
Edition ohne Transkription, oder: Wie wollen wir künftig große Briefkorpora erschließen?
-
Denise Jurst-Görlach


Abstract
Buber-Korrespondenzen Digital is a project focusing on the 41 000 preserved letters exchanged between Martin Buber and more than 7000 different correspondents. Due to the size of this corpus, the project has developed the concept of ‘modular editing’, which allows for different categories of documentation, ranging from simple bibliographic to content-related metadata and ‘full edition’. In this context, the responsibility of the future editor to help users find the texts relevant to them is highlighted. By discussing the concepts of ‚Regestausgabe‘, ‘semantic annotation’ (Dumont), ‘assertive edition’ and ‘proto-edition’ (Vogeler), the article attempts to situate the project within the landscape of scholarly editing.
Einleitung: Texte, Texte, immer mehr Texte
Die fortschreitende Digitalisierung öffnet neue Räume für die Geisteswissenschaften, und das zunächst einmal ganz wörtlich gesprochen: Dokumente, die lange Zeit und zu einem nicht unerheblichen Teil nur grob vorgeordnet hinter verschlossenen Archivtüren lagen, werden zunehmend sichtbar durch Online-Findbücher und Archivdatenbanken, immer häufiger ergänzt um Digitalisate der Bestände. Doch auch methodisch öffnen sich neue Räume, da erst eine maschinelle Auswertung die Untersuchung sehr großer Datenmengen für eine breitere Anwendergruppe praktikabel macht. Dadurch entstehen neue Ansätze zur Beantwortung altbekannter – etwa philologischer, linguistischer oder geschichtswissenschaftlicher – Fragen an Texte, aber auch gänzlich neue Fragestellungen. Zu beobachten ist dabei der Trend, dass die von Forschungs- und Editionsprojekten bearbeiteten Textkorpora zunehmend umfangreicher werden. War es in Zeiten des gedruckten Buches beispielsweise kaum denkbar, eine Edition über die (in der Regel ausgewählten) Briefe einer oder zweier zentraler Persönlichkeiten hinaus zu konzipieren, stehen in digitalen Briefeditionen nun häufig größere Personengruppen[1] oder sehr umfangreiche, auf Vollständigkeit abzielende Egonetzwerke[2] im Zentrum. Hinzu kommen die Möglichkeiten von (teil-)automatisierten Erschließungsprozessen sowie die – bereits seit langem geforderte – Nachnutzung und Verknüpfung von bereits bestehenden (gedruckten sowie Online-)Editionen. Mit beiden Verfahren verbinden sich unweigerlich Fragen nach der wissenschaftlichen Zuverlässigkeit der so entstehenden Angebote, ihrer Kuratierung sowie der Transparenz.
Auch eine weitere, kürzlich auf einer Tagung gehörte Frage mag sich angesichts dieses vermeintlichen Überangebots von Texten stellen: „Wollen wir die in der Edition präsentierten Briefe eigentlich lesen oder wollen wir sie nicht lesen? Und wenn nicht, was wollen wir dann?“[3] Eine Antwort darauf könnte lauten: Wir wollen die Briefe, die für unsere je spezifischen Forschungsfragen relevant sind, zunächst überhaupt einmal finden, um sie dann mit aller philologischen Sorgfalt lesen und auswerten zu können. Zugleich wollen wir aber auch Aussagen treffen über Textkorpora, die aufgrund ihres schieren Umfangs lesend nicht zu bewältigen sind. Um diese Ziele erreichen zu können, kommen etwa Verfahren wie Netzwerkanalysen, Wissensgraphen und semantische Codierungen zum Einsatz.
Zu beobachten ist dabei die Entstehung von etwas ‚Neuem‘ im digitalen Raum, das nicht mehr gänzlich den klassischen philologischen Editionskonzepten entspricht, zugleich aber zahlreiche neue Anknüpfungspunkte zu angrenzenden Disziplinen ermöglicht, etwa den Geschichts- und Archivwissenschaften. Ausgehend von dem Projekt Buber-Korrespondenzen Digital der Akademie der Wissenschaften und der Literatur, Mainz, bemüht sich der vorliegende Beitrag um eine Reflexion mehr oder weniger etablierter sowie neu vorgeschlagener Konzepte der mit Edition beschäftigten Wissenschaften sowie um eine Einordnung des Projekts und seiner Methoden in die editionswissenschaftliche Landschaft. Da die nachfolgenden Überlegungen unmittelbar aus einem konkreten Projektkontext heraus entwickelt wurden und die vorgestellten Lösungsansätze sich auf diesen beziehen, erfolgt zunächst eine Einführung in die Rahmenbedingungen, Projektziele und das entwickelte Editionskonzept.[4]
Selbstbeschreibung: Buber-Korrespondenzen Digital
Das Projekt Buber-Korrespondenzen Digital (BKD) wurde 2021 mit einer Gesamtlaufzeit von 24 Jahren in das Programm der Union der Deutschen Akademien der Wissenschaften aufgenommen.[5] Es widmet sich der umfangreichen, von der Forschung jedoch bislang weitestgehend nicht berücksichtigten Korrespondenz des Religionsphilosophen Martin Buber (1878–1965). Buber gilt bis heute als zentraler Akteur der deutsch-jüdischen Kultur- und Geistesgeschichte des 20. Jahrhunderts, der nicht zuletzt als Herausgeber diverser Zeitschriften und Schriftenreihen mit zahlreichen berühmten, aber auch heute vergessenen zeitgenössischen Persönlichkeiten und Institutionen vielfältig vernetzt war. Er war dabei nicht nur in den Bereichen der jüdischen wie nichtjüdischen Theologie, Philosophie und Religionswissenschaft tätig, sondern gilt auch als einer der Wegbereiter der Soziologie als wissenschaftlicher Disziplin, beschäftigte sich intensiv mit moderner Pädagogik und Psychologie, mit Literatur und Kunst. Außerdem nutzte Buber seine Stimme innerhalb der zionistischen Bewegung, um neben der Stärkung jüdischer Kultur in der Diaspora im Kontext der Idee einer ‚Jüdischen Renaissance‘ auch zeit seines Lebens die Bedeutung des jüdisch-arabischen Dialogs zu betonen. All diese Themenkomplexe finden sich nicht nur in Bubers Schriften – die seit 2019 in einer vollständigen Werkausgabe vorliegen[6] –, sondern auch in seinen umfangreichen Korrespondenzen. Die im Martin-Buber-Archiv der National Library of Israel (NLI) in Jerusalem überlieferten Briefbestände umfassen mehr als 41 000 Korrespondenzstücke, die Buber mit über 7000 Personen und Institutionen wechselte. Hinzu kommen mehrere hundert weitere Briefe, überwiegend von Martin Buber, die bereits in anderen Beständen der NLI sowie in weiteren Archiven unter anderem in Israel, Deutschland, Österreich, der Schweiz und den USA recherchiert werden konnten. Die Korrespondenzen umfassen die Zeitspanne von 1895 bis zu Bubers Tod 1965 und sind in mindestens 16 Sprachen verfasst, wobei Deutsch, Hebräisch und Englisch den größten Teil bilden.
„Ziel des Projekts“, so wurde es bereits im Antrag formuliert, „ist eine digitale Briefedition, deren Fokus auf der systematischen Rekonstruktion, der editorischen Erschließung zur Herstellung eines möglichst originalgetreuen Textverlaufs und der kulturgeschichtlichen Analyse der dialogischen Beziehungen wie der Gelehrten- und Intellektuellennetzwerke Martin Bubers liegen soll.“[7] Aus dieser Formulierung wird bereits die doppelte Orientierung des Projekts im Spannungsfeld zwischen historischer und philologischer Tradition der Texterschließung erkennbar: Einerseits werden gewisse Ansprüche an eine quellennahe Transkription der Dokumente gestellt, andererseits wird die zentrale Bedeutung einer kulturwissenschaftlichen Analyse der so genannten „Briefdiskurse“[8] als Forschungsziel formuliert. Da sich Bubers Wirken in den unterschiedlichen wissenschaftlichen, kulturellen und politisch-sozialen Sphären in mehrere größere Kontexte einordnen lässt, bilden diese ‚Briefdiskurse‘ ein wesentliches Strukturierungsmerkmal des Projekts. Dabei lassen sich die Themenfelder von Bubers Werk zwar teilweise bestimmten Perioden seines Lebens zuordnen, vielfach verlaufen sie jedoch als Stränge seines Denkens parallel, sind eng miteinander verwoben oder werden in unterschiedlichen Phasen in neuer Form aufgegriffen. Für das Projekt wurden acht thematische Module identifiziert, anhand derer zentrale Forschungsfragen und die zeitgenössischen ‚Briefdiskurse‘ analysiert werden sollen.[9] Eine zusammenhängende und damit auch zeitnahe Bearbeitung solcher inhaltlich verwandten Korrespondenzen hat sich vor allem im Bereich der Kommentierung bislang bewährt.
