Maximum Likelihood Estimation in a Semicontinuous Survival Model with Covariates Subject to Detection Limits
-
Paul W. Bernhardt


Abstract
Semicontinuous data are common in biological studies, occurring when a variable is continuous over a region but has a point mass at one or more points. In the motivating Genetic and Inflammatory Markers of Sepsis (GenIMS) study, it was of interest to determine how several biomarkers subject to detection limits were related to survival for patients entering the hospital with community acquired pneumonia. While survival times were recorded for all individuals in the study, the primary endpoint of interest was the binary event of 90-day survival, and no patients were lost to follow-up prior to 90 days. In order to use all of the available survival information, we propose a two-part regression model where the probability of surviving to 90 days is modeled using logistic regression and the survival distribution for those experiencing the event prior to this time is modeled with a truncated accelerated failure time model. We assume a series of mixture of normal regression models to model the joint distribution of the censored biomarkers. To estimate the parameters in this model, we suggest a Monte Carlo EM algorithm where multiple imputations are generated for the censored covariates in order to estimate the expectation in the E-step and then weighted maximization is applied to the observed and imputed data in the M-step. We conduct simulations to assess the proposed model and maximization method, and we analyze the GenIMS data set.
1 Introduction
Semicontinuous data are common in medical and biological studies and typically occur when there is a point mass at zero and a continuous, right-skewed distribution over a positive range. Researchers have analyzed this type of data in a variety of applications, including annual medical expenses [1, 2], daily alcohol intake [3], driving scores [4], and health assessment scores [5]. Manning et al. [6], Duan et al. [7], Moulton et al. [8] and Olsen and Schafer [9], among many others, have suggested two-part mixture models for handling both cross-sectional and longitudinal semicontinuous data. In the presence of covariates, the two-part model usually employs logistic regression to model the probability of observing a zero outcome and a continuous regression model to describe the distribution of outcomes above zero.
In the motivating Genetic and Inflammatory Markers of Sepsis (GenIMS) Study, biological measurements were collected on patients admitted to the hospital with community acquired pneumonia (CAP). One of the main purposes of the study was to determine how three cytokine biomarkers are related to survival for patients with CAP. Unlike typical analyses of time-to-event data, the original study investigators were primarily interested in modeling the binary event of surviving at least 90 days [10], based on recommendations by two international expert panels, which suggested that most if not all deaths due to pneumonia and resulting sepsis would have occurred by this time [11, 12]. Alternatively, some recent analyses of the data have directly modeled the available survival times [e.g., [13, 14, 15].
Rather than choosing between a binary and continuous survival outcome, we suggest simultaneously modeling the event of surviving 90 days and the actual survival times for those not surviving to 90 days. In order to frame this problem in a familiar way, we note that for the purposes of the GenIMS study, we may conceptually consider the patients who survived to 90 days as cured from CAP. Though cure rate models have been developed to model long-term survival data [16, 17], a typical cure rate model does not apply for the GenIMS data set since the cure status is known for all individuals and the survival part of the model is truncated. Thus, we instead suggest framing the problem in the context of a semicontinuous regression model, which in this survival modeling context we term a semicontinuous survival model. Unlike in a typical semicontinuous data model, the continuous part of the distribution occurs between zero and 90, while the point mass occurs at 90.
An additional complication with the GenIMS data set is that the biomarker covariates of interest are subject to lower detection limits (DLs). Traditionally, a few common approaches have been taken to handle censoring due to DLs. One approach has been to replace the censored observations using either a function of the DL, such as DL
Several authors have considered more sophisticated approaches to handling DLs in the context of survival data. Langohr et al. [28] and Sattar et al. [15] proposed fully-parametric survival models with an interval-censored predictor while Bernhardt et al. [13] used multiple imputation techniques for accelerated failure time models with left-censored covariates. In the context of semiparametric Cox proportional hazards models with covariates subject to DLs, Lee et al. [29] suggested a partial likelihood approach based on an empirical estimate of the relative risk function using uncensored covariate observations, D’ Angelo and Weissfeld [14] developed an indexing approach where censored covariate values are directly replaced by their conditional expectation given a linear combination of the fully observed covariates, and Chen et al. [30] considered a Bayesian strategy where the censored covariates are modeled parametrically. Recently, [31] suggested using a nonparametric density estimator for a single censored covariate in the context of frailty models.
All of the methods mentioned above for handling covariates subject to DLs in survival models are either statistically naive — such as the DL
In this paper, we propose a straightforward and flexible method for analyzing a semicontinuous survival outcome with covariates subject to DLs, where the interest lies in estimating both the associations of covariates with the survival time for those experiencing the event of interest and the associations of covariates with the probability of surviving to the known “cure time.” We suggest using a truncated accelerated failure time model to model the survival times for those experiencing the event of interest and a logistic regression to model the probability of being cured (surviving to the “cure time”). We propose using a series of mixture of normal regression models to flexibly model the multivariate distribution of the censored covariates, though our modeling strategy allows for a more standard parametric model or even a semiparametric approach. To obtain estimates in this semicontinuous survival model, we develop a Monte Carlo EM algorithm where to estimate the expectation in the E-step, multiple imputations are generated for the censored covariates according to a mixture of normals distribution, and weighted maximum likelihood is applied to the observed and imputed data.
The remainder of the paper is organized as follows. In Section 2, we develop our proposed semicontinuous survival model, including our proposal for the distribution of the covariates. In Section 3, we present a Monte Carlo EM algorithm for obtaining parameter estimates. In Section 4, we summarize the main goals of inference as well as some notes on model checking. In Section 5, we conduct a simulation study comparing our proposed method to naive or less flexible methods. In Section 6, we apply our method to the GenIMS data set. Finally, in Section 7, we briefly review our method and discuss its advantages and shortcomings.
2 Semicontinuous survival model
2.1 Notation
Suppose for each individual,
For the ith individual, we additionally define
We allow the vector of DLs
2.2 Model
The main inferential goals for a semicontinuous survival outcome are three-fold: (a) to determine the relationship between the covariates and the probability of surviving to time c; (b) to determine the relationship between the covariates and the survival time for those individuals not surviving to time c; (c) to determine if there is a statistically significant relationship between the covariates and the semicontinuous survival outcome. In order to address these goals, we first define the semicontinuous survival density
where
where
The observed data likelihood for the proposed semicontinuous model can be written succinctly as
where
For a univariate
where
Mixtures of normal regression models were introduced by Quandt and Ramsey [32] and have been shown to be suitably flexible to represent a wide variety of densities [33]. If desired, to increase flexibility of the mixture distribution (3),
For a multivariate
3 Monte carlo EM algorithm
Unless q is small, eq. (2) may be extremely challenging to maximize directly using algorithms like the Newton-Raphson method, since a potentially high-dimensional integral would need to be evaluated for each individual at each iteration in the maximization procedure. Thus, in order to maximize the likelihood eq. (2), we suggest using an expectation-maximization (EM) algorithm, originally described by [35]. The main advantages of using the EM algorithm for maximization over competing methods are that it is very numerically stable [36] and is convenient in the presence of missing data. Maximization is achieved by iterating between two steps, the E-step and M-step. In the E-step, the expected value of the log-likelihood of the complete data is calculated with respect to the missing data conditional on all of the observed data at a set of current parameter estimates. In the M-step, this expected log-likelihood is maximized to obtain new parameter estimates. In this section, we extend the EM algorithm to handle covariates subject to DLs in the context of a semicontinuous survival model.
