Introducing Grid WAR: rethinking WAR for starting pitchers
-
Ryan S. Brill

 and
Abraham J. Wyner
and
Abraham J. Wyner

Abstract
The baseball statistic “Wins Above Replacement” (WAR) has emerged as one of the most popular evaluation metrics. But it is not readily observed and tabulated; WAR is an estimate of a parameter in a vaguely defined model with all its attendant assumptions. Industry-standard models of WAR for starting pitchers from FanGraphs and Baseball Reference all assume that season-long averages are sufficient statistics for a pitcher’s performance. This provides an invalid mathematical foundation for many reasons, especially because WAR should not be linear with respect to any counting statistic. To repair this defect, as well as many others, we devise a new measure, Grid WAR, which accurately estimates a starting pitcher’s WAR on a per-game basis. The convexity of Grid WAR diminishes the impact of “blow-up” games and up-weights exceptional games, raising the valuation of pitchers like Sandy Koufax, Whitey Ford, and Catfish Hunter who exhibit fundamental game-by-game variance. Although Grid WAR is designed to accurately measure historical performance, it has predictive value insofar as a pitcher’s Grid WAR is better than Fangraphs’ FIP WAR at predicting future performance. Finally, at https://gridwar.xyz we host a Shiny app which displays the Grid WAR results of each MLB game since 1952, including career, season, and game level results, which updates automatically every morning.
1 Introduction
1.1 Why calculate WAR?
Player valuation is one of the fundamental goals of sports analytics. In team sports, the goal in particular is to quantify the contributions of individual players towards the collective performance of their team. In baseball player roles are clearly defined and events are discrete (see Appendix A for a review of the rules of baseball). This has led to the development of separate player valuation measures for each aspect of the game: hitting, pitching, fielding, and baserunning (Baumer et al. 2015). Historically fundamental measures for evaluating hitters include batting average (BA), on-base percentage (OBP), and slugging percentage (SLG). Classical measures of pitching include earned run average (ERA) and walks and hits per inning pitched (WHIP). For a more thorough review of other player performance measures in baseball, we refer to the reader to Thorn and Palmer (1984), Lewis (2003), Albert and Bennett (2003), Schwarz and Gammons (2005), Tango et al. (2007), Baumer and Zimbalist (2014), and Baumer et al. (2015).
The benefit of separately measuring different aspects of baseball is that it isolates different aspects of player ability. The drawback is that it doesn’t provide a comprehensive measure of overall player performance. This makes it difficult to compare the value of players across positions. For instance, is a starting pitcher with a 2.50 ERA more valuable than a shortstop with a 2.80 batting average? As the fundamental result of a baseball game is a win or loss, the ideal unified measure of a player’s performance is his contribution to the number of games his team wins. On this view, an analyst’s task is to apportion this total number of wins to each player.
To this end, wins above replacement (WAR) estimates an individual baseball player’s contribution on the scale of team wins relative to a replacement level player. Win contribution is not estimated relative to a league average player because average players themselves are valuable. A better baseline is a replacement level player who is freely available to add to your team in the absence of the player being evaluated (e.g., a minor league free agent). With this baseline, Sandy Koufax having 11.5 wins above replacement in 1966 means that losing Koufax to injury is associated, on average, with his team dropping about 11.5 games in the standings over an entire season.
1.2 Standard WAR calculations
Traditional measures of player performance like ERA and others listed previously are counting statistics. In other words, they are statistics which tabulate what factually happened during a season. For instance, in 1966 Sandy Koufax had 62 earned runs in 323 innings, resulting in a 1.73 ERA. WAR, on the other hand, is not a readily observed counting statistic. In other words, how many of the 1966 Dodgers’ 95 wins were due to Koufax’s contributions is not a known or observable quantity. Rather, WAR must be estimated from historical data.
Estimating a player’s wins above replacement is an inherently difficult task because the ultimate win/loss result of a game is the culmination of a complex interaction of event outcomes involving players of varying roles. Accordingly, there have been many different attempts to estimate a baseball player’s WAR. The fundamental idea behind each of these estimation procedures is to capture the contribution of a player’s observed performance isolated from the factors outside of his control. The way in which we measure observed performance is a crucial component of estimating his contribution to winning games.
To estimate WAR, a baseball analyst first chooses a base metric of performance and then maps this base metric to wins. Different choices of base metric yield substantially different estimates for WAR. For instance, FanGraphs builds separate WAR values for pitchers from two counting stats: fielding-independent pitching (FIP) and average runs allowed per nine innings (RA/9). FIP is a weighted average of a pitcher’s isolated pitching metrics[1] (e.g., home runs, walks, and strikeouts) (Slowinski 2012). Baseball Reference builds WAR for pitchers from expected runs allowed (xRA), which assigns to each potential at-bat outcome[2] an expected run value (Baseball Reference 2011). For instance, the expected runs allowed off a single reflects the average number of runs that follow a single in a half-inning.
The difference between Runs Allowed, FIP, and xRA, and hence the associated WAR values for players, can be substantial. FIP, unlike runs allowed and xRA, ignores at-bat outcomes involving fielders in order to fully disentangle pitching performance from fielding. Specifically, FIP excludes balls-in-play (singles, doubles, triples, ground outs, fly outs, etc.) because fielders’ actions play a role in the outcome of these plays. Furthermore, FIP and xRA, unlike runs allowed, do not depend on the sequencing of events in an inning. For example, consider an inning where a pitcher strikes out three, while allowing a home run, two walks, and a single. Depending on the sequence of the events, the pitcher could be charged with one to four runs. The pitcher’s FIP and xRA for this inning, however, are the same regardless of the sequence. For a more thorough review of the differences in their methodologies, we refer the reader to the supplementary materials of Baumer et al. (2015).
After choosing a base measure of player performance, a baseball analyst then decides how to aggregate player performance over the course of a season. Current implementations of WAR from FanGraphs and Baseball Reference average pitcher performance over the entire season (e.g., RA per nine innings, FIP per inning, and xRA per out).
1.3 Problems with standard WAR calculations for starting pitchers
For starting pitchers in particular, there are two problems with standard WAR calculations. First, a base measure of pitcher performance should account for sequencing context; FIP and xRA do not. Second, pitcher performance should not be a simple average across innings and games.
Problem 1: excluding sequencing context. Standard WAR calculations are functions of pitcher performance, traditionally one of FIP, xRA, or runs allowed. If the pitcher cannot affect the sequence of events in an inning, then it makes sense to measure his performance using FIP or xRA. If sequencing variation were due to chance alone, it would not be controlled by the pitcher and should reasonably be excluded. For starting pitchers, however, sequencing variability has other causes. Blake Snell in 2023 is a prime example: he has the highest walk rate since 2000[3] yet has the best ERA in baseball (2.33) and an exceptional 1.2 ERA through the last 23 games at the time of this writing. High-strikeout pitchers like Snell can give up walks strategically without giving up runs; he can increase his effort to strike out a batter when necessary. All this indicates that he exerts some control over the sequencing of events.[4] Thus, we believe starting pitchers bear responsibility for their sequence of outcomes and that their performance in situations of varying leverage should be taken into account. For batters, there is enough evidence of this to generate a substantial debate – see for example, Bill James’ comparison of Altuve and Judge[5] – but for pitchers the argument against it is nonsense. Thus, we should not use FIP or xRA, which remove sequencing context, as a base measure of pitcher performance to estimate a starting pitcher’s WAR. Rather, in this paper we use runs allowed.[6]
Problem 2: averaging across games. After selecting a base measure of pitcher performance, standard WAR calculations from FanGraphs and Baseball Reference then average pitcher performance over the entire season (e.g., RA per nine innings, FIP per inning, and xRA per out). If the pitcher doesn’t affect his variability across games, then it makes sense to average his performance across games. If variation across games were due to chance alone, it would not be controlled by the pitcher and should reasonably be excluded. For starting pitchers, however, we believe that game-by-game variability has causes other than chance. Sandy Koufax in 1966 is a prime example: he had an astounding 17 complete games in which he allowed at most one run[7] yet had three terrible “blow-up” games. The variability of pitchers like Koufax appears in noticeable patterns, indicating that his non-stationarity across games is a fundamental trait. Our method will account for the possibility that the version of Sandy Koufax that starts a game and gets tagged for six runs in two innings is fundamentally different from the Koufax who strikes out the first six batters (colloquially known as the “the left arm of God”).
Since a starting pitcher’s game-by-game variability is not entirely due to chance, averaging pitcher performance across games is wrong, specifically because not all runs have the same value within each game. To understand this, think of a starting pitcher’s WAR in a single game as a function R ↦ WAR(R) where R is the number of runs allowed in that game.[8] We expect WAR to be a decreasing function of R because allowing more runs in a game should correspond to fewer wins above replacement. Additionally, we expect WAR to be a convex function in R (i.e. its second derivative is positive.) As R increases, we expect the relative impact of allowing an extra run, given by WAR(R + 1) − WAR(R), to decrease. For instance, allowing two runs instead of one should have a much steeper drop off in WAR than allowing eight runs instead of seven.[9] Therefore, by Jensen’s inequality,
Traditional methods for computing WAR are reminiscent of the left side of Equation (1): first average a pitcher’s performance, then compute his WAR from the resulting average scaled by the number of innings pitched. Averaging weighs each run allowed equally, causing a pitcher’s “blow-up” games to unfairly dilute the value of high quality performances. Because winning a baseball game is defined by the runs allowed during a game, WAR should look like the right side of Equation (1) – compute the WAR of each of a pitcher’s individual games, and then aggregate. Crucially, these quantities are not the same.
For concreteness, consider Max Scherzer’s six game stretch from June 12, 2014 through the 2014 All Star game, shown in Table 1 (ESPN 2014). We re-arrange the order of these games to aid our explanation. He was excellent in games one through five and had a 1.2 ERA (five runs in 37 innings). This corresponds to about 2 WAR according to standard metrics (the Detroit Tigers did in fact win all 5). In game six, Scherzer was rocked for ten runs in four innings, exiting in the fifth inning with runners on second and third and no outs. His ERA over the six game stretch ballooned to 3.3 (15 runs allowed in 41 innings), reducing his total WAR to about 1/2 according to standard metrics. This is a complete absurdity: because a game can’t be lost more than once, accumulated “real” WAR cannot drop from 2 to 1/2 with the addition of one game! The correct assessment would charge Scherzer with the maximum possible damage, about −0.40 wins. So Scherzer’s “real” WAR over the six games should be about 1.5, which is three times higher than the standard calculation. By evaluating Scherzer’s performances using only the average, standard WAR significantly devalues his contributions during this six game stretch. The correct approach would be to calculate WAR per game and sum them up.
Max Scherzer’s performance over six games prior to the 2014 all star break, consisting of five excellent games and one bad “blow-up” game.
| Game | 1 | 2 | 3 | 4 | 5 | 6 | total |
|---|---|---|---|---|---|---|---|