Doch neben der wichtigen Frage, in welcher Reihenfolge das vorliegende Material bearbeitet werden soll, stellt sich mit Blick auf den enormen Umfang der Überlieferung noch eine zweite, ebenso entscheidende Frage: „Wie edieren wir das Material?“, d. h. zum einen: „Was müssen wir leisten, damit die künftigen Nutzerinnen und Nutzer ihren je eigenen Forschungsfragen und Interessen in der Edition nachgehen können?“, und zum anderen: „Was können wir leisten?“, realistisch betrachtet. Einerseits erlaubt (und verlangt) die weite zeitliche Perspektive als Akademieprojekt konzeptionelle Innovationen, die nicht nur erdacht, sondern auch tatsächlich erprobt werden können. Andererseits sind sogar diesem zeitlichen und institutionellen Rahmen editorische Grenzen gesetzt, betrachtet man die mehr als 41 000 zu bearbeitenden Korrespondenzstücke, die nicht nur erschlossen und für die Forschung aufbereitet, sondern auch im eigenen Rahmen mit Mitteln der historischen und digitalen Netzwerkforschung analysiert werden sollen.
Ein wesentliches Ziel von Buber-Korrespondenzen Digital ist die möglichst vollständige Zugänglichmachung des überlieferten Materials, wobei zunächst die Rekonstruktion der Wechselseitigkeit der Korrespondenzverläufe (etwa durch Recherche von ‚Gegenbriefen‘), darüber hinaus aber auch die strukturierte Erfassung und damit die Möglichkeit einer explorativen Erforschung des großen Textkorpus im Zentrum stehen. Eine editorische Vollerschließung im Sinne einer historisch-kritischen Edition für alle Korrespondenzeinheiten ist im Rahmen des Projekts jedoch weder zu leisten, noch ist sie für die genannten Zwecke zwingend erforderlich. Vielmehr werden nach Kriterien der Relevanz[10] unterschiedliche Erschließungstiefen für einzelne Korrespondenzen realisiert, die von der reinen Erfassung bibliographischer Metadaten – etwa für große Teile der umfangreichen Verlagskorrespondenz – bis zur kritischen Transkription mit Einzelstellenkommentierung für besonders relevante Korrespondenzen reichen. Zu diesem Zweck hat BKD ein dreistufiges Erschließungsmodell erarbeitet:
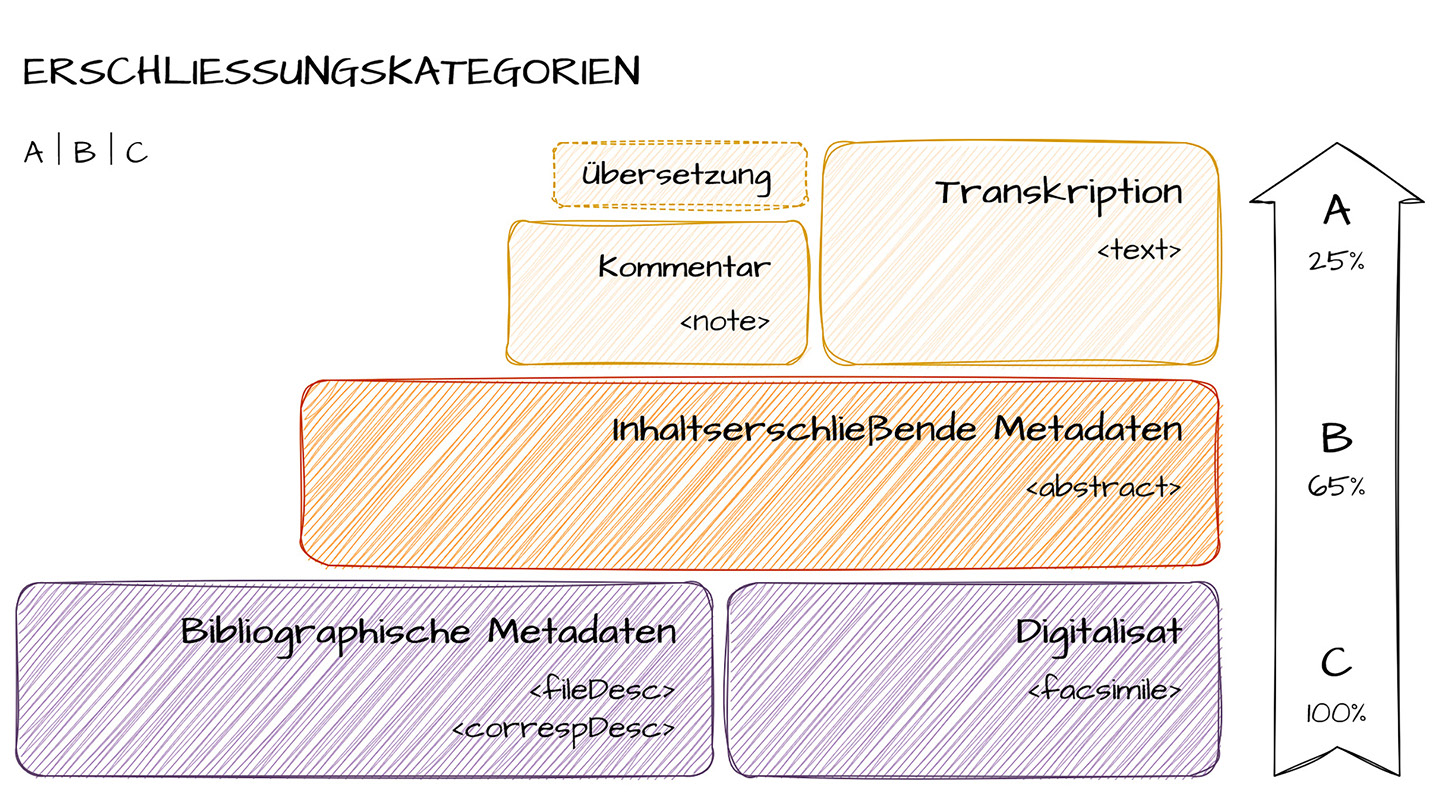
Abb. 1: Erschließungskategorien von Buber-Korrespondenzen Digital.
Korrespondenzen der Kategorie C (ca. 35 % des Gesamtkorpus) werden durch die strukturierte Erfassung von Metadaten zu Sender, Empfänger, Datum, Ort, Umfang, Sprache, Objekttyp (Brief, Postkarte etc.), Schreiberhänden und eventuell vorhandenen Beilagen erschlossen. Außerdem wird ein digitales Faksimile zur Verfügung gestellt.
Für Briefe der Kategorie B (ca. 40 % des Gesamtkorpus) wird zusätzlich zur formalen auch eine inhaltliche Erschließung vorgenommen. Diese umfasst zum einen ein menschenlesbares Regest der zentralen Briefinhalte, zum anderen umfangreiche strukturierte Metadaten, die sowohl zur Erstellung von ‚klassischen‘ Registern als auch zur maschinengestützten Analyse der Daten genutzt werden. Sie enthalten alle im Brief genannten, aber auch implizit vorkommende und für das Verständnis des Briefes besonders relevante Personen, Körperschaften, Orte, Werke und Ereignisse sowie Schlagwörter. Diese werden mit projektinternen Identifikatoren versehen und zusätzlich, wo immer möglich, mit Normdaten verknüpft. Darüber hinaus werden diese erfassten Entitäten in einer maschinenlesbaren Form zueinander in Beziehung gesetzt (s. dazu ausführlich unten).
Kategorie A schließlich umfasst einen sorgfältig ausgewählten Teil der Korrespondenzen (ca. 25 % des Gesamtkorpus), der zusätzlich zu dieser formalen und inhaltlichen Beschreibung auch nach editionsphilologischen Standards transkribiert und annotiert,[11] gegebenenfalls übersetzt und wo nötig mit Einzelstellenkommentaren versehen wird.
Die einzelnen Kategorien bzw. die in ihnen enthaltenen ‚Informationspakete‘ funktionieren dabei nach dem Baukastenprinzip. Das bedeutet, dass sämtliche Korrespondenzen mit den Kategorie-C-Bausteinen ‚Digitalisat‘ und ‚Bibliographische Metadaten‘ versehen werden, während insgesamt 65 % der Briefe (Kategorie A + B) darüber hinaus über ‚inhaltserschließende Metadaten‘ verfügen. Nur 25 % aller Korrespondenzen erreichen schließlich die höchste editorische Stufe und erhalten zusätzlich auch noch die Blöcke ‚Transkription‘ und ‚Einzelstellenkommentar‘.
