Blockchain localization cloud computing big data application evaluation method
-
Lin Xu


Abstract
Blockchain technology is a widely used emerging technology. It can integrate cloud computing technology and big data to form a distributed cloud computing system, providing efficient services for local enterprises and governments. In addition, local cloud computing is also widely used, and there are many big data in these applications. Blockchain and local cloud computing technology offers safe and reliable information exchange for data exchange and provides a practical method for analyzing big data. This article aims to study how to analyze and research the application analysis method of big data based on blockchain technology and improve the classical apriori algorithm (CAA). This article compares and analyzes the performance of CAA and improved apriori algorithm (IAA) in big data applications. When the number of key words in the query are 20 and 100, the result search time of the CAA are 1.08 and 9.24 s, respectively, and the IAA are 0.76 and 7.58 s, respectively. The result search cost of the CAA is 12.43 and 91.55 kB, respectively, and the IAA is 5.05 and 63.72 kB, respectively. It is not difficult to see that applying the IAA to the blockchain-based government data-sharing scheme had relatively excellent performance and was worth further promotion and application.
1 Introduction
The distributed computing system based on blockchain technology has the characteristics of security, stability, and information tamper-proof. Combined with cloud computing technology, it can effectively solve various problems of the cloud on the information system. The combination of blockchain and cloud technology can solve the trust problem of enterprises and public institutions in the cloud and realize the migration of information systems of various units to the cloud on the premise of existing resource investment. In addition, the idle resources (computing, storage, broadband) of all departments would be collected and distributed to the institutions and companies that need resources, and a certain amount of compensation would be given according to their respective contributions, thus forming a new business model. In order to understand the data stored in the cloud, users can download the cloud data to the local for detection. However, this method would cause many network resource consumption, thus weakening the advantages of the cloud computing business. Particularly, for the storage of many cloud data, the feasibility of this scheme is lower. In addition, from the perspective of users, cloud service providers are not trustworthy because they would not warn users to avoid damaging their own reputation without damaging the integrity of users’ information. From the perspective of cloud service providers, users are also unreliable, because they can claim against cloud computing providers through forged data integrity. Therefore, in order to avoid conflicts, both parties need to have a mutually recognized third-party organization or mechanism.
With the advancement of society, the research of big data applications has gradually increased. Sandhu discussed the definition, classification, and characteristics of big data, as well as various cloud services, and compared and analyzed various cloud-based big data frameworks. Various research challenges were defined in terms of distributed database storage, data security, heterogeneity, and data visualization [1]. Varatharajan et al. used the support vector machine model and the weighted kernel function method to classify more features in the input electrocardiogram signal in cloud computing. The sensitivity, specificity, and mean square error were calculated to prove the effectiveness of the proposed linear discriminant analysis and support vector machine method based on an enhanced kernel [2]. Gupta et al. discussed various security and privacy rights involved in mobile and cloud computing and also mentioned many open issues [3]. In order to solve the above security challenges of big data, Zhang et al. proposed an efficient and secure cloud computing big data storage system in which the leakage elastic encryption scheme was the main component. In addition, the formal security proof analysis showed that even if part of the key was leaked in cloud computing, the proposed scheme could ensure the user’s data privacy [4]. Although these studies promoted the application of big data to a certain extent, they were not combined with the actual situation.
Blockchain technology has gradually drawn extensive interest from the academic community. Gupta and Godavarti believed that data were needed to export all the metrics of Internet of Things (IoT) devices. These metrics could be used for appropriate analysis later to make some business decisions. In addition, these massive data were difficult to be processed with traditional data warehouse technology, and a better system was needed. Therefore, he designed a model to better handle the data generated by IoT devices through Rest API [5]. Mohbey and Kumar introduced big data prediction and analysis and its importance and also detailed the applications and challenges in current and future scenarios of cloud computing. In addition, it also included various technologies and frameworks for storing, managing, and processing big data in the cloud platform [6]. Jagadeeswari et al. conducted a detailed study of the latest technologies in personalized medical systems, focusing on cloud computing, fog computing, big data analysis, the IoT, and mobile-based applications. The challenges faced in designing a better medical system for early detection and diagnosis of diseases were analyzed, and the possible solutions were discussed while providing electronic medical services in a safe way [7]. Although these research methods were very innovative, many experimental data were needed to prove the reliability of the methods.
Blockchain technology itself is decentralized, tamper-proof, highly secure, and effective in protecting data. In recent years, the rapid development of blockchain technology has provided a safe and efficient solution for the security and efficient consensus of distributed systems. The innovation of this article was to improve the classical apriori algorithm (CAA) and carry out simulation experiments on the two algorithms to prove the effectiveness of the improved apriori algorithm (IAA). The IAA was applied to the government data security management, and its performance was compared and analyzed.
