Individualized treatment rules under stochastic treatment cost constraints
-
Hongxiang Qiu
 ,
Marco Carone
,
Marco Carone

Abstract
Estimation and evaluation of individualized treatment rules have been studied extensively, but real-world treatment resource constraints have received limited attention in existing methods. We investigate a setting in which treatment is intervened upon based on covariates to optimize the mean counterfactual outcome under treatment cost constraints when the treatment cost is random. In a particularly interesting special case, an instrumental variable corresponding to encouragement to treatment is intervened upon with constraints on the proportion receiving treatment. For such settings, we first develop a method to estimate optimal individualized treatment rules. We further construct an asymptotically efficient plug-in estimator of the corresponding average treatment effect relative to a given reference rule.
1 Introduction
The effect of a treatment often varies across subgroups of the population [1,2]. When such differences are clinically meaningful, it may be beneficial to assign treatments strategically depending on subgroup membership. Such treatment assignment mechanisms are called individualized treatment rules (ITRs). A treatment rule is commonly evaluated on the basis of the mean counterfactual outcome value it generates – what is often referred to as the treatment rule’s value – and an ITR with an optimal value is called an optimal ITR. There is an extensive literature on estimation of optimal ITRs and their corresponding values using data from randomized trials or observational studies [3,4,5, 6,7].
Most existing approaches for estimating ITRs do not incorporate real-world resource constraints. Without such constraints, an optimal ITR would assign the treatment to members of a subgroup provided there is any benefit for such individuals, even when this benefit is minute. In contrast, under treatment resource limits, it may be more advantageous to reserve treatment for subgroups with the greatest benefit from treatment. This issue has received attention in the recent work. Luedtke and van der Laan developed methods for estimation and evaluation of optimal ITRs with a constraint on the proportion receiving treatment [8]. Qiu et al. instead considered related problems in settings in which instrumental variables (IVs) are available [9]. In one of the settings they considered, the same resource constraint is imposed as in the study by Luedtke and van der Laan [8], but a binary IV is used to identify optimal ITRs even in settings in which there may be unmeasured confounders. In another setting considered in the study by Qiu et al. [9], the authors considered interventions on a causal IV or encouragement status and developed methods to estimate individualized encouragement (rather than treatment) rules with a constraint on the proportion receiving both encouragement and treatment [10]. They also developed nonparametrically efficient estimators of the average causal effect of optimal rules relative to a prespecified reference rule. Sun et al. [11] considered a setting in which the cost of treatment is random and dependent on baseline covariates. They developed methods to estimate optimal ITRs under a constraint on the expected additional treatment cost compared to control, though inference on the impact of implementing the optimal ITR in the population was not studied [11]. Sun [12] considered a related problem involving the development of optimal ITRs under resource constraints and established the asymptotic properties of the estimated optimal ITR. Their method appears viable when the class of ITRs is restricted by the user a priori.
In this article, we study estimation and inference for an optimal rule under two different cost constraints. The first is the same as appearing in the study by Sun et al. [11]. In contrast to earlier work on this setting, we do not constrain the class of ITRs considered and provide a means to obtain inference about the optimal ITR. The second constraint we consider places a cap on the total cost under the rule rather than on the incremental cost relative to control. To our knowledge, the latter problem has not previously been considered in the literature. Both of these estimation problems mirror the intervention-on-encouragement setting considered in the study by Qiu et al. [9] but involve different constraints and a more general cost function.
Similarly as in the study by Qiu et al. [9], the estimators that we develop are asymptotically efficient within a nonparametric model and enable the construction of asymptotically valid confidence intervals (CIs) for the impact of implementing the optimal rule. We develop our estimators using similar tools – such as semiparametric efficiency theory [13,14] and targeted minimum loss-based estimation (TMLE) [15,16] – as were used to tackle the related problem studied in the study by Qiu et al. [9]. Consequently, our proposed estimators are similar to that presented in the study by Qiu et al. [9]. Therefore, we will streamline the presentation by highlighting the key similarities and focusing on the differences between these related problems and estimation schemes.
