Testing lexical specificity hypotheses in world Englishes: evidence from the null subject alternation
-
Iván Tamaredo



Abstract
The present paper tests a series of hypotheses dealing with variation, across dialects of English, in the degree of lexical specificity of constructions. The study focuses on the null subject alternation, which is conceptualized here as consisting of two allostructions, the null and overt variants, of a more schematic constructeme. Five hypotheses put forward in the specialized literature are adapted to the null subject alternation and tested on a dataset of null and overt subjects extracted from GloWbE by means of five indexes of frequency and lexical specificity. The results confirm four of the five hypotheses and provide further support to the claim that speakers of varieties of English in earlier phases in Schneider’s Dynamic Model rely more on partially lexically filled constructions.
Funding source: Spanish Ministry of Science, Innovation and Universities
Award Identifier / Grant number: PID2023-146887NB-I00
Acknowledgments
I am grateful to two anonymous reviewers for their helpful and constructive comments on an earlier version of the paper.
-
Research ethics: Not applicable.
-
Informed consent: Not applicable.
-
Author contributions: The author has accepted responsibility for the entire content of this manuscript and approved its submission.
-
Use of Large Language Models, AI and Machine Learning Tools: None declared.
-
Conflict of interest: The author states no conflict of interest.
-
Research funding: This research was conducted with the financial support of the Spanish Ministry of Science, Innovation and Universities (grant PID2023-146887NB-I00).
-
Data availability: The raw data can be obtained on request from the corresponding author.
This appendix contains more detailed information about the indexes of productivity, prototypical fillers, allostructional asymmetry, and probabilistic indigenization. In particular, the data used to calculate the indexes is presented and briefly discussed.
A. Productivity index
As mentioned in Section 2.2, the index of productivity is calculated on the basis of LNRE models computed for each allostruction and phase (cf. Table A1 for goodness-of-fit statistics of these models). Using the results of finite Zipft-Mandelbrot LNRE models, and considering the different sizes of the subcorpora examined, the number of different verb types used with each allostruction is predicted at different sample sizes, up to 1,500 tokens (cf. Figure A1). This threshold was established because the largest sample in the data is that of Phase 5, with 1,186 and 1,119 null and overt subjects, respectively. The productivity index is then the result of dividing the number of verb types of the null subject allostruction, predicted at a size of 1,500 tokens, by the number of predicted verb types of the overt subject allostruction (cf. Table A2).
Goodness-of-fit statistics of LNRE models.
| Phase 2 | Phase 3 | Phase 4 | Phase 5 | |||||
|---|---|---|---|---|---|---|---|---|
| Null | Overt | Null | Overt | Null | Overt | Null | Overt | |
| χ 2 | 3.731 | 7.502 | 4.038 | 1.658 | 1.750 | 6.200 | 2.072 | 4.942 |
| df | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 4 |
| p | 0.292 | 0.058 | 0.257 | 0.646 | 0.626 | 0.102 | 0.557 | 0.293 |
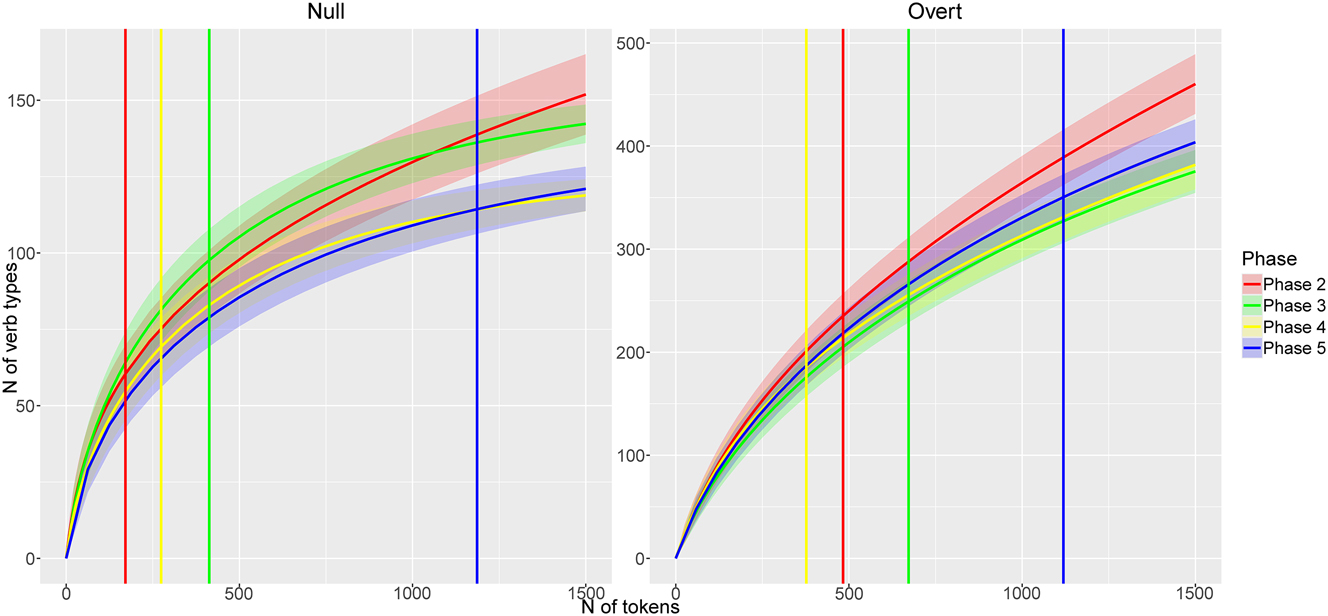
Verb types per phase of the null (left) and overt (right) subject allostructions; vertical lines indicate observed sample sizes; shaded areas around lines represent confidence intervals.