2 Improvement methods in cloud computing big data
2.1 Blockchain technology in cloud computing services
Big data is a group of data that cannot be obtained and processed in a certain period of time through traditional technical methods. It is a massive, diverse, and fast data resource that can be applied to data mining, decision-making, and other fields [8]. Cloud storage technology is a network storage service technology based on cloud computing. Through server clusters, network communication, distributed file system, and other technologies, and through the separation of software and software, it realizes the collaborative work of many various storage devices in the file server and achieves access to user data storage and services [9,10]. In short, cloud storage is a way to use cloud storage resources in the cloud for users’ storage. Users can easily access through any networkable network. The cloud computing security architecture is shown in Figure 1.
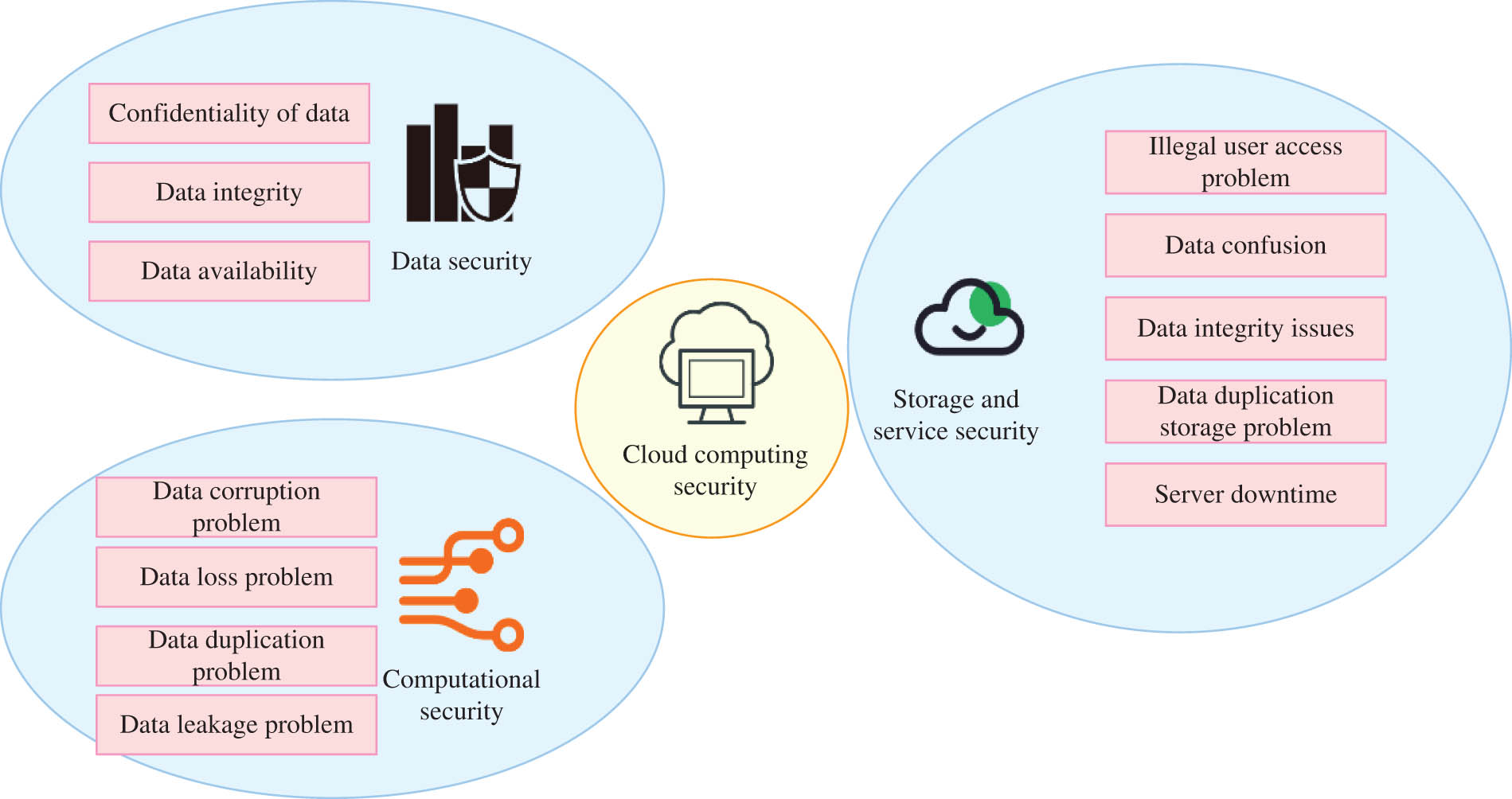
Cloud computing security architecture.
According to Figure 1, cloud computing security includes data security, storage and service security, and computing security. Figure 1 refers to the works of Srivastava and Khan [11]. Data security includes data confidentiality and data availability; storage and service security includes illegal user access issues, data confusion issues, data integrity issues, data duplicate storage issues, and server downtime issues; computing security includes data corruption or loss and sensitive data disclosure.
