GAMLSS for high-variability data: an application to liver fibrosis case
-
Andrea Marletta

 and
Mariangela Sciandra
and
Mariangela Sciandra

Abstract
This article aims to provide rigorous and convenient statistical models for dealing with high-variability phenomena. The presence of discrepance in variance represents a substantial issue when it is not possible to reduce variability before analysing the data, leading to the possibility to estimate an inadequate model. In this paper, the application of Generalized Additive Model for Location, Scale and Shape (GAMLSS) and the use of finite mixture model for GAMLSS will be proposed as a solution to the problem of overdispersion. An application to Liver fibrosis data is illustrated in order to identify potential risk factors for patients, which could determine the presence of the disease but also its levels of severity.
1 Introduction
In many applicative studies, the average level of certain response variables cannot be controlled unless variability in its measurements is previously reduced. This happens very often in medical studies when the interest lies in determining the presence of some diseases and the relevant level of progression, through the use of some laboratory measurements. Those are characterized by high-variability between observations and no gold standard exists; or, alternatively, when repeated measurements with high-variability are available for the same patient. In both cases, it is essential to know the within-subject variability in order to establish the presence of the disease. Clinicians must understand variability in measurements both qualitatively and quantitatively and endeavour to reduce that variability before trying to use data to establish a patient’s health condition.
In fact, when data exhibit high-variability, any model fit in order to derive an average behaviour of the phenomenon under study will be characterized by “overdispersion” [1]. When it is not possible to eliminate variability before analysing the data, it will result in a substantial discrepancy in variance, which constitutes evidence of an inadequate model fit for the high-frequency variations in the outcome. In this regard, [2], [3] obtained results suggesting that the extent of overdispersion can be reduced, but not necessarily eliminated, by fitting more complex stochastic models that better reflect the nature of the observed extra-variability. In this paper, we propose management of the problem caused by overdispersed data by applying the generalized additive model for location, scale and shape framework (GAMLSS) as introduced by [4]. The idea of using a GAMLSS approach for handling our problem comes from the idea of [5] consisting in the use of an EM maximum likelihood estimation algorithm [6] to deal with overdispersed generalized linear models (GLM). As in the GLM case, the algorithm is initially derived as a form of Gaussian quadrature assuming a normal mixing distribution. The GAMLSS specification allows the extension of the Aitkin algorithm to probability distributions not belonging to the exponential family. In particular, aim of this work is to show the importance of using a GAMLSS strutcure when a mixture is used to provide a natural representation of heterogeneity in a finite number of latent classes [7].
From an applicative point of view, the need for the specification of a GAMLSS able to deal with overdispersed data comes from the analysis of Liver fibrosis data. In the Liver fibrosis data, the response variable is liver stiffness measured as wave speed (expressed in m/s) registered by the Acoustic Radiation Force Impulse (ARFI), while the explanatory variables are divided into two groups: patient-specific explanatory variables (sex, age, size and weight) and explanatory variables relevant to the exam (depth, liver segment, patient position). As Figure 1 shows, wave speed data seem to exhibit overdispersion. In particular, data show a variance increasing with the mean (A) and a non-linear relationship between means and the log transformed variances (B) is observed. In this work, the use of a finite mixture model for GAMLSS will be proposed as a solution to the problem of multimodality in determining the presence of liver diseases and to establish its level of severity.
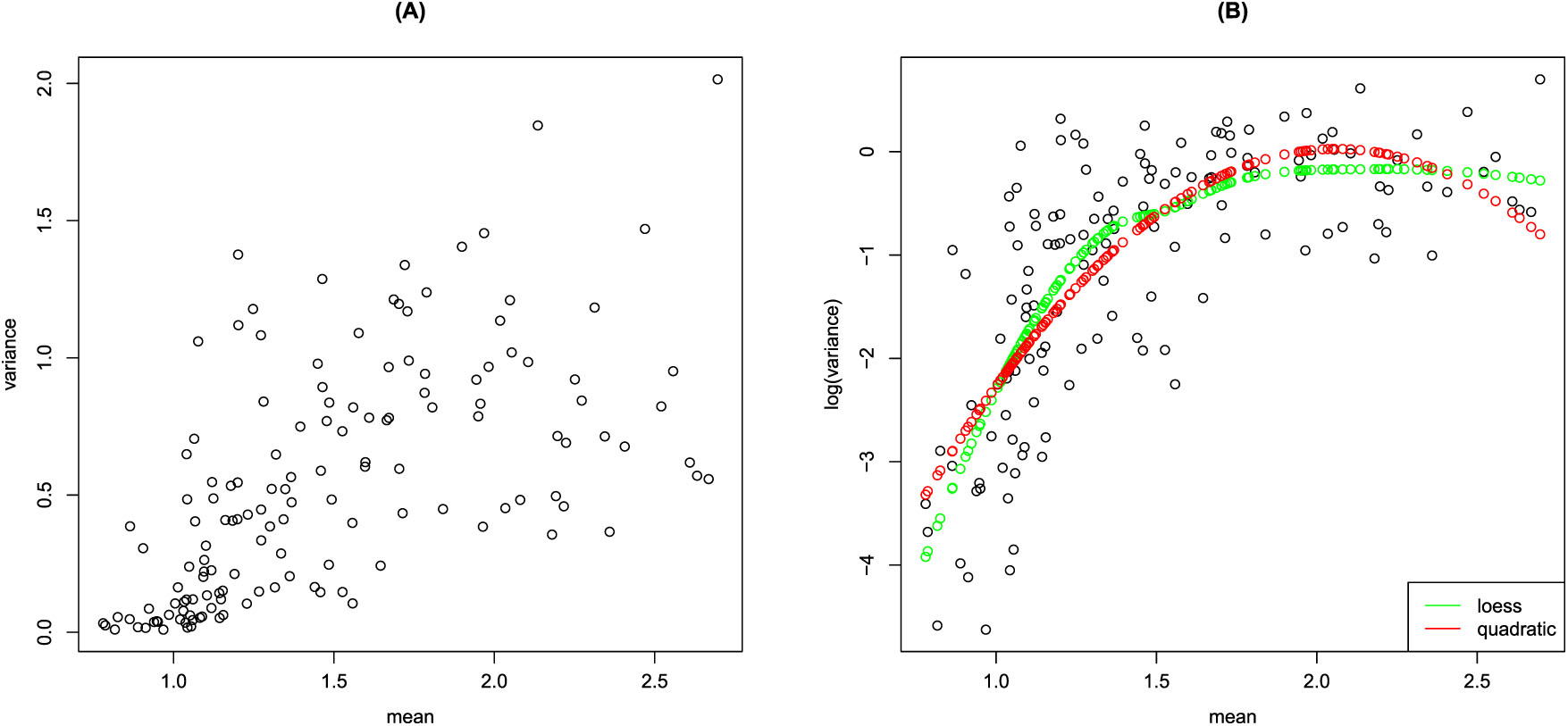
Mean-variance (A) and mean-log(variance) (B) relationships in Liver fibrosis data, in green a fitted curve for loess, in red a fitted curve for quadratic.