The rest of this article is organized as follows. In Section 2, we describe the problem setup, introduce notation, and present the causal estimands along with basic causal conditions. In Section 3, we present additional causal conditions and the corresponding nonparametric identification results. In Section 4, we present our proposed estimators and their theoretical properties. In Section 5, we present a simulation illustrating the performance of our proposed estimators. We make concluding remarks in Section 6. Proofs, technical conditions, and additional simulation results can be found in the Supplementary material.
2 Setup and objectives
To facilitate comparisons with the study by Qiu et al. [9], we adopt similar notation. Suppose that we observe independent and identically distributed data units
In this work, we adopt the potential outcomes framework [17,18]. For each individual, we use
Condition A1
(Stable unit treatment value assumption) The counterfactual data unit of one individual is unaffected by the treatment assigned to other individuals, and there is only a single version of the treatment, so that
Remark 1
The ITRs we consider are not truly individualized, because they are based on the value of covariate
We define
where
Remark 2
Our setup is similar to that in the study by Qiu et al. [9] if we view
To evaluate an optimal ITR
3 Identification of causal estimands
In this section, we present nonparametric identification results. Though these results are similar to those for individualized encouragement rules in the study by Qiu et al. [9], there are two key differences. First, the form of some of the conditions in the study by Qiu et al. [9] need to be modified to account for the novel resource constraint considered here. Second, two additional conditions are needed to overcome challenges that arise due to this new constraint.
We first introduce notation that will be useful when presenting our identification results and our proposed estimators. For any observed-data distribution
We introduce additional causal conditions we will require, positivity and unconfoundedness. In one form or another, these conditions commonly appear in the causal inference literature [16], including in the IV literature [30,31, 32,33].
Condition A2
(Strong positivity). There exists a constant
Condition A3
(Unconfoundedness of treatment). For each
Equipped with these conditions, we are able to state a theorem on the nonparametric identification of the mean counterfactual outcomes and average treatment effect (ATE) – these results can be viewed as a corollary of the well-known G-formula [34].
Theorem 1
(Identification of ATE and expected treatment resource expenditure). Provided Conditions
A1–A3
are satisfied, it holds that
In view of Theorem 1, the objective function in (1) can be identified as follows:
and, similarly, the expected cost is identified as
This differs from equation (3) defining optimal individualized encouragement rules in the study by Qiu et al. [9]. We now present two additional conditions so that (2) is a fractional knapsack problem [35], thereby allowing us to use existing results from the optimization literature. These conditions are similar to those in the study by Sun et al. [11].
Condition A4
(Strictly costlier treatment). There exists a constant
Condition A5
(Financial feasibility of assigning treatment). The inequality
Condition A4 is reasonable if the treatment is more expensive than control. When applied to an IV setting as outlined in Remark 2, this condition corresponds to the assumption that the IV is indeed an encouragement to take treatment. This condition is slightly stronger than its counterpart in the study by Sun et al. [11], which only requires that
Under these two additional conditions, (2) is a fractional knapsack problem [35] in which every subgroup defined by a different value of
Theorem 2
(Optimal ITR). Under Conditions A1–A5, a solution to (2) is explicitly given by
Here, the first case is the boundary case with the randomization probability that saturates the treatment resource.
We also note that the reference ITRs introduced in Section 2 are also identified under the aforementioned conditions. In particular, it can be shown that
4 Estimating and evaluating optimal ITRs
In this section, we present an estimator of an optimal ITR
We begin by introducing some notations that are useful for defining the estimands. We define the parameter
4.1 Pathwise differentiability of the ATE
We first present a result regarding the pathwise differentiability of the ATE. Pathwise differentiability of the parameter of interest serves as the foundation for constructing asymptotically efficient estimators of this parameter, based on which an inferential procedure may be developed. Additional technical conditions are required and are provided in Section S1 in the Supplementary Material. For a distribution
One key condition we rely on is the following nonexceptional law assumption.
Condition B1
(Nonexceptional law).
Under this condition, the true optimal ITR
We can now provide a formal result describing the pathwise differentiability of the ATE parameter.
Theorem 3
(Pathwise differentiability of the ATE). Let
We note that the pathwise differentiability of
for
Remark 3
We have noted similar additional terms related to the resource being used in the canonical gradient of the mean counterfactual outcome or ATE of optimal ITRs under resource constraints, for example, in the studies by Luedtke and van der Laan [8] and Qiu et al. [9]. In our problem, this additional term is
Such terms appear to come from solving a fractional knapsack problem with truncation at zero and take the form of a product of (i) the threshold in the solution, and (ii) a term that equals the influence function of the resource being used under the solution when the resource is saturated. We conjecture that such structures generally exist for fractional knapsack problems.
