Preferences in the use of overabundance: predictors of lexical bias in Estonian
-

 and
and

Abstract
This study of morphological overabundance focuses on the (non-)synonymy of parallel forms in Estonian illative case (‘into’) and the type of entrenchment behind it. We focus on the lexical level, testing whether the form preferred for a lexeme depends on semantic or morphophonological factors, or both. Using multifactorial regression analyses, we compare three corpus datasets: lexemes biased toward long forms, those biased toward short forms and lexemes with balanced form distribution. This is the first study to investigate realised overabundance in this way, and to include inflection class membership in the model, enabling us to test whether declension class subsumes the morphophonological factors found to affect form preference in previous studies. The analysis shows that cell token frequency and inflection class are significant predictors of form preference, while the lexical-semantic features included in the study do not affect formative choice, highlighting the role of cell entrenchment instead of formative entrenchment in guiding form use. In conclusion, the study highlights the important role of inflection class (morphophonology) in the general shaping of form usage patterns in parallel forms and the weak role of semantic factors on the lexical level.
1 Introduction
Inflectional overabundance describes a phenomenon where a single morphological paradigm cell is represented by two parallel forms. For instance, an English speaker can choose between dived and dove to denote the past tense of dive: both are available in the morphological system. The phenomenon has become a topic of interest in linguistics, because, in the canonical approach to inflectional morphology (Corbett 2005), it represents one type of deviation from an idealised canonical paradigm, in which all forms are expected to have one meaning, and all meanings (paradigm cells) are expected to be represented by one form.
The phenomenon is especially interesting from a theoretical perspective. Parallel forms, mapping what is apparently the same meaning to two distinct morphological formatives, can be viewed as grammatical synonyms on the morphological level. However, cognitive linguistics has shown that true equivalence, or semantic-pragmatic synonymy, is rare and unexpected in language. Investigations of apparent grammatical (near-)synonymy have demonstrated distinctions in usage, reflecting semantic and/or pragmatic differences (Baayen et al. 2013; Klavan 2014; Szmrecsanyi 2010). Distinctions have also been proposed for parallel forms in Estonian, but they have not been confirmed by quantitative data focusing on parallel form usage.
Semantic-pragmatic distinctions are believed to stem from entrenchment arising from usage. One of the two competing forms is expected to dominate in expressing the unmarked meaning of a cell, while the other form will express a related, distinct – and possibly marked – meaning (see, e.g., Divjak and Caldwell-Harris 2019). Entrenchment may play into parallel form usage on the level of the formative or the cell. Formative entrenchment means that one of the two parallel formatives in one cell has systematically become more entrenched with the unmarked meaning of that cell, while the other systematically expresses one or more marked meanings. Cell entrenchment refers to a phenomenon where more frequent and entrenched cells express distinct behaviour from less entrenched cells. For instance, Kaalep (2009) notes that the Estonian partitive plural is expressed with two possible formatives, one of which is transparently agglutinative (-sid) and the other is a more fusional form, leaning more heavily on lexical knowledge about theme vowels and stem change. Kaalep proposes a connection between overall cell frequency (the sum of parallel form frequencies in a cell) and form choice, in that fusional forms are more likely to be used with the more entrenched cells, which make lexeme-specific knowledge more readily accessible in online production. The agglutinative, morphologically transparent -sid form is found more with lower frequency cells.
This study focuses on the factors determining form bias type in the Estonian illative singular cell, investigating whether semantic distinctions align with the lexical biases in form preference, or whether these distinctions are found instead on a morphophonological level, or both. This is the first study to test the effect of inflection class on form preference in Estonian; this factor has not been linked to the phenomenon in any Estonian grammar. Furthermore, by including cell frequency in this analysis, we are able to elaborate on the ways in which entrenchment affects parallel form usage in Estonian.
Studies that investigate the usage patterns of two seemingly synonymous formatives can do so on the lexical or clausal level. While the clausal level features more prominently in linguistic research on overabundance (Aigro and Vihman 2023a; Bermel and Knittl 2012a, 2012b; Lečić 2015; Thornton 2011), some studies have shown that structures as well as formatives can be sensitive to lexical information (Santilli 2014; see Metslang 2016 and Guzmán Naranjo 2017 for a mixed approach).
Such studies, however, do not always include the question of lexical bias regarding the parallel forms. If we look at lexemes which occur with both parallel forms, the frequency ratios of these forms can be generalised into bias types (lexemes preferring one form, the other form, or equal usage of both forms). Including a variable encoding bias type allows us to investigate the distinctions between sets of lexemes, including what facilitates the emergence of even or biased usage in forms. The dearth of such comparisons may be explained by the nature of the phenomenon of overabundance. Parallel forms in noun paradigms are not expected to occur with even ratios; one form tends to be more dominant than the other (Bermel and Knittl 2012a; Kaalep 2010; Thornton 2011). Hence, a design attempting to investigate the lexical factors affecting bias may struggle to achieve datasets of lexemes with both types of bias, and especially those with even usage ratios.
In this light, Estonian language data can provide valuable insight into the lexical level of parallel form usage. Estonian has a rich nominal inflection system with 28 nominal paradigm cells. The standard grammar posits theoretically available parallel forms in numerous cells, mostly concentrated in the plural paradigm. While most overabundant cells show strong usage preferences for one of the variants over the other (Aigro and Vihman 2023a), the system includes two cells with more varied usage preferences: the partitive plural (the canonical case for marking direct objects) and the illative singular (a spatial case meaning ‘into’). The illative singular is more heterogeneous than other cells in terms of the proportions of use of the long and short forms, with parallel form usage being much less skewed toward one formative than in most other cells. Hence, it provides an amenable context for investigating the factors affecting bias in parallel form usage.
We test a number of lexical factors to explore the existing hypothesis that illative forms are sensitive to syntactic role and are therefore semantically-pragmatically distinct, in contrast with the alternative that form usage stems from morphophonology. We compare lexemes with short formative bias, long formative bias and equal form distribution. In this way, the study tests a fundamental question in cognitive linguistics, namely whether two grammatical forms with assumed synonymy will display semantic distinctions.
2 Background
Overabundance, the existence of parallel forms in a single morphological paradigm cell, is a phenomenon open to complex multidimensional interpretations. This was first observed by Thornton (2011, 2019 who described its multidimensional space by means of parameters in a Canonical Typology framework (Brown and Chumakina 2013). The values of these parameters define the level of canonicity of a particular instance of the morphological phenomenon. Overabundance may be clustered in a particular lexical space, or it may be widespread. It may also be restricted to very few cells, or it may exist in a wider range in the inflectional system. The more widespread the overabundance is in a system, the more systematic the phenomenon.
The present paper is concerned with two of Thornton’s (2019) canonicity parameters: frequency ratios and conditions of use. Frequency ratios (Thornton 2019: 238) of overabundant forms may be heavily skewed toward one form, or may be balanced between the forms, indicating a more stable and accepted presence of overabundance in the system. The Conditions of Use parameter assesses the degree to which certain lexical or contextual conditions favour one form over the other. The intersection of these two parameters may be expressed by the question of what guides form choice in usage. Balanced ratios are expected to be rare, as form use is believed to often be affected by external conditions (Thornton 2011). Guzmán Naranjo and Bonami (2021) show that in Czech, parallel forms with and without sociolinguistic conditioning render distinct ratio distributions, both of which predict a very low proportion of balanced distribution pairs.
