Anti-hiatus tendencies in Spanish: rate of occurrence and phonetic identification
-
Alfredo Herrero de Haro

 and
Antonio Alcoholado Feltstrom
and
Antonio Alcoholado Feltstrom

Abstract
Spanish normative grammar considers any two-vowel combination of /e/, /a/, and /o/ as a hiatus, accepting that they can be pronounced as a diphthong in lower basilects and/or informal registers. This article analyzes speeches of educated speakers, performing an acoustic analysis of 60 segmental and suprasegmental features in 493 vowel sequences. Linear mixed-effects models suggest that two-vowel sequences of /e/, /a/, and /o/ are pronounced as diphthongs in 77.27 % of cases; suprasegmental features (especially duration) are the most reliable cues to distinguish a hiatus from a diphthong in Spanish. These results call for a re-examination of diphthong classification in Spanish.
1 Introduction
1.1 Objectives
Spanish has five phonemic vowels (/i/, /e/, /a/, /o/, and /u/) and any two-vowel combination is possible within a word and/or across word boundaries. The Royal Spanish Academy (henceforth RAE, as per its Spanish acronym), an institution established in 1713 that sets the official spelling rules for Spanish and observes what grammatical and lexical uses are normative in the language, describes the combination of a high vowel with any other vowel as a diphthong, as long as the high vowel is not the stressed element in the sequence. Likewise, a hiatus is any two-vowel combination of /e/, /a/, and /o/ or a combination of a mid or low vowel with a stressed /i/ or /u/ (Barbería Aurrekoetxea 2021: 20). However, even though RAE does not accept that /e/, /a/, or /o/ can act as a glide in a diphthong, there are studies which support this (Colina 2009; Contreras 1969; Garrido 2013, among others). The pronunciation of a two-vowel sequence of /e/, /a/, or /o/ as a hiatus or a diphthong is a complex phenomenon with different degrees of acceptance and stigmatization across regions and lexical items; however, the present study focuses on RAE’s normative description. The normative classification of diphthongs or hiatuses in Spanish is important since the spelling rules that dictate whether or not a word needs to carry an accent mark are based on the number of syllables between the lexical stress and the end of a word. Therefore, a change in the normative categorization of diphthongs or hiatuses in Spanish might have consequences for the spelling system, such as spelling the word héroe ‘hero’ as heroe.
RAE and the rest of the academies for the Spanish language in other Spanish-speaking countries (Association of Academies of the Spanish Language, henceforth ASALE as per its Spanish acronym), consider the pronunciation of a two-vowel combination of /e/, /a/, and /o/ as a diphthong as “non-normative” (ASALE 2005: 339, 2011: 339) and link this phonetic realization to speakers with a low level of education, to an informal register or, in a somewhat unspecific manner, to speakers from the Americas. The present study analyzes 493 two-vowel sequences of /e/, /a/, and /o/ in the RAE acceptance speech of 29 new members. RAE members are acclaimed authors, linguists, artists, and scholars and they represent the highest reference point for the Spanish language in Spain for the general population and for academics. These speeches are usually presided by the Spanish monarch and/or other royals, by high-ranking politicians, and by other academics, so these speeches are delivered in a formal register. According to the diastratic, diatopic and diaphasic criteria set by RAE, the speakers in our sample should pronounce words such as aeropuerto ‘airport’ and héroe ‘hero’ as [a.e.ɾo.ˈpwer.to] and [ˈe.ɾo.e], respectively. If these speakers pronounced these words as [ae.ɾo.ˈpwer.to] or [ˈe.roe], this would demonstrate that mid and low vowels have the same ability as high vowels to act as glides in formal Spanish and it would also show that the anti-hiatus tendency to pronounce a two-vowel sequence of /e/, /a/, or /o/ as diphthong is also present in speakers of the highest sociocultural status in Spain and in the most formal of registers.
The present article aims to establish whether a two-vowel sequence of /e/, /a/, and /o/ is pronounced as a hiatus, as per normative descriptions of Spanish, or as a diphthong by highly educated speakers in a formal situation. Furthermore, this article also seeks to identify the best acoustic cues to distinguish diphthongs from hiatuses in Spanish. Implications of any findings for Spanish orthography will also be considered.
1.2 Background
The issue of anti-hiatus tendencies in Spanish has been present in the Spanish prosody literature since the first Spanish grammar (Nebrija 1492). However, despite several analyses of the issue in studies since the early 20th century (e.g., Alarcos Llorach 1950, 1999; Alcina and Blecua 1975; ASALE 2005, 2011; Hualde 2005; Navarro Tomás 1918; Quilis 1999; RAE 1920; 1973, and some phonological explanations based on Optimality Theory (Colina 2009), there is a great deal of controversy around the topic.
The first issue is regarding terminology, since not all authors use the same term to refer to the pronunciation of a hiatus as a diphthong. Rabanales (1960) refers to it as antihiato ‘antihiatus’ and antihiatismo ‘antihiatism’, and Lloyd (1987) uses the term tendency to eliminate a hiatus, while Quilis (1999: 189–190) refers to it as tendencia antihiática ‘antihatus tendency’. Hualde (2005: 86) uses the term anti-hiatus tendency, which he defines as a general trend by Spanish speakers to pronounce adjoining vowels, in a same syllabic impulse, as a diphthong, even though normative descriptions say that those vowels are pronounced as different syllables, as a hiatus (ASALE 2011: 339).
While definitions of a syllable are challenging in the field of phonetics (Davenport and Hannahs 2005: 73–74), syllabic units are easily identified by speakers (Ladefoged and Jonhson 2009: 243–244; Collins and Mees 2013: 16). In Spanish, the syllable is accepted as a main phonological unit (Alcina and Blecua 1975: 267–268; ASALE 2011: 15, 68, 283; Colina 2009: 3; Hualde 2005: 70; Quilis 1999: 360–361) and, most succinctly, described as a process of articulatory opening and closure in which sounds are grouped according to their sonority. In the case of vowel sounds, given that they are open articulations, syllable boundaries are difficult to establish (as noted above by Colina 2009; Quilis 1999) and the reality of speech contradicts the grammatical norm.
For example, according to normative descriptions, in the word línea ‘line’, /e/ and /a/ should be pronounced as two different syllables ([ˈli.ne.a]); however, they tend to be pronounced in one syllabic impulse ([ˈli.ne̯a]). Pronouncing a two-vowel sequence of /e/, /a/, and /o/ as one syllable is referred to as synaeresis if it occurs within a word or as synalepha if it occurs across word boundaries (ASALE 2011: 353). Although normative descriptions reserve the term diphthong to refer to vowel combinations of an unstressed high vowel and another vowel, the term diphthong is used in the present article to refer to any two-vowel combination that is pronounced as a syllable, following RAE (1973: 89–101).
The pronunciation of a two-vowel combination of /e/, /a/, and /o/ as a diphthong has been widely studied and there are a range of views on the topic. Navarro Tomás (1918), the first study on Spanish pronunciation supported by experimental phonetic analyses, supports the fact that /e/ and /o/ can act as glides in Spanish. Depicting a spectrogram of this kind of vowel combination, Navarro Tomás (1918) points to the gliding ability of mid vowels in Spanish. Navarro Tomás (1918: 115–118) argues the importance of understanding the functions of synaeresis and synaloepha, describing the process of this hiatus resolution as an intimate rapport which could be interpreted as vowel coarticulation; Monroy Casas (2004: 65, 75, 77) confirms this in an instrumental study. Going a bit further, Contreras (1969: 60) refers to mid vowels as glides in cases of synaeresis and synaloepha. Alcina and Blecua (1975: 416–419) believe that there is a strong anti-hiatus tendency in speakers with lower levels of education and in informal registers, admitting that even educated speakers can display synaeresis and synaloepha in informal situations. Furthermore, Martínez Celdrán (1984: 372), Gili Gaya (1988: 117) and Alarcos Llorach (1999) also believe there is a strong anti-hiatus tendency in Spanish. Alarcos Llorach (1999) links the high frequency of anti-hiatus pronunciation in everyday speech to speakers of lower sociolects in Spain and to educated speakers from the Americas (Alarcos Llorach 1999: 43, 47–48); ASALE (2005) also supports this. The prevalence of anti-hiatus tendencies in the Spanish spoken in the Americas has also been noted in other studies, such as in a study of northern New Mexico, where Jenkins (1999) finds that diphthongization is found to be the most common strategy of hiatus resolution regardless of whether they contain high vowels or not. In contrast, RAE (1920: 480–481) considers a two-vowel sequence of /e/, /a/, or /o/ only as a hiatus, although it admits that synaeresis and synaloepha do occur. However, these are considered to “obey laws of stress and rhythm, totally unrelated to the grammatical law of diphthongs” (RAE 1920: 480); there is no update on this particular issue in RAE (1931). In line with RAE (1920), Alarcos Llorach (1976: 151–152, 202) considers the frequent monosyllabic articulation of a two-vowel combination of /e/, /a/, and /o/ as an analogy with diphthongs, but he restricts the gliding function to the high vowels. ASALE (2011: 339, 353) describes examples of anti-hiatus pronunciation in words like teatro ‘theatre’ [ˈte̯a.tɾo] or cohete ‘rocket’ [ˈko̯e.te]. However, according to ASALE (2011: 353), that anti-hiatus tendency is not generalized, it is not completely sociably accepted and it depends on whether or not a speaker resorts to careful speech. Therefore, despite various accounts that a two-vowel combination of /e/, /a/, and /o/ can be pronounced as a diphthong, Spanish normative grammar does not accept this and it maintains that /e/, /a/, and /o/ can only act as syllable nuclei, not as glides (ASALE 2011: 25, 333, 345; Alcoholado Feltstrom 2020: 162–165). It could be said, perhaps, that the normative predicament of the anti-hiatus tendency in Spanish seems to depend on whether the articulation of mid vowels as glides in cases of synaereses and synaloepha do take place in the speech of educated speakers from Spain and in a formal register.
