A Linear “Microscope” for Interventions and Counterfactuals
-
Judea Pearl


Abstract
This note illustrates, using simple examples, how causal questions of non-trivial character can be represented, analyzed and solved using linear analysis and path diagrams. By producing closed form solutions, linear analysis allows for swift assessment of how various features of the model impact the questions under investigation. We discuss conditions for identifying total and direct effects, representation and identification of counterfactual expressions, robustness to model misspecification, and generalization across populations.
1 Introduction
Two years ago, I wrote a paper entitled “Linear Models: A Useful ‘Microscope’ for Causal Analysis” [1] in which linear structural equations models (SEM), were used as “microscopes” to illuminate causal phenomenon that are not easily managed in nonparametric models. In particular, linear SEMs enable us to derive close-form expressions for causal parameters of interest and to easily test or refute conjectures about the behavior of those parameters and what aspects of the model control this behavior. I now venture to leverage the simplicity of linear SEMs to illuminate interventions and counterfactuals, also called “potential outcomes,” which often present a formidable challenge to non-parametric analysis.
After reviewing the basic notions of path analysis and counterfactual logic, we will demonstrate, using simple examples, how concepts and issues in modern counterfactual analysis can be understood and analyzed in SEM. These include: Causal effect identification, mediation, the mediation fallacy, unit-specific effects, the effect of treatment on the treated (ETT), generalization across populations, and more.
Section 2 reviews the fundamentals of path analysis as summarized in Pearl [1]. Section 3 introduces
2 Preliminaries[1]
2.1 Covariance, regression, and correlation
We start with the standard definition of variance and covariance on a pair of variables
and measures the degree to which
The covariance of
and measures the degree to which
Associated with the covariance, we define two other measures of association: (1) the regression coefficient
We note that
2.2 Partial correlations and regressions
Many questions in causal analysis concern the change in a relationship between
In words,
The partial correlation coefficient
A well known result in regression analysis [2] permits us to express
Accordingly, we can also express
Note that none of these conditional associations depends on the level
2.3 Path diagrams and structural equation models
A linear structural equation model (SEM) is a system of linear equations among a set
declares
This interpretation renders the equality sign in eq. (7) non-symmetrical, since the values of
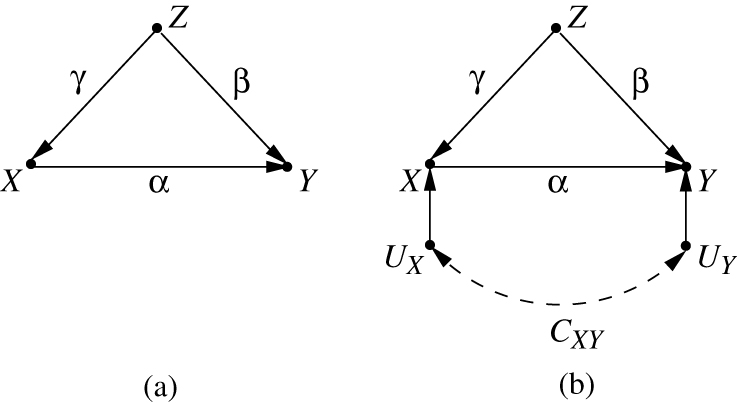
The directionality of this assignment process is captured by a path-diagram, in which the nodes represent variables, and the arrows represent the (potentially) non-zero coefficients in the equations. The diagram in Figure 1(a) represents the SEM equations of (7)–(9) and the assumption of zero correlations between the
The diagram in Figure 1(b) on the other hand represents eqs. (7)–(9) together with the assumption
while
The coefficients
2.4 Wright’s path-tracing rules
In 1921, the geneticist Sewall Wright developed an ingenious method by which the covariance
For example, in Figure 1(a), the standardized covariance
The method above is valid for standardized variables, namely, variables normalized to have zero mean and unit variance. For non-standardized variables the method needs to be modified slightly, multiplying the product associated with a path
2.5 Computing partial correlations using path diagrams
The reduction from partial to pair-wise correlations summarized in eqs. (4)–(6), when combined with Wright’s path-tracing rules permits us to extend the latter so as to compute partial correlations using both algebraic and path tracing methods. For example, to compute the partial regression coefficient
At this point, each pair-wise covariance can be computed from the diagram through path-tracing and, substituted in eq. (10), yields an expression for the partial regression coefficient
To witness, the pair-wise covariances for Figure 1(a) are:
Substituting in eq. (10), we get
Indeed, we know that, for a confounding-free model like Figure 1(a) the direct effect
leaving
2.6 Reading vanishing partials from path diagrams
When considering a set
The idea of
Definition 1
[d-Separation] A path
If
Armed with the ability to read vanishing partials, we are now prepared to demonstrate some peculiarities of interventions and counterfactuals.