| Earned runs | 0 | 1 | 2 | 1 | 1 | 10 | 15 |
| Innings pitched | 9 | 6 | 7 | 8 | 7 | 4 | 41 |
Here is another revealing albeit hypothetical example. Suppose a pitcher tosses two nearly flawless eight inning starts, allowing one run in each start, followed by a terrible two-inning blow-up where he gives up eight runs. His averaged performance over the three games is a thoroughly mediocre five runs per nine innings, which translates to a WAR of about 0.0 when calculated using standard metrics. In contrast, it is clear that over the three starts his team will win, with near certainty, two out of three, which translates to a “real” WAR of about 0.8 in total. Our hypothetical pitcher, who is great in two out of three starts and terrible in every third, would accumulate more than eight WAR over a full season, constituting an all-time great season worthy of a Cy Young award.[10] In contrast, standard WAR metrics would suggest he be designated for assignment. What drives the difference? A poor performance can greatly affect the average, effectively allowing a single game to be “lost” more than once. Specifically, standard metrics allow the one blow-up game to count for two losses, resulting in 0 WAR. The example is somewhat extreme, but not that rare.[11]
1.4 Paper organization
These examples illustrate that calculating WAR as a function of pitcher performance averaged across games is wrong. Hence in Section 2 we devise Grid WAR, which estimates a starting pitcher’s WAR in each of his games. Grid WAR estimates the completely context-neutral win probability added above replacement at the point when a pitcher exits the game. Then in Section 3 we discuss our results. We find that averaging pitcher performance across games tends to, in general, undervalue mediocre and highly variable pitchers. This is because the convexity of GWAR diminishes the impact of games in which a pitcher allows many runs, and these pitchers have more of those games. We also find that Grid WAR has predictive value: past Grid WAR is more predictive than past FanGraphs WAR of future Grid WAR. This suggests that some pitchers’ game-by-game variance in performance is not just “bad luck” but a measurable characteristic. Finally, in Section 4 we conclude with a discussion. Notably, we compare the careers of starting pitchers via Grid WAR across baseball history. Although Grid WAR values many pitchers’ careers similarly as other metrics, it substantially changes our view of some pitchers who exhibit fundamental game-by-game variance. Sandy Koufax is a prime example: although his 1966 season is just the 20th best season of all time according to FanGraphs WAR, it is the best season of all time according to Grid WAR. Other methods incorrectly overweight his three outlying blow-up games.
2 Defining Grid WAR for starting pitchers
Our task is to estimate a starting pitcher’s WAR for an individual game, which we call Grid WAR (GWAR). The idea is to estimate a context-neutral version of win probability added derived only from a pitcher’s performance, invariant to factors outside of his control such as his team’s batting.[12] This is very different from the usual win-probability-added calculation, which is completely dependent on the starting pitcher’s team’s offense. In Section 2.1 we detail our mathematical formulation of Grid WAR. We give a brief overview of our data in Section 2.2, and then we discuss how we estimate the grid functions f and g (Sections 2.3 and 2.4), the constant w rep (Section 2.5), and the park effects α (Section 2.6) which allow us to compute a starting pitcher’s Grid WAR for a baseball game.
2.1 Grid WAR formulation
In baseball, each team’s starting pitcher is the first pitcher in the game for that team. A starter usually exits midway through a game according to the discretion of the field manager (the equivalent of a head coach in baseball). Generally a starter pitches for a significant portion of the game and sometimes pitches the entire game (known as a complete game). Often times, a starter is removed between innings.[13] We first define a starter’s Grid WAR for a game in which he exits at the end of an inning. To do so, we define the function f = f(I, R) which, assuming both teams have league-average offenses, computes the probability a team wins a game after giving up R runs through I innings (the values of f(I, R) for integer values of I and R can be displayed in a simple grid). In short, f is a context-neutral version of win probability, as it depends only on the starter’s performance.
Note that f also depends on the league (AL vs. NL), season, and ballpark. For example, games in which the home team is in the National League (NL) prior to 2022 did not feature designated hitters, whereas American League (AL) games did, leading to different run environments. Additionally, baseballs have different compositions across seasons, leading to different proportions of home runs and base hits, and hence different run environments. Finally, it is easier to score runs at some ballparks that at others. For instance, Coors Field at high altitude in Denver features many more home runs that other parks. Consequently, f = f(I, R) is implicitly a function of league, season, and ballpark.
To compute a wins above replacement metric, we need to compare this context-neutral win-contribution to that of a potential replacement-level pitcher. A replacement-level player is freely available to add to your team in the absence of the player being evaluated (e.g., a minor league free agent). We use a constant w rep which denotes the probability a team wins a game with a replacement-level starting pitcher, assuming both teams have league-average offenses. We expect w rep < 0.5 since replacement-level pitchers are worse than league-average pitchers. Then, we define a starter’s Grid WAR during a game in which he gives up R runs through I complete innings as
We call our metric Grid WAR because the function f = f(I, R) is defined on the 2D grid {1, …, 9} × {0, …, R max = 10}.
Next, we define a starting pitcher’s Grid WAR for a game in which he exits midway through an inning. In this case, a starter exits an inning having thrown a certain number of outs O ∈ {0, 1, 2} and having potentially left baserunners on first, second, or third base, encoded by the base-state
We define an auxiliary function g = g(r|S, O) which, assuming both teams have league-average offenses, computes the probability that, starting midway through an inning with O outs and base-state S, a team scores exactly r runs through the end of the inning. Given g, we define a starter’s Grid WAR during a game in which he gives up R runs and leaves midway through inning I with O outs and base-state S as the expected Grid WAR at the end of the inning,
Finally, we define a starting pitcher’s Grid WAR for an entire season as the sum of the Grid WAR of his individual games.
2.2 Our data
In the remainder of Section 2, we discuss how we estimate the grid functions f and g, the constant w rep, and the park effects α which allow us to compute a starting pitcher’s Grid WAR for a baseball game (Equations (2) and (3)). In our analysis we use play-by-play data from Retrosheet. We scraped every plate appearance from 1990 to 2020 from the Retrosheet database. For each plate appearance, we record the pitcher, batter, home team, away team, league, park, inning, runs allowed, base state, and outs count. Our final dataset is publicly available online.[14] In our study, we restrict our analysis to every plate appearance from 2010 to 2019 featuring a starting pitcher. Additionally, we scraped FanGraphs RA/9 WAR (abbreviated henceforth as FWAR (RA/9)) and FanGraphs FIP WAR (abbreviated henceforth as FWAR (FIP)) using the baseballr package (Petti and Gilani 2021). All computations in our analysis are performed in R, and our code is publicly available online.[15]
2.3 Estimating the grid function f
Now, we estimate the grid function f = f(I, R) which, assuming both teams have average offenses,[16] computes the probability a team wins a game after giving up R runs through I complete innings. We call f a grid because the values of f(I, R) for integer values of I and R can be displayed in a simple 2D grid. To account for different run environments across different seasons, leagues (NL vs. AL), and ballparks, it is imperative to estimate a different grid for each league-season-ballpark. Thus we estimate f using a parametric mathematical model rather than a statistical or machine learning model fit from historical data. Here, we give an overview as to why; see Appendix B for a more detailed discussion.
The naive solution to estimating f is the empirical grid: across all combinations of I and R, simply take the observed proportion of times a starter’s team won the game. Due to a lack of data, the empirical grid fit on all half-innings from any given league-season massively overfits. In particular, it fails to be monotonic in I or R even though it should be.[17] Thus any ballpark-adjusted empirical grid would also massively overfit. To force the grid to be monotonic, we try XGBoost with monotonic constraints. While the fitted f is monotonic and also convex in R as expected, it still overfits, especially towards the tails (e.g., for R large). Refitting the grid using a statistical model for each league-season is clearly not optimal.
As there is not enough data to use machine learning to fit a separate grid for each league-season without overfitting, we turn to a parametric mathematical model. Specifically, we use an Empirical Bayes Poisson model from which we explicitly compute context-neutral win probability. We find that our Poisson model is a powerful approximation technique, yielding reasonable grids for our application which vary across each league, season, and ballpark without overfitting. Indeed, by distilling the information of our dataset into just a few parameters, our Poisson model creates a strong model from limited data.
Because the runs allowed in a half-inning is a natural number, we begin our parametric modeling process by supposing that the runs allowed in a half-inning is a Poisson random variable. In particular, denoting the runs scored by the pitcher’s team’s batters in inning i by X i and the runs scored by the opposing team in inning i by Y i (for innings after the pitcher exits the game), we model
The two teams have their own runs per inning parameters λ X and λ Y because a baseball season involves teams of varying strength playing against each other. The assumption that runs scored in an inning is independent across innings given a team’s strength, while technically false due to non-stationarity across innings,[18] is justified by working. In particular, it yields a grid which looks like a smoothed, non-overfit version of the empirical and XGBoost grids, and so we deem it a reasonable enough assumption. In other words, we view the independence and Poisson assumptions as tools for creating flexible, non-overfit grids which vary across league, season, and ballpark.
Given the team strength parameters, the probability that a pitcher wins the game after allowing R runs through I innings, assuming win probability in overtime is 1/2, is
If I = 9, this is equal to
If I < 9, it is equal to
noting that the Skellam distribution arises as a difference of two independent Poisson random variables. To capture variability in team strength across each of the 30 MLB teams, we impose a positive normal prior,
We estimate the prior hyperparameters λ and
where
Additionally, recall that f = f(I, R) is implicitly a function of ballpark. To adjust for ballpark, we first define the park effect α of a ballpark as the expected runs allowed in one half-inning at that park above that of an average park, if an average offense faces an average defense. With our parametric model, the ballpark adjustment is easy: we simply incorporate the park effect into our Poisson parameters. With a statistical model, the ballpark adjustment is more difficult and prone to overfitting, providing yet another justification of our mathematical model. As λ represents the mean runs allowed in a half-inning for a given league-season, λ + α represents the mean runs allowed in a half-inning at a given ballpark during that league-season. So, to adjust for ballpark, we use λ + α in place of λ in our Poisson model (9) and positive Normal prior (8). In Section 2.6 we estimate the park effects α.
In Figure 1 we visualize the estimated grid f according to our Poisson model (9), with prior (8), using the 2019 NL λ and
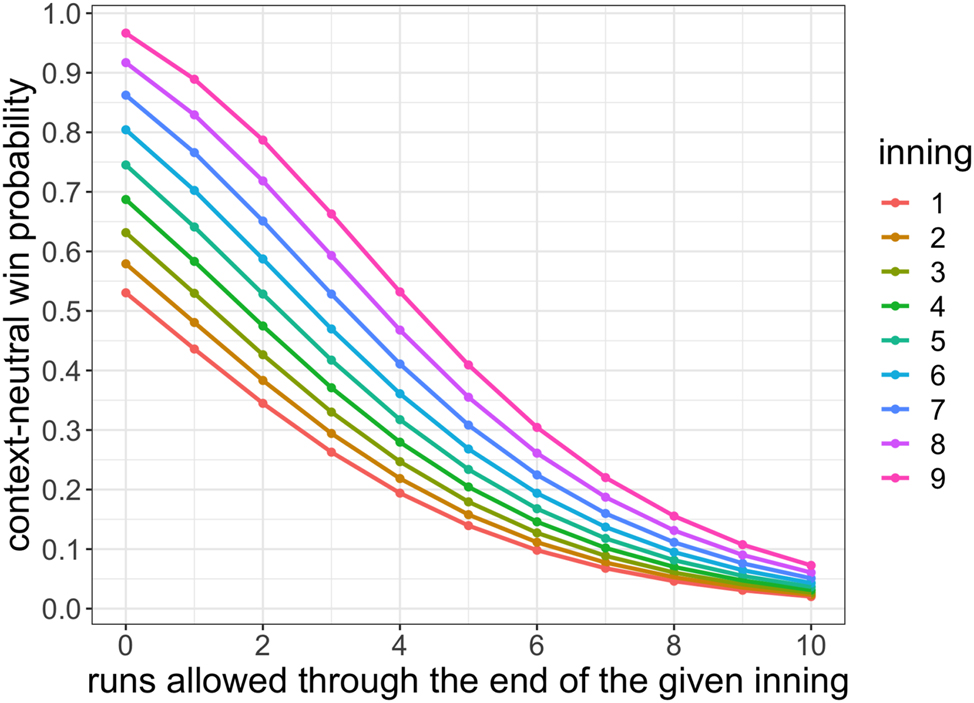
2.4 Estimating the grid function g
Now, we estimate the function g = g(r|S, O) which, assuming both teams have league-average offenses, computes the probability that, starting midway through an inning with O ∈ {0, 1, 2} outs and base-state
a team scores exactly r runs through the end of the inning. We estimate g(r|S, O) using the empirical distribution. Specifically, we bin and average over the variables (r, S, O), using data from every game from 2010 to 2019. Because g isn’t significantly different across innings, we use data from each of the first eight innings. In Figure 2 we visualize g(r|S, O = 0), with O = 0 outs, for each base-state S.