Dieser vergleichsweise geringe Anteil von transkribierten Texten mag auf den ersten Blick überraschen, er ist jedoch Resultat sorgfältiger Abwägung von Edendum und angestrebten Forschungszielen. Vorrangiges Bestreben muss sein, das überlieferte Material in einer Form zu erschließen, die es Forschenden ermöglicht, für sie relevante Korrespondenz-Subsets zu bilden und/oder größere Datenmengen maschinell auszuwerten. Die Grenzen von Volltext und seiner Durchsuchbarkeit liegen bei der enormen Polyglossie des Quellenkorpus im vorliegenden Fall auf der Hand. Andere etablierte Verfahren wie Regesten und Register versprechen hier bessere Zugriffsmöglichkeiten, doch sind auch ihre Möglichkeiten begrenzt. Denn obwohl eine Beschreibung der Briefinhalte im Regest durchaus hilfreich für die einzelne Korrespondenz sein kann, ist sie nicht standardisiert und damit nicht zuverlässig maschinell auswertbar. Die Verzeichnung im Register wiederum ist zwar maschinell auswertbar, gibt aber über die bloße Erwähnung hinaus noch keine Auskunft darüber, in welchem Verhältnis die aufgelisteten Entitäten zueinander stehen.
Hier versucht das Projekt Buber-Korrespondenzen Digital anzusetzen und aus der anfänglichen Not, nicht alle Briefe ‚voll‘ edieren zu können, eine Tugend zu machen, indem einzelne Entitäten in sinnvolle (und maschinenlesbare!) Relationen zueinander gesetzt werden. Dabei werden Aussagen getroffen wie etwa, dass eine Person eine andere einlädt, eine Person an einer bestimmten Veranstaltung teilnimmt oder sie organisiert, Personen oder Körperschaften ideologische Gegner oder Verbündete oder zu bestimmten Zeiten an bestimmten Orten aktiv sind. Ziel bei der Erfassung dieser Relationen ist ausdrücklich nicht die möglichst vollständige Rekonstruktion sämtlicher Briefinhalte in Form von Relationen, sondern die maschinenlesbare und damit -auswertbare Modellierung ausgewählter Themenkomplexe, die vor allem den Netzwerkcharakter der Buber’schen Korrespondenzen charakterisieren. Im Zentrum der erfassten Relationen stehen die Entwicklung von (persönlichen, politischen und geschäftlichen) Beziehungen und die Nachverfolgung von Informationsflüssen sowie von Publikations- und Rezeptionsprozessen. Damit wird die Auswertung großer Datenmengen möglich, etwa in Bezug auf die Veränderung von Beziehungen oder die Entstehung von Netzwerken beruflicher, intellektueller oder privater Art. Die so gewonnenen Erkenntnisse können bereits existierende Forschungshypothesen bestätigen oder widerlegen, aber auch neue Ansätze für die Forschung offenlegen.
Betrachtet man z. B. die Beziehung zwischen Martin Buber und Theodor Herzl über die Dauer ihres Briefwechsels – das heißt alle direkt zwischen den beiden Personen vergebenen Relationen (vgl. Abb. 2) –, fällt auf, dass nach einer Phase der Annäherung überwiegend Konsens bestand. Danach wurde das Verhältnis sachlicher (‘informs’), bevor es im Mai 1903 zum Dissens und kurz darauf zum Abbruch der Beziehung kam. Was sich hier andeutet, ist in der Forschung keineswegs neu (der Konflikt spiegelt die so genannte Altneuland-Kontroverse) – dass die Entwicklung dieser Beziehung sich jedoch bereits mit einer geradezu unterkomplexen Abfrage so deutlich in den erhobenen Daten nachvollziehen lässt, zeigt das Potential der Relationen.
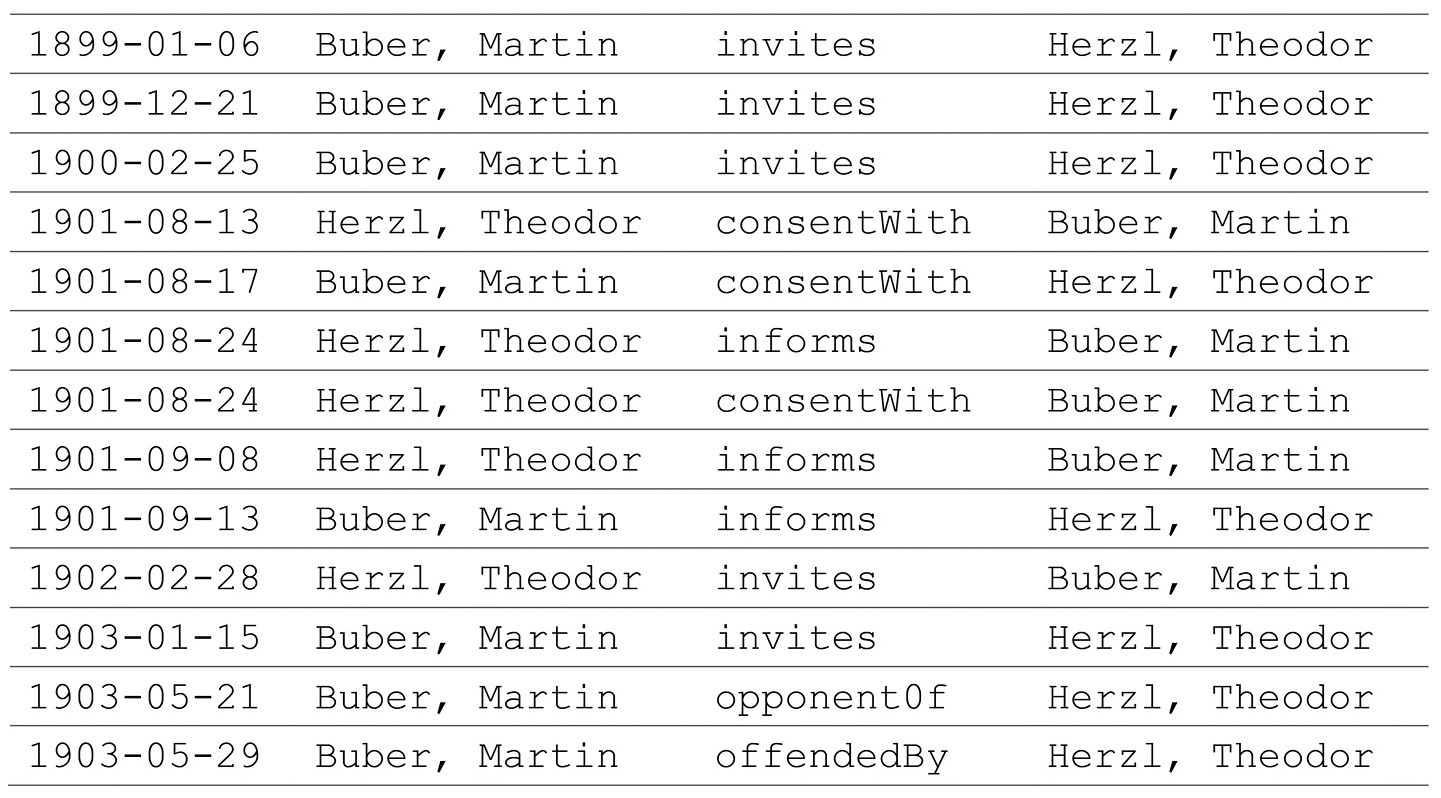
Abb. 2: Entwicklung der Beziehung zwischen M. Buber und Th. Herzl anhand der zwischen ihnen erfassten ‚Relationen‘.
Leitmotiv für die editorische Praxis beim Erfassen von Relationen bildet dabei das ‚Denken in Belegen‘: Die Auszeichnung von Relationen direkt in der jeweiligen Briefdatei[12] garantiert die Rückkopplung der erfassten Information an die historische Quelle.[13] Zugleich wird auch das enge Zusammenspiel mit den Registern mitgedacht, d. h. Informationen, die unveränderlich und ‚allgemein bekannt‘ sind, werden nach Möglichkeit an anderer Stelle erfasst, um die Editionsarbeit in den einzelnen Dateien zu entlasten – das betrifft in der Regel die Autorschaft von Werken oder auch zahlreiche Buber-Biographica. Umgekehrt aber werden über die in den Briefen erfassten Relationen zusätzliche Informationen zu vorhandenen Entitäten gesammelt, die später die Einträge in den Registern ergänzen. Das können etwa Aufenthaltsorte bestimmter Personen zu bestimmten Zeitpunkten sein, eine Liste geplanter und/oder tatsächlicher Teilnehmerinnen und Teilnehmer an einem Treffen oder Publikationspläne, die möglicherweise am Ende nicht oder anders als geplant realisiert wurden. Darüber hinaus sind auch die einzelnen Register über die projektinternen Identifikatoren miteinander verbunden und bilden so ebenfalls Relationen, etwa, dass ein Buch (Werk) in einem bestimmten Verlag (Körperschaft) an einem bestimmten Ort erschienen ist.