The paper is structured as follows: after a brief review of GAMLSS theory (Section 2), an extension of the finite mixture framework to the class of GAMLSS is introduced in Section 3. Section 4 is devoted to an application of the proposed approach to Liver fibrosis data. Some simulation results are reported in Section 5 before presenting our conclusions.
2 GAMLSS modelling: a real application
General Additive Models for Location Scale and Shape were introduced firstly by [8] as a way of overcoming some of the limitations associated with Generalized Linear Models [9] and Generalized Additive Models [10]. They represent a flexible class of models for several reasons. Firstly, they allow the response variable to be selected in a very general family of distributions D including highly skewed and kurtotic continuous and discrete distributions. Moreover, they are a flexible class of models because, once the response distribution has been fixed, all the parameters characterizing the chosen distribution can be modelled by using parametric and/or non-parametric smooth functions of the explanatory variables (i. e. cubic splines, penalized splines, lowess) and/or random effects. Thus, assuming the response variable Y follows a four-parameter distribution
where
Liver fibrosis is one of the 10 most frequent causes of death in the world and consists of excessive accumulation of extracellular matrix proteins, including collagen, which occurs in most types of chronic liver diseases. Advanced liver fibrosis can result in cirrhosis, liver failure, and portal hypertension and often requires liver transplantation [16]. The severity of liver fibrosis can be classified in five stages, based on the Metavir scoring system, from a normal (F0) to a cirrhotic (F4) liver [17]. In medicine, liver biopsy represents the gold standard test for staging liver disease [18]. An alternative diagnostic technique is represented by the Acoustic Radiation Force Impulse (ARFI) [19].
ARFI measures liver stiffness through mechanical excitation of tissue, using acoustic pulses producing shear wave propagation. According to the ARFI principle, the stiffer the tissue, the faster shear waves will propagate. The dataset used in this example consists of ARFI measurements taken in 2013 from 141 patients. As during each elastography, several measurements are gathered, the dataset has a two-step hierarchical structure: a macro “exam level” and a second nested level for the measurements taken during the same exam. The response variable is liver stiffness measured as wave speed (expressed in m/s) registered by ARFI, while the explanatory variables are divided into two groups: patient-specific explanatory variables (sex, age, size and weight) and explanatory variables relevant to the exam (depth, liver segment, patient position).
Since hepatic fibrosis affects the liver patchy, the advantage of obtaining repeated measurements from different parts of liver becomes fundamental. The possibility of obtaining depth data represents the most important innovation of this dataset since data on depth is available for the first time. ARFI allows to measure liver stiffness at different depths starting from 1.5 cm to a maximum of 8 cm. Understanding how wave speed changes when stiffness is measured at different depths represents a very important objective of this study. Moreover, as liver is divided into segments, a four-level (Segment = 5, 6, 7, 8) factor variable has been included in the dataset. Some studies in the literature show how the position of a patient during the examination affects the value of wave speed measured by ARFI [20], [21]. Liver fibrosis data also include information about patient positions: supine (ant), lateral (lat) and prone (pos).
The complexity of the dataset, together with the overdispersion already shown in Figure 1, has led us to consider not only modelling of the location parameter but also use of GAMLSS object in order to provide a structure to the other parameters characterizing the assumed response variable distribution. Among the more than 80 distributions implemented in GAMLSS, we have to search for a continuous and positive skewed distribution in R+ taking kurtosis also into account. Six probability distributions have been selected, and a null model has been fitted for the reduced dataset. In particular, we fitted the following probability distributions: IG (Inverse Gaussian) [22]; BCCG (Box–Cox Cole and Green) [12]; BCPE (Box-Cox Power Exponential) [23]; BCT (Box–Cox generalized t) [11]; GB2 (Generalized Beta 2) [24]; ex-GAUS (exponentially modified Gaussian (EMG) distribution) [25]. The choice of a suitable distribution for the ARFI speed variable relapsed on the Box–Cox Power Exponential (BCPE) distribution. It was introduced by [23] in order to model both skewness and kurtosis in the distribution of a continuous response variable Y.
Once the response variable distribution has been properly specified, the GAMLSS model is selected by comparing various competing models in which different combinations of the components of the model are used. Thus, for example, a set G of link functions
The model with the smallest GAIC value will be selected. Several GAMLSS models have been fitted to Liver fibrosis data. A grid of penalty values p has been checked, and the respective number of explanatory variables included in the model for each parameter (
Number of linear predictor terms included in the fitted GAMLSS for different penalty values p.
| p | μ | σ | ν | τ |
|---|---|---|---|---|
| 2 (AIC) | 7 | 6 | 4 | 5 |
| 3– 4 | 4 | 6 | 2 | 3 |
| 5–6 | 3 | 5 | 2 | 2 |
| 7 | 3 | 5 | 1 | 2 |
| log(n) = 8.32 | 3 | 4 | 1 | 1 |
Once the value p for the penalty has been selected, we tried to use a modified version of BCPE distribution using a log link function for parameter µ of the model. Finally, in order to account for the correlation between observations measured on the same patient, a random effect component for the patient grouping factor was included. The selected final model is shown below:
where
Results from the best fitting GAMLSS for the response variable wave speed: standard error of the estimates in brackets. Significance codes: “***” <0.001; “**” (0.0001–0.01); “*” (0.01–0.05); “.” (0.05–0.1).
