = 0.5) | NN-1 (ω 1 = 0.3) | |||||||
| AGE | −0.3592 | 0.2300 | 0.1278 | −0.3584 | 0.2318 | 0.1220 | −0.3613 | 0.2343 | 0.1231 |
| GENDER | −0.1307 | 0.2661 | 0.6233 | −0.1389 | 0.2658 | 0.6013 | −0.1416 | 0.2674 | 0.5965 |
| ADAS11 | −0.0999 | 0.0739 | 0.1763 | −0.1095 | 0.0737 | 0.1372 | −0.0993 | 0.0732 | 0.1749 |
| ADAS13 | 0.1562 | 0.0561 | 0.0053 | 0.1628 | 0.0557 | 0.0035 | 0.1551 | 0.0556 | 0.0053 |
| RAVLT | −0.0545 | 0.0156 | 0.0005 | −0.0543 | 0.0157 | 0.0005 | −0.0538 | 0.0156 | 0.0006 |
| FAQ | 0.1317 | 0.0246 | 0.0000 | 0.1306 | 0.0246 | 0.0000 | 0.1323 | 0.0246 | 0.0000 |
| MIDTEMP | −2.3375 | 0.4716 | 0.0000 | −2.3995 | 0.4680 | 0.0000 | −2.3872 | 0.4761 | 0.0000 |
| APOE4 | 0.4248 | 0.1577 | 0.0071 | 0.4119 | 0.1572 | 0.0088 | 0.4116 | 0.1580 | 0.0092 |
| NN-5 (ω 1 = 0.8) | NN-5 (ω 1 = 0.5) | NN-5 (ω 1 = 0.3) | |||||||
| AGE | −0.3564 | 0.2334 | 0.1267 | −0.3419 | 0.2311 | 0.1390 | −0.3439 | 0.2313 | 0.1371 |
| GENDER | −0.1353 | 0.2684 | 0.6142 | −0.1166 | 0.2657 | 0.6607 | −0.1230 | 0.2651 | 0.6426 |
| ADAS11 | −0.1022 | 0.0734 | 0.1638 | −0.1040 | 0.0740 | 0.1600 | −0.1034 | 0.0733 | 0.1583 |
| ADAS13 | 0.1591 | 0.0555 | 0.0042 | 0.1582 | 0.0563 | 0.0049 | 0.1586 | 0.0556 | 0.0043 |
| RAVLT | −0.0533 | 0.0157 | 0.0007 | −0.0552 | 0.0157 | 0.0004 | −0.0544 | 0.0157 | 0.0005 |
| FAQ | 0.1311 | 0.0247 | 0.0000 | 0.1298 | 0.0248 | 0.0000 | 0.1319 | 0.0247 | 0.0000 |
| MIDTEMP | −2.3488 | 0.4827 | 0.0000 | −2.3379 | 0.4695 | 0.0000 | −2.3324 | 0.4711 | 0.0000 |
| APOE4 | 0.4183 | 0.1574 | 0.0079 | 0.4164 | 0.1584 | 0.0086 | 0.4121 | 0.1578 | 0.0090 |
| NN-10 (ω 1 = 0.8) | NN-10 (ω 1 = 0.5) | NN-10 (ω 1 = 0.3) | |||||||
| AGE | −0.3722 | 0.2338 | 0.1114 | −0.3501 | 0.2321 | 0.1314 | −0.3487 | 0.2330 | 0.1345 |
| GENDER | −0.1562 | 0.2645 | 0.5549 | −0.1254 | 0.2626 | 0.6329 | −0.1084 | 0.2654 | 0.6828 |
| ADAS11 | −0.1023 | 0.0742 | 0.1681 | −0.1018 | 0.0735 | 0.1661 | −0.1001 | 0.0738 | 0.1747 |
| ADAS13 | 0.1571 | 0.0561 | 0.0051 | 0.1572 | 0.0557 | 0.0048 | 0.1563 | 0.0560 | 0.0052 |
| RAVLT | −0.0545 | 0.0156 | 0.0005 | −0.0550 | 0.0157 | 0.0004 | −0.0554 | 0.0157 | 0.0004 |
| FAQ | 0.1294 | 0.0248 | 0.0000 | 0.1307 | 0.0246 | 0.0000 | 0.1305 | 0.0247 | 0.0000 |
| MIDTEMP | −2.4725 | 0.4715 | 0.0000 | −2.3581 | 0.4710 | 0.0000 | −2.3302 | 0.4774 | 0.0000 |
| APOE4 | 0.4120 | 0.1595 | 0.0098 | 0.4143 | 0.1579 | 0.0087 | 0.4070 | 0.1582 | 0.0101 |
One can see from Tables 5 and 6 that all methods suggested that the factors ADAS13, MIDTEMP, RAVLT, FAQ and APOE4 were significant predictors of the AD conversion. More specifically, it seems that the AD conversion was negatively correlated with MIDTEMP and RAVLT but positively related to ADAS13, FAQ, and APOE4. In addition, all methods also indicated that the factors GENDER and ADAS11 had no significant effects on AD conversion. On the factor AGE, all of the proposed methods suggest that it did not have a significant effect on the AD conversion but both the CCA and IPW approaches overestimated its effect and indicated that it was negatively significantly related to the AD conversion. In other words, contrary to the common belief, they suggest that older subjects had a lower risk of AD conversion. A possible explanation for this is that the resulting estimates are seriously biased. Note that as mentioned above, the results on the factor MIDTEMP, which suffers missing values, are consistent across all methods. This may be because of its extremely significant effects.