In the era of big data, terminals can no longer carry a large volume of data and store many data in cloud servers. Therefore, the security of cloud computing is an important guarantee to improve the quality of cloud computing services and attract customers, which makes big data cloud storage technology become a research hotspot in the field of big data security. In the era of big data, data storage is a promising business, but large volume of data poses a huge challenge to the traditional cloud storage system [12]. The value of big data mainly comes from its secondary use. Therefore, the integrity authentication technology of big data becomes an indispensable guarantee technology to protect the value of big data [13]. In addition, key management technology is an important technology to ensure user data security and privacy.
In terms of current distributed cloud computing, the data stored in multiple data centers are not scattered. Data are concentrated in multiple data centers. Even if one of them is invaded, it would cause a large volume of data leakage. Meanwhile, in recent years, major media around the world have continuously reported security incidents related to cloud storage, such as the disclosure of personal data of users on iCloud. However, there is no effective way to solve the security problem of distributed cloud storage.
Blockchain is a distributed database that can be added and tampered with. It is a basic technology that supports Bitcoin. In the blockchain, data ownership is established through keys, digital signatures, and account addresses, and these passwords are generated by users and stored in local files or local databases. Without another trusted administrator, the blockchain can manage its own keys. At the same time, the blockchain can also use the load verification consensus mechanism on the blockchain to attract computing resources, thus bringing greater benefits to the integrity work of nodes.
2.2 Localization of big data of blockchain technology
Localized cloud computing private network service is a new technology. Its essence is to provide users with a hybrid cloud service based on cloud computing and traditional architecture in a specific application field, including several aspects covered in Figure 2 (Figure 2 refers to the works of Manikandan and Chinnadurai [14]).

Application form.
2.2.1 Use of data center architecture
In the application of localized cloud computing technology, it is a traditional network architecture based on cloud computing. It includes all kinds of hardware at the user end, most of which are personal computers. These devices usually store and analyze some scattered data and can provide operators with cloud computing systems. When they are used, a large volume of data would be stored. In the application process of localized cloud computing technology, the two systems are regarded as a complete whole, thus facilitating staff to obtain more intuitive and specific data and content. Cloud computing is used to integrate and analyze different data to achieve better execution results.
2.2.2 Cloud computing center architecture
Cloud computing is the infrastructure and content for telecom operators to provide cloud services. Compared with the previous cloud computing technology, the localized cloud computing technology can fully integrate different data and disperse them on different blockchains, thus meeting the higher requirements for cloud computing and can also comprehensively integrate distributed data and information. Private city can be used to ensure that the cloud computing center can connect with various data and reasonably apply it to the private field. The development center of cloud computing can make full use of its advantages and allocate all information to its own resources. According to their own needs, appropriate protocol addresses between networks are selected. The corresponding routers are configured, and the network is divided. In this way, relevant information can be effectively integrated, and knowledge can be transferred smoothly. All information can be automatically stored and shared in the cloud computing center, so as to achieve different automation objectives.
2.2.3 Communication mode selection
In the application of localized cloud computing technology, there are two major parts. One is the local data storage system, and the other is the establishment of a cloud computing center to store and establish various communication data in a reasonable way. This working mode can speed up data transmission and facilitate data transmission, so as to maximize the time of data storage and prevent malicious tampering and theft.
2.2.4 Integration of blockchain and local cloud computing virtual private cloud services
Through the existing optical fiber and virtual private network leased line, the user data center can be connected to the local cloud service. The local cloud computing center can provide reasonable services for the user’s resource configuration and obtain simpler data without affecting the user’s data and content, thus making the content of cloud computing more stable and specific.
Blockchain technology must be integrated with the private cloud to integrate all data into the cloud service center. Different enterprises should integrate reasonably and then distribute profits according to their respective contributions. Only in this way can regional problems be solved and, at the same time, can trust relationships be established. The information between enterprises can be more reasonable, so as to realize the construction of the system.
2.3 IAA
Cloud computing provides an economic and effective method for the storage and analysis of massive data. Therefore, in-depth research on data mining algorithms in cloud computing has been widely used not only in theory but also in practice.
The main function of data mining is to predict the future development trend and possible behavior through the analysis of data and then make corresponding decisions. The ultimate goal of data mining is to discover hidden and meaningful information from massive data.
Data mining includes several main applications shown in Figure 3 (Figure 3 refers to the works of Yates and Islam [15]).

Main applications of data mining.
Concept description: A concise and typical description is obtained by describing the common characteristics and behaviors of the data set. Classification: Based on the analysis of known data, a model that can identify different types or concepts is established to predict unknown data. Clustering: Clustering analysis can be summed up as gathering birds of a feather. Its goal is to differentiate the divided groups so that each group has significant differences in characteristics in different categories, while all data in the same category have significant similarities. This process is to divide a dataset into different classes according to different attributes. Association analysis: Through mining frequent items in the dataset, the correlation between data is obtained. Prediction: By analyzing the rules and development trends of data, future data would be predicted. Isolated point analysis: This is a description of the very few, extreme and specific analysis objects and internal reasons. The discovery of outlier detection plays an important role in commercial fraud and tax evasion.