|
|
Estimate | p-value |
|---|---|---|
|
|
0.069 (0.020) | 0.0004* |
| Depth | −0.046 (0.003) | <2e-16*** |
| Age | 0.008 (0.001) | <2e-16*** |
| seg6 | −0.019 (0.012) | 0.1119 |
| seg7 | −0.126 (0.010) | <2e-16*** |
| seg8 | 0.075 (0.033) | 0.0256* |
|
|
Estimate | p-value |
|
|
−0.439 (0.232) | 0.0588 |
| Age | 0.007 (0.001) | 6.49e-14*** |
| weight | 0.008 (0.001) | <2e-16*** |
| Size | −0.920 (0.139) | 4.47e-11*** |
| positlat | −0.025 (0.026) | 0.3321 |
| positpos | 0.108 (0.029) | 0.0002*** |
| ν | Estimate | p-value |
|
|
−2.474 (0.140) | <2e-16*** |
| Age | 0.031 (0.002) | <2e-16*** |
|
|
Estimate | p-value |
|
|
−0.761 (0.107) | 1.93e-12*** |
| Age | 0.024 (0.001) | <2e-16*** |
Age seems to be the most important predictor for wave speed since it enters each equation of the selected model. Its estimated value is positive for all the equations. On the contrary, depth has a negative effect on wave speed; in particular, a unitary increase in depth produces, on average, a 5% decrease (
3 Mixture models in GAMLSS
When conducting any statistical analysis, it is important to evaluate how well the model fits the data and whether the data meet the assumptions of the model. There are numerous ways to do this and a variety of statistical tests to evaluate deviations from model assumptions. Generally, once a model is fitted, the overall adequacy of the selected model is assessed through the analysis of residuals by using both diagnostic plots and tests. Within the framework of GAMLSS, the analysis of residuals is based on the use of randomized quantile residuals. This class of residuals has been introduced by [28] for regression models with independent responses. They are defined as the standard normal quantiles corresponding to the inverse of the fitted distribution function evaluated for each response value. In particular, let us assume that
where
In a GAMLSS context, worm plots are largely used to derive hints about the positions where the GAMLSS fit needs to be improved, but also to identify particular features in the data [30], such as overdispersion or multimodality. Liver fibrosis data, from a first descriptive analysis, appear to be characterized by high variability; in particular, the worm plot relevant to the selected model, which is summarized in Equation (2) (Figure 2 (A)) exhibits an M-shape pattern that requires improvement in the specified parametric model. In fact, as extensively discussed in the literature, when inadequately modelled, heterogeneity can lead to underestimation of the standard errors of regression parameters, too narrow confidence intervals and too small p-values [5], [31].
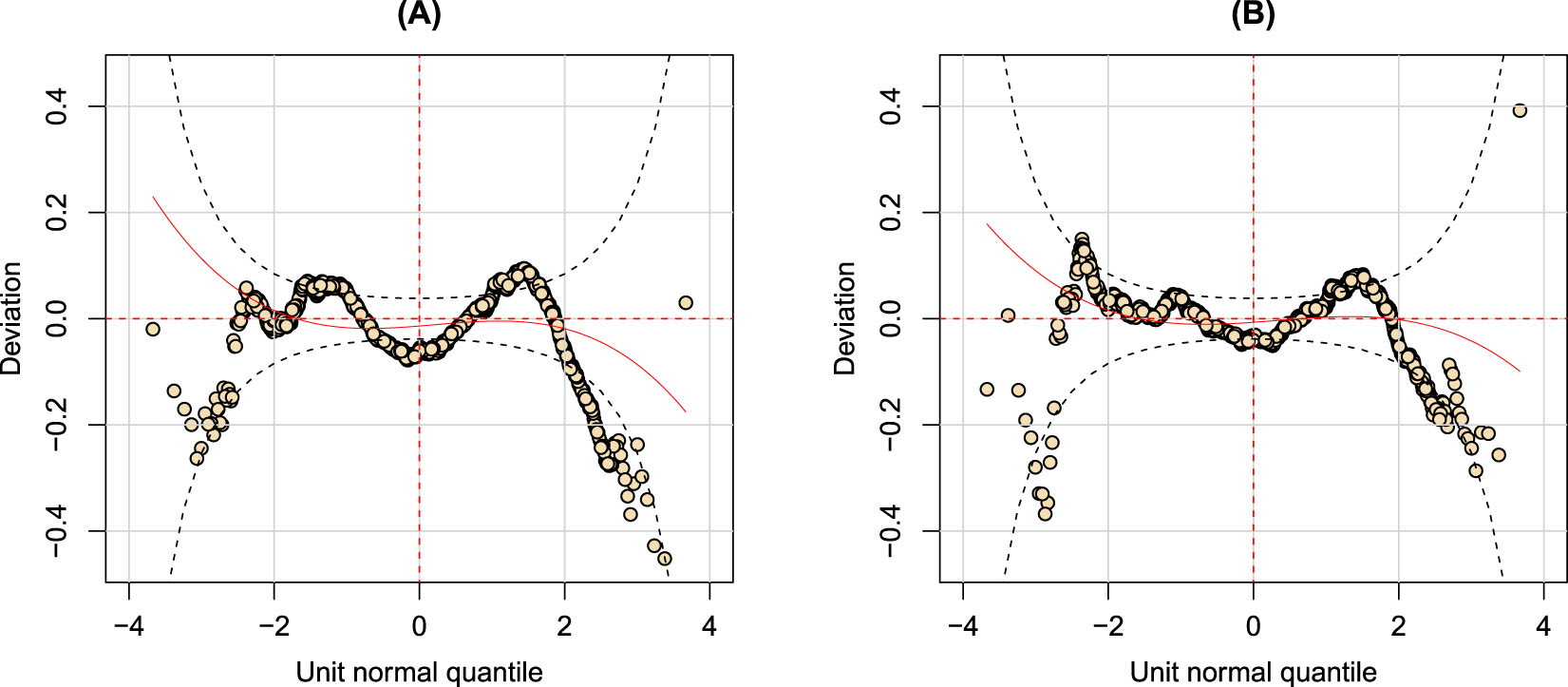
Worm plots for two fitted GAMLSS objects: (A) the worm plot of the BCPEo GAMLSS in Equation (2); (B) the worm plot of the GAMLSS with a finite mixture distribution for the response.
When heterogeneity is due to the presence of subpopulations within an overall population, then a mixture model could be the best solution for representing the probability distribution of observations in the overall population. There is an extensive amount of literature on mixture distributions and their use in modelling data [32], [33], [34], [35]. Yet, the use of mixture distributions for GAMLSS represents a complex and interesting area of research for this class of models.