3 Interventions and counterfactuals in linear systems
3.1 Interventions and their effects
Consider an experiment in which we intervene on variable
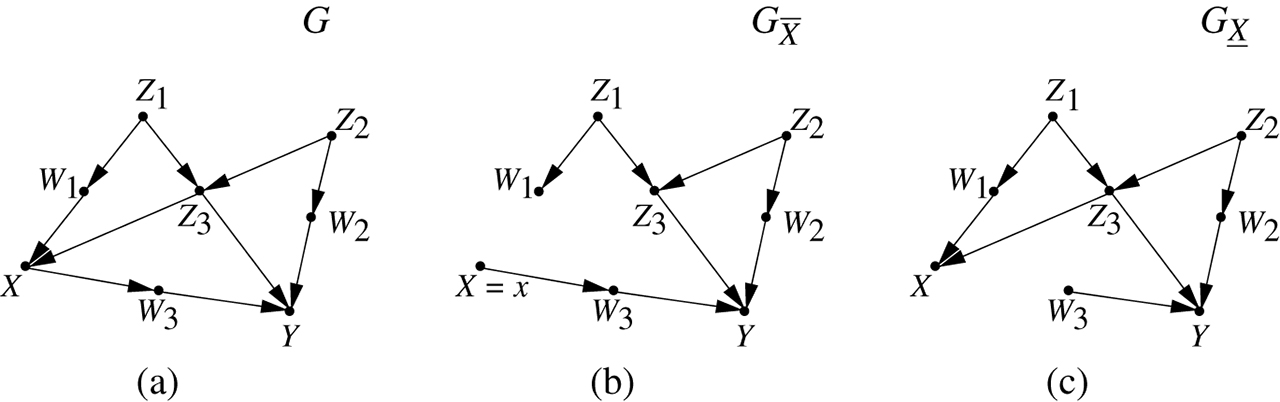
Illustrating the graphical reading of interventions. (a) The original graph. (b) The modified graph
Thus, the interventional expectation
Likewise, the average causal effect (ACE) of
is a constant, independent of
In the early days of path analysis, total effects were estimated by first estimating all path coefficients along the causal paths and then summing up products along those paths. The
Theorem 1 (Identification of total effects)
The total effect of
This identification condition is known as backdoor, and it is written as
A modification of Theorem 1 is required whenever the target quantity is the direct, rather than the total effect of
Theorem 2 (Single-door Criterion)
Let
In Figure 1(a), for example, the parameter
Usually, to identify a direct effect
A full account of identification conditions in linear systems is given in Chen and Pearl [6].