Predicted verb types at a sample size of 1,500 tokens of the null and overt subject allostructions per phase.
| Phase 2 | Phase 3 | Phase 4 | Phase 5 | |
|---|---|---|---|---|
| Null subjects | 151.95 | 142.30 | 118.87 | 121.00 |
| Overt subjects | 460.18 | 375.40 | 381.81 | 403.66 |
| Productivity index | 0.33 | 0.38 | 0.31 | 0.30 |
B. Prototypical fillers index
The prototypical fillers index is calculated on the basis of the results of DCA. In the present study, DCA was used to uncover the verb lemmas that are significantly associated with each of the allostructions of the null subject alternation per phase of development (cf. Tables A3–A6). Then, for each allostruction in each phase, the percentage of significant verb lemmas is calculated out of the total number of verb lemmas used in the verb slot of the allostruction. Finally, the index is calculated by dividing the percentage of significant verb lemmas of the null subject allostruction by the percentage of significant verb lemmas of the overt variant (cf. Table A7).
Significant verb lemmas of the null and overt subject allostructions in phase 2 varieties.
| Lemma | Obs. freq. null | Obs. freq. overt | Exp. freq. null | Exp. freq. overt | Preference | Coll. strength | Significance |
|---|---|---|---|---|---|---|---|
| Sound | 22 | 0 | 5.752 | 16.248 | Null | 13.275 | *** |
| Make | 19 | 10 | 7.583 | 21.417 | Null | 5.228 | *** |
| Seem | 10 | 2 | 3.138 | 8.862 | Null | 4.317 | *** |
| Include | 6 | 1 | 1.830 | 5.170 | Null | 2.786 | ** |
| Look | 9 | 5 | 3.661 | 10.339 | Null | 2.565 | ** |
| Depend | 4 | 0 | 1.046 | 2.954 | Null | 2.342 | ** |
| Take | 5 | 2 | 1.830 | 5.170 | Null | 1.817 | * |
| Provide | 3 | 0 | 0.784 | 2.216 | Null | 1.753 | * |
| Happen | 4 | 1 | 1.307 | 3.693 | Null | 1.743 | * |
| Mean | 7 | 6 | 3.399 | 9.601 | Null | 1.530 | * |
| Say | 5 | 62 | 17.518 | 49.482 | Overt | 4.280 | *** |
| Ask | 0 | 11 | 2.876 | 8.124 | Overt | 1.461 | * |
-
Significance levels are as follows: ‘***’ equals p < 0.001, ‘**’ stands for p < 0.01, and ‘*’ means p < 0.05.
Significant verb lemmas of the null and overt subject allostructions in phase 3 varieties.
| Lemma | Obs. freq. null | Obs. freq. overt | Exp. freq. null | Exp. freq. overt | Preference | Coll. strength | Significance |
|---|---|---|---|---|---|---|---|
| Sound | 57 | 2 | 22.458 | 36.542 | Null | 22.149 | *** |
| Remind | 23 | 1 | 9.135 | 14.865 | Null | 8.625 | *** |
| Include | 19 | 3 | 8.374 | 13.626 | Null | 5.459 | *** |
| Make | 39 | 20 | 22.458 | 36.542 | Null | 5.164 | *** |
| Require | 5 | 0 | 1.903 | 3.097 | Null | 2.104 | ** |
| Happen | 8 | 2 | 3.806 | 6.194 | Null | 2.073 | ** |
| Return | 8 | 2 | 3.806 | 6.194 | Null | 2.073 | ** |
| Contain | 7 | 2 | 3.426 | 5.574 | Null | 1.740 | * |
| Look | 13 | 8 | 7.994 | 13.006 | Null | 1.660 | * |
| Support | 6 | 2 | 3.045 | 4.955 | Null | 1.417 | * |
| Help | 11 | 7 | 6.852 | 11.148 | Null | 1.410 | * |
| Say | 5 | 69 | 28.168 | 45.832 | Overt | 9.674 | *** |
| Tell | 2 | 16 | 6.852 | 11.148 | Overt | 1.920 | * |
| Ask | 0 | 8 | 3.045 | 4.955 | Overt | 1.671 | * |
| Offer | 0 | 7 | 2.665 | 4.335 | Overt | 1.462 | * |
-
Significance levels are as follows: ‘***’ equals p < 0.001, ‘**’ stands for p < 0.01, and ‘*’ means p < 0.05.
