Automatic Segmentation of Insurance Rating Classes Under Ordinal Constraints via Group Fused Lasso
-
Atsumori Takahashi



Abstract
This paper proposes a sparse regularization technique for ratemaking under practical constraints. In tariff analysis of general insurance, rating factors with many categories are often grouped into a smaller number of classes to obtain reliable estimate of expected claim cost and make the tariff simple to reference. However, the number of rating-class segmentation combinations is often very large, making it computationally impossible to compare all the possible segmentations. In such cases, an L1 regularization method called the fused lasso is useful for integrating adjacent classes with similar risk levels in its inference process. Particularly, an extension of the fused lasso, known as the group fused lasso, enables consistent segmentation in estimating expected claim frequency and expected claim severity using generalized linear models. In this study, we enhance the group fused lasso by imposing ordinal constraints between the adjacent classes. Such constraints are often required in practice based on bonus–malus systems and actuarial insight on risk factors. We also propose an inference algorithm that uses the alternating direction method of multipliers. We apply the proposed method to motorcycle insurance claim data, and demonstrate how some adjacent categories are grouped into clusters with approximately homogeneous levels of expected claim frequency and severity.
1 Introduction
Premium tariffs have long been used to reference general insurance premiums according to insured’s attribute information. Tariff theory has developed along with modern statistical theory. Generalized linear models (GLMs) by Nelder and Wedderburn (1972) can model expected claim frequency and severity for each risk profile and estimate them from past claims data. Many rating factors can be incorporated into GLMs, and the optimal model can be chosen via model selection methods such as cross validation. However, some rating factors, such as the insured’s age, address and occupation, often have too many categories to obtain reliable estimates for their individual categories. In addition, complex tariffs with many categories may increase the operational risk of applying incorrect premiums. Hence, rating categories are often grouped into fewer categories which have similar risk levels in practice.
However, finding the optimal grouping of the rating categories based on a model selection criterion is difficult, because of the immense computational workload required to process almost infinite number of grouping combinations. In such cases, rating categories have been grouped based on simplicity, sales strategies, and actuarial decision-making. Some studies have applied clustering methods to reduce the rating factors and categories (e.g. Pelessoni and Picech 1998; Guo 2003; Sanche and Lonergan 2006; Yao et al. 2016). Nonetheless, most of them separate the inference and clustering procedures, which would not provide solutions satisfying both the inference criterion and the clustering criterion simultaneously.
In recent years, sparse regularization techniques, originating from the least absolute shrinkage and selection operator (lasso) by Tibshirani (1996), have been developed to enable fast variable selection when processing big data. Particularly, the fused lasso by Tibshirani et al. (2005) and its extensions are useful for automatically integrating the categories of factors by optimizing an objective function with L1 regularization terms for the differences between the regression coefficients on adjacent categories. Fujita et al. (2020) implemented the one-dimensional fused lasso for GLMs by introducing dummy variables with the ordinary lasso which indicate whether the category in each data comes before or after some change-points. Devriendt et al. (2021) proposed an efficient algorithm for sparse regression with multi-type regularization terms including the lasso and fused lasso with an application to insurance pricing analytics. Bleakley and Vert (2011) proposed the group fused lasso on a line to detect multiple change-points in multi-task learning and Alaíz, Barbero, and Dorronsoro (2013) generalized that approach to the group fused lasso on general adjacent graphs with an efficient algorithm. Nomura (2017) used the group fused lasso to integrate rating categories consistently between expected claim frequency and expected claim severity, which are modeled separately using GLMs.
In this paper, we enhance the group fused lasso used in Nomura (2017) by imposing ordinal constraints on the regression coefficients in the GLMs to meet practical requirements such as the bonus–malus system in automobile insurance. The optimization problem for parameter inference can be solved by the alternating direction multiplier method (ADMM), which is modified from the one in Nomura (2017) to satisfy the ordinal constraints. Interaction of variables with the ordinal constraints can also be incorporated into our model and solved by the modified ADMM.
The remainder of this article is organized as follows; The GLMs for claim frequency and claim severity are introduced in Section 2. The group fused lasso and the ADMM as its optimization algorithm proposed in Nomura (2017) are presented in Sections 3 and 4, respectively. The ordinal constraints on the group fused lasso and the modified ADMM are proposed in Section 5. An application of the proposed methods to motorcycle insurance data is presented in Section 6. The conclusion is finally presented in Section 7.