There have been some descriptions that explain anti-hiatus tendencies without admitting that mid vowels can act as glides in Spanish. For example, ASALE (2005) describes synaeresis and synaloepha as cases of vowel closing of /e/ and /o/, as in acordeón ‘accordion’ [akorˈdjon] and cohete ‘rocket’ [ˈkwete]. These anti-hiatus tendencies are linked to less educated speakers (ASALE 2005: 339) and this classifies any combination of mid and open vowels only as a hiatus. Similar cases of vowel closing have also been reported in the literature in the Americas and Spain (Lapesa 1997) and, more specifically, in uneducated speech in Chile (Rabanales 1960), in Mexico, Central America, the Antilles, Venezuela, Ecuador, and Paraguay (Alvar 1996a, 1996b), in New Mexico (Alba 2006), and in Colombia (Garrido 2008).
There is some evidence that RAE’s phonetic description does not coincide with its normative description. RAE (1973: 5–6, 89; 101) deals with Spanish phonotactics and synaeresis and synaloepha are referred to as diphthongs, describing the anti-hiatus tendency as dominant in natural Spanish speech. RAE (1973: 5–6, 89–101) describes mid vowels as syllabic nucleus as well as semi-nucleus, which aligns with Navarro Tomás (1918) and Contreras (1969) and it accepts the fact that mid vowels can act as glides in Spanish. However, RAE does not consider RAE (1973) a normative authority and considers RAE (1973) as lacking normative authority. When RAE finally gets close to solving the problem around anti-hiatus phenomena, RAE declares their own work is non-normative.
There have also been different attempts at explaining the reasons behind anti-hiatus tendencies in Spanish. For example, Quilis (1999: 65–66, and 190) believes that, since vowels are open articulations, it is rather difficult to establish syllable boundaries between them. Quilis (1999: 65–66, 190) also posits that pronouncing vowels in one syllable requires less articulatory effort. From the point of view of Optimality Theory, and in line with Quilis’s (1999) observation about syllable boundaries among vowels, this tendency to diphthongization is a logical solution to avoid onsetless syllables (Colina 2009: 52). This aspect is key to understanding anti-hiatus tendencies.
To complicate matters further, it should be noted that, despite descriptions of acoustic differences between diphthongs and hiatuses in Spanish (e.g., Hualde and Prieto 2002), there is no specific formula or measurement to distinguish between both types of vowel sequences; they can be distinguished on a spectrogram and auditorily but there is no quantifiable criteria to distinguish between them and this can cause differences in classification between researchers. Martínez Celdrán (1984: 187–188), Aguilar Cuevas (1994), Quilis (1999: 186–188), Hualde (2005: 96), Martínez Celdrán and Fernández Planas (2007: 161–165), ASALE (2011: 336–337), and Hidalgo Navarro and Quilis Merín (2012: 156–157) describe differences in duration and formant transitions between diphthongs and hiatuses. Martínez Celdrán (1984: 187–188, 372), Quilis (1999: 187), and ASALE (2011: 337) believe that hiatuses display more abrupt formant transitions while diphthongs show smoother transitions; the latter point to the instability of the vowel, which acts as a glide. Aguilar Cuevas (1994: 200) believes that, in Spanish, the degree of curvature of F1 and F2 transitions differentiate diphthongs and hiatuses. Some authors (e.g., Aguilar Cuevas 1999; Hualde and Prieto 2002) argue that diphthongs are shorter than hiatuses, but Hualde and Prieto (2002) admit that despite well-defined durational differences between diphthongs and hiatuses, there is variation and overlap between both categories.
The situation is somewhat different for other languages. For example, in Italian, Abete’s (2011: 179) coefficient of diphthongization classifies vowel sequences over 60 ms long as monophthongs if they have a coefficient under 1 and as diphthongs if the coefficient is over 1.8. The coefficient equates to the value (in bark) of the hypotenuse of a right triangle where the base is the difference between the maximum and minimum F2 of a vowel and the height is the difference between the maximum and the minimum of the F1 of the vowel. This coefficient of diphthongization, however, cannot be used to distinguish diphthongs and hiatuses in Spanish since the coefficient was developed to differentiate monophthongs from diphthongs but not diphthongs from hiatuses. Furthermore, the formula was developed for Italian, not for Spanish, and research shows that “the transitional range and duration may be language-specific” (Lindau et al. 1990: 14).
1.3 Research questions
The information presented in the previous section highlights the importance of analyzing anti-hiatus tendencies in educated speakers from Spain and it also raises the question of phonetic differences between diphthongs and hiatuses in Spanish. With all this in mind, the present article has two main research questions:
Do Spanish speakers from a high sociocultural background pronounce two-vowel sequences of /e/, /a/, and /o/ as hiatuses, as prescribed by RAE, even in the most formal of registers?
What are the most reliable phonetic features to distinguish a diphthong from a hiatus in Spanish?
2 Acoustic analysis
2.1 Data gathering
Members of the Royal Spanish Academy are first elected to join the organization but do not become official members until after the ceremonia de ingreso ‘admission ceremony’. In this ceremony, the new member is required to deliver a speech accepting the nomination to join the institution and an existing member of RAE delivers another speech in reply to the new member. Both types of speeches have a flexible formal format and the ceremony is usually attended by the Spanish monarch and/or other royals, by other members of RAE, writers, linguists, and high-ranking politicians. Bearing in mind that the members of RAE are recognized as prestigious figures regarding the use and knowledge of the Spanish language in Spain and, given the level of formality of the speech, this specific example of communication is of an extremely high level of formality by very prestigious users of the Spanish language in Spain. The data analyzed in the present study come from the first 30 two-vowel combinations of /e/, /a/, and /o/ (roughly 2–3 min) of the acceptance speeches of the last 29 members of RAE who joined the institution between the 4th of June 2003 (Margarita Salas) the 19th of May 2019 (Juan Mayorga). These were all the recordings of acceptance speeches on www.rae.es available at the time of designing the present study; with the exception of the speech by Carmen Iglesia, recorded on the 30th of September 2002. This is the only speech not included as the audio quality did not allow for a reliable acoustic analysis.
Some researchers have identified phonetic features that differentiate diphthongs and hiatuses in Spanish but these present various issues. Aguilar Cuevas (1994: 200) concludes that the degree of curvature of F1 and F2 transitions allow discriminating between diphthongs and hiatuses in Spanish; nevertheless, this analysis was developed when one of the vowels in the sequence is /i/ or /u/, so it is not a reliable method for our study since the present article focuses on /e/, /a/, and /o/. Furthermore, there is evidence that supports that hiatuses are longer than diphthongs (e.g., Aguilar Cuevas 1999; Hualde and Prieto 2002). However, although Hualde and Prieto (2002) found that the durational differences between both types of sequences were well defined, they also found that there is variation and overlap between both categories. Therefore, it was considered that, for the present study, categorization of vowel sequences as either diphthongs or hiatuses had to be performed perceptually since there is no defined and accepted instrumental methodology to classify vowel sequences as either diphthongs or hiatuses in Spanish for a two-vowel sequence of /e/, /a/, or /o/ based on acoustic measures.
The second author listened to each speech and selected a portion of audio with the first 30 two-vowel sequences of e/, /a/, and /o/; sequences were not analyzed if they were pronounced next to another vowel (e.g., tarea ‘task’ is analyzed but ‘tarea o’ ‘task or’ is not) or if there were clearly unsuitable for a phonetic analysis (e.g., background noise); a total of 730 sequences were first identified. Both authors listened to the recordings independently and classified each of the vowel sequences as either a diphthong or a hiatus. Only those instances in which a vowel sequence had been classified as the same by both authors were analyzed and instances that one author identified as a diphthong and the other as a hiatus were discarded for the phonetic analysis (Table 1). This was done to categorize each vowel sequence as either diphthong or hiatus and to try to identify acoustic correlates for each of them. In order to avoid any potential bias in the classification of the sequences, there was no calibrating or discussion between the authors regarding coding; each author identified a sequence as either a diphthong or a hiatus independently without using agreed-to criteria and based on each author’s linguistic interpretation of a diphthong or a hiatus. Both authors have doctorates in Spanish linguistics and experience in the analysis of spoken language.
Identification of vowel sequences as either diphthong or hiatus per author.
| Author 1 | Author 2 | Agreement | |
|---|---|---|---|
| Diphthong | 472 | 532 | 391 |
| Hiatus | 258 | 198 | 115 |
| Total | 730 | 730 | 506 |
An inter-rater reliability test (henceforth IRR) was performed to judge the level of agreement between both authors; 13 sequences were discarded from the acoustic analysis due to various issues compromising the phonetic analysis (e.g., someone coughing in the background). In order to judge the level of inter-rater reliability test, a Cohen’s kappa was calculated since this test is used to rate the level of agreement between different raters (Wongpakaran et al. 2013). Cohen’s kappa has been proven to yield more conservative values than other inter-rater reliability tests, such as Gwet’s AC1 or Aickin’s α (Hsu and Field 2003; Wongpakaran et al. 2013). Both raters agreed on a total of 506 sequences (391 diphthongs and 115 hiatuses) and, with a total of 730 sequences, the agreement rate is 69.32 %; Hualde and Prieto (2002) identified variation and overlap between acoustic features of diphthongs and hiatuses, so it is possible that this variation and overlap have caused disagreement in coding between the two authors of the present article. A Cohen’s kappa yields a result of 0.29, which is categorized as fair according to Landis and Koch (1977) and Altman (1991). It should be noted that, to date, there is no specific values for acoustic features to classify a vowel sequence as either a diphthong or a hiatus in Spanish. We understand that the identification of a sequence as either diphthong or hiatus does not necessarily mean that this classification is correct but, at least, we can justify this classification by saying that the categories are being identified as the same by both authors in 69.32 % of cases. A similar limitation has been noted in other studies where categorization has been necessary to code variables (e.g., Landers 2015). Although it can be argued that, at least phonetically, the difference between pronouncing a vowel sequence as a diphthong or a hiatus is continuous, forcing the authors to carry out a categorical classification of the tokens could perhaps help filter out ambiguous sequences; this could explain the agreement rate of 69.32 %. As explained above, no identification criteria were agreed on by the authors as a way of avoiding bias and ensuring that both authors used their own linguistic interpretation of a diphthong or a hiatus; this could also explain the agreement rate of 69.32 %. Analyzing only the tokens both authors agreed on was considered necessary as a way of coding variables, as in Landers (2015).
