
Is discourse made up of sentences? Focusing on dependent grafted speech in modern standard Japanese
-
Toshiyuki Sadanobu


Abstract
The idea that discourse is made up of sentences has been widespread among linguists. Does this traditional discourse perspective (“sententialism”) apply to casual language in daily communication? This paper examines the validity of sententialism by focusing on a type of speech called “dependent grafted speech” in Japanese conversation. Close examinations of various words, phrases, and sentences reveal that dependent grafted speech is different from sentences on two points: (i) Generally, the lexical accent of the copula at the beginning of dependent grafted speech is a high tone; and (ii) the interaction particle at the end of dependent grafted speech is not uttered with a falling intonation unless it is proceeded by a very abrupt rising intonation (“leaping” intonation). These findings cast doubt on the status of dependent grafted speech as a sentence. Moreover, they demonstrate a new conception of discourse as a mixture of diverse constituents, including sentences, dependent grafted speech, and other utterance types.
1 Introduction
It has traditionally been thought that discourse is made up of sentences (e.g., Nitta 2016; Ōiwa 1949; Smith 2003). Although this view of discourse (“sententialism” hereafter) might appear valid for well-prepared formal Japanese language, does it also apply to casual Japanese in daily communication?
It should be noted that there is a disagreement about the treatment of Japanese speech consisting of just one noun. While considerable research, based on sententialism, views one-noun utterances as a special sentence (itigobun in Japanese), Oki (2006) argues that while one-noun speech is a case of one-word speech, it still does not constitute one sentence. Regrettably, however, neither of these arguments for and against one-noun speech being a sentence are supported by sufficient evidence, as both are highly abstract.
Sententialism also has an impact on utterances that would appear at first glance to be incomplete. Nitta (2016) argues that the utterance rasii desu ne (“apparently so”) in Example (1) below would be judged by him as well as Japanese researchers, in general, to be a sentence.
| “ohukuro | -san | =mo, | sō | =da | -tta | -no | =ka?” | hirosi=ga | i-tta. | ||||
| mother | -HON | =SIM | same | =COP | -PST | -NMLZ | =Q | Hirosi=NOM | say-PST | ||||
| “Did your mother also think the same thing?” said Hirosi. | |||||||||||||
| “rasii | =desu | =ne.”[1] | |||||||||||
| apparently | =COP | =IP | |||||||||||
| “Apparently.”[2] | |||||||||||||
| (Tosio Kamata, Kin’yōbi no tumatati e) | |||||||||||||
| [Nitta 2016: 13] | |||||||||||||
Based on the observation of two prosodic points, it will be argued that these utterances (“dependent grafted speech” hereafter) do not resemble sentence speech. Below I will introduce the concept of dependent grafted speech (Section 2), discuss observations of each of the two prosodic points (Sections 3 and 4), and summarize the argument (Section 5).
2 What is dependent grafter speech?
In horticulture, a graft is well known as a tree grafted onto the base stock of a tree (Figure 1).
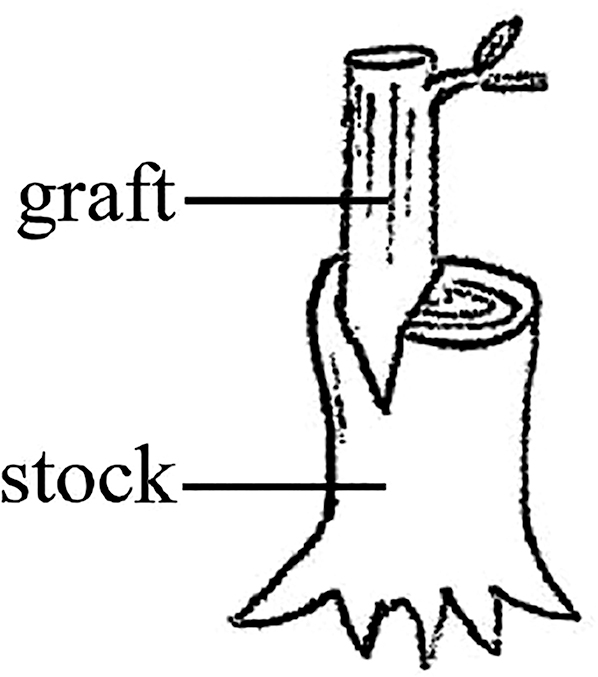
Illustration of grafting.
While the stock stands on its own power, the graft is not independent. It grows from where it is inserted into the stock. Continuing from a prior study that discussed the semantic and pragmatic aspects of grafted speech (Sadanobu 2020b), this paper will employ the word “graft” metaphorically to describe a type of utterance in modern standard Japanese as grafted speech. Grafted speech refers to utterances that lack independence at their starting points and thus involve a conspicuous dependence on the preceding context.
Some examples of grafted speech appearing in communication in modern standard Japanese are illustrated in examples (2) and (3).
| asita, | ame | =ka | =na? |
| tomorrow | rain | =Q | =IP |
| ‘I wonder if it’ll rain tomorrow.’ | |||
| =to | omou | =kedo | =na. |
| =QUO | think | =CONJP | =IP |
| ‘I think so.’ | |||
| asita, | ame | =ka | =na? |
| tomorrow | rain | =Q | =IP |
| ‘I wonder if it’ll rain tomorrow.’ | |||
| =da | =naa. |
| =COP | =IP |
| ‘Probably.’ | |
In Example (2), Speaker B replies to A’s utterance, asking about the following days’ weather, =to omou=kedo=na (‘I think so’). The =to at the beginning of this response is not a free word but an enclitic indicating quotation. In this way, it is apparent that the utterance =to omou=kedo=na is dependent on the preceding utterance asita, ame=ka=na? (‘I wonder if it’ll rain tomorrow’), which is what could be called the stock utterance. Similarly, the =da at the start of Speaker B’s reply in Example (3), =da=naa (“probably”) is not a free word but an enclitic (a copula),[3] and thus the dependence of =da=naa on the preceding utterance asita, ame=ka=na? is overt. Of the two grafted speech utterances =to omou=kedo=na and =da=naa above, the free word omou (‘think’) appears in the former, while the latter is completely lacking in independence, as both the starting =da and the following postpositional particle =naa are dependent.
Using the term “grafted” instead of another term such as “accompanying” avoids misunderstandings from possible nuances such as conformity or expectedness. For example, grafted speech also includes utterances that reveal, to some degree, an attitude of incredulity or denial, such as that in Example (4).[4]
| de, | uti | =wa | urokoinko -tte, | |
| CONJP | my house | =TOP | green-cheeked parakeet-QUO | |
| ‘Our parakeet is green-cheeked parakeet,’ | ||||
| tyotto | hitomawari | okki | -ku | -tte |
| a little | one size | big | -CONS | -CONJP |
| ‘It is about one size bigger (than the budgerigar that E keeps), and’ | ||||
| huun, | urokoinko | -tte | iu | =no. |
| hmm | green-cheeked parakeet | -QUO | say | =Q |
| ‘Hmm, a green-cheeked parakeet, huh?’ | ||||
| hutamawari | =kurai | okki | -ku | -na | -katta? |
| two sizes | =about | big | -CONS | -NEG | -PST |
| ‘Isn’t it about two sizes bigger?’ | |||||
| = ka | = naa. | de, | ma, | sōziki … |
| =Q | -IP | CONJ | anyway | vacuum cleaner |
| ‘I am not sure. But, anyway, the vacuum cleaner …’ | ||||
| [http://www.speech-data.jp/chotto/2012/2012025.html] | ||||
Here, Speaker C is describing to Listeners D and E the physical traits of her parakeet as a preamble to telling them about an incident involving the parakeet. When she describes the parakeet as one size larger (than a shell parakeet), Listener D, who has seen the parakeet, asks if it was about two sizes larger. In response, C inclines her head to the side (Photo 1) as if she were thinking about the question and says, =ka = naa (‘I am not sure’; underlined passage in (4)). This utterance =ka = naa is an example of grafted speech that starts with the dependent word (postpositional particle) =ka. As this utterance, at the very least, does not indicate ready agreement with D’s preceding utterance, it does not express conformity, and thus it would not be described as “accompanying” its preceding utterance. Incidentally, the =naa that follows =ka here is also dependent, and thus the entire grafted speech utterance lacks independence.

Speaker C inclines her head slightly while replying =ka=naa to Listener E’s utterance. Video published at: http://www.speech-data.jp/chotto/2012/2012025.html.
This paper will observe in particular the prosody of dependent grafted speech, that is, grafted speech that includes no free words, not only at the beginning but through to the end of the utterance (as seen in =da=naa in Example (3) and =ka=naa in Example (4)).