2 Generalized Linear Models for Claim Frequency and Severity
This section introduces the generalized linear models for insurance pricing as the fundamental models used in this study. Consider p rating factors whose numbers of categories are n 1, …, n p , respectively. There are T policies or a group of policies with the same factor categories. Let x t1, …, x tp denote the categories to which the tth policy or group of policies belongs. A generalized linear model (GLM) is an extended version of an ordinary linear regression model that can handle probability distributions in the exponential dispersion model and nonlinear link functions. In the exponential dispersion model, the probability mass functions or probability density functions of the observations a 1, …, a T have a common form expressed as
where θ t denotes the parameter related to the mean of the observation a t of the tth policy and ϕ is the dispersion parameter related to the variance of all the observation a 1, …, a T across the policies. Moreover, d t is the weight assigned to the tth policy and affects the variance of the observation a t . The function b(θ t ) is assumed to be twice-differentiable and the function c(a t , d t , ϕ) is a normalization constant that makes the sum of probabilities equal to one irrespective of the value of θ t . The mean and variance of a t are expressed using the first-order derivative b′ and second-order derivative b″ of the function b as follows:
Ratemaking in general insurance often involves estimating the expected claim frequency and expected claim severity, separately, rather than estimating the expected total claim cost as the pure premium directly. Therefore, we next introduce the exponential dispersion models for claim frequency and claim severity, respectively.
The Poisson distribution with the following probability mass function is often applied to the number of claims per policy:
where z
t
and w
t
are the number of claims and the exposure of the tth policy, respectively. Then, it holds that
Given the number of claims z t from the tth policy, the gamma distribution with the following probability density function can be fitted to the claim severity:
where y
t
is the mean severity of the claims from the tth policy. Then, we have
Let x ti t = 1, …, T, i = 1, …, p denote the category of the ith factor to which the tth policy belongs. In a generalized linear model, the mean parameter μ t found in (3) and (4) is formulated by:
where β 0 is the intercept and β ij is the regression coefficient for the jth category of the ith factor. Note that each factor has one reference category whose regression coefficient is fixed at zero. The function g is a differentiable monotonic function called a link function. When the link function is an identity function g(y) ≡ y, the mean parameter μ t is just the right side of Equation (5). In contrast, when the link function is a logarithmic function g(y) = logy, the mean parameter μ t is formulated by
In this case, exp(β ij ) represents the relative risk of the jth category from the reference category in the ith factor.
The parameters in GLMs are typically estimated via the maximum likelihood method. Let
where
Particularly, the maximum likelihood estimate
Therefore, we can first estimate the regression coefficients β by (9) and then estimate the dispersion parameter ϕ by optimizing the log-likelihood (7). Regarding the Poisson distribution (3), the dispersion parameter ϕ is fixed at one, as mentioned above, and the regression coefficients β are estimated by
Regarding the gamma distribution (4), the estimates (9) of the regression coefficients become
These optimization problems can be solved quickly through optimization methods, which are typically gradient-based methods such as Newton’s method. If we apply the logarithmic link function g(y) = log(y), the objective functions in (10) and (11) become strictly convex functions, each of which has a unique local minimum that can be obtained by ordinary optimization methods.
3 Automatic Segmentation of Rating Categories via the Group Fused Lasso
We have introduced the GLMs to estimate expected claim frequency and expected claim severity from claim data. However, when using rating factors with so many categories or interactions of the factors, we have so many regression coefficients that their estimates might have large errors. In such cases, categories with similar risk levels are often integrated into groups in practice. Thus, in this section, we introduce the group fused lasso proposed by Bleakley and Vert (2011) to facilitate automatic segmentation of categories in rating factors.
For sake of simplicity, let the first factor consist of a large number of categories V = {1, …, n 1} which need to be integrated into fewer groups for ratemaking. We define a set of pairs of adjacent categories E = {e 1, …, e m } ⊆ V × V as candidates of pairs to be integrated. The set (V, E) is often referred as an undirected graph where V is a set of vertices and E is a set of edges. The fused lasso on the graph (V, E) is a regularization technique to estimate the regression coefficients by solving the following optimization problem:
where the first term q( β , ϕ; y t , w t ) is a loss function, which becomes the negative log-likelihood function in GLMs. The second term is the L1 regularization term on the differences between the pairs of coefficients (β 1u , β 1v ) of adjacent categories (u, v) ∈ E, which encourages the coefficients β 1u , β 1v to have similar or even the same values. The categories whose regression coefficients are estimated at the same value are regarded as a group in rating-class segmentation. The weight κ on the second term is called a regularization parameter, and adjusts the impact of the regularization term.
Using the fused lasso (12), expected claim frequency and expected claim severity are estimated separately and hence would have different groupings. Since the pure premium is obtained by the product of expected claim frequency and expected claim severity, it is more desirable to determine grouping of rating classes consistently between expected claim frequency and expected claim severity. Therefore, we introduce the group fused lasso to estimate expected claim frequency and expected claim severity simultaneously by solving the following optimization problem:
where f
1 and f
2 are the probability mass function (3) of the Poisson distribution and the probability density function (4) of the gamma distribution, respectively. The loss function in Equation (13) is a negative log-likelihood for the joint distribution of the number of claims z
t
and claim severity y
t
. The regression coefficients
β
(1) and
β
(2) are involved with the expected claim frequency
where
This probability distribution of the total claim cost s t = y t z t is a compound Poisson distribution with the gamma distribution (4) and known as the Tweedie distribution proposed by Tweedie (1984). By using the Tweedie distribution, we intend to evaluate predictive performance for the total claim costs directly. Finally, the value which minimizes the validation error is selected for the regularization parameter κ.