Dieses Modell, das wir als ‚Relationales Entitätenmodell‘ bezeichnen, geht somit weit über die einzelne Brief-Datei hinaus und vernetzt tatsächlich das gesamte Projekt im Sinne einer relationalen Datenbank – oder, als Begriff weniger technisch vorbelastet: eines Wissensgraphen. Informationen, die quasi ‚nebenbei‘ bei der Editionsarbeit erhoben werden, können sowohl innerhalb des Projekts als auch über die Projektgrenzen hinaus vielfältig miteinander in Beziehung gesetzt und ausgewertet werden. Dieser Nutzen strukturierter, für Mensch und Maschine verwertbarer Daten übersteigt die Möglichkeiten einer ‚reinen‘ Volltexterschließung um ein Vielfaches.
Selbstverortung: Edition? Regestausgabe? Plattform?
Während das beschriebene ‚Relationale Entitätenmodell‘ für Briefe der Kategorie A in der editionswissenschaftlichen Community weitgehend Akzeptanz finden dürfte, da die inhaltserschließenden Metadaten einen Mehrwert der geleisteten Editionsarbeit bieten, wirft das Konzept mit Blick auf die (für das Projekt zentrale) Kategorie B beträchtliche Fragen auf: Inwieweit handelt es sich bei der vorgestellten Erschließung dieser Briefe um eine Edition derselben? Kann es Edition ohne Transkription überhaupt geben? Und falls nein: Mit welchem Recht nennt sich Buber-Korrespondenzen Digital dann ‚Editionsprojekt‘, wenn ‚nur‘ etwa ein Viertel der Briefe tatsächlich ‚ediert‘ wird?
Vom Nutzen und Schaden von Regesten
Ein Blick zurück in die analoge Vergangenheit des Edierens drängt die Analogie zur ‚Regestausgabe‘ geradezu auf. Ursprünglich von den historischen Wissenschaften im 19. Jahrhundert für die inhaltliche Erschließung von mittelalterlichen und frühneuzeitlichen Urkunden entwickelt, wurde das Verfahren im 20. Jahrhundert gelegentlich auch für die Bearbeitung umfangreicher Briefkorpora genutzt. Das bekannteste Beispiel aus dem philologischen Bereich bilden die seit 1980 erscheinenden Briefe an Goethe,[14] als Weiteres wären die fünf Bände der Briefe Thomas Manns, Regesten und Register[15] zu nennen. Die Hoffnung war, mit dieser Methode der „knappe[n] Zusammenfassung der wichtigsten Informationen eines Schriftstückes“[16] besonders umfangreicher Korrespondenz-Überlieferungen beizukommen. Rückblickend lässt sich sagen, dass sich das Verfahren im Bereich der philologischen Editionswissenschaft nicht etablieren konnte: Während Bodo Plachta in seinem 1997 erschienenen Standardwerk zur Editionswissenschaft die Regestausgabe noch als „editorische Sonderform“[17] gelten ließ und relativ milde ihre „Grenzen“ markierte, erfuhr das Konzept im selben Jahr während eines Symposiums zum Thema Wissenschaftliche Briefeditionen und ihre Probleme geradezu vernichtende Kritik. Schon in der „Einführung zum Thema“ sprach sich Hans-Gert Roloff klar gegen Sinn und Nutzen von Regestausgaben aus und plädierte für die vollständige Textedition unabhängig von Umfang und vermeintlicher Bedeutung der Überlieferung.[18] Andere Redner des Symposiums schlossen sich diesem Urteil nachdrücklich an. Die Hauptargumente gegen die Regestausgabe waren dabei folgende:
die Subjektivität der Herausgebenden: „Der literarisch-kommunikative Text läßt sich weder allein auf sein faktisches Substrat reduzieren, noch dürfte die Interpretation des Bearbeiters allgemeine Verbindlichkeit haben, fürderhin als Faktum zu gelten“;[19]
die Erkenntnis, „daß ein Briefregest keinesfalls die Individualität des einzelnen Briefes auch nur annähernd kompensieren kann und daß für die letztlich individuell-interpretatorisch verfahrende literaturwissenschaftliche Auswertung von Brieftexten nur die vollständige Edition des Originals Sinn und Sicherheit gibt“;[20]
das Ungleichgewicht von Kosten und Nutzen: „Die Inhaltserfassung ist zeitaufwendiger als die Transkription des Briefes! […] Die Schwierigkeiten, vor die uns Massen-Korrespondenzen stellen, lassen sich nicht mit Briefregesten lösen.“[21]
Nach diesem gründlichen Rundumschlag wurde im weiteren Bereich der Philologien kein neues Editionsprojekt mehr in Angriff genommen, das sich mit diesem verpönten Verfahren identifizieren wollte.[22] Selbst die Edition der Briefe an Goethe bietet seit ihrer Transformation ins Digitale im Rahmen der Goethe-Biographica-Plattform PROPYLÄEN nun zusätzlich zu den Regesten auch Digitalisate und Volltexte zu allen überlieferten Briefen.[23] Und in der Tat fällt mit dem Umzug der Editionen ins Digitale ein wesentliches Argument für die Erstellung von Regesten – nämlich der begrenzte Raum zwischen zwei Buchdeckeln – weg. Darauf wiesen bereits die Teilnehmer am erwähnten Briefsymposium Ende der 1990er Jahre hin, als sie die neuen Möglichkeiten der Disketten- und CD-ROM-Editionen priesen.[24] Um wie viel mehr gilt das heute für Online-Editionen! Warum also sollte ein seriöses Projekt sich heute noch mit diesem überkommenen Konzept auseinandersetzen?
Wenn die Erfahrungen der vergangenen zwei Jahrzehnte im digitalen Raum etwas gelehrt haben, dann dieses: Nicht der Speicherplatz ist heute die limitierende Ressource, sondern die menschliche Aufmerksamkeit bzw. die menschliche Auffassungsgabe. Während die Zahl verfügbarer Texte im Internet ständig steigt, wachsen weder die Zeit, die Menschen zum Lesen dieser Texte zur Verfügung haben, noch ihre Fähigkeit, sich diese umfassend zu erschließen. Sie wollen suchen und finden. Ein großer Vorteil von Volltexten ist dabei per definitionem die Möglichkeit der Suchfunktionen, doch auch sie haben ihre Grenzen, spätestens wenn es an stark heterogene Textkorpora geht, seien es historische, regional- oder mehrsprachige Quellen. Vermutlich sind hier in den kommenden Jahren noch große Fortschritte im Bereich von maschinellem Lernen und ‘Large Language Models’ (LLM) zu erwarten. Doch sollte automatisierte Volltexterschließung künftig die Arbeit von Editorinnen und Editoren tatsächlich obsolet machen? Wohl kaum. Das beginnt schon beim Begriff Volltext. Welcher Text ist denn gemeint, wenn wir von einem Volltext sprechen? Was genau meinte Hans-Gert Roloff, wenn er vom „literarisch-kommunikative[n] Text“ sprach, vom „Brieftext“ und der „Transkription des Briefes“?
Von gewandelten Textbegriffen
Das Nachdenken über unterschiedliche Textbegriffe und ihre Konsequenzen für die editorische Arbeit ist seit jeher fester Bestandteil jeder Textkritik. Unter den jüngeren Publikationen ist vor allem Patrick Sahles Beitrag zu nennen, der mit seinen „Sechs (Grund-)Textbegriffe[n]“ einen gleichermaßen anschaulichen wie auf den Bereich der Digitalen Edition fokussierten Vorschlag zur Klassifizierung von Textbegriffen vorgelegt hat.[25]
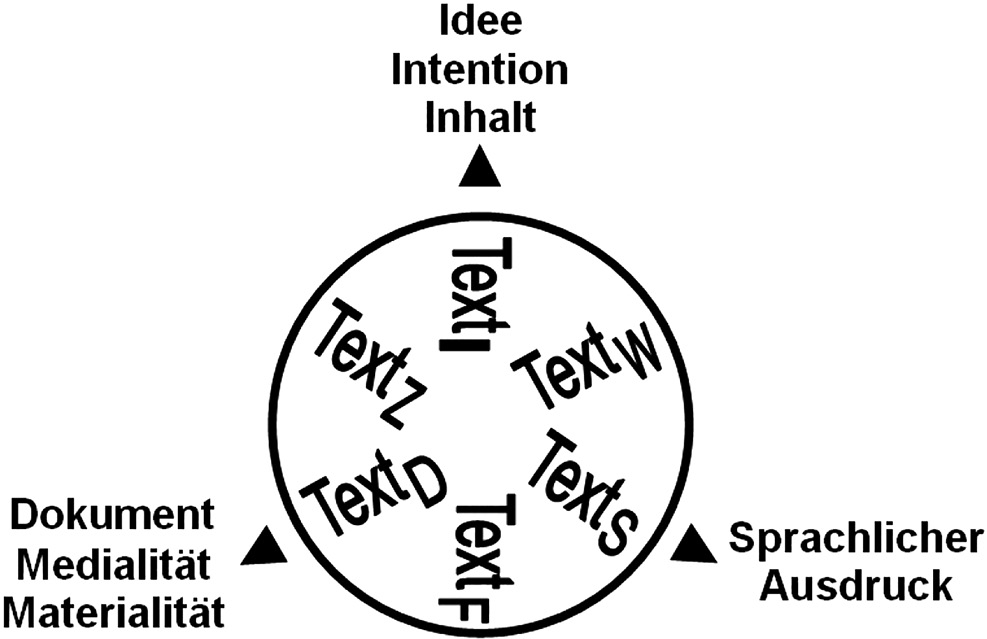
Abb. 3: Patrick Sahles Textrad, aus Sahle 2013, Teil 3 (Anm. 21), S. 47.
