Nearest-Neighbor Estimation for ROC Analysis under Verification Bias
-
Gianfranco Adimari
 and
Monica Chiogna
and
Monica Chiogna

Abstract
For a continuous-scale diagnostic test, the receiver operating characteristic (ROC) curve is a popular tool for displaying the ability of the test to discriminate between healthy and diseased subjects. In some studies, verification of the true disease status is performed only for a subset of subjects, possibly depending on the test result and other characteristics of the subjects. Estimators of the ROC curve based only on this subset of subjects are typically biased; this is known as verification bias. Methods have been proposed to correct verification bias, in particular under the assumption that the true disease status, if missing, is missing at random (MAR). MAR assumption means that the probability of missingness depends on the true disease status only through the test result and observed covariate information. However, the existing methods require parametric models for the (conditional) probability of disease and/or the (conditional) probability of verification, and hence are subject to model misspecification: a wrong specification of such parametric models can affect the behavior of the estimators, which can be inconsistent. To avoid misspecification problems, in this paper we propose a fully nonparametric method for the estimation of the ROC curve of a continuous test under verification bias. The method is based on nearest-neighbor imputation and adopts generic smooth regression models for both the probability that a subject is diseased and the probability that it is verified. Simulation experiments and an illustrative example show the usefulness of the new method. Variance estimation is also discussed.
1 Introduction
The evaluation of the ability of a diagnostic or a screening test to separate diseased from non-diseased subjects is a crucial issue in modern medicine. In fact, before applying a test in a clinical setting, rigorous statistical assessment of its performance in discriminating the disease status from the non-disease status is required.
Typically, in evaluating a diagnostic test’s discriminatory ability, the available data come from medical records of patients who undergo the test. The accuracy of the test under study is ideally evaluated by comparison with a perfect gold standard test, which assesses disease status with certainty. In practice, however, a gold standard may be too expensive, or too invasive or both for regular use. Hence, only a subset of patients undergoes disease verification, and the decision to send a patient to verification is often based on the test result and other patient characteristics. As noted by many authors (see Begg and Greenes [1], Begg [2] and Zhou [3], among others), summary measures of test performance based on data from patients with verified disease status only may be badly biased. This bias is usually referred to as verification bias.
For a diagnostic test that yields a continuous test result, the receiver operating characteristic (ROC) curve is a popular tool for displaying the ability of the test to discriminate between healthy and diseased subjects. The continuous test result can be dichotomized at a specified cutpoint. Given the cutpoint c, the sensitivity
In the presence of verification bias, under the assumption that the true disease status, if missing, is missing at random (MAR), estimation of the ROC curve of a continuous test, i.e., estimation of sensitivity and specificity, has been discussed in Alonzo and Pepe [5], where alternative estimators are reviewed and compared. MAR assumption states that the probability of a subject having the disease status verified is purely determined by the test result and the subjects’ observed characteristics and is conditionally independent of the unknown true disease status. This corresponds to a so-called ignorable missingness, which is often assumed in practice. Estimation of the ROC curve when the true diseased status is subject to non-ignorable missingness is tackled in Fluss et al. [6] and Liu and Zhou [7]. In all these cases, however, inference on the ROC curve requires specification of a parametric regression model for the probability of a subject being diseased and/or verified. A wrong specification of these parametric models affects the behavior of the estimators.
To reduce the effects of model misspecification, He and McDermott [8] propose a method that stratifies the verified sample into several subsamples that have homogeneous propensity scores (the conditional probabilities of verification) and allows correction for verification bias within each subsample. Parametric models are still used to estimate the propensity scores, but since the estimated propensity scores are only used for the purpose of stratification, the estimators of sensitivity and specificity are less sensitive to model misspecification. The method applies to binary tests under the MAR assumption.
In this paper, we propose a fully nonparametric method for the estimation of the ROC curve of a continuous test under verification bias. The proposed method is based on nearest-neighbor imputation and adopts generic smooth regression models for both the probability that a subject is diseased and the probability that it is verified. Our choice is motivated by the results in Ning and Cheng [9], according to which the nearest-neighbor imputation method favorably compares with other nonparametric imputation methods in estimating a population mean.
The estimators for the sensitivity and the specificity obtained by the new approach are shown to be consistent and asymptotically normal under the MAR assumption. Estimation of their variance is also discussed. Some simulation results and an illustrative example show usefulness of our proposal and advantages in comparison with known estimators.
The paper is organized as follows. In Section 2, we give a brief review of existing methods for estimating the ROC curve under verification bias. Section 3 describes the proposed approach, giving theoretical justification. Section 4 presents some results of a simulation study carried out to compare the new method with the existing methods. In Section 5, we illustrate the method with an example, and Section 6 contains details about variance estimation. A concluding discussion is given in Section 7.