As pointed out by a reviewer, our current analysis does not account for death as a competing risk under interval censoring. Since the number of such cases is small, as noted earlier, we believe this limitation is unlikely to affect the main conclusions. Nonetheless, it would be valuable to consider this aspect in future work [32].
7 Discussion and concluding remarks
In this paper, we discussed regression analysis of interval-censored failure time data arising from semiparametric transformation models in the presence of missing covariates. For the problem, we proposed a novel nonparametric multiple imputation procedure by integrating multiple imputations with the sieve maximum likelihood estimation. The method makes use of two predictive scores for each individual and then a neighborhood set for imputations. An extensive simulation study was performed and indicates that the proposed approach performs well and can yield better and more efficient estimators than the complete-case analysis and IPW methods in general.
It is noteworthy that the proposed estimation procedure relies solely on simple maximum likelihood regression, rendering it computationally straightforward. This sets it apart from the existing literature on MAR and general interval-censored data, which entails a more intricate formulation [16]. In particular, the approach given in Zhou et al. [16] involves calculating expected values for missing covariates, introducing significant complexity, especially when handling multiple covariates with missing values and requiring the computation of high-dimensional integrals. Despite incorporating multiple imputation steps, the proposed procedure maintains a swift calculation speed, making it easily implementable using existing packages in standard software such as the icenReg package in R [33]. Furthermore, we extended the proportional hazards model utilized in Zhou et al. [16] to a much broader class of semiparametric transformation models.
In the preceding sections, the focus has been on semiparametric transformation models. However, it should be straightforward to generalize the idea to other models such as the additive hazards models and Cox-Aalen models. Also in the above, we have assumed the independent or non-informative interval censoring and sometimes one may face informative censoring [34], 35]. The idea discussed above can be generalized to this latter situation too but may not be straightforward. For example, with informative interval censoring, one usually needs to model or formulate the censoring mechanism.
Another important assumption made above is that the missing mechanism is MAR or the missingness depends solely on the observed values. It is apparent that sometimes one may encounter more complex mechanisms where the missingness could be related to both observed and missing values, which is usually referred to as nonignorable missing or missing not at random [36]. It would be useful to generalize the proposed method to such situations.
Acknowledgement
The authors want to thank Prof. Olivier Bouaziz, the Associate Editor and two anonymous referees for their many insightful comments and suggestions that greatly improved the paper.
-
Research ethics: Not applicable.
-
Informed consent: Not applicable.
-
Author contributions: The authors have accepted responsibility for the entire content of this manuscript and approved its submission.