From base-state S (color) and O = 0 outs through the end of an inning, the context-neutral probability (y-axis) that the pitcher allows R runs (x-axis) according to the grid function g.
2.5 Estimating the constant w rep
To estimate wins above replacement, we need to compare a starting pitcher’s context-neutral win contribution to that of a potential replacement-level pitcher. Thus we estimate a constant w rep which represents the context-neutral probability a team wins a game with a replacement-level starting pitcher, assuming both teams have a league-average offense and league-average fielding. Fangraphs (2010) defines replacement-level as the “level of production you could get from a player that would cost you nothing but the league minimum salary to acquire.” We could estimate w rep in a given season by averaging the context neutral win probability at the point when the starter exits the game across all games featuring a replacement-level starting pitcher. To facilitate fair comparison of Grid WAR to FanGraphs WAR, we instead estimate w rep so as to match FanGraphs’ definition of replacement-level. In particular, we choose w rep = 0.428 so that the sum of GWAR across all starting pitchers from 2010 to 2019 equals the sum of FWAR (RA/9).
2.6 Estimating the park effects α
Finally, we estimate the park effect α of each ballpark, which measures the expected runs scored in one half-inning at that park above that of an average park, if an average offense faces an average defense. To compute the park effects for 2019, we take all half-innings from 2017 to 2019 and fit a ridge regression, using cross validation to tune the ridge hyperparameter, where the outcome is runs scored during the half-inning and the covariates are fixed effects for each park, team-offensive-season, and team-defensive-season. We compute similar three-year park effects for other seasons. We visualize the 2019 park effects in Figure 3. We use ridge regression, as opposed to ordinary least squares or existing park effects from ESPN, FanGraphs, or Baseball Reference, because, as detailed in Appendix D, it performs the best in two simulation studies and has the best out-of-sample predictive performance on observed data.

Our 2019 three-year park effects (x-axis), fit from half-inning data from 2017 to 2019, for each ballpark (y-axis). The abbreviations are retrosheet ballpark codes.
3 Results
After estimating the grid functions f and g, the constant w rep, and the park effects α, we compute Grid WAR for each starting pitcher in each game from 2010 to 2019. As a quick exposition, we show the full 2019 Grid WAR rankings (Figure 4) and a full game-by-game breakdown of Justin Verlander’s 2019 season (Figure 5). The remainder of this section is organized as follows. In Section 3.1 we compare GWAR to FanGraphs WAR (FWAR) in order to understand the effect of averaging pitcher performance over the entire season on valuing pitchers. We find that averaging over the season allows a pitcher’s terrible performances to dilute the contributions of his great ones. This is because the convexity of GWAR diminishes the impact of games in which a pitcher allows many runs, whereas averaging across games doesn’t. Thus traditional measures of WAR have generally undervalued mediocre pitchers and higher variance pitchers who tend to have more of these terrible games. Then in Section 3.2 we quantify the value lost by using FWAR to estimate pitcher quality rather than using GWAR. We find that pitcher rankings built from past GWAR are better than pitcher rankings built from past FWAR at predicting future pitcher rankings according to GWAR. This provides evidence that game-by-game variability in pitcher performance is a fundamental and measurable trait.
3.1 Averaging pitcher performance across games dilutes the contributions of his great games
In this section we compare GWAR to FanGraphs WAR (FWAR) in order to understand the effect of averaging pitcher performance over the entire season on valuing pitchers. We find that averaging over the season allows a pitcher’s terrible performances to dilute the contributions of his great ones. Note that to compare the relative value of starting pitchers according to GWAR relative to FWAR (RA/9), in this section we rescale GWAR in each year so that the sum of GWAR across all starters in each season equals the corresponding sum in FWAR (RA/9).
We begin with Figure 6, which visualizes GWAR versus FWAR (RA/9) for starting pitchers in 2019. Pitchers who lie above the line y = x are undervalued according to GWAR relative to FWAR and pitchers who lie below the line are overvalued. To understand why some players are undervalued and others are overvalued, we compare players who have similar FWAR but different GWAR values in 2019. In Figure 7 we compare Homer Bailey’s 2019 season to Tanner Roark’s. They have the same FWAR (RA/9), 2.7, but Bailey has a much higher GWAR (Bailey 3.43, Roark 2.48). Similarly, in Figure 8 we compare Mike Fiers’s 2019 season to Aaron Nola’s. They have the same FWAR (RA/9), 4.1, but Fiers has a higher GWAR (Fiers 5.25, Nola 4.2).

Ranking starting pitchers in 2019 by Grid WAR.

A game-by-game breakdown of Justin Verlander’s 2019 season.

Grid WAR (y-axis) versus FanGraphs WAR (RA/9) (x-axis) for each pitcher-season in 2019. The pitcher name refers to the dot on its immediate left.
In each of these comparisons, we see a similar trend explaining the differences in GWAR. The pitcher with higher GWAR allows fewer runs in more games and allows more runs in fewer games. This is depicted graphically in the “Difference” histograms, which show the difference between the histogram on the left and the histogram on the right. The green bars denote positive differences (i.e. the pitcher on the left has more games with a given number of runs allowed than the pitcher on the right) and the red bars denote negative differences (i.e. the pitcher on the left has fewer games with a given number of runs allowed than the pitcher on the right). In each of these examples, the green bars are shifted towards the left (pitchers with higher GWAR allow few runs in more games) and the red bars are shifted towards the right (pitchers with lower GWAR allow many runs in more games). In Figure 7, Bailey pitches four more games than Roark in which he allows two runs or fewer and Roark pitches four more games than Bailey in which he allows three runs or more. Similarly, in Figure 8, Fiers pitches four more games than Nola in which he allows zero runs and Nola pitches five more games than Fiers in which he allows one run or more. The convexity of GWAR diminishes the impact of games in which a pitcher allows many runs, explaining why Bailey has more GWAR than Roark and why Fiers has more GWAR than Nola.
Next, in Figure 9 we visualize GWAR versus FWAR (RA/9) for each starting pitcher-season across all years from 2010 to 2019. Pitchers who lie above the line y = x (the solid black line) are undervalued according to GWAR relative to FWAR and pitchers who lie below the line are overvalued. Worse pitchers generally lie above the line y = x (the solid black line), and so are undervalued, whereas better pitchers generally lie below the line. The regression line y = 0.47 + 0.85x (the blue dashed line), which has slope less than one, summarizes this phenomenon. This occurs because FWAR averages pitcher performance across an entire season, which dilutes the contributions of his good games. Since Grid WAR is (mostly) convex in runs allowed, GWAR downweights the contribution of the Rth run of a game for large R, whereas FWAR weighs all runs allowed in a season equally. Since worse pitchers have many more occurrences than better pitchers of allowing a large number of runs allowed in a game, FWAR (RA/9) undervalues worse pitchers in general. As we have constrained GWAR and FWAR to have the same sum, FWAR (RA/9) must therefore overvalue better pitchers in general.

Histogram of runs allowed in a game in 2019 for Homer Bailey (left), Tanner Roark (middle), and the difference between these two histograms (right). Even though they have the same FWAR, Bailey has a higher GWAR than Roark because he has more games in which he allows fewer runs.
In Figure 10 we show the six most undervalued and overvalued pitchers according to GWAR relative to FWAR (RA/9), aggregated across all seasons from 2010 to 2019. As expected, the undervalued pitchers are generally considered worse pitchers and the overvalued pitchers are generally considered better pitchers. In Figure 11 we visualize the runs allowed distribution of the most undervalued pitcher, Yovani Gallardo, in his three most undervalued seasons. Gallardo has many great games (say, zero or one run allowed) and many terrible games (say, six or more runs allowed). GWAR diminishes the impact of these terrible games and magnifies the impact of these great games, increasing his estimated contribution to winning.

Histogram of runs allowed in a game in 2019 for Mike Fiers (left), Aaron Nola (middle), and the difference between these two histograms (right). Even though they have the same FWAR, Fiers has a higher GWAR than Nola because he has more games in which he allows fewer runs.

Grid WAR (y-axis) versus FanGraphs WAR (RA/9) (x-axis) for each pitcher-season from 2010 to 2019. The solid black line is y = x and the dashed blue line is the regression line y = 0.47 + 0.85x. The slope of the regression line is less than 1, indicating that worse pitchers are generally undervalued and better pitchers are generally overvalued by FWAR (RA/9) relative to GWAR.
As averaging pitcher performance across games allows a pitcher’s worse performances to dilute his better performances, we also expect FanGraphs WAR to undervalue higher variance pitchers. We see this in Figure 12 in which we visualize the relationship between a pitcher’s variability in performance across games and the extent to which he is undervalued by FanGraphs WAR. For each starting pitcher-season from 2010 to 2019 consisting of at least 30 games, we plot the difference between his seasonal GWAR and FWAR (RA/9) against the game-by-game standard deviation of his GWAR. Higher variance pitchers indeed generally have higher GWAR than FWAR.