Significant verb lemmas of the null and overt subject allostructions in phase 4 varieties.
| Lemma | Obs. freq. null | Obs. freq. overt | Exp. freq. null | Exp. freq. overt | Preference | Coll. strength | Significance |
|---|---|---|---|---|---|---|---|
| Sound | 44 | 2 | 19.361 | 26.639 | Null | 14.864 | *** |
| Make | 45 | 7 | 21.886 | 30.114 | Null | 11.182 | *** |
| Seem | 13 | 0 | 5.472 | 7.528 | Null | 4.959 | *** |
| Remind | 14 | 2 | 6.734 | 9.266 | Null | 3.684 | *** |
| Bring | 6 | 0 | 2.525 | 3.475 | Null | 2.269 | ** |
| Represent | 5 | 0 | 2.104 | 2.896 | Null | 1.888 | * |
| Save | 4 | 0 | 1.684 | 2.316 | Null | 1.509 | * |
| Include | 7 | 2 | 3.788 | 5.212 | Null | 1.483 | * |
| Say | 6 | 33 | 16.415 | 22.585 | Overt | 3.612 | *** |
| Tell | 3 | 19 | 9.26 | 12.74 | Overt | 2.409 | ** |
| Ask | 0 | 8 | 3.367 | 4.633 | Overt | 1.912 | * |
| Know | 0 | 6 | 2.525 | 3.475 | Overt | 1.431 | * |
-
Significance levels are as follows: ‘***’ equals p < 0.001, ‘**’ stands for p < 0.01, and ‘*’ means p < 0.05.
Significant verb lemmas of the null and overt subject allostructions in phase 5 varieties.
| Lemma | Obs. freq. null | Obs. freq. overt | Exp. freq. null | Exp. freq. overt | Preference | Coll. strength | Significance |
|---|---|---|---|---|---|---|---|
| Sound | 180 | 11 | 98.276 | 92.724 | Null | 40.736 | *** |
| Make | 178 | 25 | 104.45 | 98.55 | Null | 29.543 | *** |
| Seem | 113 | 17 | 66.889 | 63.111 | Null | 17.804 | *** |
| Include | 56 | 3 | 30.357 | 28.643 | Null | 12.816 | *** |
| Depend | 23 | 1 | 12.349 | 11.651 | Null | 5.594 | *** |
| Look | 65 | 22 | 44.764 | 42.236 | Null | 5.284 | *** |
| Remind | 30 | 4 | 17.494 | 16.506 | Null | 5.244 | *** |
| Give | 35 | 16 | 26.241 | 24.759 | Null | 2.043 | ** |
| Save | 9 | 1 | 5.145 | 4.855 | Null | 1.872 | * |
| Allow | 15 | 5 | 10.291 | 9.709 | Null | 1.560 | * |
| Help | 21 | 10 | 15.951 | 15.049 | Null | 1.312 | * |
| Say | 45 | 93 | 71.006 | 66.994 | Overt | 5.496 | *** |
| Ask | 0 | 13 | 6.689 | 6.311 | Overt | 4.096 | *** |
| Tell | 8 | 25 | 16.98 | 16.02 | Overt | 2.903 | ** |
| Think | 1 | 11 | 6.174 | 5.826 | Overt | 2.638 | ** |
| Mean | 2 | 12 | 7.203 | 6.797 | Overt | 2.331 | ** |
| Know | 6 | 19 | 12.863 | 12.137 | Overt | 2.330 | ** |
| Cite | 0 | 7 | 3.602 | 3.398 | Overt | 2.201 | ** |
| Play | 2 | 11 | 6.689 | 6.311 | Overt | 2.077 | ** |
| Feature | 0 | 6 | 3.087 | 2.913 | Overt | 1.886 | * |
| Involve | 0 | 6 | 3.087 | 2.913 | Overt | 1.886 | * |
| Live | 0 | 6 | 3.087 | 2.913 | Overt | 1.886 | * |
| Point | 0 | 6 | 3.087 | 2.913 | Overt | 1.886 | * |
| State | 0 | 6 | 3.087 | 2.913 | Overt | 1.886 | * |
| Offer | 0 | 5 | 2.573 | 2.427 | Overt | 1.571 | * |
| Remain | 0 | 5 | 2.573 | 2.427 | Overt | 1.571 | * |
| Stop | 0 | 5 | 2.573 | 2.427 | Overt | 1.571 | * |
| Speak | 2 | 8 | 5.145 | 4.855 | Overt | 1.348 | * |
| Get | 10 | 19 | 14.921 | 14.079 | Overt | 1.313 | * |
-
Significance levels are as follows: ‘***’ equals p < 0.001, ‘**’ stands for p < 0.01, and ‘*’ means p < 0.05.
