
Estimation of Partially Specified Spatial Autoregressive Model
-
Yuanqing Zhang


Abstract
In this paper, we study estimation of a partially specified spatial autoregressive model with heteroskedasticity error term. Under the assumption of exogenous regressors and exogenous spatial weighting matrix, we propose an instrumental variable estimation. Under some sufficient conditions, we show that the proposed estimator for the finite dimensional parameter is root-n consistent and asymptotically normally distributed and the proposed estimator for the unknown function is consistent and also asymptotically distributed though at a rate slower than root-n. Monte Carlo simulations verify our theory and the results suggest that the proposed method has some practical value.
1 Introduction
Since Paelinck coined the term “spatial econometrics” in the early 1970s to refer to a set of methods that explicitly handles with spatial dependence and spatial heterogeneity, this field has grown rapidly. The books by Cliff and Ord[1], Anselin[2], Cressie[3], contribute significantly to the development of the field. For a recent survey about the subject, see Anselin and Bera[4].
Among the class of spatial models, spatial autoregressive (SAR) models have attracted a lot of attention. Many methods have been proposed to estimate the SAR models, which include the method of maximum likelihood (ML) by Ord[5] and Smirnov and Anselin[6], the method of moments (MM) by Kelejian and Prucha[7–9], and the method of quasi-maximum likelihood estimation (QMLE) by Lee[10]. A common characteristic of these methods is that they are all developed to estimate finite dimensional parameters in the SAR models which are assumed to be linear. Linearity is widely used in the parametric statistical inference and it needs many model assumptions. Although their properties are very well established, linear models are often unrealistic in applications. Moreover, mis-specification of the data generation by a linear model could lead to a large bias. To achieve greater realism, Su and Jin[11] propose partially specified spatial autoregressive model in the following (hereafter PLSAR):
where yi denotes the dependent variable of individual i, xi is q-dimensional explanatory variable and zi denotes p-dimensional explanatory variable, wij denotes the spatial weight between individual i and j, εi denotes random noise, and λ0 and β0 denote the unknown true parameter value.
Recently, Su and Jin[11] give a profiled quasi-maximum likelihood based estimator (PQMLE) and show that the rates of consistency for the finite dimensional parameters in the model depend on some general features of the spatial weight matrix. Unfortunately, A major weakness for Su and Jin[11]’s PQMLE seems to be that the error term εi’s in their model are required to be homoscedastically distributed. In the presence of heteroscedasticity, Lin and Lee[12] have demonstrated that the QML-based estimator is usually inconsistent. Their estimator does not have a closed form expression. More recently, Su[13] proposes semi-parametric GMM (SPGMM) estimation of semi-parametric SAR models where the spatial lag effect exists the model linearly and the exogenous variables enter the model nonparametrically, but the model of Su[13] is absence of
However, both estimators mentioned above seem to be computationally challenging for applied scientists and are not easy to use in practice. In this article, an alternative computationally simple estimator is proposed for consistently estimating PLSAR model (1) for both finite dimensional parameters and nonparametric component under heteroskedasticity in the model. We give the asymptotic normality and consistent covariance matrices for the parametric and nonparametric part. The estimators all have closed form expressions in the paper, so, it is easy to implement in practice. Monte Carlo simulation results indicate that our estimators perform well in finite samples.
The paper is organized as follows: Section 2 proposes an estimation of the model (1); Section 3 gives the asymptotic properties of the proposed estimators; Section 4 reports some Monte Carlo simulation results. All technical proofs are relegated to the appendices.
2 Estimation
There are two issues with estimation of the model (1). First is the correlation between the spatial term
Let wi = (wi1, wi2, · · ·, win)T, Y = (y1, y2, · · ·, yn)T, We rewrite the model (1) yields
Then taking conditional expectation yields
Since E(εi|xi) = 0, we get
Finally, we deal with the endogeneity problem by applying the 2SLS. Let hi denote a column vector of instrumental variables. The instrumental variables include all exogenous regressors in the model. The instrument matrices H have full column rank r≥q + 1.
Denote pi = pK(zi), P = (p1, p2, · · ·, pn)′,
The 2SLS estimators for the unknow parameters δ0, π0, g0(z) are respectively given by
3 Asymptotic properties
The following assumptions will be maintained throughout the paper.