The six most undervalued (a) and overvalued (b) pitchers according to GWAR relative to FWAR (RA/9), aggregated across all seasons from 2010 to 2019. The undervalued pitchers are generally considered worse pitchers and the overvalued pitchers are generally considered better pitchers.
3.2 Grid WAR has predictive value
Recall that it is wrong to average pitcher performance across games in estimating a starting pitcher’s WAR. This is why we devised Grid WAR, which estimates WAR on a per-game basis and is the right way to estimate historical WAR for starting pitchers. Nonetheless, it is possible a priori that averaging provides a stabler estimate of pitcher quality which is more predictive of future WAR. In particular, if game-by-game variability in pitcher performance is due mostly to chance, accounting for these variations introduces noise into estimates of pitcher quality.
Because a pitcher’s historical WAR at the end of a season defines how valuable he was during the season, we want a predictive pitcher quality measure to predict his next season’s historical WAR as best as possible. In other words, pitcher quality is simply predicted future historical WAR. Hence our goal is to predict a starting pitcher’s future Grid WAR. A priori, it is not immediately obvious whether a pitcher’s past Grid WAR is predictive of his future Grid WAR. In particular, if a pitcher’s game-by-game variance in runs allowed is due mostly to randomness rather than a fundamental identifiable trait, a WAR which averages pitcher performance over the season may be more predictive than Grid WAR of future Grid WAR. Thus, in this section, we compare the predictive capabilities of Grid WAR and FanGraphs WAR. We find that, in predicting future pitcher rankings according to Grid WAR, our predicted pitcher ranking built from Grid WAR is more predictive than that built from FanGraphs WAR. This suggests that some pitchers’ game-by-game variance in performance is a fundamental trait.
To value a starting pitcher using his previous seasons’ WAR and number of games played, we could simply use his mean game WAR. The fewer games a pitcher has played, however, the less reliable his mean game WAR is in predicting his latent pitcher quality. Therefore, we use shrinkage estimation to construct a pitcher quality metric. In calculating pitcher p’s quality estimate
Recall that our goal is to predict each starting pitcher’s next season’s cumulative Grid WAR, which at the end of next season will represent his historical value added. So, using the 2019 season as a hold-out validation set, our goal is to predict each starting pitcher’s 2019 Grid WAR. We use our remaining data from 2010 to 2018 to estimate pitcher quality, built separately from GWAR and FWAR, in order to predict 2019 Grid WAR. Thus we restrict our analysis to the set of starting pitchers who have a FanGraphs’ WAR in at least one season from 2010 to 2018 (so, they must have at least 25 starts in that season). Our pitcher quality estimators, however, are on different scales since each WAR metric is on its own scale. To ensure fair comparison of Grid WAR and FanGraphs WAR, we map each estimator to a starting pitcher ranking, ranking each pitcher from one (best) to the number of pitchers (worst). We denote the three ranks of pitcher p according to
The rmse of the observed pitcher ranking R
GWAR in 2019 and three pitcher ranking estimates
| Symbol | Observed ranking R | Predicted ranking
|
|
|---|---|---|---|
| A | R GWAR |
|
10.2 |
| B | R GWAR |
|
12.4 |
| C | R GWAR |
|
13.1 |
In Tables 3 and 4 we conduct a similar analysis, but restricting the test set to just the five most undervalued starting pitchers in 2019 according to
The rmse of the observed pitcher ranking R
GWAR in 2019 and pitcher ranking estimates
| Observed ranking R | Predicted ranking
|
|
|---|---|---|
| R GWAR |
|
7.2 |
| R GWAR |
|
15.7 |
The rmse of the observed pitcher ranking R
GWAR in 2019 and pitcher ranking estimates
| Observed ranking R | Predicted ranking
|
|
|---|---|---|
| R GWAR |
|
5.1 |
| R GWAR |
|
15.0 |
The rmse of the observed pitcher ranking R
GWAR in 2019 and pitcher ranking estimates
| Observed ranking R | Predicted ranking
|
|
|---|---|---|
| R GWAR |
|
10.7 |
| R GWAR |
|
14.0 |
The rmse of the observed pitcher ranking R
GWAR in 2019 and pitcher ranking estimates
| Observed ranking R | Predicted ranking
|
|
|---|---|---|
| R GWAR |
|
10.2 |
| R GWAR |
|
18.0 |

Histogram of Yovani Gallardo’s runs allowed in each game across three seasons. Gallardo has many great and terrible games. Traditional WAR metrics allow his terrible performances to dilute his great ones.
Further, in Figure 14 we visualize the variability of Grid WAR and FanGraphs WAR from season to season. For each pitcher-season from 2011 to 2019, we plot a pitcher’s seasonal WAR against his previous season’s WAR. We see that FWAR (FIP) is more stable from season to season than GWAR and FWAR (RA/9), which have similar levels of season-to-season variability. This makes sense: runs allowed, from which GWAR and FWAR (RA/9) are constructed, is inherently more noisy than FIP, which doesn’t account for balls in play. Having greater stability across seasons, however, does not mean that FWAR (FIP) is a better pitcher valuation metric than GWAR. As shown previously in this section, an estimate of latent pitcher quality built from GWAR is more predictive of future GWAR than estimates built from FWAR (FIP) and FWAR (RA/9). Predictiveness of future Grid WAR is a more important quality than year-to-year stability, as a general manager should want to acquire a starting pitcher who will have more Grid WAR in future seasons.

For each starting pitcher-season from 2010 to 2019 consisting of at least 30 games, the difference between his seasonal GWAR and FWAR (RA/9) (y-axis) versus the game-by-game standard deviation of his GWAR (x-axis). Higher variance pitchers are undervalued by FWAR (RA/9) because they allow a pitcher’s worse performances to dilute his better performances.
So, a game-by-game measure of WAR like Grid WAR is not only the right way to measure historical WAR for starting pitchers, but is also predictive of future Grid WAR. In particular, an estimator of latent pitcher talent should be built using Grid WAR or some other game-by-game metric. Now that we have such an estimator of pitcher talent at our disposal, we explore the relationship between a pitcher’s talent according to
In Figure 15 we provide a sense of the distribution of pitcher talent

Visualizing the observed pitcher rankings R
GWAR in 2019 and pitcher ranking estimates

For each pitcher-season from 2011 to 2019, a pitcher’s seasonal WAR (y-axis) versus his previous season’s WAR (x-axis). FWAR (FIP) is more stable from year to year than GWAR or FWAR (RA/9), which have similar levels of season-to-season variability.
Averaging pitcher performance over the season allows a pitcher’s bad performances to dilute the value of his good ones. Consequently, such WAR metrics like FanGraphs WAR devalue the contributions of mediocre and bad pitchers, who have many more bad games than great pitchers. In short, the baseball community has been undervaluing the contributions of the mediocre.

Distribution of estimated pitcher talent

All pitchers have terrible games, but great pitchers have fewer of them. (a) Shows the distribution of game-by-game Grid WAR conditional on being a bad pitcher (red), a typical pitcher (green), and a great pitcher (blue), according to
4 Discussion
Traditional implementations of WAR for starting pitchers estimate WAR as a function of pitcher performance averaged over the entire season. Averaging pitcher performance, however, allows a pitcher’s bad games to dilute the performances of his good games. One bad “blow-up” game after averaging can reduce a pitcher’s WAR by more than minimum possible WAR in a game. Therefore, a starters’ seasonal WAR should be the sum of the WAR of each of his individual games. Hence we devise Grid WAR, which estimates a starting pitcher’s WAR in each of his games. Grid WAR estimates the context-neutral win probability added above replacement at the point when a pitcher exits the game. Grid WAR is convex in runs allowed, capturing the fundamental baseball principle that you can only lose a game once.
Comparing starting pitchers’ Grid WAR to his FanGraphs WAR from 2010 to 2019, we find that standard WAR calculations undervalue mediocrity and variability relative to Grid WAR. Because all starters pitch great games, but great starters don’t pitch many terrible games, averaging pitcher performance over a season discounts the contributions of great games by mediocre and bad pitchers. We also show that past performance according to Grid WAR is predictive of future Grid WAR, providing evidence that a pitcher’s runs allowed profile is not entirely random, but is the result of an identifiable game-by-game variation.
To compare starting pitchers across baseball history through the lens of Grid WAR, we created an interactive Shiny app,[19] hosted at https://gridwar.xyz, which displays the Grid WAR results of every starting pitcher game, season, and career since 1952. For many starters, Grid WAR is similar to FanGraphs WAR.[20] Grid WAR, however, looks much more favorably upon the careers of some starters with intrinsic game-by-game variance (that is, the occasional tendency to pitch an awful game).[21] There are many starters that have substantial differences including Whitey Ford and Catfish Hunter. Whitey Ford (resp., Catfish Hunter) has a whopping 25 (resp., 15) more career GWAR than FWAR! Ford is the 49th best starter since 1952 according to FanGraphs (53 FWAR) but is the 19th best according to Grid WAR (78 GWAR). Similarly, Hunter is the 107th best starter since 1952 according to FanGraphs (37 FWAR) but is the 32nd best according to Grid WAR (52 GWAR). What drives this difference? Ford and Hunter are extreme boom-bust pitchers. Standard WAR, from either FanGraphs and Baseball Reference, average pitcher performance across games, allowing these pitchers’ many blow-up games to dilute their great performances which accumulate into huge discrepancies across careers, significantly devaluing them relative to other starters. To understand the fundamental game-by-game variance of these pitchers, consider Ford’s 1961 season and Hunter’s 1967 season. In 1961 Ford (7.2 GWAR) started 39 games with six complete game shutouts accompanied by seven blow-up games (lower than −0.1 GWAR). Similarly, in 1967 Hunter (4.5 GWAR) started 35 games with five complete game shutouts and four one-run complete games accompanied by eight blow-up games (lower than −0.1 GWAR). Grid WAR, which correctly values pitcher performance in each individual game, sees the value of pitchers having such strong variability across games. The public agrees with us: Catfish Hunter made the Hall-of-Fame (despite having just the 107th best career according to FanGraphs) and Whitey Ford won a Cy Young award in 1961. We continue our discussion of Grid WAR across baseball history in Appendix E.
While we focus in this paper on developing WAR for starting pitchers, some of the principles we discussed should be used to estimate WAR for relief pitchers, opening pitchers, and batters and some should not. The primary difference between valuing starting and relief pitchers is that opposing batter context matters for valuing the latter but not the former. A relief pitcher who pitches the ninth inning up or down, say, three runs only marginally impacts the game, as its outcome has essentially already been decided. Conversely, a relief pitcher who pitches the ninth inning up or down, say, one run hugely impacts the game. Grid WAR for starting pitchers, as developed in this paper, doesn’t account for opposing batter context and so is not appropriate to value relief pitchers. Nonetheless, due to the massive variability in leverage for relief pitchers across games, relief pitcher WAR should be estimated separately for each game. Perhaps we should construct relief pitcher game WAR using a context-neutral version of win probability added that adjusts for score differential at the time the relief pitcher enters the game.
Opening pitchers are starting pitchers, so we can use Grid WAR to estimate their value. Grid WAR provides a strong justification for the use of an opener. For concreteness, suppose you are the manager of the 2023 Padres, featuring closer Josh Hader who had a 1.28 ERA through 56 innings in 61 games. For simplicity, suppose Hader pitched for exactly one inning, the ninth inning, in each of 56 games, resulting in 1.7 FanGraphs WAR.[22] Now suppose he had instead pitched just the first inning in 56 games with that ERA, allowing an average of about 0.14 runs per inning, or 0 runs in 86 % of innings and 1 run in 14 % of innings. His average context neutral win probability per game would be about
taking these values of f from Figure 1, resulting in
seasonal Grid WAR. Our preliminary analysis suggests that Hader would be much more valuable as an opener than as a closer. What drives the difference? Closers aren’t that valuable because many of the games they pitch in are low leverage situations in which the outcome of the game has essentially already been decided. Conversely, the performance of an opening pitcher always matters. Allowing few runs through the first inning is very valuable since those innings always impact the outcome of the game. Of course, our initial analysis is overly simplistic and is intended to be just an impetus for further research. A closing pitcher’s dominant ERA doesn’t necessarily extrapolate to the first inning because, for instance, in each first inning but not necessarily in each ninth inning, a pitcher faces the opposing team’s best batters. A more thorough analysis would also need to account for the following telescoping phenomenon: if we moved the closing pitcher to the opening pitcher position, the setup man would become the closer and the middle relief pitcher would become the setup man; but, we expect the resulting potential loss of WAR to be much smaller than the positive gain in WAR from switching the closer to the opener position. Finally, if many teams used an opening pitcher, replacement-level w rep for openers may change.
Game-by-game WAR, on the other hand, doesn’t make sense for batters. This largely stems from the fact that each individual batter has just three to five plate appearances in a typical nine-inning game. A batter doesn’t influence any individual game enough for the non-convexity of game-level WAR to meaningfully change his valuation over the course of a season. Also, these aren’t enough plate appearances to allow strong evidence of fundamental variance in batter performance across games to appear in the data. Finally, in each game the starting pitcher is responsible for the vast majority of his team’s (defensive) context (until he is pulled), which is not true for any individual batter. Having said that, in estimating seasonal batter WAR, batter performance should still be adjusted for opposing pitcher quality and park.
Although Grid WAR improves substantially upon existing estimates of WAR for starting pitchers, our analysis is not without limitations. In particular, the version of Grid WAR described in this paper, as well WAR estimates from FanGraphs and Baseball Reference, doesn’t adjust for opposing batter quality. Thus, for a pitcher who faces good offensive teams more often than other pitchers do, Grid WAR underestimates his WAR. In our updated version of Grid WAR at gridwar.xyz, we adjust for opposing batter quality via GWAR+ (details are included on the website). Additionally, the current version of Grid WAR doesn’t adjust for the pitcher’s team’s fielding. Thus, for a pitcher who plays with great fielders who reduce his runs allowed, Grid WAR overestimates his WAR. Nonetheless, we expect these adjustments to have a very small impact. In particular, we expect the effect of fielding to have a smaller total impact than ballpark, which itself has a small impact, except at extreme parks like Coors Field. This can be seen in Figure 27: Grid WAR computed with our ridge-adjusted park effects is extremely similar to Grid WAR without park effects. We leave the addition of batting and fielding adjustments to future work.
Moreover, the distribution of runs scored in a half-inning is not Poisson; more likely it is a zero-inflated Poisson, a more general Conway-Maxwell-Poisson, or a similar distribution on the non-negative integers. Computationally, it is straightforward to modify the f grid formula (Equation (5)) to accommodate different distributions. One interesting modification would adjust to allow different parameters for each inning depending on when a starting pitcher is pulled. In particular, middle relievers tend to be worse than starting pitchers, suggesting a higher value of λ for those innings, and closers are often very good pitchers, suggesting a lower value of λ. But there are several substantial benefits to sticking with a simpler Poisson model. First, it produces a closed-form formula which is quick to evaluate. Second, a simple parametric model makes it easier to adjust for ballpark (and other confounders like batting quality and fielding quality). Finally, the resulting f grid is reasonable and quite accurate for our purposes. For example, while the Poisson model systematically underestimates the probability of big-deficit late inning comeback, these differences have an insignificant impact on Grid WAR. We leave any adjustment to the half-inning runs distribution as future work.
Finally, there is a flaw in our Empirical Bayes shrinkage estimator of latent pitcher quality μ p . Formula (20) assumes that μ p remains constant over the entire decade from 2010 to 2019, but player quality is non-stationary over time, and a more elaborate estimator should account for this. In future work we suggest using a similar Empirical Bayes approach to estimate pitcher quality, with weights that decay further back in time (e.g., using exponential decay weighting as in Medvedovsky and Patton 2022) in the posterior mean Formulas (20) and (32).
Acknowledgments
The authors thank Eric Babitz and Sam Bauman, who first calculated Grid WAR for starting pitchers and created the name Grid WAR, and Justin Lipitz, Emma Segerman, and Ezra Troy, who contributed to an early version of this paper.
-
Research ethics: Not applicable.
-
Author contributions: The authors have accepted responsibility for the entire content of this manuscript and approved its submission.
-
Competing interests: The authors state no conflict of interest.
-
Research funding: None declared.
-
Data availability: There is a link to the data in the paper and the raw data can be obtained on request from the corresponding author.
Appendix A: A review of the rules of baseball
In a baseball game, two teams of nine players each take turns on offense (batting and baserunning) and defense (fielding and pitching). The game occurs as a sequence of plays, with each play beginning when the pitcher throws a ball that a batter tries to hit with a bat. The objective of the offensive team (batting team) is to hit the ball into the field of play, away from the other team’s players, in order to get on base. The goal of a baserunner is to eventually advance counter-clockwise around all four bases to score a “run”, which occurs when he touches home plate (the position where the batter initially began batting). The defensive team tries to prevent batters from reaching base and scoring runs by getting batters or baserunners “out”, which forces them out of the field of play. The pitcher can get the batter out by throwing three pitches which result in “strikes”. Fielders can get the batter out by catching a batted ball before it touches the ground, and can get a runner out by tagging them with the ball while the runner is not touching a base. The batting team’s turn to bat is over once the defensive team records three outs. The two teams switch back and forth between batting and fielding; one turn batting for each team constitutes an inning. A game is usually composed of nine innings, and the team with the greater number of runs at the end of the game wins. Most games end after the ninth inning, but if scores are tied at that point, extra innings are played (Wikipedia 2023).
Appendix B: Estimating f using a mathematical, not a statistical, model
In this section, we detail our modeling process for estimating the grid function f = f(I, R) which, assuming both teams have randomly drawn offenses, computes the probability a team wins a game after giving up R runs through I complete innings. In particular, we compare statistical models fit from observational data to mathematical probability models, which are superior.
To account for different run environments across different seasons and leagues (NL vs. AL), we estimate a different grid for each league-season. We begin by estimating f from our observational dataset of half-innings from 2010 to 2019. The response variable is a binary indicator denoting whether the pitcher’s team won the game, and the features are the inning number I, the runs allowed through that half-inning R, the league, and the season. Note that if a home team leads after the top of the 9th inning, then the bottom of the 9th is not played. Therefore, to avoid selection bias, we exclude all 9th inning instances in which a pitcher pitches at home.
With enough data, the empirical grid (e.g., binning and averaging over all combinations of I and R within a league-season) is a great estimator of f. In Figure 17a we visualize the empirical grid fit on a dataset of all half-innings from 2019 in which the home team is in the National League. The function f should be monotonic decreasing in R. In particular, as a pitcher allows more runs through a fixed number of innings, his team is less likely to win the game. It should also be monotonic increasing in I because giving up R runs through I innings is worse than giving up R runs through I + i innings for i > 0, since giving up R runs through I + i innings implies a pitcher gave up no more than R runs through I innings. The empirical grid, however, is not monotonic in either R or I because each league-season dataset is not large enough. Moreover, even when we use our entire dataset of all half-innings from 2010 to 2019, the empirical grid is still not monotonic in R or I.