Das aus ihnen resultierende Textrad mit den Begriffen vom Text als Idee (TextI ), Werk (TextW ), sprachlicher Äußerung (TextS ), Fassung (TextF ), Dokument (TextD ) oder Zeichen (TextZ ) eröffnet zahlreiche, teils überraschende Perspektiven auf das eigene editorische Handeln. Während die ‚traditionellen‘ philologischen Editionskonzepte meist irgendwo zwischen TextW und TextF pendeln,[26] orientieren sich andere Disziplinen wie Philosophie oder Geschichtswissenschaften stärker an der Seite der Begriffe TextI und TextW. Durch kultur- und medienwissenschaftliche Ansätze rücken schließlich zunehmend auch TextD und TextZ in den Fokus der Forschung.[27] Die unterschiedlichen Blickwinkel auf das, was als ‚Text‘ begriffen, ediert und erforscht wird, sind demnach nicht grundsätzlich neu. Was sich allerdings in den letzten Jahren mit dem Wechsel ins Digitale geändert hat, sind die Ansprüche an die einzelne Edition und damit an die ihr zugrundeliegende Transkription. War es in Zeiten von gedruckten Editionen noch ausreichend, je nach Ausgabetyp einen oder gegebenenfalls mehrere TexteF zu präsentieren und einige Aspekte von TextD im Apparat zu berücksichtigen, soll die in XML/TEI codierte Transkription heute möglichst alle Textbegriffe bedienen, um so für ein möglichst breites Zielpublikum nutzbar zu sein. Schließlich lassen sich aus einer solchermaßen gewissenhaften Transkription in der Remedialisierung die unterschiedlichsten ‚Text‘-Fassungen generieren und darüber hinaus zahlreiche weitere Phänomene maschinell auswerten. Die Idee, um nicht zu sagen: der Idealismus eines „integrative[n] Textbegriff[s] als Aufgabe der Editorik“[28] ist in der Theorie bestechend und kaum anzufechten. Eine auf seiner Basis erstellte Transkription verspricht schließlich die Möglichkeit, mit einer Edition unterschiedlichste Bedürfnisse zu bedienen, sei es durch verschiedene Ansichten und Zugänge auf der Präsentationsoberfläche der Edition oder – da diese am Ende doch nicht alle Codierungen wird abbilden können – durch die Bereitstellung der ihr zugrundeliegenden Dateien, in denen doch sämtliche Phänomene für die Auswertung erfasst und damit zugänglich wären. In der Praxis, dem editorischen Alltag, steht diesem unbestreitbaren Mehrwert jedoch ein nicht unerheblicher Mehraufwand bei der Erstellung einer solchen Transkription gegenüber; ganz zu schweigen von der leise nagenden Frage, ob denn tatsächlich je diese eine Spezialistin über die Edition stolpern wird, die sich für genau dieses eine Phänomen interessiert, das hier gerade mit viel Zeit und Liebe ausgezeichnet wird. Nicht zuletzt kommt schließlich die Schwierigkeit hinzu, dass – wie auch Sahle zugesteht – für den gesamten Bereich TextD bis TextI bislang das Instrumentarium für eine vollständige und systematische Recodierung fehlt.[29] Blickt man mit diesen Überlegungen zurück auf die fundamentale Kritik am Erstellen von Regesten, dass „die Inhaltserfassung […] zeitaufwendiger [ist] als die Transkription des Briefes“,[30] ist doch anzuzweifeln, inwiefern diese Aussage in Zeiten einer „Hinwendung zu einem ‚multiplen‘ Textbegriff“[31] noch zutrifft.
Von Registern und ihren Funktionen
Hinzu kommt im Fokus auf das Edendum ‚Korrespondenzen‘, dass das Interesse an ihnen von jeher weniger ihrer sprachlichen Ausformung galt als vielmehr ihrer inhaltlichen und der Mitteilungsfunktion, die sie übernehmen – also vermehrt den Bereichen TextW und TextI. Sowohl Spuren der Textgenese als auch Varianten sind meist überschaubar, und mit einigen Ausnahmen steht auch bei den beteiligten Akteurinnen und Akteuren eher der Informationsaustausch im Vordergrund als die ausgefeilte sprachliche Formulierung. Darin dürfte letztlich auch der Grund liegen, dass umfangreichere, also auf Vollständigkeit zielende Briefausgaben schon in der analogen Vergangenheit kaum je linear von vorne bis hinten gelesen wurden. Vielmehr treten Nutzende mit ihren je eigenen Interessen und Fragestellungen an sie heran, denen sie sich meist über bestimmte Korrespondenzpartnerinnen und -partner oder bestimmte zu untersuchende Zeiträume anzunähern versuchen. Eine wichtige Funktion für diese Annäherung, das Auffinden eines bestimmten Briefes, übernehmen dabei die Personen-, Orts-, Werk- und Sachregister, deren Vorhandensein, Umfang und Tiefe allerdings von Ausgabe zu Ausgabe stark variiert. Register haben – in Editionen von Briefen und anderen Ego-Dokumenten mehr noch als in anderen Ausgaben – eine doppelte Funktion, sind einmal Teil der so genannten Sacherläuterungen, also des Kommentars,[32] zugleich aber auch Wegweiser und Einstiegspunkte in die Edition.
Auf die veränderte, nämlich insgesamt deutlich gestärkte Funktion von Registern in digitalen Briefausgaben hat Stefan Dumont 2019 in seinem Beitrag Briefe kommentieren im Semantic Web hingewiesen. Dabei beobachtet er einen „‘Shift’ vom Namen hin zur Entität“,[33] also der durch eine ID eineindeutigen Zuordnung einer Erwähnung zu einer bestimmten Person, Körperschaft oder einem Ort. Dieser Identifikator ist zugleich Ausgangspunkt für die Vernetzung von Briefen bzw. deren Inhalten über die einzelne Edition hinaus – was gerade mit Blick auf die Tatsache nottut, dass sich der einzelne Briefwechsel in den seltensten Fällen im ‚luftleeren Raum‘ abspielt, sondern in einem mitunter weit gefächerten Netzwerk weiterer Korrespondenzen, die (im Idealfall) Gegenstand weiterer Editionsprojekte sind. Angesichts solcher weitverzweigten Netzwerke und dem Bestreben, sie zu erforschen, erkennt Dumont die neuen Möglichkeiten, die sich mit der digitalen Erfassung von Entitäten gegenüber ‚klassischen‘ Registern ergeben. Statt der bloßen Verzeichnung einer – wie auch immer gearteten – Erwähnung einer Entität möchte er diese klassifizieren und typisieren, was konkret dadurch geschehen soll, dass die erwähnten Entitäten zueinander in Beziehung gesetzt werden. Dumont nennt diese Auszeichnungspraxis – die einen wesentlichen Ausgangspunkt des von Buber-Korrespondenzen Digital entwickelten ‚Relationalen Entitätenmodells‘ bildet – ‚semantisches Kommentieren‘, da es ihm in erster Linie um die projektübergreifenden Austauschmöglichkeiten des Kommentars in Form der qualifizierten Erwähnungen im Semantic Web geht. Folglich plädiert er für eine Auszeichnung im RDF-Format und die Anbindung an bestehende oder zu erarbeitende Ontologien. Interessant ist im vorliegenden Kontext jedoch auch Dumonts Überlegung, ob es sich bei dem vorgestellten Verfahren denn tatsächlich um ‚Kommentar‘ handele oder ob die so vorgenommenen Annotationen nicht eher ein ‚Regest‘ bilden. Dumont erkennt gewisse Ähnlichkeiten an, möchte seine Methode jedoch letztlich lieber als Weiterentwicklung des Kommentars verstanden wissen, unter anderem da „das semantische Kommentieren nicht als Ersatz für eine Transkription gedacht [ist], sondern […] sie nur begleiten und auf eine bestimmte Art analysierbar machen [soll].“[34]
In eine ähnliche Richtung stieß zeitgleich Georg Vogeler, der – ebenfalls im Jahr 2019 – sein Konzept einer ‘assertive edition’ vorstellte.[35] Diese ‚aussagekräftige‘ – so eine nicht wörtlich, aber vielleicht inhaltlich treffende Übersetzung – Edition stellt dabei ausdrücklich den Versuch dar, die geschichtswissenschaftliche Editionstradition, die auf ‚Inhalt‘ fokussiert, mit jener der Philologien zu versöhnen, die auf kritischen ‚Text‘ zielt. Kern des Konzepts ist, dass auf eine textkritisch erstellte Transkription zusätzlich strukturierte inhaltserschließende Daten bezogen werden. Vogeler sieht darin vor allem eine Möglichkeit, die bei Historikerinnen und Historikern beliebten Datenbanken wieder stärker an die historischen Quellen und ihre Texte rückzubinden. Auch er denkt dabei an die semantische Verknüpfung von Entitäten und eine Notation in RDF-Tripeln, die als adressierbare Datensätze außerhalb der XML/TEI-Datei bestehen und auf die aus der Transkription heraus verwiesen wird.[36]
Nicht zufällig wurden diese Impulse zur stärkeren inhaltlichen Erschließung der digital edierten Dokumente von zwei Historikern eingebracht. Beide Konzepte, das ‚semantische Kommentieren‘ ebenso wie die ‘assertive edition’, gehen aber nichtsdestotrotz von einem transkribierten Text aus, auf den sich die annotierten Aussagen beziehen. Sie sind auf eine Mittlerposition von philologischer und historischer Edition ausgerichtet.