2.2 Acoustic analysis: methods
The audio was analyzed on Praat (Boersma and Weenink 2016) and all settings were the standard ones with a few exceptions to account for differences between male and female voices. The maximum formant was set at 5,000 Hz for males and at 5,500 Hz for females as in other studies (e.g., Wikström 2013). Regarding pitch, the pitch floor was set at 50 for males and 70 for females, and the pitch ceiling at 300 for males and 400 for females, as in Wu et al. (2014). Other authors use different settings for pitch floors and ceilings (e.g., Hualde et al. 2015), although they did so to minimize errors in voicing analysis. Segmentation was carried out manually by the first author but the acoustic analysis was performed using a Praat (Boersma and Weenink 2016) script written by the first author. Segmentation was carried out as per standard procedures in phonetic sciences. For example, vowel onset and offset were marked at zero crossings as in Jacewicz et al. (2009) and spectrogram and waveform information were both used to identify specific features, as in other studies analyzing diphthongs and hiatuses (e.g., Chitoran and Hualde 2002) and other acoustic analyzes of speech (e.g., Kuzla et al. 2007; Recasens and Mira 2012). Waveforms, however, were used to set boundaries since they allow for better resolution (Torreira 2007). The features in the present study were segmented according to the following criteria:
The onset of V1 was marked at the closest zero crossing to an abrupt increase of energy in the F2 and F3 (as in Torreira 2012); this usually is accompanied by an abrupt increase in the amplitude of the waveform. These criteria proved effective in setting the onset of V1 after any type of consonant, even consonants that display formants, such as /n/, present fainter formants and lower amplitude than vowels (e.g., Bongiovanni 2015; Hedia and Plag 2017; Jacewicz et al. 2009; Recasens and Mira 2012).
The boundaries between V1 and V2 were established following three steps. The first author analyzed the spectrogram and identified the transition from V1 to V2. As the transition is a gradient, an initial rough section was selected on Praat (Boersma and Weenink 2016). After this, the first author listened to the word and to different parts of the word to analyze the correlation between perception and formant structure to identify the point at which there seemed to be a change from V1 to V2. Finally, the author zoomed into the rough area of transition from V1 to V2 and analyzed the waveform to identify sudden changes in the waveform structure. This procedure was carried out in all the samples by the first author, so this ensured consistency when delimiting vowel boundaries. Ultimately, the limit between V1 and V2 was based on information from the waveform rather than the spectrogram, even though, on some occasions, the spectrogram showed (some) changes in the amount of energy of V1 and V2 and/or changes in the formant structure. It is difficult to be objective and consistent based on formant structure alone regarding at which point in the transition from V1 and V2 to mark the limit between the vowels. Instead, the waveform was found to be a much more reliable measure and the limit between V1 and V2 was marked at the first zero crossing of the first cycle displaying a noticeable change in the structure, pattern, or amplitude of the waveform; Torreira (2007) also supports using the waveform for delimiting boundaries since this offers a higher resolution than spectrograms. For example, in Figure 1, the transition from /e/ to /a/ in the word real ‘royal’ is noticeable in the changes that the F1 displays, and we can also see an increase in formant energy in /a/; however, it would be difficult to set the boundary between /e/ and /a/ only with that information. Nevertheless, we can see in the waveform how there is a change from cycles with two peaks and no (or very small) additional peaks to cycles with three visibly distinct peaks; the structure of these peaks changes towards the end of /a/.
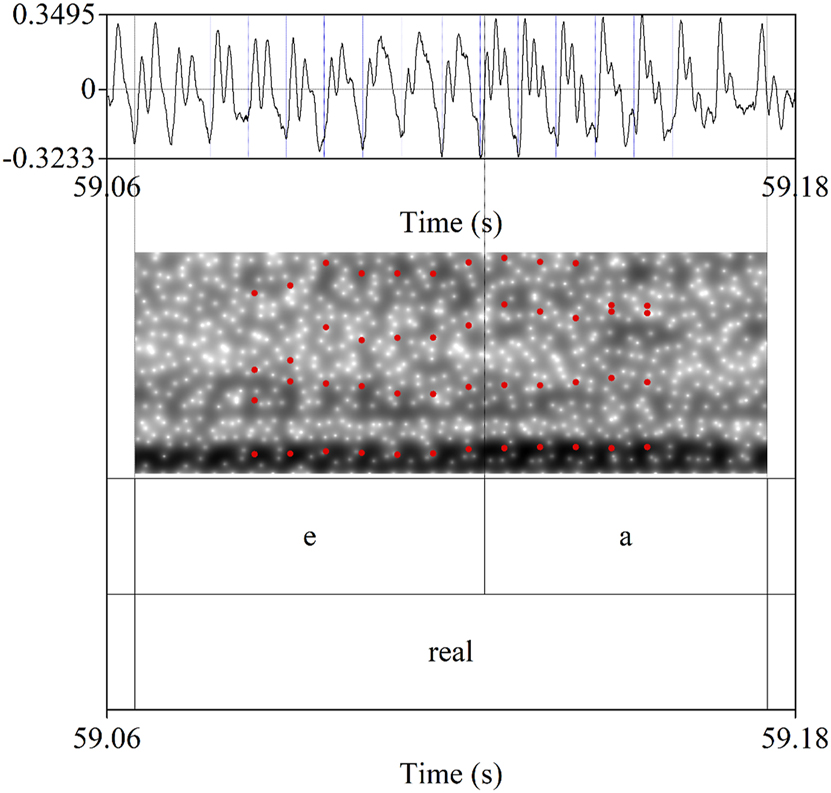
Boundary between V1 and V2 in the vowel sequence /ea/ in the word real ‘royal’.
The offset of V2 was marked at the closest zero crossing to a sudden decrease of energy in the F2; this cue is used by several authors (e.g., Bongiovanni 2015; Nadeu 2016; Roettger et al. 2014; Turk et al. 2006). This abrupt drop of energy in the F2 is usually accompanied by a sudden decrease in the amplitude of voicing (Roettger et al. 2014).
Acoustic measurements were not normalized, as normalization generates data that are not linguistically meaningful (Thomas and Kendall 2007). Instead, between-subject variation was accounted for by including the speaker as a random variable in the statistical model, together with a random intercept and slope for each speaker.
The script developed for the present study analyzed the following 35 parameters: V1 duration, V1 F1 mean, V1 F1 at 20 % (of duration of the vowel), V1 F1 at 80 %, V1 F2 mean, V1 F2 at 20 %, V1 F2 at 80 %, V1 mean pitch, V1 highest pitch, V1 lowest pitch, V1 pitch at 20 %, V1 pitch at 80 %, V1 mean intensity, V1 maximum intensity, V1 minimum intensity, V1 intensity at 20 %, V1 intensity at 80 %, V2 duration, V2 F1 mean, V2 F1 at 20 %, V2 F1 at 80 %, V2 F2 mean, V2 F2 at 20 %, V2 F2 at 80 %, V2 mean pitch, V2 highest pitch, V2 lowest pitch, V2 pitch at 20 %, V2 pitch at 80 %, V2 mean intensity, V2 maximum intensity, V2 minimum intensity, V2 intensity at 20 %, V2 intensity at 80 %, and duration of the two-vowel sequence. Measurements were taken at different points, as in other studies analyzing diphthongs (e.g., Mayr and Davies 2011) and, although some studies on Spanish diphthongs and hiatuses only consider the length of the whole sequence (e.g., Aguilar Cuevas 1999), the duration of individual vowels was also analyzed in the present study.
In addition, another 25 parameters were also calculated from the 35 parameters mentioned above. These are explained in Table 2.
Parameters obtained from the phonetic features measured in the recordings.
| Parameter | Definition |
|---|---|
| V1 F1 variation | V1 F1 at 80 % – V1 F1 at 20 % |
| V1 F2 variation | V1 F2 at 80 % – V1 F2 at 20 % |
| V2 F1 variation | V2 F1 at 80 % – V2 F1 at 20 % |
| V2 F2 variation | V2 F2 at 80 % – V2 F2 at 20 % |
| F1 mean difference | V2 F1 mean – V1 F1 mean |
| F2 mean difference | V2 F2 mean – V1 F2 mean |
| Distance | Distance from V1 to V2. The distance is the value of the hypotenuse (c) of a right triangle where V2 F2 mean – V1 F2 mean represent side b of the triangle and V2 F1 mean – V1 F1 mean represent side a |
| Angle | Considering the right triangle described above, angle is the angle A of this triangle, which indicates the angle of travel from V1 (V1 F1 mean, V1 F2 mean) to V2 (V2 F1 mean, V2 F2 mean). This angle is given as an absolute value so, for example, if the difference between V2 and V1 in terms of F2 is negative (e.g., V2 F2 – V1 F2 < 0), the angle would be negative, but the value given here is the absolute value (e.g., if the resulting angle was −43°, the one given here would be 43°) |
| Distance/angle | Distance (from V1 to V2) divided by angle |
| Angle/distance | Angle divided by distance |
| Distance/duration | Distance divided by duration |
| Duration/distance | Duration divided by distance |
| Distance × angle/duration | (Distance multiplied by angle) divided by duration |
| Duration × angle/distance | (Duration multiplied by angle) divided by distance |
| Distance × duration/angle | (Distance multiplied by duration) divided by angle |
| V1 to V2 pitch variation | Pitch V2 at 20 % – pitch V1 at 80 % |
| V1 to V2 intensity variation | Intensity V2 at 20 % – V1 at 80 % |
| Variation pitch V1 | V1 pitch at 80 % – V1 pitch at 20 % |
| Variation intensity V1 | V1 intensity at 80 % – V1 intensity at 20 % |
| Variation pitch V2 | V2 pitch at 80 % – V2 pitch at 20 % |
| Variation intensity V2 | V2 intensity at 80 % – V2 intensity at 20 % |
| Pitch span V1 | V1 highest pitch/V1 lowest pitch (following Knight and Nolan 2006) |
| Pitch span V2 | V2 highest pitch/V2 lowest pitch |
| Intensity span V1 | V1 maximum intensity/V1 minimum intensity |
| Intensity span V2 | V2 maximum intensity/V2 minimum intensity |
Regarding Table 2, it is important to note the following: Measuring vowels at 20 % and 80 % of each respective duration was done to minimize any effects of coarticulation and it also serves as a way of normalizing points of measurements in relation to duration between the speakers. As different speakers speak at different rates, and even the same speaker might speak faster or slower at different points of his/her speech, measuring acoustic features at 20 % and 80 % maintains the same ratio of point of measure in relation to total length between all the tokens.