3 The lexical accent at the start of dependent grafted speech
In Section 3, we will observe the lexical accent at the start of dependent grafted speech. Figure 2 reproduces the overall structure of the argument in the somewhat complex form of layering observations on top of observations.

Structure of Section 3.
In Figure 2, the basic assumption of the argument is illustrated at the bottom. The arrow indicates the order in which the argument will proceed.
More specifically, we will begin by introducing the principle of lexical determinacy (by which lexical accents lack regularity and vary from word to word), which is well known as a distinguishing feature of lexical accents of simple words in modern standard Japanese ([1]). Then, we will identify an exceptional tendency that does not conform to this principle (referred to tentatively as the tendency toward inconspicuousness). This is the tendency for simplex words that are not conspicuous in syntactic, semantic, and phonological terms to have regular, rather than varied, lexical accents (specifically, to conform to the surrounding environment without standing out) ([2]). The inconspicuous words that tend to conform to the surroundings act as a sort of litmus test paper by which we can assess the surrounding environment. Observing these allows us to elucidate the lexical accent required of words positioned on the boundaries of utterances (lexical accent as a boundary tone) ([3]), after which we consider the boundaries of utterances to identify whether boundary tones are present or not. Sections 3.1–3.4 describe each stage of the structure [1]–[4], outlined in Figure 2, in that order.
3.1 Lexical determinacy
Languages such as English and Russian are considered to constitute a group in which the lexical accent is not determined by matters such as the phoneme structure of words and grammatical qualities (Lyons 1968), and modern standard Japanese can also be included in this group. The lexical accent of modern standard Japanese is not predetermined but varies among individual words (Beckman and Pierrehumbert 1986: 256), as seen in the examples of saru (‘monkey’), which has a word-initial accent pattern (a high accent on the first syllable); inu (‘dog’), which has a word-final accent pattern; and kizi (‘pheasant’), which has a flat accentless pattern.[5]
3.2 Tendency toward inconspicuousness
These observations concern the lexical accents of simplex words, while the lexical accents of complex words in modern standard Japanese are known to exhibit a considerable degree of regularity (e.g., McCawley 1968). Furthermore, various tendencies can be observed even among complex words that deviate from this regularity. Here we will propose, as one such tendency, the tendency toward inconspicuousness described under (5) below.
| Tendency toward inconspicuousness: |
| Inconspicuous words—that is, words that are not conspicuous syntactically, are light in semantic content, and are short in phonological form—will tend to be inconspicuous in terms of lexical accent as well and, as a result, conform to their surrounding environments. |
This tendency demonstrates that one reason why lexical accents of complex words deviate from general regularity is because it is difficult to recognize words that are syntactically, semantically, and phonologically inconspicuous as words in their own right. See Examples (6)–(10) (the capitals in the examples are used for moras with high pitch except for term abbreviations.[6] The same applies hereafter).
| a. | KAi ‘strange’ | + | geNSHŌ ‘phenomenon’ | -> | kaIGEnshō ‘strange phenomenon’ |
| b. | kyuU ‘sudden’ | + | haSSHIN ‘start’ | -> | kyuUHAssin ‘sudden start’ |
| c. | HI ‘non-’ | + | zyoOSIKI ‘common sense’ | -> | hiZYOosiki ‘insane’ |
| d. | huKU ‘vice’ | + | gaKUTYŌ ‘president’ | -> | huKUGAkutyō ‘vice president’ |
| e. | SI ‘private’ | + | seIKATU ‘life’ | -> | siSEikatu ‘private life’ |
| a. | O (HON) | + | deN’WA ‘telephone’ | -> | oDEn’wa ‘telephone’ |
| b. | O (HON) | + | kaGEN ‘condition’ | -> | oKAgen ‘moderation’ |
| c. | O (HON) | + | seNTAKU ‘washing’ | -> | oSEntaku ‘washing’ |
| d. | O (HON) | + | soOZI ‘cleaning’ | -> | oSOozi ‘cleaning’ |
| e. | O (HON) | + | ziKAN ‘time’ | -> | oZIkan ‘time’ |
| a. | O (HON) | + | beNKYŌ ‘study’ | -> | oBENKYŌ ‘study’ |
| b. | O (HON) | + | gyoOGO ‘deportment’ | -> | oGYŌGI ‘deportment’ |
| c. | O (HON) | + | saIHŌ ‘sewing’ | -> | oSAIHŌ ‘sewing’ |
| d. | O (HON) | + | saIHU ‘purse’ | -> | oSAIHU ‘purse’ |
| e. | O (HON) | + | zyaMA ‘obstacle’ | -> | oZYAMA ‘obstacle’ |
| GO (HON) | + | siDŌ ‘guidance’ | -> | goSIdō ‘guidance’ |
| a. | GO (HON) | + | byoOKI ‘disease’ | -> | goBYŌKI ‘disease’ |
| b. | GO (HON) | + | kaNKEI ‘relationship’ | -> | goKANKEI ‘relationship’ |
| c. | GO (HON) | + | keIKEN ‘experience’ | -> | goKEIKEN ‘experience’ |
| d. | GO (HON) | + | keKKON ‘marriage’ | -> | goKEKKON ‘marriage’ |
| e. | GO (HON) | + | seNMON ‘specialty’ | -> | goSENMON ‘specialty’ |
The words in Example (6) are complex words in which the latter elements (in the first example (a), genshō, ‘phenomenon’) consist of two feet of Chinese-derived words (that is, two characters). Incidentally, the latter elements of the complex words in Examples (6)–(10) are words spoken with an accentless pattern. These were chosen as examples that would make it easy to judge whether or not the accents were compounded.
Generally, the accent on a complex word with a two-foot latter element is, as in Example (6), one in which the accent nucleus (the ending point of the high accent) is positioned in the first mora of the latter element. For example, the word kaigenshō (‘strange phenomenon’) in (6a) has the accent nucleus positioned in the first mora ge of the latter element genshō (ka: low; i: high; ge: high; n: low; sho: low; o: low, LHHLLL hereafter).[7]
However, when the former element of a complex word is the honorific o or go—that is, in the case of a prefix, with a light semantic content (which probably could be described as merely one of politeness), and only one syllable in length, this general regularity does not necessarily apply. While some complex words have this general regularity (such as o-den’wa LHLL ‘telephone’ and go-sidō LHLL ‘guidance’ in Examples (7) and (9)), others deviate from it and exhibit a tendency toward inconspicuousness (such as o-benkyō LHHHH ‘study’ and go-byōki LHHH ‘disease’ in Examples (8) and (10)). The latter complex words are accentless from the accent pattern of their latter elements. That is, in Examples (8) and (10), the prefixes o and go are ignored with regard to accent, and the lexical accent information of the latter elements (i.e., no accent nucleus) is succeeded by the entire complex word without change. This is what is referred to by the tendency toward inconspicuousness (5): “Inconspicuous words … will tend to be inconspicuous in terms of … lexical accent as well, … conforming to their surrounding environments.”
As with prefixes, a tendency toward inconspicuousness can also be observed in suffixes. Examples (11)–(13) illustrate complex words in which the latter element consists of one foot of a Chinese-derived word (that is, one character).[8]
| a. | HYOoga ‘ice’ | + | KI ‘period’ | -> | hyoOGAki ‘ice age’ |
| b. | koONETSU ‘light and heat’ | + | HI ‘cost’ | -> | koONETUhi ‘utility cost’ |
| c. | siKŌ ‘thinking’ | + | RYOku ‘power’ | -> | siKOoryoku ‘thinking power’ |
| d. | SYOki ‘initial period’ | + | TI ‘value’ | -> | syoKIti ‘initial value’ |
| e. | TAiho ‘arrest’ | + | SYA ‘person’ | -> | taIHOsya ‘arrestee’ |
| a. | gaIRAI ‘imported’ | + | GO ‘word’ | -> | gaIRAIGO ‘foreign-derived word’ |
| b. | kiKAKU ‘project’ | + | SYO ‘paper’ | -> | kiKAKUSHO ‘proposal’ |
| c. | KOzin ‘individual’ | + | YOo ‘use’ | -> | koZIN’YŌ ‘private use’ |
| d. | TYOosa ‘survey’ | + | TAi ‘team’ | -> | tyoOSATAI ‘survey team’ |
| e. | ZIka ‘home’ | + | SEi ‘-made’ | -> | ziKASEI ‘homemade’ |
| a. | KAtō ‘Katō (personal name)’ | + | KUn (HON) | -> | KAtō-kun ‘dear Katō’ |
| b. | oKUtō ‘Okutō (p.n.)’ | + | KUn (HON) | -> | oKUtō-kun ‘dear Okutō’ |
| c. | saITŌ ‘Saitō (p.n.)’ | + | KUn (HON) | -> | saITŌ-KUN ‘dear Saitō’ |
Of these, Example (11) lists complex words that conform to general regularity, while Example (13) lists complex words that exhibit the tendency toward inconspicuousness as they include the latter element -kun.