There is one more interventional concept that deserves our attention before we switch to discuss counterfactuals: covariate-specific effect. Assume we are interested in predicting the interventional expectation of
Since
hence
We see that, in general, the
If however
3.2 The graphical representation of counterfactuals
The
Let
In words: The counterfactual
Equation (18) also tells us how we can find the potential outcome variable
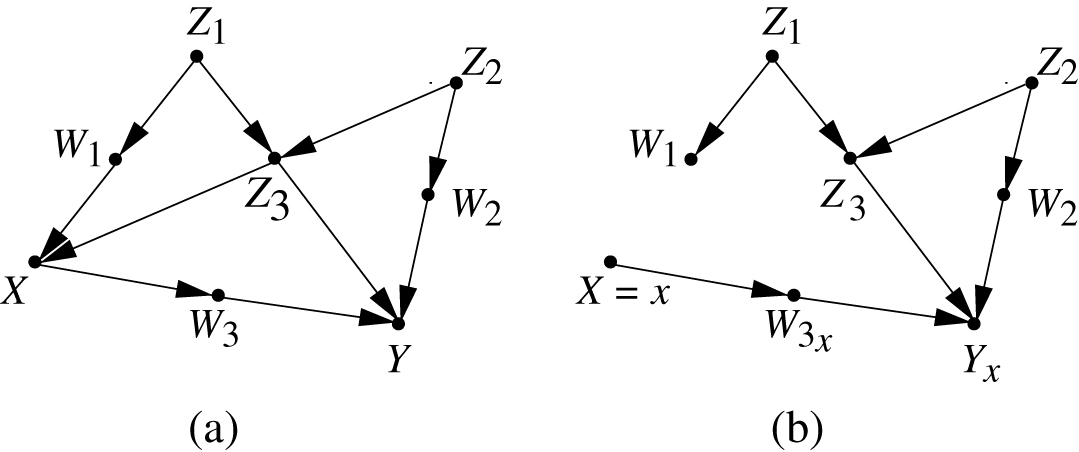
Illustrating the graphical reading of counterfactuals. (a) The original model. (b) The modified model
Since modification calls for removing all arrows entering the variable
This temporary visualization of counterfactuals is sufficient to describe the statistical properties of
These considerations are summarized formally in Theorem 3.
Theorem 3 (Counterfactual interpretation of backdoor)
If a set
The condition of Theorem 3, sometimes called “conditional ignorability” implies that
3.3 Counterfactuals in linear models
In linear Gaussian models any counterfactual quantity is identifiable whenever the model parameters are identified. This is because the parameters fully define the model’s functions, with the help of which we can define
Theorem 4
Let
then, for any evidence
This provides an intuitive interpretation of counterfactuals in linear models:
Methodologically, the importance of Theorem 4 lies in enabling researchers to answer hypothetical questions about individuals (or sets of individuals) from population data. The ramifications of this feature in legal and social contexts will be explored in the following sections. In the situation illustrated by Figure 4,
we will demonstrate how Theorem 4 can be used in computing the effect of treatment on the treated [9]
Substituting the evidence
In other words, the effect of treatment on the treated is equal to the effect of treatment on the entire population. This is a general result in linear systems that can be seen directly from eq. (20);
4 The microscope at work
4.1 The mediation fallacy
In Figure 4, the effect of
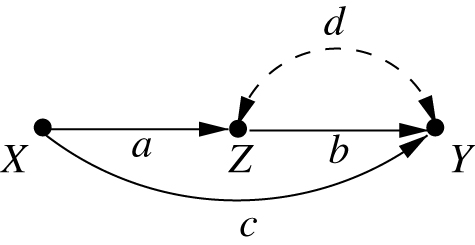
Demonstrating the mediation fallacy; “controlling for” the mediator
methods has led to a persistent fallacy among pre-causal analysts. Define the direct effect of
But this can’t be true because, using Wright’s rule, we get (using eq. (6)):
which coincides with
The discrepancy also reveals itself through the fact that
The fallacy comes about from the habit of translating “holding
Thus, the correct definition of the direct effect of
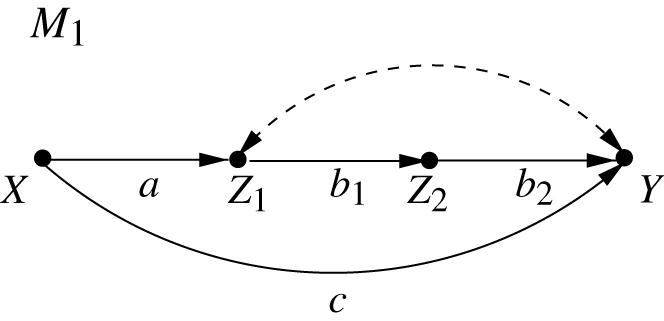
A model in which
Readers versed in causal mediation will recognize this expression as the “controlled direct effect” [15, 16] which, for linear systems, coincides with the natural direct effect.