Speech rate was measured for each of the 493 vowel sequences. Speech rate was calculated quantitatively, as suggested by Wang and Narayanan (2007). The phonetic unit chosen to calculate the speech rate for each two-vowel sequence (local speech rate) was the syllable, since it is the chosen unit in speech rate studies (Wang and Narayanan 2007). To calculate the local speech rate, the audio was segmented to measure five syllables before and after each of the two-vowel sequences analyzed for the present study and the measurements were taken using a Praat (Boersma and Weenink 2016) script. The number of syllables analyzed before or after each two-vowel sequence was fewer than five if the beginning or end of the sentence (or a pause) was before the five-syllable threshold. For example, in seguramente lo han sido ‘most likely they have been like that’, the section included in the speech rate analysis was five syllables before the sequence /oa/ and two syllables after. The number of syllables measured was divided by their duration to obtain the speech rate as syllables per second.
The interest in analyzing variation in the formants and duration arises from the fact that F1 and F2 values for V1 have been reported to be closer to those of V2 in diphthongs than in hiatuses (Aguilar Cuevas 1994: 196) and diphthongs have been found to be shorter than hiatuses, regardless of whether they are stressed or unstressed (Quilis 1981). “As for diphthongs, two steady-state parts are rarely present in their formant tracks, instead, a continuous transition from one frequency area to another is generally observed” (Aguilar Cuevas 1999: 62). Furthermore, it was considered plausible that diphthongs would present shorter distance from V1 to V2 and a less steep angle, indicating close formant values between vowels. Likewise, V1 to V2 pitch and intensity variation, as well as pitch and intensity span and variation within each vowel, could perhaps be a reliable manner to distinguish between diphthongs and hiatuses. Formant, pitch, and intensity values were rounded off to the nearest whole number, as in other studies (e.g., Al-Tamimi and Khattab 2015).
2.3 Acoustic analysis: results
The acoustic analysis returned a huge amount of data and a table with 1,740 cells would be required to show the mean of the 60 parameters for our 29 speakers. Therefore, a table with only the mean values for the 60 parameters for diphthongs and hiatuses is included (Table 3).
Mean values for diphthongs and hiatuses. All sequences for all speakers.
| Diph | Hia | Diph | Hia | Diph | Hia | |||
|---|---|---|---|---|---|---|---|---|
| V1 dur | 42.53 | 74.93 | V2 dur | 50.70 | 80.74 | Dur seq | 92.77 | 155.64 |
| V1 F1 mean | 510 | 553 | V2 F1 mean | 538 | 564 | F1 mean diff | 28.5809 | 0.3019 |
| V1 F1 20 % | 486 | 565 | V2 F1 20 % | 554 | 580 | F2 mean diff | −11.4251 | 50.7774 |
| V1 F1 80 % | 534 | 568 | V2 F1 80 % | 524 | 536 | Dis (distance) | 234.20 | 349.75 |
| V1 F2 mean | 1,571 | 1,587 | V2 F2 mean | 1,558 | 1,643 | Angle | 29.06 | 29.83 |
| V1 F2 20 % | 1,576 | 1,598 | V2 F2 20 % | 1,559 | 1,620 | Dis/angle | 109.62 | 57.48 |
| V1 F2 80 % | 1,568 | 1,604 | V2 F2 80 % | 1,558 | 1,654 | Angle/dis | 0.26 | 0.19 |
| V1 mean pitch | 165 | 163 | V2 mean pitch | 160 | 165 | Dis/dur | 2.73 | 2.30 |
| V1 H pitch | 169 | 170 | V2 H pitch | 164 | 171 | Dur/dis | 0.64 | 0.75 |
| V1 L pitch | 160 | 157 | V2 L pitch | 155 | 157 | Dis × angle/dur | 60.95 | 54.63 |
| V1 pitch 20 % | 166 | 163 | V2 pitch 20 % | 162 | 163 | Dur × angle/dis | 23.21 | 28.57 |
| V1 pitch 80 % | 163 | 163 | V2 pitch 80 % | 158 | 167 | Dis × dur/angle | 9,063.23 | 10,324.34 |
| V1 mean int | 71 | 71 | V2 mean int | 71 | 72 | V1 to V2 pitch var | −1.8544 | −1.5040 |
| V1 max int | 72 | 73 | V2 max int | 72 | 73 | V1 to V2 int var | −0.1834 | 0.1707 |
| V1 min int | 70 | 70 | V2 min int | 69 | 70 | Variation pitch V1 | −2.86 | 0.20 |
| V1 int 20 % | 71 | 71 | V2 int 20 % | 72 | 72 | Variation int V1 | 0.90 | 0.98 |
| V1 int 80 % | 72 | 72 | V2 int 80 % | 70 | 71 | Variation pitch V2 | −3.46 | 4.04 |
| V1 F1 var | 52 | 1 | V2 F1 var | −32 | −43 | Variation int V2 | −1.5 | −0.76 |
| V1 F2 var | −6 | 5 | V2 F2 var | 4 | 35 | Pitch span V1 | 1.06 | 1.08 |
| Pitch span V2 | 1.07 | 1.10 | ||||||
| Int span V1 | 1.03 | 1.04 | ||||||
| Int span V2 | 1.04 | 1.05 |
Table 3 includes the combined mean values for diphthongs and hiatuses for all sequences and all speakers. The biggest differences between acoustic features of diphthongs and hiatuses seem to be in V1 dur, V2 dur, Sequence dur, V1 F1 mean, F2 mean difference, Distance, and Distance/Angle. This suggests that the biggest differences seem to be regarding the duration of individual vowels and the whole sequence. Distance also seems to be an important factor in this differentiation. However, it should be noted that this combined data might mask some important differences since the results for all sequences and speakers are amalgamated in this table. This had to be done due to space: with 29 speakers, 60 features, and the categories of diphthongs versus hiatuses, 3,480 cells would be needed to include data of each feature for each speaker for diphthongs and hiatuses in that table. Furthermore, 20,880 cells would be needed to add data for each of the six possible sequences to each speaker in Table 3. Those large tables, however, were created and used on SPSS as part of the statistical analysis. A statistical analysis is needed to understand what features, if any, better distinguish between diphthongs and hiatuses.
3 Statistical analysis
3.1 Statistical analysis: methods
Each of the 60 different features was included as a dependent variable. Given the complexity of the data, each acoustic feature was analyzed using a separate linear mixed-effects model; using a separate statistical analysis per feature is common in the literature (e.g., Al-Tamimi and Khattab 2018). The independent variable was the type of sequence (diphthong or hiatus), and the dependent variable was each of the acoustic features to analyze. The features Speaker, Gender, Vowel sequence, Stress pattern, Sequence forms part of one or two words, and Speech rate were entered as random variables. It has been shown that the frequency of use of two-word sequences can influence hiatus resolution in New Mexican Spanish (Alba 2008); however, frequency of use has not been controlled for as a variable in our study because some of our vowel sequences came from two-word sequences but others came from one word.
The local speech rate for each two-vowel sequence was converted into a categorical variable since linear mixed-effects models do not allow continuous variables as random variables. The mean speech rate was 6.12 syllables per second, the lowest value was 1.39, the highest was 12.97, and the SD was 1.44; speech rate values were normally distributed. Initially, it was considered to categorize as “normal” speech rate values within one SD, values more than one SD under the mean as “slow”, and values more than one SD over the mean as “fast”; however, it was decided to use a categorical scale with more points to reflect better the spread of speech rate values. Speech rate values were categorized as a variable by creating 12 categories (from one to 12). Speech rate values with the same integer were assigned to the same category. For example, sequences with a speech rate of 3.4 syllables per second were categorized as 3 and sequences with a speech rate of 7.8 were categorized as 7.
The categorization of the features above as random variables was justified by conclusions in previous studies. Each of the 493 vowel sequences were categorized according to the stress pattern of V1 and V2 (unstressed – unstressed, unstressed – stressed, stressed – unstressed, and stressed – stressed) and this was coded as a random variable in the statistical model; it has been shown that stress influences vowel sequence duration (e.g., Aguilar Cuevas 1999). Furthermore, according to Aguilar Cuevas (1999), hiatuses are longer than diphthongs regardless of the vowels which form the sequence, although hiatuses with /a/ are longer than those with /e/ or /o/ and diphthongs present the opposite tendency. The effect of vowel phoneme on duration and, most importantly, for F1 and F2 values, justifies entering Vowel sequence as a random variable with six values (/ea/, /eo, /ae/, /ao/, /oe/, and /oa/). Lastly, it was decided to differentiate between sequences within a word or across word boundaries as research, albeit not specifically on diphthongs or hiatuses, points to differences in phonetic realization word-internally and across word boundaries (e.g., Oh and Redford 2012; White et al. 2020).