Let us first consider Example (11). While in a complex word with a one-foot latter element the accent nucleus is placed on the final foot of the former element (e.g., ki in hyōga=ki LHHL ‘ice age’),[9] for certain latter elements, the accent follows the accentless pattern (e.g., go ‘word,’ gairaigo LHHHH; ‘foreign-derived word,’ Nihongo LHHH ‘Japanese language,’ and Tyūgokugo LHHHH ‘Chinese language’), as in Example (12).[10]
However, this does not apply in the case of complex words with -kun, in which the latter element is a suffix, lighter in semantic content (it could probably be described as a way of referring to somebody), and only one syllable in length, as seen in Example (13). Specifically, this includes (a) complex words, in which -kun is attached to a former element that originally has a word-initial accent (e.g., Satō HLL), take a word-initial accent (HLLLL); (b) complex words, in which -kun is attached to a former element that originally has a word-internal or word-final accent (e.g., Okutō LHLL), take a word-internal of word-final accent (LHLLLL); and (c) complex words, in which -kun is attached to a former element that originally has no accent nucleus (e.g., Naitō LHHH), take an accentless pattern (LHHHHH). In these ways, whether there is an accent nucleus and its position are unchanged by attaching -kun. The same can also be observed in the cases of the other personal suffixes -san and -chan.
Conformity to this tendency toward inconspicuousness can also be observed in many cases among postpositional particles and copulas used to form phrases connected to nouns. Example (14) concerns postpositional particles and Example (15) copulas. Here, the noun saru (‘monkey’) is used as representative of the word-initial accent pattern noun inu (‘dog’) with word-internal/final and kizi (‘pheasant’) with an accentless pattern (See the end of Section 3.1.).
| a. | SAru=dake | iNU=dake | kiZI=DAKE | (=dake: RES) |
| b. | SAru=de | iNU=de | kiZI=DE | (=de: INS) |
| c. | SAru=e | iNU=e | kiZI=E | (=e: ALL) |
| d. | SAru=ga | iNU=ga | kiZI=GA | (=ga: NOM) |
| e. | SAru=hodo | iNU=hodo | kiZI=HODO | (=hodo: COMP) |
| f. | SAru=ka | iNU=ka | kiZI=KA | (=ka: SEL) |
| g. | SAru=kara | iNU=kara | kiZI=KARA | (=kara: ABL) |
| h. | SAru=mo | iNU=mo | kiZI=MO | (=mo: SIM) |
| i. | SAru=ni | iNU=ni | kiZI=NI | (=ni: LOC) |
| j. | SAru=o | iNU=o | kiZI=O | (=o: ACC) |
| k. | SAru=to | iNU=to | kiZI=TO | (=to: COM) |
| l. | SAru=tte | iNU=tte | kiZI=TTE | (=tte: QUO) |
| m. | SAru=wa | iNU=wa | kiZI=WA | (=wa: TOP) |
| n. | SAru=ya | iNU=ya | kiZI=YA | (=ya: ACCM) |
| o. | SAru=yo | iNU=yo | kiZI=YO | (=yo: VOC) |
| a. | SAru=da | iNU=da | kiZI=DA | (=da: COP) |
| b. | SAru=zya | iNU=zya | kiZI=ZYA | (=zya: COP[11]) |
Here, the word-initial accent of the host word (saru ‘monkey,’ inu ‘dog,’ and kizi ‘pheasant’) is maintained even in a phrase that includes an enclitic (e.g., (14a) saru=ga HLL, inu=ga LHL, kizi=ga LHH). When the enclitic has a length of one mora, for the most part, the only exception is the genitive enclitic no. When no is attached to a word-final-accented word (e.g., inu), the word-final accent is not maintained and is removed (inu=no LHH).[12]
Even when the enclitic has a length of two mora or longer, it can be observed that the first mora of the enclitic within the phrase often conforms to the “tendency toward inconspicuousness” (with the second and later morae taking a low accent). Example (16) illustrates this in the case of a postpositional particle and Example (17) in the case of a copula.[13]
| a. | SAru=demo | iNU=demo | kiZI=D E mo | (=demo: ‘even’) |
| b. | SAru=made | iNU=made | kiZI=MAde | (=made: ‘even’) |
| c. | SAru=nado | iNU=nado | kiZI=NAdo | (=nado: ‘and so on’) |
| d. | SAru=nara | iNU=nara | kiZI=N A ra | (=nara: COND) |
| e. | SAru=nanka | iNU=nanka | kiZI=NAnka | (=nanka: ‘such as’) |
| f. | SAru=oba | iNU=oba | kiZI=Oba | (=oba: ACC (archaic)) |
| g. | SAru=sae | iNU=sae | kiZI=SAe | (=sae: ‘even’) |
| h. | SAru=sura | iNU=sura | kiZI=SUra | (=sura: ‘even’) |
| i. | SAru=toka | iNU=toka | kiZI=TOka | (=toka: ‘such as’) |
| j. | SAru=yori | iNU=yori | kiZI=YOri | (=yori: ABL (archaic)) |
| a. | SAru=desu | iNU=desu | kiZI=DEsu | (=desu: COP) |
| b. | SAru=nari | iNU=nari | kiZI=NAri | (=nari: COP) |
| c. | SAru=zamasu | iNU=zamasu | kiZI=ZAmasu | (=zamasu: COP) |
For example, while de in the postposition demo (“to”) of Example (16a) and de in the copula desu of Example (17a) have low accents when they immediately follow the word-initial-accented word saru or the word-final-accented word inu and high accents when they immediately follow the accentless word kizi, the mo in demo and the su in desu consistently take low accents.
3.3 Lexical accent as a boundary tone
Next, we will observe the lexical accent required of words positioned on the boundaries of utterances—that is, lexical accent as a boundary tone—by using these “inconspicuous” words that conform to the “tendency toward inconspicuousness” as a litmus test paper to assess the surrounding environment.
As seen in Section 3.2, the lexical accent on a one-mora long case particle that is ignored and conforms to its surrounding environment should be high when it immediately follows an accentless word. However, exceptional cases exist, such as when some kind of boundary is recognized between the accentless word and the case particle (Sadanobu 2017, 2019). Examples are presented under (18). Hereinafter, a boundary is indicated by a slash [/].
| aTARU/ | =o | saIWAI, … |
| hit | =ACC | fortune |
| ‘By chance …’ | ||
| iKU/ | =ga | YOi. |
| go | =NOM | good |
| ‘You had better go.’ | ||
| iKU/ | =ni | koSI-TA | KOTO | =wa | NAi. |
| go | =COMP | exceed-PAST | thing | =TOP | inexistent |
| ‘It’s a good idea to go.’ | |||||
| iU/ | =ni | koTOkai-te …. |
| say | =for | lack-gerund |
| ‘That’s not a nice thing to say …’ | ||
| koNO | koKUGOJIten =no | DAi-SAn-kan=wa | ||
| this | Japanese dictionary=GEN | No. –three-volume=TOP | ||
| ‘noRU’/ | =kara | ‘maKU’/ | =made | =da. |
| ride | =ABL | wind | =G | =COP |
| ‘Volume three of this Japanese dictionary includes the words from noru through maku.’ | ||||
In the environment of directly following an accentless word (such as ataru ‘hit’ in Example (18a)), a high accent would be expected (as in the way ta and te in atatta ‘hit (past tense)’ and atatte ‘hit and’ take a high accent). Nevertheless, the accusative particle that immediately follows o has a low accent. This is because a boundary is recognized in terms of parts of speech between the accentless word and the particle. Such a boundary in terms of parts of speech is explained below.
One might say ryokō=ga suki=desu (‘I love travel’) or ryokōsuru=no=ga suki=desu (“I love to travel”) but would not say *ryokō=suru=ga suki=desu. In general, a verb will not be connected directly to a case particle in that order. These examples demonstrate that even when connecting such words together directly on an exceptional basis, a prominent boundary remains at the point of connection as this connection itself is not very strong. The examples illustrated under (18) are truly exceptional cases. They include two types of exceptions: idiomatic phrases (specifically, ataru=o saiwai [‘By chance …’] in (a), … suru=ga yoi [‘You had better …’] in (b), … suru=ni kosita koto=wa nai [‘It’s a good idea to …’] in (c), and iu=ni kotokaite … [‘be so stupid to (say …)’] in (d)), and cases in which verbs are quoted ((e)). In both of these cases, a verb is connected directly to a particle in that order.[14]
From a cross-linguistic perspective, the phenomenon of spoken utterances taking a special form before and after boundaries is not unusual, both in terms of rhythm (e.g., Hyman and Leben 2000: 592) and phonation/voice quality (e.g., Chafe 2001: 674; Gordon and Ladefoged 2001: 391–392). Recognizing the tendency toward boundary tones (19) in modern standard Japanese, we can consider this to be the lexical accent version of that tendency (20).
| In modern standard Japanese, tone tends to be lower before and after a boundary. |
| In modern standard Japanese, lexical accent tends to be lower before and after a boundary. |
In this way, with regard to lexical accent, we can understand the tendency of a particle, which tends to be ignored and conform to its surrounding environment, to take a low accent in the environment immediately following a verb even if it is accentless due to conformity with the tendency described under (20).