Suppose that, without loss of generality, we observe
A closed form expression of eq. (5) is usually not attainable, so we propose a Monte Carlo approach for estimating this integral, originally suggested by Wei and Tanner [37], in the same spirit as Ibrahim [34] for missing data in parametric regression models and May et al. [38] for generalized linear models with covariates subject to censoring. Specifically, we estimate
where
In practice, we use a random walk Metropolis method [39] with truncated Gaussian proposals.
For the M-step of the EM algorithm, we then maximize eq. (5) with the Monte Carlo estimate eq. (6) replacing
a maximization for the part involving the parameters in the distribution of the time-to-event variable for those experiencing an event,
and a maximization for the part involving the parameters in the distribution of the covariates subject to DLs,
The eqs. (7) and (8) can be maximized using standard optimization routines for logistic regression and AFT models, respectively, for a set of
We summarize the steps for the proposed Monte Carlo EM algorithm, with additional details and computational tips based on the statistical software R.
Obtain initial values for estimating the parameters
At the
Repeat steps 2-3 until
where s is the number of elements in
In practice, we recommend letting m, the number of Monte Carlo imputations for
4 Inference and model checking
Recall that the main analysis goals in the semicontinuous survival regression model are to estimate
While estimating
To assess whether the jth covariate is associated with the survival outcome, the hypothesis test of interest is
With the proposed parametric modeling scheme, it is important to choose a good model prior to conducting inference. In practice, we suggest fitting several competing models and comparing them using standard tools for assessing fit such as AIC or BIC. For modeling the binary event of surviving to time c, two popular choices are probit and logistic regression, while for modeling the observed survival times less than c, lognormal, exponential, Weibull, gamma, and generalized gamma models, among others, could be considered. Even if these response models are reasonable, a poor imputation model for the censored covariates could bias inference. While we suggested a flexible mixture of normal regressions approach, alternative distributions could be considered. However, we show in Section 5 that the mixture of normals performs well in a variety of scenarios.
After choosing the best model among those considered, residual analyses or goodness-of-fit tests may be of interest to further confirm that the best model is in fact a reasonable model. However, diagnostics are complicated by the censoring on
5 Simulation study
We conducted simulations to study the performance of our proposed semicontinuous survival model. We set up the simulations to represent a situation similar to that in the GenIMS application described in Section 6, and we compared the proposed method to other practical approaches.
5.1 Single censored covariate: response model known
We generated N = 500 data sets of size n = 200 with a survival response
The values for
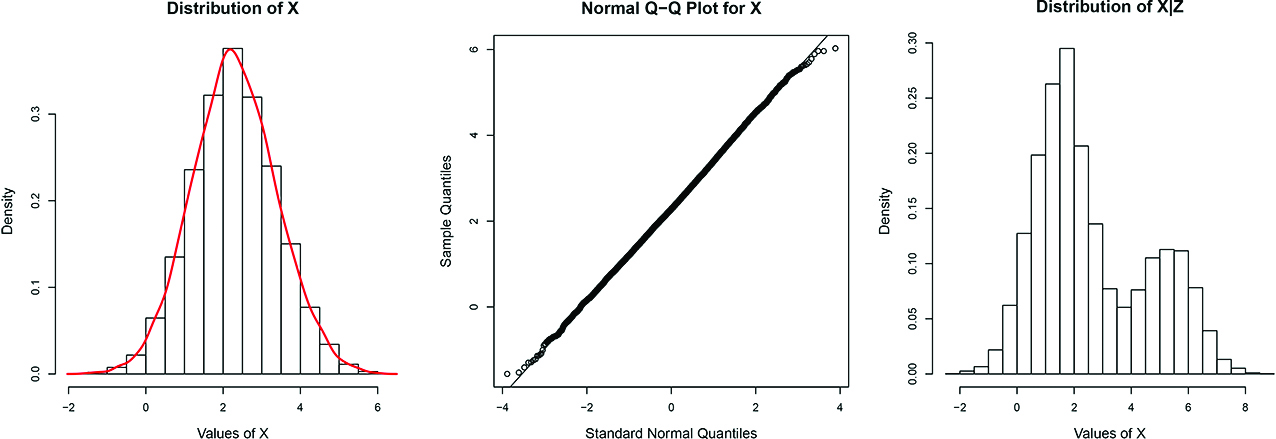
From left to right: (1) Histogram and estimated density for X based on 10,000 randoms samples; (2) Normal q-q plot based on same 10,000 random samples; (3) Histogram for X conditional on a single randomly generated
We generated the log of the survival response as
For the simulations in this section, we assumed that the distributional forms of the semicontinuous survival response were known in order to focus on assessing the proposed Monte Carlo EM estimation approach and the use of a mixture of normals to model the covariate subject to censoring. Specifically, we assumed it was known that a truncated normal AFT model describes the distribution of the log event times for those experiencing an event and a logistic regression describes the probability of never experiencing an event (surviving to 90 days). In Section 5.2, we study simulations for alternative time-to-event and binary regression scenarios.
We considered six data analysis approaches: our proposed semicontinuous survival method using a mixture of two normals for the distribution of
For the MI approach, we used an improper imputation strategy based on fixed parameter estimates to generate imputations from
Single censored covariate: comparison of relative bias and standard deviations (in parenthesis below bias) of estimates for (a) the proposed semicontinuous survival model strategy assuming a mixture of normals distribution for the censored covariate (SS-MN) or a normal distribution for the censored covariate (SS-N); (b) the semicontinuous survival model using multiple imputations based on a normal distribution for the censored covariate (MI); (c) an AFT and logistic regression model replacing censored values with DL
| Cens. | Method | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 20% | Mixture | SS-MN | 0.01 | 0.00 | 0.03 | 0.05 | 0.03 | 0.07 | 0.08 | |||