Assumption 1
(i) {(Xi, Zi, εi), i = 1, 2, · · ·, n} are independently and identically distributed; (ii) for all i, E[εi|Xi, Zi, W] = 0; (iii) there exist some constants
Assumption 2
(i) The diagonal element of the spatial weighting matrix W is zero; (ii) the matrix I – λ0W is nonsingular with |λ0| < 1, where I is an n × n identity matrix; (iii) the row and column sums of the matrices W, (I – λ0W)–1 are bounded uniformly in absolute value.
Assumption 1 is needed for establishing the asymptotic distribution of the nonparametric estimator
Assumption 3
For every K; (i) the smallest eigenvalue of
Assumption 4
For any function g(·) satisfying the normalization of g0(·), (i) there exist some α(>0), π = π(K),
Assumption 5
The limits
Assumption 3 are imposed on the sieve approximations. Since the constant is not identified, we must impose some normalization on g0(·) such as g0(z0) = 0 at some point z0 so that g0(·) can be identified. The basis functions pK(z) shall be constructed to satisfy this normalization. In addtion, the assumption imposes a normalization on the approximating functions, bounding the second moment matrix away from singularity, and restricting the magnitude of the series terms. This condition is needed to ensure the convergence in probability of the sample second moment matrix of the approximating functions to their expectations. Without loss of generality, we will assume
Define
The following assumptions will be maintained throughout.
Theorem 1
Suppose assumptions 1~5 are satisfied, then we can establish
For any given value z0, denote
We can establish the following theorem regarding the nonparametric component.
Theorem 2
Suppose Assumptions 1~5 are satisfied, then we can establish: (i)
We estimate the residuals by
4 Monte Carlo simulation
In this section, we conduct a monte carlo experiment to evaluate finite sample performance of the proposed method. The data generating process is given by
where zi follows the uniform distribution on [0,1], xi follows the exponential distribution with parameter 3, and the error term εi is normally distributed with mean zero and variance σ2. We take the spatial weights matrix as the spatial scenario in [17] with R number of districts, m members in each district, and with each neighbor of a member in a district given equal weight, i.e., W = IR ⨂ Bm, where