Estimates of the 2019 National League function R ↦ f(I, R) using the empirical grid (a) and XGBoost with monotonic constraints (b).
To force our fitted f to be monotonic, we use XGBoost with monotonic constraints, tuned using cross validation (Chen and Guestrin 2016). We visualize our 2019 NL XGBoost fit in Figure 17b. We indeed see that the fitted f is decreasing in R and increasing in I. Additionally, R ↦ f(I, R) is mostly convex: if a pitcher has already allowed a high number of runs, there is a lesser relative impact of throwing an additional run on winning the game. Nonetheless, XGBoost overfits, especially towards the tails (e.g., for R large). For instance, the 2019 NL XGBoost model indicates that the probability of winning a game after allowing 10 runs through 9 innings is about 0.11, which is too large.
As there is not enough data to use machine learning to fit a separate grid for each league-season without overfitting, we turn to a parametric mathematical model. Indeed, the power of parameterization is that it distills the information of a dataset into a concise form (e.g., into a few parameters), allowing us create a strong model from limited data. Because the runs allowed in a half-inning is a natural number, we begin our parametric quest by supposing that the runs allowed in a half-inning is a Poisson(λ) random variable. In particular, denoting the runs allowed by the pitcher’s team’s batters in inning i by X i and the runs allowed by the opposing team in inning i (for innings i after the pitcher exits the game), we assume
Then the probability that a pitcher wins the game after allowing R runs through I innings, assuming win probability in overtime is 1/2, is
If I = 9, this is equal to
If I < 9, it is equal to
noting that the Skellam distribution arises as a difference of two independent Poisson distributed random variables. Then, we estimate λ separately for each league-season by computing each team’s mean runs allowed in each half inning, and then averaging over all teams.
In Figure 18a we visualize the estimated f according to our Poisson model (11) using the 2019 NL λ. We see that f is decreasing in R, increasing in I, convex in the tails of R, and is smooth. Nonetheless, some of the win probability values from this model are unrealistic. For instance, it implies the probability of winning the game after shutting out the opposing team through 9 innings is about 99 %, which is too high, and the probability of winning the game after allowing 10 runs through 9 innings is about 1 %, which is too low.
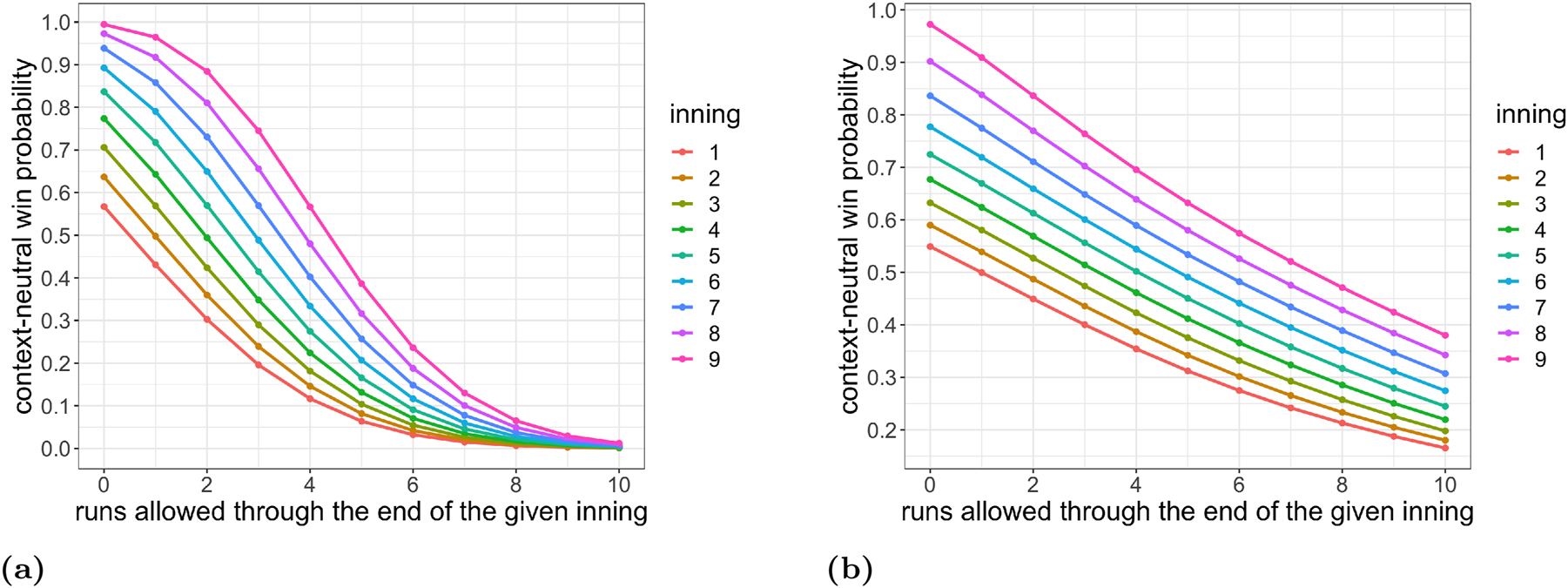
The win probability values at both tails of R are too extreme in our original Poisson model (11) because we assume both teams have the same mean runs per inning λ. This is an unrealistic assumption: in real life, a baseball season involves teams of varying strength playing against each other. When teams of differing batting strength play each other, win probabilities differ. For instance, a great hitting team down seven runs has a larger probability of coming back to win the game than a worse hitting team would. Thus, accounting for random differences in team strength across games should flatten the f(I, R) grid.
On this view, it is more realistic to assume the pitcher’s team and the opposing team have their own runs scored per inning parameters,
and
Moreover, to capture the variability in team strength across each of the 30 MLB teams, we impose a positive normal prior,
We estimate the prior hyperparameters λ and σ λ separately for each league-season by computing each team’s mean and s.d. of the runs allowed in each half inning, respectively, and then averaging over all teams.
Given λ X and λ Y , we compute Formula (15) similarly as before using the Poisson and Skellam distributions. We use Monte Carlo integration with B = 100 samples to estimate the posterior mean grid,
where
In Figure 18b we visualize the estimated f according to this Poisson model (17), with prior (16), using the 2019 NL λ and
To resolve the overdispersion issue, we introduce a tuning parameter k designed to tune the dispersion across team strengths to match observed data,
In particular, we use k = 0.28, which minimizes the log-loss between the observed win/loss column and predictions from the induced grid