Random intercepts and slopes were included for each random variable (Speaker, Gender, Vowel sequence, Stress pattern, Sequence as part of one or two words and Speech rate) to minimize residuals for the model to fit the data better (Eddington 2015: 112).
Random slopes were used for each speaker under each condition (diphthong vs. hiatus) as each speaker gave various responses under each condition (Eddington 2015: 113). Different models were compared using −2LL (Eddington 2015: 118; Field 2018: 947) and a likelihood ratio test (Eddington 2015: 119; Field 2018: 963). Different covariance structures were used to compare models (Field 2018: 948) and, following (Field 2018: 966), a covariance structure Unstructured was used in the end, assuming that intercepts and slopes are not correlated in any of the dependent variables and bearing in mind that “when slopes are random an unstructured covariance structure is often assumed” (Field 2018: 1,202). All assumptions were tested (e.g., residuals must be homoscedastic) and, as per Field (2018: 232), the assumption of normality of residuals was tested at each unique level (diphthong or hiatus). However, it should be noted that the results of linear mixed-effects models are robust even if distributional assumptions are violated (Schielzeth et al. 2020). The data were transformed following the procedures outlined in Eddington (2015: 54) when a variable violated any assumption (e.g., normality, homoscedasticity, etc.).
3.2 Statistical analysis: results
The results from the linear mixed-effects models testing whether any variable could distinguish a diphthong from a hiatus are included in Table 4. The table also contains information regarding whether the statistical analysis was performed from untransformed or transformed data, as well as the type of transformation carried out for each variable.
Results of the linear mixed-effects models regarding features that can distinguish diphthongs from hiatuses.
| Variable | Transformation, if needed | Results of the linear mixed-effects models | |
|---|---|---|---|
| 1 | V1 duration | Untransformed | F (1, 491) = 11.163 p < 0.001 |
| 2 | V1 F1 mean | Untransformed | F (1, 491) = 0.000 p = 0.998 |
| 3 | V1 F1 20 % | SQRT | F (1, 491) = 0.000 p = 0.995 |
| 4 | V1 F1 80 % | SQRT | F (1, 491) = 1.084 p = 0.298 |
| 5 | V1 F2 mean | Untransformed | F (1, 491) = 0.154 p = 0.695 |
| 6 | V1 F220 % | Untransformed | F (1, 491) = 0.074 p = 0.786 |
| 7 | V1 F280 % | Untransformed | F (1, 491) = 0.081 p = 0.777 |
| 8 | V1 mean pitch | Untransformed | F (1, 480) = −0.517 p = 0.606 |
| 9 | V1 pitch 20 % | Untransformed | F (1, 465) = 1.187 p = 0.277 |
| 10 | V1 pitch 80 % | Untransformed | F (1, 471) = 0.012 p = 0.913 |
| 11 | V1 highest pitch | Untransformed | F (1, 480) = 0.009 p = 0.923 |
| 12 | V1 lowest pitch | Untransformed | F (1, 480) = 0.257 p = 0.613 |
| 13 | V1 mean intensity | SQRT | F (1, 491) = 0.023 p = 0.878 |
| 14 | V1 intensity 20 % | SQRT | F (1, 491) = 0.039 p = 0.845 |
| 15 | V1 intensity 80 % | Untransformed | F (1, 491) = 0.046 p = 0.830 |
| 16 | V1 maximum intensity | Squared | F (1, 491) = 0.058 p = 0.810 |
| 17 | V1 minimum intensity | Untransformed | F (1, 491) = 0.592 p = 0.442 |
| 18 | V2 duration | SQRT | F (1, 491) = 4.568 p = 0.033 |
| 19 | V2 F1 mean | SQRT | F (1, 491) = 0.005 p = 0.941 |
| 20 | V2 F120 % | Untransformed | F (1, 491) = 0.186 p = 0.666 |
| 21 | V2 F180 % | SQRT | F (1, 491) = 0.043 p = 0.836 |
| 22 | V2 F2 mean | Untransformed | F (1, 491) = 0.008 p = 0.929 |
| 23 | V2 F2 20 % | Untransformed | F (1, 491) = 0.026 p = 0.872 |
| 24 | V2 F2 80 % | Untransformed | F (1, 491) = 0.044 p = 0.834 |
| 25 | V2 mean pitch | Untransformed | F (1, 484) = 0.004 p = 0.949 |
| 26 | V2 pitch 20 % | Untransformed | F (1, 475) = 0.018 p = 0.895 |
| 27 | V2 pitch 80 % | Untransformed | F (1, 470) = 0.076 p = 0.783 |
| 28 | V2 highest pitch | Untransformed | F (1, 484) = 0.039 p = 0.844 |
| 29 | V2 lowest pitch | Untransformed | F (1, 484) = 0.052 p = 0.820 |
| 30 | V2 mean intensity | Untransformed | F (1, 491) = 0.010 p = 0.921 |
| 31 | V2 intensity 20 % | Untransformed | F (1, 491) = 0.000 p = 0.990 |
| 32 | V2 intensity 80 % | Untransformed | F (1, 491) = 0.090 p = 0.764 |
| 33 | V2 maximum intensity | Untransformed | F (1, 491) = 0.032 p = 0.857 |
| 34 | V2 minimum intensity | Untransformed | F (1, 491) = 0.067 p = 0.796 |
| 35 | Duration of the sequence | Untransformed | F (1, 491) = 8.529 p = 0.004 |
| 36 | Variation V1 F1 (V1F1 80 % – V1F1 20 %) | Cos (variable) | F (1, 108) = 0.081 p = 0.776 |
| 37 | Variation V1 F2 (V1F2 80 % – V1F2 20 %) | 1/Variable | F (1, 108) = 0.840 p = 0.362 |
| 38 | Variation V2 F1 (V2F1 80 % – V2F1 20 %) | Untransformed | F (1, 491 = 0.000 p = 0.987 |
| 39 | Variation V2 F2 (V2F2 80 % – V2F2 20 %) | +1,000 | F (1, 108) = 0.064 p = 0.800 |
| 40 | Pitch V2 20 % – pitch V1 80 % | Cos (variable) | F (1, 101) = 0.075 p = 0.785 |
| 41 | Intensity V2 20 % – intensity V1 80 % | Untransformed | F (1, 491) = 0.004 p = 0.948 |
| 42 | Distance | Untransformed | F (1, 491) = 1.450 p = 0.229 |
| 43 | Angle (not corrected) | Untransformed | F (1, 491) = 0.001 p = 0.975 |
| 44 | Distance by angle | SQRT | F (1, 491) = 0.001 p = 0.978 |
| 45 | Angle by distance | SQRT | F (1, 491) = 0.148 p = 0.700 |
| 46 | Distance by duration | SQRT | F (1, 491) = 0.028 p = 0.867 |
| 47 | Duration by distance | SQRT | F (1, 491) = 0.363 p = 0.547 |
| 48 | (Distance × angle)/duration | SQRT | F (1, 491) = 0.001 p = 0.973 |
| 49 | (Duration × angle)/distance | SQRT | F (1, 491) = 0.336 p = 0.562 |
| 50 | (Distance × duration)/angle | Cos (variable) | F (1, 108) = 0.096 p = 0.758 |
| 51 | Variation pitch V1 (V1 pitch 80 % – V1 pitch 20 %) | Untransformed | F (1, 459) = 0.263 p = 0.608 |
| 52 | Variation intensity V1 (V1 intensity 80 % – V1 intensity 20 %) | + 1,000 | F (1, 108) = 0.047 p = 0.830 |
| 53 | Variation pitch V2 (V2 pitch 80 % – V2 pitch 20 %) | + 1,000 | F (1, 99) = 0.352 p = 0.554 |
| 54 | Variation intensity V2 (V2 intensity 80 % – V2 intensity 20 %) | Untransformed | F (1, 491) = 0.064 p = 0.801 |
| 55 | Mean difference V2 F1 – V1 F1 | Untransformed | F (1, 491) = 0.030 p = 0.864 |
| 56 | Mean difference V2 F2 – V1 F2 | Untransformed | F (1, 491) = 0.089 p = 0.765 |
| 57 | Pitch span V1 | Squared | F (1, 480) = 0.153 p = 0.696 |
| 58 | Intensity span V1 | Untransformed | F (1, 491) = 0.000 p = 1.000 |
| 59 | Pitch span V2 | Squared | F (1, 484) = 1.425 p = 0.233 |
| 60 | Intensity span V2 | SQRT | F (1, 491) = 0.833 p = 0.362 |
-
Statistically significant results appear in bold.
Apart from a global analysis with all sequences, a separate analysis was run for each vowel sequence in order to investigate simpler statistical models, since “the transitional range and duration may be language-specific, and possibly even diphthong-specific as well” (Lindau et al. 1990: 14). The methodology is the same as the one stated above. Data is only recorded for values that are statistically significant amongst the 60 parameters investigated per vowel sequence (Table 5).