Percentage of significant verb lemmas per phase.
| Phase 2 | Phase 3 | Phase 4 | Phase 5 | |
|---|---|---|---|---|
| N of significant lemmas – null | 10 | 11 | 8 | 11 |
| Total n of lemmas – null | 57 | 97 | 69 | 114 |
| % Of significant lemmas – null | 17.54 | 11.34 | 11.59 | 9.65 |
| N of significant lemmas – overt | 2 | 4 | 4 | 18 |
| Total n of lemmas – overt | 220 | 250 | 174 | 348 |
| % Of significant lemmas – overt | 0.91 | 1.60 | 2.30 | 5.17 |
| Prototypical fillers index | 19.27 | 7.09 | 5.04 | 1.87 |
C. Allostructional asymmetry index
The allostructional asymmetry index is calculated by dividing the percentage of verb lemmas shared by both allostructions, out of the total number of verb lemmas in the null subject allostruction, by the percentage of shared verb lemmas in the overt allostruction (cf. Table A8).
Percentage of shared verb lemmas out of the total number of verb lemmas of the null and overt subject allostructions per phase.
| Phase 2 | Phase 3 | Phase 4 | Phase 5 | |
|---|---|---|---|---|
| N of shared lemmas | 39 | 79 | 49 | 101 |
| Total n of lemmas – null | 57 | 97 | 69 | 114 |
| % Of shared lemmas – null | 68.42 | 81.44 | 71.01 | 88.60 |
| Total n of lemmas – overt | 220 | 250 | 174 | 348 |
| % Of shared lemmas – overt | 17.73 | 31.60 | 28.16 | 29.02 |
| All. asymmetry index | 3.86 | 2.58 | 2.52 | 3.05 |
D. Probabilistic indigenization index
The probabilistic indigenization index is calculated on the basis of the results of VADIS, a method to measure the degree of grammatical dissimilarity between varieties of English developed by Szmrecsanyi and colleagues (Szmrecsanyi et al. 2019; Szmrecsanyi and Grafmiller 2023). As mentioned in Section 2.2, VADIS examines probabilistic differences in the grammars of varieties of English along three lines of evidence: (i) Do the same variables have a statistically significant effect across varieties? (ii) Are probabilistic constraints similar with respect to the size of their effects across varieties? (iii) Do the constraints have the same relative importance in all the varieties considered?
VADIS is carried out in three steps. First, a mixed-effects binary logistic regression model (e.g., Baayen 2008: Ch. 7) is calculated for each phase using the same formula (cf. Tables A9–A13); in the present study, the allostruction (overt vs. null) was the response variable, the constraints in Table 1 were included as fixed predictors, while verb lemma was the only random predictor in the models. Second, a score reflecting the dissimilarities between phases is calculated for each of the three lines of evidence. The first score, statistical significance, is derived from the number of significant and non-significant constraints shared by the phases. The second score, effect size, is computed as the difference between the coefficient estimates in the per-phase mixed-effects models. The third score, constraint ranking, is computed from the Spearman’s rank correlation coefficients between the factor’s variable importance values. Finally, a mean dissimilarity score is calculated per phase by averaging over the three scores (cf. Table A14). This dissimilarity score, which reflects how different the probabilistic grammar of one phase is from the rest, constitutes the probabilistic indigenization index.
Data for mixed-effects models.
| Constraint | Overt | Null | Total | |||
|---|---|---|---|---|---|---|
| N | % | N | % | |||
| Phase | Phase 2 | 483 | 73.85 | 171 | 26.15 | 654 |
| Phase 3 | 672 | 61.94 | 413 | 38.06 | 1,085 | |
| Phase 4 | 377 | 57.91 | 274 | 42.09 | 651 | |
| Phase 5 | 1,119 | 48.55 | 1,186 | 51.54 | 2,305 | |
| V. Semantics | Activity | 990 | 56.15 | 773 | 43.85 | 1,763 |
| Aspectual | 102 | 60.00 | 68 | 40.00 | 170 | |
| Causative | 73 | 47.40 | 81 | 52.60 | 154 | |
| Communication | 713 | 85.39 | 122 | 14.61 | 835 | |
| Existence | 252 | 35.95 | 449 | 64.05 | 701 | |
| Psychological | 433 | 46.76 | 493 | 53.24 | 926 | |
| Simple occ. | 88 | 60.27 | 58 | 39.73 | 146 | |
| Tense | Present | 1,092 | 39.15 | 1,697 | 60.85 | 2,789 |
| Past | 1,559 | 81.79 | 347 | 18.21 | 1,906 | |
| R. Continuity | Full | 678 | 45.75 | 804 | 54.25 | 1,482 |
| Maintenance | 1,449 | 67.96 | 683 | 32.04 | 2,132 | |
| Partial | 524 | 48.47 | 557 | 51.53 | 1,081 | |
| Persistence | Other | 1,361 | 58.69 | 958 | 41.31 | 2,319 |
| Pronoun | 983 | 58.86 | 687 | 41.14 | 1,670 | |
| Null | 307 | 43.48 | 399 | 56.52 | 706 | |
| Pronoun | It | 821 | 33.48 | 1,631 | 66.52 | 2,452 |
| S/he | 1,830 | 81.59 | 413 | 18.41 | 2,243 | |
| Total | 2,651 | 56.46 | 2,044 | 43.54 | 4,695 | |
Results and goodness-of-fit statistics of the phase 2 model.