Appendix C: Estimating pitcher quality using Empirical Bayes
In this section, we describe how we estimate pitcher quality. Given enough data, a pitcher’s mean game WAR would suffice to capture his quality. In the MLB, however, a pitcher starts just a finite number of games per season, so for many pitchers there is not enough data to use just his mean game WAR to represent his quality. Therefore, in this section we use a parametric Empirical Bayes approach in the spirit of Brown (2008) to devise shrinkage estimators
C.1 Empirical Bayes estimator of pitcher quality built from Grid WAR
To begin, index each starting pitcher by
In this model, μ
p
represents pitcher p’s unobservable “true” pitcher quality, or his latent underlying mean game Grid WAR. Similarly,

For four starting pitchers p, the distribution of his game-level GWAR {X pg } from 2010 to 2018.
We estimate pitcher p’s pitcher quality μ p using the posterior mean, which as a result of our normal-normal conjugate model (19) is
The posterior mean is a weighted sum between the observed total Grid WAR and the overall mean pitcher quality, weighted by the variances
Estimator (20), however, is defined in terms of unknown parameters μ, τ
2, and
We being finding the MLE by noting the marginal distribution of X pg according to model (19),
Thus the likelihood of pitcher p’s data {X pg : 1 ≤ g ≤ N p } is
Therefore the log-likelihood of the full dataset
To find the MLE of μ, we set the derivative of the log-likelihood with respect to μ equal to 0 and solve for μ,
which yields
We use a similar approach to find the MLE of τ
2 and
or equivalently
Additionally, for each pitcher p,
or equivalently
This process yields
Algorithm 1.
Compute the MLE of
| 1: Input: Grid
|
| 2: Initialization: |
| 3:
|
| 4:
|
| 5:
|
| 6: t = 1 |
| 7: while TRUE do |
| 8: Step 1. Solve for μ and save the result as μ(t):
|
| 9: Step 2. Solve for τ
2 (e.g., using a root finder) and save the result as τ
2(t): |
| 10: for p = 1 to
|
| 11: Step 3. Solve for
|
| 12: end for |
| 13: if |μ(t) − μ(t − 1)| < ϵ, |τ
2(t) − τ
2(t − 1)| < ϵ, and
|
| 14: break the while loop |
| 15: else |
| 16: t = t + 1 |
| 17: end if |
| 18: end while |
| 19: Output:
|
Using our dataset of all starting pitchers from 2010 to 2018,[23] we run Algorithm 1, yielding maximum likelihood estimators of μ, τ
2, and
In Figure 22 we visualize starting pitcher rankings prior to the 2019 season according to

For starting pitchers p from 2010 to 2018, his mean game GWAR versus his Empirical Bayes estimator

Pitcher quality estimates
C.2 Empirical Bayes estimator of pitcher quality built from FanGraphs WAR
Our estimator
To begin, again index each starting pitcher by
As before, we use model (19), which implies
Therefore the posterior mean of pitcher p’s latent pitcher quality μ p is
This estimator is analogous to that from Equation (20), using FWAR instead of GWAR.
As before, we use a parametric Empirical Bayes approach to estimate each starting pitcher’s latent quality from his FanGraphs WAR. In particular, we compute maximum likelihood estimates for μ, τ
2, and
Thus the log-likelihood of the full FanGraphs dataset {X p } is proportional to
Setting the derivative of the log-likelihood with respect to μ (resp., τ 2) equal to 0 and solving for μ (resp., τ 2) yields the following equations,
and
So, in designing an iterative algorithm analogous to Algorithm 1 but for FanGraphs WAR, we replace Equations (25) (Step 1) and (27) (Step 2) with Equations (35) and (36).
Setting the derivative of the log-likelihood with respect to
Algorithm 2.
Compute the MLE of
| 1: procedure 1 |
| 2: Input: FanGraphs
|
| 3: Initialization: |
| 4:
|
| 5:
|
| 6: t = 1 |
| 7: while TRUE do |
| 8: Step 1. Solve for μ and save the result as μ(t): |
| 9: Step 2. Solve for τ
2 (e.g., using a root finder) and save the result as τ
2(t):
|
| 10: if |μ(t) − μ(t − 1)| < ϵ and |τ 2(t) − τ 2(t − 1)| < ϵ then |
| 11: break the while loop |
| 12: else |
| 13: t = t + 1 |
| 14: end if |
| 15: end while |
| 16: Output:
|
| 17: end procedure |
| 18: |
| 19: procedure 2 |
| 20: Input: FanGraphs
|
| 21: Initialization: |
| 22: Split {X
p
} into a training set
|
| 23: In particular,
|
| 24: Sigmas = vector of smartly chosen positive values |
| 25: Losses = empty vector |
| 26: for σ 2 in Sigmas do |
| 27: Step 1. Run Procedure 1 with inputs
|
| 28: Step 2. Use
|
| 29: Step 3. Append
|
| 30: end for |
| 31: Output:
|
| 32: end procedure |
Using the same dataset of starting pitchers from 2010 to 2018 as before, we run Algorithm 2, yielding maximum likelihood estimators of μ and τ
2 and an estimate of
A weakness of our Empirical Bayes approach is that it assumes latent pitcher quality μ p is constant over the decade from 2010 to 2019. Player quality is, however, non-stationary over time. Therefore, in future work we suggest using a similar Empirical Bayes approach to estimate pitcher quality, except downweighting data further back in time (e.g., using exponential decay weighting as in Medvedovsky and Patton 2022) in the posterior mean Formulas (20) and (32).
In Figure 22 we visualize starting pitcher rankings prior to the 2019 season according to

For starting pitchers p from 2010 to 2018, his mean game FWAR versus his Empirical Bayes estimator
Appendix D: Estimating the park effects α
In this section, we detail why we use ridge regression to estimate park effects. First, in Section D.1, we discuss existing park factors from ESPN, FanGraphs, and Baseball Reference. Then, in Section D.2, we discuss problems with these existing park effects. In Section D.3, we introduce our park effects model, designed to yield park effects which represent the expected runs scored in a half-inning at a ballpark above that of an average park, if an average offense faces an average defense. Then, in Sections D.4 and D.5, we conduct two simulation studies which show that ridge repression works better than other methods at estimating park effects. Then, in Section D.6, we show that our ridge park effects have better out-of-sample predictive performance than existing park effects from ESPN and FanGraphs. Finally, in Sections D.7 and 2.6, we discuss our final ridge park effects, fit on data from all half-innings from 2017 to 2019.
D.1 Existing park effects
FanGraphs, Baseball Reference, and ESPN each have runs-based park factors, which are all variations of a common formula: the ratio of runs per game at home to runs per game on the road. In particular, ESPN’s park factors are an unadjusted version of this formula (ESPN 2022),
FanGraphs modifies this formula by imposing a form of regression onto the park factors (Appelman 2016). In particular, the FanGraphs park factors α FanGraphs are computed via
where w is a regression weight determined by the number of years in the dataset (e.g., for a three year park factor, w = 0.8).
Finally, Baseball Reference’s park factors are a long series of adjustments on top of ESPN’s park factors, computed separately for batters and pitchers (Baseball Reference 2022). In particular, Baseball Reference begins with
for batters and
for pitchers as base park factors. Then, they apply several adjustments on top of these base values. For instance, they adjust for the quality of the home team and the fact that the batter doesn’t face its own pitchers. These adjustments, however, are a long series of convoluted calculations, so we do not repeat them here.
D.2 Problems with existing park effects
There are several problems with these existing runs-based park effects. First, ESPN and FanGraphs do not adjust for offensive and defensive quality at all, and Baseball Reference adjusts for only a fraction of team quality. It is important to adjust for team quality in order to de-bias the park factors. For example, the Colorado Rockies play in the NL West, a division with good offensive teams such as the Dodgers, Giants, and Padres. So, by ignoring offensive quality in creating park factors, the Rockies’ park factor may be an overestimate, since many of the runs scored at their park may be due to the offensive power of the NL West rather than the park itself. By ignoring team quality, the ESPN and FanGraphs park factors are biased. Baseball Reference’s park factors adjust for the fact that a team doesn’t face its own pitchers, albeit through a convoluted series of ad-hoc calculations. Although adjusting for not facing one’s own pitchers slightly de-biases the park factors, it does not suffice as a full adjustment of the offensive and defensive quality of a team’s schedule.
Second, these existing runs-based park effects do not come from a statistical model. This makes it more difficult to quantitatively measure which park factors are the “best”, for instance via some loss function. In other words, it is more difficult to quantitatively know that Baseball Reference’s park factors are actually more accurate than FanGraphs’, in some mathematical sense, besides that it claims to adjust for some biases in its derivation, although we discuss a way to do so in Section D.6. Another benefit of a statistical model is that it will allow us to adjust for the offensive and defensive quality of a team and its opponents simultaneously. Finally, a statistical model will give us a firm physical interpretation of the park factors.
Hence, in this paper, we create our own park factors, which are the fitted coefficients of a statistical model that adjusts for team offensive and defensive quality.
D.3 Our park effects model
In this section, we introduce our park effects model, designed to yield park effects which represent the expected runs scored in a half-inning at a ballpark above that of an average park, if an average offense faces an average defense.
We index each half-inning in our dataset by i, each park by j, and each team-season by k. We define the park matrix P so that P ij is 1 if the ith half-inning is played in park j, and 0 otherwise. Similarly, we define the offense matrix O so that O ik is 1 if the kth team-season is on offense during the ith half-inning, and 0 otherwise, and define the defense matrix D so that D ik is 1 if the kth team-season is on defense during the ith half-inning, and 0 otherwise. We denote the runs scored during the ith half-inning by y i . Then, we model y i using a linear model,
where ϵ i is mean-zero noise,
Succinctly, we model
where
and
The coefficients are fitted relative to the first park ANA (the Anaheim Angels) and relative to the first team-season ANA2017 (the Angels in 2017). By including distinct coefficients for each offensive-team-season and each defensive-team-season, we adjust for offensive and defensive quality simultaneously in fitting our park factors. Finally, in order to make our park effects represent the expected runs scored in a half-inning at a ballpark above that of an average park, we subtract the mean park effect from each park effect,
D.4 First simulation study
We have a park effects model, Formula (41), but it is not immediately obvious which algorithm we should use to fit the model. In particular, due to multicollinearity in the observed data matrix X, ordinary least squares is sub-optimal. Hence we run a simulation study in order to test various methods of fitting model (41), using the method which best recovers the “true” simulated park effects as the park factor algorithm to be used in computing Grid WAR: ridge regression.
Simulation setup. In our first simulation study, we assume that the park, team offensive quality, and team defensive quality coefficients are independent. Specifically, we simulate 25 “true” parameter vectors
Then, we assemble our data matrix X to consist of every half-inning from 2017 to 2019. Then, we simulate 25 “true” outcome vectors
We use a truncated normal distribution, denoted by
Our goal is to recover the park effects β
(park), so our evaluation metric of an estimator
Note that it doesn’t make sense to compare the existing ESPN and FanGraphs park factors to park effects methods based on model (41) as part of this simulation study because they are not based on model (41). In fact, ESPN and FanGraphs park effects are not based on any statistical model. Rather, in Section D.6, we separately compare these existing park factors to our model-based park factors.
Method 1: OLS without adjusting for team quality. The naive method of estimating the park factors β (park) is ordinary least squares regression while ignoring team offensive quality and team defensive quality, as done in Baumer et al. (2015, Formula 11). In other words, fit the park coefficients using OLS on the following model,
In failing to adjust for offensive and defensive quality, we expect this algorithm to perform poorly.
Method 2: OLS. Next, we adjust for offensive quality, defensive quality, and park simultaneously using ordinary least squares (OLS) on model (41). This method is similar to that from Acharya et al. (2008), although they compute game-level park factors and we compute half-inning-level park factors. This yields an unbiased estimate of the park effects, and so we expect this method to perform better than the previous one.
Method 3: Three-Part OLS. Although OLS using model (41) is unbiased, the fitted coefficients have high variance due to the multicollinearity of the data matrix X. In particular, the park matrix P is correlated with the offensive team matrix O and the defensive team matrix D because in each half-inning, either the team on offense or defense is the home team. We may visualize the collinearity in X by denoting all of the half-innings (rows) in which the road team is batting by road, denoting the half-innings in which the home team is batting by home, and writing X (e.g., for one season of data) as
To address this collinearity issue, we propose a three-part OLS algorithm. First, we estimate the offensive quality coefficients during half-innings in which the road team is batting. We do so via OLS on the following model,
This yields a decent estimate
Second, we estimate the defensive quality coefficients during half-innings in which the home team is batting. We do so via OLS using the following model,
This yields a decent estimate
Third, we use the fitted team quality coefficients
yielding fitted park coefficients
Method 4: Ridge. Finally, we use ridge regression to fit model (41). In the presence of multicollinearity, ridge regression coefficient estimates may improve upon OLS estimates by introducing a small amount of bias in order to reduce the variance of the estimates (Hoerl and Kennard 1970). We tune the ridge parameter λ using cross validation.
Simulation Results. Recall from the start of this section that we simulate 25 sets of “true” parameters
Results of our first simulation study.
| Method | Simulation error |
|---|---|
| Ridge | 0.0244 |
| OLS | 0.0326 |
| Three-part OLS | 0.0330 |
| OLS without adjusting for team quality | 0.0610 |
-
The bold value indicates the best method that has the lowest error.
The OLS estimator without adjusting for team quality performs worst, as ignoring team quality leads to a biased estimate of the park effects. OLS and three-part OLS, which include proper adjustments for team quality, perform similarly and are second best. Three-part OLS turns out not to be an improvement over OLS because despite the multicollinearity, there is enough linear independence between the batting-road and batting-home half-innings to obtain reasonably accurate team quality estimates. Also, if X contains multiple years worth of data, three-part OLS leads to slightly biased estimates of β (off) and β (def) since steps one and two only adjust for park. Additionally, three-part OLS uses half as much data to estimate team quality, which is significant because the outcome variable inning runs is so noisy. Lastly, ridge regression performs the best, and is significantly better than OLS. In Figure 24, we visualize one of the 25 simulations by plotting the “true” park effects against the ridge estimates and the OLS estimates. We see that OLS is biased, whereas ridge lies more evenly around the line y = x.