| (1.13) | (0.19) | (0.01) | (0.43) | (0.01) | (1.13) | (0.17) | (0.02) | (0.50) | (0.01) | |||
| SS-N | 0.00 | 0.01 | 0.00 | 0.04 | 0.07 | 0.03 | 0.07 | 0.08 | ||||
| (1.13) | (0.19) | (0.01) | (0.43) | (0.01) | (1.13) | (0.18) | (0.02) | (0.50) | (0.01) | |||
| MI | 0.00 | 0.01 | 0.00 | 0.04 | 0.07 | 0.03 | 0.07 | 0.08 | ||||
| (1.14) | (0.19) | (0.01) | (0.43) | (0.01) | (1.13) | (0.18) | (0.02) | (0.50) | (0.01) | |||
| DL | 0.01 | 0.01 | 0.00 | 0.05 | 0.08 | 0.02 | 0.06 | 0.07 | ||||
| (1.14) | (0.19) | (0.01) | (0.43) | (0.01) | (1.13) | (0.18) | (0.02) | (0.50) | (0.01) | |||
| CC | 0.00 | 0.00 | 0.02 | 0.05 | 0.03 | 0.09 | 0.07 | |||||
| (1.17) | (0.20) | (0.01) | (0.44) | (0.01) | (1.20) | (0.20) | (0.02) | (0.52) | (0.01) | |||
| Omni | 0.01 | 0.02 | 0.04 | 0.03 | 0.08 | 0.07 | ||||||
| (1.13) | (0.19) | (0.01) | (0.43) | (0.01) | (1.13) | (0.17) | (0.02) | (0.50) | (0.01) | |||
| 40% | Mixture | SS-MN | 0.02 | 0.10 | −0.02 | 0.06 | 0.08 | 0.02 | 0.03 | 0.01 | ||
| (1.39) | (0.13) | (0.02) | (0.50) | (0.01) | (1.19) | (0.15) | (0.02) | (0.51) | (0.02) | |||
| SS-N | 0.08 | 0.03 | 0.25 | 0.14 | 0.47 | |||||||
| (1.39) | (0.13) | (0.02) | (0.50) | (0.01) | (1.21) | (0.12) | (0.02) | (0.52) | (0.02) | |||
| MI | 0.06 | 0.04 | 0.01 | 0.03 | 0.24 | 0.16 | 0.40 | |||||
| (1.42) | (0.14) | (0.02) | (0.50) | (0.01) | (1.31) | (0.15) | (0.02) | (0.60) | (0.02) | |||
| DL | 0.08 | 0.19 | 0.19 | 0.24 | 0.38 | 0.21 | 0.79 | |||||
| (1.44) | (0.15) | (0.02) | (0.52) | (0.02) | (1.17) | (0.15) | (0.02) | (0.48) | (0.02) | |||
| CC | 0.04 | 0.15 | 0.14 | 0.17 | 0.09 | 0.28 | 0.10 | |||||
| (1.74) | (0.21) | (0.02) | (0.59) | (0.02) | (2.17) | (0.31) | (0.03) | (1.76) | (0.03) | |||
| Omni | 0.02 | 0.10 | 0.06 | 0.08 | 0.03 | 0.02 | 0.02 | |||||
| (1.34) | (0.13) | (0.02) | (0.49) | (0.01) | (1.16) | (0.14) | (0.02) | (0.49) | (0.02) | |||
| 40% | Normal | SS-MN | 0.01 | 0.05 | 0.05 | 0.03 | 0.05 | 0.03 | ||||
| (1.17) | (0.16) | (0.01) | (0.46) | (0.01) | (1.02) | (0.15) | (0.01) | (0.41) | (0.01) | |||
| SS-N | 0.00 | 0.05 | 0.05 | 0.04 | 0.05 | 0.05 | ||||||
| (1.17) | (0.16) | (0.01) | (0.46) | (0.01) | (1.01) | (0.15) | (0.01) | (0.41) | (0.01) | |||
| MI | 0.01 | 0.06 | 0.07 | 0.06 | 0.05 | 0.07 | ||||||
| (1.20) | (0.16) | (0.01) | (0.46) | (0.01) | (1.06) | (0.16) | (0.02) | (0.42) | (0.01) | |||
| DL | 0.10 | 0.53 | 0.24 | 0.20 | 0.10 | |||||||
| (1.22) | (0.18) | (0.01) | (0.47) | (0.01) | (0.98) | (0.17) | (0.01) | (0.38) | (0.01) | |||
| CC | 0.01 | 0.00 | 0.11 | 0.10 | 0.09 | 0.09 | 0.09 | |||||
| (1.56) | (0.23) | (0.02) | (0.54) | (0.02) | (1.62) | (0.25) | (0.02) | (0.60) | (0.02) | |||
| Omni | 0.00 | 0.03 | 0.04 | 0.04 | 0.04 | 0.04 | ||||||
| (1.14) | (0.15) | (0.01) | (0.46) | (0.01) | (0.93) | (0.12) | (0.01) | (0.40) | (0.01) | |||
| 40% | LogGam | SS-MN | 0.03 | 0.00 | 0.00 | 0.07 | 0.07 | 0.00 | 0.05 | |||
| (1.18) | (0.24) | (0.02) | (0.46) | (0.02) | (1.02) | (0.20) | (0.02) | (0.37) | (0.01) | |||
| SS-N | 0.07 | 0.06 | 0.07 | 0.10 | 0.17 | 0.08 | 0.18 | |||||
| (1.19) | (0.24) | (0.02) | (0.46) | (0.02) | (1.00) | (0.21) | (0.01) | (0.37) | (0.01) | |||
| MI | 0.07 | 0.06 | 0.07 | 0.11 | 0.17 | 0.07 | 0.16 | |||||
| (1.22) | (0.25) | (0.02) | (0.46) | (0.02) | (1.03) | (0.23) | (0.02) | (0.38) | (0.01) | |||
| DL | 0.02 | 0.42 | 0.17 | 0.11 | 0.13 | |||||||
| (1.21) | (0.24) | (0.02) | (0.46) | (0.01) | (0.97) | (0.20) | (0.01) | (0.35) | (0.01) | |||
| CC | 0.00 | 0.00 | 0.01 | 0.08 | 0.08 | 0.08 | 0.13 | 0.08 | ||||
| (1.56) | (0.34) | (0.02) | (0.55) | (0.02) | (1.68) | (0.38) | (0.02) | (0.56) | (0.02) | |||
| Omni | 0.00 | 0.01 | 0.05 | 0.05 | 0.04 | 0.08 | 0.05 | |||||
| (1.10) | (0.20) | (0.01) | (0.43) | (0.01) | (0.94) | (0.15) | (0.01) | (0.36) | (0.01) | |||
Table 1 displays the relative bias and standard deviation (in parentheses) of the parameter estimates for each of the six analysis methods. The relative bias for a parameter θ is estimated as
where
Relative biases that are statistically significant at the 0.05 level, without multiplicity corrections, are shown in bold. The first two sections in Table 1 give simulation results for two different censoring levels on
Due to the relatively small sample size for the simulations, there are minimal but statistically significant biases for several of the
5.2 Single censored covariate: response model unknown or misspecified
In practice, the underlying distributions of the variables are usually unknown. In this section, we consider several scenarios with a single censored covariate where the parametric models in eq. (1) are unknown. In Section 5.2.1, we explore cases when the true distribution of event times for those experiencing the event is not lognormal. In Section 5.2.2, we consider a case where all of the parametric models are unknown - the AFT model, the binary response model, and the model for the covariates. Various flexible parametric models are assumed and are shown to perform well.