The tendency “to be lower before and after a boundary” under (20) includes cases in which an inconspicuous word is positioned before a boundary. Example (21) illustrates examples of inconspicuous words traditionally positioned immediately before clause boundaries, as conjunctive particles, and most of these can be understood in accordance with the tendency in (20).
| waTASI | =GA | iKE | =ba/, … |
| I | =NOM | go | =CONJP (conditional) |
| ‘if I go, …’ | |||
| waTASI | =GA | iKU | =ga/, … |
| I | =NOM | go | =CONJP (adversative) |
| ‘I will go, but …’ | |||
| waTASI | =GA | iKU | =kara/, … |
| I | =NOM | go | =CONJP (‘because’) |
| ‘because I will go, …’ | |||
| waTASI | =GA | iKU | =kedo/, … |
| I | =NOM | go | =CONJP (adversative) |
| ‘I will go, but …’ | |||
| waTASI | =GA | iKU | =nara/, … |
| I | =NOM | go | =CONJP (conditional) |
| ‘If I go, …’ | |||
| waTASI | =GA | iKU | =node/, … |
| I | =NOM | go | =CONJP (‘since’) |
| ‘as I will go, …’ | |||
| waTASI | =GA | iKU | =noni/, … |
| I | =NOM | go | =CONJP (adversative) |
| ‘although I go, …’ | |||
| waTASI | =GA | iKU | =si/, … |
| I | =NOM | go | =CONJP (copulative) |
| ‘I will go, and …’ | |||
| waTASI | =GA | iKU | =TO |
| I | =NOM | go | =CONJP (conditional) |
| ‘if I go, …’ | |||
| waTASI | =GA | i | =TTAra/, … |
| I | =NOM | go | =CONJP (conditional) |
| ‘if I go, …’ | |||
| waTASI | =GA | i | =TTAri/, … |
| I | =NOM | go | =CONJP (copulative) |
| ‘I go, and …’ | |||
| waTASI | =GA | i | =TTE/ |
| I | =NOM | go | =CONJP (gerund) |
| ‘I go, and …’ | |||
| waTASI | =GA | i | =TTEmo/ |
| I | =NOM | go | =CONJP (concessive) |
| ‘even if I go, …’ | |||
These are examples of main conjunctive particles connected directly to the accentless verb iku (‘go’). Of these, ba, ga, kara, kedo, nara, node, noni, and si take low accents ((a)–(h)), and tara, tari, and temo, which include ta and te, conform to the surroundings in the first mora ta and te, while their second morae ra, ri, and mo, the last morae directly before the boundaries, take a low accent ((j)–(n)). Only the te and to take high accents ((i), (m)).[15] Each of these conjunctive particles is a clitic that is light in semantic content (which probably serve only as connectors), short in length with only one or two morae, and inconspicuous, and each conforms to the “tendency toward inconspicuousness” in terms of accent, by conforming to its surrounding environment. However, the surroundings to which it conforms is not only the immediately preceding accentless word but also the immediately following clause boundary; whether it takes a high accent under the influence of the accentless word or a low accent in accordance with the tendency of boundary tone (20) varies by word.
The same can be said of the particles wa and mo, which should not be connected directly to elements other than nouns, as could be said of ordinary particles. See Example (22).
| iU/ | =wa | yaSU-ku, | oKONAU/ | =wa | kaTAsi. |
| say | =TOP | easy-and | do | =TOP | hard |
| ‘Things are easy to say but hard to do.’ (proverb) | |||||
| kiKU/ | =wa | iTTOKI | =no | haZI. |
| ask | =TOP | a moment | =GEN | shame |
| ‘Asking is a shame for a moment.’ (proverb) | ||||
| siRA-NU/ | =wa | HOnnin | hiTORI | =DAKE |
| know-NEG | =TOP | the person himself | one person | =only |
| ‘The person himself is the only one who doesn’t know.” | ||||
| kaTARU/ | =mo | NAmida, | kiKU/ | =mo | NAmida | =no | monogatari |
| talk | =also | tear | listen to | =also | tear | =GIN | story |
| ‘It is a story that brings tears to the eyes of both the teller and the listener.’ | |||||||
| iKU/ | =mo | iKA | -NU/ | =mo | soNATA-SIdai. | |
| go | =also | go | -NEG | =also | you-up to | |
| ‘It’s up to you whether to go or not.’ | ||||||
| ‘noRU’/ | =mo | ‘maKU’/ | =mo | DAi | SAn | -kan | =da. |
| ride | =also | wind | =also | No. | three | -volume | =COP |
| ‘Both of noru and maku are in volume three.’ | |||||||
These are examples of exceptional combinations of accentless verbs ((a)(b)(d)(e)(f)) or negative ending ((c)) plus particles wa and mo. Such combinations are possible in idiomatic phrases including proverbs ((a)–(e)) and quotation ((f)). In these various environments, wa and mo consistently take low accents.[16]
An observation similar to that above can be made in the case of exceptionally connecting an element other than a noun to another copula. See Example (23) below.
| iKU/ | =da |
| go | =COP |
| ‘(Someone) goes.’ | |
| iKU/ | =detyu |
| go | =COP |
| ‘(Someone) goes.’ | |
| iKU/ | =zamasu |
| go | =COP |
| ‘(Someone) goes.’ | |
| “hiTOri | =de | iKU | =no | =ka?” |
| one person | =by | go | =NMLZ | =Q |
| “iYA. | syaTYŌ | =TO/ | =da.” | |
| no | boss | =COM | =COP | |
| “Will you go by yourself?” “No, with my boss.” | ||||
| soREMO, | koOREI=NO | OYA=o | oI-TE/ | =da. |
| what’s more | high age=GEN | parent=ACC | leave-gerund | =COP |
| ‘What’s more, they left an elder parent alone.’ | ||||
| taBE | -NAGARA/ | =da. |
| eat | -while | =COP |
| ‘It is while eating.’ | ||
| SUgu | iKU/ | =da | nante, | Uso | =baKKAri. |
| right away | go | =COP | such as | lie | =all |
| ‘You said “you’d go right away,” you liar.’ | |||||
| ‘AkkanBEEEE/ | =da.’ |
| (children’s despising behavior) | =COP |
| ‘Buzz off!’ | |
| ‘IIII/ | =da.’ |
| (children’s despising behavior) | =COP |
| ‘Buzz off!’ | |
| ‘soREDE, | GUNYOOOO/ | =tte.’ | |||
| then | (ideophone) | =Q | |||
| ‘It’s warped.’ | |||||
| ‘soRE | =WA | TAsikani, | GUNYOOOO/ | =da | =ne’ |
| it | =TOP | surely | (ideophone) | =COP | =IP |
| ‘You’re right, it is warped.’ | |||||
| koNO | kuURAN | =NI | uMARU | doOSI | =WA | ‘iKU’/ | =da | =na. |
| this | blank | =LOC | fill | verb | =TOP | go | COP | =IP |
| ‘The verb that fills in this blank should be “go.”’ | ||||||||
While, in general, a copula follows a noun, in exceptional cases, a copula may follow a word other than a noun. For example, it may follow a verb in the case of utterances by speakers of rural, small children, or milady-like person types (“kyara,” cf. Sadanobu 2020a), as in Example (a–c). Example (d) classically would be analyzed to involve the omission of iku=no (‘go’ + Genitive) between syatyoo=to (“with president”) and da (copula), leading to the sense of some kind of gap, or boundary, between the two. The same is true of Examples (e) and (f), which classically would be analyzed to involve the omission of =no koto (Genitive + ‘event’) immediately before da. Additionally, Examples (g–j) are cases of da appearing immediately following quotations or utterances resembling quotations (of sugu iku ‘go right away’ in (g), akkanbeee and iii ‘nyah nyah nyah’) in (h), ideophone gunyooo in (i), and iku ‘go’ in (j), and here too one senses a boundary between these utterances and the copula da. These utterances include not only accentless words (iku) but also ones for which the accent pattern is unclear to begin with (akkanbeee, iii, gunyooo); they all are followed by da with a low accent, and thus, they also can be considered to be exceptional cases due to the boundaries.