For one of 25 simulations from our first simulation study from Section D.4, plot the “true” park effects against the ridge estimates and the OLS estimates. The line y = x, shown in black, represents a perfect fit between the “true” and fitted park effects. The OLS estimates are biased, whereas the ridge estimates lie more evenly around the line y = x.
D.5 Second simulation study
A primary criticism of the first simulation study from Section D.4 is that in actual baseball, the offensive and defensive quality coefficients are not independent. Rather, often times offensive and defensive qualities are correlated within MLB divisions. For instance, in 2021, the Rays, Red Sox, Yankees, and Blue Jays of the AL East each had at least 91 wins, and so were all good offensive teams. Correlated offensive and defensive qualities within divisions introduces additional collinearity into the data matrix X, since teams play other teams within their division at a disproportionately high rate.
Another criticism of the first simulation study is that it treats Colorado’s park effect as a draw from the same distribution as the other park effects, whereas in real life we know Colorado’s park effect is an outlier as a result of the high altitude.
So, in this section, we conduct a second simulation study which incorporates intra-divisional collinearity and forces Colorado’s park effect to be an outlier. Specifically, we simulate 25 “true” parameter vectors
where DEN refers to Coors Field in Denver, Colorado. In other words, each division has its own offensive and defensive quality means, coercing the offensive and defensive qualities within each division to be correlated. We choose the values in Formula (55) so that the simulated outcome vectors
Because Colorado is an outlier in this simulation study, we judge our methods based on two loss functions: the Colorado park effect average simulation error,
and the non-Colorado park effect average simulation error,
The remainder of the second simulation study proceeds identically to the first simulation study from the previous section.
We report the results of our second simulation study in Table 8. Again, ridge regression performs the best. In particular, ridge performs significantly better than the other methods on the outlier Colorado, and better than the other methods on the other parks. In Figure 25, we visualize one of the 25 simulations by plotting the “true” park effects against the ridge estimates and the OLS estimates. We see that ridge regression successfully fits the Colorado park effect, whereas OLS significantly overestimates Colorado. Colorado as an outlier in OLS exerts high leverage over the rest of the park effects, swaying their estimates upwards. One might suggest removing the outlier Colorado from the dataset and estimating it separately, but doing weakens the estimates of the other teams in its division as a result of removing too many games from the set schedule which determines the data matrix X. So, in both the first simulation study from Section D.4 and the second simulation study from this section, ridge regression most successfully estimates the “true” simulated park effects.
Results of our second simulation study.
| Method | Non-Colorado simulation error | Colorado error |
|---|---|---|
| Ridge | 0.0442 | 0.0502 |
| OLS | 0.0483 | 0.1791 |
| Three-part OLS | 0.0490 | 0.1807 |
| OLS without adjusting for team quality | 0.0751 | 0.1893 |
-
The bold value indicates the best method that has the lowest error.

For one of the 25 simulations from our second simulation study from Section D.5, plot the “true” park effects against the ridge estimates and the OLS estimates. The line y = x, shown in black, represents a perfect fit between the “true” and fitted park effects. The OLS estimates are biased, whereas the ridge estimates lie more evenly around the line y = x. In particular, ridge regression much better captures the park effect of the outlier, Denver.
D.6 Comparing existing park effects and ridge park effects
Now, in this section, we compare our ridge park factors, which perform best in our simulation studies from Sections D.4 and D.5, to existing park effects from ESPN and FanGraphs.
Transforming ESPN and FanGraphs park factors to an “additive” scale. Our ridge and OLS park effects of a ballpark, based on model (41), are “additive” in the sense that they represent the expected runs scored in a half-inning at that park above that of an average park, if an average offense faces an average defense. On the other hand, ESPN and FanGraphs park factors, defined in Formulas (37) and (38), are “multiplicative” in the sense that they represent the ratio of runs created at home to runs created on the road. Therefore, in order to compare these existing park factors to our park factors, we need to put them on the same scale. In particular, we transform the ESPN and FanGraphs park effects into “additive” park effects. To do so, we take the mean runs scored in a half-inning,
and multiply it by a “multiplicative” park factor subtracted by 1. For example, if the ESPN Colorado park factor α in 2019 is 1.34, representing that teams score 34 % more runs in Colorado than in other parks, then the transformed “additive” ESPN park factor is
After this transformation, the ESPN and FanGraphs park factors also represent the expected runs scored in a half-inning at that park above that of an average park.
Visualizing these park effect methods. In Figure 26 we visualize the ridge, OLS, ESPN, and FanGraphs park effects (where the latter two are transformed to an “additive” scale), fit on all half-innings from 2017 to 2019. We use the park abbreviations from Retrosheet, our data source, as discussed in Section 2.2. As expected, we see that ridge park factors are a shrunk version of OLS park factors, and FanGraphs park factors are a shrunk version of ESPN park factors. The FanGraphs and ridge park factors are remarkably similar. Also, as expected, Coors Field (DEN02) has the largest park effect for all four methods. The Texas Ranger’s ballpark in Arlington (ARL02) has the second highest park effect for all four methods. These two parks have signifihas the lowest park effect for all four methods.

Ridge, OLS, ESPN, and FanGraphs 2019 three-year park effects (where the latter two are transformed to an “additive” scale). The abbreviations are the retrosheet ballpark codes.
Additionally, we visualize how these various park effects impact the Grid WAR of various starting pitchers. In Figure 27, we show the 2019 seasonal Grid WAR for a set of starters without park effects, with ridge park effects, and with (transformed) ESPN park effects. For most pitchers, the impact of including a park adjustment is small. For some pitchers, the impact of an ESPN park adjustment is massive. For instance, the GWAR of Mike Minor and Lance Lynn, who pitched for the Rangers in 2019, each increases by a staggering one whole WAR. Ridge park factors have a much more muted impact than ESPN park factors. This makes sense, as ridge regression shrinks the park coefficients closer to 0. For a few pitchers, however, even the ridge park effects make a nontrivial impact on their GWAR. This also makes sense, as some park effects, such as those of the Mets, Rockies, and Rangers, are far enough from zero. For instance, the GWAR of Noah Syndergaard and Jacob deGrom, who pitched for the Mets, each decreases by about one-quarter of a WAR.

Grid WAR on a set of pitchers from 2019 without park effects (red triangles), with ridge park effects (blue squares), and with ESPN park effects (green circles).
Comparing these park effects quantitatively. In deciding which park effects to use in our final Grid WAR calculations, we quantitatively compare the ridge, OLS, ESPN, and FanGraphs park factors. In particular, we compare the out-of-sample predictive performance of these park effects.
We begin by fitting each park factor method using data from all half-innings from 2014 to 2016. Note that the OLS and ridge park factors adjust for team offensive and defensive quality, whereas the ESPN and FanGraphs park factors don’t. So, in order to fairly quantitatively compare which of these park factor methods is “best”, we adjust for team quality on all of these methods. Specifically, using the fitted park factors
Then, using these adjusted models based on Formula (60), we predict the expected runs scored
Each of the four methods has the same out-of-sample RMSE, 1.504. For reference, the RMSE of the overall mean is 1.508, so park factors do improve prediction, albeit slightly. But, because the runs scored in a half-inning is so noisy, and because the differences across parks are so slight, out-of-sample RMSE isn’t sensitive enough to quantitatively show which park factors have the best predictive performance.
To more clearly understand the differences in methods, we calculate the ecological RMSE to quantitatively compare the various park factor methods. This is done by first fixing a ballpark p. Then for each park factor method, we take the mean of the vector of predicted runs scored in each half-inning at the given park p, yielding
Out-of-sample ecological RMSE of predicting the runs scored in a half-inning using various park effect methods.
| Park effect | Ecological RMSE |
|---|---|
| Ridge | 0.01516 |
| FanGraphs | 0.01578 |
| ESPN | 0.01579 |
| OLS | 0.01672 |
| Overall mean
|
0.04658 |
-
The bold value indicates the best method that has the lowest error.
Hence the ridge regression park effects lead to better out-of-sample predictions of the runs scored in a half-inning than existing park factor methods from ESPN and FanGraphs.
D.7 2019 three-year park effects
As discussed in Sections D.4 and D.5, the ridge park effects outperform other park effect methods in two simulation studies. Further, as discussed in Section D.6, ridge park effects outperform existing park effect methods from ESPN and FanGraphs. Therefore, we use ridge park effects in computing Grid WAR. In particular, we use ridge regression on our observed dataset {y, X} consisting of all half-innings from 2017 to 2019, tuning the ridge parameter λ using cross validation, to fit our park effects, shown in Figure 3 in Section 2.6.
Appendix E: Grid WAR across modern baseball history
We visualize the top 15 starting pitcher-seasons of all time by total Grid WAR in Figure 28a. The pitcher with the highest total Grid WAR of all time in a single season is Sandy Koufax and it is not even close. In 1966, he accumulated 11.54 GWAR over 41 games in his final season which is half a game more GWAR than the second best season (Bob Gibson had 11.05 Grid WAR over 34 games in 1968) and the third best (Dwight Gooden had 11.04 Grid WAR over 35 games in 1985). Koufax’s 1966 season is an illuminating example of the value of Grid WAR compared to standard formulations. While his 1966 is the standout season of all time in terms of Grid WAR, it is just the sixth highest seasonal FWAR (RA/9) and the 20th highest seasonal FWAR (FIP). The other methods incorrectly overweight his three outlying blow-up games (i.e. less than −0.1 GWAR). This is an excellent example of why it is a philosophical mistake to ignore variance and convexity. In 1966, there were two versions of Koufax: the “left arm of God” or worse than replacement. The “left arm of God” threw eight complete game shutouts and 9 one-run complete games. Grid WAR properly accounts for this variation while the standard metrics do not. Among the 15 all time best seasons, no other pitcher appears more than once, while Koufax appears on the list three times (1963, 1965, 1966) with his 1964 season only falling short because Koufax lost a quarter of the season due to injury. Koufax’s “duality” is not just chance variation, it is a systematic attribute and a significant contributor to his early retirement after the 1966 season.

