Linked shrinkage to improve estimation of interaction effects in regression models
-
Mark A. van de Wiel

 ,
Matteo Amestoy
,
Matteo Amestoy

Abstract
Objectives
The addition of two-way interactions is a classic problem in statistics, and comes with the challenge of quadratically increasing dimension. We aim to a) devise an estimation method that can handle this challenge and b) to aid interpretation of the resulting model by developing computational tools for quantifying variable importance.
Methods
Existing strategies typically overcome the dimensionality problem by only allowing interactions between relevant main effects. Building on this philosophy, and aiming for settings with moderate n to p ratio, we develop a local shrinkage model that links the shrinkage of interaction effects to the shrinkage of their corresponding main effects. In addition, we derive a new analytical formula for the Shapley value, which allows rapid assessment of individual-specific variable importance scores and their uncertainties.
Results
We empirically demonstrate that our approach provides accurate estimates of the model parameters and very competitive predictive accuracy. In our Bayesian framework, estimation inherently comes with inference, which facilitates variable selection. Comparisons with key competitors are provided. Large-scale cohort data are used to provide realistic illustrations and evaluations. The implementation of our method in RStan is relatively straightforward and flexible, allowing for adaptation to specific needs.
Conclusions
Our method is an attractive alternative for existing strategies to handle interactions in epidemiological and/or clinical studies, as its linked local shrinkage can improve parameter accuracy, prediction and variable selection. Moreover, it provides appropriate inference and interpretation, and may compete well with less interpretable machine learners in terms of prediction.
Introduction
Adding interactions to a regression model is a classical problem in epidemiology which may lead to interesting insights on the joint effects of covariates [1]. Moreover, it may be crucial for reducing bias of the main effect coefficients [2]. It comes at a price though, as the number of interaction terms q increases quadratically with the number of covariates p. While one may argue that in very small p settings the plausibility of each two-way interaction may be considered separately, such a strategy is infeasible or unpractical for larger dimensions. At the other end of the spectrum, with p large – and hence q very large – compared to sample size n, the hierarchical lasso [3] and variations thereof provide a computationally efficient sparse solution. The latter, however, focuses on selection, and does not come naturally with parameter inference. This leaves a gap for the middle spectrum, with p + q of a similar order of magnitude as n, a setting which is fairly common in many biomedical or epidemiological studies. Our goal is to fill this gap using an interpretable solution that on one hand is able to deal with the large number of parameters, while on the other hand allows for inference. More specifically, our aim is three-fold: (1) accurate estimation and selection of parameters; (2) interpretation of variable importance scores in the context of our model; and (3) inference for those variable importance scores.
To achieve these goals, this study provides two novelties. First, a linked shrinkage model, which links local shrinkage of the interaction effects to that of the main effects. This extends the Bayesian local shrinkage framework [4]. The latter provides flexible, differential shrinkage of small and large effects, which may benefit the accuracy of the parameter estimation in the same spirit as the adaptive lasso and non-negative garrotte do. In addition, we draw upon its good inferential properties [5]. The linked shrinkage model also includes a global shrinkage parameter for the interaction parameters to allow those to be weaker on average than the main effect parameters, thereby providing adaptivity. Second, we deduce a computationally efficient equation for Shapley values [6], which allows quantification and inference for those sample specific variable importance scores. Shapley values are popular in machine learning, and we argue that these scores can also be of great use for regression models with many interaction terms, as the presence of the latter impedes straightforward interpretation of the regression coefficients as variable importance scores [1].
As our problem is a classical one in epidemiology, a number of solutions already exist. Below we provide a list of reference methods that we compare our method to.
Ordinary least squares (OLS), which does not apply any shrinkage, and may therefore provide unstable estimates for some settings.
Ridge regression with two tuned penalties [7], one for main effects, one for interactions: ridge2. Such global penalties likely improve the predictive abilities of the model, but do not well accommodate strong differences between parameter strengths within each of the two parameter sets.
Bayesian local shrinkage [4] using a local Gaussian prior for each parameter, the standard deviations of which are endowed with a half-Cauchy prior. For our comparisons, we use the horseshoe (hs; [8]), which extends the local shrinkage by a global shrinkage parameter to better accommodate sparse settings.
Two-step approach that only include interactions of significant main effects: 2step. While popular in practice, it may render very unstable results, as the inclusion of interactions depends on a hard threshold for the main effects.
Spike-and-slab (SandS; [9]), a prior that specificially models selection as it consists of a point mass on zero and, in our case, a Gaussian slab to model the non-zero effects.
Lasso regression with only a penalty for the interaction terms: lassoint. This type of global shrinkage may suffer from the same drawbacks as ridge2.
Adaptive lasso (adlasso; [10]), which weighs the penalties by reciprocal absolute OLS coefficients. Hence, its performance depends also on the stability of those coefficients.
Hierarchical lasso for interactions (hlasso), a state-of-the-art methodology that formalizes the reasoning of 2step in one fitting procedure [3, 11, 12]. It is mostly designed for computational efficiency to handle large p. While it has proven its use for variable selection, formal inference is far from straightforward [11], requiring strong assumptions on the underlying sparsity or extensive resampling.
We compare our linked shrinkage model, termed Bayint, to those methods as well as to several variations of Bayint which differ in how they encode the linked shrinkage. We assess estimation accuracy, prediction and variable selection. For this, we use simulations and a very large real data set, the OLS estimates of which serve as a benchmark. We study the results for two outcomes (systolic blood pressure and cholesterol), and a mix of continuous, binary and categorical covariates. In addition, we provide several illustrations to support interpretation of the model and the covariates, including those with Shapley values and their uncertainties. Finally, we perform a short comparison with random forest in terms of out-of-bag predictive performance. This illustrates that even for large sample sizes Bayint can be very competitive to such a machine learner, while providing better interpretation. We end by discussing the implementation, scalability and potential extensions.