The same applies to disfluent utterances. See Examples (24), (25), and (26) below.
| wa, | hiTO=GA | iPPAI | =DA | =NAa. |
| INTJ | person=NOM | crowded | =COP | IP |
| ‘Wow, it’s so crowded.’ | ||||
| hiTO | =GA/ | =da | =NAa, | iPPAI/ | =da | =NAa | , haI-tte/=da=NAa, … |
| person | =NOM | =COP | =IP | crowded | COP | =IP | enter-gerund=COP=IP |
| ‘There are so many, … people, … there, and …’ | |||||||
| soNNA KOTO | =wa | guUZEN | =ZYA. |
| such a thing | =TOP | coincidence | =COP |
| ‘That’s a coincidence, isn’t it?’ | |||
| uCHI | =NI/ | =zya | =NOo, | guuzen/ | =zya | =NOo, | i-TE/ | =zya =Noo,… |
| home | =LOC | =COP | =IP | coincidence | =COP | =IP | exist-gerund | =COP=IP |
| ‘They just happened to be at home, and …’ | ||||||||
| SYUkun | =no | meIREI=WA | zeTTAI =DEsu. |
| one’s load | =GEN | order=TOP | absolute =COP |
| ‘The order of one’s lord is absolute.’ | |||
| huSEI | =WA/ | =desu=ne, | zeTTAI/ =desu =ne, |
| improprieties | =TOP | =COP=IP | absolutely =COP =IP |
| yuRUS-Anai=toiu | siSEI | =GA/ | =desu=ne, … |
| allow-NEG=Q | attitude | =NOM | =COM=IP |
| ‘As a rule, improprieties are, absolutely, unacceptable, and …’ | |||
Here, a phrase consisting of an accentless noun plus a copula (ippai=da in (24), guuzen=zya in (25), and zettai=desu in (26)) appears (a) at the end of the sentence and (b) in the middle of the sentence spoken disfluently. As generally there is no problem connecting a noun to a copula, the copula following an accentless noun should take a high accent. However, this is the case only in the (a) examples above, with the copula in the (b) example taking a low accent. This is because, in the (b) examples, the utterances (hito=ga ippai haitte … in (24), uchi=ni guuzen ite … in (25), and husei=wa zettai yurusanai=to=iu sisei=ga … in (26)) are not spoken in a single breath but instead in a disfluent manner with small breaks. This way of speaking has a structure like that of a quotation, in which what the speaker wants to say is cited as “hito=ga,” “ippai,” and “haitte,” and as such, the copulas take low accents because of the boundaries between the phrases and the copula.
3.4 Cases in which no boundary tone is apparent
However, conjunctions positioned on sentence boundaries, which are the largest of all boundaries, exhibit surprising behaviors. See Example (27) below.
| aRUiwa (‘or’), iPPOo (‘on the other hand’), keKKYOKU (‘after all’), maTA (‘also’), moTTOmo (‘but’), siKAsi (‘but’), siTAGATTE (‘consequently’), soKODE (‘therefore’), soNOTAME (‘for that reason’), soNOUE (‘moreover’), soREDE (‘so’), soREDEmo (‘still’), soREDEwa (‘then’), soREKARA (‘and then’), soRENAnoni (‘in spite of that’), soRENAra (‘then’), soRENI (‘in addition’), soRENISITEmo (‘anyway’), soREYUE (‘therefore’), soSITE (‘and’), soOSITE (‘and’), suNAwati (‘namely’), suRUTO (‘and then’), taHOo (‘on the other hand’), taTOeba (‘for example’), tiNAMINI (‘by the way’), toKOROde (‘by the way’), toKOROga (‘however’), yoOSUruni (‘in short’), yuEni (‘therefore’) |
| DAga (‘but’), DAkara (‘so’), DAkedo (‘but’), DAnoni (‘but’), DAtosiTEmo (‘even if’), DAtoyūnoni (‘even though’), DAttara (‘if so’), DAtte (‘because’), DEmo (‘but’), DEsitara (‘if so’), DEsuga (‘but’), DEsukara (‘so’), DEsukedo (‘but’), DEsunode (‘so’), DEwa (‘then’), KEdo (‘but’), NAnode (‘so’), NAnoni (‘nevertheless’), NAo (‘additionally’), NAra (‘then’), NAraba (‘then’), NAzenara (‘as’), NIimokaKAwarazu (‘notwithstanding’) SArani (‘in addition’), SOmosomo (‘in the first place’), TAda (‘however’), TAdasi (‘however’), TOmoare (‘anyway’), TUmari (‘in other words’), ZYAa (‘then’) |
These examples list 60 words that can be considered typical conjunctions. Of these, those listed under (a) have lexical accents that start low (for example, in the first of these conjunctions, aruiwa, the accent on the first mora a is low), while for those under (b), the lexical accent starts high. There is no major difference in the numbers of words in these two groups, with 30 words listed under (a) and 30 under (b). However, when we look solely at conjunctions that begin with copulas, we see that all of these are listed under (b). For these conjunctions, the lexical accent starts high. The five words with dashed underlines are ones for which the naturalness is in doubt (danoni “but”)[17] or for which it is unclear whether or not they can be said to start with a copula (nanode ‘so,’ nanoni ‘nevertheless,’ nara ‘then,’ naraba ‘then’), and thus perhaps they should not be included here. Still, that leaves 15 words with solid underlines. On the other hand, not one word fits in category (a) of those for which the lexical accent starts low.
This tendency of conjunctions, which should appear at the boundaries of sentences, to start with a high accent in all cases, instead of starting with a low accent when starting with a copula, and which should be sensitive to its environment, is most likely to be explained by the fact that the speaker is (hyperbolically speaking) “intentionally” connecting them to the preceding utterances through conjunctions.
The same can be said of utterances that begin with particles, as in the underlined passages of Examples (28) and (29). As these particles are bound, these passages can be said to be grafted speech.
| roKUzi HAn | =yat-ta | -yan-naa |
| six-thirty | =COP-PST | -IP-IP |
| ‘(It) was six-thirty, wasn’t (it)?’ | ||
| Un |
| INTJ |
| ‘Yeah’ |
| NII taDORITUi-te -Naka-ttaRAa | |
| LOC arrive-gerund-NEG-if | |
| ‘(if I) haven’t arrived (there) at,’ | |
| [Taken from Example (4) in Hayashi (2004: 351), with an underline, some omissions and changes of notation are mine.] | |
| Customer: ZYAa, iTINITII ZYŌSYAken | |
| then, all-day pass | |
| ‘Then one all-day pass’ | |
| Staff: WAA Ima uRIKIRE =DESU | |
| ‘Sorry, we’re all sold out.’ | |
As already demonstrated in (14i, m) in Section 3.2, the locative marker ni and the topic marker wa are inconspicuous enclitics (that is to say, their sensitivity to the environment is made known, like a litmus test, by the prosody produced by the speaker). Additionally, nii at the top of (28A2) and waa at the top of the staff’s speech in (29) both have high accents. This is because the speaker, in starting with these dependent parts of grafted speech, is attempting to connect them to the preceding utterances.
Turning at last to the observation of the dependent grafted speech, the central subject of consideration in this paper, we see that the same applies here. In most cases of dependent grafted speech, as seen in Example (30), the elements at the start of the utterance have intrinsic lexical accents (e.g., the word-initial accent in the case of kasira “Is that so?”), and these lexical accents are used when uttering them.
| daRO(o)? (‘Isn’t it?’), daROo=NA(a) (‘It would be so’), daROo=NE(e) (‘It would be so’), deSYO(O)? (‘Isn’t it?’), deSYOo=ka=NE(e) (‘Is that so?’), deSYOo=NA(a) (‘It would be so’), deSYOo=NE(e) (‘It would be so’), KAmo (‘Maybe’), KAmo=NA(a) (‘Maybe’), KAmo=NE(e) (‘Maybe’), KAsira (‘Is that so?’), KAsira=NE(e) (‘Is that so?’), MItai (‘It looks that way’), MItai=NE(e) (‘It looks that way’), MItai=da=NA(a) (‘It looks that way’), MItai=da=NE(e) (‘It looks that way’), raSIi (‘Apparently’), raSIi=NA(a) (‘Apparently’), raSIi=NE(e) (‘Apparently’) |
On the other hand, in principle, those that start with the copulas da and desu, which would tend to conform to their surrounding environment, begin with a high accent. See Example (31).