4 Optimization Algorithm for Group Fused Lasso
This section describes the algorithm to solve the optimization problem (13) introduced in the previous section. The optimization problem (8) without regularization terms can be quickly solved by using gradient-based methods such as Newton’s method and its variants. However, gradient-based methods are not applicable to the objective function in (13) whose gradients do not exist if one of the regularization terms takes exact zero. Some optimization algorithms have been proposed for the group fused lasso; the block coordinate descent method by Bleakley and Vert (2011), the alternating direction method of multipliers (ADMM) by Wahlberg et al. (2012), and the active set projected Newton method by Wytock, Sra, and Kolter (2014). The block coordinate descent method is only applicable to group fused lasso on a chain graph which can be reduced into an ordinary grouped lasso. The active set projected Newton method proposed can achieve solutions quickly for the group fused lasso on a general graph, but is difficult to apply to general loss functions other than the residual sum of squares. In contrast, the ADMM is highly versatile and can be applied to general convex loss functions and group fused lasso on general graphs. Thus, we introduce the ADMM to solve (13).
The ADMM is an optimization method that extends the Lagrange multiplier method, in which augmented Lagrangian terms are added to the objective function. Before introducing the augmented Lagrangian, we rewrite the optimization problem (13) into the following equivalent constrained optimization problem:
where
The regularization terms
where
5 Group Fused Lasso under Ordinal Constraints
We have introduced the GLMs with the group fused lasso proposed in Nomura (2017) to estimate expected claim costs for automatically grouped rating classes. In practice, some ordinal constraints are often imposed to insurance premiums such as monotonic constraints on bonus–malus classes in automobile insurance. To obtain estimates that satisfy such constraints, we propose the group fused lasso for the GLMs under monotonic constraints and a modification of the ADMM given in the previous section.
We inherit the notation in the previous sections and consider the following optimization problem for grouping expected claim frequency and expected claim severity simultaneously under ordinal constraints.
The sign of inequality in constraints ≥ represents the inequality applied to each element, i.e., x ≥ y for x = (x 1, …, x n ) and y = (y 1, …, y n ) means x i ≥ y i (i = 1, …, n). The optimization problem (21) can be solved by the ADMM constructed in a similar manner with that in the previous section. First, we rewrite the optimization problem (21) into the following equivalent optimization problem:
Then, the update equations of the ADMM to solve (22) can be obtained by adding the constraints ξ l ≥ 0 to those in the previous section:
The objective function in (23) is the same as that in (17) and hence gradient-based methods can be used. The solution of the optimization problem in (24) can be analytically obtained by
where
6 Application to Motorcycle Insurance Data
In this section, we apply the proposed method to claim data of the Swedish motorcycle insurance in Ohlsson and Johansson (2010). The data contain attribute information, exposure, number of claims, and total claim cost of each policy. We used the following variables in the dataset:
The owner’s age, between 0 and 99.
The EV-rate class classified by so called the EV ratio (=engine output (kW) ÷ (vehicle weight (kg) + 75) × 100).[1]
The city-size class classified by the scale and location of cities and towns.[2]
The Bonus–malus class taking values from 1 to 7. The class starts from 1 for a new driver, increases by 1 for each claim-free year, and decreases by 2 for each claim.
The Exposure or the number of policy years.
The number of claims.
The claim cost in Swedish Kronor.
Table 1 shows the summary statistics aggregated by factor. Here, the claim frequency is calculated by dividing the number of claims by the exposure, and the claim severity is calculated by dividing the claim cost by the number of claims. As shown in Table 1, the claim frequency tends to be higher for younger owners, higher EV-rates (engine output), and larger cities. In contrast, the claim severity is relatively high for 20–59 year-old owners, the middle EV-rate (class 3), and large cities. Note that the claim frequency and severity do not always decline as the bonus–malus class increases.
Summary table of motorcycle insurance claim data aggregated by factor.