While these parameters are helpful for systematising a broad concept, individually they define overabundance in rather different ways. First and foremost, overabundance is defined as a “situation in which two (or more) inflectional forms are available to realize the same cell in an inflectional paradigm” (Thornton 2019: 223). The term “availability” here can only mean grammatical acceptability: available overabundance exists in cases for which speakers judge two or more forms as acceptable in a single inflectional paradigm cell, regardless of how they are used. However, both frequency ratios and the conditions of use define overabundance based on usage. If one of the two forms is not used in a sample of linguistic data, according to Thornton (2019) the parameter value is 0, which is to be interpreted as a lack of overabundance (2019: 241). For the purposes of Thornton’s Canonical Typology approach, several distinct definitions do not pose a critical problem, as the approach is meant to enable concept comparison across languages (Brown and Chumakina 2013; Corbett 2005).
However, vagueness in the definition of terms becomes problematic when the two types of overabundance – availability and usage – are viewed as essentially the same kind of phenomenon. Cognitive linguistics has long recognised the fundamental role of usage patterns (rather than acceptability patterns) in shaping linguistic phenomena. Furthermore, while Estonian has extensive availability of overabundance across many cells of thousands of lexemes (potential overabundance), the actual usage of lexemes with both parallel forms (realised overabundance), has been shown to mainly pertain to six cells and only a couple hundred lexemes for each, based on a 15 million word written corpus (Aigro and Vihman 2023a). Hence, realised overabundance needs to be addressed separately in order to answer research questions essential to understanding the cognitive status of parallel forms. Why these cells and these lexemes, not others? What explains the usage ratios between parallel forms? The present paper addresses the latter question, leaving the former for future studies.
As discussed, studies on near-synonymy would expect parallel formatives to be employed with different groups of lexemes, reflecting subtle semantic distinctions (Klavan 2014). This is inherently linked to formative entrenchment; a meaning distinction would be expected to draw on the entrenchment of one of the two forms, in order to link it with the expected inflectional meaning, rendering a systematic usage bias in its favour (as found in Czech, Bermel and Knittl 2012b), reserving the other for a more marked meaning. For instance, as will be discussed in 2.2, short fusional forms of Estonian illative singular are more expected in a literal spatial sense (koli-sin majja, move-pst.1sg house.ill ‘I moved into the house’) while the longer, agglutinative form is thought to be more predominant with metaphorical meanings found with case selection (armu-sin Kaja-sse, fall-in-love-pst.1sg Kaja-ill ‘I fell in love with Kaja’).
However, non-synonymy cannot be assumed without evidence from usage data in diverse languages. In the domain of overabundance in morphology, corpus studies have mainly been conducted in various Slavic languages (e.g., the Polish genitive, Dąbrowska 2008; Czech genitive, locative and instrumental singular, Bermel et al. 2018; Guzmán Naranjo and Bonami 2021; Croatian, Bošnjak Botica and Hržica 2016; Russian, Baayen et al. 2013). Most of them support the hypothesis of non-synonymy (Bermel and Knittl 2012b). However, the nominal paradigms of these languages involve a conflation of gender and inflection class, meaning that cross-linguistically they cover a rather narrow slice of existing variation. In the next section, we turn to a language from the unrelated Uralic family which lacks grammatical gender and boasts a larger array of inflection classes.
2.1 Overabundance in Estonian nominal inflection
We set out to investigate nominal overabundance in Estonian, a Finno-Ugric language with no gender and with multiple declension classes and rich nominal morphology. Its nominal inflectional paradigm, which consists of 14 cases and two numbers, amounting to 28 cells, constitutes a valuable resource for investigating overabundance.
The system includes 26 nominal inflection classes, which are not entirely predictable based on phonological form, nor are individual word forms predictable from the reference form (see Blevins 2008). No studies have shown any semantic distinctions between these classes and they are believed not to constitute semantically cohesive groupings (Blevins 2008: 241), although the validity of this assumption is an interesting question for detailed quantitative analysis in future studies. While various classifications have been proposed with varying numbers of classes, most grammars have accepted the 26-class system offered by Viks (1992), where class membership is defined by affixes and stem types in particular cells, described by means of three dimensions. Five of the 28 cells are diagnostic in class identification: nominative singular, partitive singular and plural, genitive singular and plural. First, classes are distinguished based on the pattern by which stems vary across these five cells: some classes have the same stem across all five cells, while others may have matching stems in genitive singular and partitive plural and another stem in the other three cells. Several patterns are available, but lexemes in a single class are uniform in this dimension.
Second, gradation patterns are uniform for all lexemes within a single class. Some classes have weakening gradation, meaning the genitive stem is “weaker” (either in phonological length or type of phoneme) than nominative and partitive stems, while others have strengthening gradation, where the pattern is the other way around, with the genitive stem “stronger” than nominative and partitive. Third, formatives in partitive singular, plural and genitive plural are uniform inside a single class. Inflection classes are referred by arbitrary numbers (1–26), which we will use to indicate distinctions between classes.
With 28 nominal cells and 26 inflection classes there is a good deal of room for deviation from an entirely transparent, one-to-one system, including both cell syncretism and overabundance, the latter shown in the two forms of illative singular for two lexemes in (1).
| maja | > | maja-sse ∼ majja, ‘into the house’ |
| house.nom.sg | house-ill.sg | |
| akvaarium | > | akvaariumi-sse ∼ akvaariumi, ‘into the aquarium’ |
| aquarium.nom.sg | aquarium-ill.sg | |
It is justified to ask whether the inflection classes described in the reference grammars (Erelt and Metslang 2017; Viht and Habicht 2019) correspond to cognitive constructs used by speakers, or whether they are merely a descriptive tool for the linguist. We return to this question in the discussion.
According to academic grammars (Erelt and Metslang 2017; Viht and Habicht 2019), overabundance affects most plural cells in the nominal paradigm, as well as at least one singular cell (illative, see 1). Thirteen out of 26 classes include systematic overabundance for most of their plural paradigm (Kaalep 2018: 146), and another seven predict overabundance in some lexemes. The partitive plural is expected to be overabundant in seven declension classes, and illative singular in twenty classes. This would amount to 22,902 lexemes for the latter, if it were to apply to the entire class (Viht and Habicht 2019: 124–129).
In addition to inflection classes which include overabundant cells (1a), a lexeme may be overabundant through membership in multiple inflection classes at once, e.g. ‘aquarium’, in (1b). This means that the two available paradigms for that lexeme align with separate classes: the -sse illative form (akvaariumi-sse) is part of a paradigm inflected according to class 19 and the short form (akvaariumi) is part of a class 2 paradigm. This is prevalent in the nominal system, as 19 out of 26 inflection classes include some dual-membership lexemes (Kaalep 2018).
Parallel forms are accepted by normative language planning institutions, but usage is rather restricted (Aigro and Vihman 2023a; Kaalep 2010). “The language norm assumes that it is very common for a word to have multiple ways of forming a surface form per some morphosyntactic category bundle. Usage-wise, the distribution of such forms is very skewed, though” (Kaalep 2018: 147).
While there are no systematic, quantitative studies based on extensive datasets of parallel form usage, some studies have linked the preference of partitive plural form to the morphophonology derived from inflection class membership. For instance, class 19 lexemes, e.g., seminar ‘seminar’ are assumed to prefer the stem-changing partitive plural (seminare, seminar.par.pl) rather than an agglutinative option (seminari-sid, seminar-par.pl). Form preference has also been linked to derivational morphology, e.g., nouns formed with the -ik suffix (e.g., kodanik ‘citizen’) also prefer stem plural (kodanikke, citizen.par.pl) rather than the agglutinative -sid (kodanikku-sid, citizen- par.pl, Erelt et al. 1995: 205).