Table 1 summarizes the simulation results for estimating λ, β and g(z) under different selections of the true parameters for n = 200, 500, and 1000. Each entry is based on 1000 repetitions.
when σ2 = 1, Summary of Bias, SEE, ESE and CP for λ and β, the estimator for σ2 under model (8)
| σ2 | λ | ß | g(z) | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| n | σ̂2 | Bias | SEE | ESE | CP | Bias | SEE | ESE | CP | RISE |
| λ = –0.5 | β = 6 | |||||||||
| 200 | 0.9706 | 0.0092 | 0.0720 | 0.0742 | 0.946 | 0.0056 | 0.2129 | 0.2186 | 0.944 | 0.2466 |
| 500 | 0.9952 | –0.0009 | 0.0434 | 0.0436 | 0.945 | 0.0050 | 0.1385 | 0.1371 | 0.943 | 0.1740 |
| 1000 | 1.0020 | 0.0008 | 0.0293 | 0.0301 | 0.960 | 0.0010 | 0.0963 | 0.0957 | 0.949 | 0.1458 |
| λ = 0 | β = 6 | |||||||||
| 200 | 0.9699 | 0.0072 | 0.0504 | 0.0501 | 0.948 | 0.0048 | 0.2119 | 0.2176 | 0.942 | 0.2457 |
| 500 | 0.9951 | 0.0007 | 0.0306 | 0.0299 | 0.940 | 0.0013 | 0.1379 | 0.1367 | 0.943 | 0.1738 |
| 1000 | 1.0020 | –0.0006 | 0.0207 | 0.0207 | 0.955 | 0.0011 | 0.09611 | 0.0954 | 0.949 | 0.1456 |
| λ = 0.5 | β = 6 | |||||||||
| 200 | 0.9691 | 0.0042 | 0.0265 | 0.0265 | 0.951 | 0.0046 | 0.2123 | 0.2178 | 0.944 | 0.2456 |
| 500 | 0.995 | 0.0004 | 0.0161 | 0.0160 | 0.942 | 0.0036 | 0.1381 | 0.137 | 0.942 | 0.1739 |
| 1000 | 1.0020 | –0.0003 | 0.0109 | 0.0112 | 0.957 | 0.0015 | 0.0964 | 0.0957 | 0.948 | 0.1456 |
| λ = –0.5 | β = –6 | |||||||||
| 200 | 0.9706 | 0.0086 | 0.0688 | 0.0736 | 0.944 | 0.0061 | 0.2121 | 0.2186 | 0.947 | 0.2446 |
| 500 | 0.9952 | 0.0006 | 0.0421 | 0.0438 | 0.957 | 0.0023 | 0.1386 | 0.1372 | 0.943 | 0.1721 |
| 1000 | 1.0020 | –0.0005 | 0.0289 | 0.0300 | 0.954 | 0.0019 | 0.0963 | 0.0957 | 0.947 | 0.1453 |
| λ = 0 | β =-6 | |||||||||
| 200 | 0.9699 | 0.0068 | 0.0482 | 0.0498 | 0.942 | 0.0060 | 0.2116 | 0.2177 | 0.944 | 0.2438 |
| 500 | 0.9952 | 0.0005 | 0.0297 | 0.0300 | 0.956 | 0.0043 | 0.1384 | 0.1367 | 0.940 | 0.1720 |
| 1000 | 1.0020 | –0.0002 | 0.0204 | 0.0207 | 0.950 | 0.0021 | 0.0962 | 0.0954 | 0.948 | 0.1452 |
| λ = 0.5 | β = –6 | |||||||||
| 200 | 0.9691 | 0.0040 | 0.0253 | 0.0264 | 0.951 | 0.0070 | 0.2123 | 0.2179 | 0.944 | 0.2438 |
| 500 | 0.9952 | 0.0003 | 0.0157 | 0.0161 | 0.959 | 0.0061 | 0.1390 | 0.1369 | 0.938 | 0.1722 |