Results of the linear mixed-effects models regarding features that can distinguish diphthongs from hiatuses broken down per sequence.
| Sequence | Parameter | Results from the linear mixed-effects models. Only statistically significant results included |
|---|---|---|
| /ea/ | Variation pitch V1 (V1 pitch at 80 % minus V1 pitch at 20 %) | F (1, 159) = 6.048 p = 0.015 |
| Variation intensity V1 (V1 intensity 80 % – V1 intensity at 20 %) | F (1, 11) = 18.978 p = 0.001 | |
| /eo/ | Duration of V1 | F (1, 28) = 13.809 p < 0.001 |
| Duration of vowel sequence | F (1, 28) = 16.227 p < 0.001 | |
| /ae/ | Duration of V1 | F (1, 85) = 8.255 p = 0.005 |
| V1 F1 at 80 % | F (1, 85) = 8.985 p = 0.004 | |
| Duration of V2 | F (1, 85) = 16.063 p < 0.001 | |
| Distance | F (1, 85) = 8.396 p = 0.005 | |
| Pitch span V1 | F (1, 83) = 7.827 p = 0.006 | |
| Pitch span V2 | F (1, 83) = 7.611 p = 0.007 | |
| /ao/ | Duration of V1 | F (1, 29) = 17.586 p < 0.001 |
| Duration of V2 | F (1, 29) = 10.729 p = 0.003 | |
| Duration of the vowel sequence | F (1, 29) = 36.997 p < 0.001 | |
| Mean difference V2 F1 – F1 F1 | F (1, 29) = 5.442 p = 0.027 | |
| Variation V1 F2 (V1 F2 at 80 % minus V1 F2 at 20 %) | F (1, 6) = 7.706 p = 0.032 | |
| Variation pitch V2 (V2 pitch at 80 % minus V2 pitch at 20 %) | F (1, 29) = 29.694 p < 0.001 | |
| Pitch span V2 | F (1, 29) = 15.145 p < 0.001 | |
| Intensity span V2 | F (1, 29) = 5.540 p = 0.026 | |
| /oe/ | Duration of V2 | F (1, 87) = 31.054 p < 0.001 |
| Duration of the vowel sequence | F (1, 87) = 7.778 p = 0.006 | |
| Variation V1 F2 (V1 F2 80 % – V1 F2 20 %) | F (1, 25) = 4.507 p = 0.044 | |
| Distance | F (1, 87) = 5.603 p = 0.020 | |
| Variation intensity V1 (V1 intensity 80 % – V1 intensity 20 %) | F (1, 87) = 6.021 p = 0.016 | |
| /oa/ | Duration of V1 | F (1, 78) = 27.215 p < 0.001 |
| Duration of V2 | F (1, 78) = 4.344 p = 0.040 | |
| Duration of vowel sequence | F (1, 78) = 46.903 p < 0.001 | |
| Variation F2 V1 (V1 F2 80 % – V1 F2 20 %) | F (1, 14) = 12.921 p = 0.003 | |
| Variation IntensityV2 (V2 intensity 80 % – V2 intensity 20 %) | F (1, 78) = 5.746 p = 0.019 | |
| Intensity span V1 | F (1, 78) = 5.371 p = 0.023 |
4 Discussion
4.1 Diphthongs and hiatuses across all sequences
The analysis across all sequences only identifies three out of the 60 features as being able to distinguish diphthongs from hiatuses: V1 duration, V2 duration, and Duration of the sequence. The results from the linear mixed-effects models show that V1 and V2 are shorter in diphthongs than in hiatuses; these results are calculated from raw data, since duration has not been normalized, although speech rate has been accounted for in the statistical model. We can be 95 % confident that V1 is between 40.61 and 44.1 ms in diphthongs and between 70.1 and 80.66 ms in hiatuses in Spanish. V1’s mean duration is 42.35 ms in diphthongs and 75.34 ms in hiatuses. Regarding V2, we can be 95 % confident that V2 is between 48.25 and 52.41 ms in diphthongs and between 75.04 and 85.95 ms in hiatuses in Spanish. V2’s mean duration is 50.33 ms in diphthongs and 80.5 ms in hiatuses. The linear mixed-effects models suggests that the vowel sequence is longer in hiatuses than in diphthongs. The 95 % confidence interval suggests that diphthongs are between 89.45 and 95.92 ms long, and that hiatuses are between 147.23 and 164.44 ms long. The mean duration for diphthongs is 92.69 ms and for hiatuses is 155.83.
These results are in partial agreement with Quilis (1999) and Aguilar Cuevas (1999), who also claim that diphthongs and hiatuses differ in duration. Nevertheless, Quilis (1999) and Aguilar Cuevas (1999) identify differences in formant stability between diphthongs and hiatuses, with Aguilar Cuevas (1999) also pointing to vowel centralization in diphthongs. However, differences in formants between diphthongs and hiatuses were not statistically significant in our sample when all types of vowel sequences were considered.
4.2 Diphthongs and hiatuses analyzed by vowel sequence
Regarding the analysis per sequence, the results show different patterns depending on the vowels involved, which is to be expected. Durational differences can differentiate diphthongs from hiatuses in five out of the six vowel sequences, formant measurements, intensity measurements, and pitch measurements can distinguish diphthongs and hiatuses in four out of the six vowel sequences.
For the sequence /ea/, Variation of V1 pitch and Variation of V1 intensity are the only parameters that can differentiate diphthongs from hiatuses. In the sequence /eo/, Duration of V1 and Duration of the vowel sequence can difference between diphthongs and hiatuses. For the sequence /ae/, Duration of V1, Duration of V2, V1 F1 at 80 %, Distance, Pitch span V1, and Pitch span V2 can distinguish diphthongs and hiatuses. For /ao/, the features that can identify this difference are Duration of V1, Duration of V2, Duration of the vowel sequence, Difference between mean F1 of V1 and V2, Variation of V1 F2, Variation of V2 pitch, Pitch span V2, and Intensity span V2. In the sequence /oe/, Duration of V2, Duration of the vowel sequence, Variation in V1 F2, Distance, and Variation of V1 intensity can differentiate between diphthongs and hiatuses. Finally, in the sequence /oa/, Duration of V1, Duration of V2, Duration of the vowel sequence, Variation of V1 F2, Variation of V2 intensity, and Intensity span V1 can differentiate between diphthongs and hiatuses.
Although these results may seem chaotic at first, a closer analysis reveals some interesting patterns. For example, the different combinations of the features Distance and Angle are never statistically significant either for all sequences or for each individual sequences; Duration is only statistically significant by itself, but not when combined with Distance or Angle. Duration, pitch, and intensity are statistically significant in more cases than formant-re-related measures; this shows that suprasegmental features are more relevant in diphthong and hiatus distinction than segmental ones. Furthermore, F2 is a more robust acoustic cue of diphthongization than F1.
Durational differences seem to be in operation regardless of differences in height, since we can see that diphthong and hiatus distinction based on duration is in operation in vowels with the same degree of openness (e.g., /eo/) and with vowels with different ones (e.g., /oa/). Duration seems to be as robust to distinguish diphthongs from hiatuses in V1 as in V2.
Pitch-related differences are only statistically significant in the sequences /ea/, /ae/, and /ao/. This could mean that pitch acts as a stronger acoustic cue to differentiate diphthongs from hiatuses when the vowel /a/ is part of the sequence. This could be due, perhaps, to differences in how tense different vowels are in Spanish (Gil Fernández 2007).
Intensity-related features are statistically significant in the sequences /ea/, /ao/, /oe/ and /oa/. Intensity appears to be slightly more robust in V1 than in V2 when it comes to distinguishing diphthongs from hiatuses.
Finally, although Quilis (1999) and Aguilar Cuevas (1999) support formant differences between diphthongs and hiatuses, F1 is only statistically significant in our sample in /ae/ and /ao/, and F2 in /ao, /oe/ and /oa/. This could indicate that F2 is able to distinguish diphthongs from hiatuses when V1 is /o/. Perhaps, this is due to larger differences in F2 between front/central vowels and the back vowel /o/. Formant differences seem to more relevant in V1 than in V2.
While the sequences /ea/ and /eo/ only yield two statistically significant results each, the sequences /oe/ yields five statistically significant results, /ae/ and /oa/ six, and /ao/ eight. This suggests that it is easier to differentiate acoustically between diphthongs and hiatuses when the vowel /o/ is part of the sequence. Furthermore, the fact that suprasegmental features seem to be stronger acoustic cues to diphthongization than segmental features could mean that there is not as much coarticulation between vowels as it could be expected.
5 Conclusions
The aim of this article was to answer two research questions:
Do Spanish speakers from a high sociocultural background pronounce two-vowel sequences of /e/, /a/, and /o/ as hiatuses, as prescribed by RAE, even in the most formal of registers?
What are the most reliable phonetic features to distinguish a diphthong from a hiatus in Spanish?
Regarding the first question, perceptual, acoustic, and statistical analyses in this article provide support to proof that, despite the classification of any two-vowel sequence of /e/, /a/, and /o/ as a hiatus by RAE, these sequences are, in fact, pronounced more often as a diphthong; it should be noted that the classification is based on results from a perception study by the two authors. This is the case even in the most prestigious users of the language in the most formal of situations.
According to our analysis, out of 506 two-vowel sequences of /e/, /a/, and /o/, 391 (77.27 %) were pronounced as diphthongs by members of RAE and 115 (22.73 %) were pronounced as a hiatus. The rate of diphthongization of two-vowel sequences of /e/, /a/, and /o/ was of 77.27 % in the perception analysis by the two authors. However, given that our corpus comes from reading extracts from speakers of the highest sociocultural level in extremely formal situations, that Aguilar Cuevas (1999) says that diphthongization is more common in spontaneous speech than in read speech, and that RAE considers diphthongization of hiatuses as more common in speakers of lower levels of education, we can only assume that two-vowel sequences of /e/, /a/, and /o/ are pronounced as diphthongs at a much higher rate than 77.27 % in Spanish by the general population and in more informal contexts.
With regards to the second question, the only acoustic features that can differentiate diphthongs from hiatuses when the data for all vowel sequences are analyzed together are Duration of V1, Duration of V2, and Duration of the sequence. When we analyze each vowel sequence separately, the most reliable feature is duration; formant changes, intensity and pitch are much less reliable. Therefore, we can conclude that duration is the most reliable clue to distinguish between diphthongs and hiatuses in Spanish. The importance of durational differences in these types of distinctions has already been noted in the literature (e.g., Aguilar Cuevas 1999; Barbería Aurrekoetxea 2012; Garrido 2013); however, to our knowledge, this is the first article to provide evidence of the role of intonation and pitch in such distinctions. While duration seems to be an equally important cue for distinction in V1 and V2, formant changes is much more robust for V1.