2 Background
In this section, we review current bias-correction methods in the presence of verification bias, as presented in Alonzo and Pepe [5]. Let
When all patients are verified, i.e.,
where
If not all patients have their disease status verified, several estimators based on the MAR assumption have been proposed. MAR assumption states that the binary responses D and V are mutually independent given the test result T and the covariates X, i.e.,
The so-called full imputation (FI) estimators of
Parametric models, such as logistic regression models, have to be used to obtain the estimate
The inverse probability weighting (IPW) estimator weights each verified subject by the inverse of the probability that the subject is selected for verification. Therefore, the estimators of
where
Alonzo and Pepe [5] find that SPE estimators are doubly robust in the sense that they are consistent if either
3 The proposal
All the verification bias-corrected estimators of
To avoid misspecification problems, in what follows we propose a fully nonparametric approach to the estimation of
Hereafter, we will assume
where
Let
Therefore
are KNN imputation estimators for the sensitivity
Let
Theorem 1Assume (1) and first-order differentiability of the functions
Proof 1Since
It is straightforward to show that estimators
Clearly, by varying
In practice, the use of our estimators requires to select the neighborhood size K and a suitable distance measure. Such aspects, touched upon in the following section, are discussed in Section S1 of Supplementary Material.
4 Simulation study
In this section, Monte Carlo experiments are used to compare the new method with existing approaches with respect to bias and standard deviation. In particular, we compare the ability of the MSI, IPW, SPE and KNN methods to estimate the sensitivity and the specificity of a test. We do not consider the FI method because of its similarities with the MSI method. As for the KNN method, we give the results for the estimators based on the quite commonly used Euclidean distance and on values of K equal to 1 and 3. This choice is supported by the results of a preliminary simulation study, in which KNN estimators based on various distance measures (Manhattan, Euclidean, Lagrange and Mahalanobis) and on different neighborhood sizes (
From Section 2, the MSI method requires a parametric model for
Simulation settings are similar to those in Alonzo and Pepe [5] and He and McDermott [8]. Starting from two independent random variables
Models for
where
According to the aim of the study in this scenario, we fix two sample sizes, a relatively small one, i.e.,
To estimate the conditional disease probabilities, we use a generalized linear model for D given T and X with probit link; this model is correctly specified (see Alonzo and Pepe [5]). The conditional verification probabilities are estimated from a logistic regression model with V as the response and T and X as predictors. Evidently, also this model is correct.
Tables 1 and 2 show Monte Carlo means and standard deviations (in brackets) of the estimators for the sensitivity and the specificity. Results concern the estimators IPW, MSI, SPE and the new proposals 1NN and 3NN, i.e., the KNN estimator with
Monte Carlo means and standard deviations (in brackets) of the estimators for the sensitivity and the specificity, when the models for
| Sensitivity | ||||||||
| True | 0.782 | 0.590 | 0.377 | 0.154 | ||||
| IPW | 0.787 | (0.146) | 0.598 | (0.169) | 0.384 | (0.157) | 0.163 | (0.116) |
| MSI | 0.783 | (0.133) | 0.595 | (0.158) | 0.383 | (0.147) | 0.161 | (0.109) |