Apriori algorithm (AA) is one of the common association rule (AR) algorithms. This also includes the partition algorithm, frequent pattern growth algorithm, direct hash and pruning algorithm, and Eclat algorithm. In terms of network security, AA has been widely used in such areas as network intrusion detection. The apriori method has the following disadvantages in practical applications, especially in mining massive data.
However, the strong AR found by AA have some problems that do not conform to the reality in the process of mining, so there is some misleading in mining big data [16].
The judgment of AR in AA is only judged by the two thresholds of support and confidence. If the threshold of support is set too low, it can better mine the relevant rules, but the cost is too high, which would increase the computational complexity; if the support threshold is set too high, many useful rules would be left out, resulting in the incomplete algorithm. Both would lead to the performance degradation of AA.
AA needs to traverse the database for many times when generating frequent candidate projects. When the database size is too large, the load would increase. However, due to the slow processing speed of the system, the calculation time would increase and the calculation efficiency would decrease.
In this article, AA is optimized through the level of interest, which improves its performance. The existing interest models are analyzed and compared below.
Formula (1) shows the probability-based interest model:
In formula (1),
The variance-based interest model is shown in formula (2):
The advantage of the difference-based interest model is to eliminate the impact of the high support rate of the latter item on the confidence of AR and effectively delete the rules that users are not interested in.
The correlation-based interest model is shown in formula (3):
In formula (3),
The interest model based on correlation is defined according to the correlation between the first item X and the second item Y of AR
The interest model of information content is shown in formula (4):
Among them,
This model combines the brevity of the correlation rule
Formula (5) shows the influence-based benefit model:
In formula (5),
Under the same transaction volume M and other conditions, with the increase of the number of Y occurrences
The influence-based interest model uses the influence of X on AR
This article proposes a more suitable interest model by comparing and analyzing various benefit models and the actual needs of government big data mining, and the formula is as follows:
In formula (6),
This article organically integrates the knowledge of probability, difference, and relevance and combines the advantages of three different interest models. In the calculation of interest level of AR
The level of interest calculated by
3 Government data security management experiment and evaluation
3.1 Privacy protection government data sharing framework
This article focused on the data sharing and privacy protection of government departments, including data sharing between governments. This article, from the perspective of blockchain application, fully considered the need for personal information security, and strengthened cooperation between governments, so as to promote information exchange between governments and improve the modern management level of governments. Figure 4 shows the information sharing system for government privacy protection (Figure 4 references the works of Gabelica and other scholars [17]).

Government data sharing framework for privacy protection.
The data sharing of the government departments is based on the internal database of the department and the joint blockchain of the department and the privacy processing module. The purpose is to build the data demand association mechanism, trust mechanism, and privacy protection mechanism between the government departments. The local database of government departments stores the data of relevant departments. Each department is responsible for the data of one or more data blocks, including data metadata, data department, time data directory, data sharing, event time, etc. In the nodes of the block, this information can clearly indicate the ownership and sharing of data sources. When problems or disputes arise in data sharing, these nodes can act as “witnesses” to deal with the rights and responsibilities of data. The “privacy processing” refers to the privacy protection measures taken to protect the user’s personal privacy before the data owner provides the data, such as anonymization, de-accurate identifier, noise interference addition, etc. The data sharing between departments adopts the “request-response” method. That is to say, through the query of the alliance blockchain, the department to which the data belongs is obtained, and the data-sharing request is sent to it. When the data provider receives the shared data, it would protect the privacy of the shared data and then submit the relevant data to the demand department, which would also store the shared data in the blockchain of the alliance.
On this basis, the government also shares information with the society. Each department publishes the information allowed by laws and regulations and protected by privacy to the government information sharing platform, and the published information includes the release time, operator, release data description, etc. The public, enterprises, and social groups can use the public information sharing platform to obtain the information needed by the government according to their own needs to achieve the purpose of social public sharing.
The government information security sharing system based on the alliance chain is proposed, and the relevant information sharing mechanism is proposed on this basis. It must be clear that when the government department obtains data, the metadata, collection time, collection department, and storage department of the data would be packaged into the data chain. It is assumed that there is no privacy leakage in the process of data acquisition and storage, and the data-sharing process between governments is further explained, as shown in Figure 5.