The aim of this paper is to suggest the use of a mixture approach for GAMLSS when, as in the Liver fibrosis example, data exhibit heterogeneity. The central idea is that the M-shaped pattern in the worm plots could be the result of a spurious appearance of a bimodal distribution. Therefore, the use of a GAMLSS mixture model could be useful for proper identification of the underlying distribution. Thus, as in a standard finite mixture model, let us assume that the response variable Y follows a distribution f that is a mixture of R component distributions
where each component contributes to the total density with weights
This assumption allows the use of different GAMLSS distributions for each conditional distribution component
4 Mixture GAMLSS and Liver fibrosis: results
As already discussed in the previous Section, the comparison between the worm plots obtained by the two properly specified GAMLSS fits seems to confirm the hypothesis about a bimodality in Liver fibrosis data that could justify the observed high variability. From a medical point of view, a possible explanation of this bimodality is that the two components in the mixture could represent two classes of subjects: healthy and cirrhotic patients.
Once the proposed finite mixture GAMLSS has been fitted, it is possible to derive the estimated posterior probabilities pertaining to the two mixture components for each statistical unit. If the fitted model works well, a correspondence between the estimated probabilities of belonging to a specific sub-population and the objective classification represented by the Metavir score is desired. In order to assess the aforementioned relationship, a graphical representation of the estimated probabilities versus the observed values of speed can be useful. According to the Metavir classification, liver fibrosis is divided into five stages, from F0 to F4, on the basis of the presence of connective tissue in the liver. For simplicity purposes, a three-group classification is used here, as proposed in [20]: F0–F1 (normal liver), F2–F3 (mild fibrosis) and F4 (cirrhosis). The pattern of the scatter plot (Figure 3) suggests a three-category classification for the estimated probabilities, with thresholds derived by visual inspection. By crossing both the categorized variables, a 9-sectors grid is obtained and it is noted that measurements fall within certain specific sectors only. Therefore, this result confirms the hypothesis of a direct relationship between the posterior probabilities and the Metavir staging system, and emphasizes the advantage of using a mixture GAMLSS model for this type of data. In particular, speed values in the category
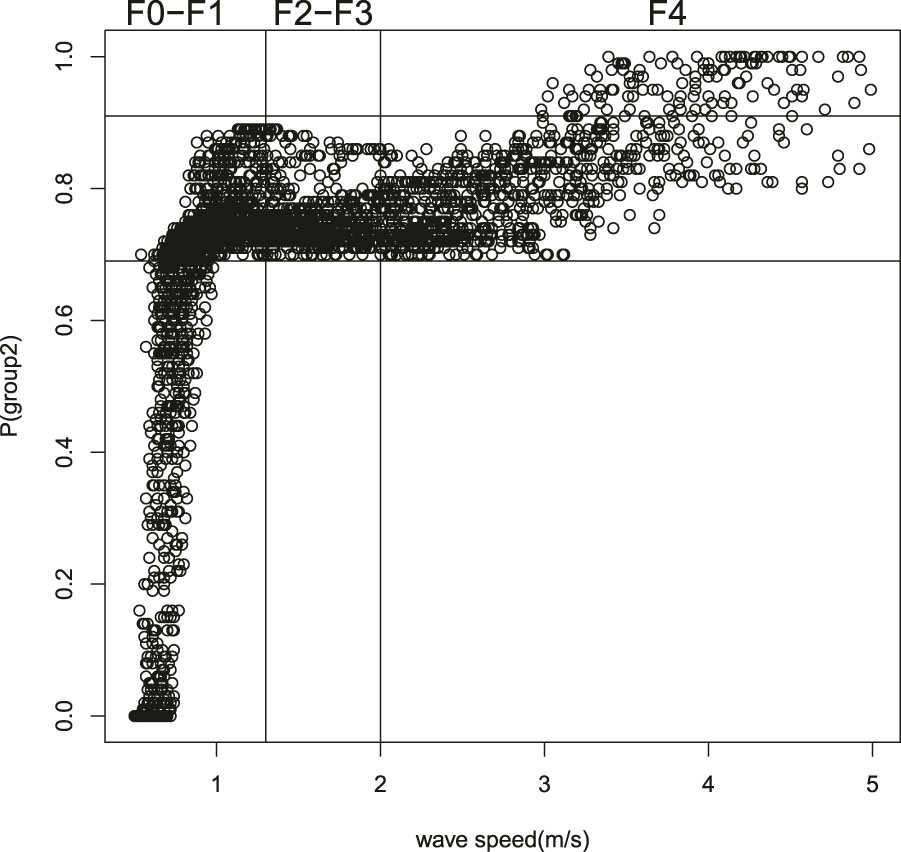
Metavir Stage speed versus mixture posterior probability.
Cross classified Metavir scores (M) and estimated probabilities (p).
| P\M | F0–F1 | F2–F3 | F4 |
|---|---|---|---|
| 0–69% | 531 | 0 | 0 |
| 69–91% | 1730 | 807 | 827 |
| 91–100% | 0 | 0 | 121 |
From a medical point of view, this represents an important result because the use of mixture GAMLSS allows to take into account variability in measurements and to derive the disease severity stage through the use of important explanatory variables. Since until now only risk factors have been considered as predictors, it could be also interesting to introduce clinical variables in the dataset. From the existing literature, it is known that laboratory tests play an important role in detecting liver diseases, since anomalous values of alanine transaminase (ALT) and aspartate transaminase (AST) are potential markers of hepatitis. Besides, production of newer serologic markers has been proposed as an aid in determining the degree of liver fibrosis. For this reason, the first clinical variable considered is an indicator variable of anomalous values for the tra ratio index defined as
The selection model procedure previously described has been implemented including clinical variables and coefficient estimates of the final selected model with the corresponding standard errors are displayed in Table 4. The model has a framework similar to the one in Table 2 except for the clinical variables. Both tra and HCV have an effect on the location parameter with positive coefficients. Moreover, Segment effect is no longer included in the model. Predictor terms for the scale parameter are the same in model 2 while tra has a positive effect on the skewness of the response variable.
Results from the best fitting GAMLSS for the response variable wave speed: in round brackets standard error of the estimates. Significance codes: “***” <0.001; “**” (0.001–0.01); “*” (0.01–0.05); “.” (0.05–0.1).
|
|
Estimate | p-value |
|---|---|---|
|
|
0.114 (0.036) | 0.0015** |
| Depth | −0.056 (0.004) | <2e-16*** |
| Age | 0.006 (0.001) | <2e-16*** |
| tra | 0.132 (0.016) | 1.66e-15*** |
| hcv | 0.075 (0.033) | 3.83e-06*** |
|
|
Estimate | p-value |
|
|
−1.145 (0.172) | 3.42e-11*** |
| Age | 0.007 (0.001) | <2e-16*** |
| Weight | 0.008 (0.001) | 1.54e-14*** |
| Size | −0.327 (0.103) | 0.001** |
| positlat | −0.005 (0.018) | 0.8669 |
| positpos | 0.114 (0.021) | 4.14e-08*** |
| ν | Estimate | p-value |
|
|
−1.779 (0.133) | <2e-16*** |
| Age | 0.019 (0.002) | <2e-16*** |
| tra | 0.363 (0.050) | 5.58e-13*** |
|
|
Estimate | p-value |
|
|
−0.513 (0.158) | 0.0012*** |
| Age | 0.031 (0.003) | <2e-16*** |
Nevertheless, the introduction of clinical variables does not solve the problem of overdispersion. An M-shaped pattern is still present in the worm plot as shown in Figure 4 (A). When a finite mixture is assumed for the response variable an improvement in model fit is again evident Figure 4 (B). Randomized quantile residuals take a flatter worm shape and few points fall out of the 95 per cent confidence intervals.