| SPE | 0.783 | (0.140) | 0.595 | (0.161) | 0.382 | (0.149) | 0.162 | (0.110) |
| 1NN | 0.783 | (0.143) | 0.596 | (0.166) | 0.382 | (0.153) | 0.162 | (0.112) |
| 3NN | 0.775 | (0.136) | 0.587 | (0.159) | 0.376 | (0.147) | 0.159 | (0.109) |
| Specificity | ||||||||
| True | 0.742 | 0.877 | 0.953 | 0.992 | ||||
| IPW | 0.735 | (0.100) | 0.873 | (0.070) | 0.953 | (0.043) | 0.992 | (0.017) |
| MSI | 0.742 | (0.074) | 0.877 | (0.057) | 0.955 | (0.035) | 0.993 | (0.014) |
| SPE | 0.742 | (0.075) | 0.876 | (0.058) | 0.954 | (0.036) | 0.993 | (0.015) |
| 1NN | 0.742 | (0.076) | 0.877 | (0.058) | 0.954 | (0.036) | 0.992 | (0.015) |
| 3NN | 0.741 | (0.074) | 0.875 | (0.057) | 0.954 | (0.035) | 0.992 | (0.015) |
| Sensitivity | ||||||||
| True | 0.951 | 0.874 | 0.742 | 0.513 | ||||
| IPW | 0.954 | (0.077) | 0.877 | (0.117) | 0.746 | (0.148) | 0.520 | (0.159) |
| MSI | 0.951 | (0.067) | 0.875 | (0.110) | 0.747 | (0.140) | 0.516 | (0.152) |
| SPE | 0.953 | (0.076) | 0.876 | (0.118) | 0.746 | (0.142) | 0.516 | (0.153) |
| 1NN | 0.950 | (0.079) | 0.872 | (0.117) | 0.744 | (0.142) | 0.515 | (0.156) |
| 3NN | 0.944 | (0.077) | 0.863 | (0.117) | 0.735 | (0.142) | 0.509 | (0.153) |
| Specificity | ||||||||
| True | 0.745 | 0.855 | 0.931 | 0.982 | ||||
| IPW | 0.729 | (0.105) | 0.846 | (0.078) | 0.926 | (0.052) | 0.980 | (0.027) |
| MSI | 0.745 | (0.074) | 0.856 | (0.060) | 0.931 | (0.043) | 0.982 | (0.022) |
| SPE | 0.745 | (0.074) | 0.856 | (0.061) | 0.931 | (0.044) | 0.982 | (0.023) |
| 1NN | 0.745 | (0.075) | 0.856 | (0.062) | 0.931 | (0.044) | 0.981 | (0.024) |
| 3NN | 0.744 | (0.074) | 0.855 | (0.060) | 0.930 | (0.043) | 0.981 | (0.023) |
| Sensitivity | ||||||||
| True | 0.991 | 0.969 | 0.918 | 0.784 | ||||
| IPW | 0.992 | (0.031) | 0.973 | (0.058) | 0.920 | (0.092) | 0.787 | (0.133) |
| MSI | 0.990 | (0.028) | 0.970 | (0.053) | 0.920 | (0.086) | 0.786 | (0.130) |
| SPE | 0.991 | (0.032) | 0.971 | (0.057) | 0.920 | (0.089) | 0.785 | (0.131) |
| 1NN | 0.990 | (0.033) | 0.970 | (0.060) | 0.918 | (0.092) | 0.783 | (0.134) |
| 3NN | 0.986 | (0.038) | 0.965 | (0.061) | 0.912 | (0.091) | 0.776 | (0.133) |
| Specificity | ||||||||
| True | 0.731 | 0.822 | 0.897 | 0.963 | ||||
| IPW | 0.700 | (0.121) | 0.803 | (0.092) | 0.886 | (0.069) | 0.958 | (0.040) |
| MSI | 0.730 | (0.076) | 0.824 | (0.065) | 0.898 | (0.053) | 0.963 | (0.032) |
| SPE | 0.731 | (0.076) | 0.824 | (0.066) | 0.898 | (0.053) | 0.963 | (0.033) |
| 1NN | 0.731 | (0.077) | 0.824 | (0.067) | 0.898 | (0.054) | 0.962 | (0.033) |
| 3NN | 0.731 | (0.076) | 0.824 | (0.065) | 0.897 | (0.053) | 0.962 | (0.032) |
Monte Carlo means and standard deviations (in brackets) of the estimators for the sensitivity and the specificity, when the models for
| Sensitivity | ||||||||
| True | 0.782 | 0.590 | 0.377 | 0.154 | ||||
| IPW | 0.785 | (0.102) | 0.595 | (0.116) | 0.379 | (0.109) | 0.159 | (0.079) |
| MSI | 0.785 | (0.091) | 0.595 | (0.107) | 0.380 | (0.103) | 0.159 | (0.076) |
| SPE | 0.785 | (0.097) | 0.594 | (0.110) | 0.379 | (0.104) | 0.159 | (0.076) |
| 1NN | 0.783 | (0.101) | 0.594 | (0.115) | 0.378 | (0.106) | 0.159 | (0.077) |
| 3NN | 0.780 | (0.096) | 0.590 | (0.110) | 0.376 | (0.104) | 0.158 | (0.075) |
| Specificity | ||||||||
| True | 0.742 | 0.877 | 0.953 | 0.992 | ||||
| IPW | 0.738 | (0.068) | 0.877 | (0.047) | 0.954 | (0.029) | 0.992 | (0.012) |
| MSI | 0.742 | (0.052) | 0.878 | (0.038) | 0.955 | (0.025) | 0.992 | (0.010) |
| SPE | 0.742 | (0.053) | 0.878 | (0.039) | 0.954 | (0.025) | 0.992 | (0.011) |