5.2.1 Misspecified AFT model
In the following simulations, we consider cases where the distribution of
We considered seven data analysis approaches, including the six previously described in Section 5.1. The additional approach we considered here assumes a truncated generalized gamma distribution for the time-to-event and a mixture of normal regressions for the distribution of
Single censored covariate, misspecified AFT response model: comparison of relative bias and standard deviations (in parenthesis below bias) of estimates for (a) the proposed semicontinuous survival model strategy assuming a mixture of normals distribution for the censored covariate and a generalized gamma AFT (SS-MN-G); (b) the proposed semicontinuous survival model strategy assuming a mixture of normals distribution for the censored covariate (SS-MN-N) or a normal distribution for the censored covariate (SS-N) and a lognormal AFT; (c) the semicontinuous survival model using multiple imputations based on a normal distribution for the censored covariate and a lognormal AFT (MI); (c) a lognormal AFT and logistic regression model replacing censored values with DL
| Method | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| GenGam | SS-MN-G | 0.03 | 0.00 | 0.09 | 0.11 | 0.06 | 0.07 | 0.08 | |||
| (0.48) | (0.05) | (0.01) | (0.14) | (0.01) | (1.19) | (0.16) | (0.02) | (0.51) | (0.02) | ||
| SS-MN-N | 0.03 | 0.03 | 0.09 | 0.11 | 0.05 | 0.06 | 0.03 | ||||
| (0.78) | (0.09) | (0.01) | (0.29) | (0.01) | (1.19) | (0.17) | (0.02) | (0.52) | (0.02) | ||
| SS-N | 0.00 | 0.02 | 0.00 | 0.02 | 0.02 | 0.22 | 0.14 | 0.38 | |||
| (0.78) | (0.09) | (0.01) | (0.29) | (0.01) | (1.18) | (0.13) | (0.02) | (0.52) | (0.02) | ||
| MI | 0.01 | 0.02 | 0.00 | 0.04 | 0.04 | 0.20 | 0.14 | 0.29 | |||
| (0.79) | (0.10) | (0.01) | (0.29) | (0.01) | (1.25) | (0.16) | (0.02) | (0.55) | (0.02) | ||
| DL | 0.10 | 0.03 | 0.12 | 0.17 | 0.22 | 0.34 | 0.21 | 0.73 | |||
| (0.82) | (0.10) | (0.01) | (0.29) | (0.01) | (1.14) | (0.16) | (0.02) | (0.49) | (0.02) | ||
| CC | 0.03 | 0.11 | 0.07 | 0.15 | 0.17 | 0.08 | 0.14 | 0.07 | |||
| (1.00) | (0.14) | (0.01) | (0.34) | (0.01) | (1.86) | (0.28) | (0.03) | (0.84) | (0.03) | ||
| Omni | 0.02 | 0.04 | 0.06 | 0.08 | 0.03 | 0.04 | 0.02 | ||||
| (0.73) | (0.09) | (0.01) | (0.28) | (0.01) | (1.13) | (0.14) | (0.02) | (0.51) | (0.02) | ||
| GEV | SS-MN-G | 0.02 | 0.04 | 0.13 | 0.06 | 0.04 | 0.06 | 0.05 | |||
| (1.63) | (0.20) | (0.02) | (0.61) | (0.02) | (0.98) | (0.12) | (0.02) | (0.47) | (0.01) | ||
| SS-MN-N | 0.18 | 0.10 | 0.73 | 0.05 | 0.14 | 0.07 | 0.04 | 0.07 | 0.04 | ||
| (1.63) | (0.26) | (0.03) | (0.69) | (0.03) | (0.98) | (0.12) | (0.02) | (0.47) | (0.01) | ||
| SS-N | 0.67 | 0.55 | 0.07 | 0.03 | 0.02 | ||||||
| (1.60) | (0.19) | (0.03) | (0.68) | (0.03) | (0.98) | (0.12) | (0.02) | (0.47) | (0.01) | ||
| MI | 0.36 | 0.04 | 0.07 | 0.03 | 0.02 | ||||||
| (1.59) | (0.21) | (0.02) | (0.63) | (0.03) | (1.02) | (0.13) | (0.02) | (0.47) | (0.01) | ||
| DL | 0.14 | 0.05 | 1.03 | 0.74 | 0.14 | ||||||
| (1.75) | (0.30) | (0.02) | (0.67) | (0.02) | (0.97) | (0.12) | (0.01) | (0.45) | (0.01) | ||
| CC | 0.11 | 0.26 | 0.12 | 0.07 | 0.07 | 0.09 | 0.10 | ||||
| (2.10) | (0.34) | (0.03) | (0.80) | (0.03) | (1.34) | (0.18) | (0.02) | (0.55) | (0.02) | ||
| Omni | 0.38 | 0.44 | 0.01 | 0.04 | 0.05 | 0.06 | 0.07 | 0.09 | |||
| (1.53) | (0.23) | (0.03) | (0.68) | (0.03) | (0.97) | (0.12) | (0.02) | (0.47) | (0.01) | ||
| Mixture | SS-MN-G | 0.02 | 0.05 | 0.12 | 0.08 | 0.05 | 0.07 | 0.04 | |||
| (0.66) | (0.10) | (0.01) | (0.29) | (0.01) | (0.90) | (0.12) | (0.02) | (0.42) | (0.01) | ||
| SS-MN-N | 0.02 | 0.04 | 0.13 | 0.09 | 0.06 | 0.07 | 0.05 | ||||
| (0.67) | (0.10) | (0.01) | (0.30) | (0.01) | (1.01) | (0.13) | (0.02) | (0.45) | (0.01) | ||
| SS-N | 0.18 | 0.66 | 0.16 | 0.08 | 0.04 | ||||||
| (0.73) | (0.12) | (0.01) | (0.31) | (0.01) | (1.01) | (0.13) | (0.02) | (0.44) | (0.01) | ||
| MI | 0.07 | 0.30 | 0.09 | 0.07 | 0.02 | 0.06 | |||||
| (0.76) | (0.12) | (0.01) | (0.31) | (0.01) | (1.03) | (0.13) | (0.02) | (0.45) | (0.01) | ||
| DL | 0.02 | 1.15 | 0.58 | 0.15 | |||||||
| (0.77) | (0.14) | (0.01) | (0.31) | (0.01) | (0.97) | (0.12) | (0.01) | (0.43) | (0.01) | ||
| CC | 0.10 | 0.09 | 0.09 | 0.08 | 0.09 | ||||||
| (1.08) | (0.17) | (0.02) | (0.40) | (0.02) | (1.24) | (0.17) | (0.02) | (0.53) | (0.02) | ||
| Omni | 0.00 | 0.01 | 0.07 | 0.07 | 0.07 | 0.08 | 0.08 | ||||
| (0.55) | (0.09) | (0.01) | (0.25) | (0.01) | (0.99) | (0.13) | (0.02) | (0.44) | (0.01) | ||
Table 2 displays the relative bias and standard deviation (in parentheses) of the parameter estimates for each of the analysis methods, with relative bias estimates in bold if the absolute bias is different from 0 at the 0.05 level. Overall, the SS-MN-G and SS-MN-N methods perform better than the SS-N and DL methods in terms of bias and better than the CC and MI methods in terms of efficiency. The SS-MN-G method additionally shows a potential improvement in bias reduction compared to the Omni and CC methods since they incorrectly assume a lognormal event time distribution. In all cases, the proposed SS-MN-G method performs well. For this reason, we suggest generally approaching modeling eq. (2) using a flexible AFT distribution such as the generalized gamma.
5.2.2 All parametric models unknown or misspecified
We now consider a scenario where all of the parametric models are unknown. Specifically, we let the conditional covariate distribution be log-gamma as defined in Section 5.1, the AFT error model be a mixture of generalized gamma and lognormal distributions as defined in Section 5.2.2, and the binary regression model be probit rather than logistic. The same seven methods are considered as in Section 5.2.2, but AIC was used to determine whether the binary submodel should be logistic or probit.
Table 3 displays the relative bias and standard deviation (in parentheses) of the parameter estimates for each of the analysis methods, with relative bias estimates in bold if the absolute bias is different from 0 at the 0.05 level. As with the simulations in the previous section, the SS-MN-G and SS-MN-N methods perform well, will lower bias than the SS-N and DL methods and better efficiency than the CC method. Interestingly, the MI method is fairly comparable in terms of bias and efficiency to the SS-MN-G and SS-MN-N methods in this particular scenario, though it was shown in other cases to be inferior.