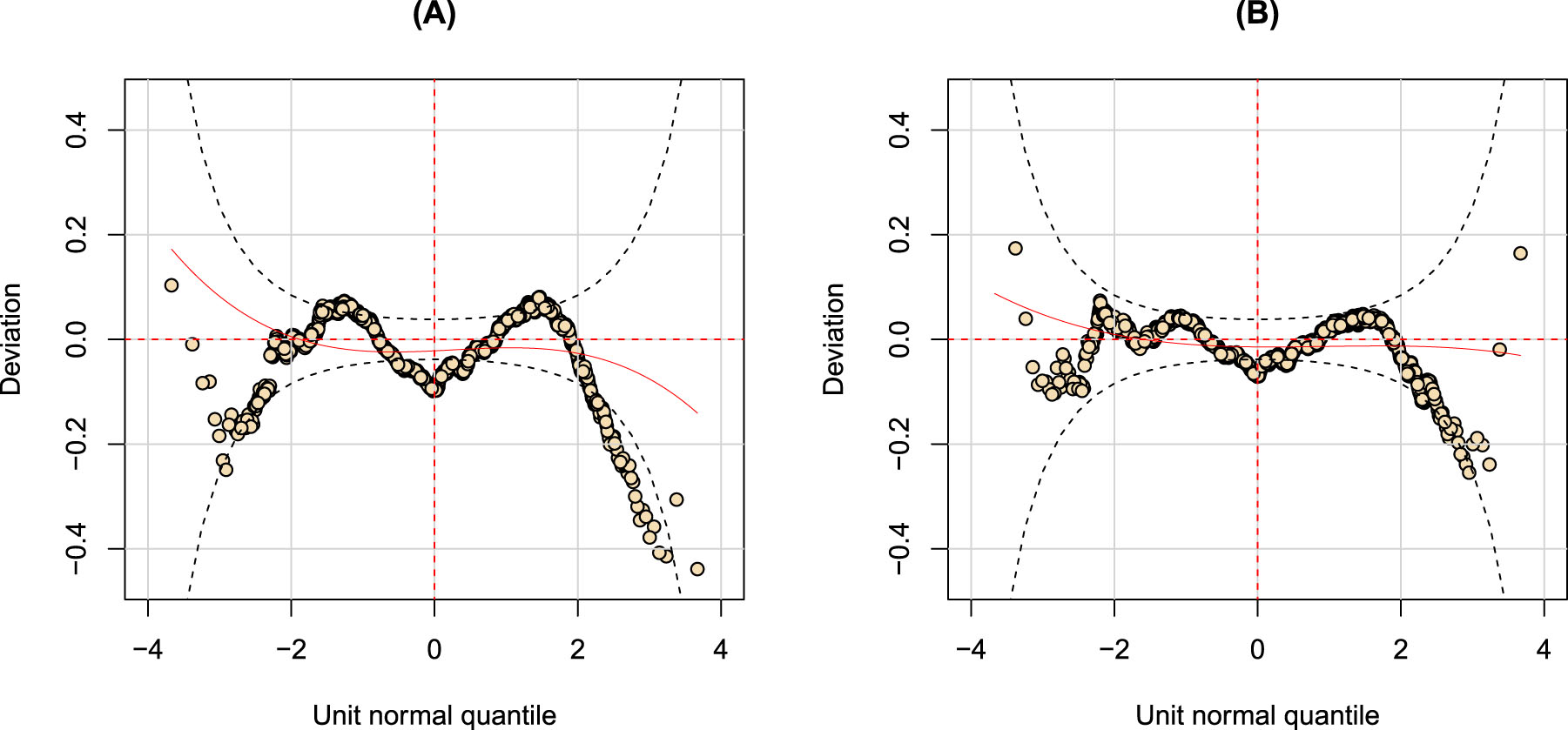
Worm plots for two fitted GAMLSS objects adding clinical variables: (A) the worm plot of the BCPEo GAMLSS in Equation (2); (B) the worm plot of the GAMLSS with a finite mixture distribution for the response.
The conclusions derived from this applicative example show that the processing of data characterized by high-variability cannot be solved by increasing the number of predictor terms in the model. Even the introduction of clinical variables did not help in establishing the severity degree of the disease. Hence, the proposed mixture approach in GAMLSS can be considered the best solution for dealing with overdispersed data.
In Table 5, the estimates of coefficients for the mixture model are presented. It is possible to compare the coefficients tables of the two models: the one in Table 2 and the mixture model one in Table 5. Most of the conclusions derived from the first output are confirmed here. Among predictors, Age is again the most important since it is present in all the equations of the model. Depth has a significant negative effect on Speed. The only liver segment that differs from the baseline (segment 5) is segment 7. As for as
Coefficients for mixture models in GAMLSS: in round brackets standard error of the estimates. Significance codes: “***” <0.001; “**” (0.001–0.01); “*” (0.01–0.05); “.” (0.05–0.1).
|
|
Estimate | p-value |
|---|---|---|
|
|
−0.105 | 1.32e-06*** |
| Depth | −0.046 | <2e-16*** |
| Age | 0.007 | <2e-16*** |
| seg6 | 0.012 | 0.2818 |
| seg7 | −0.044 | 4.29e-07*** |
| seg8 | 0.058 | 0.0529. |
| MASS | 0.276 | <2e-16*** |
|
|
Estimate | p-value |
|
|
−1.444 | <2e-16*** |
| Age | 0.012 | <2e-16*** |
| Weight | 0.005 | <2e-16*** |
| Size | −0.262 | 0.0002*** |
| positlat | −0.016 | 0.2114 |
| positpos | 0.083 | 9.14e-09*** |
| ν | Estimate | p-value |
|
|
−2.246 | <2e-16*** |
| Age | 0.026 | <2e-16*** |
|
|
Estimate | p-value |
|
|
−0.435 | 0.00345*** |
| Age | 0.040 | <2e-16*** |
Besides, comparisons between linear GAMLSS and GAMLSS mixture extension are carried out in two ways. Firstly, a comparison in terms of goodness of fit is achieved using Global Deviances (GD). Secondly, the worm plot is used as diagnostic tool and since, according to our hypotheses, the use of a mixture model gets a more flat worm, the h number of points outside the confidence interval bands, is used as criterion for comparison. We wish for a lower GD and a lower h for the mixture model. Mixture model has a lower GD with
5 Simulation studies
A number of simulations have been run in order to evaluate the goodness of a mixture approach in GAMLSS when the response variable seems to be bimodal. The starting scenario is very similar to the one in Liver fibrosis data.