| Factor | Class | Exposure | Number of claims | Claim frequency | Claim cost | Claim severity |
|---|---|---|---|---|---|---|
| Owner’s age | 0–19 | 1247 | 32 | 0.026 | 353,883 | 11,059 |
| 20–39 | 17,141 | 399 | 0.023 | 10,855,509 | 27,207 | |
| 40–59 | 41,911 | 237 | 0.006 | 5,448,987 | 22,992 | |
| 60–99 | 4938 | 29 | 0.006 | 383,441 | 13,222 | |
| EV-rate | 1 | 5190 | 46 | 0.009 | 993,062 | 21,588 |
| 2 | 3990 | 57 | 0.014 | 883,137 | 15,494 | |
| 3 | 21,666 | 166 | 0.008 | 5,371,543 | 32,359 | |
| 4 | 11,740 | 98 | 0.008 | 2,191,578 | 22,363 | |
| 5 | 13,440 | 149 | 0.011 | 3,297,119 | 22,128 | |
| 6 | 8880 | 175 | 0.020 | 4,160,776 | 23,776 | |
| 7 | 331 | 6 | 0.018 | 144,605 | 24,101 | |
| City-size | 1 | 6205 | 183 | 0.029 | 5,539,963 | 30,273 |
| 2 | 10,103 | 167 | 0.017 | 4,811,166 | 28,809 | |
| 3 | 11,677 | 123 | 0.011 | 2,522,628 | 20,509 | |
| 4 | 32,628 | 196 | 0.006 | 3,774,629 | 19,258 | |
| 5 | 1582 | 9 | 0.006 | 104,739 | 11,638 | |
| 6 | 2800 | 18 | 0.006 | 288,045 | 16,003 | |
| 7 | 241 | 1 | 0.004 | 650 | 650 | |
| Bonus–malus | 1 | 12,657 | 135 | 0.011 | 2,914,082 | 21,586 |
| 2 | 7236 | 72 | 0.010 | 1,643,990 | 22,833 | |
| 3 | 5151 | 57 | 0.011 | 1,749,701 | 30,697 | |
| 4 | 4465 | 64 | 0.014 | 1,877,441 | 29,335 | |
| 5 | 3771 | 45 | 0.012 | 1,297,572 | 28,835 | |
| 6 | 4060 | 43 | 0.011 | 1,327,955 | 30,883 | |
| 7 | 27,896 | 281 | 0.010 | 6,231,079 | 22,175 |
Throughout this section, we fit the Poisson GLM (3) and the gamma GLM (4) to the number of claims y t and the claim severity z t (=the claim cost ÷ the number of claims), respectively, with log link g(μ) = logμ and p = 4 risk factors: the owner’s age x t1, EV-rate class x t2, city-size class x t3, and bonus–malus class x t4 of the tth policy. The owner’s age x t1 has n 1 = 100 (0–99 years old) grades, whereas the other factors x t2, x t3, x t4 have n 2 = n 3 = n 4 = 7 grades for each. In particular, we apply the group fused lasso on several types of underlying graphs with monotonic constraints for the EV-rate and Bonus–malus classes in the following subsections.
6.1 Group Fused Lasso for Single Factors with Monotonic Constraints
First, we incorporated the group fused lasso for each factor into the GLMs and considered the following optimization problem to estimate the parameters:
where
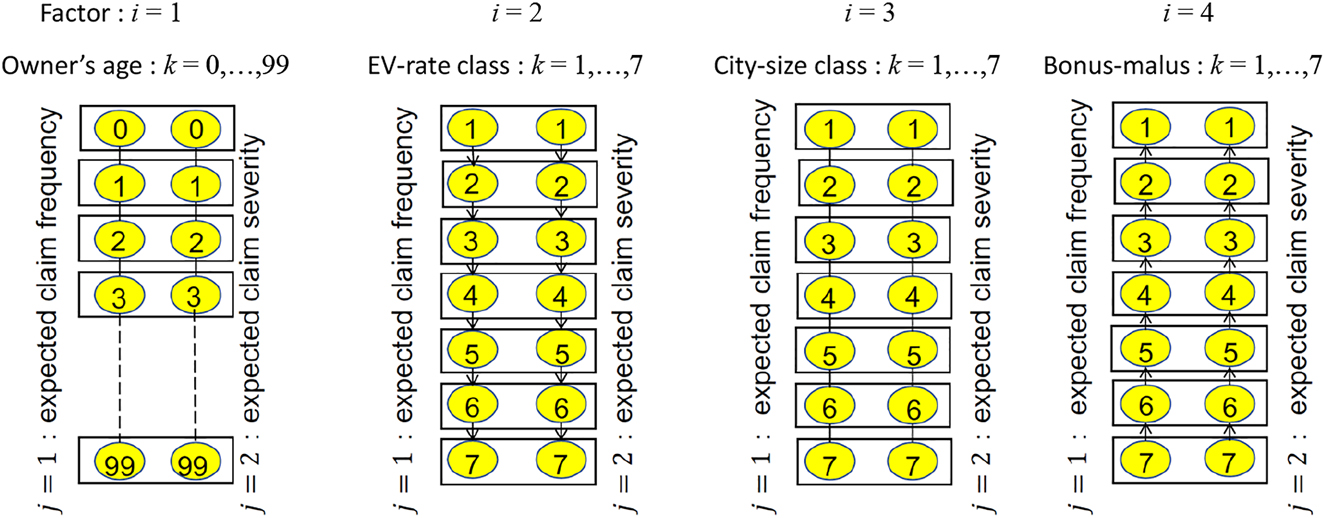
Underlying adjacent graphs of the group fused lasso for single factors.