This article provides evidence that two-vowel sequences of /e/, /a/, and /o/ are pronounced as diphthongs in Spanish, rather than as hiatuses; this means that acting as a glide in Spanish is not restricted to high vowels. Data from the current study show that this is the case even in speakers from Spain from extremely high sociocultural background in extremely formal registers.
The findings of this article have important implications for Spanish spelling. There have been some proposals in the past regarding the spelling of diphthongs and hiatuses (e.g., Benot 1898; De Herrera 1580; García del Pozo 1825); however, these were unsuccessful. As a result, anti-hiatus pronunciation has no reflection in spelling, which makes understanding this phenomenon even more difficult. Accent mark placing rules depend on syllable counting in Spanish (except in the few cases when it is used to differentiate between homophones, such as tú ‘you’ and tu ‘your’ or sí ‘yes’ and si ‘if’) and counting two-vowel sequences of /e/, /a/, and /o/ as two syllables is based on a normative description which ignores phonetic reality. This distances Spanish spelling from its focus on phonetic faithfulness (RAE 1999: V). Under current spelling conventions, words like área ‘area’ and héroe ‘hero’ carry an accent mark as they are considered proparoxytone words. However, these words are normally pronounced as paroxytone as their last two vowels are pronounced as a diphthong instead of as a hiatus. As a result, área ‘area’ and héroe ‘hero’ have no reason to carry accent marks since Spanish paroxytone words which end in a diphthong (e.g., gloria ‘glory’ [ˈɡlo.ɾja]) do not carry accent marks; área ‘area’ and héroe ‘hero’ should be spelled as area and heroe. On the other hand, paroxytone words involving a hiatus instead of a diphthong do carry an accent mark on the high vowel: dúo ‘duet’ [ˈdu.o], manía ‘fixation’ [ma.ˈni.a]. Accepting that the role of glides is not restricted to high vowels in Spanish could lead to applying these accent mark placing rules to paroxytone words that involve hiatus among mid and open vowels: tarea ‘task’ [ta.ˈre.a] spelled taréa, correo ‘mail’ [ko.ˈre.o] spelled corréo. However, such spelling changes might clash with the principle of simplicity which has driven reforms of Spanish spelling through the centuries (RAE 1999: V), even though the abovementioned changes might reflect pronunciation more effectively. The findings in this article highlight the need for an open discussion on how spelling differs from pronunciation, which could benefit the understanding of anti-hiatus tendencies in the context of to what extent can writing conventions reflect speech features.
-
Data availability statement: The data underlying the analysis my be viewed at https://zenodo.org/records/10206471.
References
Abete, Giovanni. 2011. I processi di dittongazione nei dialetti dell’Italia meridionale. Roma: Aracne.Search in Google Scholar
Aguilar Cuevas, Lourdes. 1994. Los procesos fonológicos y su manifestación fonética en diferentes situaciones comunicativas: La alternancia vocal/semiconsonante/consonante. Barcelona: Universitat Autònoma de Barcelona Dissertation.Search in Google Scholar
Aguilar Cuevas, Lourdes. 1999. Hiatus and diphthong: Acoustic cues and speech situation differences. Speech Communication 28. 57–74. https://doi.org/10.1016/s0167-6393(99)00003-5.Search in Google Scholar
Al-Tamimi, Jalal & Ghada Khattab. 2015. Acoustic cue weighting in the singleton vs geminate contrast in Lebanese Arabic: The case of fricative consonants. The Journal of the Acoustical Society of America 138(1). 344–360. https://doi.org/10.1121/1.4922514.Search in Google Scholar
Al-Tamimi, Jalal & Ghada Khattab. 2018. Acoustic correlates of the voicing contrast in Lebanese Arabic singleton and geminate stops. Journal of Phonetics 71. 306–325. https://doi.org/10.1016/j.wocn.2018.09.010.Search in Google Scholar
Alarcos Llorach, Emilio. 1950. Fonología española. Madrid: Gredos.Search in Google Scholar
Alarcos Llorach, Emilio. 1976 [1950]. Fonología Española, 4th edn. Madrid: Gredos.Search in Google Scholar
Alarcos Llorach, Emilio. 1999. Gramática de la lengua española. Madrid: Espasa.Search in Google Scholar
Alba, Matthew C. 2006. Accounting for variability in the production of Spanish vowel sequences. In Nuria Segarra & Jacqueline Toribio Almeida (eds.), Selected Proceedings of the 9th Spanish Linguistics Symposium, 273–285. Sommerville, MA: Cascadilla Proceedings Project.Search in Google Scholar
Alba, Matthew C. 2008. Ratio frequency: Insights into usage effects of phonological structure from hiatus resolution in New Mexican Spanish. Studies in Hispanic and Lusophone Linguistics 1(2). 247–286. https://doi.org/10.1515/shll-2008-1020.Search in Google Scholar
Alcina, Juan & José Manuel Blecua. 1975. Gramática española. Barcelona: Ariel.Search in Google Scholar
Alcoholado Feltstrom, Antonio. 2020. Antihiatismo en español: Un problema fonológico entre la preceptiva literaria y la normativa gramatical. Lexis 44(1). 145–173. https://doi.org/10.18800/lexis.202001.005.Search in Google Scholar
Altman, Douglas G. 1991. Practical statistics for medical research. Boca Raton, FL: Chapman & Hall/CRC.Search in Google Scholar
Alvar, Manuel. 1996a. Manual de dialectología hispánica. El español de España. Barcelona: Ariel.Search in Google Scholar
Alvar, Manuel. 1996b. Manual de dialectología hispánica. El español de América. Barcelona: Ariel.Search in Google Scholar
Asociación de Academias de la Lengua Española (ASALE). 2005. Diccionario panhispánico de dudas. Madrid: Santillana.Search in Google Scholar
Asociación de Academias de la Lengua Española (ASALE). 2011. Nueva gramática de la lengua española. Fonética y fonología. Barcelona: Espasa.Search in Google Scholar
Barbería Aurrekoetxea, Irene. 2012. The gradientnNature of hiatus resolution in Spanish. San Sebastián: Universidad de Deusto Dissertation.Search in Google Scholar
Benot, Eduardo. 1898. Prosodia castellana y versificación. Madrid: Juan Muñoz Sánchez.Search in Google Scholar
Boersma, Paul & David Weenink. 2016. Praat: Doing phonetics by computer.Search in Google Scholar
Bongiovanni, Silvina. 2015. Neutralización del contraste entre /ɲ/ y /nj/ en el español de Buenos Aires: un estudio de percepción. Signo y Seña 27. 11–46.Search in Google Scholar
Chitoran, Ioana & José Ignacio Hualde. 2002. From hiatus to diphthong: The evolution of vowel sequences in Romance. Phonology 24. 37–75. https://doi.org/10.1017/s095267570700111x.Search in Google Scholar
Colina, Sonia. 2009. Spanish phonology: A syllabic perspective. Washington, DC: Georgetown University Press.Search in Google Scholar
Collins, Beverley & Inger Mees. 2013. Practical phonetics and phonology. New York, NY: Routledge.10.4324/9780203080023Search in Google Scholar
Contreras, Heles. 1969. Vowel fusión in Spanish. Hispania 52(1). 60–62. https://doi.org/10.2307/337724.Search in Google Scholar
Davenport, Mike & Stephen J. Hannahs. 2005. Introducing phonetics and phonology. London: Hodder Arnold.Search in Google Scholar
De Herrera, Fernando. 1580. Obras de Garcilaso de la Vega con anotaciones de Fernando de Herrera. Seville: Alonso de la Barrera.Search in Google Scholar
Eddington, David. 2015. Statistics for linguists: A step-by-step guide for novices. Newcastle upon Tyne: Cambridge Scholars Publishing.Search in Google Scholar
Field, Andy. 2018 [2000]. Discovering statistics using IBM SPSS statistics: North American edition, 5 edn. Thousand Oaks, CA: Sage.Search in Google Scholar
García del Pozo, Gregorio. 1825. La doble ortología castellana, o correspondencia entre la pronunciación y la escritura de este idioma. Madrid: Imprenta de E. Aguado.Search in Google Scholar
Garrido, Marisol. 2008. Diphthongization of non-high vowel sequences in Latin-American Spanish. Urbana-Champaign, IL: University of Illinois Dissertation.Search in Google Scholar
Garrido, Marisol. 2013. Hiatus resolution in Spanish: Motivating forces, constraining factors, and research methods. Language and Linguistics Compass 7(6). 339–350. https://doi.org/10.1111/lnc3.12026.Search in Google Scholar
Gil Fernández, Juana. 2007. Fonética para profesores de español: De la teoría a la práctica. Madrid: Arco Libros.Search in Google Scholar
Gili Gaya, Samuel. 1988. Elementos de fonética general. Madrid: Gredos.Search in Google Scholar
Hedia, Sonia Ben & Ingo Plag. 2017. Gemination and degemination in English prefixation: Phonetic evidence for morphological organization. Journal of Phonetics 62. 34–49. https://doi.org/10.1016/j.wocn.2017.02.002.Search in Google Scholar
Hidalgo Navarro, Antonio & Mercedes Quilis Merín. 2012. La voz del lenguaje: Fonética y fonología del español. Valencia: Tirant Humanidades.Search in Google Scholar
Hsu, Louis M. & Ronald Field. 2003. Interrater agreement measures: Comments on Kappan, Cohen’s Kappa, Scott’s π, and Aickin’s α. Understanding Statistics 2(3). 205–219. https://doi.org/10.1207/s15328031us0203_03.Search in Google Scholar