| 1NN | 0.742 | (0.054) | 0.878 | (0.040) | 0.954 | (0.026) | 0.992 | (0.011) |
| 3NN | 0.741 | (0.053) | 0.877 | (0.039) | 0.954 | (0.025) | 0.992 | (0.011) |
| Sensitivity | ||||||||
| True | 0.951 | 0.874 | 0.742 | 0.513 | ||||
| IPW | 0.952 | (0.054) | 0.875 | (0.081) | 0.746 | (0.102) | 0.517 | (0.112) |
| MSI | 0.950 | (0.046) | 0.875 | (0.074) | 0.746 | (0.096) | 0.516 | (0.108) |
| SPE | 0.951 | (0.053) | 0.875 | (0.078) | 0.746 | (0.099) | 0.516 | (0.109) |
| 1NN | 0.950 | (0.056) | 0.873 | (0.083) | 0.744 | (0.103) | 0.515 | (0.111) |
| 3NN | 0.947 | (0.053) | 0.870 | (0.079) | 0.741 | (0.099) | 0.512 | (0.109) |
| Specificity | ||||||||
| True | 0.745 | 0.855 | 0.931 | 0.982 | ||||
| IPW | 0.738 | (0.073) | 0.851 | (0.052) | 0.929 | (0.036) | 0.982 | (0.018) |
| MSI | 0.745 | (0.052) | 0.855 | (0.042) | 0.931 | (0.030) | 0.982 | (0.015) |
| SPE | 0.746 | (0.053) | 0.855 | (0.043) | 0.931 | (0.031) | 0.982 | (0.016) |
| 1NN | 0.745 | (0.054) | 0.855 | (0.044) | 0.931 | (0.032) | 0.982 | (0.016) |
| 3NN | 0.745 | (0.053) | 0.855 | (0.043) | 0.931 | (0.031) | 0.982 | (0.016) |
| Sensitivity | ||||||||
| True | 0.991 | 0.969 | 0.918 | 0.784 | ||||
| IPW | 0.992 | (0.022) | 0.970 | (0.041) | 0.918 | (0.064) | 0.785 | (0.093) |
| MSI | 0.991 | (0.018) | 0.969 | (0.036) | 0.918 | (0.059) | 0.785 | (0.090) |
| SPE | 0.992 | (0.022) | 0.970 | (0.040) | 0.918 | (0.063) | 0.784 | (0.091) |
| 1NN | 0.991 | (0.024) | 0.969 | (0.043) | 0.917 | (0.066) | 0.783 | (0.094) |
| 3NN | 0.990 | (0.022) | 0.967 | (0.041) | 0.914 | (0.063) | 0.780 | (0.091) |
| Specificity | ||||||||
| True | 0.731 | 0.822 | 0.897 | 0.963 | ||||
| IPW | 0.713 | (0.082) | 0.812 | (0.062) | 0.893 | (0.046) | 0.961 | (0.026) |
| MSI | 0.731 | (0.052) | 0.823 | (0.045) | 0.898 | (0.036) | 0.963 | (0.022) |
| SPE | 0.731 | (0.052) | 0.823 | (0.046) | 0.898 | (0.037) | 0.963 | (0.023) |
| 1NN | 0.731 | (0.053) | 0.824 | (0.047) | 0.898 | (0.037) | 0.963 | (0.023) |
| 3NN | 0.731 | (0.053) | 0.823 | (0.046) | 0.898 | (0.037) | 0.963 | (0.022) |
Tables 1 and 2 allow also to gain insight into the effect on results of different variances of T and of different correlations between T and X. By crossing values of
As pointed out by a Referee, the values chosen for
Simulation results allowing to explore the effect of a multidimensional vector of auxiliary covariates are given in Section S4, Supplementary Material. A vector X of dimension 3 is employed. Compared with results in Tables 1 and 2, results in Tables 10 and 11, Supplementary Material, show some loss of efficiency of the KNN estimators with respect to the parametric competitors.
Models for
We set
To estimate the conditional disease probabilities, we use a generalized linear model for D given T and X with logit link; this model is misspecified. The conditional verification probabilities are estimated from a logistic regression model with V as the response and T as predictor. Clearly, also this model is misspecified.
Table 3 presents Monte Carlo means and standard deviations (across 5,000 replications) for the estimators of the sensitivity and the specificity. Results concern the estimators IPW, MSI, SPE, 1NN and 3NN. Moreover, results for the estimators based on complete data (denoted by “Full” in the table), that is with all cases verified, are also presented. Given the large sample size utilized in this setting, we expect that the Monte Carlo means for the Full estimators represent a good approximation of the true values of the sensitivity and the specificity and they are therefore used as the benchmark values.