To solve the optimization problem (27), we first rewrite it into the following equivalent optimization problem:
Then, the update equations to solve (28) are constructed in the same manner as in the previous sections and given by
where ρ i is basically set at κ for i = 1, 2, 3, 4 but partially adjusted as ρ 3 = max{10κ, 10} when κ < 10 to accelerate convergence to the optimal solution. The optimization in Equations (30)–(32) are analytically solved as described in the previous sections. First, the analytical solution of (30) is given by
where
where
where
We selected the value of the regularization parameter κ by five-fold cross validation with the validation error (14), which is the negative log-likelihood of the total claim costs in the validation data, from 100 grid points
The validation error for each candidate value of κ is shown in Figure 2 and takes a minimum value of 9462.0 when κ = 14.9 as indicated by the vertical dotted line. Therefore, we adopted κ = 14.9 and estimated the parameters from all the data. From the estimates

Cross validation errors for candidate values of regularization parameter κ.
Estimates of relative expected claim frequency, relative expected claim severity, and relative expected total claim cost for 14 groups of owner’s age.
| Owner’s age | Relative expected | Relative expected | Relative expected |
|---|---|---|---|
| claim frequency | claim severity | total claim cost | |
| 0–24 | 2.090 | 0.779 | 1.627 |
| 25 | 1.636 | 1.044 | 1.708 |
| 26 | 1.609 | 1.067 | 1.716 |
| 27 | 1.437 | 1.048 | 1.506 |
| 28 | 1.260 | 1.072 | 1.350 |
| 29 | 1.092 | 1.031 | 1.126 |
| 30 | 1.000 | 1.000 | 1.000 |
| 31–33 | 0.705 | 0.942 | 0.664 |
| 34 | 0.624 | 0.942 | 0.588 |
| 35 | 0.504 | 0.954 | 0.481 |
| 36–39 | 0.465 | 0.942 | 0.439 |
| 40–42 | 0.403 | 0.911 | 0.367 |
| 43,44 | 0.396 | 0.899 | 0.356 |
| 45–99 | 0.361 | 0.789 | 0.285 |
Estimates of relative expected claim frequency, relative expected claim severity, and relative expected total claim cost for three groups of EV-rate classes.
| EV-rate class | Relative expected | Relative expected | Relative expected |
|---|---|---|---|
| claim frequency | claim severity | total claim cost | |
| 1–4 | 1.000 | 1.000 | 1.000 |
| 5 | 1.313 | 1.000 | 1.313 |
| 6,7 | 2.023 | 1.000 | 2.023 |
Estimates of relative expected claim frequency, relative expected claim severity, and relative expected total claim cost for four groups of city-size classes.
| City-size class | Relative expected | Relative expected | Relative expected |
|---|---|---|---|
| claim frequency | claim severity | total claim cost | |
| 1 | 4.151 | 1.552 | 6.443 |
| 2 | 2.539 | 1.493 | 3.791 |
| 3 | 1.522 | 1.147 | 1.747 |
| 4–7 | 1.000 | 1.000 | 1.000 |

Estimates of relative expected claim frequency, relative expected claim severity, and relative expected total claim cost for owner’s age.
In Table 2 and Figure 3, the 100 categories of owner’s age were integrated into 14 groups; two of them contain wide ranges of younger ages 0–24 and older ages 45–99, respectively, and eight of them around 30 consist of single ages, which indicates that there are significant differences in insurance risk between those ages.
The estimated expected claim frequency decreases monotonically with respect to the owner’s age and its difference is up to 5.8 times. In contrast, the estimated expected claim severity is the lowest in the youngest class 0–24 and the highest in late 20s, whose difference is only 1.4 times. Consequently, the product of them – the estimated expected total cost of claims – has its peak at 26, monotonically decreases after 26, and has six-fold difference at most.
The EV-rate classes over and under the class 5 were integrated, respectively, which results in three groups of the EV-rate classes. There is two-fold difference in the estimated expected claim frequency but no difference in the estimated expected claim severity between the first and the last groups.
Regarding the city-size classes, the classes 4–7 were integrated into one group and the others remained as single classes. Both the estimated expected claim frequency and estimated expected claim severity decrease monotonically with respect to the city-size classes and their difference is up to 4.2 and 1.6 times, respectively, which results in the difference up to 6.4 times in the estimated expected total cost of claims.
6.2 Group Fused Lasso for Interaction of Multiple Factors with Monotonic Constraints
In GLMs, interaction of multiple factors often improves predictive performance. The group fused lasso can also be applied to interaction of multiple factors with monotonic constraints by considering a multi-dimensional lattice graph. Although we tried several kinds of combinations for interaction, we explain the specific design of the model with interaction city-size classes × bonus–malus classes, which achieved the smallest validation error in five-fold cross validation among them.
where

Underlying adjacent graphs of the group fused lasso for interaction of city-size classes and bonus–malus classes.
Then, we rewrite (37) into the following equivalent optimization problem:
Subsequently, the update equations to solve (38) are given by
where ρ i is basically set at κ 1 for i = 1, 2 and at κ 2 for i = 3, 4 but partially adjusted as ρ 3 = ρ 4 = max{10κ 2, 10} when κ 2 < 10 to accelerate convergence to the optimal solution. The optimal solutions in (40) and (41), which are the same as Equations (30) and (31), are given by (34) and (35), respectively. The analytical solution of (42) is given by
where
where
The validation error for each candidate value of κ is shown in Figure 5 and takes a minimum value of 9458.6, which is less than that in the previous analysis, when κ 2 = 1.02 as indicated by the vertical dotted line. In the similar way, we also tried some other combination of interaction; EV-rate classes × city-size classes, EV-rate classes × bonus–malus classes, and EV-rate classes × city-size classes × bonus–malus classes. The results are summarized in Table 5 and indicate that the model with interaction city-size classes × bonus–malus classes has the smallest validation error of the four candidates.