-
Use of Large Language Models, AI and Machine Learning Tools: None declared.
-
Conflict of interest: The authors state no conflict of interest.
-
Research funding: None declared.
-
Data availability: Not applicable.
Appendix A: Imputation algorithm for situations of q > 1
In this Appendix, we extend the algorithm given in Section 4 for the situation of q = 1 to the case of q > 1. For simplicity, we focus on the case of q = 2 and the case with larger q can be generalized similarly. First, let
Similar to the definition in Section 4, with
The detailed multiple imputation procedures are outlined as follows.
[Step 1] Bootstrap Sampling.
Obtain a bootstrap sample
[Step 2] Self-Consistency Algorithm.
Apply Turnbull’s self-consistency algorithm to B (s) to obtain
Perform the same procedure on O to obtain
[Step 3] Model Fitting.
Fit models H 1,(1)(⋅) and H 1,(2)(⋅), as well as H 2,(1)(⋅) and H 2,(2)(⋅) using
Calculate the initial predictive scores
Standardize the scores by subtracting the sample mean and dividing by the standard deviation, resulting in standardized scores
[Step 4] Impute Missing Values for X 1.
For each missing value X 1,k associated with individual O k in O, apply the estimated working models
Standardize these scores by subtracting the sample mean of the bootstrap predictive scores and dividing by the standard deviation of the bootstrap predictive scores, resulting in standardized scores
Use the pre-specified ω 1 to calculate the distance D k,(1) = {D(k, [1]), …, D(k, [n (s)])} between O k and the individuals in
Define a neighborhood set consisting of nearest neighbor (NN) subjects from B (s) by sorting distances in ascending order. Then, randomly draw a pseudo observation value for X 1,k from the observed values of
[Step 5] Impute Missing Values for X 2.
For each missing value X 2,c associated with individual O c in O, apply the estimated working models
Standardize these scores by subtracting the sample mean of the bootstrap predictive scores and dividing by the standard deviation of the bootstrap predictive scores, resulting in standardized scores
Use the pre-specified ω 1 to calculate the distance D c,(2) between O c and the individuals in
Define the neighborhood set from B (s), and randomly draw a pseudo observation value for X 2,c from the observed values of
[Step 6] Final Estimation.
After completing the imputation for all missing covariates, proceed with the sieve maximum likelihood procedure using the log-likelihood function to obtain the final estimator
The entire imputation procedure will be repeated K times, generating K multiple imputed data sets. The overall estimates and their variances will be obtained by applying Rubin’s combination rule, similar to the method described in Section 4.
Appendix B: Additional details about numerical studies
We also consider a scenario with q > 2. In this case, we maintain
Z
as previously defined, while letting
Simulation results under q > 1.
| Parameters | Bias | SD | ESE | CP | Bias | SD | ESE | CP |
|---|---|---|---|---|---|---|---|---|
| FULL | CCA | |||||||
| α 1 = 0.8 | 0.0173 | 0.1583 | 0.1515 | 0.948 | −0.0528 | 0.2286 | 0.2167 | 0.930 |
| α 2 = −0.8 | −0.0132 | 0.2943 | 0.2909 | 0.952 | 0.0705 | 0.4378 | 0.4212 | 0.940 |
| β 1 = 0.5 | 0.0036 | 0.2710 | 0.2738 | 0.948 | −0.0252 | 0.4107 | 0.3916 | 0.929 |
| β 2 = −0.6 | −0.0063 | 0.3158 | 0.3103 | 0.946 | −0.1939 | 0.4572 | 0.4492 | 0.942 |
| IPW-I | IPW-II | |||||||
| α 1 = 0.8 | 0.0373 | 0.2694 | 0.2827 | 0.963 | −0.0526 | 0.2355 | 0.2492 | 0.943 |
| α 2 = −0.8 | −0.0201 | 0.5242 | 0.5476 | 0.951 | 0.0639 | 0.4482 | 0.4806 | 0.967 |