Von der Bedeutung von Faksimiles
Radikaler führte Georg Vogeler seinen eigenen Ansatz 2022 mit dem Konzept einer ‚Protoedition‘ fort und definierte diese als „eine Edition ohne Transkription, die aber so erschlossen ist, dass sie geschichtswissenschaftliche Auswertungen der Quelle ermöglicht und dabei die Überprüfung solcher Auswertungen durch digitale Reproduktionen erleichtert.“[37] Vogeler verweist dabei explizit auf die in den historischen Wissenschaften gut etablierten und weit verbreiteten Regesten. Das Problem der Subjektivität der Herausgebenden bzw. der fehlenden Überprüfbarkeit ihrer Aussagen sieht er durch die Beigabe von digitalen Faksimiles gelöst. Eine strukturierte Datenerfassung der in einem Text vermittelten Inhalte – ob zusätzlich zu oder an Stelle von ‚Fließtext‘ wird nicht ganz deutlich – in Kombination mit einem Digitalisat könne so die Bedürfnisse einer Mehrheit der Historikerinnen und Historiker erfüllen und bilde einen pragmatischen Ansatz im Umgang mit der wachsenden Zahl überlieferter und für die Forschung auszuwertender Dokumente. Zur Frage, ob Edition ohne Text möglich sei, konstatiert er für einen Konferenzbeitrag unter Berufung auf Sahles TextZ schlicht: “a photograph of manuscript […] is certainly a text.”[38] Die Sorgfalt, die von Philologinnen und Philologen kritischer Editionen in die exakte Erstellung einer Transkription gelegt werde, müssten die ‚Protoeditoren‘ in die Repräsentation der Inhalte des Textes bzw. der Quelle legen. Konkret nennt Vogeler die Identifizierung von Entitäten, die Verwendung von und Anbindung an bestehende Taxonomien und Ontologien, die Einbeziehung des aktuellen Forschungsstands in die Interpretation sowie die Dokumentation des eigenen Vorgehens und die Nachhaltigkeit der verwendeten Datenmodelle.
Vergleicht man dieses Konzept und den dahinterliegenden Textbegriff mit traditionellen Ansätzen der (Editions-)Philologien, ist eine breitere Akzeptanz von Vogelers Ansatz in diesen Kreisen kaum vorstellbar, wie auch er selbst feststellt: “The proto-edition seems to be a topic for historians only.”[39] Doch Hand aufs Herz, wollte jemand wirklich textkritische oder -genetische Aussagen treffen, welcher Edition würde diese Person dabei heute noch blind vertrauen, auf welchem Editionsmodell ihr Argument aufbauen? Wenn sie die Wahl hätte, würde sie nicht immer den Blick auf das Digitalisat einer wie detailliert auch immer vorgenommenen Transkription des Textes vorziehen?
Von alten und neuen Editionskonzepten, ihren Namen und Implikationen
Komme ich mit diesen Überlegungen zurück auf die ursprüngliche Frage, ob es Edition ohne Transkription denn prinzipiell geben kann, lautet die Antwort klar: Es kommt darauf an – auf den zugrunde gelegten Textbegriff und die eigene Zielstellung, mitunter das adressierte Zielpublikum. Sollte sich Buber-Korrespondenzen Digital demnach als ‚Edition‘ bezeichnen bzw. welche Teile davon? Gemäß den eben vorgestellten Konzepten stellt sich die Situation in etwa so dar: Während für Korrespondenzen der Kategorie C (bibliographische Metadaten plus Digitalisat) keinerlei Editionsanspruch geltend gemacht werden kann, könnte es sich im Fall der Kategorie-B-Briefe (zusätzlich inhaltserschließende Metadaten) um eine Protoedition handeln. Kategorie A (zusätzlich Transkription und Einzelstellenkommentar) schließlich erfüllt die Ansprüche an eine digitale wissenschaftliche Edition, hier in der konkreten Ausformung der ‘assertive edition’.
Doch wie verhält sich die Protoedition zur oben diskutierten Regestausgabe? Hat Erstere das Potential, Letztere im digitalen Raum abzulösen und damit als Konzept obsolet zu machen – oder lässt sich die Regestausgabe vielleicht doch auch für die Philologien ins digitale Zeitalter überführen? Zur Klärung dieser Frage lohnt ein erneuter Blick auf die zentralen Kritikpunkte von Hans-Gert Roloff, nun allerdings unter den geänderten medialen Rahmenbedingungen:
Subjektivität der Herausgebenden: Ihr sind Schranken gesetzt durch die Beigabe von Digitalisaten, die die getroffenen Aussagen für die Nutzerinnen und Nutzer überprüfbar machen. Das Regest bildet nun eher einen Zusatz als einen Ersatz.[40] Durch die ‚Auslagerung‘ der stark interpretierenden Anteile ins Regest (hier als Gegensatz zu den stärker objektivierbaren bibliographischen Metadaten, die als Fortführung der ‚Kopfdaten‘ gesehen werden können) einerseits und der Kenntlichmachung von Unsicherheiten zu einzelnen Angaben im XML/TEI andererseits kann zudem versucht werden, dem Ideal der Trennung von Befund und Deutung nahezukommen.
Individualität des Briefes: Sie lässt sich nicht ersetzen und gewiss nicht in Metadaten und Relationen transformieren. Je nach angewandten Textbegriffen und Forschungsperspektive kann dieser Verlust in Kauf genommen werden oder auch nicht. Zu bedenken bleibt jedenfalls ein Aspekt, auf den Winfried Woesler bereits Mitte der 1970er Jahre aufmerksam machte, dass gerade das Medium Brief sich eben nicht in seinem Textcharakter erschöpft, sondern der optische Eindruck ein wesentlicher Bestandteil des Briefes ist, „den eigentlich nur das Faksimile annähernd wiedergeben kann.“[41]
Die Abwägung von Kosten und Nutzen: Die Ansprüche unterschiedlicher Disziplinen an einen ‚Text‘ sind so divers, dass eine entsprechende Transkription und Auszeichnung in XML/TEI eben doch einen erheblichen Mehraufwand darstellt gegenüber einer ‚nur‘ inhaltlichen Erschließung. Demgegenüber ist der Nutzen, also die Auswertbarkeit strukturierter Daten gegenüber früheren, nur gedruckten Regesten (und Registern) erheblich gestiegen.
Das im Projekt Buber-Korrespondenzen Digital erarbeitete ‘Abstract’ (als Sammelbegriff für Regest, Register und Relationen) bietet mehr und weniger als ein klassisches Regest: mehr durch strukturierte relationale Daten, weniger durch den fehlenden Vollständigkeitsanspruch – der aber ohnehin noch nie zu erreichen war. Zugleich bietet dieses ‚Abstract‘ vermutlich mehr als die von Vogeler erdachte ‚Protoedition‘, da neben der Bereitstellung des Digitalisats zusätzlich sowohl strukturierte, relationale inhaltserschließende Metadaten als auch ein klassisches, also menschenlesbares Regest erarbeitet werden. Statt für Briefe der Kategorie B also den Status als Protoedition festzulegen, könnte es eher angemessen sein, in Richtung eines Regests 2.0, einer ‚Digitalen Regestausgabe‘ zu denken. Eine solche dürfte heutzutage wohl kaum hinter digitale Ansprüche wie Beigabe eines Digitalisats, Erfassung von Normdaten und ‚semantische Kommentierung‘ zurückfallen.