4.2 Proposed estimator and asymptotic linearity
We next present our proposed nonparametric procedure for estimating an optimal ITR
Use the empirical distribution
Estimate an optimal ITR:
Estimate
Let
The rule
Compute
if
(5)then take
otherwise, set
Estimate
Obtain an estimate
For
For
obtain a targeted estimate
take
For
Estimate ATE of
obtain a targeted estimate
with
where
The aforementioned procedure is similar to that proposed in the study by Qiu et al. [9]. One key difference is the use of the refined estimator
The aforementioned procedure has both similarities and substantial differences compared to the estimation procedure proposed by Sun et al. [11]. The main difference is that our procedure is targeted towards efficient estimation of and inference about the ATE of
Remark 4
In Step 1 of the aforementioned procedure, we estimate the functions
Remark 5
In Step 2(a), it is also viable to use other efficient estimators of
We now present results on the asymptotic linearity and efficiency of our proposed estimator. We state and discuss the technical conditions required by the theorem below in Supplement S1.
Theorem 4
(Asymptotic linearity of ATE estimator) Let
Therefore,
To conduct inference about
Remark 6
It may be desirable to use cross-fitting [41,42] to estimate an optimal ITR for better finite-sample performance. The asymptotic linearity is maintained by a similar argument that is used to prove Theorem 4. We describe this algorithm in Section S3 in the Supplementary Material.
Remark 7
We note that, unlike the study by Qiu et al. [9] where the bound
5 Simulation
5.1 Simulation setting
In this simulation study, we investigate the performance of our proposed estimator of the ATE of an optimal ITR relative to specified reference ITRs. We focus here on the setting
We generate data from a model in which the treatment
We introduce
The ITRs we consider are based on all covariates – that is, we take
To evaluate the performance of our proposed estimator, we investigate the bias and root-mean-squared error (RMSE) of the estimator. We also investigate the coverage probability and the width of nominal 95% Wald CIs constructed using influence function-based standard error estimates. We further investigate the probability that our confidence lower limit falls below the true ATE, that is, the coverage probability of the 97.5% Wald confidence lower bound.
5.2 Simulation results
Table 1 presents the performance of our proposed estimator in this simulation. For sample sizes 500, 1,000 and 4,000, the CI coverage of our proposed method is lower than the nominal coverage 95%. When sample size is larger (16,000), the CI coverage of our proposed method increases to 90–93%. The coverage of the confidence lower bounds is much closer to nominal (97.5%) for all sample sizes considered, though, and is always approximately nominal when the sample size is large. For all reference ITRs, the bias and RMSE of our proposed estimator appear to converge to zero faster than and at the same rate as the square root of sample size, respectively. All biases are negative, which is expected in view of Remark 6. All standard errors underestimate the variation of the estimator with the extent decreasing as sample size increases.