| Fixed effects | ||||
|---|---|---|---|---|
| Predictor | Estimate | Standard error | z | p |
| Intercept | −0.228 | 0.449 | −0.509 | 0.611 |
| Verb semantics: aspectual | −0.571 | 0.838 | −0.681 | 0.496 |
| Verb semantics: causative | −1.590 | 1.183 | −1.344 | 0.179 |
| Verb semantics: communication | −1.329 | 0.562 | −2.363 | 0.018 |
| Verb semantics: existence | 0.222 | 0.569 | 0.390 | 0.697 |
| Verb semantics: psychological | −0.498 | 0.539 | −0.924 | 0.356 |
| Verb semantics: simple occ. | 0.006 | 0.779 | 0.008 | 0.994 |
| Tense: past | −1.496 | 0.323 | −4.637 | >0.001 |
| Ref. continuity: maintenance | −0.634 | 0.318 | −1.992 | 0.046 |
| Ref. continuity: partial | −0.322 | 0.373 | −0.864 | 0.388 |
| Persistence: pronoun | 0.226 | 0.292 | 0.773 | 0.439 |
| Persistence: null | 1.421 | 0.377 | 3.764 | >0.001 |
| Pronoun: S/he | −1.128 | 0.345 | −3.266 | 0.001 |
|
|
||||
| Random effects | ||||
|
|
||||
| Predictor | Standard deviation | |||
| Verb lemma | 1.372 | |||
|
|
||||
| Goodness-of-fit | ||||
|
|
||||
| C | 0.925 | |||
| Accuracy | 86.85 % | |||
Results and goodness-of-fit statistics of the phase 3 model.
| Fixed effects | ||||
|---|---|---|---|---|
| Predictor | Estimate | Standard error | z | p |
| Intercept | 0.592 | 0.284 | 2.087 | 0.037 |
| Verb semantics: aspectual | 0.880 | 0.667 | 1.321 | 0.186 |
| Verb semantics: causative | 0.316 | 0.689 | 0.458 | 0.647 |
| Verb semantics: communication | −1.231 | 0.427 | −2.880 | 0.004 |
| Verb semantics: existence | 0.152 | 0.408 | 0.372 | 0.710 |
| Verb semantics: psychological | −0.276 | 0.356 | −0.776 | 0.438 |
| Verb semantics: simple occ. | 0.981 | 0.665 | 1.475 | 0.140 |
| Tense: past | −1.504 | 0.220 | −6.850 | >0.001 |
| Ref. continuity: maintenance | −0.946 | 0.216 | −4.373 | >0.001 |
| Ref. continuity: partial | −0.243 | 0.264 | −0.919 | 0.358 |
| Persistence: pronoun | −0.478 | 0.205 | −2.326 | 0.020 |
| Persistence: null | 1.528 | 0.259 | 5.910 | >0.001 |
| Pronoun: S/he | −1.024 | 0.219 | −4.682 | >0.001 |
|
|
||||
| Random effects | ||||
|
|
||||
| Predictor | Standard deviation | |||
| Verb lemma | 1.066 | |||
|
|
||||
| Goodness-of-fit | ||||
|
|
||||
| C | 0.907 | |||
| Accuracy | 84.70 % | |||
Results and goodness-of-fit statistics of the phase 4 model.
| Fixed effects | ||||
|---|---|---|---|---|
| Predictor | Estimate | Standard error | z | p |
| Intercept | 0.409 | 0.377 | 1.085 | 0.278 |
| Verb semantics: aspectual | 0.245 | 0.810 | 0.302 | 0.762 |
| Verb semantics: causative | −0.805 | 0.802 | −1.003 | 0.316 |
| Verb semantics: communication | −0.523 | 0.527 | −0.993 | 0.321 |
| Verb semantics: existence | 0.380 | 0.488 | 0.777 | 0.437 |
| Verb semantics: psychological | 0.165 | 0.464 | 0.356 | 0.722 |
| Verb semantics: simple occ. | 0.243 | 0.816 | 0.298 | 0.766 |
| Tense: past | −0.836 | 0.298 | −2.809 | 0.005 |
| Ref. continuity: maintenance | −0.364 | 0.297 | −1.226 | 0.220 |
| Ref. continuity: partial | 0.082 | 0.326 | 0.251 | 0.802 |
| Persistence: pronoun | 0.209 | 0.276 | 0.757 | 0.449 |
| Persistence: null | 1.191 | 0.369 | 3.227 | 0.001 |
| Pronoun: S/he | −2.597 | 0.304 | −8.542 | >0.001 |
|
|
||||
| Random effects | ||||
|
|
||||
| Predictor | Standard deviation | |||
| Verb lemma | 1.083 | |||
|
|
||||
| Goodness-of-fit | ||||
|
|
||||
| C | 0.927 | |||
| Accuracy | 86.79 % | |||
Results and goodness-of-fit statistics of the phase 5 model.