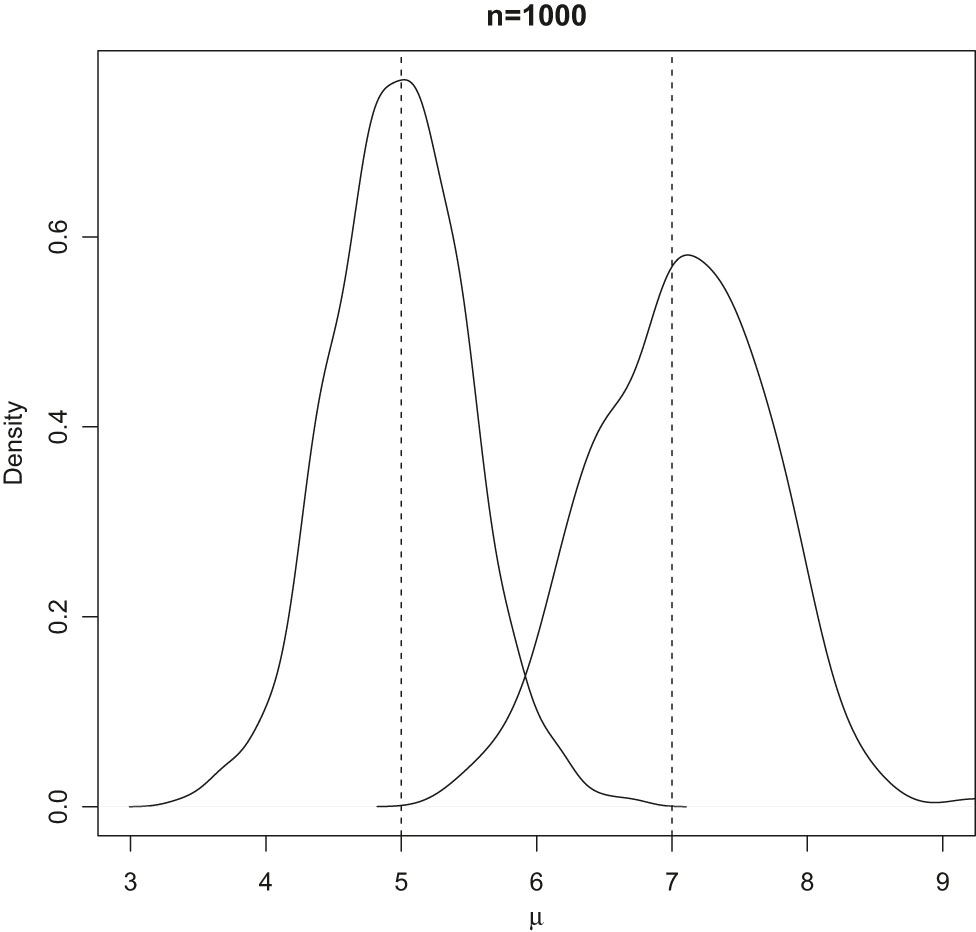
Densities of the two mixture components in Scenario 1.
A GAMLSS involving four parameters (
where
Using the same dataset, a GAMLSS with a finite mixture assumed for the response variable was estimated. Comparisons between standard GAMLSS and the proposed GAMLSS mixture are carried out in two ways. Firstly, a comparison in terms of goodness of fit is achieved using their Global Deviances. Then, worm plots are used as a diagnostic tool. In particular, since according to our hypotheses the use of a mixture model products a flatter worm, the number of points h outside the confidence interval bands is used as a criterion for model comparisons. A lower GD and a lower number of points outside the bandwidths for the mixture model are desirable.
Several scenarios have been simulated by changing a parameter value each time: different mean values for
Table 6 summarizes all possible scenarios and contains, for each of them, both the average difference in Global Deviance between the standard GAMLSS fit and the model assuming the finite mixture (
Simulation scenarios and comparison measures with
|
|
|
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|---|---|
| 1 | 5 | 7 | 0.75 | 0.1 | 1 | 2 | 19.4 | 52 |
| 2 | 5 | 6 | 0.75 | 0.1 | 1 | 2 | −0.2 | −2 |
| 3 | 5 | 8 | 0.75 | 0.1 | 1 | 2 | 62.9 | 47 |
| 4 | 5 | 9 | 0.75 | 0.1 | 1 | 2 | 90.4 | 63 |
| 5 | 5 | 10 | 0.75 | 0.1 | 1 | 2 | 107.9 | 43 |
| 6 | 5 | 7 | 0.75 | 0.25 | 1 | 2 | 2.4 | 1 |
| 7 | 5 | 7 | 0.75 | 0.5 | 1 | 2 | 0.2 | −1 |
| 8 | 5 | 7 | 0.75 | 0.1 | −1 | 2 | 25.3 | 111 |
| 9 | 5 | 7 | 0.75 | 0.1 | 0 | 2 | 27.5 | 104 |
| 10 | 5 | 7 | 0.75 | 0.1 | 1 | 1 | 0 | 0 |
| 11 | 5 | 7 | 0.75 | 0.1 | 1 | 3 | 15.4 | 49 |
| 12 | 5 | 7 | 0.5 | 0.1 | 1 | 2 | 0.1 | −4 |
| 13 | 5 | 7 | 0.9 | 0.1 | 1 | 2 | 2.64 | 2 |
-
In bold, the modified values respect to the baseline situation
Moreover, the table shows that, when the distance between
Similar results are obtained when increasing the number of observations (
Simulation scenarios and comparison measures with
|
|
|
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|---|---|
| 1 | 5 | 7 | 0.75 | 0.1 | 1 | 2 | 41.5 | 152 |
| 2 | 5 | 6 | 0.75 | 0.1 | 1 | 2 | −0.7 | −19 |
| 3 | 5 | 8 | 0.75 | 0.1 | 1 | 2 | 125.2 | 172 |
| 4 | 5 | 9 | 0.75 | 0.1 | 1 | 2 | 176 | 97 |
| 5 | 5 | 10 | 0.75 | 0.1 | 1 | 2 | 217.9 | 97 |
| 6 | 5 | 7 | 0.75 | 0.25 | 1 | 2 | 1 | 0 |
| 7 | 5 | 7 | 0.75 | 0.5 | 1 | 2 | 0.1 | −2 |
| 8 | 5 | 7 | 0.75 | 0.1 | −1 | 2 | 47 | 251 |
| 9 | 5 | 7 | 0.75 | 0.1 | 0 | 2 | 51.3 | 232 |
| 10 | 5 | 7 | 0.75 | 0.1 | 1 | 1 | −0.5 | 10 |
| 11 | 5 | 7 | 0.75 | 0.1 | 1 | 3 | 35.5 | 117 |
| 12 | 5 | 7 | 0.5 | 0.1 | 1 | 2 | −0.4 | −23 |
| 13 | 5 | 7 | 0.9 | 0.1 | 1 | 2 | 2 | 50 |
-
In bold, the modified values respect to the baseline situation
6 Discussion
The GAMLSS modelling procedures described here are useful for several reasons. First, they prove to be convenient statistical models for dealing with high-variability phenomena. Secondly, they provide information about the relationship between predictive factors, clinical variables and disease risk that is not revealed by the use of standard modelling techniques. GAMLSS could be widely applied to medical research, since high variability and overdispersion are frequently recurring situations when clinical data are analysed. For Liver fibrosis data, a linear GAMLSS model points out that wave speed produced by ARFI is influenced by a number of risk factors. In particular, age of patient, depth and segment of the measurements are the most relevant predictors in the study. In Liver fibrosis data, overdispersion appears when randomized quantile residuals are displayed through the use of worm plots. Specifically, an M-shaped pattern arises and the use of a finite mixture approach in GAMLSS appears to be the best solution for detecting this bimodality. Moreover, a graphical tool is introduced where the estimated posterior probabilities are plotted versus a categorization of wave speed; the resulting pattern confirms the hypothesis that the two identified mixture components are related to the clinical status of the statistical unit. A number of simulation studies have been run in order to evaluate the goodness of a mixture approach in GAMLSS considering similar scenarios for the Liver fibrosis data showing that, when mixture components do not overlap totally, there is a clear gain in global goodness of fit.
Concerning future works, the possibility of solving bimodality problems using this method should be verified through similar datasets and additional simulation studies; this might cover, for example simulated data from other probability distributions, different from the BCPE and data where more than two mixture components are considered.