Performance of estimators of ATEs in the simulation with nuisance functions estimated via machine learning
| Performance measure | Sample size |
|
|
|
|---|---|---|---|---|
| 95% Wald CI coverage | 500 |
|
|
|
| 1,000 |
|
|
|
|
| 4,000 |
|
|
|
|
| 16,000 |
|
|
|
|
| 97.5% confidence lower | 500 |
|
|
|
| bound coverage | 1,000 |
|
|
|
| 4,000 |
|
|
|
|
| 16,000 |
|
|
|
|
| Bias | 500 |
|
|
|
| 1,000 |
|
|
|
|
| 4,000 |
|
|
|
|
| 16,000 |
|
|
|
|
| RMSE | 500 | 0.056 | 0.039 | 0.046 |
| 1,000 | 0.039 | 0.025 | 0.031 | |
| 4,000 | 0.017 | 0.009 | 0.012 | |
| 16,000 | 0.009 | 0.004 | 0.005 | |
| Ratio of mean standard error | 500 | 0.620 | 0.620 | 0.571 |
| to standard deviation | 1,000 | 0.683 | 0.673 | 0.637 |
| 4,000 | 0.868 | 0.765 | 0.809 | |
| 16,000 | 0.913 | 0.870 | 0.906 |
Figure 1 presents the width of the Wald CIs scaled by the square root of sample size
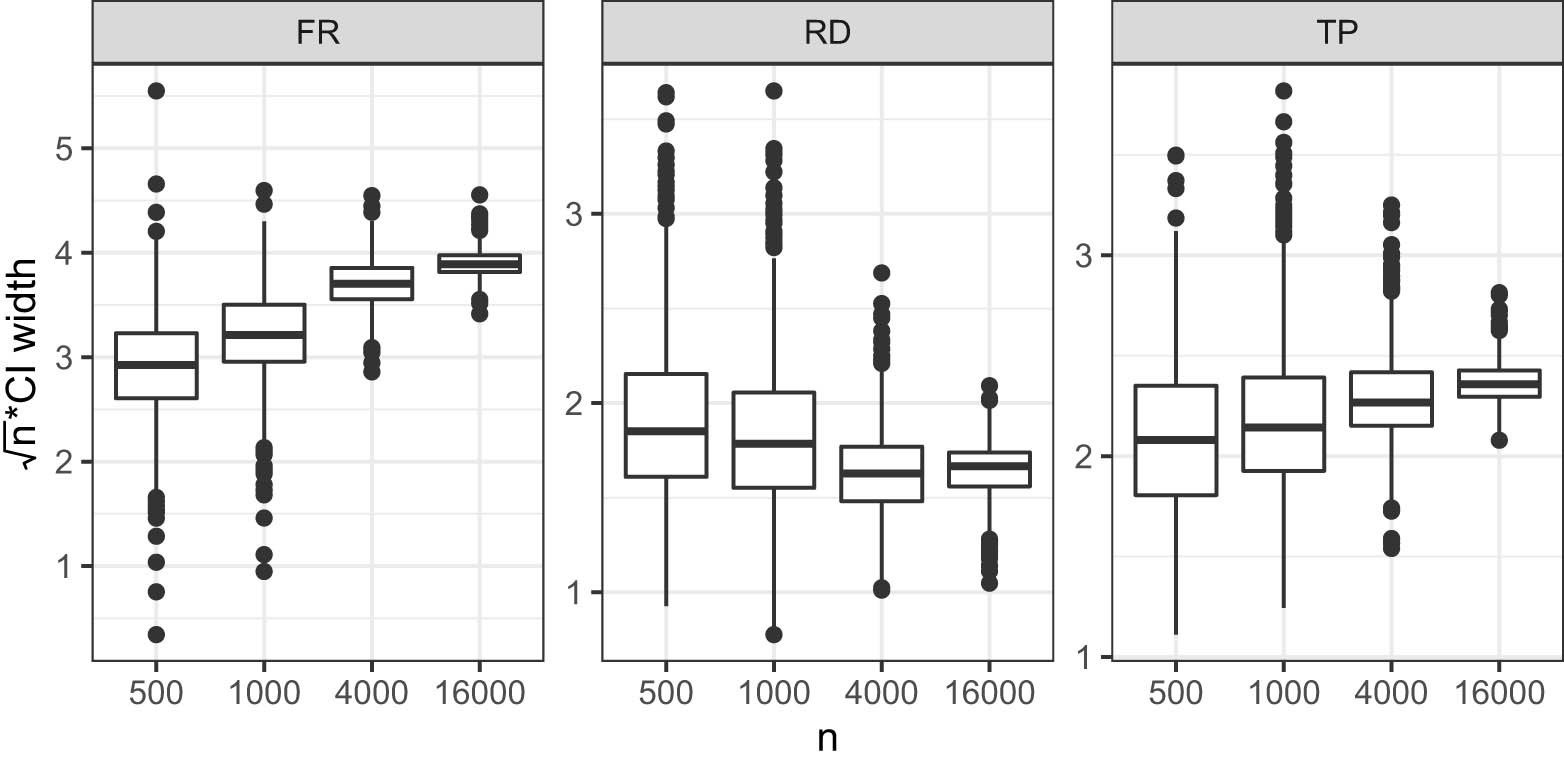
Boxplot of
As indicated in Theorem 4, theoretical guarantees for the validity of the Wald CIs rely on the nuisance function estimators converging to the truth sufficiently quickly. It appears that the undercoverage of our Wald CI in small samples may owe, in part, to poor estimation of these nuisance functions in small sample sizes. To illustrate how our procedure may perform with improved small-sample nuisance function estimators, we conducted another two simulations: one is identical to those reported earlier in all ways except that the nuisance function estimators
6 Conclusion
There is extensive literature on estimating optimal ITRs and evaluating their performance. Among these works, only a few incorporated treatment resource constraints. In this article, we build upon the study by Sun et al. [11] and study the problem of estimating optimal ITRs under treatment cost constraints when the treatment cost is random. By using similar techniques as used in the study by Qiu et al. [9], we have proposed novel methods to estimate an optimal ITR and infer about the corresponding ATE relative to a prespecified reference ITR, under a locally nonparametric model. Our methods may also be applied to IV settings in the study by Qiu et al. [9] when the IV is intervened on.