Cross validation errors for candidate values of regularization parameter κ 2 in interaction model.
Comparison of interaction models.
| Combination of interaction | Regularization parameter κ 2 | Validation error |
|---|---|---|
| City-size × bonus–malus | 1.02 | 9458.6 |
| EV-rate × city-size | 1.66 | 9470.1 |
| EV-rate × bonus–malus | 1.17 | 9461.4 |
| EV-rate × city-size × bonus–malus | 0.472 | 9474.4 |
Thus, we adopted the model using interaction city-size classes × bonus–malus classes with κ
1 = 14.9, κ
2 = 1.02 and estimated the parameters from all the data. The estimated expected claim frequency
Estimates of relative expected claim frequency, relative expected claim severity, and relative expected total claim cost for 14 groups of owner’s age by interaction model.
| Owner’s age | Expected claim | Expected claim | Expected total cost of |
|---|---|---|---|
| frequency difference | severity difference | claims difference | |
| 0–24 | 2.127 | 0.730 | 1.553 |
| 25 | 1.664 | 1.012 | 1.683 |
| 26 | 1.594 | 1.076 | 1.714 |
| 27 | 1.473 | 1.073 | 1.580 |
| 28 | 1.289 | 1.098 | 1.416 |
| 29 | 1.127 | 1.054 | 1.188 |
| 30 | 1.000 | 1.000 | 1.000 |
| 31–33 | 0.719 | 0.937 | 0.673 |
| 34 | 0.639 | 0.938 | 0.599 |
| 35 | 0.516 | 0.953 | 0.491 |
| 36–39 | 0.479 | 0.941 | 0.450 |
| 40–42 | 0.420 | 0.913 | 0.384 |
| 43,44 | 0.410 | 0.894 | 0.367 |
| 45–99 | 0.374 | 0.780 | 0.292 |
Estimates of relative expected claim frequency, relative expected claim severity, and relative expected total claim cost for three groups of EV-rate classes by interaction model.
| EV-rate class | Relative expected | Relative expected | Relative expected |
|---|---|---|---|
| claim frequency | claim severity | total claim cost | |
| 1–4 | 1.000 | 1.000 | 1.000 |
| 5 | 1.335 | 1.000 | 1.335 |
| 6, 7 | 2.078 | 1.016 | 2.110 |
Estimates of relative expected claim frequency for interaction of the city-size classes and the bonus–malus classes.
| Bonus–malus class | ||||||||
|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | ||
| City-size class | 1 | 5.741 | 4.657 | 4.578 | 4.578 | 3.917 | 3.917 | 3.917 |
| 2 | 2.618 | 2.618 | 2.618 | 2.618 | 2.618 | 2.618 | 2.618 | |
| 3 | 1.589 | 1.589 | 1.589 | 1.589 | 1.589 | 1.589 | 1.589 | |
| 4 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |
| 5 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0.980 | |
| 6 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |
| 7 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |
Estimates of relative expected claim severity for interaction of the city-size classes and the bonus–malus classes.
| Bonus–malus class | ||||||||
|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | ||
| City-size class | 1 | 1.747 | 1.747 | 1.717 | 1.717 | 1.557 | 1.344 | 1.344 |
| 2 | 1.556 | 1.556 | 1.556 | 1.556 | 1.556 | 1.556 | 1.556 | |
| 3 | 1.410 | 1.410 | 1.410 | 1.205 | 1.205 | 1.205 | 0.789 | |
| 4 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |
| 5 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0.744 | |
| 6 | 1.008 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0.650 | |
| 7 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0.650 | |
Estimates of relative expected total claim cost for interaction of the city-size classes and the bonus–malus classes.
| Bonus–malus class | ||||||||
|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | ||
| City-size class | 1 | 10.027 | 8.133 | 7.860 | 7.860 | 6.100 | 5.264 | 5.264 |
| 2 | 4.072 | 4.072 | 4.072 | 4.072 | 4.072 | 4.072 | 4.072 | |
| 3 | 2.241 | 2.241 | 2.241 | 1.915 | 1.915 | 1.915 | 1.254 | |
| 4 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |
| 5 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0.729 | |
| 6 | 1.008 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0.650 | |
| 7 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0.650 | |

Estimates of relative expected claim frequency, relative expected claim severity, and relative expected total claim cost for owner’s age by interaction model.