In addition, as mentioned, Kaalep (2010) suggests a connection between form preference in partitive plural and word frequency. Namely, speakers are said to be more likely to prefer the short, stem-changing partitive form with high frequency lexemes, while lower frequency items are expected to occur with the transparent -sid morpheme. This is because short form formation requires lexically specific knowledge of the word-final theme vowel, as the particular vowel cannot be phonologically derived from the reference form. For instance, as shown in (2), two lexemes with highly similar nominative singular forms take different theme vowels in the partitive plural.
| mark | > | mark i-sid ∼ mark e ‘some stamps’ |
| stamp. nom.sg | stamp-par.pl |
| tark | > | tark a-sid ∼ tark u ‘some smart [ones]’ |
| smart. nom.sg | smart-par.pl |
Kaalep (2010) posits that the easier accessibility of this lexically specific information for high frequency lexemes could facilitate its dominant (entirely productive) status, and the less accessible status of low frequency lexemes would elicit uncertainty in terms of theme vowel selection, leading speakers to opt for the transparent, concatenative -sid affix instead. In addition, such form use bias would be in line with general linguistic principles, e.g., Zipf’s Law of Abbreviation of Words (1949 [2012]) and Hawkins’ Minimizing Forms principle (2014), describing the tendency of longer lexical items to be less frequent than shorter items.
However, this hypothesis appears incomplete. First, the dataset used in Kaalep’s analysis was rather small, meaning that the results on high frequency items rendering higher usage ratios of short fusional forms need to be confirmed in a larger quantitative study. Second, it does not follow that lexeme frequency alone facilitates the short form becoming dominant across all such lexemes. Other factors have been discussed for illative singular, e.g. syntactic role. The fact that illative singular formative patterns are highly analogous to partitive plural allows our study of form bias comparison to indirectly test Kaalep’s hypothesis.
Illative singular is formed by means of a number of morphological strategies, shown in (3). The pattern described in (3a) is agglutinative, while 3b, 3c and 3e are fusional, often including stem change and an increase in phonological quantity (Viht and Habicht 2019), as seen in the medial consonant lengthening in (3c):
| a. | the -sse affix: maja house.nom > maja-sse house-ill |
| b. | stem vowel (a, e, i or u): mõis manor.nom > mõisa manor.ill |
| c. | stem consonant gemination: sõda war.nom > sõtta war.ill |
| d. | zero marking: põrgu hell.nom = põrgu hell.ill |
| e. | nonproductive strategies, often with stem change: suu mouth.nom > suhu mouth.ill |
While the affix -sse is assumed to be available to all lexemes (Viht and Habicht 2019: 93), the availability of the other patterns is defined lexically. Even though overabundance may occur in various combinations, parallel form pairs usually involve -sse as one of the two available forms (Aigro and Vihman 2023a).
Siiman (2019, née Metslang), who has investigated illative singular parallel forms, showed that form preference is informed by various lexical factors, including morphophonological as well as semantic and syntactic factors (Metslang 2015, 2016). Morphophonological factors include a number of gradation-related variables, stem-final phoneme and syllable count. Semantic and syntactic factors that were found to influence form choice include the noun’s semantic type and phrase status. Semantic type in Metslang’s study included the levels 1) proper names, 2) body parts, 3) locations, 4) states and 5) other. Phrase status codes verbal selection, following the assumption that when illative marks a verbal argument (e.g. usun sinusse ‘I believe in you’), the long form is preferred by speakers, while the short form dominates in non-selected adjunct roles. The same is claimed in the main descriptive grammar (Erelt et al. 2020: 217). Inflection class was not included, although several of the morphophonological variables underlie class membership.
There are issues with these results. First, the data in Metslang (2015, 2016 includes lexemes with available overabundance rather than only lexemes with attested overabundant usage. This is likely due to the lower availability of annotated corpora at the time of these studies, which restrict investigations of low-frequency phenomena such as overabundance. However, this means that the base assumption of her conclusions may not hold. As shown by Aigro and Vihman (2023a), both forms are used with only a handful of lexemes out of the tens of thousands with available overabundance. For the rest, one form may be so entrenched that there may no longer be any awareness of alternative forms for that particular lexeme in the speaker community.
Furthermore, Aigro and Vihman (2023a) show that Metslang’s results regarding Estonian case function in overabundant contexts do not seem to hold when examining only realised overabundance. They found no alignment of formative choice with particular case functions in a balanced sample of several cases, including illative singular. The same was hypothesised by Kaalep (2009). This further highlights the importance of drawing a distinction between dataset types. When investigating language users’ behaviour in a variation context, especially when this is done based on the indirect evidence of a corpus study, one needs to first confirm that variation truly exists for speakers, which is most credibly done by only focusing on cells for which both parallel forms are simultaneously used (at least to some degree, and even if they are used by different speakers).
In addition, Metslang’s studies (2015, 2016 do not include inflection class information or information on morphological variation patterns. Hence, there remains the possibility that many of the morphophonological and semantic patterns that she identified among nominals may be explained away by inflection class membership. An untested question remains, then, of whether inflection class has any effect on overabundant usage, and if so, whether this effect is independent from the other observed factors affecting form choice. Finally, regarding the role of entrenchment, no quantitative studies have outlined all form distributions for any of the Estonian nominal paradigm cells, and neither are there any quantitative results on the role of frequency in form type. We seek to address these gaps.
3 Lexical factors in parallel form distribution
The present study investigates distinct types of parallel form distribution in lexemes which exhibit overabundance in the illative singular in corpus data. We limit our approach to the lexical level, only including factors pertaining to lexemes and not their sentence context. We aim to answer the following two research questions:
RQ1:
How do lexemes favouring the long formative differ from lexemes favouring the short formative?
RQ2:
How do lexemes with balanced distribution differ from those with biased distribution?
For both RQs, contexts with realised overabundance are used to test the hypothesis that parallel formatives in overabundant cells are not entirely synonymous, but that their usage reflects semantic and morphophonological distinctions (Bermel and Knittl 2012b; Metslang 2015, 2016; Thornton 2011). We hypothesise that semantic distinctions based on argument status will not hold, and that most of the morphophonological factors proposed to affect Estonian illative singular parallel form usage are reflected in inflection class membership. Up to now, form preference has never been claimed to be related to inflection class. If we find a link between them, we may conclude that the inflection class system has effects on usage beyond its grammatical descriptive value and that level of abstraction has some cognitive reality affecting online processing. Hence, for RQ1, we expect lexemes biased toward long forms to belong to different classes than lexemes with short form bias.
RQ2 compares lexemes with balanced parallel form distribution to those in two different usage bias groups. Balanced distribution is believed to be much rarer than biased distribution (Thornton 2019), and this has been shown to apply to Estonian illative singular as well (Aigro and Vihman 2023a). If we find a distinction between the lexemes with balanced (more canonically overabundant) distribution and both types of biased distribution, this would suggest a conceptual distinction between balanced and biased overabundance. If, however, similarities are found between balanced lexemes and only one of the biased groups, this would suggest that balanced distribution is merely a variant manifestation of one of the biased groups, where certain factors facilitate more equal form use. We hypothesise the latter to be the case, and aim to identify factors at play in this distinction on a lexical level. This hypothesis stems from the assumption that even distribution is rather rare cross-linguistically, as indicated by Thornton (2019) and Bermel and Knittl (2012a).