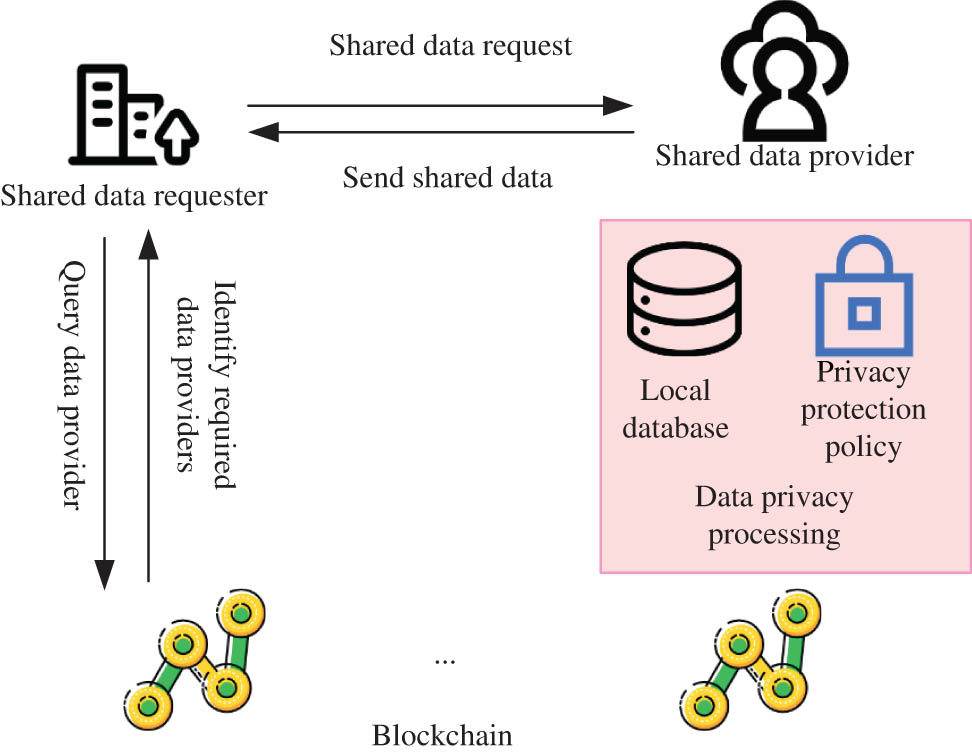
Government data sharing process of privacy protection based on blockchain.
If government department A needs information from government department B, the blockchain-based data-sharing process for public affairs between government departments can be described as follows:
The data demand department A specifies the data they want, and queries through the department alliance chain to determine the data management department B (data supply department) of the data they need.
A transmits the data-sharing request to B.
B selects appropriate data for data processing according to the data sharing request issued by A and the confidentiality policy of the affiliated unit to ensure data availability and privacy.
B transmits the confidential shared data to A and encapsulates the shared event information (such as the information of both sides of the data sharing, data description information, and event occurrence time information) into the alliance chain block.
3.2 Algorithm simulation
In order to verify the performance of the algorithm, the IAA and the CAA were simulated. Hardware in the loop simulation is the process of connecting a real controller to a fake controlled object (simulated using real-time simulation hardware) and conducting comprehensive testing of the controller in an efficient and low-cost manner. Real-time simulation hardware essentially aims to simulate the real controlled object as realistically as possible, in order to effectively deceive the controller into thinking that it is controlling a real controlled object.
The AA is a classic algorithm for mining frequent item sets that generate ARs. By using this algorithm, relationships between items can be found. The AA has two important properties: (1) a subset of frequent itemsets must be a frequent itemset. (2) The superset of a nonfrequent itemset must be a nonfrequent itemset.
To ensure the accuracy of data processing, this article uses the R data processing platform to study different big data and analyze the accuracy changes of different data calculation methods. Statistical analysis is conducted to obtain experimental results. Due to the confidentiality of government data, training data were used to simulate unexpected data: data mining. The simulation hardware environment was as follows: The CPU was Intel(R)Core(TM)i5-4250 dual-core 1.3 Hz; the memory was 6 GB; the operating system was Win764 bits. The IAA and CAA were written in JAVA language, and the development environment was jdk1.8.0_11.
Figure 6 shows the comparison of the mining time and the number of correlation rules mined by the two algorithms. In the two sets of data, the confidence threshold was set to 0.6.

Comparison of mining time and the number of correlation rules mined by the two algorithms: (a) mining time (s) and (b) number of mining correlation rules.
It could be seen from Figure 6a that when the support threshold of the CAA were 0.10, 0.20, 0.30, and 0.40, the mining time were 41.54, 2.84, 0.47, and 0.27 s, respectively. When the interest threshold of the IAA were set to 0.35, the mining time were 43.46, 2.75, 0.38, and 0.18 s, respectively, when the support threshold were 0.10, 0.20, 0.30, and 0.40. When the interest threshold of the IAA was set to 0.50, the mining time were 40.15, 2.82, 0.45, and 0.24 s, respectively, when the support threshold were 0.10, 0.20, 0.30, and 0.40. From the data, it could be seen that there was no great difference between the three, and the IAA not improved the mining time very well.