Mean estimated sensitivity, mean estimated specificity and standard deviation (in brackets) from 5,000 replications when both models for
| IPW | MSI | SPE | 1NN | 3NN | Full | |
| Sensitivity | ||||||
| c = 0.2 | ||||||
| 0.1 | 0.778 (0.052) | 0.868 (0.029) | 0.846 (0.051) | 0.888 (0.055) | 0.885 (0.047) | |
| 0.3 | 0.767 (0.060) | 0.877 (0.029) | 0.858 (0.061) | 0.889 (0.054) | 0.885 (0.048) | |
| 0.5 | 0.752 (0.077) | 0.887 (0.030) | 0.870 (0.083) | 0.886 (0.057) | 0.882 (0.049) | 0.888 (0.020) |
| 0.7 | 0.736 (0.108) | 0.898 (0.032) | 0.893 (0.158) | 0.886 (0.060) | 0.880 (0.052) | |
| 0.9 | 0.744 (0.169) | 0.903 (0.040) | 0.929 (0.731) | 0.879 (0.067) | 0.871 (0.058) | |
| 0.1 | 0.685 (0.051) | 0.778 (0.039) | 0.759 (0.050) | 0.818 (0.064) | 0.814 (0.056) | |
| 0.3 | 0.679 (0.060) | 0.794 (0.040) | 0.778 (0.060) | 0.821 (0.065) | 0.816 (0.056) | |
| 0.5 | 0.671 (0.074) | 0.810 (0.041) | 0.796 (0.077) | 0.821 (0.066) | 0.816 (0.058) | 0.820 (0.024) |
| 0.7 | 0.663 (0.100) | 0.828 (0.043) | 0.819 (0.250) | 0.820 (0.068) | 0.813 (0.060) | |
| 0.9 | 0.684 (0.164) | 0.839 (0.056) | 0.908 (3.428) | 0.813 (0.080) | 0.803 (0.070) | |
| 0.1 | 0.593 (0.049) | 0.672 (0.046) | 0.658 (0.051) | 0.738 (0.069) | 0.734 (0.061) | |
| 0.3 | 0.590 (0.056) | 0.691 (0.047) | 0.678 (0.058) | 0.739 (0.069) | 0.734 (0.061) | |
| 0.5 | 0.588 (0.070) | 0.713 (0.049) | 0.701 (0.072) | 0.737 (0.071) | 0.732 (0.063) | 0.737 (0.028) |
| 0.7 | 0.593 (0.093) | 0.739 (0.053) | 0.733 (0.103) | 0.738 (0.074) | 0.731 (0.066) | |
| 0.9 | 0.638 (0.153) | 0.759 (0.066) | 0.867 (3.715) | 0.732 (0.084) | 0.724 (0.074) | |
| Specificity | ||||||
| 0.1 | 0.776 (0.031) | 0.649 (0.024) | 0.641 (0.028) | 0.603 (0.026) | 0.603 (0.024) | |
| 0.3 | 0.799 (0.032) | 0.637 (0.023) | 0.630 (0.028) | 0.603 (0.026) | 0.603 (0.024) | |
| 0.5 | 0.827 (0.032) | 0.626 (0.023) | 0.620 (0.031) | 0.603 (0.027) | 0.603 (0.024) | 0.602 (0.018) |
| 0.7 | 0.865 (0.033) | 0.614 (0.021) | 0.607 (0.096) | 0.603 (0.028) | 0.603 (0.025) | |
| 0.9 | 0.914 (0.030) | 0.604 (0.021) | 0.613 (0.661) | 0.602 (0.029) | 0.602 (0.026) | |
| 0.1 | 0.870 (0.022) | 0.788 (0.021) | 0.782 (0.024) | 0.742 (0.025) | 0.742 (0.022) | |
| 0.3 | 0.885 (0.022) | 0.776 (0.021) | 0.772 (0.024) | 0.743 (0.025) | 0.743 (0.022) | |
| 0.5 | 0.903 (0.021) | 0.765 (0.020) | 0.762 (0.024) | 0.743 (0.025) | 0.743 (0.022) | 0.743 (0.016) |
| 0.7 | 0.926 (0.019) | 0.755 (0.020) | 0.751 (0.028) | 0.743 (0.025) | 0.743 (0.022) | |
| 0.9 | 0.956 (0.016) | 0.745 (0.019) | 0.739 (0.221) | 0.743 (0.027) | 0.744 (0.023) | |
| 0.1 | 0.932 (0.015) | 0.887 (0.016) | 0.885 (0.018) | 0.852 (0.022) | 0.852 (0.018) | |
| 0.3 | 0.939 (0.014) | 0.879 (0.016) | 0.876 (0.018) | 0.852 (0.021) | 0.852 (0.018) | |
| 0.5 | 0.948 (0.013) | 0.870 (0.016) | 0.868 (0.018) | 0.852 (0.020) | 0.853 (0.018) | 0.852 (0.013) |
| 0.7 | 0.961 (0.011) | 0.862 (0.016) | 0.860 (0.019) | 0.852 (0.021) | 0.853 (0.018) | |
| 0.9 | 0.976 (0.009) | 0.854 (0.015) | 0.851 (0.055) | 0.852 (0.022) | 0.854 (0.018) | |
Table 3 clearly shows limitations of parametric estimators when models for
Overall, the new estimators 1NN and 3NN perform well in terms of both bias and standard deviation. In particular, they yield estimates that are, in all cases, close to the full data estimates (see also results in Section S3, Supplementary Material, where some simulations have been produced for a smaller sample size). The estimator 3NN appears to be slightly more biased than 1NN, but, on the other side, with slightly less variance. Note that in this setting the function
5 An illustration
To illustrate the application of the method developed in the previous sections, we utilize the Wisconsin Breast Cancer Data, publicly available at the UCI Machine Learning Repository [11]. The construction of the dataset was motivated by the need to accurately diagnose breast masses on the basis, solely, of a Fine Needle Aspiration (FNA). The dataset collects various features which are computed from a digitized image of a FNA of a breast mass, describing characteristics of the cell nuclei present in the image. A total of 30 nuclear features are computed on each of 569 samples, of which 357 are benign and 212 malignant. The dataset has been extensively used in the literature. The interested reader can refer to the UCI Machine Learning Repository documentation for retrieving information about the dataset creation, the description of its attributes, and a list of relevant papers using or citing this data set.