-
Author contribution: All the authors have accepted responsibility for the entire content of this submitted manuscript and approved submission.
-
Research funding: None declared.
-
Conflict of interest statement: The authors declare no conflicts of interest regarding this article.
References
1. Cox, DR. Some remarks on overdispersion. Biometrika 1983;70:269–74. https://doi.org/10.1093/biomet/70.1.269.Search in Google Scholar
2. Kassahun, W, Neyens, T, Faes, C, Molenberghs, G, Verbeke, G. A zero-inflated overdispersed hierarchical poisson model. Statistical Modelling 2014;14:439–56. https://doi.org/10.1177/1471082x14524676.Search in Google Scholar
3. Kassahun, W, Neyens, T, Molenberghs, G, Faes, C, Verbeke, G. A joint model for hierarchical continuous and zero-inflated overdispersed count data. J Stat Comput Sim 2015;85:552–71. https://doi.org/10.1080/00949655.2013.829058.Search in Google Scholar
4. Rigby, RA, Stasinopoulos, DM. Generalized additive models for location, scale and shape. J R Stat Soc Ser C Appl Stat 2005;54:507–54. https://doi.org/10.1111/j.1467-9876.2005.00510.x.Search in Google Scholar
5. Aitkin, M. A general maximum likelihood analysis of overdispersion in generalized linear models. Stat Comput 1996;6:251–62. https://doi.org/10.1007/bf00140869.Search in Google Scholar
6. Dempster, AP, Laird, NM, Rubin, DB. Maximum likelihood from incomplete data via the EM algorithm. J R Stat Soc Ser B 1977; 39:1–38.10.1111/j.2517-6161.1977.tb01600.xSearch in Google Scholar
7. Celeux, G, Diebolt, J. A stochastic approximation type em algorithm for the mixture problem. Stochastics 1992;41:119–34. https://doi.org/10.1080/17442509208833797.Search in Google Scholar
8. Rigby, R, Stasinopoulos, DM. The gamlss project: a flexible approach to statistical modelling. Proceedings of the 16th International Workshop on Statistical Modelling 2001:249–56.Search in Google Scholar
9. Nelder, JA, Wedderburn, RWM. Generalized linear models. J R Stat Soc Ser A 1972;135:370–82. https://doi.org/10.2307/2344614.Search in Google Scholar
10. Hastie, T, Tibshirani, R. Generalized additive models. London: Chapman & Hall; 1990.Search in Google Scholar
11. Rigby, RA, Stasinopoulos, DM. Using the box-cox t distribution in GAMLSS to model skewness and kurtosis. Stat Model 2006;6:209–29. https://doi.org/10.1191/1471082x06st122oa.Search in Google Scholar
12. Cole, TJ, Green, PJ. Smoothing reference centile curves: the LMS method and penalized likelihood. Statistics in Medicine 1992;11:1305–19. https://doi.org/10.1002/sim.4780111005.Search in Google Scholar
13. Rigby, R, Stasinopoulos, D. A semi-parametric additive model for variance heterogeneity. Statistics and Computing 1996a;6:57–65. https://doi.org/10.1007/bf00161574.Search in Google Scholar
14. Rigby, RA, Stasinopoulos, MD. Mean and dispersion additive models. In Statistical theory and computational aspects of smoothing, Springer 1996b:215–30.10.1007/978-3-642-48425-4_16Search in Google Scholar
15. Stasinopoulos, MD, Rigby, RA, Heller, GZ, Voudouris, V, De Bastiani, F. Flexible regression and smoothing: using GAMLSS in R, Chapman and Hall/CRC; 2017.10.1201/b21973Search in Google Scholar
16. Friedman, SL. Liver fibrosis – from bench to bedside. J Hepatol 2003;38:38–53. https://doi.org/10.1016/s0168-8278(02)00429-4.Search in Google Scholar
17. Bedossa, P, Poynard, T. An algorithm for the grading of activity in chronic hepatitis c. Hepatology 1996;24:289–93. https://doi.org/10.1002/hep.510240201.Search in Google Scholar
18. Skelly, MM, James, PD, Ryder, SD. Findings on liver biopsy to investigate abnormal liver function tests in the absence of diagnostic serology. J Hepatol 2001;35:195–9. https://doi.org/10.1016/s0168-8278(01)00094-0.Search in Google Scholar
19. Nightingale, K. Acoustic radiation force impulse (arfi) imaging: a review. Curr Med Imaging Rev 2011;7:328. https://doi.org/10.2174/157340511798038657.Search in Google Scholar
20. Attanasio, M, Enea, M, Rizzo, L. Some issues concerning the statistical evaluation of a screening test: the ARFI ultrasound case. Statistica 2010;70:311–22. https://doi.org/10.6092/issn.1973-2201/3588.Search in Google Scholar
21. Goertz, R, Egger, C, Neurath, M, Strobel, D. Impact of food intake, ultrasound transducer, breathing maneuvers and body position on acoustic radiation force impulse (ARFI) elastometry of the liver. Ultraschall Med 2012;33:380–5. https://doi.org/10.1055/s-0032-1312816.Search in Google Scholar
22. Johnson, NL, Kotz, S, Balakrishnan, N. Continuous univariate distributions. New York: John Wiley & Sons; 1994, vol. 1–2.Search in Google Scholar