It could be seen from Figure 6b that when the support threshold of the CAA was 0.10, 0.20, 0.30 and 0.40, the number of mining AR was 510,548, 68,154, 16,484, and 12,048, respectively. When the interest threshold of the IAA was set to 0.35, the number of mining AR were 250,487, 62,547, 16,015, and 11,882, respectively, when the support threshold was 0.10, 0.20, 0.30, and 0.40. When the interest threshold of the IAA was set to 0.50, the number of mining AR were 175,424, 50,157, 14,315, and 10,456, respectively, when the support threshold was 0.10, 0.20, 0.30, and 0.40. It could be seen from the data that the greater the support threshold, the less AR mined by the IAA.
3.3 Performance evaluation
Figure 7 shows data related to key generation time and encryption time.

(a) Key generation time and (b) encryption time.
In Figure 7a, when the number of attributes of the data request user was 20, 40, 60, 80, and 100, the key generation time of the CAA was 186, 265, 335, 379, and 412 ms, respectively, and the key generation time of the IAA was 221, 298, 363, 402, and 432 ms, respectively. It could be seen from the data that with the increase in the number of data request user attributes, the key generation time would gradually approach the CAA.
In Figure 7b, when the number of encrypted files was 200, 400, 600, 800, and 1,000, the encryption time of the CAA was 312, 491, 710, 805, and 1,022 s, respectively, and the encryption time of the IAA was 76, 312, 406, 447, and 503 s, respectively. It could be seen from the data that the IAA required less encryption time than the CAA.
In conclusion, the IAA was effective and feasible in practice.
Figure 8 shows the data related to the number of query key words, trap generation time, and storage cost of the two algorithms.

Query key words, (a) trap generation time and (b) trap generation cost.
In Figure 8a, when the number of key words in the query was 20, 40, 60, 80, and 100, the trap generation time of the CAA was 6.22, 8.04, 8.32, 8.58, and 8.81 s, respectively, and the trap generation time of the IAA was 0.39, 0.86, 1.26, 1.76, and 2.23 s, respectively.
In Figure 8b, when the number of key words in the query was 20, 40, 60, 80, and 100, the trapdoor generation cost of the CAA was 39.87, 60.04, 72.33, 79.24, and 86.10 kB, respectively, and the trapdoor generation cost of the IAA was 4.61, 12.64, 14.02, 15.60, and 17.02 kB, respectively.
It could be seen from the data that the trapdoor generation time and trapdoor generation cost of the CAA were higher than those of the IAA. Therefore, the IAA had some advantages over GAA in trapdoor generation.
Table 1 displays the relevant data about the number of key words in the query and the search time of the results.
Query key words and result search time
| Query keywords | Algorithm | |
|---|---|---|
| CAA (s) | IAA (s) | |
| 10 | 0.53 | 0.48 |
| 20 | 1.08 | 0.76 |
| 30 | 2.15 | 0.92 |
| 40 | 2.76 | 1.68 |
| 50 | 3.98 | 2.72 |
| 60 | 5.15 | 3.74 |
| 70 | 6.28 | 4.72 |
| 80 | 7.32 | 5.69 |
| 90 | 8.31 | 6.64 |
| 100 | 9.24 | 7.58 |
Table 1 shows that when the number of key words in the query were 20, 40, 60, 80, and 100, the result search time of the CAA was 1.08, 2.76, 5.15, 7.32, and 9.24 s, respectively, and the result search time of the IAA was 0.76, 1.68, 3.74, 5.69, and 7.58 s, respectively. It could be seen from the data that with the increase of the number of key words in the query, the result search time gap between the CAA and the IAA was getting larger and larger. The result search time of the IAA was shorter than that of the CAA.
Table 2 shows the relevant data about the number of key words in the query and the search time of the results.
Query key words and result search cost
| Query keywords | Algorithm | |
|---|---|---|
| CAA (kB) | IAA (kB) | |
| 10 | 4.92 | 1.84 |
| 20 | 12.43 | 5.05 |
| 30 | 17.98 | 10.06 |
| 40 | 26.84 | 15.21 |
| 50 | 39.05 | 18.34 |
| 60 | 50.54 | 21.45 |
| 70 | 61.02 | 24.54 |
| 80 | 71.34 | 37.62 |
| 90 | 81.45 | 50.68 |
| 100 | 91.55 | 63.72 |
Table 2 suggests that when the number of key words in the query was 20, 40, 60, 80, and 100, the result search cost of the CAA was 12.43, 26.84, 50.54, 71.34, and 91.55 kB, respectively, and the result search time of the IAA was 5.05, 15.21, 21.45, 37.62, and 63.72 kB, respectively. It could be seen from the data that with the increase of the number of key words in the query, the gap between the result search cost of the CAA and the IAA was becoming larger and larger. The result search cost of the IAA was lower than that of the CAA.