Single censored covariate, all parametric models unknown: comparison of relative bias and standard deviations (in parenthesis below bias) of estimates for (a) the proposed semicontinuous survival model strategy assuming a mixture of normals distribution for the censored covariate and a generalized gamma AFT (SS-MN-G); (b) the proposed semicontinuous survival model strategy assuming a mixture of normals distribution for the censored covariate (SS-MN-N) or a normal distribution for the censored covariate (SS-N) and a lognormal AFT; (c) the semicontinuous survival model using multiple imputations based on a normal distribution for the censored covariate and a lognormal AFT (MI); (c) a lognormal AFT and logistic regression model replacing censored values with DL
| Method | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| SS-MN-G | 0.11 | 0.06 | 0.03 | 0.01 | 0.75 | 0.07 | 0.03 | 0.06 | 0.10 | |
| (0.92) | (0.18) | (0.01) | (0.34) | (0.01) | (0.89) | (0.20) | (0.02) | (0.34) | (0.02) | |
| SS-MN-N | 0.08 | 0.27 | 0.04 | 0.75 | 0.05 | 0.07 | 0.05 | 0.08 | ||
| (0.83) | (0.16) | (0.01) | (0.33) | (0.01) | (0.79) | (0.18) | (0.01) | (0.33) | (0.01) | |
| SS-N | 0.24 | 0.15 | 0.16 | 0.96 | 0.12 | 0.03 | 0.07 | |||
| (0.85) | (0.18) | (0.01) | (0.33) | (0.01) | (0.78) | (0.18) | (0.01) | (0.33) | (0.01) | |
| MI | 0.17 | 0.15 | 0.15 | 0.82 | 0.07 | 0.04 | 0.05 | 0.02 | ||
| (0.89) | (0.17) | (0.01) | (0.33) | (0.01) | (0.78) | (0.17) | (0.01) | (0.33) | (0.01) | |
| DL | 0.09 | 0.66 | 0.48 | 0.05 | 0.02 | 0.08 | ||||
| (0.86) | (0.17) | (0.01) | (0.35) | (0.01) | (0.69) | (0.15) | (0.01) | (0.32) | (0.01) | |
| CC | 0.01 | 0.08 | 0.02 | 0.84 | 0.10 | 0.08 | 0.08 | 0.08 | ||
| (1.43) | (0.30) | (0.01) | (0.44) | (0.01) | (1.25) | (0.25) | (0.01) | (0.36) | (0.01) | |
| Omni | 0.05 | -0.01 | 0.81 | 0.08 | 0.05 | 0.07 | 0.04 | |||
| (0.63) | (0.09) | (0.01) | (0.26) | (0.01) | (0.76) | (0.17) | (0.01) | (0.33) | (0.01) |
5.3 Multiple censored covariates
We conducted simulations similar to those in Section 5.1, but with three covariates subject to censoring below DLs so as to mimic the GenIMS application more closely. Specifically, for N = 300 data sets of size n = 200, we generated three fully observed covariates
These parameter values were chosen so that the conditional distribution of
The log-survival response was generated as in Section 5.1, except with the parameter vector
Multiple censored covariates: comparison of relative bias and standard deviations of estimates for (a) the proposed semicontinuous survival model strategy assuming a series of mixture of normal distributions for the censored covariates (SS-MN) or a series of normal distributions for the censored covariates (SS-N); (b) the semicontinuous survival model using multiple imputations based on a series of normal distributions for the censored covariates (MI); (c) an AFT and logistic regression model replacing censored values with DL
| Method | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SS-MN | SS-N | MI | DL | CC | Omni | ||||||||
| Par. | Bias | SD | Bias | SD | Bias | SD | Bias | SD | Bias | SD | Bias | SD | |
| Mixture | 0.00 | 1.70 | 1.69 | 0.00 | 1.75 | 1.46 | 3.91 | 1.52 | |||||
| 0.00 | 0.22 | 0.22 | 0.23 | 0.19 | 0.53 | 0.21 | |||||||
| 0.24 | 0.30 | 0.08 | 0.29 | 0.15 | 0.31 | 0.31 | 0.67 | 0.18 | |||||
| 0.33 | 0.35 | 0.35 | 0.82 | 0.23 | 0.61 | 0.27 | |||||||
| 0.01 | 0.03 | 0.03 | 0.03 | 0.01 | 0.03 | 0.02 | |||||||
| 0.09 | 0.03 | 0.46 | 0.04 | 0.04 | 0.02 | 0.18 | 0.06 | 0.15 | 0.03 | ||||
| 0.73 | 0.74 | 0.15 | 0.80 | 0.54 | 0.66 | 1.64 | 0.66 | ||||||
| 0.03 | 0.86 | 0.02 | 0.82 | 0.09 | 0.96 | 0.79 | 0.46 | 3.44 | 0.05 | 0.80 | |||
| 0.17 | 0.16 | 0.20 | 0.14 | 0.06 | 0.49 | 0.14 | |||||||
| 0.19 | 0.18 | 0.10 | 0.25 | 0.19 | 0.63 | 0.13 | |||||||
| 0.25 | 0.20 | 0.09 | 0.22 | 0.47 | 0.24 | 2.88 | 0.16 | 1.78 | 0.57 | 0.51 | 0.18 | ||
| 0.01 | 0.01 | 0.01 | 0.01 | 0.01 | 0.28 | 0.04 | 0.02 | 0.01 | |||||
| 0.13 | 0.02 | 0.26 | 0.02 | 0.02 | 1.23 | 0.02 | 0.16 | 0.06 | 0.02 | ||||
| 0.17 | 0.53 | 0.15 | 0.55 | 0.20 | 0.55 | 0.52 | 0.42 | 0.43 | 1.41 | 0.05 | 0.46 | ||
| Copula | 1.78 | 1.80 | 2.07 | 2.53 | 3.66 | 1.72 | |||||||
| 0.15 | 0.15 | 0.15 | 0.03 | 0.17 | 0.23 | 0.15 | |||||||
| 0.29 | 0.29 | 0.34 | 0.49 | 0.59 | 0.27 | ||||||||
| 0.23 | 0.23 | 0.25 | 0.30 | 0.37 | 0.21 | ||||||||
| 0.01 | 0.01 | 0.01 | 0.01 | 0.02 | 0.01 | ||||||||
| 0.02 | 0.02 | 0.02 | 0.81 | 0.02 | 0.02 | 0.02 | |||||||
| 0.02 | 0.49 | 0.49 | 0.51 | 0.11 | 0.49 | 0.72 | 0.47 | ||||||
| 0.07 | 1.24 | 0.07 | 1.23 | 0.10 | 1.54 | 1.89 | 0.31 | 3.26 | 0.06 | 1.14 | |||
| 0.17 | 0.12 | 0.13 | 0.12 | 0.22 | 0.12 | 0.11 | 0.13 | 0.47 | 0.21 | 0.33 | 0.12 | ||
| 0.01 | 0.24 | 0.03 | 0.24 | 0.13 | 0.29 | 0.40 | 0.60 | 0.57 | 0.22 | ||||
| 0.18 | 0.18 | 0.22 | 0.25 | 0.43 | 0.16 | ||||||||
| 0.07 | 0.01 | 0.07 | 0.01 | 0.07 | 0.01 | 0.01 | 0.23 | 0.02 | 0.07 | 0.01 | |||
| 0.11 | 0.01 | 0.11 | 0.01 | 0.12 | 0.01 | 1.61 | 0.01 | 0.23 | 0.02 | 0.16 | 0.01 | ||
| 0.01 | 0.35 | 0.02 | 0.35 | 0.01 | 0.37 | 0.20 | 0.33 | 0.69 | 0.04 | 0.33 | |||
Table 4 displays the relative bias and standard deviation of parameter estimates for the same six data analysis approaches as in Section 5.1: our proposed semicontinuous survival method using a mixture of two normals for modeling each of the univariate distributions in eq. (4) (SS-MN), our proposed semicontinuous survival method using a normal distribution to model each of the univariate distributions in eq. (4) (SS-N), a multiple imputation method where 100 imputed data sets were generated based on the semicontinuous survival model and a normal distribution to model each of the univariate distributions in eq. (4), an AFT and logistic regression model based on complete data where censored
The SS-MN, SS-N, and MI methods all perform similarly in terms of bias, with the CC method perhaps performing slightly better. However, the SS-MN and SS-N methods yield substantially more efficient estimates than the CC and MI methods, with standard deviations of the parameter estimates for the CC and MI methods as much as 280% and 31% higher, respectively. The mean squared errors (not shown) for the CC and MI method are significantly higher than the SS-MN and SS-N methods for all parameter estimates. The DL method estimates are poor on all accounts, with statistically significant biases for 23 of the 28 parameter estimates and magnitudes of relative bias as high as 288%. The results are similar for both the case when the distribution of the censored covariates is truly a mixture of normals and when it is generated using the copula, though there are slightly higher biases in the latter case.