As shown in Tables 6 and 7, and Figure 6, we obtained the same integrated groups and almost the same estimates as in the previous analysis for the owner’s age and the EV-rate classes. The estimates in Tables 8 –10 indicate strong interaction between the city-size classes and the bonus–malus classes. There is about two-fold difference for the city-size class 1 but no difference for the city-size classes 2 and 4 in the expected total claim cost between the bonus–malus classes. In the city-size classes 5–7, the expected total claim cost drops by around 30% when the bonus–malus class goes up to 7 from the others. Consequently, the 49 combinations of the city-size classes and the bonus–malus classes are integrated into 13 groups in the expected total claim cost, whose difference is up to 15.4 times.
7 Conclusion
This paper introduced ordinal constraints on risk factors to the group fused lasso for insurance pricing. The group fused lasso encourages grouping regression coefficients of adjacent categories through optimization of the objective function including the group fused lasso terms. Strength of the grouping is adjusted by regularization parameter κ, which is tuned by minimizing cross-validation error that evaluates predictive performance on the validation datasets. Therefore, the grouping of rating factors is determined to have the optimal predictive performance within possible groupings induced by the group fused lasso.
We added monotonic/ordinal constraints practically required for some risk factors such as bonus–malus classes to the model in Nomura (2017) and proposed the modified ADMM algorithm to estimate parameters under those constraints. If we use the model in Nomura (2017) without constraints, we may obtain regression coefficients not satisfying some of the constraints, which may result in inconsistent pure premiums such that, for example, pure premiums for upper bonus–malus classes (excellent drivers) would be higher than those for lower classes.
We demonstrated our method in the analysis of motorcycle insurance data. In Section 6.1, we incorporated the group fused lasso with monotonic constraints into the regression coefficients of some factors and obtained a moderate number of rating groups for each factor. The estimated differences in the expected total claim cost (pure premium) are up to 5.8 times among the owner’s ages, 6.4 times among the city-size classes, and 2.0 times among the EV-rate classes, whereas there is no difference in the estimated total claim cost among bonus–malus classes. In Section 6.2, we introduced the group fused lasso on the multi-dimensional lattice graphs for the interaction of multiple factors. Specifically, we estimated the interaction between the bonus–malus and city-size classes, which revealed that, in contrast to the previous analysis, the expected claim frequency and severity vary by the bonus–malus classes whose differences are not very large and depend on the city-size classes. This result indicates that premium discount rates for the bonus–malus classes should change by the city-size classes.
Sparse regularization techniques are widely applied to insurance data such as mortality analysis (SriDaran et al. 2022) and loss reserving (Gráinne, Taylor, and Miller 2021), and our method may be applicable to those fields as well. On a technical aspect, our method can be used with other distributions in the exponential dispersion family such as inverse Gaussian distribution. Furthermore, the group sparse lasso is applicable not only to GLMs but also to deep neural networks (Scardapane et al. 2017) and our approach may also be used in such machine learning models.
Funding source: ROIS-DS-JOINT
Award Identifier / Grant number: 009RP2022
Acknowledgements
We thank the editor, Professor W. Jean Kwon, and anonymous reviewers for their insightful comments, which were helpful in improving the quality of the manuscript.
-
Research funding: This work was supported, in part, by ROIS-DS-JOINT (009RP2022) to S. Nomura.
References
Alaíz, C. M., Á. Barbero, and J. R. Dorronsoro. 2013. “Group Fused Lasso.” In Artificial Neural Networks and Machine Learning – ICANN 2013. ICANN 2013. Lecture Notes in Computer Science, vol. 8131, edited by V. Mladenov, P. Koprinkova-Hristova, G. Palm, A. E. P. Villa, B. Appollini, and N. Kasabov, 66–73. Berlin: Springer.10.1007/978-3-642-40728-4_9Search in Google Scholar
Bleakley, K., and J. P. Vert. 2011. “The Group Fused Lasso for Multiple Change-point Detection.” In Working Paper. Also available at http://arxiv.org/abs/1106.4199v1.Search in Google Scholar
Devriendt, S., K. Antonio, T. Reynkens, and R. Verbelen. 2021. “Sparse Regression with Multi-type Regularized Feature Modeling.” Insurance: Mathematics and Economics 96: 248–61. https://doi.org/10.1016/j.insmatheco.2020.11.010.Search in Google Scholar
Fujita, S., T. Tanaka, K. Kondo, and H. Iwasawa. 2020. “AGLM: A Hybrid Modeling Method of GLM and Data Science Techniques.” In Actuarial Colloquium Paris 2020. Also available at https://www.institutdesactuaires.com/global/gene/link.php?doc_id=16273.Search in Google Scholar