Ein weiteres Phänomen, das in den letzten Jahren gerade mit Blick auf digitale Briefprojekte zu beobachten ist und das für die Selbstverortung des hier diskutierten Projekts nicht unberücksichtigt bleiben sollte, ist das Aufkommen von so genannten ‚Portalen‘ und ‚Plattformen‘.[42] Das erste Projekt im deutschsprachigen Raum in diesem Kontext war Exilnetz33 (offiziell: Vernetzte Korrespondenzen), das sich die „Entwicklung einer modularen interaktiven internetbasierten Plattform zur Visualisierung und Erforschung von sozialen, räumlichen, zeitlichen und thematischen Netzen in Briefkorpora“[43] exilierter deutschsprachiger Schriftstellerinnen und Schriftsteller nach 1933 zum Ziel setzte. Das bereits erwähnte Goethe-Biographica-Projekt PROPYLÄEN (online seit 2021) bezeichnet sich selbst wahlweise als „Portal“[44] oder „Plattform“,[45] das im März 2024 online gegangene Projekt Korrespondenzen der Frühromantik als „Plattform“[46] und „Open-Access-Präsentation“,[47] das „Portal“ Der deutsche Brief im 18. Jahrhundert trägt seine Selbstbezeichnung bereits im Akronym PDB18.[48] Was diese Projekte vereint, ist der Ansatz, bereits bestehende gedruckte oder Online-Editionen zusammenzuführen und/oder nachzunutzen sowie diese zu erweitern, sei es durch eine Ergänzung des Korpus um neu edierte Texte oder die Hinzufügung neuer Funktionalitäten, beispielsweise durch semantisches Markup. Wie Bodo Plachta treffend beschreibt, kommt es bei solchen Projekten noch stärker als in ‚traditionellen‘ Editionsprojekten zu einer Verschränkung von „Edition und Forschungsperspektiven“.[49] Zugleich (und folgerichtig) zeigt sich bereits anhand der genannten Projekte, wie unterschiedlich sowohl Methoden als auch Zielsetzungen solcher Plattformen sein können. Eine Bezeichnung als ‚Portal‘ oder ‚Plattform‘ gibt selbst der informierten Nutzerin zunächst kaum Informationen darüber, was sie auf der Website zu erwarten hat, sei es in Hinblick auf Vollständigkeit, Textkonstituierung, Kommentierung oder Analyse- und Visualisierungsangebote. Die mögliche Bandbreite reicht hier vom einfachen ‚Aggregationsportal‘ (Beispiel correspSearch)[50] über kritische Online-Editionen im engeren Sinn bis hin zu jenen von Sahle angedachten „eher visionäre[n] Editionsformen, die Texte z. B. als semantisch organisierte Datenbanken […] repräsentieren könnten.“[51] Insgesamt erscheint mir der Plattform-Begriff daher für einige der neueren Editionsformate einerseits zu technisch und zu vage, andererseits konnotiert er eine gewisse Abkehr von (editions-)wissenschaftlichen Prinzipien, die weder im Sinne noch im Selbstverständnis der allermeisten Projektverantwortlichen liegen dürfte. Auch könnte ein Vermeiden des Begriffs ‚Edition‘ nicht unbedingt förderlich sein mit Blick auf die institutionellen und hochschulpolitischen Kämpfe um Anerkennung, die die Editionswissenschaft von jeher, immer noch und immer wieder zu führen hat.
Nichtsdestotrotz braucht es (neue) Begriffe und Bezeichnungskonventionen in einem sich stetig ausdifferenzierenden Kontinuum, das von Digitalen Archiven[52] über ‘artificial editions’[53] und ‚Protoeditionen‘ bis hin zu digitalen wissenschaftlichen Editionsformaten im engeren Verständnis reicht.[54] Die verwendete Bezeichnung müsste möglichst transparent und nachvollziehbar machen, wo ein Projekt sich selbst verortet, wie es zu den von ihm generierten Daten (darunter auch der ‚Text‘) kommt und welche editorische Verantwortung es für diese zu übernehmen bereit ist oder eben nicht.
Ausblick: Modulare Edition
Grundlegend neu am Projekt Buber-Korrespondenzen Digital ist, wie gezeigt werden konnte, keines der angewandten Konzepte, sondern die modulare Kombination dieser unterschiedlichen Ansätze, das Baukastenprinzip. Das Projekt befindet sich im Spannungsfeld von historischer und philologischer Tradition der Texterschließung, zwischen semantisch strukturierter Datenbank und kritischer Edition. Dies ist seinem umfangreichen Korpus ebenso geschuldet wie seiner Zielsetzung und dem Zielpublikum, das aus unterschiedlichsten – fachdisziplinären, aber auch nichtwissenschaftlichen – Perspektiven darauf blicken wird.
Der große Vorteil des angewandten Editionskonzepts besteht in seiner Modularität und der damit verbundenen Pragmatik. Alle Erschließungstiefen werden einheitlich und vollständig in XML/TEI realisiert. Das bedeutet, dass ein Brief der Kategorie C jederzeit zu B ‚upgegradet‘ werden kann, ein Brief der Kategorie B zu A.[55] So kann in relativ kurzer Zeit mit vergleichsweise geringem Aufwand eine vollständige, wenn auch nur oberflächliche Erfassung aller überlieferten Briefe angeboten werden. Diese Arbeit kann weitgehend durch wissenschaftlich geschulte Hilfskräfte erfolgen,[56] während der wirklich arbeits- und know-how-intensive Teil der Erschließung, nämlich die Identifizierung und Erfassung sämtlicher Entitäten, die Verschlagwortung und semantische Kommentierung von als relevant eingestuften Dokumenten durch die fachlich ausgewiesenen Editorinnen und Editoren erfolgt. Deren Arbeit – so meine Einschätzung – wird auch in absehbarer Zukunft nicht von Maschinen übernommen werden können: zu unterschiedlich sind die brieflichen Kontexte, oftmals zu vage die Andeutungen und Anspielungen zwischen den Korrespondenzpartnern. Anders könnte es freilich in Fragen der Transkription oder möglicherweise sogar der Übersetzung aussehen. Auch Buber-Korrespondenzen Digital testet derzeit OCR- und HTR-Methoden und -Workflows, um perspektivisch mindestens für Martin Bubers Handschrift ein zuverlässiges Modell entwickeln zu können, das es erlaubt, spätestens zu Projektende alle Briefe von Buber mit Transkription und Volltext(en) anbieten zu können. Eine solche ‚Nachbearbeitung‘ eines als Kategorie B ‚manuell‘ erschlossenen Briefes zu Kategorie A ist eine Aufgabe, bei der Künstliche Intelligenz in den noch verbleibenden 20 Jahren Projektlaufzeit absehbar einen großen Beitrag leisten können wird.
Was ein modulares und upgradefähiges Editionsmodell zudem erleichtert, ist die Einbindung von externen Kräften, sei es durch universitäre Lehre, Qualifikationsarbeiten, flankierende Forschungs- oder sogar ‘Citizen-Science’-Projekte. Die Vorteile für beide Seiten liegen dabei auf der Hand: unsere digitale und editorische Expertise und Infrastruktur gegen zusätzliche Kategorie-A-Briefe.