3.1 Data and method
The corpus study reported here is based on a dataset including lexemes with both parallel forms in illative singular attested in the corpus (all datasets are freely available at https://osf.io/bsp9d/). Using Python 3.8, the dataset was extracted from the Estonian National Corpus 2021, a written corpus for Estonian totalling 2.4 billion words (Koppel and Kallas 2022). Illative singular is the only cell in Estonian nominal morphology in which language technology tools annotate parallel forms with distinct labels: the long illative (-sse affix, see 4a) is parsed as illative, while the short illative (described in 4b–4d) is coded as aditive.[1]
Out of all lexemes with at least one illative form in the corpus (n = 422,650), we extracted lexemes where both an agglutinative (-sse, see 3a) and fusional variant (3b–3d) are attested in the corpus and the more frequent form occurs at least 10 times (n = 1,907). For these 1,907 lexemes, we calculated the proportion of the most frequent -sse form and the most frequent fusional form in the grand total of their frequencies (cell frequency).[2]
The distribution of form proportions is depicted in Figure 1. Interestingly, while there is a peak in words preferring the short form (the far left part of Figure 1), the overall variation is quite uniform. For 439 lexemes, the short form strongly dominates (being used in 90–99.9999 % of cell instances), but for the other deciles in Figure 1, the number of lexemes is more or less similar, with a range of 140–219. In fact, there are significantly more lexemes in the highly even distribution interval, where the short form makes up 50–60 % of uses (n = 189), compared to the interval where the short form makes up 70–80 % of uses (n = 140, χ2 = 7.662, p = 0.006).
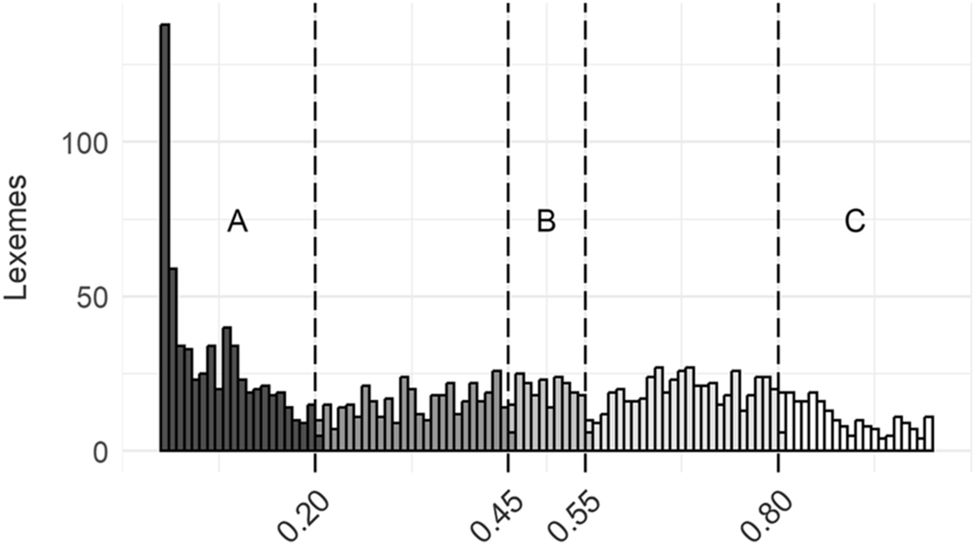
A histogram of parallel form usage frequency ratios in 1,908 nouns which are attested in both long (-sse) and short illative forms. Nouns are plotted based on the proportion of use of their long illative form: those preferring the long form cluster on the far right, with proportions close to 1, while those favouring the short form are found on the left, close to 0. Sections A, B and C mark the three datasets used in the present study.
Out of these 1,907 lexemes, we extracted long bias lexemes, i.e., lexemes where the long illative form makes up 80 % or more of illative singular cell frequency (n = 221, group C in Figure 1), and short form bias lexemes, following the same logic (n = 600, group A in Figure 1). We chose 80 % as the threshold, because a 90 % threshold would have rendered a very short lexeme list for the long-bias dataset (76 before manual cleaning, while the 80 % threshold yielded 221 for that type). A threshold lower than 80 %, however, would yield less meaningful results in terms of bias characterisation. For lexemes in the balanced distribution dataset (n = 201, group B in Figure 1), neither form exceeds 55 % of cell frequency. Approximately half (47 %, n = 889) of the initial dataset of 1,908 lexemes had a distribution where one form occurred in 20–45 % of cell instances, expressing neither bias nor even distribution. These were excluded from the present study.
All three datasets were then manually cleaned, which involved removing: 1) a small number of errors due to homonymous reference forms (e.g., soola-sse salt-ill and soolde intestine.ill both have sool as the nominative singular form), 2) lexemes in other languages (e.g., club, subwoofer), 3) other lemmatisation errors, and 4) compound duplicates. For instance, the long bias dataset included 50 compounds with the base noun keskus ‘centre’ (e.g., noortekeskus ‘youth centre’). If the bare base noun of a compound was found in the same dataset, all compounds based on it were removed. If the base noun was missing from data, all compounds except one (with the highest cell frequency) were removed. Hence, each of the three datasets is made up of unique base nouns, which may have duplicates in one of the other two datasets. For instance, ministeerium ‘ministry’ is included in the long form dataset while põllumajandusministeerium ‘Ministry for Agriculture’ is in the balanced distribution dataset.
Cleaning the data rendered 422 short bias, 105 long bias and 130 even distribution lexemes. We randomly extracted 130 lexemes from the short bias dataset to match it more closely to the other two datasets. Overall, illative singular frequency ratios present a rather evenly distributed picture, rather than the U- or L-shape described by Guzmán Naranjo and Bonami (2021), who found very few lexemes with balanced distribution. The three datasets used in the analyses are described in Table 1.
Datasets used in the study.
| Number of lexemes | Mean cell frequency per lexeme (SD) | |
|---|---|---|
| Long bias dataset | 105 | 2,945.6 (5,586.2) |
| Short bias dataset | 130 | 10,652.6 (33,715.7) |
| Balanced distribution dataset | 130 | 709.4 (2,124.1) |
| Total/overall mean | 365 | 4,769.2 (13,808.7) |
A mixed-effects logistic regression model (R package lme4, Bates et al. 2015) was used. Dataset type (short bias, long bias, even distribution, see Table 1) constitutes the dependent variable. All 365 items were then coded for nine predictors:
Cell frequency: the sum total of long and short form in the corpus.
Concreteness: a numerical index (0–10), where 10 indicates the most concrete lexemes. These indices originate from Aedmaa (2019), who assigned concreteness ratings to more than 200 thousand Estonian lemmas by means of machine learning.
Animacy: a variable with the levels human, other (non-human) animate and inanimate.
Pattern: this variable describes the type of short illative formative used with a lexeme. The long illative is constant (-sse) in all parallel forms in this study. Variable levels therefore only express short form variation and include “gem” (marking gemination of stem consonant, see 3b), “vowel” for stem alternation based on vowel distinction and “other” for all other stem changes.
Lemma syllable count: number of syllables in reference form.
Stress: a binary variable (word-initial vs non-initial syllable stress).
Maximum quantity: the highest phonological quantity in the reference form, a variable with three levels (first, second and third quantity).
Final phoneme: a binary variable (consonant-final vs vowel-final reference forms).
A mixed-effects model was used in order to investigate the role of inflection class, which was included as a random factor in the model as it has too many levels for it to be meaningfully included as a predictor. It expresses a lexeme’s class membership, as specified in the reference dictionary (Sõnaveeb), where 26 main inflection classes are distinguished. Classes are coded without sub-specifications (classes 9i and 9 are treated as the same class). In our implementation, the variable describes a lexeme’s inflection class pattern, rather than class membership. This means that a noun with parallel forms patterning with both classes 9 and 11 is coded as “9.11”, whereas those only belonging to class 9 are coded “9”. Hence, every membership combination is a unique factor level. Combinations constitute separate subpatterns inside larger classes, meaning that class “9” lexemes can, as a group, behave rather differently from “9.11” lexemes, as was also found for Czech by Guzmán Naranjo and Bonami (2021).