Materials and methods
The model, called Bayint, combines ideas behind the hierarchical lasso, which considers interactions of strong main effects to be more important, with those of Bayesian local shrinkage, the hierarchical set-up of which allows a softer link between the interactions and main effects.
The linked shrinkage model
For simplicity, we assume linear response Y i , i=1, …, n, but the model can easily be reformulated in a generalized linear model or Cox regression context. For sample i, the jth covariate is denoted by x ij , j=1, …, p. Then, the proposed model is:
Several of the components in (1) are in line with conventional Bayesian modelling, including the half-Cauchy prior on the (relative) standard deviations τ j [4]. We add linked shrinkage to the model by including the product τ j τ k in the prior of β jk . This product renders a symmetric handling of strong and weak main effects (corresponding to large τ j and small τ j , respectively), whereas it is on the same scale as each of the components when they are. In addition, τ int, 0.01≤τ int≤1 is a shrinkage parameter shared by all interactions that models the prior believe that interaction parameters might, on average, be weaker than the main effect parameters. The lower bound avoids complete shrinkage to 0 of all interaction effects, as this may be undesirable in a sparse setting. Note that when categorical covariates are present, the summation over j, k in the regression model in (1) is adjusted such that interactions between their levels are excluded.
Alternative linked shrinkage models
We discuss a few variations of Bayint (1) that may be relevant for other settings or foci. First, Bay0int, which does not apply shrinkage to the main main effects (non-informative Gaussian priors). This may be useful when one thinks of our model as (a simplification of) a general quadratic form, for which shrinkage of the main effects towards 0 is not necessarily logical. A potential disadvantage is that one looses the link between shrinkage of the two types of effects. Second, Bayintadd, which replaces τ
j
τ
k
by
If one is particularly interested in detecting interactions, a third alternative may be attractive: Bayint*, which sets τ int=1. This model does usually not compete with Bayint in terms of prediction accuracy, as the latter has a global shrinkage parameter τ int that can adapt to the interactions being weaker (on average) than the main effects for most problems. The downside of including τ int, though, is that relatively strong interactions may be over-shrunken, which is why Bayint* may be better at detecting those. Comparisons with these alternative models are provided further on.
Results
This section consists of three main parts. First, we assess model (1) (i.e. Bayint) in a broad sense by considering parameter estimation, prediction and variable selection. For that, we compare Bayint to the competitors discussed in the Introduction, first for simulated data. Then, the resulting top-5 methods are evaluated in a real data setting for which we may assume (nearly) true values to be known. When relevant we also show results for the Bayint alternatives discussed above. Second, we show how to interpret and infer results from our model using a novel formula for the Shapley values. Finally, for the data, predictive accuracy of Bayint is also compared to that of a non-regression based learner, the random forest. Implementation details of the various methods are provided in the Supplementary Material.
Evaluation criteria
We evaluate Bayint and its competitors on the basis of the following criteria:
Parameter estimation. The root Mean Squared Error (rMSE), defined by
with β=β j or β=β jk and
Prediction. Mean Squared Error of the predictions:
with X test: design matrix for large test sample, including all two-way interactions.
Variable selection. Sensitivity at prescribed False Discovery Rate (FDR) levels
Here, the second criterion is equivalent to evaluating prediction error, which includes the noise, but provides a more direct comparison of the fit with the true linear predictor.
Simulations
We consider two simulation settings, which we summarize here. For the first, we generated p=10 moderately collinear continuous covariates for n=200 samples, rendering q=p(p − 1)/2=45 two-way interactions. Five main effects are non-zero. For the non-zero interactions, we aimed for a realistic balance of three different types of interactions: six interactions of two non-zero main effects, four interactions between a non-zero and an absent main effect, and finally, three ‘surprising’ interactions between two absent main effects. Two of these interactions have one covariate in common. This implies 18 non-zero coefficients in total. These coefficients range from small to large for main effects, and from small to medium for interaction effects. The second simulation increases sample size to n=500 and adds four noise variables, rendering p=14 and q=91. We kept the same structure for the present main and interaction effects, but given that this setting is sparser than the first, we increased the signal for one main effect and one of each of the three interaction types. For generating the linear response, Gaussian noise was added such that R 2≈0.5. For both settings, B=50 datasets were generated. Details of the simulations are provided in the Supplementary Material.
Table 1 summarizes the performances of the methods on parameter estimation, prediction and selection.
Summarized performance for simulation 1 (n=200, p + q=55, 18 non-zero effects) and simulation 2 (sparser; n=500, p + q=105, 18 non-zero effects).
| Method | Simulation 1 | Simulation 2 | ||||
|---|---|---|---|---|---|---|
| Estimation | Prediction | Selection | Estimation | Prediction | Selection | |
| Bayint | ++ | ++ | ++ | ++ | ++ | ++ |
| hlasso | ++ | ++ | +− | ++ | ++ | +− |
| adlasso | + | +− | + | ++ | + | + |
| SandS | +− | + | + | +− | + | + |
| HS | + | +− | + | + | – | + |
| lassoint | + | ++ | a | + | + | a |
| ridge2 | ++ | + | a | – | – | a |
| OLS | – | −− | +− | – | −− | +− |
| 2-step | −− | −− | a | −− | −− | a |
-
aMethod not suitable for selection.