Klar ist, dass auch dieses Konzept nicht für alle digitalen Editionsprojekte und Quellenmaterialien gleichermaßen passend sein kann und dass die Diskussion um neue Editionsformate und deren Bezeichnung immer noch an ihrem Anfang steht. Doch gerade für große Korpora mag die ein oder andere Überlegung zur Modularität von Erschließungstiefen nützlich sein. Für kritische Editionen – auch anderer Textsorten, selbst narrativer – liegt unabhängig davon ein großes Potential in der Integration von inhaltserschließender Annotation in Form von Relationen, die etwa mit Blick auf Figurenkonstellationen und Netzwerkanalysen einen ebenso großen Mehrwert für die Auswertung verspricht wie die prosopographischen oder wissenschaftshistorischen Daten einer Briefedition. Wie sehr insbesondere die Edition von Briefen geradezu nach einer über die bloße Erwähnung von Entitäten hinausgehenden Verknüpfung solcher Annotationen verlangt, machte bereits Jochen Strobel deutlich: „Kontextualität ist nichts Ungewöhnliches, doch die Besonderheit des Briefs ist die Relationalität aller auf ihn bezogenen Daten. Wenn eine Entität nicht Ganzes, nicht ‚Werk‘ ist, dann der Brief.“[57]
Früher musste eine Edition als alleinige Repräsentantin eines Textes gelten, da Überlieferungsträger häufig nicht oder nur schwer zugänglich waren. Die Nutzerinnen und Nutzer waren den Entscheidungen der Edierenden mehr oder weniger hilflos ausgeliefert. Das hat sich im digitalen Raum fundamental verändert. Editorinnen und Editoren haben damit vielleicht einiges an ‚Macht‘ eingebüßt, aber nichts an Verantwortung. Sie sind schon lange nicht mehr Vollstrecker eines vermeintlichen Autorwillens, sondern Lotsen und Begleiter durch das „Dickicht der Texte“.[58] Ihre Expertise, sowohl in textkritischer wie auch in fachspezifischer Hinsicht, wird nach wie vor gebraucht. Sie bieten Lesungen und Interpretationen von ‚Texten‘ aller Art, von der Zeichen- über die Dokument- bis hin zur Inhalts- und Werkebene. Sie können sich nicht hinter der vermeintlichen Objektivität eines wie auch immer konstituierten Textes verstecken. Die Angst vor der unvermeidbaren Subjektivität beim Erstellen eines ‚semantischen Kommentars‘ oder der selektiven Repräsentation eines Textes überwiegend durch die in ihm erkannten ‚Relationen‘ ist nachvollziehbar und durchaus berechtigt. Dennoch dürfte es lohnen, hier ‚mutig‘ zu sein und zu den editorischen Entscheidungen und der damit verbundenen Verantwortung zu stehen – so kontrolliert, nachvollziehbar und transparent wie möglich, so experimentell wie nötig.
Auch wenn damit der Fokus stark auf inhaltlichen Aspekten des ‚Textes‘ liegt und folglich für manch Nutzerin oder Nutzer möglicherweise zu wenig auf sprachlichen: Was von Patrick Sahles Forderung eines „integrative[n] Textbegriff[s] als Aufgabe der Editorik“ in der Praxis möglicherweise bleibt, ist eine konzeptionelle Offenheit des zugrundeliegenden Editionsmodells, das versucht, Türen zu Textbegriffen, die es selbst (im Augenblick) nicht bedienen kann oder möchte, offen zu halten.
© 2025 the author(s), published by Walter de Gruyter GmbH, Berlin/Boston
This work is licensed under the Creative Commons Attribution 4.0 International License.
Artikel in diesem Heft
- Titelseiten
- Was, wie und für wen wollen wir in Zukunft (noch) edieren?
- Einmal alles, bitte!
- Unfeste Buchstaben
- Was ist ein philosophischer Kommentar?
- Über Transformationen bei der Edition von Musik des 18. Jahrhunderts am Beispiel der Telemann-Edition
- Integration als Aufgabe der Goethe-Edition
- Die HKA als Wissensspeicher: Von der analogen zur digitalen Marburger Büchner-Ausgabe – Ausblick und Rückblick
- Mikrogenese in der digitalen Edition
- Edition ohne Transkription, oder: Wie wollen wir künftig große Briefkorpora erschließen?
- Kommentierung als Aufgabe der digitalen Briefedition
- Von der Forschung zur Vermittlung: Die digitale Franz und Franziska Jägerstätter Edition
- Kants Anteil an der Drucklegung der ‚Streitschrift gegen Eberhard‘ (1790, 1791)
- Berichte
- Textual Scholarship, Artificial Intelligence, Corpora and Intelligent Editions (ESTS 2024). Tagung an der Eötvös Loránd University, Budapest, 2.–4. Oktober 2024
- Textkritik, Metrik und Paläographie im Leben und Werk von Paul Maas. Tagung an der Georg-August-Universität Göttingen, 19. November 2024
- Editionen frühneuzeitlicher Texte im 21. Jahrhundert – Herausforderungen und Möglichkeiten. Workshop an der Universität Heidelberg, 20./21. Februar 2025
- Der wissenschaftliche Ort des Editorischen. Disziplinäre, interdisziplinäre und transdisziplinäre Perspektiven auf die Editionswissenschaft(en). Tagung an der Bergischen Universität Wuppertal, 25.–27. Februar 2025
- Lücken-Texte. Editorische Erschließung verschollener Briefe. Internationale Tagung am Brenner-Archiv der Universität Innsbruck, 19.–21. März 2025
- Digitale Quelleneditionen und KI: Aktuelle Tendenzen, Herausforderungen und Probleme. Workshop an der Herzog August Bibliothek Wolfenbüttel, 10./11. April 2025
- Rezensionen
- Sophia Victoria Krebs: Briefe lesen. Semiotik, Materialität und Praxeologie im deutschen Brief von Mitte des 18. bis Mitte des 19. Jahrhunderts. Göttingen: Wallstein 2024, 588 S.
- Provenienz. Materialgeschichte(n) der Literatur. Hrsg. von Sarah Gaber, Stefan Höppner und Stefanie Hundehege. Göttingen: Wallstein 2024 (Kulturen des Sammelns. Akteure – Objekte – Medien. 9), 375 S., auch digital im ‘open access’ zugänglich: https://doi.org/10.15499/kds-009.
- Andreas Gerards: Dichten und Denken – Der „Gang“ ins Wirkliche. Studien zur Poetologie von Ernst Meisters Metapoesie. Baden-Baden: Rombach 2023, 553 S.
- Anschriften
- Anschriften
- Formblatt zur Einrichtung satzfertiger Manuskripte
- Formblatt zur Einrichtung satzfertiger Manuskripte
Artikel in diesem Heft
- Titelseiten
- Was, wie und für wen wollen wir in Zukunft (noch) edieren?
- Einmal alles, bitte!
- Unfeste Buchstaben
- Was ist ein philosophischer Kommentar?
- Über Transformationen bei der Edition von Musik des 18. Jahrhunderts am Beispiel der Telemann-Edition
- Integration als Aufgabe der Goethe-Edition
- Die HKA als Wissensspeicher: Von der analogen zur digitalen Marburger Büchner-Ausgabe – Ausblick und Rückblick
- Mikrogenese in der digitalen Edition
- Edition ohne Transkription, oder: Wie wollen wir künftig große Briefkorpora erschließen?
- Kommentierung als Aufgabe der digitalen Briefedition
- Von der Forschung zur Vermittlung: Die digitale Franz und Franziska Jägerstätter Edition
- Kants Anteil an der Drucklegung der ‚Streitschrift gegen Eberhard‘ (1790, 1791)
- Berichte
- Textual Scholarship, Artificial Intelligence, Corpora and Intelligent Editions (ESTS 2024). Tagung an der Eötvös Loránd University, Budapest, 2.–4. Oktober 2024
- Textkritik, Metrik und Paläographie im Leben und Werk von Paul Maas. Tagung an der Georg-August-Universität Göttingen, 19. November 2024
- Editionen frühneuzeitlicher Texte im 21. Jahrhundert – Herausforderungen und Möglichkeiten. Workshop an der Universität Heidelberg, 20./21. Februar 2025
- Der wissenschaftliche Ort des Editorischen. Disziplinäre, interdisziplinäre und transdisziplinäre Perspektiven auf die Editionswissenschaft(en). Tagung an der Bergischen Universität Wuppertal, 25.–27. Februar 2025
- Lücken-Texte. Editorische Erschließung verschollener Briefe. Internationale Tagung am Brenner-Archiv der Universität Innsbruck, 19.–21. März 2025
- Digitale Quelleneditionen und KI: Aktuelle Tendenzen, Herausforderungen und Probleme. Workshop an der Herzog August Bibliothek Wolfenbüttel, 10./11. April 2025
- Rezensionen
- Sophia Victoria Krebs: Briefe lesen. Semiotik, Materialität und Praxeologie im deutschen Brief von Mitte des 18. bis Mitte des 19. Jahrhunderts. Göttingen: Wallstein 2024, 588 S.
- Provenienz. Materialgeschichte(n) der Literatur. Hrsg. von Sarah Gaber, Stefan Höppner und Stefanie Hundehege. Göttingen: Wallstein 2024 (Kulturen des Sammelns. Akteure – Objekte – Medien. 9), 375 S., auch digital im ‘open access’ zugänglich: https://doi.org/10.15499/kds-009.
- Andreas Gerards: Dichten und Denken – Der „Gang“ ins Wirkliche. Studien zur Poetologie von Ernst Meisters Metapoesie. Baden-Baden: Rombach 2023, 553 S.
- Anschriften
- Anschriften
- Formblatt zur Einrichtung satzfertiger Manuskripte
- Formblatt zur Einrichtung satzfertiger Manuskripte