| β 1 = 0.5 | 0.0422 | 0.4944 | 0.5147 | 0.958 | −0.0288 | 0.4196 | 0.4361 | 0.951 |
| β 2 = −0.6 | −0.1190 | 0.5607 | 0.5766 | 0.951 | −0.2008 | 0.4773 | 0.5102 | 0.958 |
| NN-1 | NN-3 | |||||||
| α 1 = 0.8 | 0.0006 | 0.1960 | 0.1978 | 0.949 | −0.0020 | 0.1921 | 0.1952 | 0.954 |
| α 2 = −0.8 | 0.0564 | 0.4077 | 0.4867 | 0.972 | 0.0522 | 0.4030 | 0.4604 | 0.964 |
| β 1 = 0.5 | −0.0064 | 0.2876 | 0.2959 | 0.954 | −0.0049 | 0.2860 | 0.2940 | 0.960 |
| β 2 = −0.6 | 0.0206 | 0.3556 | 0.3541 | 0.949 | 0.0301 | 0.3486 | 0.3505 | 0.949 |
| NN-5 | NN-10 | |||||||
| α 1 = 0.8 | −0.0046 | 0.1918 | 0.1934 | 0.952 | −0.0146 | 0.1905 | 0.1914 | 0.955 |
| α 2 = −0.8 | 0.0579 | 0.4000 | 0.4469 | 0.955 | 0.0620 | 0.3960 | 0.4302 | 0.955 |
| β 1 = 0.5 | −0.0070 | 0.2861 | 0.2927 | 0.958 | −0.0089 | 0.2836 | 0.2904 | 0.954 |
| β 2 = −0.6 | 0.0378 | 0.3464 | 0.3476 | 0.946 | 0.0594 | 0.3423 | 0.3423 | 0.944 |
References
1. Sun, J. The statistical analysis of interval-censored failure time data. New York: Springer; 2006.Search in Google Scholar
2. Sun, J, Chen, D. Emerging topics in modeling interval-censored survival data. Switzerland: Springer Nature; 2022.10.1007/978-3-031-12366-5Search in Google Scholar
3. Kalbfleisch, JD, Prentice, RL. The statistical analysis of failure time data. Hoboken: John Wiley & Sons; 2011.Search in Google Scholar
4. Fine, J, Ying, Z, Wei, L. On the linear transformation model for censored data. Biometrika 1998;85:980–6.10.1093/biomet/85.4.980Search in Google Scholar
5. Chen, K, Jin, Z, Ying, Z. Semiparametric analysis of transformation models with censored data. Biometrika 2002;89:659–68. https://doi.org/10.1093/biomet/89.3.659.Search in Google Scholar
6. Zhang, Z, Zhao, Y. Empirical likelihood for linear transformation models with interval-censored failure time data. J Multivariate Anal 2013;116:398–409. https://doi.org/10.1016/j.jmva.2013.01.003.Search in Google Scholar
7. Zeng, D, Mao, L, Lin, D. Maximum likelihood estimation for semiparametric transformation models with interval-censored data. Biometrika 2016;103:253–71. https://doi.org/10.1093/biomet/asw013.Search in Google Scholar PubMed PubMed Central
8. Zhou, Q, Hu, T, Sun, J. A sieve semiparametric maximum likelihood approach for regression analysis of bivariate interval-censored failure time data. J Am Stat Assoc 2017;112:664–72. https://doi.org/10.1080/01621459.2016.1158113.Search in Google Scholar
9. Weiner, MW, Veitch, DP, Aisen, PS, Beckett, LA, Cairns, NJ, Green, RC, et al.. The alzheimer’s disease neuroimaging initiative: a review of papers published since its inception. Alzheim Dement 2013;9:e111–e1 https://doi.org/10.1016/j.jalz.2013.05.1769.Search in Google Scholar PubMed PubMed Central
10. Weiner, MW, Veitch, DP, Aisen, PS, Beckett, LA, Cairns, NJ, Cedarbaum, J, et al.. Impact of the alzheimer’s disease neuroimaging initiative, 2004 to 2014. Alzheim Dement 2015;11:865–84. https://doi.org/10.1016/j.jalz.2015.04.005.Search in Google Scholar PubMed PubMed Central
11. Little, A, Rubin, DB. Statistical analysis with missing data. New York: Wiley; 2002.10.1002/9781119013563Search in Google Scholar
12. Hsu, C-H, Yu, M. Cox regression analysis with missing covariates via nonparametric multiple imputation. Stat Methods Med Res 2019;28:1676–88. https://doi.org/10.1177/0962280218772592.Search in Google Scholar PubMed PubMed Central
13. Lou, Y, Ma, Y, Du, M. A new and unified method for regression analysis of interval-censored failure time data under semiparametric transformation models with missing covariates. Stat Med 2024a;43:2062–82. https://doi.org/10.1002/sim.10035.Search in Google Scholar PubMed