An extensive discussion of the results is included in the Supplementary Material; here we focus on the top-5 methods. Supplementary Figures 1 and 2 show that, generally, Bayint performs very well on estimating the non-zero interactions. Even for the two interactions that are not linked to any non-zero main effects, but do share one covariate, the linked shrinkage provides very competitive performance. The slightly worse estimation of hlasso of the non-zero interactions and large main effects is counterbalanced by better shrinkage for the true zero interactions. The adaptive lasso, adlasso, is quite competitive to hlasso, in particular for the larger sample size (Simulation 2) for which the OLS penalty weights stabilize. The spike-and-slab, SandS, compresses the true zero effects well, but this comes at the prize of relatively unstable estimation of the non-zero effects. The horseshoe, HS, estimates the latter better, but at the price of inferior compression of the non-zero interaction effects.
For prediction, Bayint and hlasso are very competitive to one another, somewhat better than adlasso and SandS, and markedly better than HS as shown in Supplementary Figure 3.
Finally, selection was evaluated by considering sensitivity at fixed FDR levels=0.1, 0.2 (Supplementary Table 1). Here, Bayint outperforms the others, although adlasso, SandS and HS are competitive runner-ups. We noted that the gain in sensitivity for Bayint was not exclusive for interactions; also the main effects were detected better. This is likely due to the local shrinkage and ‘reverse borrowing’ in our model, as the shrinkage of main effects also learns from the linked interactions. The default hlasso did not perform well. This is due to its property of forcing in main effects for selected interactions, which renders too many false positives; countering this by a more stringent penalty compromises the sensitivity. We also present an alternative strategy, which simply sets small effect sizes
Data
For the data, we present the results of the methods that performed most competitively in the Simulations (top 5): our model (Bayint), adaptive lasso (adlasso), hierarchical lasso (hlasso), spike-and-slab (SandS) and horseshoe (HS).
The main data we use throughout the manuscript is obtained from the Helius study [13]. We use this data set, because it reflects a fairly standard epidemiological study and contains a mix of binary, continuous and categorical covariates. We consider both systolic blood pressure (log scale; SBP) and cholesterol as response, and age, gender, ethnicity (5 levels; coded with 4 dummies), smoking (yes/no), packyears, coffee consumption (yes/no), BMI and 4 simulated standard normal noise variables as covariates, rendering p=14 covariates. All two-way interactions are considered, except those between the 4 dummy variables representing the categorical covariate, rendering
The entire data set, referred to as the ‘master set’, consists of n=21,570 samples. Therefore, OLS estimates based on the master set are very precise, and hence safely used as benchmarks. As a verification, we confirm that i) the estimated coefficients of the noise variables are indeed very close to zero; and ii) the coefficients estimated by (adaptive) lasso are very close to the OLS estimates (Supplementary Figures 4 and 5).
Continuous covariates were centered and scaled, that is standardized. On the centering, we follow the advise by Afshartous and Preston [1]; as the centering (largely) removes collinearity between main effects and two-way interactions. Scaling is generally applied in shrinkage settings, and also helps to interpret the coefficients and estimation errors relative to one another. Binary covariates were (contrast) coded as −1, 1, which renders them standardized in the balanced setting. For interpretation, we prefer to use the same coding for all binaries. The categorical covariate, ethnicity, was contrast-coded with levels −1, 0, 1.
Parameter estimation
We use the rMSE as defined above to evaluate parameter estimation. For this, we divided the master set in B=25 (nearly non-overlapping) training sets of size n=1,000, and set the ‘true’ β to the OLS estimate from the large master set. For Bayesian methods, the posterior mean was used as a point estimate for β. Figures 1 and 2 compares the results of Bayint with other methods (see Introduction) for cholesterol and SBP as outcome, respectively. The bold line demarcates the main effects and interactions; the thin lines separate the strong effects from the weaker ones, as defined by significance in the master set (p<0.01).

rMSEs for 14 main effects and 85 interactions (before and after bold vertical line), each ordered by significance in master set. Thin vertical line demarcates strong and weak effects in the master set (criterion: p

rMSEs for 14 main effects and 85 interactions (before and after bold vertical line), each ordered by significance in master set. Thin vertical line demarcates strong and weak effects in the master set (criterion: p
Overall, we observe that Bayint shows good estimation performance. For both outcomes, it outperforms the other methods on the estimation of the strong main effects. Hierarchial lasso (hlasso) and spike-and-slab (SandS) compress the weak main effects a bit better than Bayint for the cholesterol outcome. For the strong interaction effects, performances are generally very competitive for the SBP outcome, while Bayint has an edge for the cholesterol, except in comparison to the horseshoe (HS), which is competitive for those effects. The latter, however, lags behind for compressing the weak interaction effects, which is also the case for the adaptive lasso (adlasso). Note that these results are fairly well in line with those from the simulation study.
Supplementary Figure 6 connects the true main effects and interactions (estimated from the master set), to provide insight on why linked shrinkage has a benefit for both outcomes. Indeed, we observe that strong interactions tend to link relatively frequently to strong main effects, and that this tendency is somewhat stronger for cholesterol, explaining the slightly larger benefit of linked shrinkage for this outcome compared to SBP.
Finally, we provide a short comparison of Bayint with two aforementioned alternatives, Bay0int and Bayintadd, for the cholesterol model only. From Supplementary Figure 7 we observe that particularly Bayint and Bayintadd are very competitive, with the latter slightly worse for the very non-significant interactions. Bay0int may pick up the strong interactions slightly better, but seems somewhat inferior for main effects and less important interactions.