Here, we use one of the features, i.e., the worst radius (WR), as the test to diagnose malignant breast masses, and one of the remaining features, i.e., the worst concave point (WCP), as a covariate giving auxiliary information. Our aim is to estimate the ROC curve of the test WR. To mimic verification bias, a subset of the complete dataset is constructed. In this subset, the test WR and the covariate WCP are known for all samples, but the true status (benign or malignant) is available only for some samples, that we select according to the following mechanism. We select all samples having a value for both WR and WCP above their respective medians; we do not select samples having a value for both WR and WCP below their respective medians; we select all remaining samples with probability equal to 0.95.
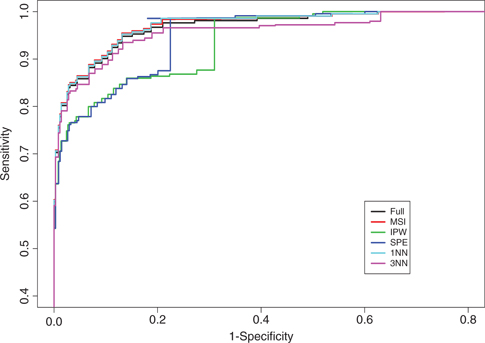
Illustrative example: estimated ROC curves of the test WR.
The obtained dataset shows a percentage of samples with true status known (verified) of about
As traditional methods (MSI, IPW, SPE) require the use of parametric regression models for the conditional probability of a sample being malignant and/or selected (i.e., with the true status known), we use a generalized linear model for the status given WR and WCP with probit link to estimate the conditional disease probabilities, and a logistic regression model with WR and WCP as predictors to estimate the conditional selection probabilities. Clearly, this last model is misspecified.
Figure 1 shows the estimated ROC curves of the test WR obtained with the IPW, MSI, SPE, 1NN and 3NN methods. Such curves are benchmarked with the estimated ROC curve obtained from the complete dataset by using the Full estimator of sensitivity and specificity. The plot shows that the estimators MSI, 1NN and 3NN well behave, whereas the estimators IPW and SPE are highly biased. This could imply that, in our data, the probit model is a good approximation of the disease process, whereas misspecification of the selection model seems to highly affect the estimators IPW and SPE. This is somehow surprising, as far as the doubly robust SPE estimator is concerned, especially taking into account the good behavior of the MSI estimator. It is worth noting, however, that the SPE estimator produces estimates that are outside the range
Illustrative example: estimates for the pair (sensitivity, specificity) of the test WR obtained by the various methods at different values of the cutpoint c.
| c | Full | MSI | IPW | SPE | 1NN | 3NN |
| 14.569 | (0.976, 0.728) | (0.984, 0.730) | (0.987, 0.558) | (0.986, 0.781) | (0.986, 0.732) | (0.966, 0.728) |
| 14.710 | (0.976, 0.739) | (0.984, 0.741) | (0.987, 0.561) | (0.986, 0.793) | (0.986, 0.743) | (0.966, 0.739) |
| 14.851 | (0.976, 0.765) | (0.984, 0.766) | (0.987, 0.569) | (0.986, | (0.986, 0.768) | (0.966, 0.765) |
| 14.993 | (0.967, 0.790) | (0.974, 0.791) | (0.877, 0.690) | (0.875, | (0.976, 0.793) | (0.955, 0.789) |
| 15.134 | (0.958, 0.812) | (0.964, 0.813) | (0.868, 0.724) | (0.867, | (0.962, 0.813) | (0.944, 0.811) |
| 15.275 | (0.953, 0.826) | (0.960, 0.827) | (0.864, 0.777) | (0.863, | (0.957, 0.827) | (0.940, 0.825) |
| 15.417 | (0.948, 0.849) | (0.955, 0.849) | (0.860, 0.813) | (0.859, 0.838) | (0.953, 0.849) | (0.935, 0.847) |
| 15.558 | (0.934, 0.868) | (0.941, 0.869) | (0.847, 0.860) | (0.846, 0.859) | (0.938, 0.869) | (0.921, 0.867) |
6 Variance estimation
In this section, we describe an approach to obtain estimates of the variances of the estimators proposed in Section 3. Such estimates could be used to build confidence intervals and perform hypothesis testing.