4.2 Sequential identification
It often happens that both the backdoor or single door conditions cannot be applied in one shot, but sequential application of them leads us to the right result.
Consider the problem depicted in Figure 5, in which we require to estimate the direct effect,
Clearly, we cannot identify
We further notice that each of
Thus we can write
and
This problem is the linear version of the sequential decision problem treated in [17] and given a nonparametric solution using a sequential application of the backdoor condition. (See also Causality, [5, p. 352].) An attempt to solve this problem without the do-operator was made in Wermuth and Cox [18, 19] where it was called “indirect confounding” [20].
4.3 Robustness to model misspecification
In his seminal book “Introduction to Structural Equation Models” [21], Otis Duncan devotes a Chapter (8) to Specification Error. He asks: Suppose the model I used is wrong and the correct model is given by another path diagram. Can we “salvage” some of the effects estimated on the basis of the wrong model, so as to give us unbiased estimates for the true model?
Duncan was fascinated by the possibility of salvaging some unbiased estimates despite the wrongness of the working model. He goes through six different pairs of models and asks: “Show that the OLS estimator of
Duncan’s analysis was based on Wright’s rules which is not very efficient. It requires that we derive the estimates in the two models, and then compare them to decide if they are algebraically identical, in light of other model assumptions.
Using the single door criterion (Theorem 2), we can solve Duncan’s puzzle by inspection. We simply enumerate the sets of admissible covariates in each of the two models and check if there is a match.
To illustrate, consider the four models in Figure 6.
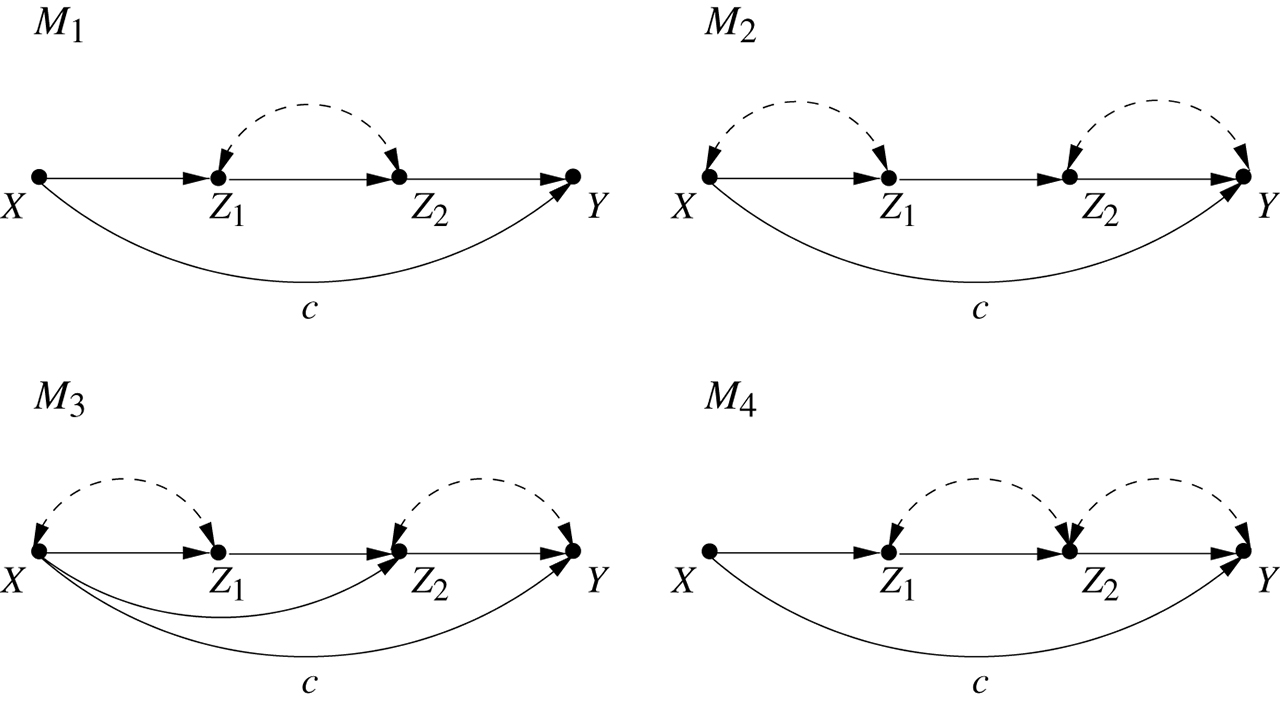
The estimate
A model demonstrating how skill-specific salary depends on education.
The admissible sets for
none
Thus, if
4.4 Mediator-specific effects
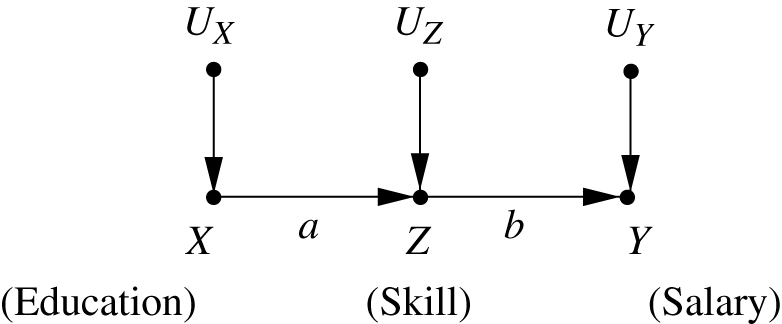
Consider the linear model depicted in Figure 7, in which
Inspecting the graph, we see that salary depends only on skill level. In other words, education has no effect on salary once we know the employee’s skill level. One might surmise, therefore, that the answer is
We now compute
Assuming
We see that the skill-specific salary depends on education
4.5 Mediator-specific effects on the treated
Consider again the model of Figure 7 and assume that we wish to assess the effect of education on salary for those individuals who have received
In the language of potential outcome this would amount to saying that treatment assignment is ignorable conditional on
Inserting
We see that
This dependence can also be seen from the graph. Recalling that
4.6 Testing S
In generalizing experimental findings from one population (or environment) to another, a common method of estimation invokes re-calibration or re-weighting [23, 24, 25]. The reasoning goes as follows: Suppose the disparity between the two populations can be attributed to a factor
then we can transfer the finding from population 1 to population 2 by writing
Thus, if we can measure the
The Achilles heal in this method is, of course, the task of finding a set
Consider the model in Figure 8(a).