Prediction
Models were tested on complementary test samples of the master data set. Figure 3 shows the mean squared errors of the predictions (MSEp) for both outcomes. We clearly observe that Bayint, and to a lesser extent, hlasso, outperform the other methods on this criterion. Note here that Bayint reduces the MSEp of hlasso for 22/25 (24/25) subsets and by a relative amount of 17.9 % (26 %) on average for the two outcomes, cholesterol and SBP, respectively.

MSE of the predictions of models trained on 25 subsets of the data.
Selection
Next, we focus on selection. Note that the five methods use very different default criteria for performing selection: the lasso-based methods simply report non-zero coefficients for a given penalty parameters, horseshoe and Bayint use credible intervals for a given level, e.g. 95 %, and the spike-and-slab uses a threshold for the posterior selection probability, e.g. 0.5. To be less dependent on such tunable parameters, and allow appropriate comparison, we set these parameters such that FDRs=0.1, 0.2 and compute the sensitivities, as we did for the simulations. For that, we define positives as those significant in the master set at p≤0.05/99 (Bonferroni correction) and negatives as those that either correspond to a noise covariate or are non-significant at cut-off 0.05. Given the sheer size of the master set the latter assures that such effects are either very small or completely absent. This defines 12 (14) positives, and 79 (76) negatives for the cholesterol (SBP) outcome; the remaining 99 − 12 − 79=8 (99 − 14 − 76=9) effects are indeterminate, which are therefore not used for calculating the FDRs and sensitivities.
Table 2 shows the results for both outcomes. For the data, the benefit of dedicated shrinkage for the model with all two-way interactions is clear: both Bayint and hlasso outperform the others. Note here that hlasso performance did not improve when applying the extra effect size cut-off discussed in the Simulation section. The gap in performance may be understood by considering the true positive interactions: all of these contained at least one true main effect for both outcomes, which supports linking their shrinkage (or selection) to that of the main effects. For a substantial part of these interactions only one of the two corresponding main effects was a positive. This may explain the better performance of Bayint as compared to hlasso, as the former encodes a softer shrinkage than the latter.
Sensitivities for variable selection, for fixed FDRs.
| FDR | Outcome | Sensitivity | ||||
|---|---|---|---|---|---|---|
| Bayint | hlasso | adlasso | HS | SandS | ||
| 0.10 | Chol | 0.490 | 0.293 | 0.180 | 0.233 | 0.267 |
| 0.20 | Chol | 0.583 | 0.450 | 0.283 | 0.330 | 0.350 |
| 0.10 | Sbp | 0.451 | 0.474 | 0.343 | 0.306 | 0.394 |
| 0.20 | Sbp | 0.540 | 0.506 | 0.391 | 0.343 | 0.443 |
-
The bold values indicate the best performing method for that setting.
For the two strongest methods, we qualitatively compare the actual detections of weak and strong main effects and interactions, where their strengths are defined by the effect sizes in the master data set. Supplementary Figure 8 plots the detections by hlasso for λ min and λ 1std against those by Bayint (using 95 % credible intervals). We observe that the selection by hlasso renders a less clear demarcation of the strong and small effects than Bayint does, in particular for the main effects. Finally, Supplementary Figure 9 compares the detections of Bayint and Bayint*, which applies less shrinkage to the interactions. Indeed, the latter detects strong interactions more often than Bayint, at the cost of detecting two main effects.
Interpretation of variable importance
Here, we discuss several techniques and visualisations to interpret results from the Bayint model. We focus on cholesterol as outcome. Bayint provides credible intervals. We previously showed the coverage of Bayesian local shrinkage – on which our shrinkage model is based – to be rather good [5] in low dimensional settings, although this will depend on the p:n ratio and the amount of collinearity. Moreover, Supplementary Table 2 shows that Bayint’s intervals are a powerful tool to select interactions, as compared to other methods. Hence, these intervals are of direct use to infer which interactions are relevant and which are not.
Interpretation and inference for the main effect parameters is hampered though by the presence of those interactions, as the effect of one unit change of a covariate depends on the values of the other covariates. Therefore, technically, β j =0 only means that for a (fictive) person with average values for all other covariates (given centering is applied), covariate j has no effect. That is, it only quantifies a conditional main effect. Afshartous and Preston [1] propose several useful alternatives, such as determining the ‘range of significance’. For this, one plots the confidence/credible intervals for β j + β jk x ik – the effect of one unit change of x ij when interacting with one covariate x ik – against x ik . Alternatively, one may compute E ij =β j + ∑ k≠j β jk x ik , i.e. a ‘personalized unit change effect’ which accounts for all interactions. Our MCMC samples easily provide the posteriors of E ij , allowing to plot its uncertainty as well. A hybrid of the latter two solutions is a plot of E ij against x ik (when continuous) or for color-coded levels of x ik to see whether one unit change of x ij (say age or BMI) has a different effect on the outcome, e.g. for x ik =−1, 1 (say female/male), while accounting for the other interacting covariates as well. Supplementary Figure 10 plots E ij and its uncertainty for 100 random test individuals (Bayint model fitted on 1,000 training samples), with x ij and x ik representing age and gender, respectively. We clearly observe a different effect of age increase between genders, but also within gender due to interactions of age with other covariates.