| DA=to (‘I heard so’),[18] DA=to=SA (‘I heard so’), DA=wa=NA(a) (‘That’s right’), DA=wa=NE(e) (‘That’s right’), DA=wa=yo=NE(e) (‘That’s right’), DA=yo=NA(a) (‘I agree with you’), DA=yo=NE(e) (‘I agree with you’), DEsu=ka=NE(e) (‘Is that so?’), DEsu=NA(a) (‘That’s right’), DEsu=NE(e) (‘That’s right’), DEsu=yo=NE(e) (‘I agree with you’) |
| da=NA(a) (‘It looks that way’), da=NE(e) (‘It looks that way’) |
While for those in (31b), the accent starts low, for those in (31a), it starts high.[19] Unlike the cases of conjunctions and other examples seen previously, instead of all falling into the category of those for which the accent starts high, as in (a), there are some cases that fall into group (b). However, these cases in (b) could be understood as following another kind of regularity, where a dependent word (that is, an inconspicuous word) in the mora immediately preceding an interactional particle na(a) or ne(e) at the end of utterances takes a low accent. This regularity applies not only to (b) but to (a) as well. For example, in da=yo=na(a) (‘I agree with you’), the yo has a low accent. Furthermore, it also can be observed in ka=na(a) (‘I am not sure’ Example (4) in Section 2) and ka=ne(e) (“I am not sure”), which do not start with copulas. In these cases, ka has a low accent. Thus, it has a high degree of generality.[20]
However, if the observations above are valid, then we probably would need to review our understanding of the boundaries of utterances. The view of boundaries up till now has held that boundaries are assigned by parts of speech, and the meanings of sentences and prosody (or, in this case, lexical accent) reflect these boundaries. This is illustrated in Figure 3 below.

The traditional view of boundaries. The vertical line indicates a boundary, the boxes “Word 1” and “Word 2” indicates inconspicuous words, and horizontal lines indicate low tones as boundary tones.
In Figure 3, there is a boundary between “Word 1” and “Word 2,” and as these words are inconspicuous, a low tone occurs before and after these boundaries to reflect these, as a boundary tone (or a low accent as described in Section 3.3).
The view of boundaries in Figure 3 is valid for our observations through Section 3.3. However, it is unable to explain the fact that the lexical accent begins high in the cases of utterances of conjunctions starting with copulas ((30b)) and those starting with particles and binding particles ((31) (32)), or the fact that in principle the accent starts high in the case of grafted speech beginning with a copula ((31a)), as seen here in Section 3.4. See Figure 4 below.
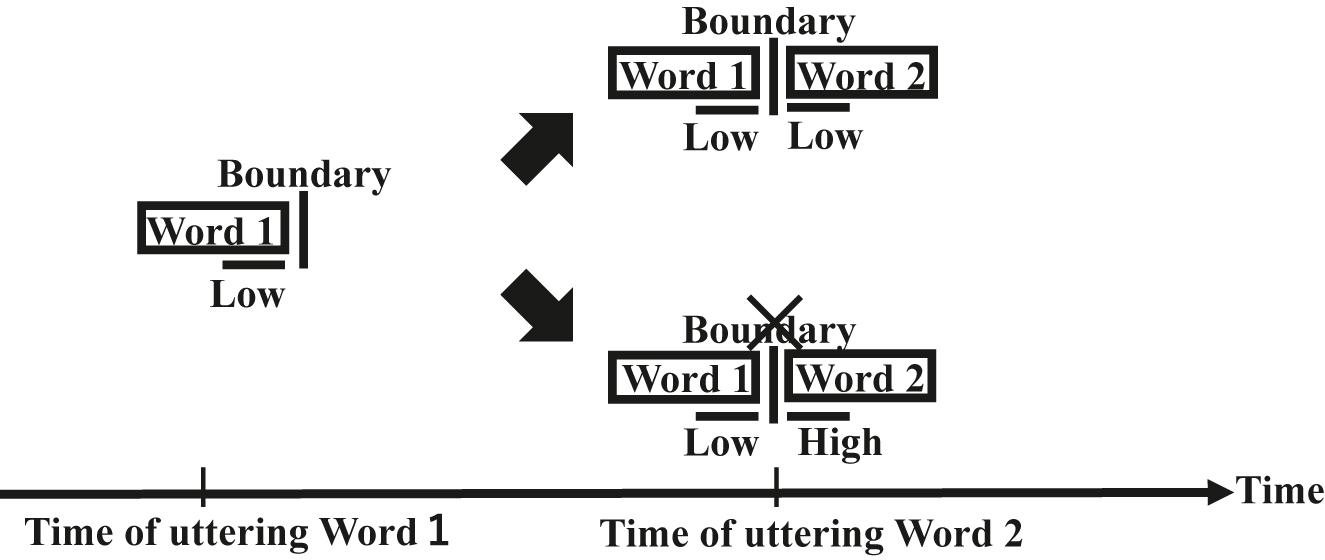
The view of boundaries proposed by this paper. The vertical line indicates a boundary, and the horizontal lines indicate boundary tones. The top arrow points to when Word 1 is not intentionally connected to Word 2; the bottom arrow points to when Word 1 is intentionally connected to Word 2. The horizontal axis indicates an abstract time.
Unless intentionally connecting a new utterance (Word 2 in the figure) to one already uttered (Word 1 in the figure), a boundary tone appears before and after the boundary, as seen in Figure 3. However, when intentionally connecting the new utterance to the one already uttered, the boundary is canceled ex post facto, and as a result, the boundary tone remains only before the boundary (the developments from left to bottom right in Figure 4).
In summing up, the initial high accent of dependent grafted speech listed in (31a) reveals that the speaker cancels the boundary when they utter them. This indicates that the speech that we call “dependent grafted speech” resembles a conjunction type of speech far from the full-fledged sentence type of speech. Its “dependency” is not just nominal or conceptual but real and substantial, with prosodic substantiation.
4 Ending intonation of dependent grafted speech
Let us observe the ending prosody of dependent grafted speech—particularly its intonation.
As used here, the end of dependent grafted speech utterance refers specifically to the interactional particle.[21] While this is considered in more detail in other papers (Sadanobu 2014, 2020b), due to its dependent nature, dependent grafted speech will, in most cases, require an interactional particle at its end. For example, while a survey of 44 native Japanese-speaking students at universities in the Kansai area (conducted May 14, 2019) demonstrated that while the informants tended to view answers to the question Ano hito=tte, hanasi, nagakunai? (“Doesn’t that person talk a lot?”) that lacked interactional particles, such as da, desu, and ka, as unnatural utterances, they tended to consider that utterances followed by interactional particles, such as da=na, da=ne, da=yo=na, da=yo=ne, desu=nee, and ka=naa, sounded natural ((32) (33) (34)). Below, for each utterance ending, the number of speakers who considered it natural (on the left) is separated by a slash (“/”) from the number of speakers who considered it unnatural (on the right).
| [When asked Ano hito=tte, hanasi, nagakunai? “Doesn’t that person talk a lot?”] |
| DA. | 1/43 |
| COP | |
| ‘(Lit.) That’s true.’ | |
| da | =NA. | 43/1 |
| COP | =IP | |
| ‘That’s true.’ | ||
| da | =NE. | 42/2 |
| COP | =IP | |
| ‘That’s true.’ | ||
| DA | =yo | =NA. | 43/1 |
| COP | =IP | =IP | |
| ‘Definitely.’ | |||
| DA | =yo | =NE. | 44/0 |
| COP | =IP | =IP | |
| ‘Definitely.’ | |||
| [When asked Ano hito=tte, hanasi, nagakunai? “Doesn’t that person talk a lot?”] |
| DEsu. | 2/42 |
| COP | |
| ‘(Lit) That’s true.’ | |
| Desu | =NEe. | 42/2 |
| COP | =IP | |
| ‘That’s true.’ | ||
| [When asked Ano hito=tte, hanasi, nagakunai? “Doesn’t that person talk a lot?”] |
| Ka. | 2/42 |
| Q | |
| ‘(Lit.) Is that so?’ | |
| ka | =NAa. | 41/3 |
| Q | =IP | |
| ‘I am not sure.’ | ||
As the above examples demonstrate, interactional particles often appear in dependent grafted speech. Here in Section 4, we will observe the intonation of these interactional particles.
From the tendencies in boundary tones in modern standard Japanese discussed in Section 3.3 (19) (reproduced as (32)), as with a lexical accent, a tendency can be identified for intonations to be lower before and after a boundary as well (33).[22]
From this tendency, the intonation of an interactional particle at the end of dependent grafted speech would be expected to be lower. However, this expectation often does not hold true. The intonation of an interactional particle tends not to be a falling one. While it is not the case that there are no examples of a falling intonation, the environments in which they appear are limited. Let us consider this point specifically using =da=yo=ne, which was judged to sound natural by all informants in the survey mentioned above (32e), as an example.