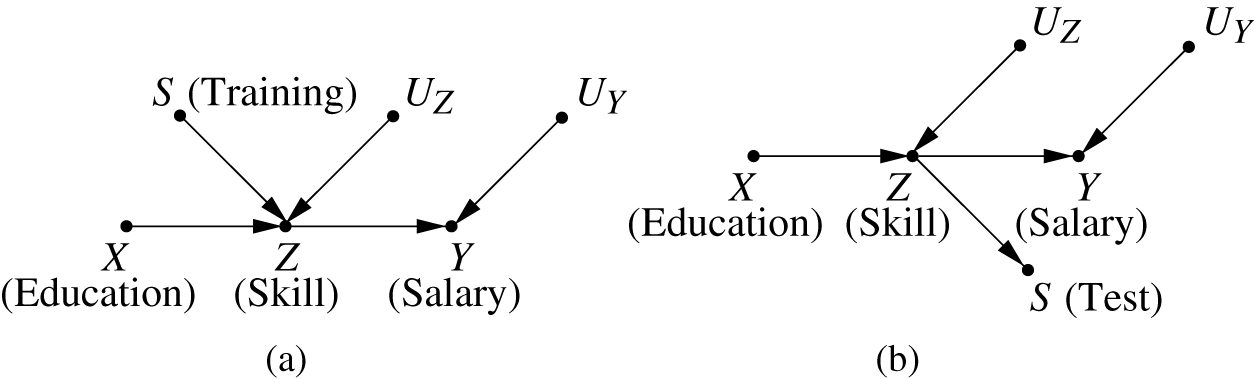
(a) The skill-specific potential outcome
The structure of the model, again, shows the salary depending on skills alone, so one might surmize that eq. (23) holds. However, leveraging our graphical representation of
with
5 Conclusions
Linear models often allow us to derive counterfactuals in close mathematical form. This facility can be harnessed to test conjectures about interventions and counterfactuals that are not easily verifiable in nonparametric models. We have demonstrated the benefit of this facility in several applications, including testing for robustness of estimands and testing the soundness of re-weighting.
Funding statement: This research was supported in parts by grants from NSF #IIS-1302448 and #1527490, ONR #N00014-17-S-B001, and DARPA #W911NF-16-1-0579.
Acknowledgements
Portions of Section 4 build on Chapter 4 of (Pearl, Glymour, Jewell, Causal Inference in Statistics: A Primer, [8]). Ilya Shpitser contributed to the proof of Theorem 4.
References
1. Pearl J. Linear models: a useful “microscope” for causal analysis. J Causal Inference 2013;1:155–70.10.21236/ADA579021Search in Google Scholar
2. Crámer H. Mathematical methods of statistics. Princeton, NJ: Princeton University Press, 1946.Search in Google Scholar
3. Wright, S. Correlation and causation. J Agric Res 1921;20:557–85.Search in Google Scholar
4. Pearl J. Probabilistic reasoning in intelligent systems. San Mateo, CA: Morgan Kaufmann, 1988.Search in Google Scholar
5. Pearl J. Causality: models, reasoning, and inference, 2nd ed. New York: Cambridge University Press, 2009.10.1017/CBO9780511803161Search in Google Scholar
6. Chen B, Pearl J. Graphical tools for linear structural equation modeling. Los Angeles, CA: Department of Computer Science, University of California. Tech. Rep. R-432; 2015. Available at: http://ftp.cs.ucla.edu/pub/stat\_ser/r432.pdf.10.21236/ADA609131Search in Google Scholar
7. Pearl J. Detecting latent heterogeneity. Sociol Methods Res 2015. doi:10.1177/0049124115600597, Online 1–20.Search in Google Scholar
8. Pearl J, Glymour M, Jewell NP. Causal inference in statistics: a primer. New York: Wiley, 2016.Search in Google Scholar
9. Shpitser I, Pearl J. Effects of treatment on the treated: identification and generalization. Proceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence. Montreal: AUAI Press, 2009:514–21.Search in Google Scholar
10. Burks B. On the inadequacy of the partial and multiple correlation technique Part I. J Exp Psychol 1926;17:532–40.10.1037/h0070156Search in Google Scholar
11. Burks B. On the inadequacy of the partial and multiple correlation technique Part II. J Exp Psychol 1926;17:625–30.10.1037/h0075654Search in Google Scholar
12. Cole S, Hernán M. Fallibility in estimating direct effects. Int J Epidemiol 2002;31:163–5.10.1093/ije/31.1.163Search in Google Scholar PubMed
13. Pearl J. Graphs causal mediation formula – a guide to the assessment of pathways and mechanisms. Prev Sci 2012;13:426–36. doi:10.1007/s11121–011–0270–1.Search in Google Scholar
14. Graphs Pearl J., causality, and structural equation models. Sociol Methods Res 1998;27:226–84.10.1177/0049124198027002004Search in Google Scholar
15. Robins J, Greenland S. Identifiability and exchangeability for direct and indirect effects. Epidemiology 1992;3:143–55.10.1097/00001648-199203000-00013Search in Google Scholar PubMed