| Fixed effects | ||||
|---|---|---|---|---|
| Predictor | Estimate | Standard error | z | p |
| Intercept | −0.556 | 0.279 | −1.993 | 0.046 |
| Verb semantics: aspectual | 1.386 | 0.616 | 2.249 | 0.025 |
| Verb semantics: causative | 0.395 | 0.700 | 0.565 | 0.572 |
| Verb semantics: Communication | −1.153 | 0.419 | −2.752 | 0.006 |
| Verb semantics: existence | 0.332 | 0.409 | 0.811 | 0.417 |
| Verb semantics: psychological | 0.218 | 0.354 | 0.617 | 0.537 |
| Verb semantics: simple occ. | 0.497 | 0.638 | 0.780 | 0.436 |
| Tense: past | −1.136 | 0.141 | −8.045 | >0.001 |
| Ref. continuity: maintenance | −0.271 | 0.145 | −1.874 | 0.061 |
| Ref. continuity: partial | −0.139 | 0.157 | −0.885 | 0.376 |
| Persistence: pronoun | 0.101 | 0.130 | 0.783 | 0.434 |
| Persistence: null | 0.823 | 0.175 | 4.696 | >0.001 |
| Pronoun: S/he | −1.032 | 0.152 | −6.812 | >0.001 |
|
|
||||
| Random effects | ||||
|
|
||||
| Predictor | Standard deviation | |||
| Verb lemma | 1.494 | |||
|
|
||||
| Goodness-of-fit | ||||
|
|
||||
| C | 0.902 | |||
| Accuracy | 82.30 % | |||
Dissimilarity scores.
| Phase 2 | Phase 3 | Phase 4 | Phase 5 | |
|---|---|---|---|---|
| Statistical significance | 0.14 | 0.19 | 0.19 | 0.19 |
| Effect strength | 0.76 | 0.57 | 0.63 | 0.60 |
| Constraint ranking | 0.19 | 0.27 | 0.34 | 0.19 |
| Prob. indigenization index | 0.36 | 0.34 | 0.39 | 0.33 |
References
Ariel, Mira. 2001. Accessibility theory: An overview. In Ted J. M. Sanders, Joost Schliperoord & Wilbert Spooren (eds.), Text representation: Linguistic and psycholinguistic aspects, 29–87. Amsterdam & Philadelphia: John Benjamins.10.1075/hcp.8.04ariSearch in Google Scholar
Baayen, R. H. 2008. Analyzing linguistic data: A practical introduction to statistics using R. Cambridge & New York: Cambridge University Press.10.1017/CBO9780511801686Search in Google Scholar
Bauer, Eva-Maria & Thomas Hoffmann. 2020. Turns Out is not ellipsis? A usage-based construction grammar view on reduced constructions. Acta Linguistica Hafniensia 52(2). 240–259. https://doi.org/10.1080/03740463.2020.1777036.Search in Google Scholar
Biber, Douglas, Stig Johansson, Geoffrey Leech, Susan Conrad & Edward Finegan. 1999. Longman grammar of spoken and written English. Harlow: Longman.Search in Google Scholar
Brunner, Thomas. 2022. Into-causatives in world Englishes. English World-Wide 43(1). 1–32. https://doi.org/10.1075/eww.21068.bru.Search in Google Scholar
Brunner, Thomas & Thomas Hoffmann. 2020. The way construction in world Englishes. English World-Wide 41(1). 1–32. https://doi.org/10.1075/eww.00038.bru.Search in Google Scholar
Brunner, Thomas & Thomas Hoffmann. 2022. Construction grammar meets the dynamic model. In Aloysius Ngefac, Hans-Georg Wolf & Thomas Hoffmann (eds.), World Englishes and creole languages today. Vol. 1: The schneiderian thinking and beyond, 25–38. München: Lincom.Search in Google Scholar
Bybee, Joan L. 2013. Usage-based theory and exemplar representations of constructions. In Thomas Hoffmann & Graeme Trousdale (eds.), The Oxford handbook of construction grammar, 49–60. Oxford: Oxford University Press.10.1093/oxfordhb/9780195396683.013.0004Search in Google Scholar
Cappelle, Bert. 2006. Particle placement and the case for ‘allostructions’. Constructions. https://hal.science/hal-01495786v1 (accessed 17 April 2025).Search in Google Scholar
Davies, Mark. 2013. Corpus of global web-based English: 1.9 billion words from speakers in 20 countries (GloWbE). https://corpus.byu.edu/glowbe/ (accessed 21 August 2023).Search in Google Scholar
De Troij, Robert. (in preparation). North and South, bottom to top. Using big data to model syntactic variation in Belgian and netherlandic Dutch. Leuven: KU Leuven Dissertation.Search in Google Scholar
De Vaere, Hilde, Julia Kolkmann & Thomas Belligh. 2020. Allostructions revisited. Journal of Pragmatics 170. 96–111. https://doi.org/10.1016/j.pragma.2020.08.016.Search in Google Scholar
Dryer, Matthew S. 2013. Expression of pronominal subjects. In Matthew S. Dryer & Martin Haspelmath (eds.), WALS online. Version 2020.4. Zenodo. http://wals.info/chapter/101 (accessed 27 August 2025).Search in Google Scholar