The top 15 starting pitcher-seasons post 1951 by total Grid WAR (a) and Grid WAR per game (b).
Grid WAR certainly favors pitchers that start more often and pitch deeper into the game. Consequently, all of the top pitcher-seasons of all time, according to cumulative Grid WAR, occurred prior to 2001. Moreover, no pitcher-season since 2001 has eclipsed 9.1 GWAR (Greinke in 2009 has the highest at 9.068). Just five pitcher seasons since 2009 have eclipsed 8.5 GWAR (Weaver in 2011, deGrom in 2018, Arrieta in 2015, and Greinke in 2009 and 2015), and only two pitcher-seasons since 2016 have eclipsed eight GWAR (deGrom in 2018 and Verlander in 2019). Starting pitchers are fundamentally less valuable today because top starters used to pitch many more games per season and more innings per game. Koufax started every fourth game in 1966, whereas high-end pitchers today start in every fifth game. Furthermore, the complete game is a thing of the past. Today, starters are typically removed prior to the seventh inning as a reaction to the time through the order penalty (Brill et al. 2023).
We visualize the top 15 starting pitcher-seasons of all time by Grid WAR per game in Figure 28b. Today’s pitchers fare substantially better on a per-start basis. The most efficient individual pitcher-season of all time, subject to starting at least 25 games, is Pedro Martinez who in 2000 finished with 0.355 Grid WAR over 29 games. Greg Maddux’s 1994 season is second all-time, with 0.330 Grid WAR over 25 games. Greg Maddux has third place too, with 0.328 Grid WAR over 28 games in 1995. These seasons were remarkable in terms of consistency. Pedro had zero blow-up games in 2000. All but two of his games resulted in positive GWAR, and his worst game featured just −0.068 GWAR. Similarly, across 1994 and 1995, Maddux had just five negative GWAR games in 53 starts, with at worst −0.13 GWAR in a game.
We visualize the top 15 starting pitchers of all time by career Grid WAR per game in Figure 29b. The most efficient starter of all time over his career (minimum of 100 games) is Clayton Kershaw who currently averages 0.208 Grid WAR per start over 410 games. Jacob deGrom is a close second with 0.206 over his 215 games. Pedro Martinez is third with an average of 0.201 over 410 games. Interestingly, only two of the top 10 pitchers of all time by career efficiency played their entire careers prior to 2000 (the exceptions are Whitey Ford and Sandy Koufax).

The top 15 starting pitchers post 1951 by career Grid WAR (a) and career Grid WAR per game (b).
We visualize the top 15 starting pitchers of all time by total career Grid WAR in Figure 29a. The pitcher with the most career Grid WAR is Roger Clemens, who accumulated 139.8 GWAR across 24 seasons from 1984 to 2007. The starter with the second highest career Grid WAR, Greg Maddux, doesn’t come close to Clemens, as he accumulated 115.6 GWAR over 23 seasons from 1986 to 2008. Three of the top ten starters according to career GWAR (Clemens, Maddux, and Randy Johnson) played in the 1980s, 90s, and 00s, and the remaining seven (Tom Seaver, Nolan Ryan, Don Sutton, Gaylord Perry, Bert Blyleven, Steve Carlton, and Jim Palmer) played in the 1960s, 70s, and 80s. Just five of the top 25 starters by career Grid WAR, on the other hand, began their career after 2000. The best such starters are Justin Verlander (85.7 GWAR over 19 seasons from 2005 to 2003) and Clayton Kershaw (85.1 GWAR over 16 seasons from 2008 to 2023). These are the 15th and 16th ranked pitchers, and they don’t come anywhere particularly close to Clemens or even Maddux, although their careers aren’t over. As discussed before, the pitchers with the highest career Grid WAR come from the previous millennium because top starters back then pitched more games per season and pitched more innings per game.
Finally, we measure a starters peak performance by the maximum total Grid WAR across all his contiguous four year stretches. We combine a starter’s peak ranking with his ranking by total career Grid WAR using the geometric mean,

The hall-of-fame chart, or the top 30 starting pitchers post 1951 by the geometric mean of career Grid WAR and peak four-year Grid WAR.
References
Acharya, R.A., Ahmed, A.J., D’Amour, A.N., Lu, H., Morris, C.N., Oglevee, B.D., Peterson, A.W., and Swift, R.N. (2008). Improving major league baseball park factor estimates. J. Quant. Anal. Sports 4: 6, https://doi.org/10.2202/1559-0410.1108.Search in Google Scholar
Albert, J. and Bennett, J. (2003). Curve ball: baseball, statistics, and the role of chance in the game. Copernicus Books, New York.Search in Google Scholar
Appelman, D. (2016). Park factors – 5 year regressed, Available at: https://library.fangraphs.com/park-factors-5-year-regressed/.Search in Google Scholar
Baseball Reference (2011). Pitcher WAR calculations and details, Available at: https://www.baseball-reference.com/about/war_explained_pitch.shtml.Search in Google Scholar
Baseball Reference (2022). Park adjustments, Available at: https://www.baseball-reference.com/about/parkadjust.shtml.Search in Google Scholar
Baumer, B. and Zimbalist, A. (2014). The sabermetric revolution: assessing the growth of analytics in baseball. University of Pennsylvania Press, Philadelphia, Pennysylvania.10.9783/9780812209129Search in Google Scholar
Baumer, B.S., Jensen, S.T., and Matthews, G.J. (2015). OpenWAR: an open source system for evaluating overall player performance in major league baseball. J. Quant. Anal. Sports 11: 69–84, https://doi.org/10.1515/jqas-2014-0098.Search in Google Scholar
Brill, R.S., Deshpande, S.K., and Wyner, A.J. (2023). A Bayesian analysis of the time through the order penalty in baseball. J. Quant. Anal. Sports 1, https://doi.org/10.1515/jqas-2022-0116.Search in Google Scholar
Brown, L.D. (2008). In-season prediction of batting averages: a field test of empirical Bayes and Bayes methodologies. Ann. Appl. Stat. 2: 113–152, https://doi.org/10.1214/07-aoas138.Search in Google Scholar
Chen, T. and Guestrin, C. (2016). XGBoost: a scalable tree boosting system. In: Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining, KDD ‘16. ACM, New York, NY, USA, pp. 785–794.10.1145/2939672.2939785Search in Google Scholar
ESPN (2014). Max Scherzer 2014 game log, Available at: https://www.espn.com/mlb/player/gamelog/_/id/28976/year/2014/category/pitching.Search in Google Scholar
ESPN (2022). MLB park factors – 2019, Available at: https://www.espn.com/mlb/stats/parkfactor/_/year/2019.Search in Google Scholar
Fangraphs (2010). Replacement level, Available at: https://library.fangraphs.com/misc/war/replacement-level/.Search in Google Scholar
Hoerl, A.E. and Kennard, R.W. (1970). Ridge regression: biased estimation for nonorthogonal problems. Technometrics 12: 55–67, https://doi.org/10.2307/1267351.Search in Google Scholar
Lewis, M. (2003). Moneyball: the art of winning an unfair game. WW Norton & Company, New York.Search in Google Scholar
Medvedovsky, K. and Patton, A. (2022). Daily adjusted and regressed Kalman optimized projections | DARKO, Available at: https://apanalytics.shinyapps.io/DARKO/.Search in Google Scholar
Petti, B. and Gilani, S. (2021). Baseballr: acquiring and analyzing baseball data. R package version 1.6.0, Available at: https://billpetti.github.io./baseballr/.10.32614/CRAN.package.baseballrSearch in Google Scholar
Retrosheet (2021). Retrosheet play-by-play data files (event files), Available at: https://www.retrosheet.org/game.htm.Search in Google Scholar
Schwarz, A. and Gammons, P. (2005). The numbers game: baseball’s lifelong fascination with statistics. Thomas Dunne Books, New York.Search in Google Scholar
Slowinski, P. (2012). WAR for pitchers, Available at: https://library.fangraphs.com/war/calculating-war-pitchers/.Search in Google Scholar
Statcast (2023). Statcast search, Available at: https://baseballsavant.mlb.com/statcast_search.Search in Google Scholar
Tango, T., Lichtman, M., and Dolphin, A. (2007). The book: playing the percentages in baseball. Potomac Books, Dulles, Virginia.Search in Google Scholar
Thorn, J. and Palmer, P. (1984). The hidden game of baseball: a revolutionary approach to baseball and its statistics. Doubleday, Garden City, NY.Search in Google Scholar
Wikipedia (2023). Baseball, Available at: https://en.wikipedia.org/wiki/Baseball.Search in Google Scholar
Wolverton, M. (1993). “Support-neutral” statistics – a method of evaluating the true quality of a pitcher’s start. By The Numbers 5: 4–14.Search in Google Scholar
Wolverton, M. (1999). The top pitchers of the 1990s: a support-neutral approach, Available at: https://www.baseballprospectus.com/news/article/416/the-top-pitchers-of-the-1990s-a-support-neutral-approach/.Search in Google Scholar
Wolverton, M. (2004). Baseball prospectus basics: the support-neutral stats, Available at: https://www.baseballprospectus.com/news/article/2590/baseball-prospectus-basics-the-support-neutral-stats/.Search in Google Scholar
© 2024 the author(s), published by De Gruyter, Berlin/Boston
This work is licensed under the Creative Commons Attribution 4.0 International License.
Articles in the same Issue
- Frontmatter
- Research Articles
- A comprehensive survey of the home advantage in American football
- Introducing Grid WAR: rethinking WAR for starting pitchers
- Improving NHL draft outcome predictions using scouting reports
- Comparison of individual playing styles in football
- A generative approach to frame-level multi-competitor races
- An empirical Bayes approach for estimating skill models for professional darts players
Articles in the same Issue
- Frontmatter
- Research Articles
- A comprehensive survey of the home advantage in American football
- Introducing Grid WAR: rethinking WAR for starting pitchers
- Improving NHL draft outcome predictions using scouting reports
- Comparison of individual playing styles in football
- A generative approach to frame-level multi-competitor races
- An empirical Bayes approach for estimating skill models for professional darts players