Alternatively, Shapley values [6] may be considered. A Shapley value ϕ
ij
quantifies the average contribution of the jth covariate to the prediction of the ith sample, fixing
Shapley values are popular in machine learning nowadays, because they uniquely possess several nice properties: efficiency, symmetry, dummy player and linearity [6]. Obtaining its exact value is usually computationally very demanding, let alone computing uncertainties. For our model, however, it is feasible to compute Shapley values and their uncertainties efficiently, if one is willing to use the common convention that the marginalization ignores the dependency between the players and the non-players [14], an approach referred to as ‘interventional Shapley value’ [6]. For a linear regression model with two-way interactions and centered covariates it equals
when the jth covariate is continuous or binary. A proof is provided in the Appendix, which also includes expressions for the non-centered setting and categorical covariates. Note that (the posterior of) ϕ
ij
is straightforward to compute after estimating E[x
ij
x
ik
] by the sample covariance. Again, we illustrate results for 100 random test samples and the Bayint model trained on 1,000 random training samples. Figure 4 shows Shapley values and their credible intervals for ‘age’ and ‘Noise.1’. The latter is a useful negative control as we observe that, as desired, all credible intervals cover 0. Note that centering of the covariates implies that Shapley values are expected to center around 0. Yet, we observe that age is an important covariate for the majority of samples as most intervals do not cover 0. The plot for ‘age’ also shows that interactions are not equally important for all samples: those that deviate relatively much from the trend, like the first one, are impacted more due to the
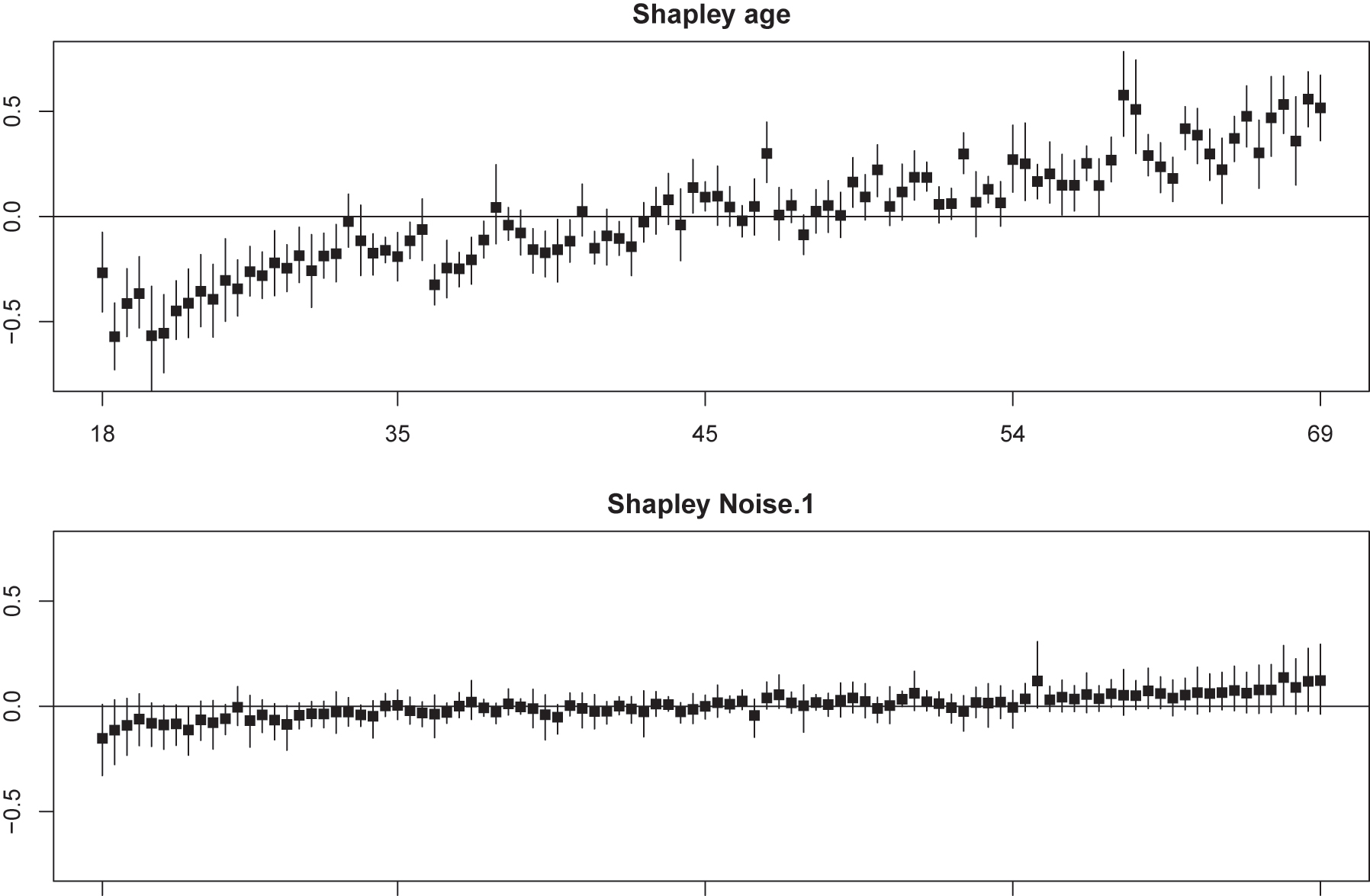
Shapley values of ‘age’ and ‘Noise.1’ and their posteriors for 100 random test individuals, ordered by ‘age’ (original scale) and ‘Noise.1’, respectively. Cholesterol (standardized) as outcome.
Clearly,

Global variable importance scores. Top: mean absolute Shapley values (I
j
); Bottom: mean absolute contributions of main effect
Finally, we compared the estimated Shapley values with the ‘true ones’, which are available by substituting the coefficients from the large master set into (2). We did so for both our method, Bayint, and the hierarchical lasso, hlasso. Supplementary Figure 16 shows that both methods estimate the Shapley values well for ‘age’, which is a strong, continuous covariate. For a weaker, binary covariate, ‘etn1’, we observe that Bayint provides much better estimation of the Shapley values than hlasso. This is in line with the results in Figure 1: Bayint has smaller estimation errors of the parameters in which this covariate is involved. Finally, a more nuanced difference in performance is visual for the covariate ‘gender’ in Supplementary Figure 18, which shows a benefit of Bayint for some training sets, but not all.