| 1000 | 1.0020 | –3.8e–05 | 0.0108 | 0.0111 | 0.952 | 0.0023 | 0.0966 | 0.0957 | 0.952 | 0.1452 |
For each estimator, Bias is the average of estimation biases from 1000 repetitions, SSE is the sample standard error of the estimates, ESE is the average of the estimated standard error, let SEE denote the sampling standard error of the estimates, CP is the coverage probability of a 95 percent confidence interval for the estimator, RISE is defined as the average of the square root of integrated square error of ĝ(z) where for each repetition,
where Ƶ is the support of z, F(z) is the distribution function of z.
Table 1 shows that σ̂2 is close to the true value 1 as n becomes larger. The biases of λ and β become smaller as n becomes larger. The SEE and ESE for λ̂ and β̂ are very close. The coverage probabilities of λ̂ and β̂ are close to 0.95 nominal level. The RISE of g(z) becomes smaller as n becomes larger. Figure 1 shows the comparison of the true function of g(z) and the estimating function of ĝ(z).
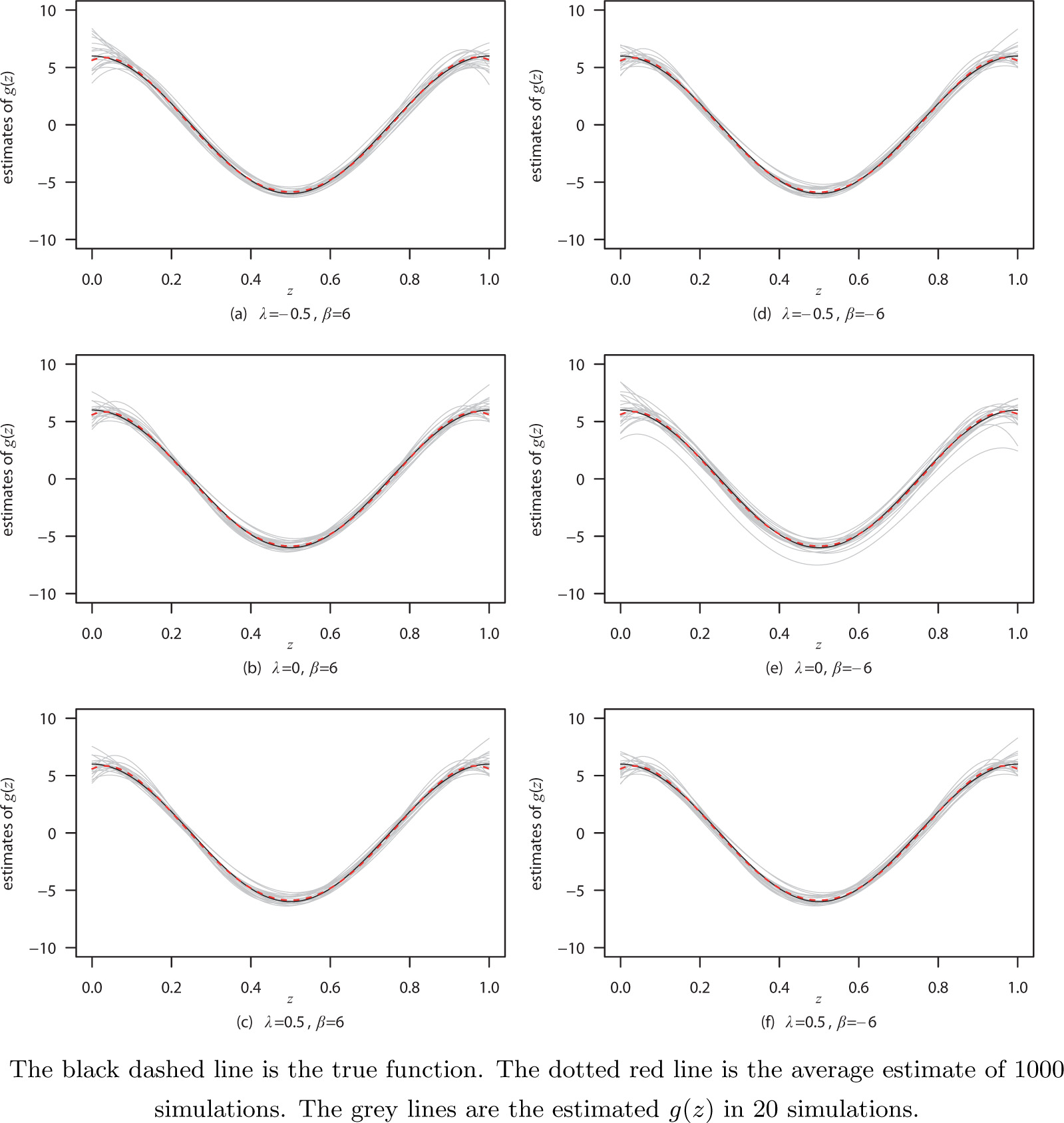
The plots of the estimates of g(z) = 6cos(2πz) under model (8) with n = 200 and σ = 1 for different values of λ and β.
5 Appendix technicalities
We denote tr(A) = trace(A) for a square matrix A.
Before we prove the main results, we first give some useful convergence results. By Assumption 3(i), we assume without loss of generality that: E {pkK(zi)pjK(zi)} = Ijk, where Ijk denotes the (j, k)th element of the identity matrix. Let ||·|| denotes the Euclidean norm. Denote
Let 1n denote the indicator function for the smallest eigenvalue of Q being greater than 1/2. Then
and
Proof of Theorem 1
For the sake of convenience, we take the instrument variables as
Hence,
Furthermore,
and
Because
So,
Because
Hence,
Because
Hence,
So,
Thus,
The proof of Theorem is completed following an application of the Crémer-Wald device.
Proof of Theorem 2
We write
Consider the second term. We have
Thus,
by applying (11). Notice that
We obtain
uniformly over z and
Furthermore, applying (12) and Assumption 3(ii), we obtain
Notice that
By substitution and at a fixed z0, we have
Let
where 1(·) denotes indicative function. Then, by the Lindbergh-Feller central limit theorem,
Thus,
6 Acknowledgements
We thank the referees for their time and comments.