16. Pearl J. Direct and indirect effects. In: Breese J, Koller D, editors. Proceedings of the Seventeenth Conference on Uncertainty in Artificial Intelligence. San Francisco, CA: Morgan Kaufmann, 2001:411–420.10.1145/3501714.3501736Search in Google Scholar
17. Pearl J, Robins J. Probabilistic evaluation of sequential plans from causal models with hidden variables. Uncertainty in Artificial Intelligence 11. In: Besnard P, Hanks S, editors. San Francisco, CA: Morgan Kaufmann, 1995:444–53.Search in Google Scholar
18. Cox D, Wermuth N. Distortion of effects caused by indirect confounding. Biometrika 2008;95:17–33.10.1093/biomet/asm092Search in Google Scholar
19. Wermuth N, Cox D. Graphical Markov models: overview. In: Wright J, editor. International Encyclopedia of the Social and Behavioral Sciences, vol. 10. Oxnard: Elsevier, 2014:341–50.10.1016/B978-0-08-097086-8.42048-9Search in Google Scholar
20. Pearl J. Indirect confounding and causal calculus (on three papers by Cox and Wermuth). Los Angeles, CA: Department of Computer Science, University of California. Tech. Rep. R-457; 2015.Search in Google Scholar
21. Duncan O. Introduction to structural equation models. New York: Academic Press, 1975.Search in Google Scholar
22. Brito C, Pearl J. Generalized instrumental variables. In: Darwiche A, Friedman N, editors. Uncertainty in Artificial Intelligence, Proceedings of the Eighteenth Conference. San Francisco, CA: Morgan Kaufmann, 2002; 85–93.Search in Google Scholar
23. Cole S, Stuart E. Generalizing evidence from randomized clinical trials to target populations. Am J Epidemiol 2010;172:107–115.10.1093/aje/kwq084Search in Google Scholar PubMed PubMed Central
24. Hotz VJ, Imbens GW, Mortimer JH. Predicting the efficacy of future training programs using past experiences at other locations. J Econ 2005;125:241–70.10.1016/j.jeconom.2004.04.009Search in Google Scholar
25. Pearl J, Bareinboim E. External validity: From do-calculus to transportability across populations. Stat Sci 2014;29:579–95.10.21236/ADA563868Search in Google Scholar
© 2017 Walter de Gruyter GmbH, Berlin/Boston
Articles in the same Issue
- Research Articles
- Design and Analysis of Experiments in Networks: Reducing Bias from Interference
- Interventional Approach for Path-Specific Effects
- Entropy Balancing is Doubly Robust
- Semi-Parametric Estimation and Inference for the Mean Outcome of the Single Time-Point Intervention in a Causally Connected Population
- Identification of the Joint Effect of a Dynamic Treatment Intervention and a Stochastic Monitoring Intervention Under the No Direct Effect Assumption
- Causal, Casual and Curious
- A Linear “Microscope” for Interventions and Counterfactuals
Articles in the same Issue
- Research Articles
- Design and Analysis of Experiments in Networks: Reducing Bias from Interference
- Interventional Approach for Path-Specific Effects
- Entropy Balancing is Doubly Robust
- Semi-Parametric Estimation and Inference for the Mean Outcome of the Single Time-Point Intervention in a Causally Connected Population
- Identification of the Joint Effect of a Dynamic Treatment Intervention and a Stochastic Monitoring Intervention Under the No Direct Effect Assumption
- Causal, Casual and Curious
- A Linear “Microscope” for Interventions and Counterfactuals