Acknowledgments
This work was partially supported by the National Institutes of Health under award numbers DP2-LM013340 and R01HL137808. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health.
-
Funding information: This work was partially supported by the National Institutes of Health under award numbers DP2-LM013340 and R01HL137808.
-
Author contributions: All authors have accepted responsibility for the entire content of this manuscript and approved its submission.
-
Conflict of interest: Prof. Marco Carone is a member of the Editorial Board in the Journal of Causal Inference but was not involved in the review process of this article.
-
Data availability statement: Data sharing is not applicable to this article as no datasets were generated or analysed during the current study.
References
[1] Rothwell PM. Subgroup analysis in randomised controlled trials: importance, indications, and interpretation. Lancet. 2005;365(9454):176–86. 10.1016/S0140-6736(05)17709-5Suche in Google Scholar PubMed
[2] Varadhan R, Segal JB, Boyd CM, Wu AW, Weiss CO. A framework for the analysis of heterogeneity of treatment effect in patient-centered outcomes research. J Clin Epidemiol. 2013;66(8):818–25. 10.1016/j.jclinepi.2013.02.009Suche in Google Scholar PubMed PubMed Central
[3] Chakraborty B, Moodie EEM. Statistical methods for dynamic treatment regimes. Statistics for biology and health. New York, NY: Springer; 2013. 10.1007/978-1-4614-7428-9Suche in Google Scholar
[4] Luedtke AR, van der Laan MJ. Statistical inference for the mean outcome under a possibly non-unique optimal treatment strategy. Annals Statistics. 2016;44(2):713–42. 10.1214/15-AOS1384Suche in Google Scholar PubMed PubMed Central
[5] Murphy SA. Optimal dynamic treatment regimes. J R Stat Soc B (Stat Methodol). 2003;65(2):331–55. 10.1111/1467-9868.00389Suche in Google Scholar
[6] Robins JM. Optimal structural nested models for optimal sequential decisions. New York, NY: Springer; 2004. p. 189–326. 10.1007/978-1-4419-9076-1_11Suche in Google Scholar
[7] Zhao Y, Zeng D, Rush AJ, Kosorok MR. Estimating individualized treatment rules using outcome weighted learning. J Am Stat Assoc. 2012;107(499):1106–18. 10.1080/01621459.2012.695674Suche in Google Scholar PubMed PubMed Central
[8] Luedtke AR, van der Laan MJ. Optimal individualized treatments in resource-limited settings. Int J Biostat. 2016;12(1):283–303. 10.1515/ijb-2015-0007Suche in Google Scholar PubMed PubMed Central
[9] Qiu H, Carone M, Sadikova E, Petukhova M, Kessler RC, Luedtke A. Optimal individualized decision rules using instrumental variable methods. J Am Stat Assoc. 2021;116(533):174–91. 10.1080/01621459.2020.1745814Suche in Google Scholar PubMed PubMed Central
[10] Qiu H, Carone M, Sadikova E, Petukhova M, Kessler RC, Luedtke A. Correction to: optimal individualized decision rules using instrumental variable methods. J Am Stat Assoc. 2021;(just-accepted):1–2. 10.1080/01621459.2020.1865166Suche in Google Scholar PubMed PubMed Central
[11] Sun H, Du S, Wager S. Treatment allocation under uncertain costs. 2021. arXiv: http://arXiv.org/abs/arXiv:210311066v1. Suche in Google Scholar
[12] Sun L. Empirical welfare maximization with constraints. 2021. arXiv: http://arXiv.org/abs/arXiv:210315298v1. Suche in Google Scholar
[13] Pfanzagl J. Estimation in semiparametric models. In: Estimation in semiparametric models. New York, NY, USA: Springer; 1990. p. 17–22. 10.1007/978-1-4612-3396-1_5Suche in Google Scholar
[14] van der Vaart AW. Asymptotic statistics. Cambridge, England: Cambridge University Press; 1998. 10.1017/CBO9780511802256Suche in Google Scholar