14. Wen, C-C, Lin, C-T. Analysis of current status data with missing covariates. Biometrics 2011;67:760–9. https://doi.org/10.1111/j.1541-0420.2010.01505.x.Search in Google Scholar PubMed
15. Li, H, Zhang, H, Zhu, L, Li, N, Sun, J. Estimation of the additive hazards model with interval-censored data and missing covariates. Can J Stat 2020a;48:499–517. https://doi.org/10.1002/cjs.11544.Search in Google Scholar
16. Zhou, R, Li, H, Sun, J, Tang, N. A new approach to estimation of the proportional hazards model based on interval-censored data with missing covariates. Lifetime Data Anal 2022;28:335–55. https://doi.org/10.1007/s10985-022-09550-y.Search in Google Scholar PubMed
17. Long, Q, Hsu, C-H, Li, Y. Doubly robust nonparametric multiple imputation for ignorable missing data. Stat Sin 2012;22:149. https://doi.org/10.5705/ss.2010.069.Search in Google Scholar
18. Turnbull, BW. The empirical distribution function with arbitrarily grouped, censored and truncated data. J Roy Stat Soc B 1976;38:290–5. https://doi.org/10.1111/j.2517-6161.1976.tb01597.x.Search in Google Scholar
19. Rubin, DB. Inference and missing data. Biometrika 1976;63:581–92. https://doi.org/10.2307/2335739.Search in Google Scholar
20. Little, RJ, Rubin, DB. Statistical analysis with missing data. Hoboken: John Wiley & Sons; 2019.10.1002/9781119482260Search in Google Scholar
21. Allison, P. Missing data. Thousand Oaks, CA: Sage; 2001.Search in Google Scholar
22. Du, M, Lou, Y, Sun, J. Estimation and variable selection for interval-censored failure time data with random change point and application to breast cancer study. J Am Stat Assoc 2025:1–12. https://doi.org/10.1080/01621459.2024.2441522.Search in Google Scholar
23. White, IR, Royston, P. Imputing missing covariate values for the cox model. Stat Med 2009;28:1982–98. https://doi.org/10.1002/sim.3618.Search in Google Scholar PubMed PubMed Central
24. Heitjan, D F, Little, R J. Multiple imputation for the fatal accident reporting system. J Roy Stat Soc Series C Appl Stat 1991;40:13–29. https://doi.org/10.2307/2347902.Search in Google Scholar
25. Lou, Y, Ma, Y, Xiang, L, Sun, J. A multiple imputation approach for flexible modelling of interval-censored data with missing and censored covariates. Comput Stat Data Anal 2025:108177. https://doi.org/10.1016/j.csda.2025.108177.Search in Google Scholar
26. Nielsen, SF. Proper and improper multiple imputation. Int Stat Rev 2003;71:593–607. https://doi.org/10.1111/j.1751-5823.2003.tb00214.x.Search in Google Scholar
27. Rubin, D B. Multiple imputation for nonresponse in surveys. New York: John Wiley & Sons; 1987.10.1002/9780470316696Search in Google Scholar
28. Huang, J, Rossini, A. Sieve estimation for the proportional-odds failure-time regression model with interval censoring. J Am Stat Assoc 1997;92:960–7. https://doi.org/10.2307/2965559.Search in Google Scholar
29. Chen, D-GD, Sun, J, Peace, KE. Interval-censored time-to-event data: methods and applications. Boca Raton: CRC Press; 2012.10.1201/b12290Search in Google Scholar
30. Li, K, Chan, W, Doody, RS, Quinn, J, Luo, S, Initiative, ADN, et al.. Prediction of conversion to alzheimer’s disease with longitudinal measures and time-to-event data. J Alzheim Dis 2017;58:361–71. https://doi.org/10.3233/jad-161201.Search in Google Scholar
31. Li, S, Wu, Q, Sun, J. Penalized estimation of semiparametric transformation models with interval-censored data and application to alzheimer’s disease. Stat Methods Med Res 2020b;29:2151–66. https://doi.org/10.1177/0962280219884720.Search in Google Scholar PubMed