Model assessment by R 2
So far we have compared our method Bayint with competitors that use the exact same model (regression with all two-way interactions), but different types of regularizations. Here, we broaden the scope and compare the overall out-of-sample fit of Bayint with a basic regression model without interactions as well as with a machine learner, here the random forest. The first comparison allows to judge the additive value of the interactions for improving test sample fit, whereas the second one is relevant, because the random forest holds the promise to capture interactions well and to provide adequate predictions, so it provides a useful benchmark. As an additional benchmark, we also include OLS with all two-way interactions in the comparison.
Random forest was either fit using the defaults in the randomForestSRC package (RF) or with hyperparameters (mtry: number of features considered per split and nodesize: minimum node size) tuned for optimal predictive performance using the tune.rfsrc function (RFtune).
For the comparison, we compute for each model and for all b=1, …, 25 training sets the out-of-bag coefficient of determination,

Out-of-bag R 2s for 25 training sets of size n=1,000 for cholesterol (top) and SBP (bottom) as outcome. Methods: Bayint: Bayesian linked shrinkage model; OLS: OLS with all terms; MainEff: OLS with main effects only; RF (RFtune): Random forest with default (tuned) parameters.
For cholesterol as outcome, we observe that Bayint provides a substantial gain in terms of R 2 as compared to its OLS counterpart, and a moderate improvement w.r.t. the main effects only model. Moreover, predictive performance is somewhat better than that of RF, and marginally better than that of RFtune. The latter two overfit substantially, as observed from comparing the in-bag and out-of-bag performances (Supplementary Figure 11). For SBP observe that all models predict this outcome than cholesterol. Here, differences between Bayint and the main effects only model are small, whereas both beat OLS, RF and RFtune by a fair margin. Note that the relative performance of the random forest improves for n=5,000 (Supplementary Figure 12), rendering it competitive to Bayint in terms of prediction.
Hence, from a predictive perspective Bayint clearly outperforms its OLS counterpart. Moreover, it is highly competitive, if not superior, to a much simpler model, the main effects only model, which provides no information on interactions, and to a more complex one, RF, the results of which are more difficult to interpret and infer.
Implementation and data availability
Our linked shrinkage model was implemented in RStan (v 2.21.8) [15]. We chose to use a general purpose sampler for several reasons. First, it allows the user to adjust the model without much extra effort in terms of fitting or inference. This includes variations on modelling the shrinkage, as illustrated, but also adjusting the likelihood to allow binary or survival outcome, as RStan accommodates these as well. We provide an example for logistic regression in the code. Second, RStan provides several diagnostic tools, such as trace plots, to check the convergence of the MCMC sampler. Our scripts are available at https://github.com/markvdwiel/ThinkInteractions/, which also contains a synthetic version of the data set. The covariates in the synthetic data are generated by imputation as described in van de Wiel et al. [5]. Then, responses (Cholesterol and SBP) are generated by drawing from normal distributions with means equal to the OLS (as fitted on the master set) predictions based on the synthetic covariates, and error variance equal to the residual error variance of the OLS model. We verified that the synthetic set renders qualitatively similar results on the regression models as those presented here (cf. Figure 1 and Supplementary Figure 19; Figure 2 and Supplementary Figure 20). Finally, as an indication: running time for our example data sets of n=1,000, p=14, q=85 is around 3 min for 25,000 MCMC samples using a single core from a PC with a 1.30 GHz processor and 16 Gb RAM.
Discussion
We demonstrated the potential of linked shrinkage for improving parameter estimation in fairly large regression models that include all two-way interactions. Naturally, the benefit depends on the data set and the relevance of those interactions, in particular in connection to the main effects. A limitation of our main model, Bayint, is that it may not perform well for interactions for which none of the main effects are relevant. We showed, however, that when such interactions share a common covariate, their linked shrinkage offers a benefit, rendering very competitive performance. Moreover, we offer an alternative, Bay0int, which provides more power to detect ‘surprising’ interactions at the cost decreased performance for the main effects, as compared to Bayint. Another limitation might be the linear scale of the covariates in the model. As regression comes with many tools for model diagnostics, such a model miss-specification can be diagnosed. In principle, it is straightforward to extend our model by adding non-linear transformations (log, quadratic) of a few covariates, each with their own local penalty. Optimizing the model by including such covariate transformations after viewing the data may come at the cost of invalid inference. Possibly, for large n, the cost of this form of data snooping may be limited when only the main effects are considered, but this requires further study. In addition, note also that if the model is very wrong its predictive performance is likely compromised, as compared to more flexible machine learners. This was not the case for our data, at least in comparison to the random forest.
We showed that Bayint is a very viable alternative for its main competitor, hlasso: it performs competitively, if not slightly better, on parameter estimation and prediction, while providing the extra benefit of uncertainty quantification. Moreover, it outperforms hlasso in terms of selection. Selection instability is a well-known problem for the lasso, which may be countered by applying stability selection [16]. This requires multiple fits for bootstrapped samples. If selection is the sole aim of the study – as is often the case in high-dimensional settings – this is a very useful solution. In our setting, however, we strived for a method that provides estimation, prediction, selection, uncertainty quantification and interpretation with one single model fit.