We conducted an additional simulation for another unusual multivariate distribution of the censored covariates, with results included in the online Supplementary Material. The relative performance of all of methods remained the same.
6 Application
We illustrate the semicontinuous survival analysis method developed in Sections 2 and 3 by applying it to the Genetic and Inflammatory Markers of Sepsis (GenIMS) data set. One of the main purposes of the GenIMS study was to determine the relationship between cytokine levels and 90-day survival (event of surviving at least 90 days) for patients with community acquired pneumonia (CAP) [10]. It is additionally relevant to model the relationship between these cytokines and survival for those not surviving to 90 days. Thus, we would like to model survival times where a point mass occurs at 90 days.
Cytokines are cell-signaling protein molecules that are sent out by cells in the immune system. Three cytokines were measured in this study: tumor necrosis factor (TNF), interleukin-6 (IL-6), and interleukin-10 (IL-10). The TNF and IL-6 cytokines serve as biomarkers of pro-inflammatory responses to CAP while IL-10 serves as a biomarker of anti-inflammatory responses to CAP. It has been thought that pro- and anti-inflammatory responses in the body help explain the development of severe sepsis and resulting deaths, and that understanding these relationships could be important for developing medical treatments.
The data for the GenIMS study were obtained by first enrolling individuals with CAP immediately after admission to a hospital and then collecting biological measurements and demographic information for each individual. In our analysis, we considered the 1418 patients who actually acquired CAP, necessitated a hospital stay, and had TNF, IL-6, and IL-10 measurements taken on the first day of hospitalization.
We fit a semicontinuous survival model for the event times based on six covariates: sex (1 representing males, 0 representing females), race (1 representing Caucasians, 0 representing all other races), age, and TNF, IL-6, and IL-10 measurements on the first day of hospitalization. While sex, race, and age were fully observed, the cytokine biomarker measurements were censored below the detection thresholds 4, 2 or 5, and 5 pg/ml, respectively, with censoring proportions of 35.54%, 13.40%, and 46.83%, respectively. We also considered using Apache III scores (a measure of severity of the CAP) as a covariate, but found they were very collinear with the cytokine levels and decided to leave them out of the analysis.
We used a generalized gamma AFT model to explain the relationship between the event time and the covariates of interest and a logistic regression model to describe the relationship between 90-day survival and the covariates of interest. While a few previous works assumed a lognormal distribution for the covariates [10, 13], we assumed that conditional on the sex, race, and age covariates, TNF, IL-6, and IL-10 are distributed according to series of mixture of normal distributions as in eq. (4). We obtained parameter estimates for each of the models using the EM algorithm described in Section 3.
Table 5 displays the analysis results for the AFT and logistic submodels. For the AFT submodel, we observe that for those individuals who do not survive 90 days after admittance to the hospital, higher levels of the cytokine IL-6 are associated with shorter survival times, conditional on TNF and IL-10 levels, sex, race, and age (
Coefficient parameter estimates and standard errors for the semicontinuous survival model for survival time based on the covariates sex, race, age, and the three cytokine covariates of interest,TNF, IL-6, and IL-10.
| AFT Model | Intercept | Sex | Race | Age | TNF | IL-6 | IL-10 |
| Estimate | 11.985 | 0.16 | |||||
| SE | 1.42 | 0.40 | 0.75 | 0.01 | 0.21 | 0.09 | 0.12 |
| p-value | < 0.001 | 0.630 | 0.903 | 0.922 | 0.434 | 0.002 | 0.930 |
| Logistic Model | Intercept | Sex | Race | Age | TNF | IL-6 | IL-10 |
| Estimate | 7.406 | ||||||
| SE | 0.78 | 0.18 | 0.31 | 0.01 | 0.11 | 0.06 | 0.07 |
| p-value | < 0.001 | 0.024 | 0.530 | < 0.001 | 0.482 | 0.179 | 0.103 |
For each of the three cytokines of interest, we conducted two degree of freedom
Due to a relatively high level of pairwise correlations among the three cytokines for the observations above the DLs (0.25-0.35), we also considered modeling each cytokine separately. In each of these models, we included sex, race, age, and one of the cytokines in both the AFT and logistic parts of the model.
Table 6 displays the results of the three single cytokine models. Unsurprisingly, the estimated coefficients for sex, race, and age are similar across all three single cytokine models and the multivariate model in Table 3. Surprisingly, perhaps, the estimated coefficients for the three different cytokines are also similar across the three separate models — in contrast to the multivariate model with results in Table 3 — indicating similar marginal associations of the cytokines with survival time. Standard errors for the estimates for the cytokine coefficients varied significantly across the three models, primarily due to different levels of censoring. There is strong evidence that, conditional on sex, race, and age, higher IL-6 levels are associated with a lower probability of surviving to 90 days and a shorter survival time. There is also strong evidence that IL-10 is conditionally related to surviving 90 days, but only moderate evidence that it is associated with survival time for those not surviving 90 days. The TNF cytokine is only moderately statistically significant in the logistic model. In all three models, there is a strong relationship between sex and age and survival to 90 days, with younger females being the most like to survive to the 90-day mark.
Coefficient parameter estimates and standard errors for the semicontinuous survival model for three different sets of covariates: one of three cytokine covariates of interest together with the covariates gender, race, and age.
| TNF | IL-6 | IL-10 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Est. | SE | p-value | Bias | SE | p-value | Bias | SE | p-value | |
| AFT Model | |||||||||
| Intercept | 13.804 | 3.771 | < 0.001 | 13.029 | 3.297 | < 0.001 | 13.910 | 3.766 | < 0.001 |
| Cytokine | 0.169 | 0.407 | 0.079 | 0.001 | 0.112 | 0.136 | |||
| Sex | 0.376 | 0.859 | 0.323 | 0.531 | 0.363 | 0.976 | |||
| Race | 0.645 | 0.663 | 0.557 | 0.812 | 0.007 | 0.640 | 0.991 | ||
| Age | 0.010 | 0.017 | 0.574 | 0.001 | 0.016 | 0.982 | 0.016 | 0.541 | |
| Logistic Model | |||||||||
| Intercept | 7.065 | 0.635 | < 0.001 | 7.271 | 0.635 | < 0.001 | 7.125 | 0.629 | < 0.001 |
| Cytokine | 0.091 | 0.039 | 0.042 | 0.001 | 0.054 | < 0.001 | |||
| Sex | 0.175 | 0.010 | 0.175 | 0.016 | 0.176 | 0.019 | |||
| Race | 0.317 | 0.405 | 0.315 | 0.506 | 0.316 | 0.558 | |||
| Age | 0.007 | < 0.001 | 0.007 | < 0.001 | 0.007 | < 0.001 | |||
We conducted two degree of freedom
7 Discussion
We have proposed a semicontinuous survival model to handle time-to-event data with a point mass at a known cure threshold and one or more covariates subject to DLs. We additionally proposed a Monte Carlo EM algorithm for obtaining estimates in this model. Through simulations, we have shown that our proposed method flexibly models the distribution of the censored covariates and leads to approximately unbiased estimates for the parameters of interest in a variety of scenarios.