Cell frequency is included to test the hypothesis that lower frequency cells have a bias toward the long (-sse) form (Kaalep 2010). Animacy and concreteness are the only lexical-semantic predictors, chosen based on the expectation that long illative dominates when the case is selected by a verb, i.e., when the case expresses a verb complement (Metslang 2015, 2016, see 2.2). As illative is a spatial case, it is expected to have concrete, inanimate referents in its canonical usage, with an increased proportion of human and more abstract referents when marking verbal arguments (Aigro 2022; Aristar 1997). Pattern is the only morphological predictor. While patterns are unlikely to vary within a single inflection class, this predictor captures the fact that for a single cell, the same pattern can conflate different classes. Finally, morphophonology was included via four variables, all automatically coded using the Python NLP package EstNLTK (v. 1.7.1). These are used to test the assumptions of Metslang (2015, 2016, that morphophonology affects illative form choice.
3.2 Results: comparing long and short form preference
Our first model compares lexemes in the long bias and short bias datasets. We used the anova function in R to select variables, building up from a model with only the interface and the random factor (inflection class). The final model (AUC = 0.979) was the following:
Under the random factor of inflection class, only illative singular cell frequency remains a significant predictor of the type of bias (β = −0.438, p = 0.012). Long bias lexemes have less frequent illative singular tokens, and they vary less (long bias lexemes, M = 2,995, SD = 5,629, short bias lexemes, M = 10,653, SD = 33,716). The same model without the random factor of inflection class shows significant effects for all variables except animacy, meaning that long form bias is predicted by lower cell frequency, non-initial syllable stress, alternation with geminating short illative and lower syllable count, consonant-final stems, and higher concreteness values (0.0003 < p < 0.02, maximum quantity was removed as its Generalized Variance Inflation Factor was 5.8, indicating high collinearity). All in all, both of our hypotheses for RQ1 hold: there are no indications of argument status related lexical-semantic distinctions and all individual morphological and morphophonological effects are explained by inflection class membership.
One such effect overlapping with inflection classes was that of pattern. A finer-grained look at alternation patterns shows that very few patterns overlap between the two datasets. First, the only patterns occurring in both datasets are “gem”, “gem_s” and “i” (Figure 2). “Gem” and “i” are more or less evenly distributed between these datasets, because these are the categories shared by most inflection classes, which is ultimately the distinguishing factor between the two plots in Figure 2 (“gem” is shared by 6 classes and “i” by 3). In the “gem” pattern, the nominative stem consonant is geminated in non-derivational lexemes (e.g., pere family.nom > pere-sse ∼ perre family.ill ‘into the family’). While “gem_s” features in both groups, it dominates in the long bias dataset (61 % of lexemes) – here the final phoneme of -us derivations is geminated (lollus stupidity.nom > lolluse-sse ∼ lollusse stupidity.ill). Unlike these, lexemes with the “gem_ne” pattern almost all demonstrate short form bias. These, in turn, include another nominalisation group, i.e., deverbal -mine nominalisations (õppimine learning.nom: õppimise learning.gen > õppimise-sse ∼ õppimisse learning.ill).

Short illative formative distribution, by lexemes with short versus long form bias. All labels represent the short form, which always alternates with long forms using the agglutinative -sse affix.
Even the “other” pattern group is made up of different formatives in the two datasets, short bias lexemes including the unproductive, archaic -h- forms in illative (pea head.nom > pähe head.ill ‘into the head’), while long bias lexemes include -te/-de forms (haare grasp.nom > haarde grasp.ill ‘into grasp’) as well as other fusional forms (hooldekodu retirement-home.nom > hooldekoju retirement-home.ill ‘into the retirement home’).
3.3 Results: comparing balanced and biased distribution
In order to compare lexemes with biased and balanced distribution, two separate models were used, one for each biased distribution datasets. Both sets of variables were determined by the same process as described in Section 3.2. The model with the best fit (AUC = 0.986) for the comparison of short form bias and balanced distribution lexemes uses the following formula:
Similarly to the model in 3.2, cell frequency is the only factor which retains its effect once inflection class is introduced into the model (β = −0.957, p < 0.001). Cell frequency is much lower and less varied for balanced lexemes (balanced distribution lexemes, M = 728, SD = 2,155; short bias lexemes, M = 10,653, SD = 33,716). In an analogous glm() model without the random factor, however, four out of eight factors significantly differ between short bias and balanced distribution lexemes, the latter being more likely among lexemes with lower cell frequency and stem-final consonants (p < 0.0001), but also with non-initial syllable stress and gemination-based short forms (0.003 < p < 0.03).
The model for comparing balanced distribution to long bias lexemes was the following (AUC = 0.828):
Balanced lexemes have significantly lower cell frequency in illative singular than long bias lexemes (β = −0.532, p < 0.001). They are also shorter in terms of syllable count (β = 0.435, p = 0.003; balanced: M = 3.5, SD = 1.4; long bias: M = 2.5, SD = 1.1). A glm() model without the random factor of inflection class shows significant effects of five variables: balanced lexemes are less frequent, less concrete, longer, more likely to be vowel-final and more likely to have stem vowel based short illatives.
Up to this point (Section 3.2–3.3), we have shown that inflection class overrides morphophonological factors, but generally does not appear to affect semantic factors, which mostly do not play a role in any case, nor cell frequency, which always plays a role. Hence, at least some of the variation in terms of which form dominates the other in Estonian illative usage is guided by cell frequency and inflection class membership. When we take a closer look at class membership proportions, however, we see that long bias and balanced lexemes align much more closely to each other in terms of inflection class than to short form bias lexemes:
As shown in Figure 3, the only overlap between short bias lexemes and the other two groups is class 17, and to a lesser extent, class 22. In all other instances, lexemes in the short bias group belong to different classes than lexemes in the other two groups. In this data, class 17 is represented mostly by two-syllable lexemes with stem consonant gemination (kivi stone.nom, kivi-sse ∼ kivvi stone.ill). Such lexemes are the only group that can have either long or short bias. Class 17 nouns with balanced distribution are mostly compounds (hence the length distinction between long bias and even distribution groups, see Section 3.3). Long bias and even distribution groups have much more in common, including the fact that both are dominated by dual class membership lexemes (9 and 11, i.e., -us nominalisations). The three main classes shared by the two (11.9, 19.2, 17) dominate both datasets, describing 72 % of the long bias and 71 % of the even distribution group, meaning the two sets of lexemes mostly originate from the same classes.
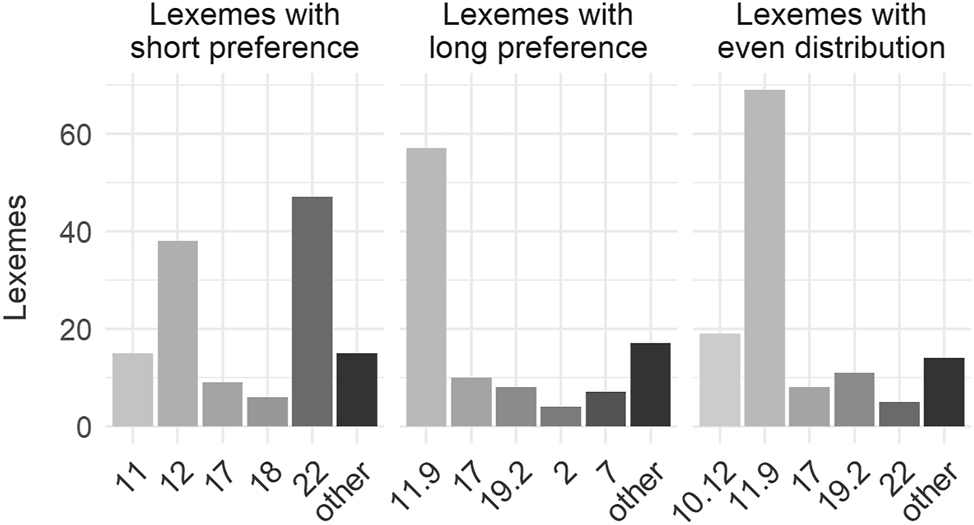
Inflection class distribution in the three datasets. Classes with 1–3 lexemes are grouped under “other”.