Recall that
From Section 3,
This result follows by an application of Theorem 1 in Ning and Cheng [9]. Note that, in the expression of
Similarly, for the asymptotic variance of
Define
and
be the KNN imputation estimators of
It is easy to see that
Finally, recall that
and
To obtain consistent estimates of the asymptotic variances given above, we may replace the unknown quantities in their expressions by the corresponding estimates. In particular, to estimate
In a nonparametric regression imputation framework, quantities as
and
from which, together with
For each parameter: relative biases, computed as
| c = 0.2 | 1NN | 0.092 | 0.027 | –0.011 | 0.126 | 0.049 | 0.125 | –0.011 | |
| 3NN | 0.081 | 0.000 | –0.030 | 0.077 | 0.036 | 0.067 | –0.034 | ||
| c = 0.5 | 1NN | 0.075 | –0.038 | 0.030 | 0.131 | 0.069 | 0.071 | 0.036 | |
| 3NN | 0.066 | –0.055 | 0.000 | 0.104 | 0.053 | 0.046 | 0.006 | ||
| c = 0.8 | 1NN | 0.126 | 0.022 | –0.026 | 0.134 | 0.125 | 0.067 | –0.030 | |
| 3NN | 0.118 | 0.000 | –0.086 | 0.112 | 0.116 | 0.047 | –0.063 | ||
| c = 0.2 | 1NN | 0.048 | 0.024 | 0.027 | 0.087 | 0.034 | 0.098 | 0.031 | |
| 3NN | 0.045 | 0.020 | 0.006 | 0.000 | 0.027 | 0.022 | 0.011 | ||
| c = 0.5 | 1NN | 0.022 | –0.011 | –0.056 | 0.060 | 0.024 | 0.082 | –0.050 | |
| 3NN | 0.032 | –0.017 | –0.078 | 0.022 | 0.020 | 0.040 | –0.070 | ||
| c = 0.8 | 1NN | 0.022 | –0.013 | –0.017 | 0.067 | 0.004 | 0.073 | –0.020 | |
| 3NN | 0.023 | –0.019 | –0.056 | 0.048 | 0.004 | 0.049 | –0.043 | ||
| c = 0.2 | 1NN | 0.023 | 0.014 | 0.022 | –0.250 | 0.016 | –0.067 | 0.021 | |
| 3NN | 0.028 | 0.015 | 0.006 | –0.250 | 0.020 | –0.170 | 0.007 | ||
| c = 0.5 | 1NN | 0.023 | 0.025 | –0.008 | 0.000 | –0.013 | 0.031 | –0.014 | |
| 3NN | 0.024 | 0.020 | –0.016 | –0.083 | –0.013 | –0.034 | –0.024 | ||
| c = 0.8 | 1NN | 0.050 | 0.021 | –0.012 | 0.000 | 0.021 | 0.014 | –0.014 | |
| 3NN | 0.047 | 0.016 | –0.025 | –0.036 | 0.017 | –0.010 | –0.030 |
To assess the behavior of the discussed variance estimators, we performed some simulation experiments. The results are given in Table 5. For the parameters
In summary, results in Table 5 (and in Section S3, Supplementary Material) seem to indicate that the proposed variance estimators behave satisfactorily. Of course, other variance estimators could be retrieved. For example one could, at least in principle, resort on resampling strategies. Naturally, this requires further investigation.
7 Discussion
This paper considers the estimation of the ROC curve of a continuous test under verification bias. Existing methods for correcting verification bias require estimation of
The new estimators of sensitivity and specificity (6) are fully nonparametric. Their use reduces the effects of possible misspecification to the inference results. The loss of efficiency with respect to the use of parametric competitors (when these can be reasonably employed) can range from minimal to sensible values according to the nature of the problem at hand, as simulation results in the main paper and in Supplementary Material, Section S4 show. This is somehow intrinsic in the nonparametric nature of the proposed estimators.
The new approach is based on the K-nearest-neighbor imputation, which requires the choice of a value for K. Our simulation results (see also the Supplementary Material) seem to confirm results in Ning and Cheng [9] according to which a small value of K-within the range 1–3 may be a good choice. It is worth noting, however, that the choice of K might depend upon the dimension of the feature space. In our study, the feature space includes the diagnostic test result T and the an auxiliary covariate X of dimension 1 (and 3, see Section S4, Supplementary Material). A small number of features is quite common in the context of the evaluation of diagnostic tests. However, if the number of features increases, it could be convenient to consider higher values for
The issue of the choice of the distance measure to use is of more general nature. Our simulation results (see Supplementary Material) seem to indicate that the standard Euclidean distance may be a good choice. However, it is clear that an adequate choice ultimately depends on several aspects, such as features of the data to analyze, as well as computational concerns.