Evert, Stefan & Marco Baroni. 2020. zipfR: Statistical models for word frequency distributions Version 0.6-70 https://zipfr.r-forge.r-project.org/ (accessed 17 April 2025).Search in Google Scholar
Grafmiller, Jason & Melanie Röthlisberger. 2015. Syntactic alternations, schematization, and collostructional diversity in world Englishes. In Paper presented at the 21st conference of the international association of world englishes. Boğaziçi University 8–15 October.Search in Google Scholar
Gries, Stefan Th. 2007. Coll.analysis 3.2a. A program for R for windows 2.x.Search in Google Scholar
Gries, Stefan Th. 2017. Syntactic alternation research: Taking stock and some suggestions for the future. Belgian Journal of Linguistics 31. 8–29. https://doi.org/10.1075/bjl.00001.gri.Search in Google Scholar
Gries, Stefan Th. & Anatol Stefanowitsch. 2004. Extending collostructional analysis: A corpus-based perspective on ‘alternations’. International Journal of Corpus Linguistics 9(1). 97–129. https://doi.org/10.1075/ijcl.9.1.06gri.Search in Google Scholar
Hoffmann, Thomas. 2014. The cognitive evolution of Englishes: The role of constructions in the dynamic model. In Sarah Buschfeld, Thomas Hoffmann, Magnus Huber & Alexander Kautzsch (eds.), The evolution of Englishes: The dynamic model and beyond, 160–180. Amsterdam & Philadelphia: John Benjamins.10.1075/veaw.g49.10hofSearch in Google Scholar
Hoffmann, Thomas. 2019. English comparative correlatives: Diachronic and synchronic variation at the lexicon-syntax interface. Cambridge: Cambridge University Press.10.1017/9781108569859Search in Google Scholar
Hoffmann, Thomas. 2020. Marginal argument structure constructions: The [V the Ntaboo-word out of]-construction in postcolonial Englishes. Linguistics Vangard 6(1). 20190054. https://doi.org/10.1515/lingvan-2019-0054.Search in Google Scholar
Hoffmann, Thomas. 2021. The cognitive foundation of post-colonial Englishes: Construction grammar as the cognitive theory for the dynamic model (Elements in World Englishes). Cambridge: Cambridge University Press.10.1017/9781108909730Search in Google Scholar
Hoffmann, Thomas. 2025. Constructionist grammar and the dynamic model. In Sofia Rüdiger, Theresa Neumaer, Sevn Leuckert & Sarah Buschfeld (eds.), World Englishes in the 21st century: New perspectives and challenges to the dynamic model, 358–378. Edinburgh: Edinburgh University Press.Search in Google Scholar
Huddleston, Rodney, Geoffrey K. Pullum, Laurie Bauer, Betty Birner, Ted Briscoe, Peter Collins, David Denison, David Lee, Anita Mittwoch, Geoffrey Nunberg, Frank Palmer, John Payne, Peter Peterson, Lesley Stirling & Gregory Ward. 2002. The Cambridge grammar of the English language. Cambridge & New York: Cambridge University Press.Search in Google Scholar
Kachru, Yamuna. 2006. Hindi. Amsterdam & Philadelphia: John Benjamins.Search in Google Scholar
Langacker, Ronald W. 1987. Foundations of cognitive grammar. Volume 1. Theoretical prerequisites. Stanford: Stanford University Press.Search in Google Scholar
Loureiro-Porto, Lucía. 2017. ICE vs GloWbE: Big data and corpus compilation. World Englishes 36(3). 448–470. https://doi.org/10.1111/weng.12281.Search in Google Scholar
Mukherjee, Joybrato & Stefan Th. Gries. 2009. Collostructional nativization in new Englishes: Verb-construction associations in the international corpus of English. English World-Wide 30(1). 27–51. https://doi.org/10.1075/eww.30.1.03muk.Search in Google Scholar
Perek, Florent. 2012. Alternation-based generalizations are stored in the mental grammar: Evidence from a sorting task experiment. Cognitive Linguistics 23(3). 601–635. https://doi.org/10.1515/cog-2012-0018.Search in Google Scholar
Perlmutter, David M. 1971. Deep and surface constraints in generative grammar. New York: Holt, Rinehart and Winston.Search in Google Scholar
Quirk, Randolph, Sidney Greenbaum, Geoffrey Leech & Jan Svartvik. 1985. A comprehensive grammar of the English language. London & New York: Longman.Search in Google Scholar