4 Conclusions
The private network service of blockchain and cloud computing solves the problem of mutual trust between local governments and enterprises. On the premise of maintaining existing resources, the computing, storage, broadband resources, and other resources of the existing system are integrated to form a regional cloud computing service chain. Through the effective combination of blockchain technology and cloud computing technology, the credibility of data on the cloud is guaranteed, and the computing speed of the system is improved. At the same time, it can also enhance the computing capacity of redundant computers and optimize resource allocation, which can also improve resource utilization and provide better services for other small enterprises without changing the infrastructure of existing equipment. The combination of blockchain technology and cloud computing technology makes data security and interaction an important guarantee for big data applications.
-
Funding information: This work was supported by Soft Science Project of Science and Technology Department of Henan Province in 2021 “Research on long-term Mechanism of Regional Education Targeted Poverty Alleviation driven by big data” (Project No: 212400410118).
-
Conflict of interest: There are no potential competing interests in this study. And all authors have seen the manuscript and approved to submit to your journal. We confirm that the content of the manuscript has not been published or submitted for publication elsewhere.
-
Data availability statement: Data sharing is not applicable to this article as no datasets were generated or analyzed during the current study.
References
[1] A. K. Sandhu, “Big data with cloud computing: Discussions and challenges,” Big Data Min. Analytics, vol. 5, no. 1, pp. 32–40, 2021.10.26599/BDMA.2021.9020016Search in Google Scholar
[2] R. Varatharajan, G. Manogaran, and M. K. Priyan, “A big data classification approach using LDA with an enhanced SVM method for ECG signals in cloud computing,” Multimed. Tools Appl., vol. 77, no. 8, pp. 10195–10215, 2018.10.1007/s11042-017-5318-1Search in Google Scholar
[3] B. B. Gupta, S. Yamaguchi, and D. P. Agrawal, “Advances in security and privacy of multimedia big data in mobile and cloud computing,” Multimed. Tools Appl., vol. 77, no. 7, pp. 9203–9208, 2018.10.1007/s11042-017-5301-xSearch in Google Scholar
[4] Y. Zhang, M. Yang, D. Zheng, P. Lang, A. Wu, and C. Chen, “Efficient and secure big data storage system with leakage resilience in cloud computing,” Soft Comput., vol. 22, no. 23, pp. 7763–7772, 2018.10.1007/s00500-018-3435-zSearch in Google Scholar
[5] S. Gupta and R. Godavarti, “IoT data management using cloud computing and big data technologies,” Int. J. Softw. Innov. (IJSI), vol. 8, no. 4, pp. 50–58, 2020.10.4018/IJSI.2020100104Search in Google Scholar
[6] K. K. Mohbey and S. Kumar, “The impact of big data in predictive analytics towards technological development in cloud computing,” Int. J. Eng. Syst. Model. Simul., vol. 13, no. 1, pp. 61–75, 2022.10.1504/IJESMS.2022.122732Search in Google Scholar
[7] V. Jagadeeswari, V. Subramaniyaswamy, R. Logesh, and V. Vijavakumar, “A study on medical Internet of things and big data in personalized healthcare system,” Health Inf. Sci. Syst., vol. 6, no. 1, pp. 1–20, 2018.10.1007/s13755-018-0049-xSearch in Google Scholar PubMed PubMed Central
[8] M. Y. Sokiyna, M. J. Aqel, and O. A. Naqshbandi, “Cloud computing technology algorithms capabilities in managing and processing big data in business organizations: Mapreduce, hadoop, parallel programming,” J. Inf. Technol. Manag., vol. 12, no. 3, pp. 100–113, 2020.Search in Google Scholar
[9] A. Ullah, “Rise of big data due to hybrid platform of cloud computing and Internet of Thing,” J. Soft Comput. Data Min., vol. 1, no. 1, pp. 46–54, 2020.Search in Google Scholar
[10] A. T. Lo'ai and G. Saldamli, “Reconsidering big data security and privacy in cloud and mobile cloud systems,” J. King Saud. University-Comput. Inf. Sci., vol. 33, no. 7, pp. 810–819, 2021.10.1016/j.jksuci.2019.05.007Search in Google Scholar
[11] P. Srivastava and R. Khan, “A review paper on cloud computing,” Int. J. Adv. Res. Comput. Sci. Softw. Eng., vol. 8, no. 6, pp. 17–20, 2018.10.23956/ijarcsse.v8i6.711Search in Google Scholar
[12] X. Li, H. Jianmin, B. Hou, and P. Zhang, “Exploring the innovation modes and evolution of the cloud-based service using the activity theory on the basis of big data,” Clust. Comput., vol. 21, no. 1, pp. 907–922, 2018.10.1007/s10586-017-0951-zSearch in Google Scholar
[13] S. P. Singh, A. Nayyar, R. Kumar, and A. Sharma, “Fog computing: from architecture to edge computing and big data processing,” J. Supercomput., vol. 75, no. 4, pp. 2070–2105, 2019.10.1007/s11227-018-2701-2Search in Google Scholar
[14] S. Manikandan and M. Chinnadurai, “Virtualized load balancer for hybrid cloud using genetic algorithm,” Intell. Autom. Soft Comput., vol. 32, no. 3, pp. 1459–1466, 2022.10.32604/iasc.2022.022527Search in Google Scholar
[15] D. Yates and M. Z. Islam, “Data mining on smartphones: An introduction and survey,” ACM Comput. Surv., vol. 55, no. 5, pp. 1–38, 2022.10.1145/3529753Search in Google Scholar
[16] J. Wang, Y. Yang, T. Wang, R. S. Sherratt, and J. Zhang, “Big data service architecture: a survey,” J. Internet Technol., vol. 21, no. 2, pp. 393–405, 2020.Search in Google Scholar
[17] M. Gabelica, R. Bojčić, and L. Puljak, “Many researchers were not compliant with their published data sharing statement: a mixed-methods study,” J. Clin. Epidemiol., vol. 150, pp. 33–41, 2022.10.1016/j.jclinepi.2022.05.019Search in Google Scholar PubMed
© 2023 the author(s), published by De Gruyter
This work is licensed under the Creative Commons Attribution 4.0 International License.