[15] van der Laan M, Rubin D. Targeted maximum likelihood learning. Int J Biostat. 2006;2(1):Article 11. doi: 10.2202/1557-4679.1043. 10.2202/1557-4679.1043Suche in Google Scholar
[16] van der Laan MJ, Rose S. Targeted learning in data science. New York, NY, USA: Springer; 2018. 10.1007/978-3-319-65304-4Suche in Google Scholar
[17] Neyman J. Sur les applications de la théorie des probabilités aux expériences agricoles: Essay des principles. (Excerpts reprinted and translated to English, 1990). Stat Sci. 1923;5:463–72. Suche in Google Scholar
[18] Rubin DB. Estimating causal effects of treatments in randomized and nonrandomized studies. J Educ Psychol. 1974;66(5):688–701. 10.1037/h0037350Suche in Google Scholar
[19] Butler EL, Laber EB, Davis SM, Kosorok MR. Incorporating patient preferences into estimation of optimal individualized treatment rules. Biometrics 2018;74(1):18–26. 10.1111/biom.12743Suche in Google Scholar PubMed PubMed Central
[20] Chen J, Fu H, He X, Kosorok MR, Liu Y. Estimating individualized treatment rules for ordinal treatments. Biometrics 2018;74(3):924–33. 10.1111/biom.12865Suche in Google Scholar PubMed PubMed Central
[21] Imai K, Li ML. Experimental evaluation of individualized treatment rules. J Am Stat Assoc. 2021;1–15. 10.1080/01621459.2021.1923511.Suche in Google Scholar
[22] Laber E, Zhao Y. Tree-based methods for individualized treatment regimes. Biometrika. 2015;102(3):501–14. 10.1093/biomet/asv028Suche in Google Scholar PubMed PubMed Central
[23] Lei H, Nahum-Shani I, Lynch K, Oslin D, Murphy SA. A “SMART” design for building individualized treatment sequences. Annual Rev Clin Psychol. 2012;8:21–48. 10.1146/annurev-clinpsy-032511-143152Suche in Google Scholar PubMed PubMed Central
[24] Petersen ML, Deeks SG, van der Laan MJ. Individualized treatment rules: Generating candidate clinical trials. Stat Med 2007;26(25):4578–601. 10.1002/sim.2888Suche in Google Scholar PubMed PubMed Central
[25] Qian M, Murphy SA. Performance guarantees for individualized treatment rules. Annal Stat. 2011;39(2):1180. 10.1214/10-AOS864Suche in Google Scholar PubMed PubMed Central
[26] Song R, Kosorok M, Zeng D, Zhao Y, Laber E, Yuan M. On sparse representation for optimal individualized treatment selection with penalized outcome weighted learning. Stat. 2015;4(1):59–68. 10.1002/sta4.78Suche in Google Scholar PubMed PubMed Central
[27] van der Laan MJ, Petersen ML. Causal effect models for realistic individualized treatment and intention to treat rules. Int J Biostat. 2007;3(1):Article 3. 10.2202/1557-4679.1022.Suche in Google Scholar PubMed PubMed Central
[28] Zhao YQ, Zeng D, Laber EB, Song R, Yuan M, Kosorok MR. Doubly robust learning for estimating individualized treatment with censored data. Biometrika. 2015;102(1):151–68. 10.1093/biomet/asu050Suche in Google Scholar PubMed PubMed Central
[29] Zhou X, Mayer-Hamblett N, Khan U, Kosorok MR. Residual weighted learning for estimating individualized treatment rules. J Am Stat Assoc. 2017;112(517):169–87. 10.1080/01621459.2015.1093947Suche in Google Scholar PubMed PubMed Central
[30] Abadie A. Semiparametric instrumental variable estimation of treatment response models. J Econom. 2003;113(2):231–63. 10.1016/S0304-4076(02)00201-4Suche in Google Scholar
[31] Imbens GW, Angrist JD. Identification and estimation of local average treatment effects. Econometrica. 1994;62(2):467–75. 10.2307/2951620Suche in Google Scholar