We note that while the methodology developed in this paper was motivated by a special case of long-term survival data where a cure time is known and no event times were censored prior to this time, the proposed model and estimation method could be applied to any semicontinuous regression model with a covariate censored due to DLs. It may also be noted that censoring due to DLs is just a special case of coarsened data and that a similar methodology could be applied to handle more general types of missing data in semicontinuous models, as has been done by authors in other regression contexts with missing covariates.
The methods proposed in this paper do have a few shortcomings. Perhaps foremost, it may be noted that the proposed methods seem specialized to a particular data set with a known cure threshold and no censoring before the threshold. However, in practice it has been relatively common to analyze survival data as a binary outcome [49]. For example, with various cancers and diseases, 2- and 5-year survival rates are important medical summary statistics. The proposed method has the advantage that it allows for simultaneously modeling survival probabilities at these times and the survival time for those not making it to the threshold of interest. If censoring occurs before the threshold of interest for some individuals, then the true survival time and cure status would be unknown. Bernhardt [50] considers this special case of cure models with a cure threshold in the context of fully observed covariates. To handle covariates subject to DLs, a similar Monte Carlo EM algorithm as that proposed in this paper could be developed in a cure model context. As another case where a semicontinuous survival model could apply, consider a timed sporting competition that includes a binary outcome. For example, in marathon qualifying events, we may be interested in a single model for the distribution of finishing times for qualifiers as well as the probability of qualifying.
A second disadvantage of our method is that it is somewhat computationally intensive. We proposed a Monte Carlo EM algorithm where each step requires obtaining many imputations and conducting three or more independent optimization routines. With relatively few parameters in the model and a single covariate subject to DLs, it may be faster to directly maximize the observed data likelihood using numerical integration techniques to approximate the integral, though numerical issues would be more likely to arise. However, we note that for the simulation and application data sets, computational effort was a relatively minor issue as the parameter estimates were obtained in a few minutes or less in the case of one covariate subject to a detection limit and less than 30 minutes with three covariates. If time was an issue, a simpler model than a mixture of normals for
Acknowledgements:
The author would like to thank the editors and reviewers for their valuable comments. The author would also like to thank Dr. Lan Kong and the CRISMA (Clinical Research, Investigation, and Systems Modeling of Acute Illness) Center at the University of Pittsburgh for providing the GenIMS data set.
References
[1] Smith VE, Preisser JS, Neelon B, Maciejewski ML. A marginalized two-part model for semicontinuous data. Stat Med. 2014;33:4891–4903.10.1002/sim.6263Search in Google Scholar PubMed
[2] Zhou X-H, Tu W. Comparison of several independent population means when their samples contain log-normal and possibly zero observations. Biometrics 1999;55:645–651.10.1111/j.0006-341X.1999.00645.xSearch in Google Scholar PubMed
[3] Liu L, Strawderman RL, Johnson BA, O’Quigley JM. Analyzing repeated measures semi-continuous data, with application to an alcohol dependence study. Stat Meth Med Res. 2016;25:133–152.10.1177/0962280212443324Search in Google Scholar PubMed
[4] Mills ED. Adjusting for covariates in zero-inflated gamma and zero-inflated log-normal models for semicontinuous data. Ph.D. thesis, University of Iowa, 2013.Search in Google Scholar
[5] Su L, Tom BD, Farewell VT. Bias in 2-part mixed models for longitudinal semicontinuous data. Biostatistics 2009;10:374–389.10.1093/biostatistics/kxn044Search in Google Scholar PubMed PubMed Central
[6] Manning Jr. WG, Morris CN, Newhouse JP, Duan N, EB Keeler, Liebowitz A, et al. A two-part model of the demand for medical care: preliminary results from the health insurance study. Health, Econ Health Econ. 1983;1:103–123.Search in Google Scholar
[7] Duan N, Manning Jr. WG, Morris CN, Newhouse JP. A comparison of alternative models for the demand for medical care. J Bus Econ Stat. 1983;1:115–126.10.1080/07350015.1983.10509330Search in Google Scholar
[8] Moulton LH, Curriero FC, Barroso PF. Mixture models for quantitative HIV RNA data. Stat Meth Med Res. 2002;11:317–325.10.1191/0962280202sm292raSearch in Google Scholar PubMed
[9] Olsen MK, Schafer JL. A two-part random-effects model for semicontinuous longitudinal data. J Am Stat Assoc. 2001;96:730–745.10.1198/016214501753168389Search in Google Scholar
[10] Kellum JA, Kong L, Fink MP, Weissfeld LA, Yealy DM, Pinsky MR, et al. Understanding the inflammatory cytokine response in pneumonia and sepsis. Archives of Internal Med. 2007;167:1655–1663.10.1001/archinte.167.15.1655Search in Google Scholar PubMed PubMed Central
[11] Angus DC, Carlet J. Surviving intensive care: a report from the 2002 brussels roundtable. Intensive Care Med. 2003;29:368–377.10.1007/s00134-002-1624-8Search in Google Scholar PubMed
[12] Cohen J, Guyatt G, Bernard GR, Calandra T, Cook D, Elbourne D, et al. New strategies for clinical trials in patients with sepsis and septic shock. Intesive Care Med. 2001;29:880–886.10.1097/00003246-200104000-00039Search in Google Scholar PubMed
[13] Bernhardt PW, Wang HJ, Zhang S. Flexible modeling of survival data with covariates subject to detection limits via multiple imputation. Comput Stat Data Anal 2014;69:81–91.10.1016/j.csda.2013.07.027Search in Google Scholar PubMed PubMed Central
[14] D’ Angelo GD, Weissfeld L. An index approach for the cox model with left censored covariates. Stat Med. 2008;27:4502–4514.10.1002/sim.3285Search in Google Scholar PubMed
[15] Sattar A, Sinha SK, Morris NJ. A parametric survival model when a covariate is subject to left-censoring. J Biomet Biostat. 2012;S3:002. DOI: 10.4172/2155–6180.S3–002.Search in Google Scholar
[16] Berkson J, Gage RP. Survival cure for cancer patients following treatment. J Am Stat Assoc. 1952;47:501–515.10.1080/01621459.1952.10501187Search in Google Scholar
[17] Boag JW. Maxmimum likelihood estimates of the proportion of patients cured by cancer therapy. J R Stat Soc, Ser B. 1949;11:15–53.10.1111/j.2517-6161.1949.tb00020.xSearch in Google Scholar
[18] Hornung RW, Reed LD. Estimation of average concentration in the presence of nondetectable values. Appl Occup Environ Hyg. 1990;5:46–51.10.1080/1047322X.1990.10389587Search in Google Scholar
[19] Austin PC, Hoch JS. Estimating linear regression models in the presence of a censored independent variable. Stat Med. 2004;23:411–429.10.1002/sim.1601Search in Google Scholar PubMed