32. Leffondré, K, Touraine, C, Helmer, C, Joly, P. Interval-censored time-to-event and competing risk with death: is the illness-death model more accurate than the cox model? Int J Epidemiol 2013;42:1177–86. https://doi.org/10.1093/ije/dyt126.Search in Google Scholar PubMed
33. Anderson-Bergman, C. icenreg: regression models for interval censored data in r. J Stat Software 2017;81:1–23. https://doi.org/10.18637/jss.v081.i12.Search in Google Scholar
34. Du, M, Zhou, Q. Analysis of informatively interval-censored case-cohort studies with application to hiv vaccine trials. Commun Math Stat 2023;13:195–215. https://doi.org/10.1007/s40304-022-00322-6.Search in Google Scholar
35. Lou, Y, Sun, J, Wang, P. Semiparametric cure regression models with informative case k interval-censored failure time data. Stat Sin 2026;36:1–22.10.5705/ss.202022.0343Search in Google Scholar
36. Du, M, Li, H, Sun, J. Regression analysis of censored data with nonignorable missing covariates and application to alzheimer disease. Comput Stat Data Anal 2021;157:107157. https://doi.org/10.1016/j.csda.2020.107157.Search in Google Scholar
Supplementary Material
This article contains supplementary material (https://doi.org/10.1515/ijb-2024-0016).
© 2025 Walter de Gruyter GmbH, Berlin/Boston
Articles in the same Issue
- Frontmatter
- Research Article
- The gROC curve and the optimal classification
- Review
- Leveraging external information by guided adaptive shrinkage to improve variable selection in high-dimensional regression settings
- Research Articles
- Enhanced doubly robust estimate with semiparametric models for causal inference of survival outcome
- Two-sample empirical likelihood method for right censored data
- Regression analysis of interval-censored failure time data under semiparametric transformation models with missing covariates
- Efficiency for evaluation of disease etiologic heterogeneity in case-case and case-control studies
- Inference on overlap index: with an application to cancer data
- Copula-based Cox models for dependent current status data with a cure fraction
- Early completion based on adjacent dose information for model-assisted designs to accelerate maximum tolerated dose finding
- An enhanced approximate Bayesian computation method for stage-structured development models
- Bayesian competing risks survival modeling for assessing the cause of death of patients with heart failure
- Forecasting mortality rates in hyponatremia: a statistical approach using Holt-Winters models
Articles in the same Issue
- Frontmatter
- Research Article
- The gROC curve and the optimal classification
- Review
- Leveraging external information by guided adaptive shrinkage to improve variable selection in high-dimensional regression settings
- Research Articles
- Enhanced doubly robust estimate with semiparametric models for causal inference of survival outcome
- Two-sample empirical likelihood method for right censored data
- Regression analysis of interval-censored failure time data under semiparametric transformation models with missing covariates
- Efficiency for evaluation of disease etiologic heterogeneity in case-case and case-control studies
- Inference on overlap index: with an application to cancer data
- Copula-based Cox models for dependent current status data with a cure fraction
- Early completion based on adjacent dose information for model-assisted designs to accelerate maximum tolerated dose finding
- An enhanced approximate Bayesian computation method for stage-structured development models
- Bayesian competing risks survival modeling for assessing the cause of death of patients with heart failure
- Forecasting mortality rates in hyponatremia: a statistical approach using Holt-Winters models