23. Rigby, RA, Stasinopoulos, DM. Smooth centile curves for skew and kurtotic data modelled using the box–cox power exponential distribution. Stat Med 2004;23:3053–76. https://doi.org/10.1002/sim.1861.Search in Google Scholar
24. McDonald, JB, YJ Xu. A generalization of the Beta distribution with applications. J Econom 1995;66:133–52. https://doi.org/10.1016/0304-4076(94)01612-4.Search in Google Scholar
25. Grushka, E. Characterization of exponentially modified gaussian peaks in chromatography. Anal Chem 1972;44:1733–8. https://doi.org/10.1021/ac60319a011.Search in Google Scholar
26. Akaike, H. A new look at the statistical model identification. IEEE Trans Autom Control 1974;19:716–23. https://doi.org/10.1109/tac.1974.1100705.Search in Google Scholar
27. Schwarz, G. Estimating the dimension of a model. Ann Stat 1978;6:461–4. https://doi.org/10.1214/aos/1176344136.Search in Google Scholar
28. Dunn, P, Smyth, G. Randomized quantile residuals. J Comput Graph Stat 1996;5:236–44. https://doi.org/10.1080/10618600.1996.10474708.Search in Google Scholar
29. van Buuren, S, Fredriks, M. Worm plot: a simple diagnostic device for modelling growth reference curves. Statistics in Medicine 2001;20:1259–77. https://doi.org/10.1002/sim.746.Search in Google Scholar
30. López, J, Francés, F. Non-stationary flood frequency analysis in continental spanish rivers, using climate and reservoir indices as external covariates. Hydrol Earth Syst Sci 2013;17:3103–42. https://doi.org/10.5194/hess-17-3189-2013.Search in Google Scholar
31. Payne, EH, Hardin, JW, Egede, LE, Ramakrishnan, V, Selassie, A, Gebregziabher, M. Approaches for dealing with various sources of overdispersion in modeling count data: scale adjustment versus modeling. Stat Methods Med Res 2015; 26:1802–23. https://doi.org/10.1177/0962280215588569.Search in Google Scholar
32. Everitt, BS, Hand, DJ. Finite mixture distributions. Monographs on Applied Probability and Statistics. London, New York: Chapman & Hall; 1981.10.1007/978-94-009-5897-5Search in Google Scholar
33. McLachlan, G, Peel, D. Finite mixture models. John Wiley & Sons; 2004.Search in Google Scholar
34. Schlattmann, P. Medical applications of finite mixture models, Springer Science & Business Media; 2009.Search in Google Scholar
35. Titterington, D, Smith, A. Statistical analysis of finite mixture distributions; 1985.Search in Google Scholar
36. Stasinopoulos, D, Rigby, B, Akantziliotou, C. Gamlss: generalized additive models for location scale and shape. R package version, 2–0; 2009.10.32614/CRAN.package.gamlss.addSearch in Google Scholar
© 2020 Andrea Marletta and Mariangela Sciandra, published by De Gruyter, Berlin/Boston
This work is licensed under the Creative Commons Attribution 4.0 International License.
Articles in the same Issue
- Research Articles
- Nonparametric bootstrap inference for the targeted highly adaptive least absolute shrinkage and selection operator (LASSO) estimator
- A Bayesian Framework for Robust Quantitative Trait Locus Mapping and Outlier Detection
- Inference for the Analysis of Ordinal Data with Spatio-Temporal Models
- An iterative algorithm for joint covariate and random effect selection in mixed effects models
- An extended trivariate vine copula mixed model for meta-analysis of diagnostic studies in the presence of non-evaluable outcomes
- Super Learner for Survival Data Prediction
- Model-based random forests for ordinal regression
- A Parametric Bootstrap for the Mean Measure of Divergence
- Derivation of Passing–Bablok regression from Kendall’s tau
- Direct effect and indirect effect on an outcome under nonlinear modeling
- GAMLSS for high-variability data: an application to liver fibrosis case
- Variable selection for high-dimensional quadratic Cox model with application to Alzheimer’s disease
Articles in the same Issue
- Research Articles
- Nonparametric bootstrap inference for the targeted highly adaptive least absolute shrinkage and selection operator (LASSO) estimator
- A Bayesian Framework for Robust Quantitative Trait Locus Mapping and Outlier Detection
- Inference for the Analysis of Ordinal Data with Spatio-Temporal Models
- An iterative algorithm for joint covariate and random effect selection in mixed effects models
- An extended trivariate vine copula mixed model for meta-analysis of diagnostic studies in the presence of non-evaluable outcomes
- Super Learner for Survival Data Prediction
- Model-based random forests for ordinal regression
- A Parametric Bootstrap for the Mean Measure of Divergence
- Derivation of Passing–Bablok regression from Kendall’s tau
- Direct effect and indirect effect on an outcome under nonlinear modeling
- GAMLSS for high-variability data: an application to liver fibrosis case
- Variable selection for high-dimensional quadratic Cox model with application to Alzheimer’s disease