As illustrated in Section 3.4, the copula da at the beginning of =da=yo=ne has a high accent, and this is reflected in F0 as a high tone. The yo that follows it has a low tone in accordance with the regularity under which the accent of a dependent word in the mora immediately before interactional particle na(a) or ne(e) at the end of utterances takes a low accent (see Section 3.4). Our chief concern, the ending ne, might be spoken with a rising intonation that goes from a low to a high tone. Additionally, under the non-gradual, very abrupt rising intonation referred to hereafter as a “leaping” intonation,[23] ne might be spoken with an abruptly higher tone than yo (i.e., =yo=ne sounds as if it were an accentual sequence LH) as an auditory impression. On the other hand, ne is never uttered with a falling intonation that falls from a low tone to an even lower one. While it may be spoken with a falling intonation, this occurs only in cases in which the tone returns from a high one immediately after a leaping intonation (i.e., =da=yo=nee sounds roughly like HLHL).
We have seen above, the intonation of an interactional particle at the end of dependent grafted speech, which is the subject under consideration here, (i) basically does not fall, and (ii) the cases in which it does fall are limited to those of returning from a leaping intonation. These two points seem to have something important to tell us about the status of dependent grafted speech.
We will consider the second point first. Previous research on the [leaping intonation with a falling end] (Kōri 1996: 69) described it as not appearing at the end of a sentence. While there are exceptions to this description, such as the way the sentence Hara=ga tatuu! (“That makes me so angry!”) may end with a [leaping intonation with a falling end] (roughly like LHLLHL), it describes a tendency. For example, while in Dakara, are=wa, iya=na=no (“That’s why I hate it”) the phrases dakara and are=wa may be pronounced using a [leaping intonation with a falling end], as dakaraa (roughly like HLHL) and are=waa (roughly like LH SuperH L), only the sentence-final phrase iya=na=no may not be pronounced using a [leaping intonation with a falling end] (roughly like LHLHL). We should accept the tendency that a [leaping intonation with a falling end] will not appear in the final phrase of a sentence (Sadanobu 2016: Chapter 4, Section 6.2). The fact that the interactional particle at the end of dependent grafted speech may be uttered using a [leaping intonation with a falling end] without difficulty suggests that the end of dependent grafted speech does not follow the pattern of the end of a sentence—that is, that dependent grafted speech does not resemble a sentence.
The same can be seen with regard to the first point above—that the intonation of an interactional particle, which is the subject under consideration here, basically does not fall. This is because the phenomenon by which the intonation of an interactional particle basically does not fall without being proceeded by a leaping intonation can be observed when an interactional particle appears in the middle, rather than the end, of a sentence (Sadanobu 2019).
For example, the phrase yame=te=yo (“stop it”) uttered with a falling intonation on the ending interactional particle yo (roughly like LHHL) is heard only as an utterance of a woman asking somebody to stop doing something. That is, this is the sentence speech of yame=te=yo. It does not sound like a spoken phrase (i.e., phrase speech) within a sentence (… yame=te=yo, … ‘I stopped it and …’). For it to sound like phrase speech within a sentence, it would need to be pronounced with a leaping intonation immediately before the falling intonation, such as yame=te=yoo, … (roughly like LHH SuperH L). Spoken in this way, it would sound like phrase speech within a sentence (and not like sentence speech), as in ore=ga=yoo, sore=o=yoo, yame=te=yoo, sorede=yoo (“I stopped it and …”), although in this case, the speaker’s person-type changes to that of a vulgar male type.
As another example, the phrase sore=de=sa uttered with a falling intonation on the interactional particle sa at its end (roughly like LHHL) can only be heard as an utterance with a meaning such as “That’s why.” It sounds like a sentence, but not like a phrase in the middle of a sentence. To sound as a phrase uttered in the middle of a sentence, it would need to have a leaping intonation immediately before the falling intonation, as in sore=de=saa (roughly like LHH SuperH L). In this way, it no longer sounds like sentence speech but sounds only like phrase speech in the middle of a sentence.
One more example is the phrase koi=ne spoken with a falling intonation on the interactional particle ne at its end (roughly like HL SuperL). It can only be heard as an utterance with the meaning of acknowledging the strength of something. It sounds like a sentence (Koi=ne. “It is strong.”), but does not sound like a phrase in the middle of a sentence (koi=ne, …). While if uttered with a leaping intonation immediately before the falling intonation, as in koi nee (roughly like HLHL), it could still be a case of sentence speech (as in Kono kōhī, koi=nee. “This coffee is strong!”). It also could sound like phrase speech within a sentence (as in Koi=nee, kōhī=o=nee, non=de=nee, … “I drank strong coffee and …”). The interactional particle na follows the same pattern as seen here for ne.
More strictly speaking, the only interactional particles that may be spoken with an intonation that includes a falling intonation, as a [leaping intonation with a falling end], when appearing at the end of a phrase in the middle of a sentence are yo, sa, and ne, as seen above, and na. When they appear at the end of a phrase within a sentence, other interactional particles will, in principle, lose the possibility of a falling pattern and be spoken with a rising intonation. For example, an interactional particle such as zo said to appear only at the end of a sentence, may appear at the end of a phrase within a sentence, as in Minna=de taisetsu=ni sodatete ita, sono hana=o=da=zo, heiki=de musiritot=te, … (“To tear out remorselessly those flowers that everybody had taken such good care of, …”), and in such a case the interactional particle has a rising intonation.[24]
To summarize the above, the interactional particle (e.g., ne) at the end of dependent grafted speech (e.g., da=ne) is not uttered with falling intonation (i.e., da=ne cannot sound like HL) unless it is proceeded by a leaping intonation (i.e., da=ne can sound like LHL). While this restriction of intonation pattern cannot be found for interactional particles at the end of a sentence, interactional particles in the middle of a sentence generally have the same restriction of intonation (e.g., Ne of koi=ne in the middle of a sentence cannot be uttered as a falling intonation without being proceeded by a leaping intonation). These all indicate that the end part of dependent grafted speech is not like that of a sentence.
5 Conclusion
This paper intensively examined the lexical accent of copulas at the start of Japanese dependent grafted utterances (Section 3) and the intonation of their ending interactional particles (Section 4), together with the prosody of various other words, phrases, and sentences. The investigation results reveal that both the starting and ending parts of dependent grafted speech do not look like those of a sentence. These findings cast doubt on the grammatical status of dependent grafted speech as a sentence and contrast with long-held views guided by sententialism that maintained that discourse consists of sentences. Rather, the findings presented in this paper open up doors to a new concept of discourse, as a mixture of diverse constituents, including sentences, but also dependent grafted speech.
Funding source: Ministry of Education, Culture, Sports, Science and Technology, Grant-in-Aid for Scientific Research
Award Identifier / Grant number: 20H05630
Funding source: NINJAL-Project
Acknowledgments
We thank our colleagues, especially Donna Erickson, for their help. We also acknowledge the helpful comments provided by two anonymous reviewers.
-
Research funding: This study was partially supported by the Ministry of Education, Culture, Sports, Science and Technology, Grant-in-Aid for Scientific Research (S), 20H05630, and by NINJAL-Project “Cross-linguistic studies of Japanese prosody and grammar” and “Multiple approaches to analyzing the communication of Japanese language learners.”