A natural extension of our method is the inclusion of higher-order interaction. In principle, this is easily achieved with our code, and may be a viable option when only few covariates are present. Note, however, that the number of three-way interactions increases cubicly with the number of covariates, and one may argue that regression models with higher-order interaction are hardly any easier to interpret than many machine learners.
As mentioned, we coded our method in RStan, because its flexibility allows the user to extend the framework to one’s own needs, such as the various illustrated shrinkage links and non-continuous outcomes (survival, binary). A potential disadvantage of using such a general purpose sampler is that it is likely too slow for large p, large n settings. RStan provides variational Bayes approximations, but we experienced that both the mean-field and the (Gaussian) full-rank approximations do not provide satisfactory results (compared to sampling) for our model. Alternatively, the RStan manual suggests to use a thin QR-decomposition of the design matrix for large scale regression problems, but this did not speed up computations in our setting, probably due to the non-exchangeable prior for the regression coefficients. Dedicated sampling or variational Bayes techniques such as proposed for the horseshoe prior in Makalic and Schmidt [17] and Busatto and van de Wiel [18] may provide more scalable alternatives, but this requires more research.
While certainly simpler than many machine learners, the interpretation of a regression model with many two-way interactions is not trivial [1]. Inference for parameters and variable importance scores aids such interpretation. Therefore, we showed that our methods provides a good basis for inference, which we extend to variable importance scores, in particular the Shapley value. We derived the computational efficient formula (2) for its interventional version. If one prefers to account for dependency when marginalizing, approaches as in Aas et al. [6] may be explored, but likely at a high computational cost. For other regressions, e.g. logistic or Cox, formula (2) is only valid if one evaluates the prediction on the level of the linear predictor. This may be reasonable as the regression coefficients are also on that scale.
While it is straightforward to define global variable importance scores from the personalized ones, including Shapley, it less obvious how to perform inference for these, both from a technical and philosophical perspective. As for the first: one may average absolute or squared scores, but the result lacks a natural null. As for the second: in such models, the importance of a covariate depends on the values of the other ones, and is hence individual specific. Possibly, an informal argument, such as: the credible intervals should not contain ‘0’ for at 10 % of the individuals, may be reasonable in practice, but this needs further research.
Finally, we illustrated that the addition of two-way interactions, as in Bayint, may improve predictive performance with respect to a main effect only regression model. In fact, Bayint can be very competitive to more advance machine learners, such as random forest. Of course, such comparative results depend strongly on the data, sample size and true complexity of the associations between covariates and response. If prediction is an important aim of the study, possibly alongside interpretation, we recommend comparing the predictive performance of Bayint with more flexible machine learners. In the eventual case of inferior predictive performance of the former, one should balance this loss against the improved interpretability.
All-in-all, Bayint is an attractive alternative for existing strategies to handle interactions in epidemiological and/or clinical studies, as its linked local shrinkage can improve parameter accuracy, prediction and variable selection. Moreover, it provides appropriate inference and interpretation, and may compete well with less interpretable machine learners in terms of prediction.
Funding source: ZonMw
Award Identifier / Grant number: 200500003
Funding source: Netherlands Organization for Scientific Research
Award Identifier / Grant number: 024.004.017
Funding source: Dutch Heart Foundation
Award Identifier / Grant number: 2010T084
Funding source: Seventh Framework Programme
Award Identifier / Grant number: 278901
-
Research ethics: Not applicable.
-
Informed consent: Not applicable.
-
Author contributions: The authors have accepted responsibility for the entire content of this manuscript and approved its submission.
-
Competing interests: The authors state no conflict of interest.
-
Research funding: The Amsterdam University Medical Centres and the Public Health Service of Amsterdam (GGD Amsterdam) provided core financial support for HELIUS. The HELIUS study is also funded by research grants of the Dutch Heart Foundation (Hartstichting; grant no. 2010T084), the Netherlands Organization for Health Research and Development (ZonMw; grant no. 200500003), the European Integration Fund (EIF; grant no. 2013EIF013) and the European Union (Seventh Framework Programme, FP-7; grant no. 278901). This work was also supported by EXPOSOME-NL, funded through the Gravitation program of the Dutch Ministry of Education, Culture, and Science and the Netherlands Organization for Scientific Research (NWO grant number 024.004.017).
-
Data availability: Synthetic data is made available through the github repository mentioned in the manuscript.
Appendix: Shapley values
Here, we derive the interventional Shapley value for our model. For clarity we fix the sample index i, and denote x
j
=x
ij
and its realization by
For the interventional Shapley, it is assumed that
The following result shows that for a linear regression model with all main effects and two-way interactions the exact ϕ
p
can be computed with linear complexity
Theorem 1.
Let ϕ
p
be defined as in (3) and assume
Proof.
First, for convenience we write
Likewise,
Therefore, we have:
with
To compute
as the weight
as
Corrollary 1.
If covariates are centered, we have:
Proof.
This simply follows from the fact that centering implies E[x j ] = 0. □
Corrollary 2.
If a categorical covariate is present, then:
For a non-categorical covariate ϕ p remains unchanged
For a categorical covariate
(7)
Proof.