Estimators (6) modify in an obvious way when no covariates are measured, i.e., when
where
As suggested by a Referee, one could think of possible devices aimed at enhancing performances of the estimators. One possibility could be to assign unequal weights to the K nearest neighbors entering in the estimates
Acknowledgement
The contribution of Stefano Mussi in producing some simulation results in Supplementary Material is gratefully acknowledged.
References
1. BeggCB, GreenesRA. Assessment of diagnostic tests when disease verification is subject to selection bias. Biometrics1983;39:207–15.10.2307/2530820Search in Google Scholar
2. BeggCB. Biases in the assessment of diagnostic tests. Statist Med1987;6:411–23.10.1002/sim.4780060402Search in Google Scholar PubMed
3. ZhouX-H. Correcting for verification bias in studies of a diagnostic test’s accuracy. Stat Meth Med Res1998;7:337–53.10.1191/096228098676485370Search in Google Scholar
4. ZhouX-H, ObuchowskiNA, McClishDK. Statistical methods in diagnostic medicine. New York: Wiley-Interscience, 2002.Search in Google Scholar
5. AlonzoTA, PepeMS. Assessing accuracy of a continuous screening test in the presence of verification bias. J R Stat Soc Ser C2005;54:173–90.10.1111/j.1467-9876.2005.00477.xSearch in Google Scholar
6. FlussR, ReiserB, FaraggiD, RotnitzkyA. Estimation of the ROC curve under verification bias. Biometrical J2009;51:475–90.10.1002/bimj.200800128Search in Google Scholar PubMed PubMed Central
7. LiuD, ZhouXH. A model for adjusting for nonignorable verification bias in estimation of the ROC curve and its area with likelihood-based approach. Biometrics2010;66:1119–28.10.1111/j.1541-0420.2010.01397.xSearch in Google Scholar PubMed PubMed Central
8. HeH, McDermottMP. A robust method using propensity score stratification for correcting verification bias for binary tests. Biostatistics2012;13:32–47.10.1093/biostatistics/kxr020Search in Google Scholar PubMed PubMed Central
9. NingJ, ChengPE. A comparison study of nonparametric imputation methods. Statist Comput2012;22:273–85.10.1007/s11222-010-9223-ySearch in Google Scholar
10. AlonzoTA, PepeMS. Estimating disease prevalence in two-phase studies. Biostatistics2003;4:313–23.10.1093/biostatistics/4.2.313Search in Google Scholar PubMed
11. AsuncionA, NewmanDJ. UCI machine learning repository. Irvine, CA: School of Information and Computer Science, University of California, 2007. Available at: http://www.ics.uci.edu/mlearn/MLRepository.htmlSearch in Google Scholar
12. ChengPE. Nonparametric estimation of mean functionals with data missing at random. J Am Stat Assoc1994;89:81–7.10.1080/01621459.1994.10476448Search in Google Scholar
Supplemental Material
The online version of this article (DOI: 10.1515/ijb-2014-0014) offers supplementary material, available to authorized users.
© 2015 Walter de Gruyter GmbH, Berlin/Boston
Articles in the same Issue
- Frontmatter
- Research Articles
- Within-Subject Mediation Analysis in AB/BA Crossover Designs
- Conditional Transformation Models for Survivor Function Estimation
- A Universal Approximate Cross-Validation Criterion for Regular Risk Functions
- Double Bias: Estimation of Causal Effects from Length-Biased Samples in the Presence of Confounding
- Flexible Regression Models for Rate Differences, Risk Differences and Relative Risks
- Nearest-Neighbor Estimation for ROC Analysis under Verification Bias
- Quantifying an Agreement Study
- Robust Bayesian Sensitivity Analysis for Case–Control Studies with Uncertain Exposure Misclassification Probabilities
- A Semi-stationary Copula Model Approach for Bivariate Survival Data with Interval Sampling
- Comparison of Splitting Methods on Survival Tree
Articles in the same Issue
- Frontmatter
- Research Articles
- Within-Subject Mediation Analysis in AB/BA Crossover Designs
- Conditional Transformation Models for Survivor Function Estimation
- A Universal Approximate Cross-Validation Criterion for Regular Risk Functions
- Double Bias: Estimation of Causal Effects from Length-Biased Samples in the Presence of Confounding
- Flexible Regression Models for Rate Differences, Risk Differences and Relative Risks
- Nearest-Neighbor Estimation for ROC Analysis under Verification Bias
- Quantifying an Agreement Study
- Robust Bayesian Sensitivity Analysis for Case–Control Studies with Uncertain Exposure Misclassification Probabilities
- A Semi-stationary Copula Model Approach for Bivariate Survival Data with Interval Sampling
- Comparison of Splitting Methods on Survival Tree