Hualde, José I., Christopher D. Eager & Marianna Nadeu. 2015. Catalan voiced prepalatals: Effects of nonphonetic factors on phonetic variation? Journal of the International Phonetic Association 45(3). 243–267. https://doi.org/10.1017/s0025100315000031.Search in Google Scholar
Hualde, José Ignacio. 2005. The sounds of Spanish. Cambridge: Cambridge University Press.Search in Google Scholar
Hualde, José Ignacio & Mónica Prieto. 2002. On the diphthong/hiatus contrast in Spanish: Some experimental results. Linguistics 40. 217–234. https://doi.org/10.1515/ling.2002.010.Search in Google Scholar
Jacewicz, Ewa, Robert Fox & Samantha Lyle. 2009. Variation in stop consonant voicing in two regional varieties of American English. Journal of the International Phonetic Association 39(3). 313–334. https://doi.org/10.1017/s0025100309990156.Search in Google Scholar
Jenkins, Devin L. 1999. Hiatus resolution in Spanish: Phonetic aspects and phonological implications from Northern New Mexican data. Albuquerque, NM: University of New Mexico Dissertation.Search in Google Scholar
Knight, Rachael-Anne & Francis Nolan. 2006. The effect of pitch span on intonational plateaux. Journal of the International Phonetic Association 36(1). 21–38. https://doi.org/10.1017/s0025100306002349.Search in Google Scholar
Kuzla, Claudia, Taehyong Cho & Mirjam Ernestus. 2007. Prosodic strengthening of German fricatives in duration and assimilatory devoicing. Journal of Phonetics 35(3). 301–320. https://doi.org/10.1016/j.wocn.2006.11.001.Search in Google Scholar
Ladefoged, Peter & Keith Johnson. 2009. A course in phonetics. Boston, MA: Wadsworth.Search in Google Scholar
Landers, Richard N. 2015. Computing intraclass correlations (ICC) as estimates of interrater reliability in SPSS. The Winnower 2. 1–4.Search in Google Scholar
Landis, J. Richard & Gary G. Koch. 1977. The measurement of observer agreement for categorical data. Biometrics 33(1). 159–174. https://doi.org/10.2307/2529310.Search in Google Scholar
Lapesa, Rafael. 1997 [1942]. Historia de la lengua, 9th edn. Madrid: Gredos.Search in Google Scholar
Lindau, Mona, Kjell Norlin & Jan-Olof Svantesson. 1990. Some cross-linguistic differences in diphthongs. Journal of the International Phonetic Association 20(1). 10–14. https://doi.org/10.1017/s0025100300003996.Search in Google Scholar
Lloyd, Paul M. 1987. From Latin to Spanish. Philadelphia: American Philosophical Society.Search in Google Scholar
Martínez Celdrán, Eugenio. 1984. Fonética. Barcelona: Teide.Search in Google Scholar
Martínez Celdrán, Eugenio & Ana María Fernández Planas. 2007. Manual de fonética española. Barcelona: Ariel.Search in Google Scholar
Mayr, Robert & Hannah Davies. 2011. A cross-dialectal acoustic study of the monophthongs and diphthongs of Welsh. Journal of the International Phonetic Association 41(1). 1–25. https://doi.org/10.1017/s0025100310000290.Search in Google Scholar
Monroy Casas, Rafael. 2004. Aspectos fonéticos de las vocales españolas. Buenos Aires: Libros en red.Search in Google Scholar
Nadeu, Marianna. 2016. Phonetic and phonological vowel reduction in Central Catalan. Journal of the International Phonetic Association 46(1). 33–60. https://doi.org/10.1017/s002510031500016x.Search in Google Scholar
Navarro Tomás, Tomás. 1918. Manual de pronunciación española. Madrid: Centro de Estudios Históricos.Search in Google Scholar
Nebrija, Antonio. 1492. Arte de la lengua castellana. Salamanca: Juan de Porras.Search in Google Scholar
Oh, Grace E. & Melissa A. Redford. 2012. The production and phonetic representation of fake geminates in English. Journal of Phonetics 40(1). 82–91. https://doi.org/10.1016/j.wocn.2011.08.003.Search in Google Scholar
Quilis, Antonio. 1981. Fonética acústica de la lengua española. Madrid: Gredos.Search in Google Scholar
Quilis, Antonio. 1999. Tratado de fonología y fonética españolas. Madrid: Gredos.Search in Google Scholar
Rabanales, Ambrosio. 1960. Hiato y antihiato en el español vulgar de Chile. Boletín de Filología 12. 197–223.Search in Google Scholar
Real Academia Española de la Lengua (RAE). 1920. Gramática de la lengua castellana. Madrid: Perlado, Páez y Cía.Search in Google Scholar
Real Academia Española de la Lengua (RAE). 1931. Gramática de la lengua española. Madrid: Espasa-Calpe.Search in Google Scholar
Real Academia Española de la Lengua (RAE). 1973. Esbozo de una nueva gramática de la lengua Española. Madrid: Espaca-Calpe.Search in Google Scholar
Real Academia Española de la Lengua (RAE). 1999. Ortografía de la lengua española. Madrid: Espasa-Calpe.Search in Google Scholar
Recasens, Daniel & Meritxell Mira. 2012. Voicing assimilation in Catalan two-consonant clusters. Journal of Phonetics 40(5). 639–654. https://doi.org/10.1016/j.wocn.2012.06.001.Search in Google Scholar
Roettger, Timo B., Bodo Winter, Seven Grawunder, James Kirby & Martine Grice. 2014. Assessing incomplete neutralization of final devoicing in German. Journal of Phonetics 43. 11–25. https://doi.org/10.1016/j.wocn.2014.01.002.Search in Google Scholar
Schielzeth, Holger, Neils J. Dingemanse, Shinichi Nakagawa, David F. Westneat, Hassen Allegue, Céline Teplitsky, Denis Réale, Ned A. Dochtermann, László Zsolt Garamszegi & Yimen G. Araya‐Ajoy. 2020. Robustness of linear mixed‐effects models to violations of distributional assumptions. Methods in Ecology Evolution 11(9). 1141–1152. https://doi.org/10.1111/2041-210x.13434.Search in Google Scholar
Thomas, Erik R. & Tyler Kendall. 2007. NORM: The vowel normalization and plotting suite. Online Resource. Available at: http://lingtools.uoregon.edu/norm/about_norm1.php.Search in Google Scholar
Torreira, Francisco. 2007. Coarticulation between aspirated-s and voiceless stops in Spanish. An interdialectal comparison. In Nuria Sagarra & Jacqueline Toribio Almeida (eds.), Selected proceedings of the 9th Spanish Linguistics Symposium, 114–120. Sommerville, MA: Cascadilla Proceedings Project.Search in Google Scholar
Torreira, Francisco. 2012. Investigating the nature of aspirated stops in Western Andalusian Spanish. Journal of the International Phonetic Association 42(1). 49–63. https://doi.org/10.1017/s0025100311000491.Search in Google Scholar
Turk, Alice, Satsuki Nakai & Mariko Sugahara. 2006. Acoustic segment durations in prosodic research: A practical guide. In Stefan Sudhoff, Denisa Lenertová, Roland Meyer, Sandra Pappert, Petra Augurzky, Ina Mleinek, Nicole Richter & Johannes Schließer (eds.), Methods in empirical prosody research, 1–27. Berlin & New York: Walter de Gruyter.Search in Google Scholar
Wang, Dagen & Shrikanth Narayanan. 2007. Robust speech rate estimation for spontaneous speech. IEEE Transactions on Audio, Speech, and Language Processing 15(8). 2190–2201. https://doi.org/10.1109/tasl.2007.905178.Search in Google Scholar
White, Laurence, Silvia Benavides-Varela & Katalin Mády. 2020. Are initial-consonant lengthening and final-vowel lengthening both universal word segmentation cues? Journal of Phonetics 81. 100982. https://doi.org/10.1016/j.wocn.2020.100982.Search in Google Scholar
Wikström, Jussi. 2013. An acoustic study of the RP English LOT and THOUGHT vowels. Journal of the International Phonetic Association 43(1). 37–47. https://doi.org/10.1017/s0025100312000345.Search in Google Scholar
Wongpakaran, Nahathai, Tinakon Wongpakaran, Danny Wedding & Kilem L. Gwet. 2013. A comparison of Cohen’s Kappa and Gwet’s AC1 when calculating inter-rater reliability coefficients: A study conducted with personality disorder samples. BMC Medical Research Methodology 13(1). 61. https://doi.org/10.1186/1471-2288-13-61.Search in Google Scholar
Wu, Xianghua, Murray J. Munro & Yue Wang. 2014. Tone assimilation by Mandarin and Thai listeners with and without L2 experience. Journal of Phonetics 46. 86–100. https://doi.org/10.1016/j.wocn.2014.06.005.Search in Google Scholar
© 2023 the author(s), published by De Gruyter, Berlin/Boston
This work is licensed under the Creative Commons Attribution 4.0 International License.
Articles in the same Issue
- Frontmatter
- Adversative and experiential applicative constructions in Northern Amis (Austronesian)
- Inflection and derivation as traditional comparative concepts
- Comprehension and production of Kinyarwanda verbs in the Discriminative Lexicon
- Psych verbs: the behavior of ObjExp verbs in Brazilian Portuguese
- Semantic roles and the causative-anticausative alternation: evidence from French change-of-state verbs
- Anti-hiatus tendencies in Spanish: rate of occurrence and phonetic identification
- Discourse markers as the locus of signaling the main-event line in Alsea narratives
Articles in the same Issue
- Frontmatter
- Adversative and experiential applicative constructions in Northern Amis (Austronesian)
- Inflection and derivation as traditional comparative concepts
- Comprehension and production of Kinyarwanda verbs in the Discriminative Lexicon
- Psych verbs: the behavior of ObjExp verbs in Brazilian Portuguese
- Semantic roles and the causative-anticausative alternation: evidence from French change-of-state verbs
- Anti-hiatus tendencies in Spanish: rate of occurrence and phonetic identification
- Discourse markers as the locus of signaling the main-event line in Alsea narratives