First, 1. follows directly from redefining
References
1. Afshartous, D, Preston, RA. Key results of interaction models with centering. J Stat Educ 2011;19. https://doi.org/10.1080/10691898.2011.11889620.Search in Google Scholar
2. Vatcheva, K, M Lee, JB McCormick, MH Rahbar. The effect of ignoring statistical interactions in regression analyses conducted in epidemiologic studies: an example with survival analysis using cox proportional hazards regression model. Epidemiology 2016;6:216. https://doi.org/10.4172/2161-1165.1000216.Search in Google Scholar PubMed PubMed Central
3. Bien, J, Taylor, J, Tibshirani, R. A lasso for hierarchical interactions. Ann Stat 2013;41:1111. https://doi.org/10.1214/13-aos1096.Search in Google Scholar
4. Gelman, A, Jakulin, A, Pittau, MG, Su, YS. A weakly informative default prior distribution for logistic and other regression models. Ann Appl Stat 2008;2:1360–83. https://doi.org/10.1214/08-aoas191.Search in Google Scholar
5. van de Wiel, MA, Leday, GG, Hoogland, J, Heymans, MW, van Zwet, EW, Zwinderman, AH. Think before you shrink: alternatives to default shrinkage methods can improve prediction accuracy, calibration and coverage. 2023. arXiv preprint arXiv:2301.09890. https://arxiv.org/abs/2301.09890.Search in Google Scholar
6. Aas, K, Jullum, M, Løland, A. Explaining individual predictions when features are dependent: more accurate approximations to Shapley values. Artif Intell 2021;298:103502. https://doi.org/10.1016/j.artint.2021.103502.Search in Google Scholar
7. Wood, SN. Fast stable restricted maximum likelihood and marginal likelihood estimation of semiparametric generalized linear models. J Roy Stat Soc B 2011;73:3–36. https://doi.org/10.1111/j.1467-9868.2010.00749.x.Search in Google Scholar
8. Carvalho, C, Polson, N, Scott, J. Handling sparsity via the horseshoe. J Mach Learn Res 2009;5:73–80.Search in Google Scholar
9. Newcombe, PJ, Raza Ali, H, Blows, FM, Provenzano, E, Pharoah, PD, Caldas, C, et al.. Weibull regression with Bayesian variable selection to identify prognostic tumour markers of breast cancer survival. Stat Methods Med Res 2014;26:1–23. https://doi.org/10.1177/0962280214548748.Search in Google Scholar PubMed PubMed Central
10. Zou, H. The adaptive lasso and its oracle properties. J Am Stat Assoc 2006;101:1418–29. https://doi.org/10.1198/016214506000000735.Search in Google Scholar
11. Lim, M, Hastie, T. Learning interactions via hierarchical group-lasso regularization. J Comput Graph Stat 2015;24:627–54. https://doi.org/10.1080/10618600.2014.938812.Search in Google Scholar PubMed PubMed Central
12. Du, Y, Chen, H, Varadhan, R. Lasso estimation of hierarchical interactions for analyzing heterogeneity of treatment effect. Stat Med 2021;40:5417–33. https://doi.org/10.1002/sim.9132.Search in Google Scholar PubMed
13. Snijder, MB, Galenkamp, H, Prins, M, Derks, EM, Peters, RJ, Zwinderman, AH, et al.. Cohort profile: the healthy life in an urban setting (HELIUS) study in Amsterdam, The Netherlands. BMJ Open 2017;7:e017873. https://doi.org/10.1136/bmjopen-2017-017873.Search in Google Scholar PubMed PubMed Central
14. Lundberg, SM, SI Lee. A unified approach to interpreting model predictions. Adv Neural Inf Process Syst 2017;30. https://proceedings.neurips.cc/paper_files/paper/2017/file/8a20a8621978632d76c43dfd28b67767-Paper.pdf.Search in Google Scholar
15. Stan Development Team. RStan: the R interface to Stan; 2022. Available from: https://mc-stan.org/.Rpackageversion2.21.7.Search in Google Scholar
16. Meinshausen, N, Bühlmann, P. Stability selection. J Roy Stat Soc B Stat Methodol 2010;72:417–73. https://doi.org/10.1111/j.1467-9868.2010.00740.x.Search in Google Scholar
17. Makalic, E, Schmidt, DF. A simple sampler for the horseshoe estimator. IEEE Signal Process Lett 2015;23:179–82. https://doi.org/10.1109/lsp.2015.2503725.Search in Google Scholar
18. Busatto, C, van de Wiel, MA. Informative co-data learning for high-dimensional horseshoe regression. 2023. arXiv preprint arXiv:2303.05898. https://arxiv.org/abs/2303.05898.Search in Google Scholar
Supplementary Material
This article contains supplementary material (https://doi.org/10.1515/em-2023-0039).
© 2024 the author(s), published by De Gruyter, Berlin/Boston
This work is licensed under the Creative Commons Attribution 4.0 International License.
Articles in the same Issue
- Research Articles
- Using specific, validated vs. non-specific, non-validated tools to measure a subjective concept: application on COVID-19 burnout scales in a working population
- Linked shrinkage to improve estimation of interaction effects in regression models
- A study of a deterministic model for meningitis epidemic
- Population dynamic study of two prey one predator system with disease in first prey using fuzzy impulsive control
- Leveraging data from multiple sources in epidemiologic research: transportability, dynamic borrowing, external controls, and beyond
- Temporal discontinuity trials and randomization: success rates versus design strength
- Effect of designations of index date in externally controlled trials: an empirical example
Articles in the same Issue
- Research Articles
- Using specific, validated vs. non-specific, non-validated tools to measure a subjective concept: application on COVID-19 burnout scales in a working population
- Linked shrinkage to improve estimation of interaction effects in regression models
- A study of a deterministic model for meningitis epidemic
- Population dynamic study of two prey one predator system with disease in first prey using fuzzy impulsive control
- Leveraging data from multiple sources in epidemiologic research: transportability, dynamic borrowing, external controls, and beyond
- Temporal discontinuity trials and randomization: success rates versus design strength
- Effect of designations of index date in externally controlled trials: an empirical example