Radford, Andrew. 2006. Minimalist syntax revisited. http://courses.essex.ac.uk/lg/lg514.Search in Google Scholar
Schneider, Edgar W. 2007. Postcolonial English: Varieties around the world. Cambridge & New York: Cambridge University Press.10.1017/CBO9780511618901Search in Google Scholar
Schröter, Verena. 2019. Null subjects in English: A comparison of British English and Asian Englishes. Berlin & Boston: De Gruyter Mouton.10.1515/9783110649260Search in Google Scholar
Schröter, Verena & Bernd Kortmann. 2016. Pronoun deletion in Hong Kong English and colloquial Singaporean English. World Englishes 35(2). 221–241. https://doi.org/10.1111/weng.12192.Search in Google Scholar
Steger, Maria & Edgar W. Schneider. 2012. Complexity as a function of iconicity: The case of complement clause constructions in new Englishes. In Bernd Kortmann & Benedikt Szmrecsanyi (eds.), Linguistic complexity: Second language acquisition, indigenization, contact, 156–191. Berlin & Boston: De Gruyter.10.1515/9783110229226.156Search in Google Scholar
Súarez-Gómez, Cristina. 2014. Relative clauses in Southeast Asian Englishes. Journal of English Linguistics 42(3). 245–268. https://doi.org/10.1177/0075424214540528.Search in Google Scholar
Szmrecsanyi, Benedikt. 2017. Variationist sociolinguistics and corpus-based variationist linguistics: Overlap and cross-pollination potential. Canadian Journal of Linguistics/Revue Canadienne de Linguistique 62(4). 685–701. https://doi.org/10.1017/cnj.2017.34.Search in Google Scholar
Szmrecsanyi, Benedikt & Jason Grafmiller. 2023. Comparative variation analysis: Grammatical alternations in world Englishes. Cambridge: Cambridge University Press.10.1017/9781108863742Search in Google Scholar
Szmrecsanyi, Benedikt, Jason Grafmiller, Benedikt Heller & Melanie Röthlisberger. 2016. Around the world in three alternations: Modeling syntactic variation in varieties of English. English World-Wide 37(2). 109–137. https://doi.org/10.1075/eww.37.2.01szm.Search in Google Scholar
Szmrecsanyi, Benedikt, Jason Grafmiller & Rosseel Laura. 2019. Variation-based distance and similarity modeling: A case study in world Englishes. Frontiers in Artificial Intelligence 2. 23. https://doi.org/10.3389/frai.2019.00023.Search in Google Scholar
Tamaredo, Iván. 2020. Complexity, efficiency, and language contact: Pronoun omission in World Englishes. Bern: Peter Lang.10.3726/b16943Search in Google Scholar
Tamaredo, Iván. 2024. Clause initial null subjects in web-based written language: An analysis of eight varieties of English. International Journal of English Studies 24(2). 81–105. https://doi.org/10.6018/ijes.584081.Search in Google Scholar
Tamaredo, Iván, Melanie Röthlisberger, Jason Grafmiller & Benedikt Heller. 2020. Probabilistic indigenization effects at the lexis-syntax interface. English Language and Linguistics 24(2). 413–440. https://doi.org/10.1017/S1360674319000133.Search in Google Scholar
Tegey, Habibullah & Barbara Robson. 1996. A reference grammar of Pashto. Washington, D.C.: Center for Applied Lingusitics.Search in Google Scholar
Thompson, Hanne-Ruth. 2010. Bengali: A comprehensive grammar. London & New York: Routledge.Search in Google Scholar
Torres Cacoullos, Rena & Catherine E. Travis. 2014. Prosody, priming and particular constructions: The patterning of English first-person singular subject expression in conversation. Journal of Pragmatics 63. 19–34. https://doi.org/10.1016/j.pragma.2013.08.003.Search in Google Scholar
Vartiainen, Turo, Callies Marcus & Aatu Liimatta. 2025. The productivity of the complex modifier construction in world Englishes. English Language and Linguistics 29(2). 389–410. https://doi.org/10.1017/S1360674325000231.Search in Google Scholar
Wagner, Susanne. 2012. Null subjects in English: Variable rules, variable language? Chemnitz: Chemnitz University of Technology postdoctoral dissertation.Search in Google Scholar
Wagner, Susanne. 2018. Never saw one – first-person null subjects in spoken English. English Language and Linguistics 22(1). 1–34. https://doi.org/10.1017/S1360674316000216.Search in Google Scholar
© 2025 Walter de Gruyter GmbH, Berlin/Boston