Articles in the same Issue
- Nondestructive detection of potato starch content based on near-infrared hyperspectral imaging technology
- Regular Articles
- SMACS: A framework for formal verification of complex adaptive systems
- Data preprocessing impact on machine learning algorithm performance
- A combinatorial algorithm and its application in computing all minimum toll sets of graphs
- Special Issue on Programming Models and Algorithms for Big Data - Part II
- Application of artificial intelligence-based style transfer algorithm in animation special effects design
- Zebra-crossing detection based on cascaded Hough transform principle and vanishing point characteristics
- Visual inspection intelligent robot technology for large infusion industry
- RFID supply chain data deconstruction method based on artificial intelligence technology
- Dynamic system allocation and application of cloud computing virtual resources based on system architecture
- Special Issue on Big Data Applications and Techniques in Cyber Intelligence
- Application of fingerprint image fuzzy edge recognition algorithm in criminal technology
- Big data technology for computer intrusion detection
- Digital forensics analysis based on cybercrime and the study of the rule of law in space governance
- Machine learning-based processing of unbalanced data sets for computer algorithms
- Intelligent cluster construction of internet financial security protection system in banking industry
- Artificial intelligence-based public safety data resource management in smart cities
- Simulation evaluation of underwater robot structure and control system based on ADAMS
- Application of SSD network algorithm in panoramic video image vehicle detection system
- UAV patrol path planning based on machine vision and multi-sensor fusion
- Analysis of research results of different aspects of network security and Internet of Things under the background of big data
- Exploration on the application of electronic information technology in signal processing based on big data
- Application of wireless sensor network technology based on artificial intelligence in security monitoring system
- Blockchain localization cloud computing big data application evaluation method
- Low-illumination image enhancement with logarithmic tone mapping
Articles in the same Issue
- Nondestructive detection of potato starch content based on near-infrared hyperspectral imaging technology
- Regular Articles
- SMACS: A framework for formal verification of complex adaptive systems
- Data preprocessing impact on machine learning algorithm performance
- A combinatorial algorithm and its application in computing all minimum toll sets of graphs
- Special Issue on Programming Models and Algorithms for Big Data - Part II
- Application of artificial intelligence-based style transfer algorithm in animation special effects design
- Zebra-crossing detection based on cascaded Hough transform principle and vanishing point characteristics
- Visual inspection intelligent robot technology for large infusion industry
- RFID supply chain data deconstruction method based on artificial intelligence technology
- Dynamic system allocation and application of cloud computing virtual resources based on system architecture
- Special Issue on Big Data Applications and Techniques in Cyber Intelligence
- Application of fingerprint image fuzzy edge recognition algorithm in criminal technology
- Big data technology for computer intrusion detection
- Digital forensics analysis based on cybercrime and the study of the rule of law in space governance
- Machine learning-based processing of unbalanced data sets for computer algorithms
- Intelligent cluster construction of internet financial security protection system in banking industry
- Artificial intelligence-based public safety data resource management in smart cities
- Simulation evaluation of underwater robot structure and control system based on ADAMS
- Application of SSD network algorithm in panoramic video image vehicle detection system
- UAV patrol path planning based on machine vision and multi-sensor fusion
- Analysis of research results of different aspects of network security and Internet of Things under the background of big data
- Exploration on the application of electronic information technology in signal processing based on big data
- Application of wireless sensor network technology based on artificial intelligence in security monitoring system
- Blockchain localization cloud computing big data application evaluation method
- Low-illumination image enhancement with logarithmic tone mapping