[32] Tchetgen Tchetgen EJ, Vansteelandt S. Alternative identification and inference for the effect of treatment on the treated with an instrumental variable. Harvard University Biostatistics Working Paper Series. 2013. Suche in Google Scholar
[33] Wang L, Tchetgen Tchetgen E. Bounded, efficient and multiply robust estimation of average treatment effects using instrumental variables. J R Stat Soc B (Stat Methodol). 2018;80(3):531–50. 10.1111/rssb.12262Suche in Google Scholar PubMed PubMed Central
[34] Robins J. A new approach to causal inference in mortality studies with a sustained exposure period-application to control of the healthy worker survivor effect. Math Modell. 1986;7(9–12):1393–512. 10.1016/0270-0255(86)90088-6Suche in Google Scholar
[35] Dantzig GB. Discrete-variable extremum problems. Operat Res. 1957;5(2):266–88. 10.1287/opre.5.2.266Suche in Google Scholar
[36] Gruber S, Van Der Laan MJ. A targeted maximum likelihood estimator of a causal effect on a bounded continuous outcome. Int J Biostat. 2010;6(1):Article 26. 10.2202/1557-4679.1260. Suche in Google Scholar PubMed PubMed Central
[37] van der Laan MJ, Luedtke AR. Targeted learning of the mean outcome under an optimal dynamic treatment rule. J Causal Inference. 2014;3(1):61–95.10.1515/jci-2013-0022Suche in Google Scholar PubMed PubMed Central
[38] Luedtke AR, van der Laan MJ. Super-learning of an optimal dynamic treatment rule. Int J Biostat. 2016;12(1):305–32. 10.1515/ijb-2015-0052Suche in Google Scholar PubMed PubMed Central
[39] Kennedy EH. Towards optimal doubly robust estimation of heterogeneous causal effects. 2020. arXiv: http://arXiv.org/abs/arXiv:200414497v3. Available from: http://arxiv.org/abs/2004.14497. Suche in Google Scholar
[40] Nie X, Wager S. Quasi-oracle estimation of heterogeneous treatment effects. Biometrika. 2021;108(2):299–319. 10.1093/biomet/asaa076Suche in Google Scholar
[41] Newey WK, Robins JR. Cross-fitting and fast remainder rates for semiparametric estimation. 2018. arXiv: http://arXiv.org/abs/arXiv:180109138v1. 10.1920/wp.cem.2017.4117Suche in Google Scholar
[42] Zheng W, van der Laan MJ. Cross-validated targeted minimum-loss-based estimation. New York, NY: Springer; 2011. p. 459–74. 10.1007/978-1-4419-9782-1_27Suche in Google Scholar
[43] van der Laan MJ, Polley EC, Hubbard AE. Super learner. Stat Appl Genetics Mol Biol. 2007;6(1):Article 25. 10.2202/1544-6115.1309. Suche in Google Scholar PubMed
[44] Hastie T, Tibshirani R. Generalized additive models. London: Chapman and Hall; 1990. Suche in Google Scholar
[45] Friedman JH. Greedy function approximation: a gradient boosting machine. Annal Stat. 2001;29(5):1189–232.10.1214/aos/1013203451Suche in Google Scholar
[46] Friedman JH. Stochastic gradient boosting. Comput Stat Data Anal. 2002;38(4):367–78. 10.1016/S0167-9473(01)00065-2Suche in Google Scholar
[47] Mason L, Baxter J, Bartlett PL, Frean M. Boosting algorithms as gradient descent; 2000. p. 512–8.Suche in Google Scholar
[48] Bennett KP, Campbell C. Support vector machines: hype or hallelujah? SIGKDD Explor Newsl. 2000;2(2):1–13. 10.1145/380995.380999Suche in Google Scholar
[49] Cortes C, Vapnik V. Support-vector networks. Machine Learning. 1995;20(3):273–97. 10.1007/BF00994018Suche in Google Scholar
[50] Bishop CM. Neural networks for pattern recognition. Oxford, England: Oxford University Press; 1995. 10.1093/oso/9780198538493.001.0001Suche in Google Scholar
[51] Ripley BD. Pattern recognition and neural networks. Cambridge, England: Cambridge University Press; 2014. Suche in Google Scholar
© 2022 the author(s), published by De Gruyter
This work is licensed under the Creative Commons Attribution 4.0 International License.