References
[1] Cliff A D, Ord J K. Spatial autocorrelation. London: Pion Ltd, 1973.Search in Google Scholar
[2] Anselin L. Spatial econometrics: Methods and models. The Netherlands: Kluwer Academic Publishers, 1988.10.1007/978-94-015-7799-1Search in Google Scholar
[3] Cressie N. Statistics for spatial data. JohnWiley Sons, New York, 1993.10.1002/9781119115151Search in Google Scholar
[4] Anselin L, Bera A K. Spatial dependence in linear regressionmodels with an introduction to spatial econometrics. In: Ullah A, Giles D E A. Handbook of Applied Economics Statistics. Marcel Dekker, New York, 2002.Search in Google Scholar
[5] Ord J K. Estimation methods for models of spatial interaction. Journal of the American Statistical Association, 1975, 70: 120–126.10.1080/01621459.1975.10480272Search in Google Scholar
[6] Smirnov O, Anselin L. Fast maximum likelihood estimation of very large spatial autoregressive models: A characteristic polynomial approach. Computational Statistics and Data Analysis, 2001, 35: 301–319.10.1016/S0167-9473(00)00018-9Search in Google Scholar
[7] Kelejian H H, Prucha I R. A generalized spatial two-stage least squares procedure for estimating a spatial autoregressive model with sutoregressive disturbance. Journal of Real Estate Finance and Economics, 1998, 17: 99–121.10.1023/A:1007707430416Search in Google Scholar
[8] Kelejian H H, Prucha I R. A generalized moments estimator for the autoregressive parameter in a spatial model. International Economic Review, 1999, 40: 509–533.10.1111/1468-2354.00027Search in Google Scholar
[9] Kelejian H H, Prucha I R. Specification and estimation of spatial autoregres-sive models with autoregressive and heteroskedastic disturbances. Journal of Econometrics, 2010, 157: 53–67.10.1016/j.jeconom.2009.10.025Search in Google Scholar PubMed PubMed Central
[10] Lee L F. Asymptotic distribution of quasi-maximum likelihood estimators for spatial autoregressive models. Econometrica 2004, 72: 1899–1925.10.1111/j.1468-0262.2004.00558.xSearch in Google Scholar
[11] Su L, Jin S. Profile quasi-maximum likelihood estimation of spatial autoregressive models. Journal of Econometrics, 2010, 157: 18–33.10.1016/j.jeconom.2009.10.033Search in Google Scholar
[12] Lin X, Lee L F. GMM estimation of spatial autoregressive models with unknown heteroskedasticity. Journal of Econometrics, 2010, 157(1): 34–52.10.1016/j.jeconom.2009.10.035Search in Google Scholar
[13] Su L. Semi-parametric GMM estimation of spatial autoregressive models. Journal of Econometrics, 2012, 167: 543–560.10.1016/j.jeconom.2011.09.034Search in Google Scholar
[14] Ai C, Chen X. Efficient estimation of models with conditional moment restrictions containing unknown functions. Econometrica 2003, 71: 1795–1843.10.1111/1468-0262.00470Search in Google Scholar
[15] Newey W K. Convergence rates and asymptotic normality for series estimators. Journal of Econometrics, 1997, 79: 147–168.10.1016/S0304-4076(97)00011-0Search in Google Scholar
[16] Lee L F. GMM and 2SLS estimation of mixed regressive, spatial autoregressive models. Journal of Econometrics, 2007, 137: 489–514.10.1016/j.jeconom.2005.10.004Search in Google Scholar
[17] Case A C. Spatial patterns in household demand. Econometrica, 1991, 59: 953–965.10.2307/2938168Search in Google Scholar
© 2014 Walter de Gruyter GmbH, Berlin/Boston
Articles in the same Issue
- Forecasting the Crude Oil Price with Extreme Values
- Pricing Strategy and Governments Intervention for Green Supply Chain with Strategic Customer Behavior
- Fiscal Behavior Volatility, Economic Growth, and Urban-Rural Income Disparity
- Estimation of Partially Specified Spatial Autoregressive Model
- A Study on the Asymmetry in the Role of Monetary Policy by Using STR model
- A Real-time Products Management Method in Supply Chain Management based on IOT
- A Convergent Control Strategy for Quantum Systems
- Qualification Evaluation of Computer Information System Integration Based on Weighted Products
- Exponential Stability and Availability Analysis of a Complex Standby System
Articles in the same Issue
- Forecasting the Crude Oil Price with Extreme Values
- Pricing Strategy and Governments Intervention for Green Supply Chain with Strategic Customer Behavior
- Fiscal Behavior Volatility, Economic Growth, and Urban-Rural Income Disparity
- Estimation of Partially Specified Spatial Autoregressive Model
- A Study on the Asymmetry in the Role of Monetary Policy by Using STR model
- A Real-time Products Management Method in Supply Chain Management based on IOT
- A Convergent Control Strategy for Quantum Systems
- Qualification Evaluation of Computer Information System Integration Based on Weighted Products
- Exponential Stability and Availability Analysis of a Complex Standby System