Furthermore, Section 3.2 mentioned that while three out of four vowel-based stem types (a-final: kõrva-sse ∼ kõrva ear.ill; e-final: pilve-sse ∼ pilve cloud.ill, u-final: laulu-sse ∼ laulu song.ill) are biased towards short forms, lexemes with i-final short forms (veebruari-sse ∼ veebruari February.ill) are found in both long and short form bias datasets. This finding highlights the effect of inflection class over morphological pattern as the i-final items in the two datasets belong to different classes: long bias lexemes with an -i formative belong to classes 2, 2.22 and 2.19, while short bias pairs belong to 19, 22 and 22.23.
All in all, inflection class membership appears to be the strongest lexical predictor of bias type next to cell frequency. It groups long bias and balanced distribution datasets together, while the short bias dataset is markedly different from both. The long bias and balanced groups do not even differ in terms of alternation patterns or their proportions in the datasets, with -us nominalisations making up 57–61 %, followed by non-derivational geminations (10–17 %) and -i stem vowel forms (11–12 %).
The factors which might facilitate the occurrence of balanced distribution include cell frequency and word length. Section 3.3 showed that longer lexemes with less frequent illative forms (lower cell frequency) are more likely to end up in the balanced dataset. The balanced distribution group contains a higher proportion of compound lexemes than the long bias group (42 % vs 12 %). However, this is not the main factor differentiating between the two groups, because, even when compounds are excluded from the data, balanced distribution lexemes show lower cell frequency (t = −3.11, df = 132.98, p = 0.002) and longer lemmas (t = 2.99, df = 137.65, p = 0.003). The effect even persists inside a single alternation pattern. For instance, gemination-based -us nominalisations (e.g., süütus innocence.nom, süütuse-sse ∼ süütusse innocence.ill.sg), make up over half of the lexemes in both datasets, but the long bias group has -us lexemes with significantly more frequent ill.sg cells (M(long) = 2,631 tokens, M(balanced) = 579 tokens; t = 2.84, df = 77.6, p = 0.006) and significantly shorter lemmas (M(long) = 2,3 syllables, M(balanced) = 3.5 syllables; t = −6.58, df = 125.25, p < 0.001). This outlines a clear, strong frequency effect. Hence, we can posit that lexemes preferring the long form may end up with even usage proportion of both available forms when they are longer and have less frequent illative singular tokens, regardless of whether they are compounds or not.
In summary, the hypothesis for RQ2 holds. Rather than being entirely distinct from short and long bias datasets, lexemes with even usage ratios between illative singular variants appear to group together with lexemes preferring the long form. Balanced distribution lexemes are, however, less frequent and longer: features which in themselves are expected to correlate in Zipfian distribution. Both long bias and balanced distribution datasets are distinct from short bias lexemes, in terms of both distinct morphophonology and lower cell frequencies.
4 Discussion and conclusions
This paper reports on an investigation of the usage of overabundant forms of illative singular nouns in Estonian from the perspective of formative preference. Two research questions targeted the potential factors in form usage bias, asking whether form usage is affected by lexical-semantic or morphophonological factors, or both.
For RQ1, we compared lexemes with long and short illative singular form bias in usage, expecting to find no lexical-semantic effects in terms of syntactic role and an effect of inflection class explaining the morphophonological factors. This was confirmed: only cell frequency and class membership were found to distinguish between bias types. Lexical-semantic factors related to verbal selection, such as animacy and concreteness, play no role in form preference, confirming the results of a clause-level study including the Estonian illative (Aigro and Vihman 2023a). This finding undermines one of the most prominent claims about Estonian illative form choice, that particular formatives correlate with usage in verb complement contexts. We also show for the first time that inflection class membership explains all the included morphophonological features, guiding form choice in language usage.
Under RQ2 we predicted that lexemes with an even distribution of parallel form use would pattern with either the short or long bias dataset, and not constitute a distinct group. This was confirmed: long bias and even distribution lexemes have the same make-up in terms of inflection class membership and accompanying similarities (morphophonology, alternation patterns). Lexemes with even distribution are longer and less frequent than long bias lexemes, but both groups differ significantly from short bias lexemes in terms of class membership and lower cell frequency. While the study finds no evidence for lexical non-synonymy in the expected domain of syntactic role (see Aigro and Vihman 2023b; Aigro 2022 for studies investigating locative cases in complement functions in Estonian), future studies will need to undertake a more thorough investigation of various semantic factors, including pragmatic and sociolinguistic factors.
We interpret the findings as indicating that inflection classes are a useful tool not only for describing the idealised paradigms of lexemes, but also the patterns of morphological behaviour in speakers’ usage, beyond what inflection classes are intended to capture. It is important to note that nothing about the inflection classes themselves prescribes a preference for one form or the other. For lexemes allowing both forms, it is unexpected that the preference in use of these forms should correlate so strongly with the morphological inflection classes.
Furthermore, the observed usage patterns of overabundant forms are not orthogonal to the inflection class system, but aligned with it, as found in Czech locative singular usage by Guzmán Naranjo and Bonami (2021). The formative preference behaviour of the lexeme groups in our study points to the possibility that in Estonian, as in Czech, overabundant lexemes belonging to two distinct inflection classes describe an inflection class in their own right, with consequences for the use of parallel forms. Although inflection classes do not incorporate gradience, the gradient frequency ratios at play in overabundance allow us to see the probabilistic effects of inflection classes in usage, otherwise hidden to a purely paradigmatic approach focusing on availability, or to a clause-level analysis.
These findings also have strong implications for the role entrenchment plays in Estonian parallel form usage. If one of the parallel formatives were morphologically more entrenched with unmarked cell meaning than the other, we would expect to find semantic factors distinguishing between them. This was not observed. In addition, it would also follow from formative entrenchment that finding both formatives of an overabundant lexeme used in similar proportions should be rare, because the more entrenched formative would be expected to dominate in frequency. However, even distribution of both formatives was not found to be a rare phenomenon in this study – all usage proportions were somewhat equally populated by lexemes, except the band where the short form dominates in more than 90 % of cell instances. In fact, more lexemes were found in certain even distribution bands than in some bands where the short form dominates (Figure 1, Section 3.1). Based on these results, we conclude that formative entrenchment is very low in the Estonian illative singular.
However, cell entrenchment seems to play a role in illative form usage. We found an effect of cell frequency in form usage in that the fusional illative singular formative – in which lexically specific knowledge determines the choice of stem vowel (karp ∼ karpi box.nom ∼ box.ill) or stem change (maja ∼ majja house.nom ∼ house.ill) – is more prominent with more entrenched cells with higher frequencies. In these instances, higher exposure to a lexeme in this cell makes lexical knowledge more cognitively accessible in processing and facilitates the use of forms depending on it. Less frequent, and less entrenched cells, however, show higher proportions of agglutinative form use (-sse), where token formation is more transparent. The same was noted by Kaalep (2018: 147), based on a small sample of Estonian partitive plural forms alternating between agglutinative and fusional forms. Hence, higher cell entrenchment (frequency) leads to a preference for morphologically more complex forms, which are made available by greater exposure. Lower entrenchment, on the other hand, leads to a preference for a more “foolproof” agglutinative strategy.