[20] Giovanini J. Generalized linear mixed models with censored covariates. Ph.D. thesis. Oregon State University, 2008.Search in Google Scholar
[21] Austin PC, Brunner LJ. Type I error inflation in the presence of a ceiling effect. Am Statistician. 2003;57:97–104.10.1198/0003130031450Search in Google Scholar
[22] Bernhardt PW, Wang HJ, Zhang S. Statistical methods for generalized linear models with covariates subject to detection limits. Stat Biosci. 2015;7:68–89.10.1007/s12561-013-9099-4Search in Google Scholar PubMed
[23] Helsel DR. Statistics for censored environmental data using minitab and R, 2nd ed. Wiley, 2012.10.1002/9781118162729Search in Google Scholar
[24] Lubin JH, Colt JS, Camann D, Davis S, Cerhan JR, Severson RK, et al. Epidemiologic evaluation of measurement data in the presence of detection limits. Environ Health Perspect. 2004;112:1691–1696.10.1289/ehp.7199Search in Google Scholar PubMed
[25] Lynn HS. Maximum likelihood inference for left-censored hiv rna data. Stat Med. 2001;20:33–45.10.1002/1097-0258(20010115)20:1<33::AID-SIM640>3.0.CO;2-OSearch in Google Scholar PubMed
[26] Rigobon R, Stoker TM. Estimation with censored regressors: basic issues. Int Econ Rev. 2007;48:1441–1467.10.1111/j.1468-2354.2007.00470.xSearch in Google Scholar
[27] Rigobon R, Stoker TM. Bias from censored regressors. J Bus Econ Stat. 2009;27:340–353.10.1198/jbes.2009.06119Search in Google Scholar
[28] Langohr K, Gomez G, Muga R. A parametric survival model with an interval-censored covariate. Stat Med. 2004;23:309–319.10.1002/sim.1892Search in Google Scholar
[29] Lee S, Park SH, Park J. The proportional hazards regression with a censored covariate. Stat Probab Lett. 2003;61:309–319.10.1016/S0167-7152(02)00394-2Search in Google Scholar
[30] Chen Q, Wu H, Ware LB, Koyama T. A Bayesian approach for the Cox proportional hazards model with covariates subject to detection limit. Int J Stat Med Res. 2014;3:32–43.10.6000/1929-6029.2014.03.01.5Search in Google Scholar PubMed PubMed Central
[31] Sattar A, Sinha SK, Wang X-H, Li Y. Frailty models for pneumonia to death with a left-censored covariate. Stat Med. 2015;34:2266–2280.10.1002/sim.6466Search in Google Scholar PubMed
[32] Quandt R, Ramsey J. Estimating mixutres of normal distributions and switching regression. J Am Stat Assoc. 1978;73:730–738.10.1080/01621459.1978.10480085Search in Google Scholar
[33] Norets A. Approximation of conditional densities by smooth mixtures of regression. Ann Stat. 2010;38:1733–1766.10.1214/09-AOS765Search in Google Scholar
[34] Ibrahim J. Monte Carlo EM for missing covariates in parametric regression models. Biometrics 1999;55:591–596.10.1111/j.0006-341X.1999.00591.xSearch in Google Scholar PubMed
[35] Dempster AP, Laird NM, Rubin DB. Maximum likelihood from incomplete data via the EM algorithm. J R Stat Soc, Ser B. 1977;39:1–38.10.1111/j.2517-6161.1977.tb01600.xSearch in Google Scholar
[36] McLachlan GJ, Krishnan T. The EM Algorithm and Extensions, 2nd ed. John Wiley and Sons, Inc., 2008.10.1002/9780470191613Search in Google Scholar
[37] Wei GC, Tanner MA. A Monte Carlo implementation of the EM algorithm and the poor man’s data augmentation algorithm. J Am Stat Assoc. 1990;85:699–704.10.1080/01621459.1990.10474930Search in Google Scholar
[38] May RC, Ibrahim JG, Chu H. Maximum likelihood estimation in generalized linear models with multiple covariates subject to detection limits. Stat Med. 2011;30:2551–2561.10.1002/sim.4280Search in Google Scholar PubMed PubMed Central
[39] Metropolis N, Rosenbluth AW, Rosenbluth MN, Teller AH, Teller E. Equation of state calculations by fast computing machines. The Journal of Chemical Physics 1953;21:1087–1092.10.1063/1.1699114Search in Google Scholar
[40] Faria S, Soromenho G. Fitting mixtures of linear regressions. J Stat Comput Simul. 2010;80:201–225.10.1080/00949650802590261Search in Google Scholar
[41] Jackson C. 2013 flexmix: flexible parameter survival and multi-slate models. Available at: http://CRAN.R-project.org/package=flexsurv, R package version 0.7.Search in Google Scholar
[42] Geyer CJ. 2016 mcmc: Markov chain Monte Carlo. Available at: http://CRAN.R-project.org/package=mcmc, R package version 0.9-4.Search in Google Scholar
[43] Louis TA. Finding the observed information matrix when using the EM algorithm. J R Stat Soc, Ser B. 1982;44:226–233.10.1111/j.2517-6161.1982.tb01203.xSearch in Google Scholar
[44] Gelman A, Mechelan IV, Verbeke G, Heitjan D, Meulders M. Multiple imputation for model checking: completed-data plots with missing and latent data. Biometrics 1977;61:74–85.10.1111/j.0006-341X.2005.031010.xSearch in Google Scholar PubMed
[45] Bernhardt PW. Model validation and influence diagnostics for regression models with missing covariates. Statistics in Medicine 2018. DOI: 10.1002/sim.7584.Search in Google Scholar PubMed
[46] Wang N, Robins JM. Large-sample theory for parametric multiple imputation procedures. Biometrika 1998;84:935–948.10.1093/biomet/85.4.935Search in Google Scholar
[47] Tsiatis AA. Semiparametric Theory and Missing Data. Springer, 2006.Search in Google Scholar
[48] Cox C, Chu H, Schneider MF, Mu noz A. Parametric survival analysis and taxonomy of hazard functions for the generalized gamma distribution. Stat Med. 2007;23:4352–4374.10.1002/sim.2836Search in Google Scholar PubMed
[49] Lim J, Lee KE, Hahn KS, Park K. Analyzing survival data as binary outcomes with logistic regression. Commun Korean Stat Soc. 2010;17:117–126.10.5351/CKSS.2010.17.1.117Search in Google Scholar
[50] Bernhardt PW. A flexible cure rate model with dependent censoring and a known cure threshold. Stat Med. 2016;25. DOI: 10.1002/sim.7014.Search in Google Scholar PubMed
Supplementary Material
The online version of this article offers supplementary material (DOI:https://doi.org/10.1515/ijb-2017-0058).
© 2018 Walter de Gruyter GmbH, Berlin/Boston
Articles in the same Issue
- Commentary
- A Serious Flaw in Nutrition Epidemiology: A Meta-Analysis Study
- Research Article
- A Fast and Robust Way to Estimate Overlap of Niches, and Draw Inference
- A Spatio-Temporal Model and Inference Tools for Longitudinal Count Data on Multicolor Cell Growth
- Optimal and/or Efficient Two treatment Crossover Designs for Five Carryover Models
- A New Class of Robust Two-Sample Wald-Type Tests
- Estimating Causal Effects from Nonparanormal Observational Data
- Maximum Likelihood Estimation in a Semicontinuous Survival Model with Covariates Subject to Detection Limits
Articles in the same Issue
- Commentary
- A Serious Flaw in Nutrition Epidemiology: A Meta-Analysis Study
- Research Article
- A Fast and Robust Way to Estimate Overlap of Niches, and Draw Inference
- A Spatio-Temporal Model and Inference Tools for Longitudinal Count Data on Multicolor Cell Growth
- Optimal and/or Efficient Two treatment Crossover Designs for Five Carryover Models
- A New Class of Robust Two-Sample Wald-Type Tests
- Estimating Causal Effects from Nonparanormal Observational Data
- Maximum Likelihood Estimation in a Semicontinuous Survival Model with Covariates Subject to Detection Limits