Gráinne, M., G. Taylor, and G. Miller. 2021. “Self-assembling Insurance Claim Models Using Regularized Regression and Machine Learning.” Variance 14 (1).Search in Google Scholar
Guo, L. 2003. “Applying Data Mining Techniques in Property/casualty Insurance.” In CAS 2003 Winter Forum, Data Management, Quality, and Technology Call Papers and Ratemaking Discussion Papers, 1–25. CAS.Search in Google Scholar
Nelder, J. A., and R. W. M. Wedderburn. 1972. “Generalized Linear Models.” Journal of the Royal Statistical Society: Series A 135 (3): 370–84. https://doi.org/10.2307/2344614.Search in Google Scholar
Nomura, S. 2017. “Automatic Segmentation of Rating Classes via the Group Fused Lasso (In Japanese).” JARIP (Japanese Association of Risk, Insurance and Pensions) Journal 9 (1): 10–28.Search in Google Scholar
Ohlsson, E., and B. Johansson. 2010. Non-Life Insurance Pricing with Generalized Linear Models. EAA Series, Berlin/Heidelberg: Springer.10.1007/978-3-642-10791-7Search in Google Scholar
Pelessoni, R., and L. Picech. 1998. “Some Applications of Unsupervised Neural Networks in Rate Making Procedure.” In 1998 General Insurance Convention & ASTIN Colloquium, 549–67, Glasgow.Search in Google Scholar
Sanche, R., and K. Lonergan. 2006. “Variable Reduction for Predictive Modeling with Clustering.” In Casualty Actuarial Society Forum, Winter 2006, 89–100, Salt Lake City.Search in Google Scholar
Scardapane, S., D. Comminiello, A. Hussain, and A. Uncini. 2017. “Group Sparse Regularization for Deep Neural Networks.” Neurocomputing 241: 81–9. https://doi.org/10.1016/j.neucom.2017.02.029.Search in Google Scholar
SriDaran, D., M. Sherris, A. Villegas, and J. Ziveyi. 2022. “A Group Regularization Approach for Constructing Generalized Age-Period-Cohort Mortality Projection Models.” ASTIN Bulletin 52 (1): 247–89. https://doi.org/10.1017/asb.2021.29.Search in Google Scholar
Tibshirani, R. 1996. “Regression Shrinkage and Selection via the Lasso.” Journal of the Royal Statistical Society: Series B 58 (1): 267–88. https://doi.org/10.1111/j.2517-6161.1996.tb02080.x.Search in Google Scholar
Tibshirani, R., M. Saunders, S. Rosset, J. Zhu, and K. Knight. 2005. “Sparsity and Smoothness via the Fused Lasso.” Journal of the Royal Statistical Society: Series B 67 (1): 91–108. https://doi.org/10.1111/j.1467-9868.2005.00490.x.Search in Google Scholar
Tweedie, M. 1984. “An Index Which Distinguishes between Some Important Exponential Families.” In Statistics: Applications and New Directions. Proceedings of the Indian Statistical Institute Golden Jubilee International Conference, edited by J. Ghosh, and J. Roy, 579–604. Calcutta: Indian Statistical Institute.Search in Google Scholar
Wahlberg, B., S. Boyd, M. Annergren, and Y. Wang. 2012. “An ADMM Algorithm for a Class of Total Variation Regularized Estimation Problems.” IFAC Proceedings Volumes 45 (16): 83–8. https://doi.org/10.3182/20120711-3-be-2027.00310.Search in Google Scholar
Wytock, M., S. Sra, and J. Z. Kolter. 2014. “Fast Newton Methods for the Group Fused Lasso.” In Proceedings of the Thirtieth Conference on Uncertainty in Artificial Intelligence, 888–97.Search in Google Scholar
Yao, J. 2016. “Clustering in General Insurance Pricing.” In Predictive Modeling Applications in Actuarial Science, Volume II: Case Studies in Insurance, edited by E. W. Frees, G. Meyers, and R. A. Derrig, 159–79. Cambridge: Cambridge University Press.10.1017/CBO9781139342681.007Search in Google Scholar
© 2022 the author(s), published by De Gruyter, Berlin/Boston
This work is licensed under the Creative Commons Attribution 4.0 International License.
Articles in the same Issue
- Frontmatter
- Featured Articles (Research Paper)
- Are Stay-at-Home and Face Mask Orders Effective in Slowing Down COVID-19 Transmission? – A Statistical Study of U.S. Case Counts in 2020
- The Impact of GATS on the Insurance Sector: Empirical Evidence from Pakistan
- Processing of Information from Risk Maps in India and Germany: The Influence of Cognitive Reflection, Numeracy, and Experience
- The Determinants of Credit Rating and the Effect of Regulatory Disclosure Requirements: Evidence from an Emerging Market
- Automatic Segmentation of Insurance Rating Classes Under Ordinal Constraints via Group Fused Lasso
Articles in the same Issue
- Frontmatter
- Featured Articles (Research Paper)
- Are Stay-at-Home and Face Mask Orders Effective in Slowing Down COVID-19 Transmission? – A Statistical Study of U.S. Case Counts in 2020
- The Impact of GATS on the Insurance Sector: Empirical Evidence from Pakistan
- Processing of Information from Risk Maps in India and Germany: The Influence of Cognitive Reflection, Numeracy, and Experience
- The Determinants of Credit Rating and the Effect of Regulatory Disclosure Requirements: Evidence from an Emerging Market
- Automatic Segmentation of Insurance Rating Classes Under Ordinal Constraints via Group Fused Lasso