All in all, the study contributes some answers as well as raising a number of questions about inflection classes. A particular classification system of declension paradigms, in a language with such a complex system as Estonian, may be subject to some arbitrary choices on the part of the theoretician, and may be revised accordingly. However, the finding that inflectional paradigm classes have effects on form usage beyond the paradigmatic description they codify is important for the question of whether inflection classes have cognitive reality. If speakers select among parallel forms in a cell according to the class a lexeme belongs to, this must draw on a cognitive representation of class membership. Mental representations of paradigms, then, do not only include an array of cell-filling information, but also build on and enable analogical processes which connect lexemes inflected according to the same principles. This allows speakers to draw on morphological knowledge not only about a given lexeme’s paradigm, but also the inflectional class it represents. This level of representation then facilitates analogy with other class members when making online decisions about form usage.
Previous studies have similarly shown that in languages with rich morphology like Estonian, whole-word frequency has effects on morphological processing beyond the highest-frequency lexemes (e.g., Lõo et al. 2018). Moreover, effects on morphological processing have been demonstrated for paradigmatic information, phonological and morphological neighbourhood size and morphological family size (Granlund et al. 2019; Lõo et al. 2018; Vitevitch and Luce 2016). Taken together, these amount to strong evidence that mental representations include both abstract information about morphological classes and lexically specific information about inflectional particularities. Analogical processes may operate on both levels. The results of our corpus analysis show that in the case of lexical formative selection between two parallel forms, the inflection patterns a lexeme operates with may define an analogical base, and that language users make use of this analogical pool during online production. We cannot make a claim as to whether this is more bound to morphophonological similarities underlying the inflectional classes or the abstract shorthand provided by the classes themselves. Whichever is the case, the mechanism of analogical processing and basing formative selection on a lexical group defined by inflection patterns provides evidence that the inflection classes have some cognitive status of their own, and are not merely a theoretical descriptive tool. Although corpus data does not provide a direct view of speakers’ processing, nor do we have individual speaker-level information about the lexical frequency ratios, the distribution patterns are indicative, and provide solid motivation for further study using experimental approaches and further computational modelling.
Future work should also look into the nature of mixed classes, investigating their similarities to classes with only a single formative and the shape of the network they form together. Semantic vector analysis may reveal distinctions in form use and show whether contextual feature distinctions also align with inflectional classes. Finally, the question of whether the distribution of form preferences is a stable scenario in the language merits investigation in corpora large enough to allow investigations of form preference among speakers of different ages or at different time points.
Data availability statement
The datasets generated and analysed during the current study are available in the OSF repository: https://osf.io/bsp9d/.
Funding source: Arts and Humanities Research Council
Award Identifier / Grant number: AH/T002859/1
Acknowledgments
We gratefully acknowledge the support of the UK Arts and Humanities Research Council (grant no. AH/T002859/1). We are also grateful to three anonymous reviewers and the editors of this special issue for their very helpful comments, and also to Neil Bermel and other colleagues in the Feast and Famine project, who helped us greatly in conducting and writing up this research.
References
Aedmaa, Eleri. 2019. Detecting compositionality of Estonian particle verbs with statistical and linguistic methods. Tartu: University of Tartu Press.Search in Google Scholar
Aigro, Mari. 2022. In any case? Estonian spatial cases as argument markers. Tartu: University of Tartu Press.Search in Google Scholar
Aigro, Mari & Virve-Anneli Vihman. 2023a. Realised overabundance in Estonian noun paradigms: A corpus perspective. [Special issue]. Word Structure 16(2–3). 154–175. https://doi.org/10.3366/word.2023.0227.Search in Google Scholar
Aigro, Mari & Virve-Anneli Vihman. 2023b. Oblique complements in Estonian: A corpus perspective. Journal of Linguistics. 1–31. https://doi.org/10.1017/s0022226722000536.Search in Google Scholar
Aristar, Anthony R. 1997. Marking and hierarchy types and the grammaticalization of case-markers. Studies in Language 21(2). 313–368. https://doi.org/10.1075/sl.21.2.04ari.Search in Google Scholar
Baayen, R. Harald, Anna Endresen, Laura Janda, Anastasia Makarova & Tore Nesset. 2013. Making choices in Russian: Pros and cons of statistical methods for rival forms. Russian Linguistics 37. 253–291.10.1007/s11185-013-9118-6Search in Google Scholar
Bates, Douglas, Martin Mächler, Ben Bloker & Steve Walker. 2015. Fitting linear mixed-effects models using lme4. Journal of Statistical Software 67(1). 1–48. https://doi.org/10.18637/jss.v067.i01.Search in Google Scholar
Bermel, Neil & Luděk Knittl. 2012a. Corpus frequency and acceptability judgments: A study of morphosyntactic variants in Czech. Corpus Linguistics & Linguistic Theory 8(2). 241–275. https://doi.org/10.1515/cllt-2012-0010.Search in Google Scholar
Bermel, Neil & Luděk Knittl. 2012b. Morphosyntactic variation and syntactic constructions in Czech nominal declension: Corpus frequency and native-speaker judgments. Russian Linguistics 36. 91–119. https://doi.org/10.1007/s11185-011-9083-x.Search in Google Scholar
Bermel, Neil, Luděk Knittl & Jean Russell. 2018. Frequency data from corpora partially explain native-speaker ratings and choices in overabundant paradigm cells. Corpus Linguistics & Linguistic Theory 14(2). 197–231. https://doi.org/10.1515/cllt-2016-0032.Search in Google Scholar
Blevins, James P. 2008. Declension classes in Estonian. Linguistica Uralica 43(4). 241–267. https://doi.org/10.3176/lu.2008.4.01.Search in Google Scholar
Bošnjak Botica, Tomislava & Gordana Hržica. 2016. Overabundance in Croatian dual-class verbs. Fluminensia 28(1). 83–106.Search in Google Scholar
Brown, Dunstan & Marina Chumakina. 2013. What there might be and what there is: An introduction to Canonical Typology. In Dunstan Brown, Marina Chumakina & Greville Corbett (eds.), Canonical morphology and syntax, 1–19. Oxford: Oxford University Press.10.1093/acprof:oso/9780199604326.003.0001Search in Google Scholar
Corbett, Greville. 2005. The canonical approach in typology. In Zygmunt Frajzyngier, Hodges Adam & David Rood (eds.), Linguistic diversity and language theories, 25–49. Amsterdam: John Benjamins Publishing Company.10.1075/slcs.72.03corSearch in Google Scholar
Dąbrowska, Ewa. 2008. The later development of an early-emerging system: The curious case of the Polish genitive. Linguistics 46(3). 629–650. https://doi.org/10.1515/ling.2008.021.Search in Google Scholar