References
Akinaga, Kazue. 1966. Nihongo no hatsuon: Intonēshon nado [Pronunciation of Japanese language: Intonation and so on]. Kōza Nihongokyōiku 2. 48–60.Suche in Google Scholar
Beckman, Mary E. & Janet B. Pierrehumbert. 1986. Intonational structure in Japanese and English. In Colin J. Ewen & John M. Anderson (eds.), Phonology yearbook: An annual journal, vol. 3, 255–309. Cambridge: Cambridge University Press. https://doi.org/10.1017/s095267570000066x.Suche in Google Scholar
Chafe, Wallace. 2001. The analysis of discourse flow. In Deborah Schiffrin, Deborah Tannen & Heidi Ehernberger Hamilton (eds.), The handbook of discourse analysis, 673–687. MA: Blackwell.10.1002/9780470753460.ch35Suche in Google Scholar
Gordon, Matthew & Ladefoged Peter. 2001. Phonation types: A cross-linguistic overview. Journal of Phonetics 29. 383–406. https://doi.org/10.1006/jpho.2001.0147.Suche in Google Scholar
Hayashi, Makoto. 2004. Discourse within a sentence: An exploration of postpositions in Japanese as an interactional resource. Language in Society 33. 343–376. https://doi.org/10.1017/s0047404504043027.Suche in Google Scholar
Hyman, Larry M. & William R. Leben. 2000. Suprasegmental processes. In Geert Booij, Christian Lehmann & Joachim Mugdan (eds.), in collaboration with Wolfgang Kesselheim & Stavros Skopeteas, Morphology: An international handbook on inflection and word-formation, vol. 1, 587–594. Berlin; New York: Walter de Gruyter. https://doi.org/10.1515/9783110111286.1.8.587.Suche in Google Scholar
Kawakami, Shin. 1956. Kyōchō no shurui [Variety of emphasis]. Gengo Kenkyu 31. 63–64.10.5979/cha.1956.64Suche in Google Scholar
Kōri, Shirō. 1996. Onsei no tokuchō kara mita bun [Sentence from the perspective of the feature of speech]. Nihongogaku 10(15). 60–70.Suche in Google Scholar
Kōri, Shirō. 1997. Nihongo no intonēshon: Kata to kinō [Japanese intonation: Forms and functions]. In Miyoko Sugitō (supervised), Tetsuya Kunihiro, Hajime Hirose & Morio Kōno (eds.), Akusento, Intonēshon, Rizumu to Pōzu [Accent, intonation, rhythm, and pause], 169–202. Tokyo: Sanseido.Suche in Google Scholar
Liu, Yajin. 2010. Danwa reberu kara mita ‘da’ no imi kinō: ‘Da’ no tandoku yōhō o chūshin ni [Semantic function of ‘da’ from the perspective of the discourse level: With a focus on da’s absolute usage]. Tsukuba Working Papers in Linguistics 3. 90–107.Suche in Google Scholar
Lyons, John. 1968. Introduction to theoretical linguistics. Cambridge: Cambridge University Press.10.1017/CBO9781139165570Suche in Google Scholar
McCawley, James D. 1968. The phonological component of a grammar of Japanese. The Hague: Mouton.Suche in Google Scholar
Miyaji, Yutaka. 1963. Intonēshon [Intonation]. Hanashikotoba no Bunkei 2: Dokuwa shiryō niyoru Kenkyū, 178–208. Tokyo: Shūei Shuppan.Suche in Google Scholar
Nitta, Yoshio. 2016. Bun to Jitai Ruikei o Chūsin ni [Centering sentence and types of events]. Tokyo: Kurosio Publishers.Suche in Google Scholar
Noji, Jun’ya. [1946] 2005. Onna kyōshi no kotoba no seitai [Ecology of female teachers’ speech]. In Jun’ya Noji (ed.), Hanashikotoba no Kyouiku [Education of spoken language], 53–60. Tansuisha: Hiroshima.Suche in Google Scholar
Oki, Hiroko. 2006. Nihongo Danwaron [Discussing Japanese discourse]. Osaka: Izumi Shoin.Suche in Google Scholar
Ōishi, Hatsutatō. [1959] 1980. Purominensu nitsuite: Tōkyōgo no kansatsu ni motoduku oboegaki [On prominence: A note based on observation of Tokyo dialect]. In Takeshi Shibata, Hajime Kitamura & Haruhiko Kindaichi (eds.), Nihon no Gengogaku Vol. 2 On’in, 594–612. Tokyo: Taishukan Publishing Co.Suche in Google Scholar
Ōiwa, Masanaka. 1949. Bun no teigi [Definition of sentence]. Kokugogaku 3. 309–332. https://doi.org/10.7312/garr92804-015.Suche in Google Scholar
Sadanobu, Toshiyuki. 1999. Akusento o gouseisuru towa nani o dousuru koudouka [What is it to synthesize accent?]. In Onseibunpoukenkyūkai (ed.), Bunpou to Onsei, vol. 2, 151–171. Tokyo: Kurosio Publishers.Suche in Google Scholar
Sadanobu, Toshiyuki. 2000. Ninchigengoron [A cognitive study on language]. Tokyo: Taishukan Publishing Co.Suche in Google Scholar
Sadanobu, Toshiyuki. 2012. Fukuzatsuna kouzou o motsu Nihongo onseigengo no kihonteki kansatsu [A basic observation on spoken Japanese with complex structure]. Proceedings of Japanese Cognitive Science Society 29. 559–566.Suche in Google Scholar
Sadanobu, Toshiyuki. 2014. Hanashikotoba ga konomu fukuzatsuna kouzou: Kimochi ketsuboushou o chūshin ni [Preference of complex structure by spoken language: With a focus on the deficiency of expressiveness]. In Kei Ishiguro & Yukihiro Hashimoto (eds.), Hanashikotoba to Kakikotoba no Setten, 13–36. Tokyo: Hituzi Syobo.Suche in Google Scholar
Sadanobu, Toshiyuki. 2015. Four types of linguistic resources for variable speaking units in common Japanese. Journal of the Phonetic Society of Japan 19(2). 109–114.Suche in Google Scholar
Sadanobu, Toshiyuki. 2016. Komyunikēshon eno Gengoteki Sekkin [A linguistic approach to communication]. Tokyo: Hituzi Syobo.Suche in Google Scholar
Sadanobu, Toshiyuki. 2017. Hatsuwa ga umidasu akusento [Accent produced by the act of speaking]. In Yō Gaiei Kyōju Kanreki Kinen Ronbunshū Kankōkai (ed.), Yō Gaiei Kyouju Kanreki Kinen Ronbunshū Chūnichi Gengo Kenkyū Ronsou, 333–354. Tokyo: Asahi Press.Suche in Google Scholar
Sadanobu, Toshiyuki. 2019. Bunsetsu no Bunpou [A grammar of Bunsetsu]. Tokyo: Taishukan Publishing Co.Suche in Google Scholar
Sadanobu, Toshiyuki. 2020a. Komyunikēshon to Gengo niokeru Kyara [Kyara in communication and language]. Tokyo: Sanseido.Suche in Google Scholar
Sadanobu, Toshiyuki. 2020b. Jiritsusei ga nai Nihongo ‘tsugiho hatsuwa’ no imi-goyouron [A semantics/pragmatics of Japanese ‘grafted speech’ without free words]. Journal of the Japanese Association of Language Proficiency 8. 77–94.Suche in Google Scholar
Shioda, Takehiro. 2016. Joshi, jodoushi nado no fuzokugo ga tsuita toki no hatsuon to akusento [Pronunciation and accent in cases clitics such as particles and auxiliary verbs are attached]. In NHK Broadcasting Culture Research Institute (ed.), NHK Japanese Pronunciation Dictionary, Appendix, 200–255. Tokyo: NHK Publishing, Inc.Suche in Google Scholar
Smith, Carlota S. 2003. Modes of discourse: The local structure of texts. Cambridge, UK: Cambridge University Press.10.1017/CBO9780511615108Suche in Google Scholar
Tanaka, Akio. 1973. Shūjoshi to kantoujoshi [Sentence-final particles and phrase-final particles]. In Kazuhiko Suzuki & Ōki Hayashi (eds.), Joshi [Postpositional particles], 209–247. Tokyo: Meiji Shoin.Suche in Google Scholar
© 2021 Toshiyuki Sadanobu, published by De Gruyter, Berlin/Boston
This work is licensed under the Creative Commons Attribution 4.0 International License.
Artikel in diesem Heft
- Frontmatter
- Editorial
- Editorial
- Articles
- Is discourse made up of sentences? Focusing on dependent grafted speech in modern standard Japanese
- Correlating cognitive effort and noun role in spoken Japanese
- A formal approach to role language: sentence-final particles and the speaker-hearer link
- Discourse functions and pitch patterns of the Japanese interactional particle yo in student-professor conversation
- The interrogative intonation in the Kunigami dialect of Okinoerabu, Ryukyu
- Book Reviews
- Wesley M. Jacobsen and Yukinori Takubo: Handbook of Japanese Semantics and Pragmatics
- Hisashi Noda: Nihongo to sekai no gengo no toritate-hyōgen
- Mayumi Usami: Shizen kaiwa bunseki e no goyōronteki apurōchi: BTSJ kōpasu o riyōshite
Artikel in diesem Heft
- Frontmatter
- Editorial
- Editorial
- Articles
- Is discourse made up of sentences? Focusing on dependent grafted speech in modern standard Japanese
- Correlating cognitive effort and noun role in spoken Japanese
- A formal approach to role language: sentence-final particles and the speaker-hearer link
- Discourse functions and pitch patterns of the Japanese interactional particle yo in student-professor conversation
- The interrogative intonation in the Kunigami dialect of Okinoerabu, Ryukyu
- Book Reviews
- Wesley M. Jacobsen and Yukinori Takubo: Handbook of Japanese Semantics and Pragmatics
- Hisashi Noda: Nihongo to sekai no gengo no toritate-hyōgen
- Mayumi Usami: Shizen kaiwa bunseki e no goyōronteki apurōchi: BTSJ kōpasu o riyōshite