Artikel in diesem Heft
- Editorial
- Causation and decision: On Dawid’s “Decision theoretic foundation of statistical causality”
- Research Articles
- Simple yet sharp sensitivity analysis for unmeasured confounding
- Decomposition of the total effect for two mediators: A natural mediated interaction effect framework
- Causal inference with imperfect instrumental variables
- A unifying causal framework for analyzing dataset shift-stable learning algorithms
- The variance of causal effect estimators for binary v-structures
- Treatment effect optimisation in dynamic environments
- Optimal weighting for estimating generalized average treatment effects
- A note on efficient minimum cost adjustment sets in causal graphical models
- Estimating marginal treatment effects under unobserved group heterogeneity
- Properties of restricted randomization with implications for experimental design
- Clarifying causal mediation analysis: Effect identification via three assumptions and five potential outcomes
- A generalized double robust Bayesian model averaging approach to causal effect estimation with application to the study of osteoporotic fractures
- Sensitivity analysis for causal effects with generalized linear models
- Individualized treatment rules under stochastic treatment cost constraints
- A Lasso approach to covariate selection and average treatment effect estimation for clustered RCTs using design-based methods
- Bias attenuation results for dichotomization of a continuous confounder
- Review Article
- Causal inference in AI education: A primer
- Commentary
- Comment on: “Decision-theoretic foundations for statistical causality”
- Decision-theoretic foundations for statistical causality: Response to Shpitser
- Decision-theoretic foundations for statistical causality: Response to Pearl
- Special Issue on Integration of observational studies with randomized trials
- Identifying HIV sequences that escape antibody neutralization using random forests and collaborative targeted learning
- Estimating complier average causal effects for clustered RCTs when the treatment affects the service population
- Causal effect on a target population: A sensitivity analysis to handle missing covariates
- Doubly robust estimators for generalizing treatment effects on survival outcomes from randomized controlled trials to a target population
Artikel in diesem Heft
- Editorial
- Causation and decision: On Dawid’s “Decision theoretic foundation of statistical causality”
- Research Articles
- Simple yet sharp sensitivity analysis for unmeasured confounding
- Decomposition of the total effect for two mediators: A natural mediated interaction effect framework
- Causal inference with imperfect instrumental variables
- A unifying causal framework for analyzing dataset shift-stable learning algorithms
- The variance of causal effect estimators for binary v-structures
- Treatment effect optimisation in dynamic environments
- Optimal weighting for estimating generalized average treatment effects
- A note on efficient minimum cost adjustment sets in causal graphical models
- Estimating marginal treatment effects under unobserved group heterogeneity
- Properties of restricted randomization with implications for experimental design
- Clarifying causal mediation analysis: Effect identification via three assumptions and five potential outcomes
- A generalized double robust Bayesian model averaging approach to causal effect estimation with application to the study of osteoporotic fractures
- Sensitivity analysis for causal effects with generalized linear models
- Individualized treatment rules under stochastic treatment cost constraints
- A Lasso approach to covariate selection and average treatment effect estimation for clustered RCTs using design-based methods
- Bias attenuation results for dichotomization of a continuous confounder
- Review Article
- Causal inference in AI education: A primer
- Commentary
- Comment on: “Decision-theoretic foundations for statistical causality”
- Decision-theoretic foundations for statistical causality: Response to Shpitser
- Decision-theoretic foundations for statistical causality: Response to Pearl
- Special Issue on Integration of observational studies with randomized trials
- Identifying HIV sequences that escape antibody neutralization using random forests and collaborative targeted learning
- Estimating complier average causal effects for clustered RCTs when the treatment affects the service population
- Causal effect on a target population: A sensitivity analysis to handle missing covariates
- Doubly robust estimators for generalizing treatment effects on survival outcomes from randomized controlled trials to a target population