Divjak, Dagmar & Catherine Caldwell-Harris. 2019. Frequency and entrenchment. In Ewa Dąbrowska & Dagmar Divjak (eds.), Cognitive linguistics – Foundations of language, 61–86. Berlin, Boston: De Gruyter Mouton.10.1515/9783110626476-004Search in Google Scholar
Erelt, Mati, Reet Kasik, Helle Metslang, Henno Rajandi, Kristiina Ross, Henn Saari, Kaja Tael & Silvi Vare. 1995. Eesti keele grammatika I [Estonian grammar, vol I]. Tallinn: Estonian Academy Publishers.Search in Google Scholar
Erelt, Mati & Helle Metslang (eds.). 2017. Eesti keele süntaks [Syntax of Estonian]. Tartu: University of Tartu Press.Search in Google Scholar
Erelt, Mati, Tiiu Erelt & Kristiina Ross (eds.). 2020. Eesti keele käsiraamat [Handbook of Estonian]. Tallinn: Estonian Language Institute.Search in Google Scholar
Granlund, Sonia, Joanna Kołak, Virve-Anneli Vihman, Felix Engelmann, Elana V. M. Lieven, Julian M. Pine, Anna L. Theakston & Ben Ambridge. 2019. Language-General and language-specific phenomena in the acquisition of inflectional noun morphology: A cross-linguistic elicited-production study of Polish, Finnish and Estonian. Journal of Memory & Language 107. 169–194. https://doi.org/10.1016/j.jml.2019.04.004.Search in Google Scholar
Guzmán Naranjo, Matias. 2017. The se-ra alternation in Spanish subjunctive. Corpus Linguistics & Linguistic Theory 13(1). 97–134. https://doi.org/10.1515/cllt-2015-0017.Search in Google Scholar
Guzmán Naranjo, Matias & Olivier Bonami. 2021. Overabundance and inflectional classification: Quantitative evidence from Czech. Glossa 6(1). 1–31. https://doi.org/10.5334/gjgl.1626.Search in Google Scholar
Hawkins, John A. 2014. Cross-linguistic variation and efficiency. Oxford: Oxford University Press.10.1093/acprof:oso/9780199664993.001.0001Search in Google Scholar
Kaalep, Heiki-Jaan. 2009. Kuidas kirjeldada ainsuse lühikest sisseütlevat kasutamisandmetega kooskõlas? [Describing the short illative in accordance with usage data]. Keel ja Kirjandus 6. 411–425.Search in Google Scholar
Kaalep, Heiki-Jaan. 2010. Mitmuse osastav eesti keele käändesüsteemis [Partitive plural in the Estonian case system]. Keel ja Kirjandus 2. 94–111.Search in Google Scholar
Kaalep, Heiki-Jaan. 2018. Parallel forms in Estonian finite state morphology. In Proceedings of the 4th international workshop for computational linguistics for Uralic languages, 139–153. Helsinki: Association for Computational Linguistics.10.18653/v1/W18-0212Search in Google Scholar
Klavan, Jane. 2014. A multifactorial corpus analysis of grammatical synonymy: The Estonian adessive and adposition peal ‘on’. In Dylan Glynn & Justyna A. Robinson (eds.), Corpus methods for semantics: Quantitative studies in polysemy and synonymy, 253–278. Amsterdam: John Benjamins.10.1075/hcp.43.10klaSearch in Google Scholar
Koppel, Kristina & Jelena Kallas. 2022. Eesti keele ühendkorpuste sari 2012−2021: Mahukaim eestikeelsete digitekstide kogu. [The Estonian National Corpus series 2012−2021: The largest collection of digital texts in Estonian]. Estonian Papers in Applied Linguistics 18. 207–228. https://doi.org/10.5128/erya18.12.Search in Google Scholar
Lečić, Dario. 2015. Morphological doublets in Croatian: The case of the instrumental singular. Russian Linguistics 39. 375–393. https://doi.org/10.1007/s11185-015-9152-7.Search in Google Scholar
Lõo, Kaidi, Juhani Järvikivi, Fabian Tomaschek, Benjamin Tucker & R. Harald Baayen. 2018. Production of Estonian case-inflected nouns shows whole-word frequency and paradigmatic effects. Morphology 28. 71–97. https://doi.org/10.1007/s11525-017-9318-7.Search in Google Scholar
Metslang, Ann. 2015. Ainsuse pika ja lühikese sisseütleva valiku olenemine morfofonoloogilistest tunnustest: Korpusanalüüs. [The effect of morphophonological factors on the variation of long and short illative singular: A corpus study]. Yearbook of the Estonian Mother Tongue Society 60. 127–147. https://doi.org/10.3176/esa60.06.Search in Google Scholar
Metslang, Ann. 2016. Ainsuse sisseütleva vormi valiku seos morfosüntaktiliste ja semantiliste tunnustega [The effect of morphosyntactic and semantic factors on the variation of long and short illative singular]. Yearbook of the Estonian Mother Tongue Society 61. 207–232.10.3176/esa61.10Search in Google Scholar
Santilli, Enzo. 2014. Italian comparatives: A case of overabundance? L’Aquila: University of L’Aquila Dissertation.Search in Google Scholar
Siiman, Ann. 2019. Vormikasutuse varieerumine ning selle põhjused osastava ja sisseütleva käände näitel [Variation in form usage in partitive and illative case]. Tartu: University of Tartu Press.Search in Google Scholar
Szmrecsanyi, Benedikt. 2010. The English genitive alternation in a cognitive sociolinguistics perspective. In Dirk Geeraerts, Gitte Kristiansen & Yves Peirsman (eds.), Advances in cognitive sociolinguistics, 141–166. Berlin and New York: Mouton de Gruyter.10.1515/9783110226461.139Search in Google Scholar
Thornton, Anna M. 2011. Overabundance (multiple forms realizing the same cell): A non-canonical phenomenon in Italian verb morphology. In Martin Maiden, John Charles Smith, Maria Goldbach & Marc-Oliver Hinzelin (eds.), Morphological autonomy: Perspectives from Romance inflectional morphology, 358–381. Oxford: Oxford University Press.10.1093/acprof:oso/9780199589982.003.0017Search in Google Scholar
Thornton, Anna M. 2019. Overabundance: A Canonical Typology. In Franz Rainer, Francesco Gardani, Wolfgang U. Dressler & Hans Christian Luschützky (eds.), Competition in inflection and word-formation, 223–258. Dordrecht: Springer.10.1007/978-3-030-02550-2_9Search in Google Scholar
Viht, Annika & Külli Habicht. 2019. Eesti keele sõnamuutmine [Estonian inflection system]. Tartu: University of Tartu Press.Search in Google Scholar
Viitso, Tiit-Rein. 1976. Eesti muutkondade süsteemist [Inflection class system in Estonian]. Keel ja Kirjandus 3. 148–162.Search in Google Scholar
Viks, Ülle. 1982. Klassifikatoorne morfoloogia. Noomen [Classifying morphology: Nominals]. Tallinn: Estonian Academy Publishers.Search in Google Scholar
Viks, Ülle. 1992. Väike vormisõnastik [Small Form Dictionary]. Tallinn: Estonian Academy Publishers.Search in Google Scholar
Vitevitch, Michael S. & Paul A. Luce. 2016. Phonological neighborhood effects in spoken word perception and production. Annual Review of Linguistics 2. 75–94. https://doi.org/10.1146/annurev-linguistics-030514-124832.Search in Google Scholar
Zipf, George K. 1949 [2012]. Human behavior and the principle of least effort. Connecticut: Martino Publishing.Search in Google Scholar
© 2024 the author(s), published by De Gruyter, Berlin/Boston
This work is licensed under the Creative Commons Attribution 4.0 International License.
Articles in the same Issue
- Frontmatter
- Research Articles
- Cognitive approaches to uniformity and variability in morphology
- Ideal and real paradigms: language users, reference works and corpora
- Baseless derivation: the behavioural reality of derivational paradigms
- The role of entrenchment and schematisation in the acquisition of rich verbal morphology
- Preferences in the use of overabundance: predictors of lexical bias in Estonian
Articles in the same Issue
- Frontmatter
- Research Articles
- Cognitive approaches to uniformity and variability in morphology
- Ideal and real paradigms: language users, reference works and corpora
- Baseless derivation: the behavioural reality of derivational paradigms
- The role of entrenchment and schematisation in the acquisition of rich verbal morphology
- Preferences in the use of overabundance: predictors of lexical bias in Estonian